F021 五种推荐算法之美食外卖推荐可视化系统vue+flask
文章结尾部分有CSDN官方提供的学长 联系方式名片
B站up账号: 麦麦大数据
关注B站,有好处!
编号: F021
视频
五种推荐算法之美团美食外卖推荐大数据可视化系统python vue源码(+百度热力图+无敌爬虫)
1 系统简介
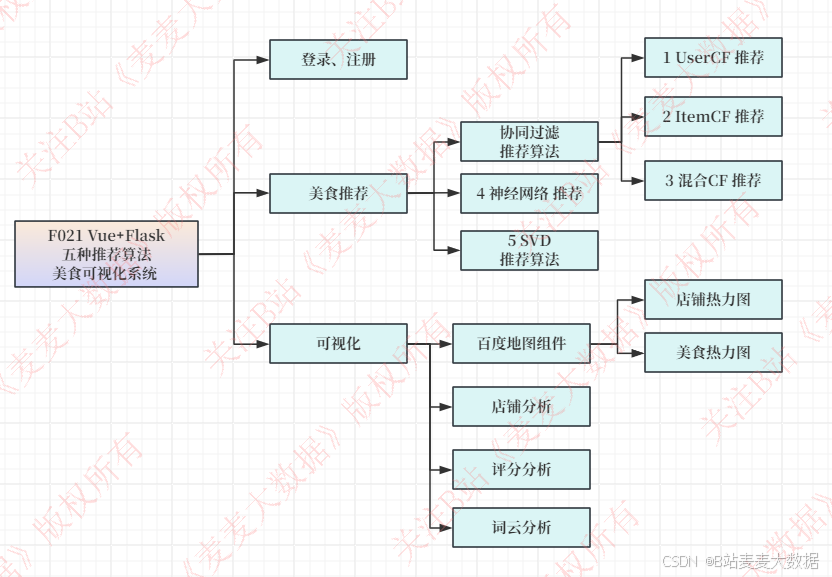
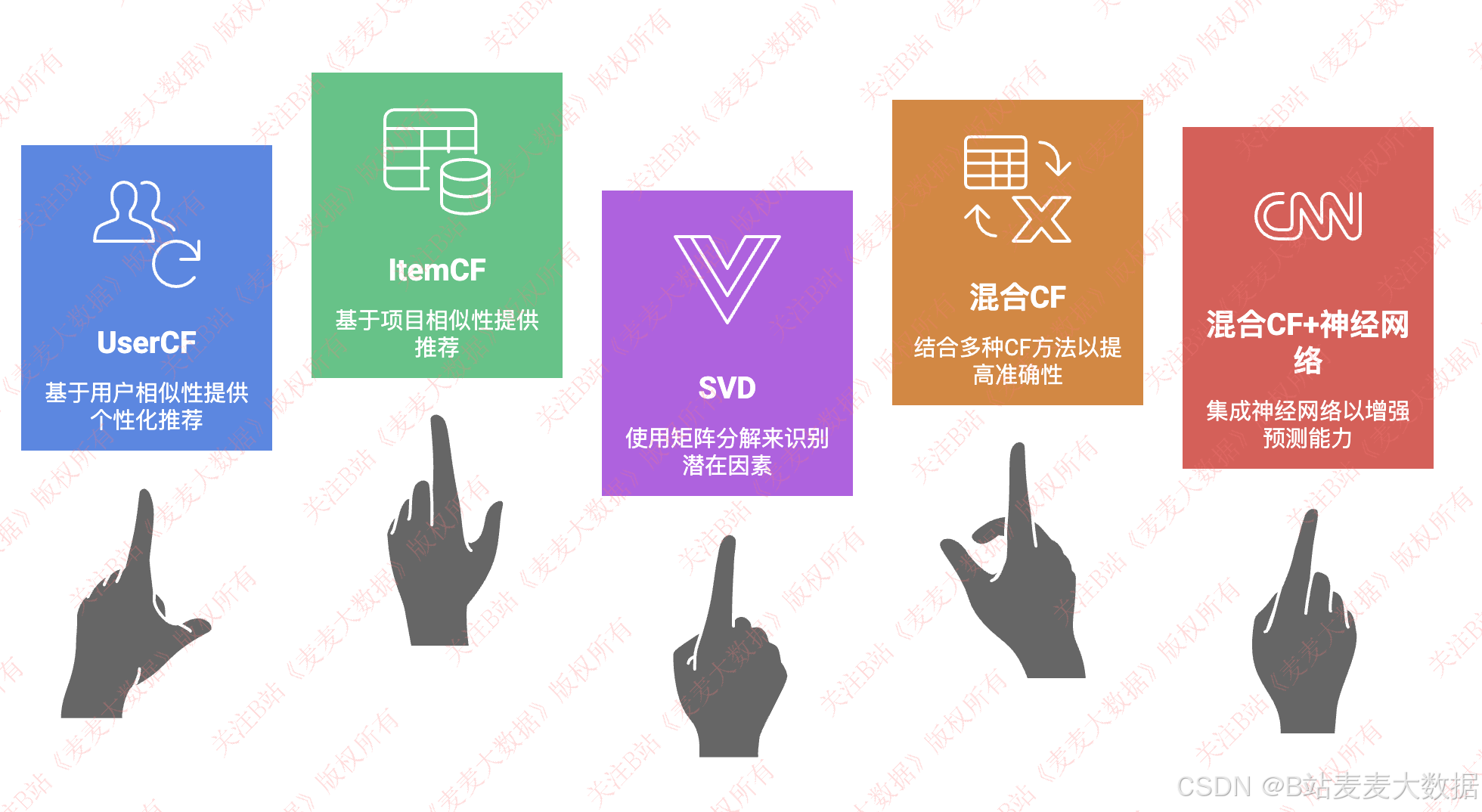
系统简介:本系统是一个基于Vue+Flask架构的美食推荐可视化平台,核心功能包括美食数据的展示与存储、多种美食推荐算法的应用,以及丰富的用户交互与数据分析功能。系统通过爬虫模块从外部来源抓取美食数据并存入MySQL数据库;在美食推荐方面,集成了五种推荐算法:UserCF(基于用户的协同过滤)、ItemCF(基于物品的协同过滤)、SVD(奇异值分解)、混合CF(结合多种协同过滤方法)以及混合CF+神经网络(融合协同过滤与深度学习),为用户提供个性化的美食推荐。此外,系统还包含用户管理模块(登录与注册功能)、百度地图集成(用于展示美食店铺位置及评分)、店铺热力图(可视化店铺热度分布)、店铺分析(通过柱状图、折线图等展示店铺数据趋势)、以及美食评分分析(使用仪表盘、花瓣图等可视化工具展示评分分布和用户反馈)。整体设计旨在提升用户体验,通过数据驱动的方式帮助用户发现美食。
2 功能设计
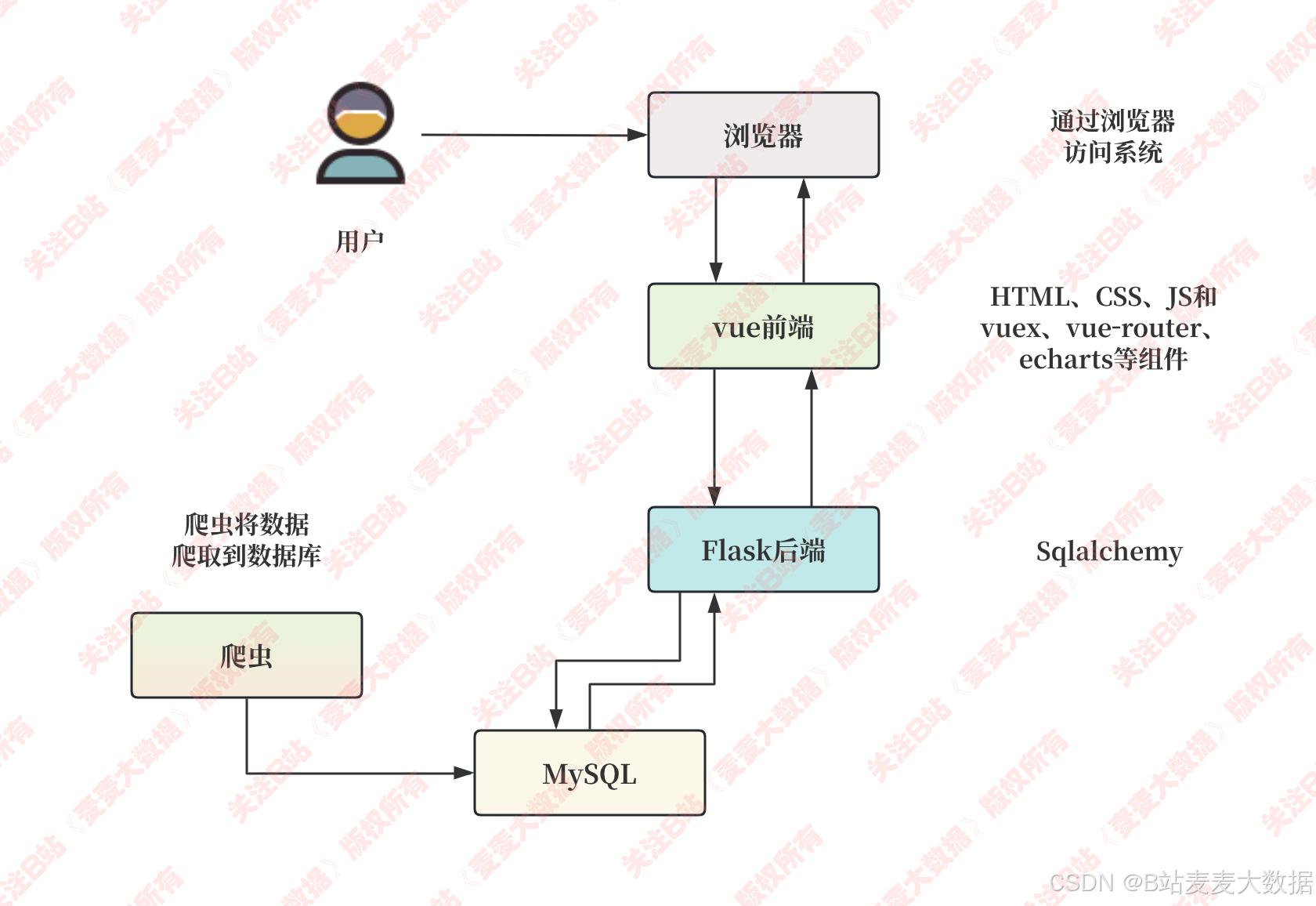
该系统采用B/S(浏览器/服务器)架构模式。用户通过浏览器访问基于Vue.js构建的前端界面,该前端利用HTML、CSS、JavaScript以及Vue生态系统中的组件(如Vuex用于状态管理、Vue Router用于路由导航)和可视化库(如Echarts用于图表展示)实现交互功能。前端通过RESTful API与Flask后端进行数据交互,Flask后端负责处理业务逻辑,包括用户认证、推荐算法执行(集成UserCF、ItemCF、SVD、混合CF和混合CF+神经网络)、数据查询和地图集成(如调用百度地图API)。后端使用SQLAlchemy(或类似ORM工具)与MySQL数据库进行数据持久化,存储数据、用户信息、美食店铺数据及评分。系统还包含一个独立的爬虫模块,用于定期从外部源抓取电影数据并导入MySQL,确保数据的新鲜度和完整性。整体架构确保了系统的可扩展性、高性能和用户友好性。
2.1系统架构图
2.2 功能模块图
五大算法
3 功能展示
3.1 登录 & 注册
登录注册做的是一个可以切换的登录注册界面,点击去登录后者去注册可以切换,背景是一个视频,循环播放。
登录需要验证用户名和密码是否正确,如果不正确会有错误提示。
注册需要验证用户名是否存在,如果错误会有提示。
3.2 主页 数据统计
主页的布局采用了左侧是菜单,右侧是操作面板的布局方法,右侧的上方还有用户的头像和退出按钮,如果是新注册用户,没有头像,这边则不显示,需要在个人设置中上传了头像之后就会显示。
数据统计展示了店铺总数和经营各类不同类型店铺的数量:

3.3 推荐算法
usercf:

itemcf:

svd:

混合CF:

神经网络:

3.4 数据分析
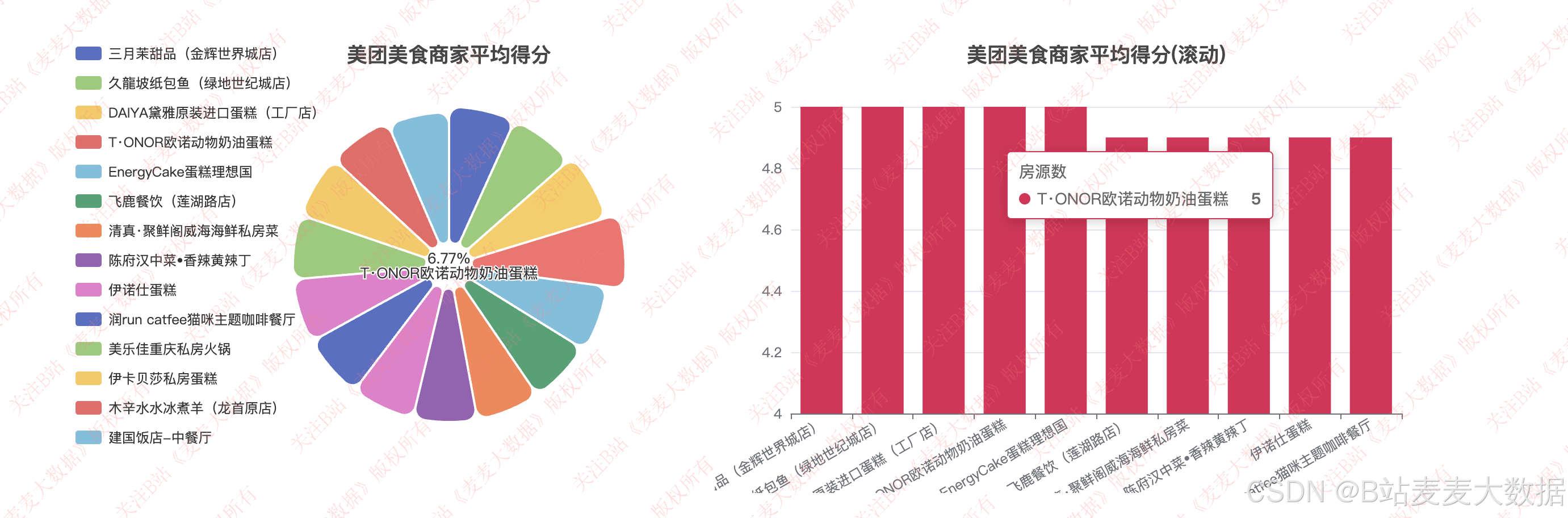
得分分析:
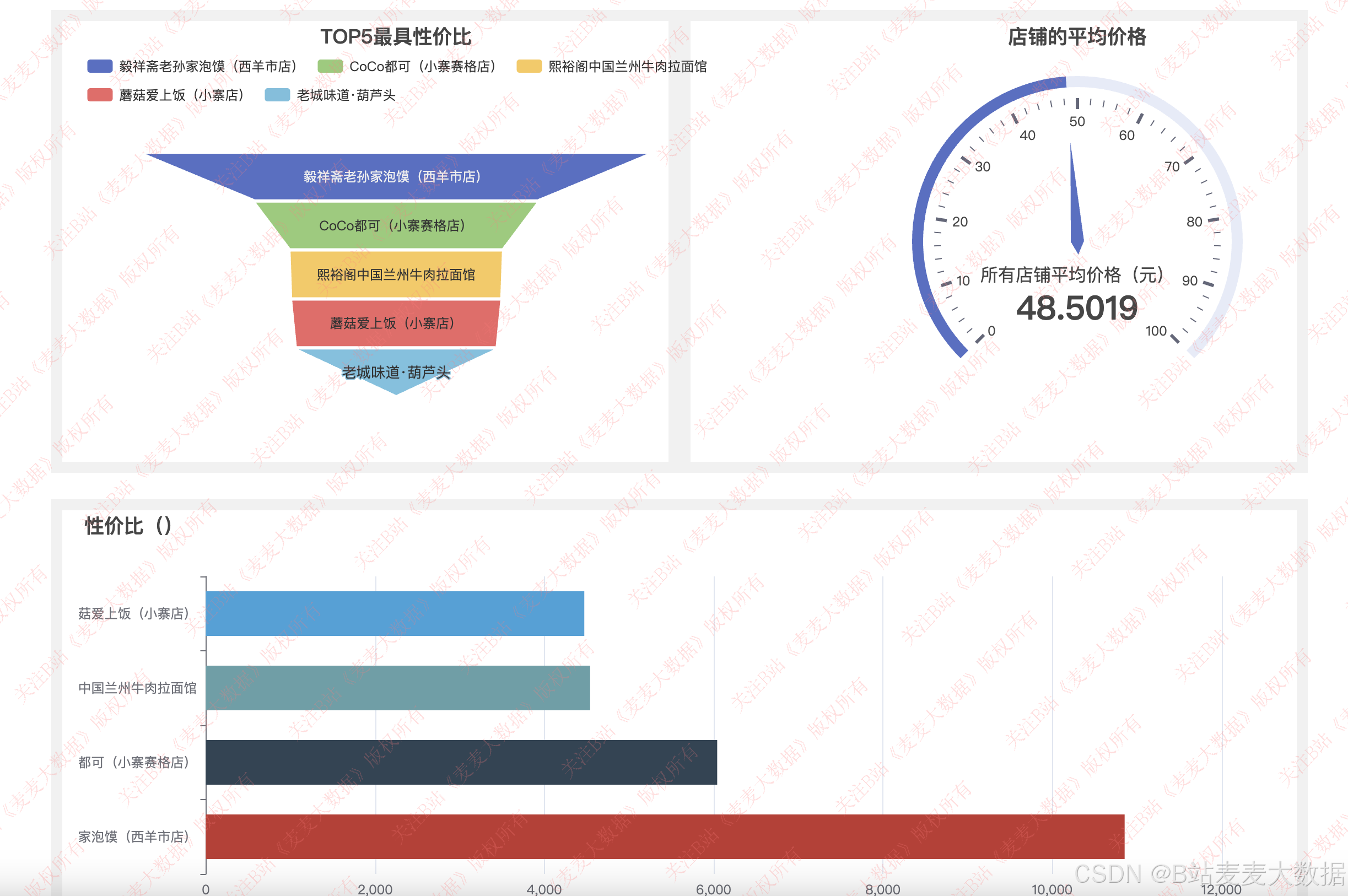
性价比分析:
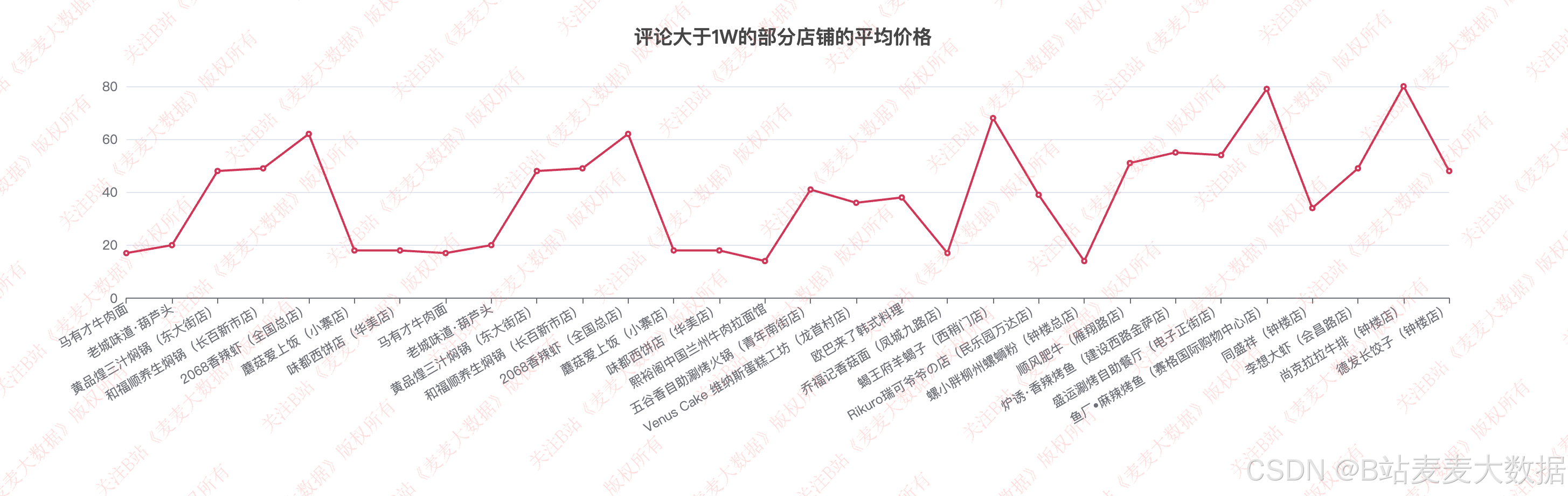
价格分析:
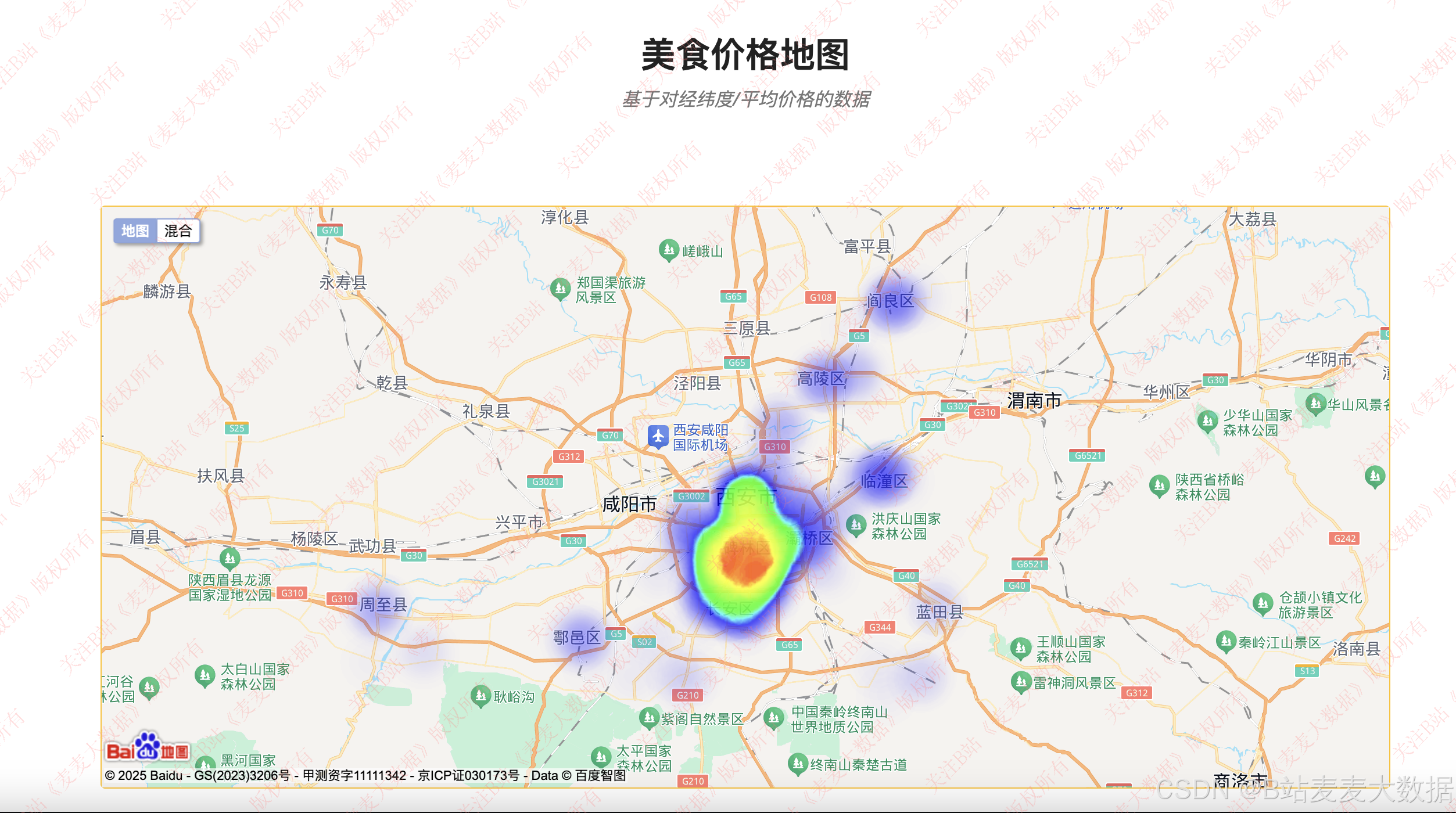
利用百度地图实现的价格热力图:
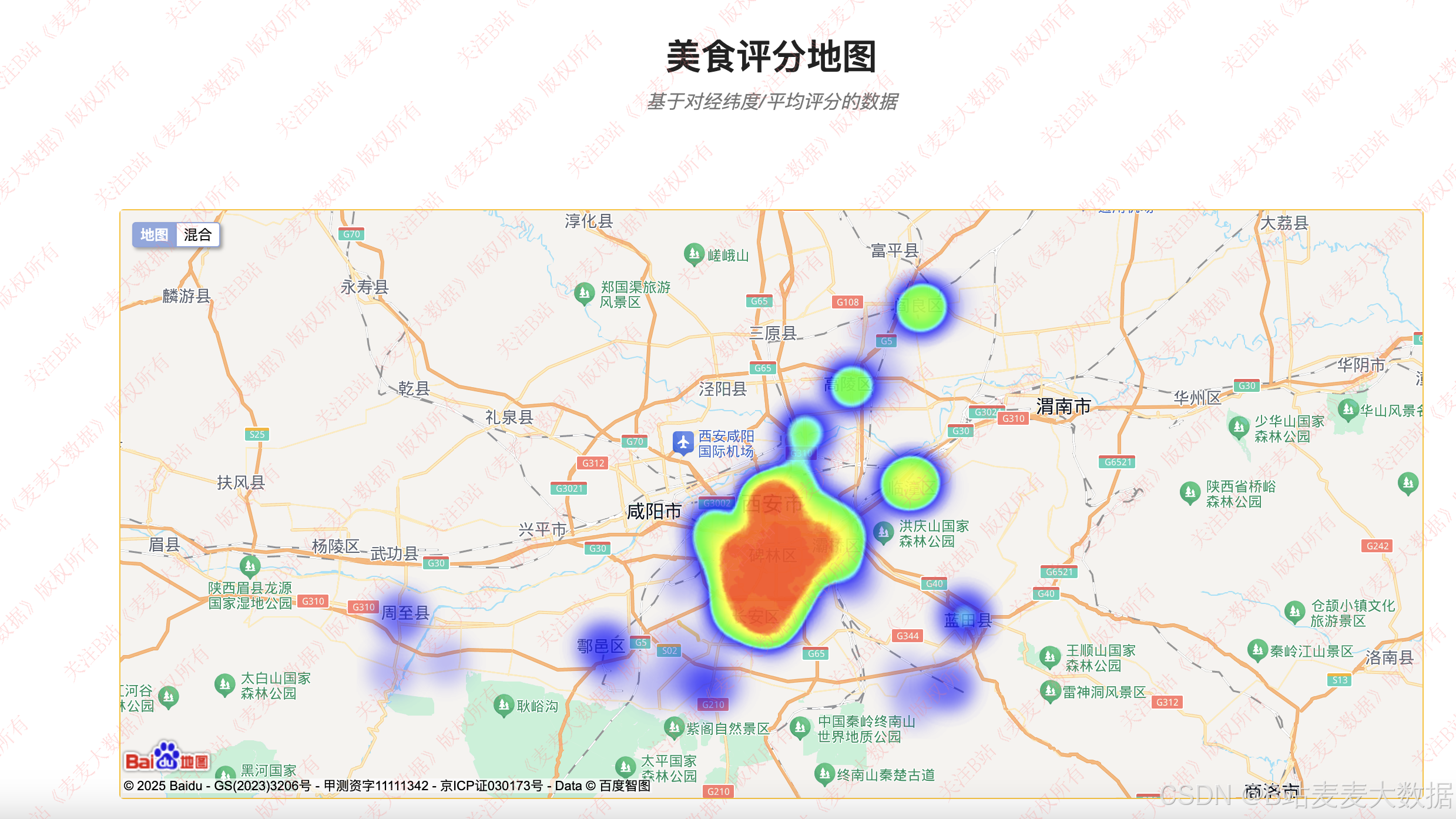
利用百度地图实现的评分热力图:
词云分析:

4程序代码
4.1 代码说明
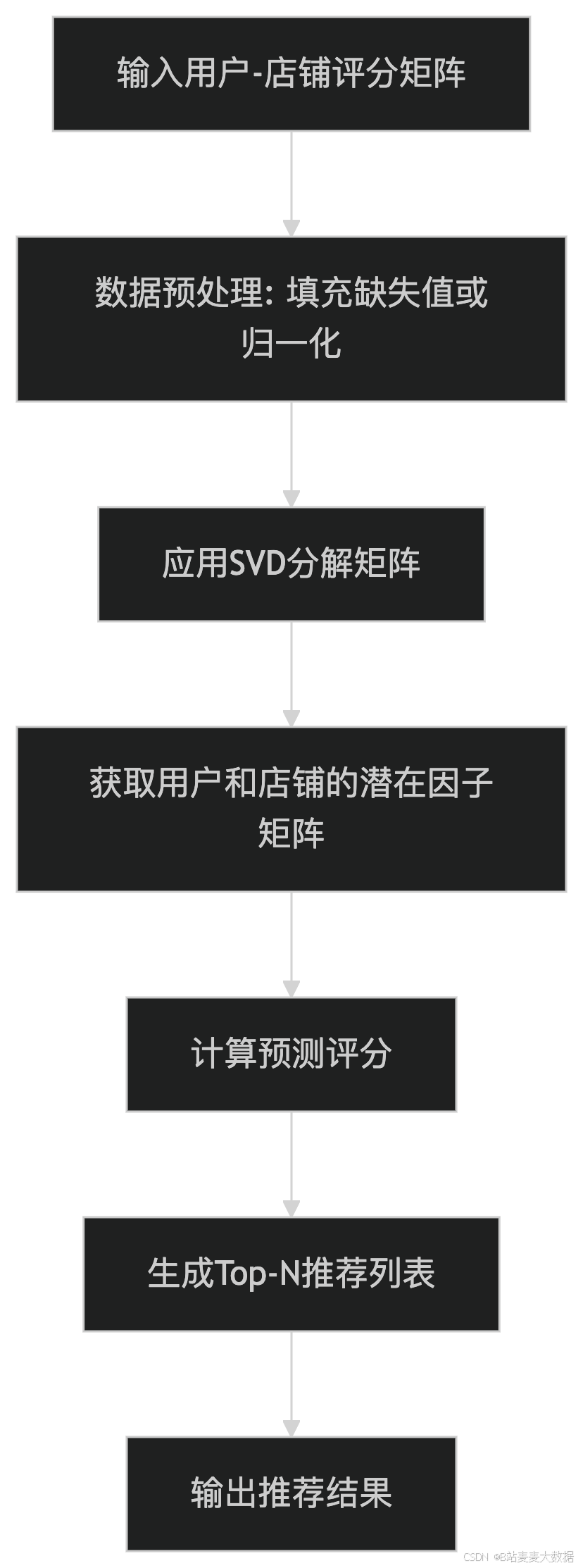
代码介绍:基于Python的SVD大众点评美食店铺推荐算法是一种协同过滤推荐系统,利用奇异值分解(SVD)技术从用户-店铺评分矩阵中提取潜在特征。该算法通过分解高维稀疏矩阵,学习用户和店铺的潜在因子向量,从而预测用户对未评分店铺的偏好。SVD能够有效处理数据稀疏性问题,并捕捉用户和店铺之间的隐含关系,实现个性化美食推荐。该方法在大众点评等场景中,可根据历史评分数据快速生成推荐列表,提升用户体验和商业价值
4.2 流程图
4.3 代码实例
import numpy as np
from scipy.sparse.linalg import svds
from scipy.sparse import csr_matrixdef svd_recommendation(ratings_matrix, n_factors=50, top_n=10):# 数据预处理:填充缺失值为0(或使用均值),并转换为稀疏矩阵以提高效率filled_matrix = ratings_matrix.fillna(0).valuessparse_matrix = csr_matrix(filled_matrix)# 执行SVD分解,k为潜在因子数量U, sigma, Vt = svds(sparse_matrix, k=n_factors)sigma = np.diag(sigma)# 重建预测评分矩阵predicted_ratings = np.dot(np.dot(U, sigma), Vt)# 获取每个用户的Top-N推荐(忽略已评分的店铺)recommendations = []for user_idx in range(predicted_ratings.shape[0]):user_ratings = predicted_ratings[user_idx]rated_indices = np.where(ratings_matrix.iloc[user_idx].notna())[0] # 已评分的索引user_ratings[rated_indices] = -np.inf # 将已评分项设为负无穷,避免推荐top_indices = np.argsort(user_ratings)[::-1][:top_n] # 取评分最高的Top-Nrecommendations.append(top_indices.tolist())return recommendations# 示例使用:假设ratings_df是用户-店铺的评分DataFrame(行为用户,列为店铺)
# recommendations = svd_recommendation(ratings_df, n_factors=50, top_n=10)