HDFS和MapReduce——Hadoop的两大核心技
摘要
本文介绍了了Hadoop中两个非常核心的技术——HDFS和MapReduce。Hadoop是一个分布式系统基础架构,它主要是通过HDFS来实现对分布式存储的底层支持,以及通过MapReduce来实现对分布式并行任务处理的程序支持。本文分别介绍了HDFS和MapReduce体系结构的相关技术。
关键词:云计算, Hadoop,HDFS,MapReduce
1. 引言
Hadoop是一个分布式系统基础架构,由Apache基金会开发。用户可以再不了解分布式底层细节的情况下,开发分布式程序。它充分利用集群的威力告诉运算和存储。Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。HDFS有着高容错性的特点,并且设计用来部署在低廉的硬件上。而且,它提供高传输率来访问应用程序的数据,适合那些有着超大数据集的应用程序。HDFS放宽了POSIX的要求,这样可以以流的形式访问文件系统的数据。
2. HDFS和MapReduce综述
HDFS和MapReduce是Hadoop的两大核心。而整个Hadoop的体系结构主要是通过HDFS来实现对分布式存储的底层支持的,并且它会通过MapReduce来实现对分布式并行任务处理的程序支持。
2.1 HDFS的体系结构
HDFS采用了主从(Master/Slave)结构模型,一个HDFS集群是由一个NameNode和若干个DataNode组成的。其中NameNode作为主服务器,管理文件系统的命名空间和客户端对文件的访问操作;集群中的DataNode管理存储的数据。HDFS允许用户以文件的形式存储数据。从内部来看,文件被分成若干个数据块,而且这若干个数据块存放在一组DataNode上。NameNode执行文件系统的命名空间操作,比如打开、关闭、重命名文件或目录等,它也负责数据块到具体DataNode的映射。DataNode负责处理文件系统客户端的文件读写请求,并在NameNode的统一调度下进行数据块的创建、删除和复制工作。下图给出了HDFS的体系结构。
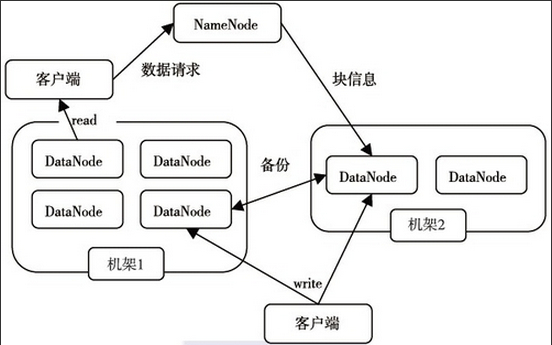
图2.1 HDFS的体系结构
NameNode和DataNode都被设计成可以在普通商用计算机上运行。这些计算机通常运行的是GNU/Linux操作系统。HDFS采用Java语言开发,因此任何支持Java的机器都可以部署NameNode和DataNode。一个典型的部署场景是集群中的一台机器运行一个NameNode实例,其他机器分别运行一个DataNode实例。当然,并不排除一台机器运行多个DataNode实例的情况。集群中单一的NameNode的设计则大大简化了系统的架构。NameNode是所有HDFS元数据的管理者,用户数据永远不会经过NameNode。
2.2 MapReduce的体系结构
MapReduce是一种并行编程模式,这种模式使得软件开发者可以轻松地编写出分布式并行程序。在Hadoop的体系结构中,MapReduce是一个简单易用的软件框架,基于它可以将任务分发到由上千台商用机器组成的集群上,并以一种高容错的方式并行处理大量的数据集,实现Hadoop的并行任务处理功能。MapReduce框架是由一个单独运行在主节点上的JobTracker和运行在每个集群从节点上的TaskTracker共同组成的。主节点负责调度构成一个作业的所有任务,这些任务分布在不同的从节点上。主节点监控它们的执行情况,并且重新执行之前失败的任务;从节点仅负责由主节点指派的任务。当一个Job被提交时,JobTracker接收到提交作业和配置信息之后,就会将配置信息等分发给从节点,同时调度任务并监控TaskTracker的执行。
2.3 小结
从上面的介绍可以看出,HDFS和MapReduce共同组成了Hadoop分布式系统体系结构的核心。HDFS在集群上实现了分布式文件系统,MapReduce在集群上实现了分布式计算和任务处理。HDFS在MapReduce任务处理过程中提供了文件操作和存储等支持,MapReduce在HDFS的基础上实现了任务的分发、跟踪、执行等工作,并收集结果,二者相互作用,完成了Hadoop分布式集群的主要任务。
3. HDFS相关技术
3.1 RPC
RPC(Remote Procedure Call)指远程过程调用协议。它通过网络从远程计算算计程序上请求服务,而不需要了解底层网络技术的协议。RPC协议假定已经存在某些传输 协议,如TCP或UDP,它采用客户机/服务器模式。为通信程序之间携带信息数据。HFDS源代码中大量使用了RPC。
RPC采用客户机/服务器面膜是,请求程序就是一个客户机,而服务提供程序就是一个服务器。首先,客户机调用进程发送一个有进程参数的调用信息岛服务进程,然后等待答应信息。在服务器端,进程保持睡眠状态直到调用信息的到达为止。当一个调用信息到达,服务器获得进程参数,计算结构,发送答复信息,然后等待下一个调用信息,最后,客户端调用进程接受答复信息,获得进程结果,然后调用继续进行。
3.2 基于Socket的Java网络编程
网络编程简单的理解就是两台计算机相互通信。对于程序员而言,去掌握一种编程接口并使用一种编程模型相对就会简单许多。JavaSDK提供一些相对简单的API来完成这些工作,Socket就是其中之一。对于Java而言,这些API存在于Java.net这个包里面,因此只要导入这个包就可以准备网络编程了。
网络上的两个程序通过一个双向的通信链接实现数据的交换,这个双向链路的的一段称为一个Socket。Socket通常用来实现客户方和服务方的连接。Socket是TCP/IP协议的一个十分流行的编程界面,一个Socket由一个IP地址和一个端口唯一确定。
但是,Socket所支持的协议种类也不光TCP/IP一种,因此两者间是没有必然联系的。在Java环境下,Socket编程主要是指基于TCP/IP协议的网络编程。
3.2 Socket通信过程
Server端监听某个端口是否有连接请求,Client端向Server端发出Connect请求,Server端向Client端发回Accept消息,这样一个连接就建立起来了。Server端和Client端都可以通过Send、Write等方法与对方通信。
对于一个功能齐全的Socket,其工作过程包含以下4个基本步骤:
- 创建Socket;
- 打开连接到Socket的输入/出流;
- 按照一定的协议对Socket进行读/写;
- 关闭Socket。
3.3 创建Socket
Java在包Java.net中提供了两个类Socket和ServerSocket,分别用来表示双向连接的客户端和服务端。这是两个封装得非常好的类。
需要注意的是,每一个端开口提供一种特定的服务,只有给出正确的端口,才能获得相应的服务。0至1023的端口号为系统所保留,例如,HTTP的服务的端口号为80,telnet服务的端口号为21,ftp服务的端口号为23,所以在选择端口号时,最好选择一个大于1023的数,以防止发生冲突。
在创建Socket时如果发生错误,将产生IOException,在程序中必须对之做出处理。所以在创建Socket或ServerSocket时必须捕获或抛出异常作出处理。所以在创建Socket或ServerSocket时必须捕获或抛出例外。
4. MapReduce相关技术
4.1 Java反射机制
Java反射机制是Java语言被视为准动态语言的关键性质。Java反射机制的核心就是允许在运行时通过Java Reflection APIs 来取得已知名字的Class类的相关信息,动态地生成此类,并调用其方法或修改其域(甚至是本身声明为private的域或方法)。
Java中有一个Class类,Class类本身表示Java对象的类型,可以通过一个Object(子)对象getClass方法取得一个对象的类型,此函数返回的就是一个Class类。当然,获得Class对象的方法有许多,但是没有一种方法是通过Class的构造函数来生成Class对象的。
Class类是整个Java反射机制的源头。要想使用Java反射,需要首先得到Class类的对象。
4.2 序列化和反序列化
序列化是将对象状态转换为可保持或传输的格式的过程。与序列化相对的是反序列化。它将流转换为对象。这两个过程结合起来,可以轻松地存储和传输数据。在下面3种情况下需要进行序列化:
- 把内存中的对象状态保存到一个文件中或者数据库中的时候。
- 用套接字在网络上传送对象的时候。
- 通过RMI(远程方法调用)传输对象的时候。
在没有序列化之前,每个保存在堆(Heap)中的对象都有相应的状态(State),即实现变量(Instance Variable)。
实现Java.io.Serializable接口对象可以转换成字节流或从字节流恢复,不需要在类中增加任何代码。只有极少数情况下才需要定制代码保存或恢复对象状态。这里要注意:不是每个类都可以序列化,有些类是不能序列化的,如涉及线程的类与特定JVM有非常复杂的关系。
序列化和反序列化的过程就是对象写入字节流和从字节流中读取对象。将对象状态转换成字节流后,可以用java.io包中的各种字节流类将其保存到文件中,通过管道传输到另一线程中或通过网络连接将对象数据发送到另一主机。对象序列化功能在RMISocket、JMS等方卖弄都有应用。对象序列化有许多实用意义:
(1)对象序列化可以实现分布式对象。主要应用如:RMI要利用对象序列化运行远程主机上的服务,就像在本地机上运行对象时一样。
(2)Java对象序列化不仅保留一个对象的数据,而且递归保存对象引用的每个对象的数据。可以讲整个对象层次写入字节流中,可以保存在文件中或在网络连接上传递。利用对象序列化可以进行对象的“深复制”,即复制对象本身及引用的对象本身。序列化一个对象可能得到整个对象序列。
5. Hadoop前景
Winter Corp.咨询公司的总裁Richard Winter说道大数据技术方面出现了两个主要发展趋势。首先,传统的数据仓库供应商正在引入可扩展性优化技术,以适应事务数据容量的增加。其次,诸如Hadoop、MapReduce和NoSQL等新开源技术也在兴起,主要用来替代用于跟踪其他形式大数据的数据仓库——例如,Web活动日志和检测数据。
Winter说:“如果您有大量的数据需要管理和分析,那么数据仓库可能是一种非常昂贵的解决方案。”它对于事务数据并非一定是有效的:通常数据仓库技术在处理组织中保持高度结构化、严格管理和使用广泛的数据时是具有较高投资回报的。
但采用Hadoop类型的方法来处理大数据管理在特定情况下更为经济。例如,科学研究过程可能产生大量的数据,位于日内瓦的高强子碰撞机每年产生15PB的高能物理实验原始检测数据。
Hadoop是一种框架,支持在集群系统之间采用分布式机制处理大数据集;它的MapReduce组件是用于编写基于Hadoop应用程序的编程模型。Forrester分析师Kobielus认同Winter的观点,他也认为Hadoop在管理大数据方面发挥重要作用。而在2011年6月的一篇博客中他提到,Forrester客户关于Hadoop的咨询已经从“到底Hadoop是什么?”变为更多是“有哪些供应商提供可靠的Hadoop解决方案?”
然而Hadoop并非适合所有情况。Kobielus认为Hadoop很好但仍然不成熟。他在博客中提到,Hadoop已经被许多公司成功应用来支持“极具可扩展性的”分析应用程序。另一方面,在有更多数据仓库供应商应用这项技术以及早期应用者整合了核心技术协议之后,Hadoop才会被更广泛的企业应用。
根据Kobielus的介绍,在今年初Forrester Wave发布一篇关于数据仓库平台的报告,报告提到的供应商中只有两家在他们的核心产品中使用了Hadoop。他写道:其他供应商“只是初步接触Hadoop,而且仅仅停留在使用层面。”但是他预期大多数主流供应商“将来可能会通过收购而更全面地使用Hadoop”。
在用户端,Kobielus表示MapReduce似乎是他所采访公司所应用的Hadoop的唯一通用元素。他写道:“除非我们都接受在每一次部署中投入资源进行优化,否则我们还不能说Hadoop已经具备全面应用的水平。”此外,管理Hadoop和相关项目的Apache开源社区应该将技术提交到一个正式标准过程,以保证跨平台互操作性。
根据分析,现在的Hadoop部署通常是由应用程序开发人员完成,组织的IT和数据仓库管理员并未参与其中。多伦多一家咨询公司WiseAnalytics的总裁和创始人Lyndsay Wise说,就长期而言,Hadoop很可能会被更多地整合到主流的数据仓库过程中。
那么,大数据技术会越来越受到重视吗?Wise说:“几年前,主数据管理和数据治理的概念大多出现在数据仓库领域之外,但是现在组织更关注于他们数据仓库环境内的这类问题。”类似地,随着数据变得“越来越复杂”,以及组织认识到提高数据仓库策略的管理效率有利于从信息获取更高的商业价值,越来越多的数据仓库团队最终会参与管理Hadoop和MapReduce实现。
但是,TechTarget公司的业务应用程序和架构媒体部门的研究主管Wayne Eckerson说,组织在大数据技术的投入程度应该避免受到市场宣传的影响,这其中既包括反对传统数据中心仓库的言论,也包括推崇Hadoop及其他新技术的言论。
Eckerson指出,Hadoop尽管是开源的,但也并非免费的午餐。除了硬件和其他技术成本,还包括许多内部资源问题:“无论用什么技术,您都需要配备人员——而他们中有一些是非常稀缺的人才。”
Eckerson提醒说,Hadoop也可能产生废进废出的情况。他说:“Hadoop人员需要确定他们处理的信息是否有价值,因此它们需要清除无价值的信息,否则会将时间浪费在无用的数据上。Hadoop是否有用并不是问题;问题是Hadoop是否真正被某个特定组织所使用。”