Torch-Rechub学习笔记-task2
Torch-Rechub学习笔记-task2
以下以DatawhaleTorch—Rechub组队学习的Task笔记
[项目开源地址]: https://github.com/datawhalechina/torch-rechub
推荐系统召回模型与向量检索
task2中主要是对推荐场景的召回部分进行探索,具体引用到以下的模型以及工具。
- 场景:召回(Matching/Retrieval)
- 模型:DSSM、YouTubeDNN
- 数据集:MovieLens-1M
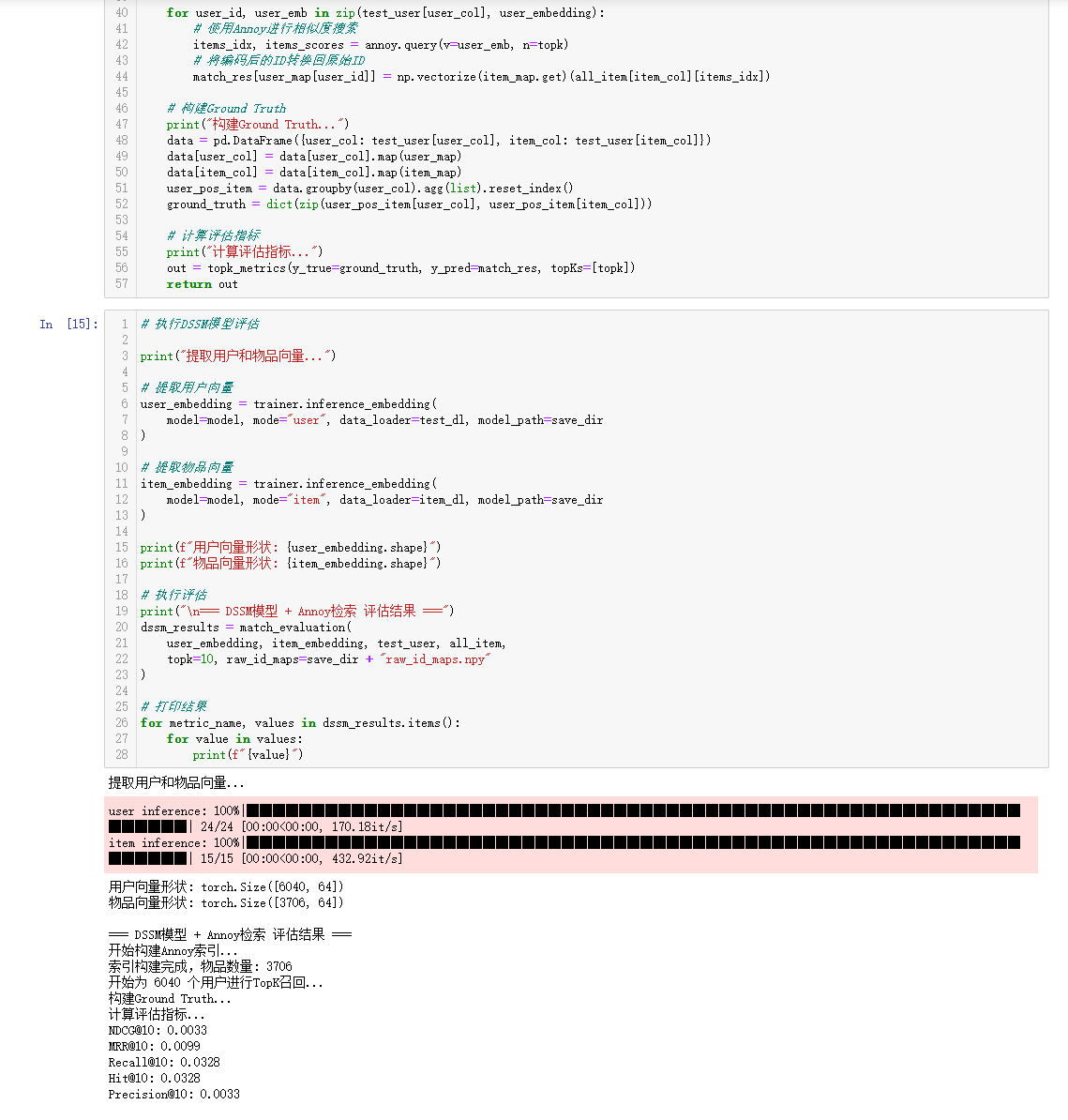
- 向量检索:Annoy、Milvus
- 通过代码的角度去对比DSSM以及YouTubeDNN两个模型之间的差异以及特点
- 向量检索工具Milvus的环境搭建和使用部署
- 模型训练后生成的embedding应用在向量检索工具Annoy和Milvus的功能、优势和使用场景
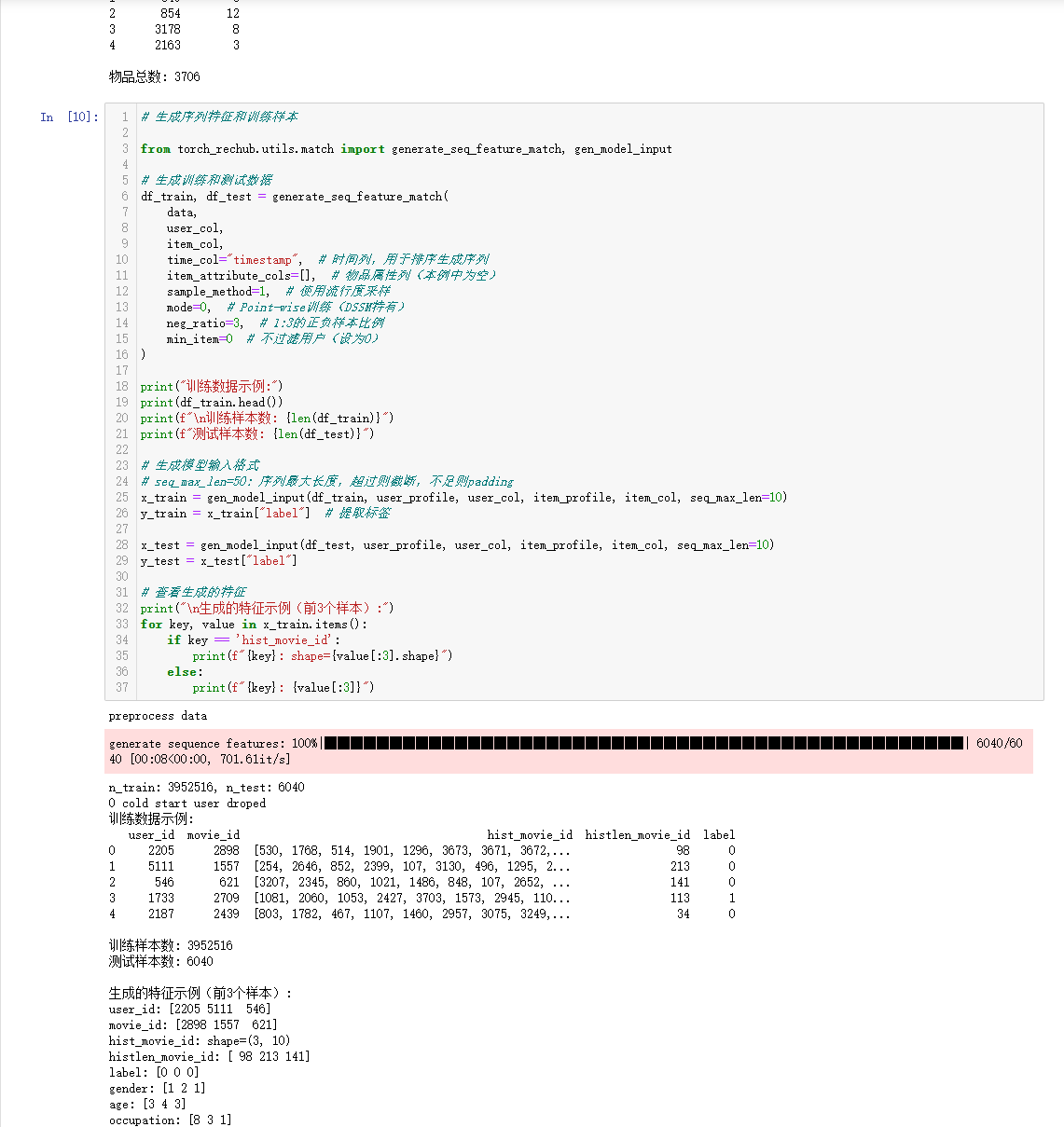
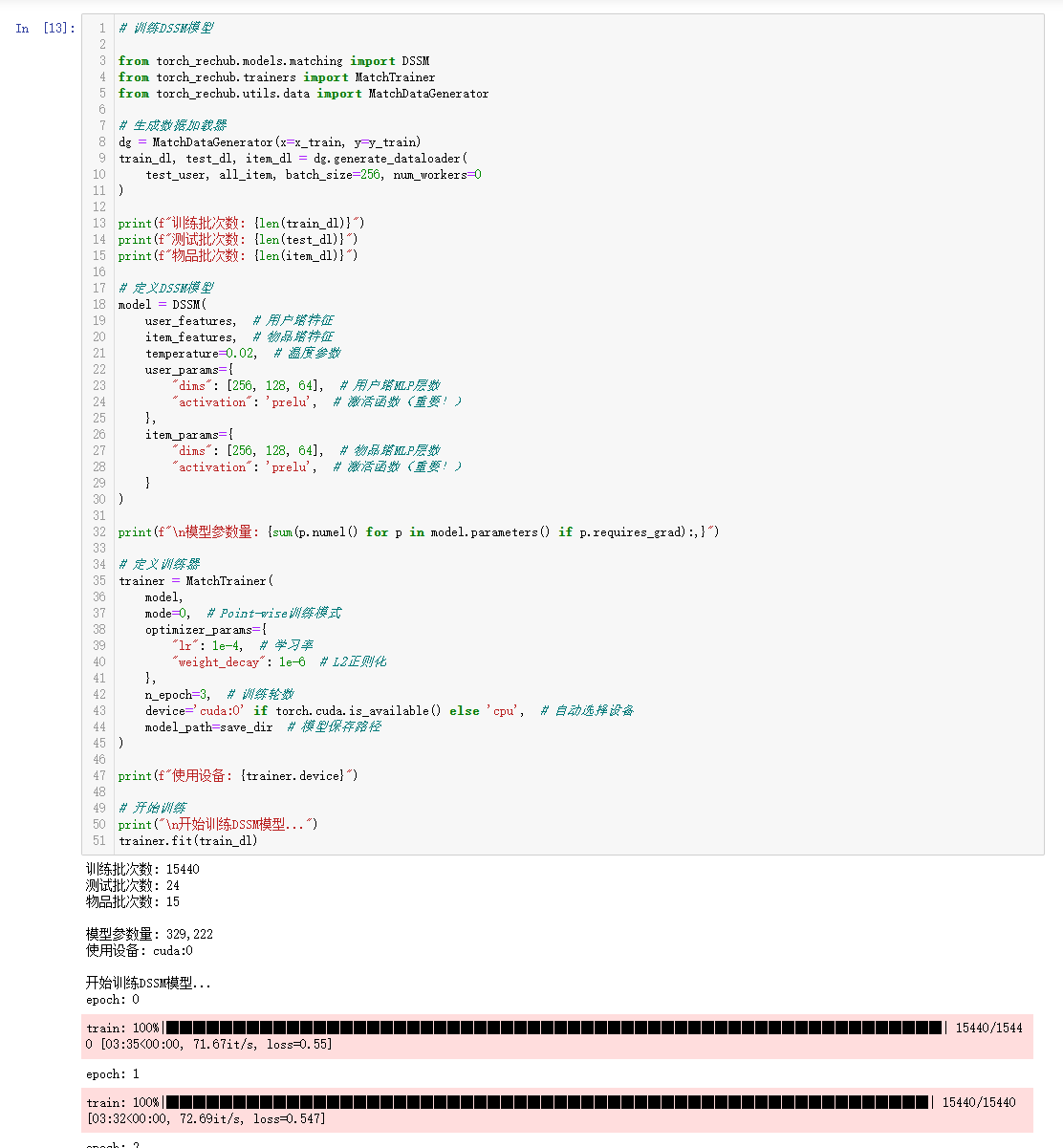
代码与task1中的召回模型代码结构大差不差,本次学习具体还是对向量检索工具Milvus的使用和部署。
部分代码贴图

学习思考以及心得
task2中我的主要学习重点偏向于向量检索工具这方面,首先Milvus是我新接触到的向量检索工具,通过代码能够了解到该工具的使用。以及课程有关于该工具与annoy的性能对比,能够非常直观的感受到Milvus性能和生产化部署的便捷,而且也学习到了部署方式。同时也需要思考课后提到的优化项和扩展学习(包括生产上面的监控、A/BTest、更多特征挖掘处理)等等。