C++学习记录(10)模板进阶
一、非类型模板参数
1.基本内容
学习了几个STL库里明确标注的容器,我们见识到了模板在类中的强大作用,包括但不限于泛型编程后生成存储不同类型数据的类、仿函数控制类中的某些行为。这些的特点都是模板参数全部接收的都是类型。
那么有没有模板里能不能不传类型传参呢?
非类型模板参数常见于这种场景:
template <class T>
class stack
{private:T _arr[100];size_t _top;size_t _capacity = 100;
};设计一个底层为固定长度数组的静态栈,有的场景就是大量应用这种玩意,但是这样的设计有一个弊端,我开辟的大小如果想要控制,还必须找到这个类,深入其中修改,所以C语言阶段我们通常用宏来解决:
#define N 100
template <class T>
class stack
{private:T _arr[N];size_t _top;size_t _capacity = N;
};但是这样就又有弊端了,如果同时要求两个不同大小的栈怎么办?
int main()
{stack<int> st1;//100stack<int> st2;//1000return 0;
}数组大小只能说插一个宏,总不能说让宏无缝切换,这个时候我们就渴求一种可以改变大小的静态栈的形式出现,因此类模板的参数列表中允许传非类型模板参数,非类型模板参数就是用常量作为模板的一个参数,在模板逻辑设计的时候可以将其当成常量使用。
简单展示:
template <class T,size_t N = 100>
class stack
{private:T _arr[N];size_t _top;size_t _capacity = N;
};int main()
{stack<int, 100> st1;//100stack<int, 1000> st2;//1000return 0;
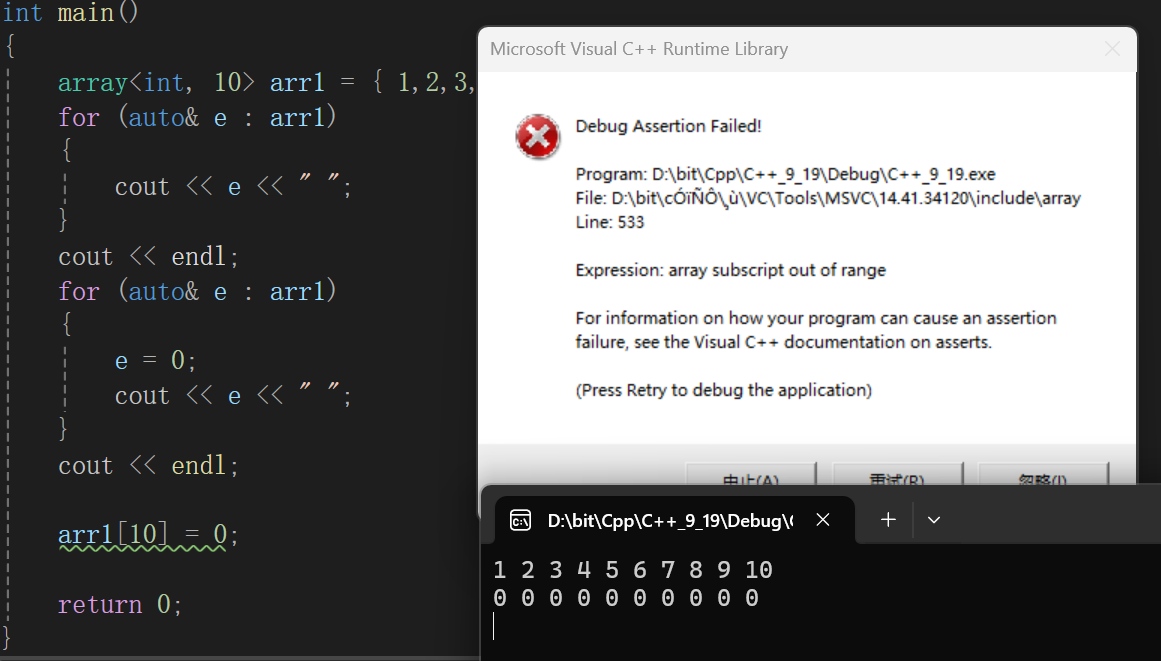
}当然,静态的参数一定要谨慎使用,比如上面的场景,我们如果给静态数组的大小过大,将会造成栈满的情况,因为一般来说,我们设计的栈区内存很小(相比于堆区),就说是8M,大概也能存八百万的数据(1 MB = 1024 KB,1 KB = 1024 Byte,只算数量级大概就是1 MB = 1000000 Byte),假如你设计的静态数组过大,比如:
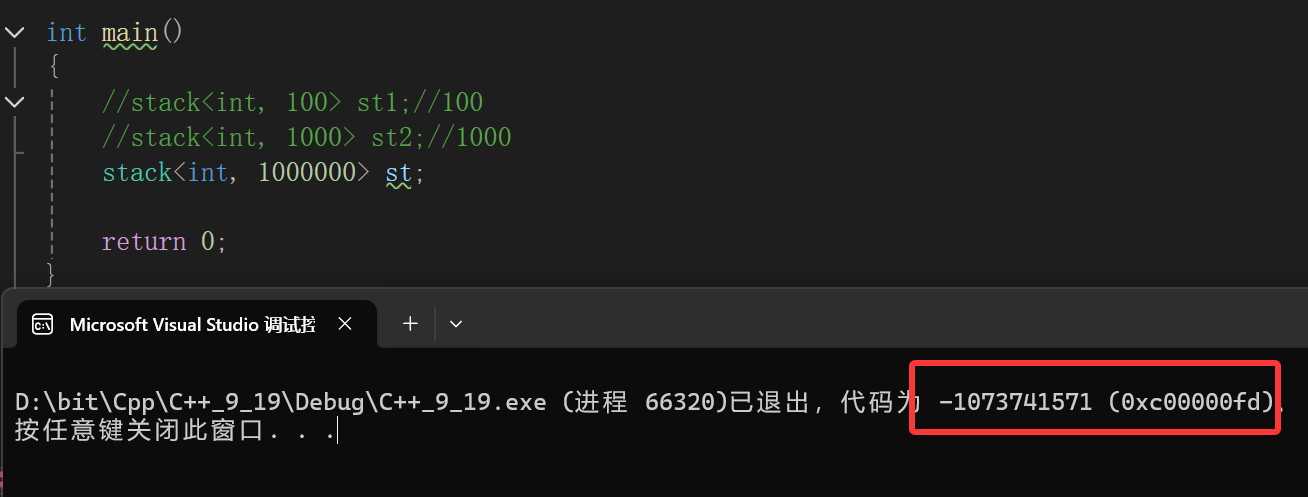
四百万个int,大概直接给了一半栈内存给了这个数组,但是栈区难道就你一个吗?多的不说,main函数就得在栈区申请内存吧,你这是啥意思,往死里面侵占,所以直接给栈干爆了:
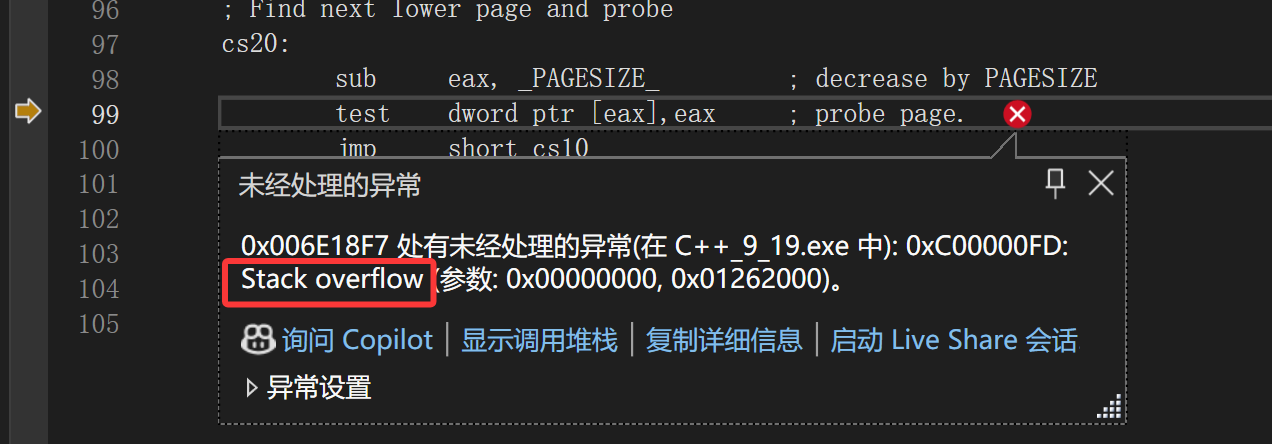
一调试人家都给你跳转了,说stack overflow,flow表示流动的意思,overflow不就是太满了,漫出来了,所以流出来了,非常形象的说明栈空间申请的太多了。特别是这种直接在main函数申请的空间,它只会等main函数销毁时被销毁。
2.强调


关于这个事我大概搜了搜:

低版本的C++(98/03)只支持这些类型,而且大部分其实都相当于是常量,或者说有确定值的才能作为非类型参数传过去。
不过高版本:

还是慢慢增多,甚至可以传自定义类型做非类型模板参数。
3.STL库中的非类型模板参数
其实在STL库中就有使用非类型模板参数的情况:

模板参数里确实是一个代表容器存储数据的类型,一个代表非类型模板参数,但是一看这名字,array,玩我呢?
我自己没事int arr[]就能干出来数组,你给我往容器里放array,这是干啥的,脱裤子放屁吗?
拿过来array的接口:
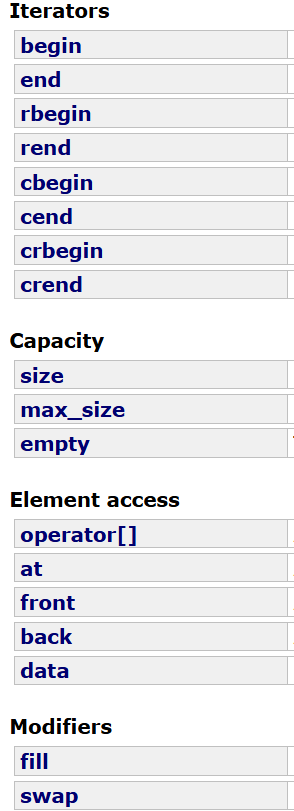
其实老实说,这些接口正常的数组基本上都能实现,除了极个别的size,empty,大概率这个array底层搞了个成员变量_size来实现。
看了看接口还是解不了我们心头的疑惑,于是:

这种情况有毛病吗,没有,但是往往对于初学C语言数组的人来说,现在我让你把整个数组的元素全部置为零,如果学艺不精加上没有人提醒,就会:

符合语法吧,看起来没啥毛病吧,一运行:
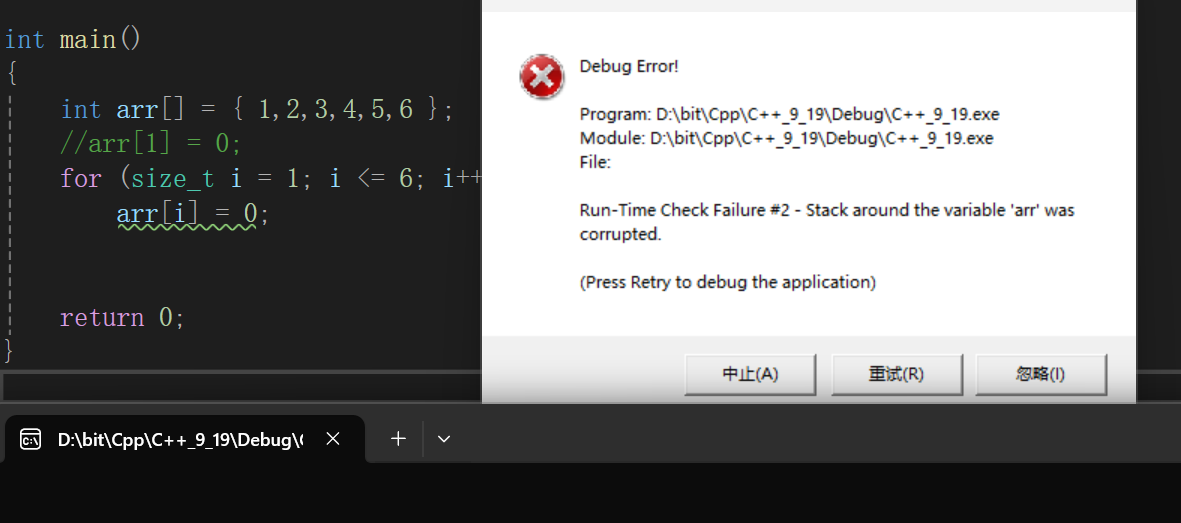
直接就越界访问了,因为往往按照我们的习惯,排成绩前后是不是按的是1 2 3 4名,没有说搞个第0名的吧,或者就是高中数列我们学习也是第1 2 3 4项,没有说第0项的吧,把生活中的规律套进数组里就会写出这样的代码然后就是越界访问了,刚开始学可能老师了,或者书上就会跟你说,切记数组下标从0开始到第n - 1停止,直到后来学了指针了,知道了,原来底层数组的[pos]会被转换成*(arr+pos)通过下标的偏移量来解引用访问,所谓数组的下标,就是偏移量。
这是非常经典的错误了。
编译器直接报错是好事,但是编译器对于数组是否越界的行为是抽查:
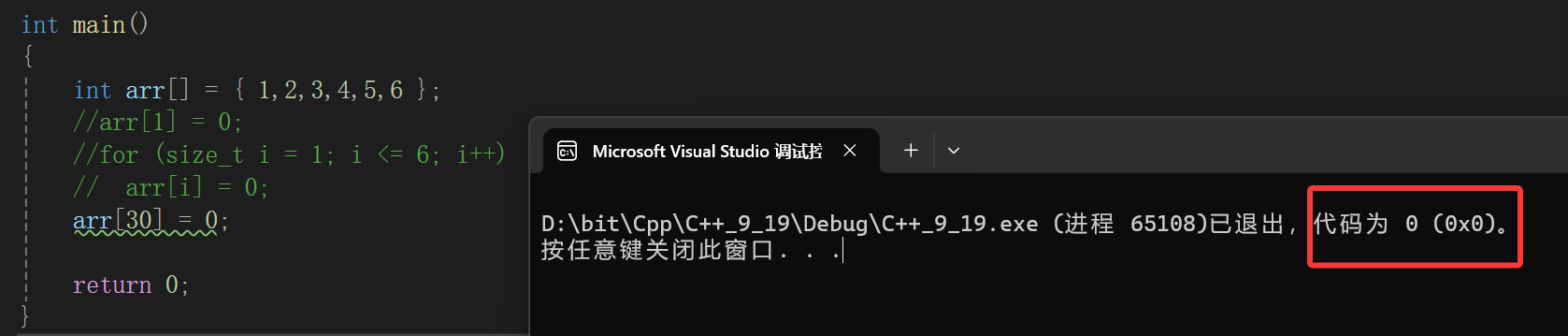
好家伙,越界那么多直接没事,有点天高皇帝远的意思了。这才是最致命的,前面我们讲迭代器失效的问题时就说过,报错其实不害怕,害怕的就是明明代码写错了,稀里糊涂通过了,说不定哪天就给你来个大爆炸。
编译器对数组越界的访问确实就类似于天高皇帝远的意味:

编译器防止越界的时候,大概机制就是监测数组后面几个值(具体取决于编译器),看看数组访问前和访问后这几个值是否发生改变,如果没有发生改变,那就认为你没有越界访问,其实想想也合理,大部分情况都是这样的,你说你离得很远越界我如果还想检查,那岂不是我得访问整个内存空间,那样检查的效率太低了。
同样我们说了,编译器只是检查数组空间后几个内存空间改变了没有,如果不改变的话可是检查不出来的啊:
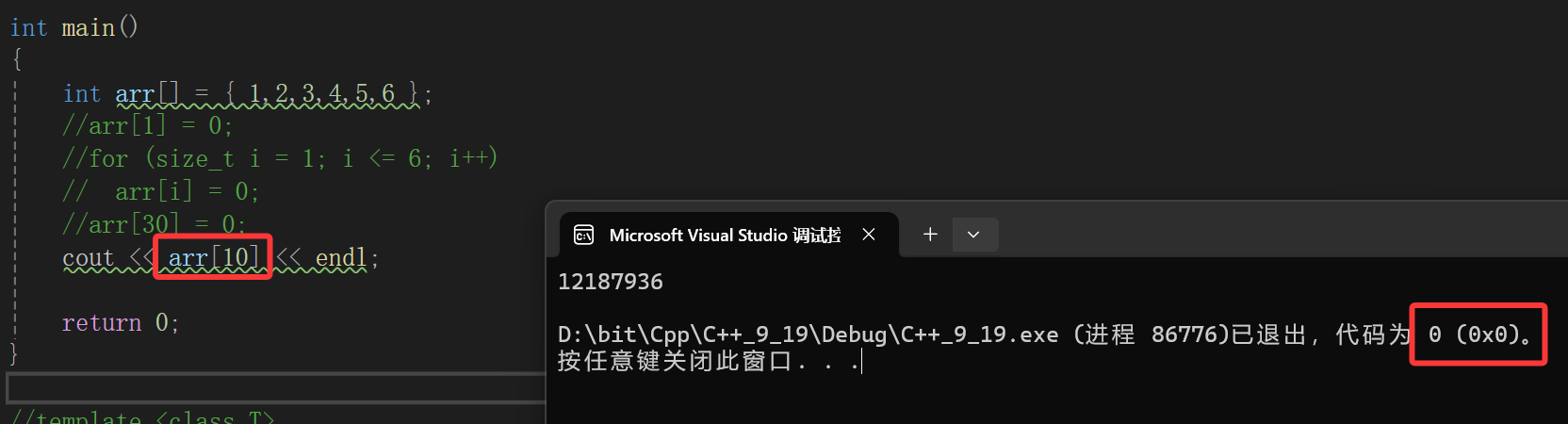
照样舒舒服服用了,那你就等着炸吧,原因就是我说的,编译器抽查的行为就是随机检查数组空间后那几个变了没,只读访问又不改变值,因此检查不出来,可能上面这个例子太远了,这次我们贴着数组空间访问:
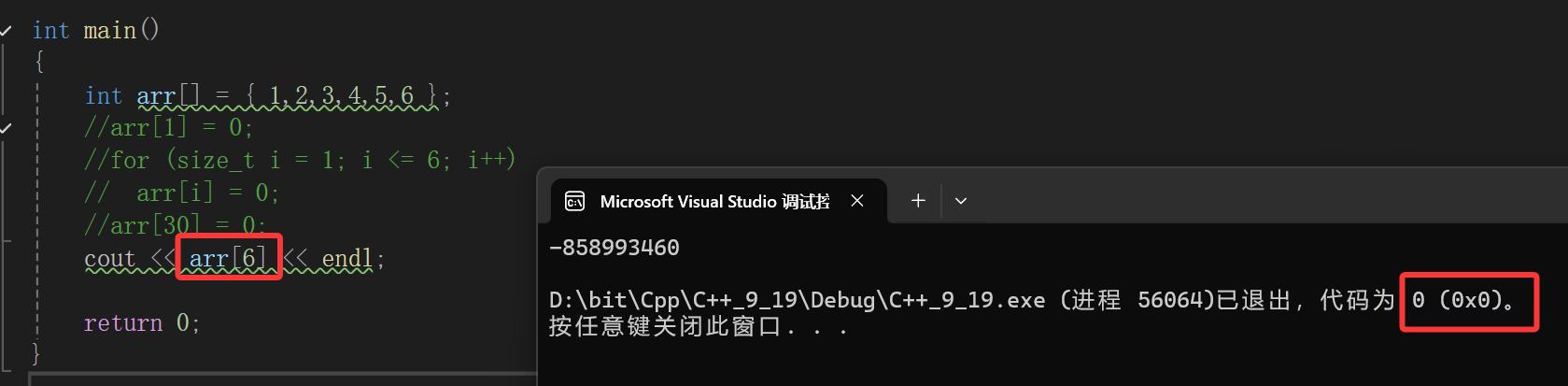
还是检查不出来,那如果要是大量使用静态数组的场景这岂不是很不安全吗?
因此,容器中设计出来array。
为什么容器的array就安全了呢?
其实很容易想,底层operator[]大概是这样设计的:
T& operator[](size_t pos)
{assert(pos >= 0 && pos < _size);return _arr[pos];
}人家[]可不是简单的计算偏移量,而是先断言,合法再计算进行访问。这样不就安全了嘛。
所以大量使用静态数组的场景你是用容器里的array还是原生的数组。
二、模板的特化
1.函数的特化
刚刚学习过优先级队列,在优先级队列中我们首次见识了仿函数在类模板中的强大作用,比如:
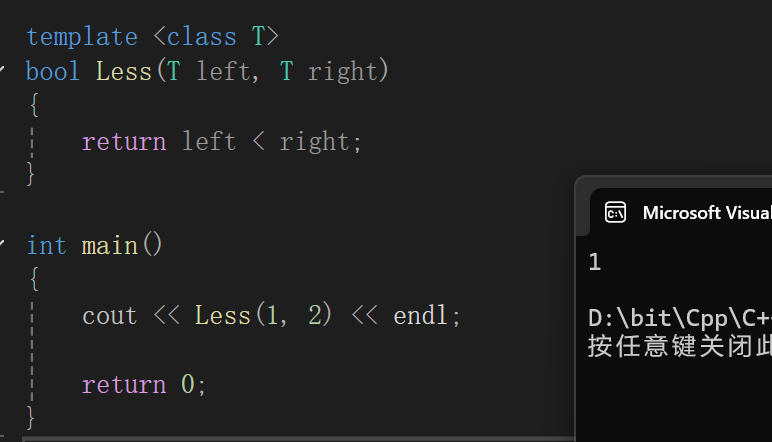
这个没啥疑问吧,写了一个模板函数,专门用来比较大小。
但是有些特殊的场景:
class Date
{
public:Date(int year = 1,int month = 1,int day = 1):_year(year),_month(month),_day(day){}bool operator<(const Date& d)const{return (_year < d._year) ||(_year == d._year && _month < d._month) ||(_year == d._year && _month == d._month && _day < d._month);}bool operator==(const Date& d)const{return _year == d._year && _month == d._month && _day == d._day;}private:size_t _year;size_t _month;size_t _day;
};template <class T>
bool Less(T left, T right)
{return left < right;
}int main()
{cout << Less(1, 2) << endl;double* d1 = new double(1.1);double* d2 = new double(2.2);cout << Less(d1, d2) << endl;Date* pd1 = new Date(2025, 9, 10);Date* pd2 = new Date(2024, 9, 10);cout << Less(pd1, pd2) << endl;return 0;
}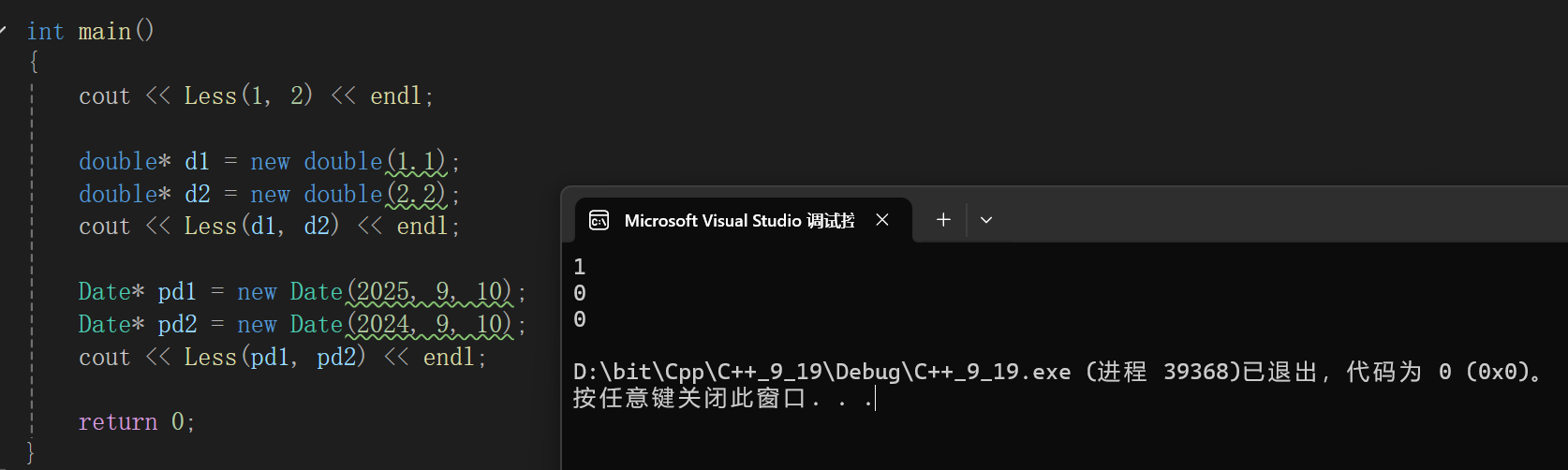
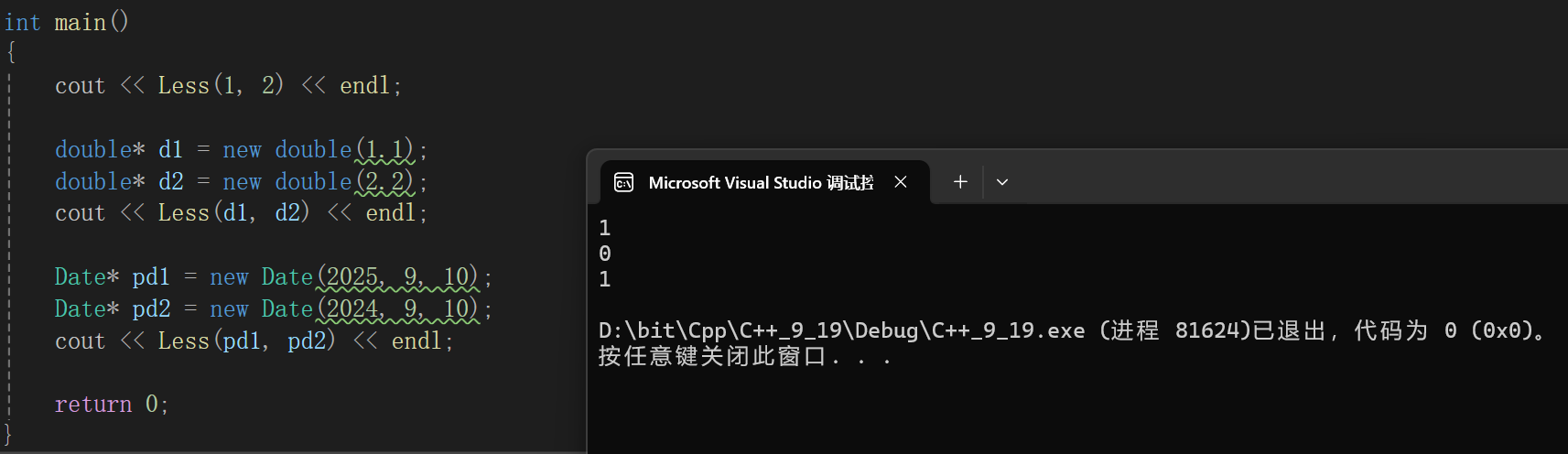
好家伙,后面俩玩上排列组合了,原因我们也解释过了,对于指向有效元素的指针变量,我们比较大小的逻辑肯定是比较指针指向的元素的,但是我们的模板函数的逻辑是什么呢?
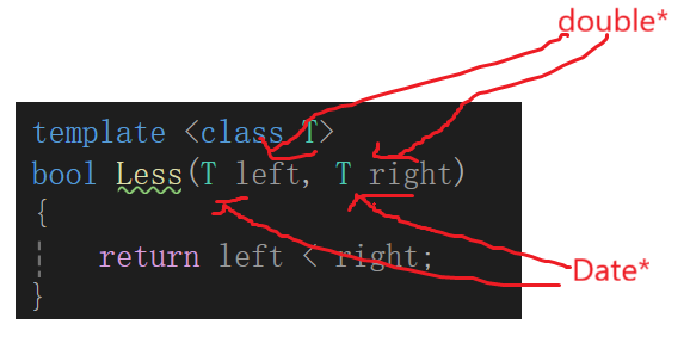
等于直接比较指针的大小了,但是问题就是,其实堆区的内存可不是说谁先申请谁的内存地址一定大或者小,肯定是哪里有符合大小的内存往哪申请啊,所以这就造成了函数内部逻辑不符合部分场景的情况,这种情况下,我们就需要把模板的参数特别设置一下,并且修改函数逻辑。
①语法格式
函数模板特化的语法:
template<>
FuncName<指定类型>(parameter-list)
{}
- 有基础的对应的模板
- template<>,即template关键字后跟空的尖括号
- 函数名后跟尖括号,其中填需要特化的参数类型(即把泛性的参数,在此处特化)
- 需要注意的是参数列表中参数类型必须能够和基础模板的类型对应,否则将会导致编译器报一些奇怪的错误
对于上述操作,实行以后:
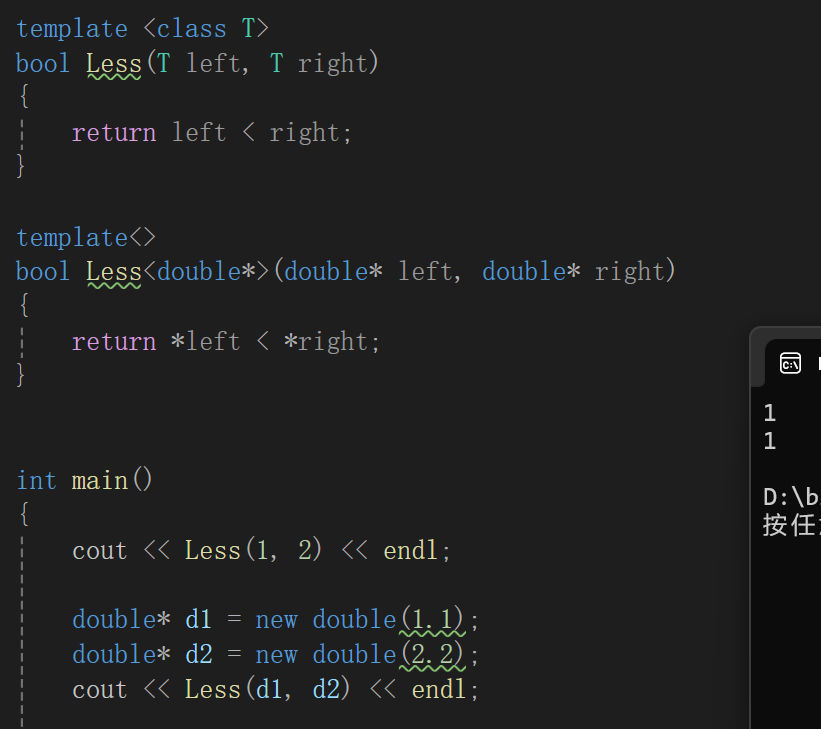
调试也可以看到:
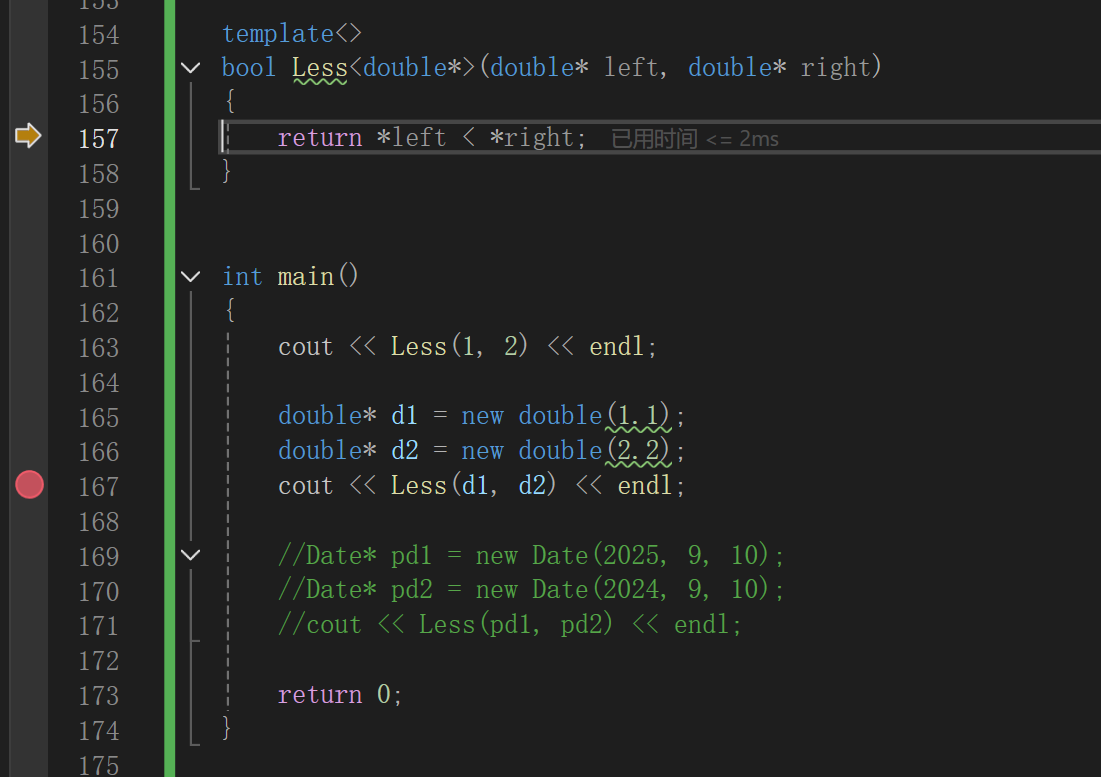
特化完成任务。
②优化
接下来的问题就是,我们写的函数模板实在是太差劲了:
template <class T>
bool Less(T left, T right)
{return left < right;
}学的是C++,传参的时候也不考虑考虑能不能用引用,特别是在模板里,你弄个int double甚至是指针的传值传参我都不挑你的理,毕竟引用底层是指针,其实也不会差太多,但是你要是干个自定义类型还给我传值传参,那我就得怀疑怀疑你的类与对象学的咋样了,在自定义类型传值传参的时候,编译器采用的是调用拷贝构造函数,你要是搞个类似于Date类型的我还能忍,就几个内置类型,但是vector,list,你还敢这么玩吗?拷贝死你。
③可能遇到的问题
所以说还是得考虑考虑,该const的const,该引用的引用:
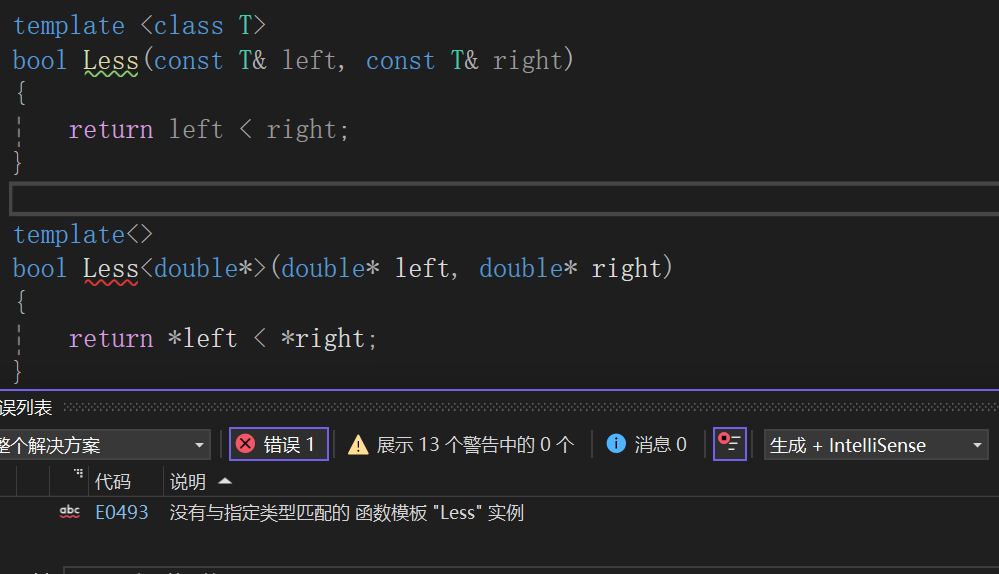
上面说了,特化的函数一定得跟它对应的函数模板照应,这样看来,是const和引用搞得事,那我就补:
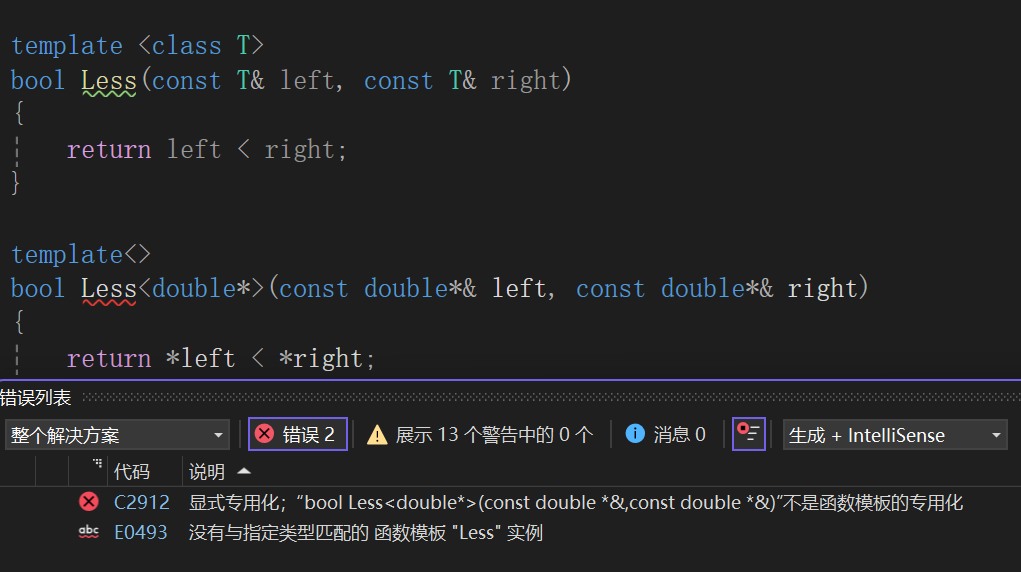
结果又tm出事了,真想发个哭笑的表情,因为我真的很无语啊。我就纳了闷了,咋回事啊,你咋长的我就咋长的,咋会出事呢?
指针。
不妨细细的分析:

你现在啥都别干,盯着这张图往死里看,追究到根源。
我问你const是不是修饰的T,T是个什么,指针,是不是相当于const修饰的指针,如果修饰的是指针,那特化的函数参数列表里的类型必须和函数模板相同。
上面这个说法看不懂,那你这么看,const T&修饰的T是不是意味着left的值不变(当然,left是引用,本来它的指向就改变不了,只能限定值改变或者不改变),left的值如果类型是double*的话,那是指针指向的内容还是指针本身,肯定是指针本身啊。
那么你的特化:

这是一个意思吗?
最经典的:
const int* p1;//const修饰*p1
int const* p2;//const修饰*p2
int* const p3;//const修饰p3
再回来看,现在总知道为啥编译器不满意了吧,因为你并没有做到特化的函数与其对应的模板的参数完全对应,语义都不同,所以正确的修改应该是:
template <class T>
bool Less(const T& left, const T& right)
{return left < right;
}template<>
bool Less<double*>(double*const & left, double*const & right)
{return *left < *right;
}再强调一个点,double* const & left,说句实话,符号太多了,真给人看的晕头转向的,就这个* const &三个的位置,可能还有人弄不懂。
首先引用的语法格式是变量类型 + & + 别名 = 变量,所以*一定在&前;
再来就是const一定得在*后,因为为了匹配需要绑定成一个常量指针;
最关键的就是const和&相对位置,其实也好说。
double* & const left还有double* const & left合适。
如果是double* & const left,等于const修饰是引用这个变量本身,问题是人家就是具有常性的啊,也就是必须初始化,初始化绑定以后不能改变指向,const既没必要也不允许。
所以最后就只剩下double* const & left。
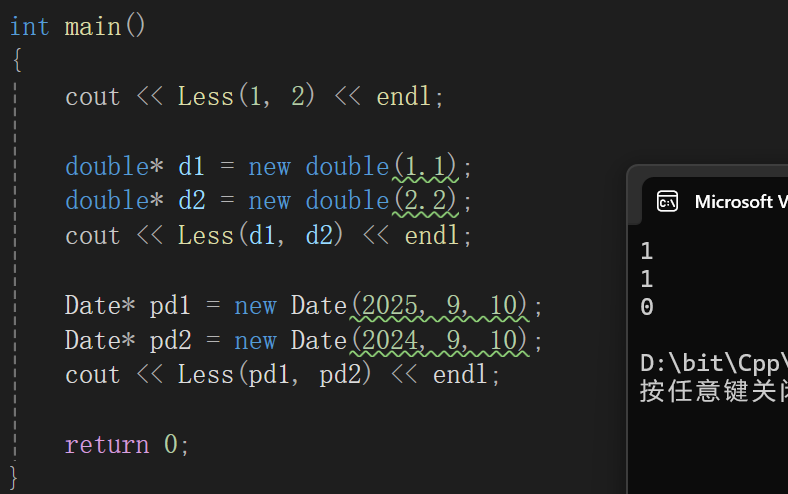
自定义对象Date的特化也是如此:
template<>
bool Less<Date*>(Date* const& left, Date* const& right)
{return *left < *right;
}
④一些自己的想法
说实话,写函数模板的特化的时候跟通灵或者说召唤一样,真是累人啊。
template<>
bool Less<double*>(double*const & left, double*const & right)
{return *left < *right;
}
template<>
bool Less<Date*>(Date* const& left, Date* const& right)
{return *left < *right;
}template<>呼叫天上的神仙;
Less函数名点名召唤的神仙;
后面的<double*>以及参数列表里的类型,都是合神仙胃口的祭品;
神仙为我们实现了 *left < *right这个事。
开个小玩笑,但是我个人看来,为什么非的要函数特化呢,我直接写个符合我要求的函数不完了,也就是我们当时说的那种有现成的函数,而且和模板形成重载,为什么还要用模板生成呢?语法可以说真跟祭祀一样麻烦。
2.类模板的特化

正常写一个类,底层肯定是根据你实例化的类型在编译阶段生成类,并且生成对应的一系列接口,
①全特化
假如我现在实例化类型为int char类型的Date类我要做特殊处理:
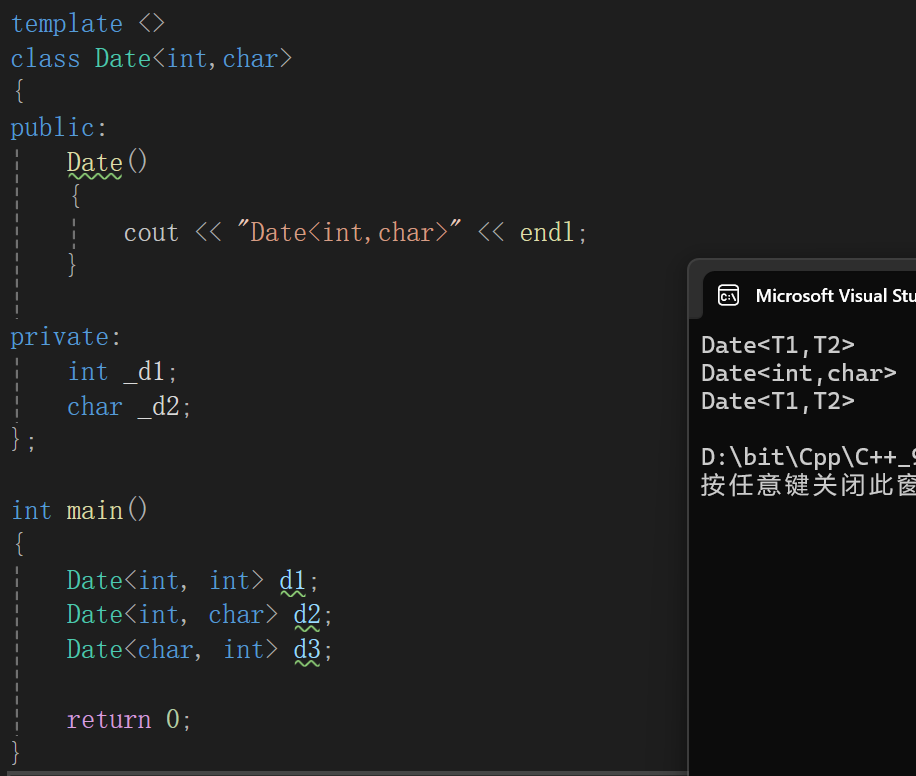
其实这里可以说自己手动根据模板生成了一个类,只不过内部逻辑可能有所不同。
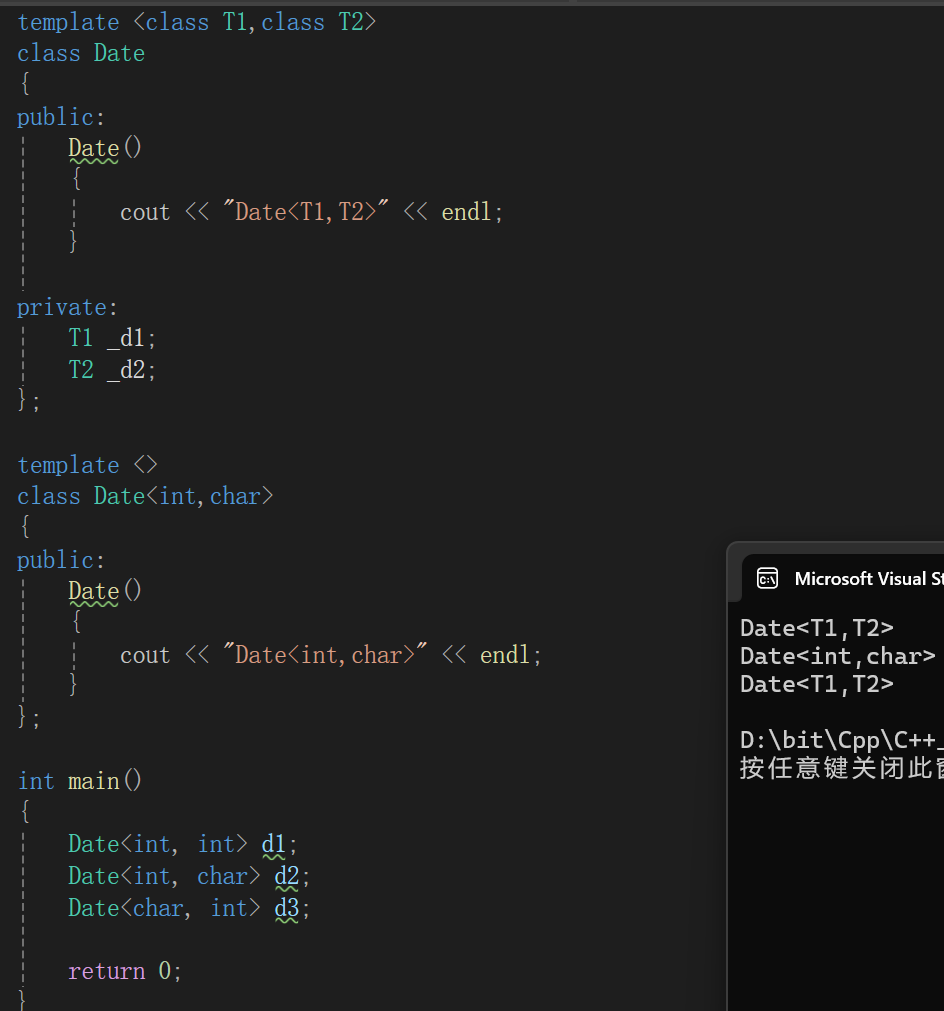
比如我这里把全特化生成的类的成员变量全部删去,它也不会说啥,模板特化唯一需要注意的是指定类型特化,参数列表对应模板即可。
也就是说:
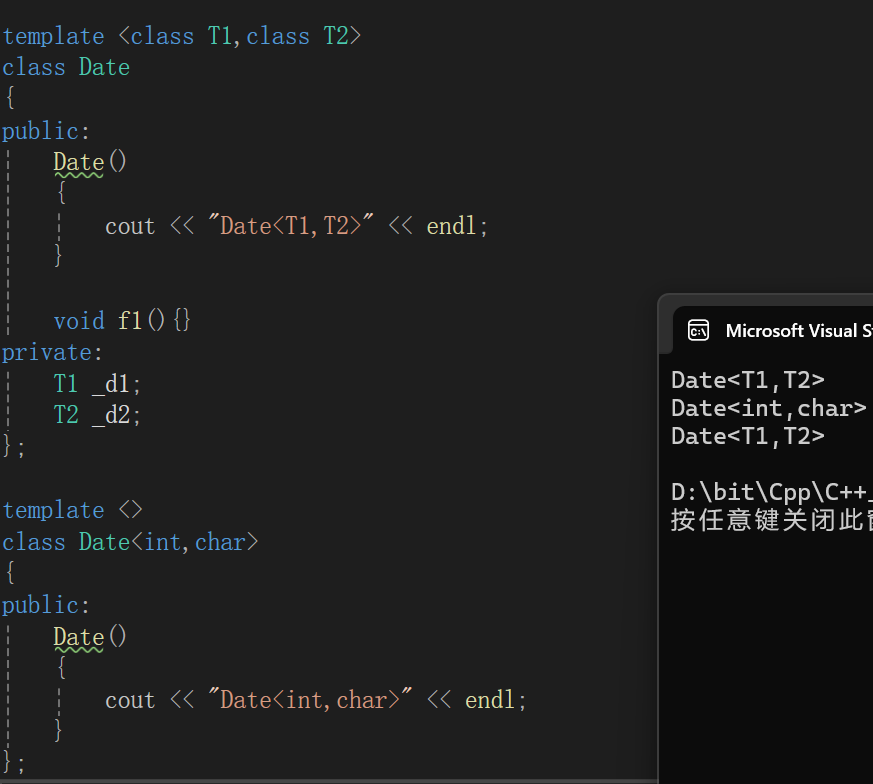
即使内部成员变量不照应,成员函数不照应,照样可以使用,重点只是参数列表。
template <class T1,class T2>
class Date
{
public:Date(){cout << "Date<T1,T2>" << endl;}void f1(){}
private:T1 _d1;T2 _d2;
};template <>
class Date<int,char>
{
public:Date(){cout << "Date<int,char>" << endl;}
};
int main()
{Date<int, int> d1;Date<int, char> d2;Date<char, int> d3;return 0;
}
②偏特化
偏特化部分参数
偏特化可以只特化部分参数:
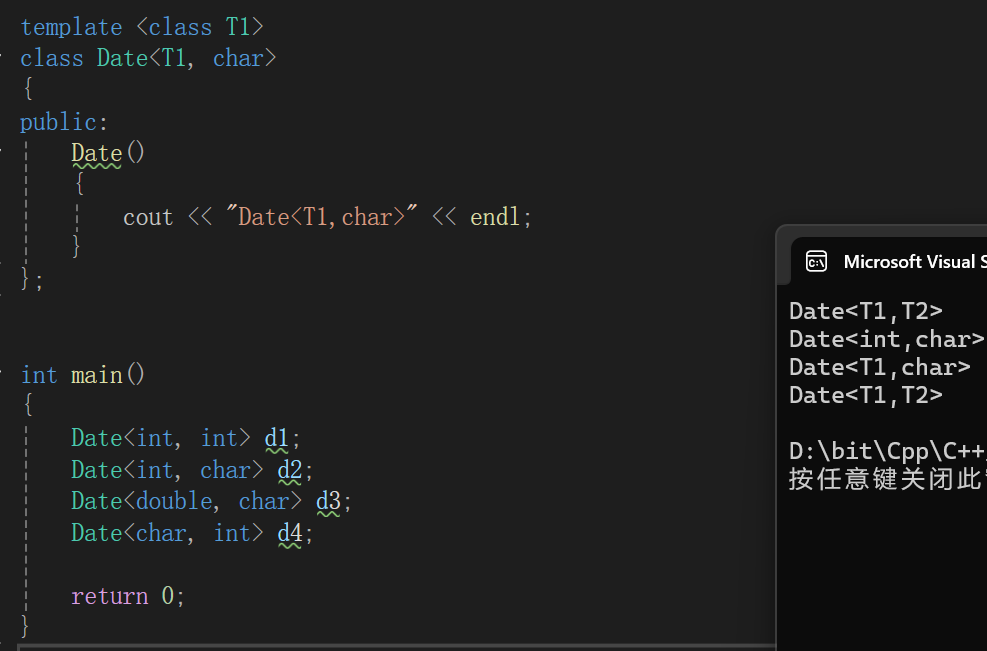
在上面的基础上我们特化其中一个参数,在最终的结果中可以看到,int char类型仍旧走的是Date<int,char>这个全特化类的逻辑,double char走的是Double<T1,char>这个偏特化的逻辑,大概解释就是:
有全特化,或者说现成的类能用,就用全特化;
没有全特化,但是有契合的偏特化用,就用偏特化;
完全没有就只能根据原始模板生成类用。
偏特化给参数添加限制
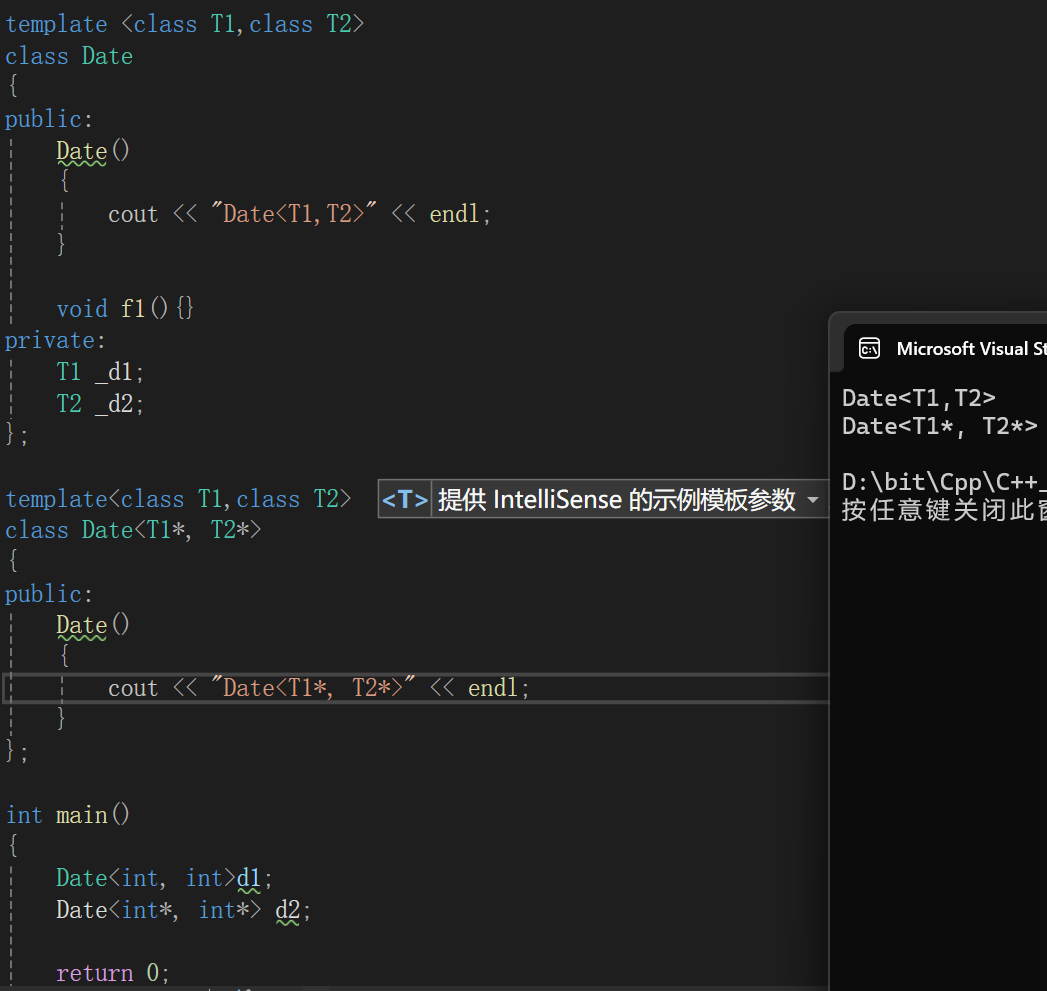
有时候我们指针可能要做特殊处理吧,比如认识仿函数的时候就是由priority_queue的大小逻辑的控制引出来的,难免有些时候需要对指针特殊处理,这个时候就产生了可以特化的时候限制参数的类型的方式。
需要特别的是,最后给类中传的到底是int*还是int,也就是T1是int类型还是int*类型呢?
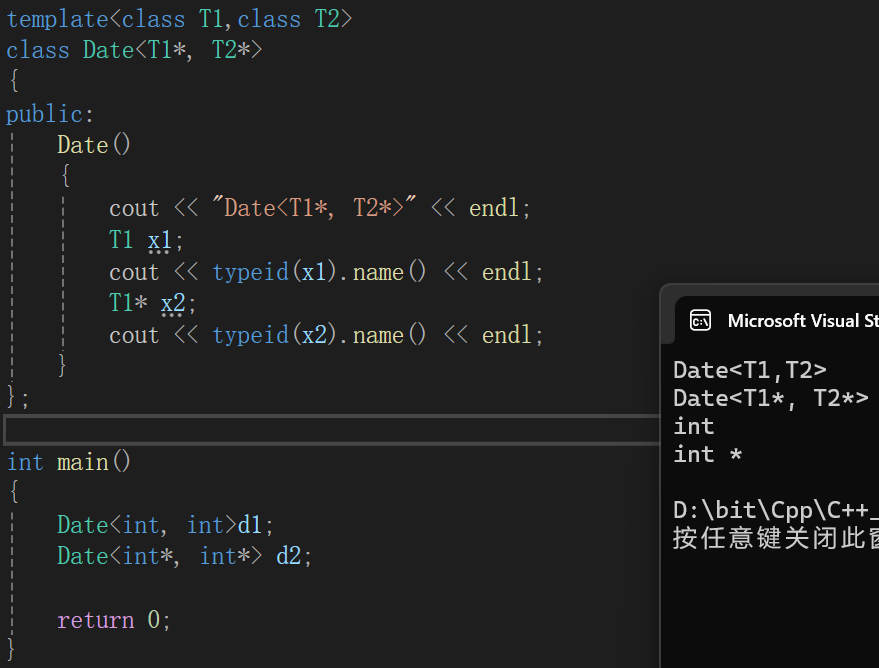
容易知道,为了传参的方便,T1仍旧传的是普通类型所以用的时候一定要多加注意。
比如,之前我们写的优先级队列解决关于Date*类的指针的比较错误问题是这么办的:
class Date
{
public:Date(int year = 1,int month = 1,int day = 1):_year(year),_month(month),_day(day){}bool operator<(const Date& d)const{return (_year < d._year) || (_year == d._year && _month < d._month) || (_year == d._year && _month == d._month && _day < d._day);}bool operator==(const Date& d)const{return _year == d._year && _month == d._month && _day == d._day;}friend ostream& operator<<(ostream& out, const Date& d);private:size_t _year;size_t _month;size_t _day;
};
ostream& operator<<(ostream & out, const Date & d)
{out << d._year << "-" << d._month << "-" << d._day;return out;
}void test_pq()
{xx::priority_queue<Date*> pq;Date* d1 = new Date(2025, 9, 10);Date* d2 = new Date(2024, 8, 10);Date* d3 = new Date(2024, 9, 10);pq.push(d1);pq.push(d2);pq.push(d3);while (!pq.empty()){cout << (*pq.top()) << " ";pq.pop();}cout << endl;
}int main()
{test_pq();return 0;
}这种情况下,我们期望是根据Date的值而不是Date*的值比较,因为Date*的值没啥意义啊。但是这么创建优先级队列,最后应用的逻辑就是:
我们之前提供的解决方法是:
class Date
{
public:Date(int year = 1,int month = 1,int day = 1):_year(year),_month(month),_day(day){}bool operator<(const Date& d)const{return (_year < d._year) || (_year == d._year && _month < d._month) || (_year == d._year && _month == d._month && _day < d._day);}bool operator==(const Date& d)const{return _year == d._year && _month == d._month && _day == d._day;}friend ostream& operator<<(ostream& out, const Date& d);private:size_t _year;size_t _month;size_t _day;
};
ostream& operator<<(ostream & out, const Date & d)
{out << d._year << "-" << d._month << "-" << d._day;return out;
}class PqPtrDate
{
public:bool operator()(Date*const & d1,Date*const & d2){return *d1 < *d2;}};void test_pq()
{xx::priority_queue<Date*,vector<Date*>,PqPtrDate> pq;Date* d1 = new Date(2025, 9, 10);Date* d2 = new Date(2024, 8, 10);Date* d3 = new Date(2024, 9, 10);pq.push(d1);pq.push(d2);pq.push(d3);while (!pq.empty()){cout << (*pq.top()) << " ";pq.pop();}cout << endl;
}int main()
{test_pq();return 0;
}专门写个类,实现Date*对象的仿函数。
有没有办法提前弄好,到时候不自己传呢?
当然就得上我们的特化:
template <class T>
class Less
{
public:bool operator()(const T& x, const T& y){return x < y;}
};template<>
class Less<Date*>
{
public:bool operator()(Date*const& x, Date*const& y){return *x < *y;}
};
void test_pq()
{//xx::priority_queue<Date*,vector<Date*>,PqPtrDate> pq;xx::priority_queue<Date*> pq;Date* d1 = new Date(2025, 9, 10);Date* d2 = new Date(2024, 8, 10);Date* d3 = new Date(2024, 9, 10);pq.push(d1);pq.push(d2);pq.push(d3);while (!pq.empty()){cout << (*pq.top()) << " ";pq.pop();}cout << endl;
}int main()
{test_pq();return 0;
}
直接出结果:
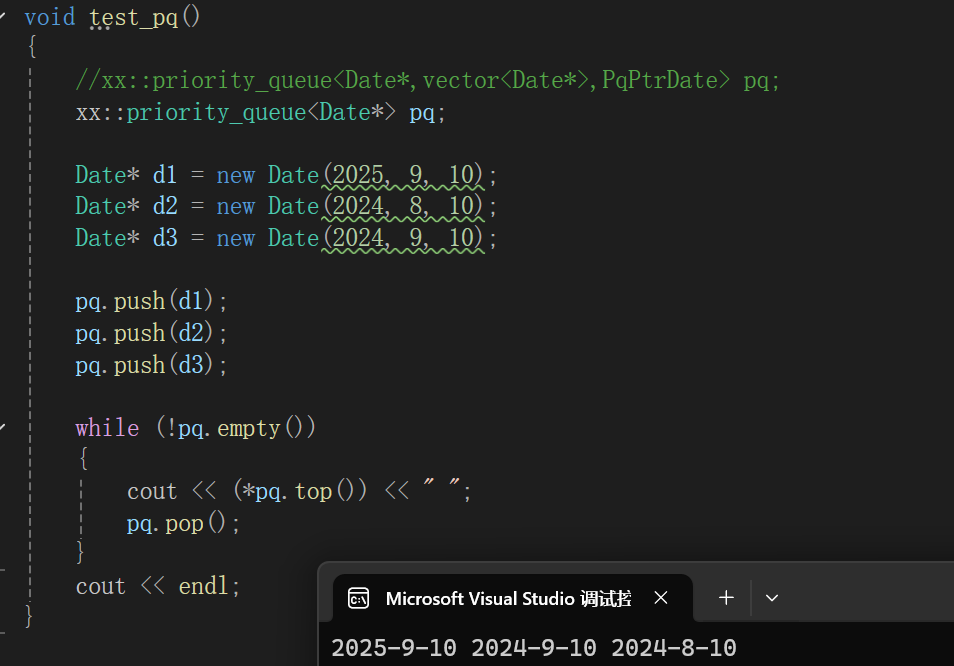
同样道理,还可以展示一下偏特化:
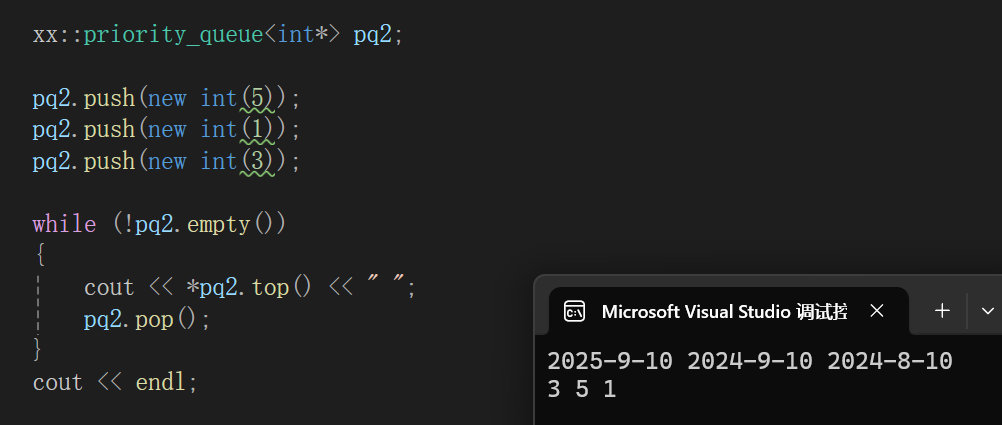
总不能说我每次碰见指针都得写一下,那还不麻烦死,不如:

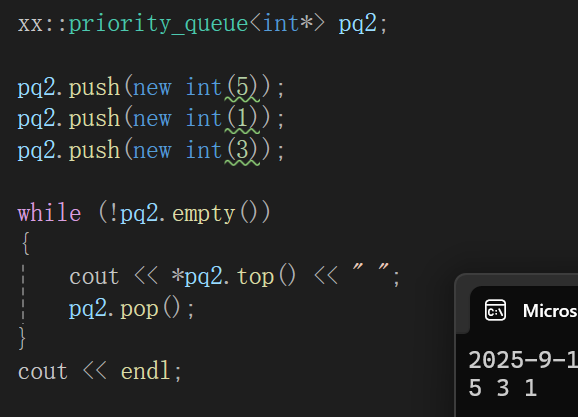
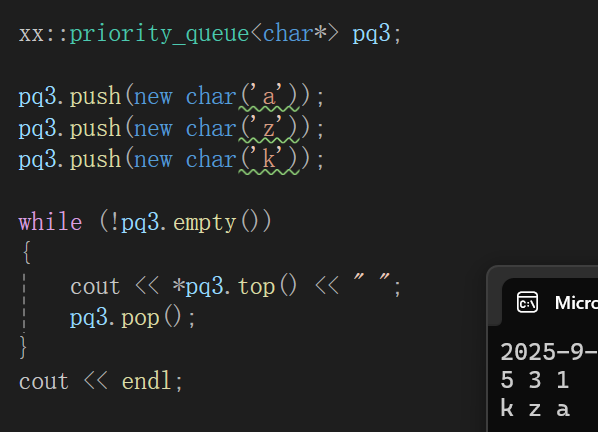
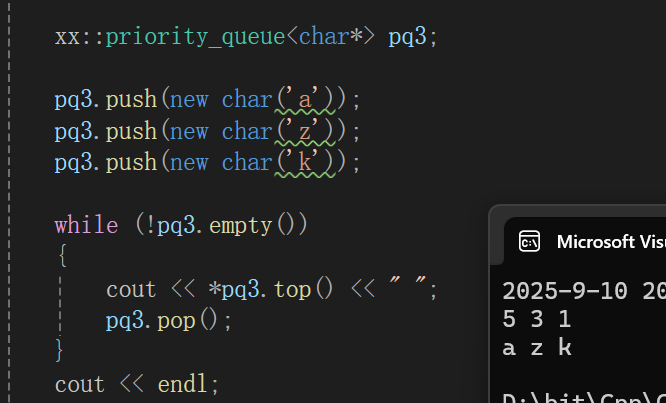
多舒服的场景,再者,如果你某个指针,比如char*就想按照指针大小比,你还可以用全特化来拦截:

③小结
- 全特化可以用来指定某一类型的特殊行为,也可以用来拦截偏特化的部分类型
- 偏特化不仅可以只特化部分类型,还可以给参数上限制(指针引用等)
三、模板分离编译问题
在一开始实现STL容器的时候,我当时说了,不要做声明和定义的分离,直接把模板所有的代码都甩到.h中,最多你嫌类内太长,你搁类外写,但是总归还是都在头文件中实现。
为什么会产生这样的问题呢?
1.函数模板声明和定义的分离
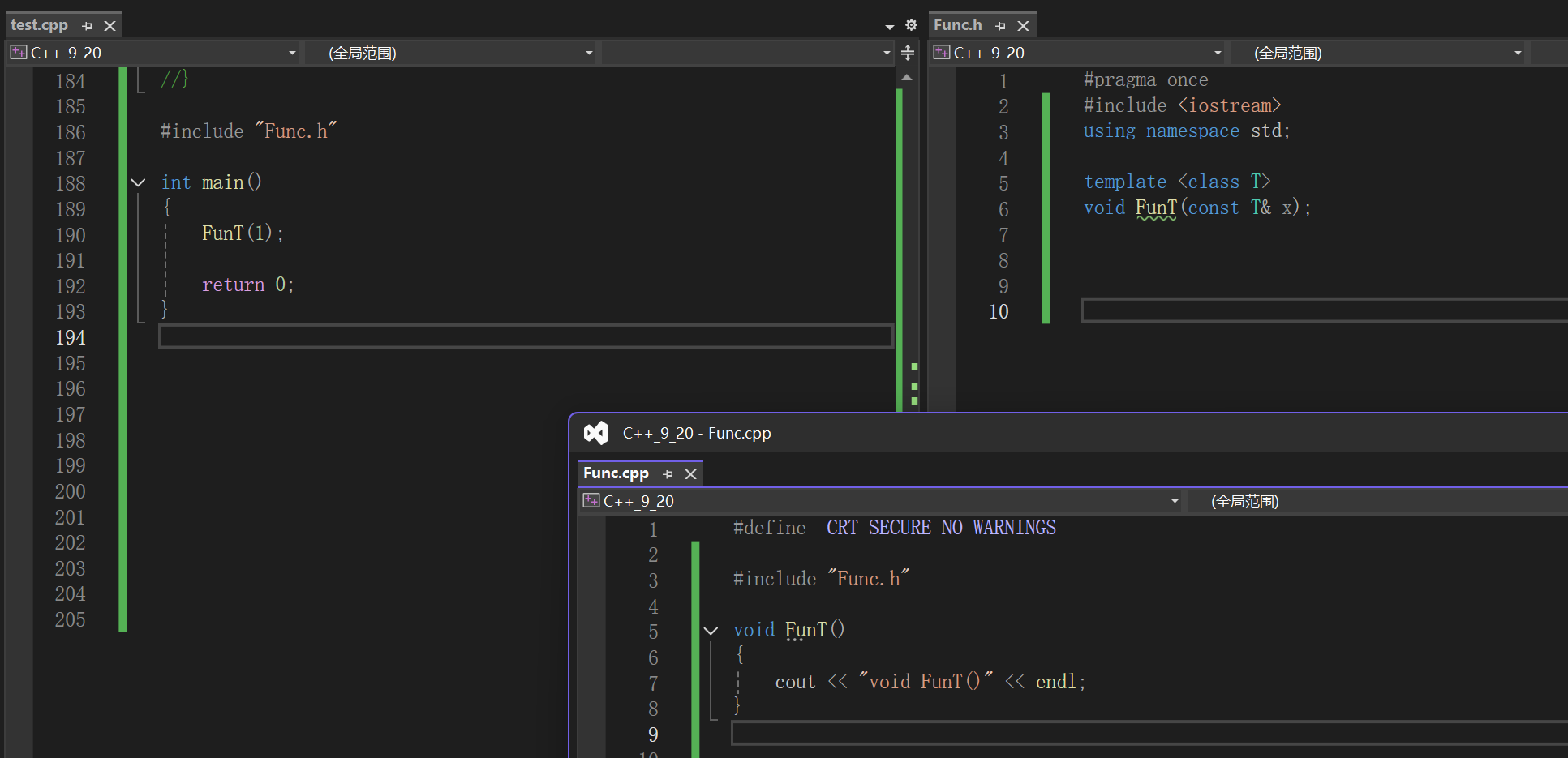
头文件 声明 定义都有了昂:

大概意思就是FunT这个函数我并没有找到啊,而且是在链接阶段没找到,LNK错误嘛。
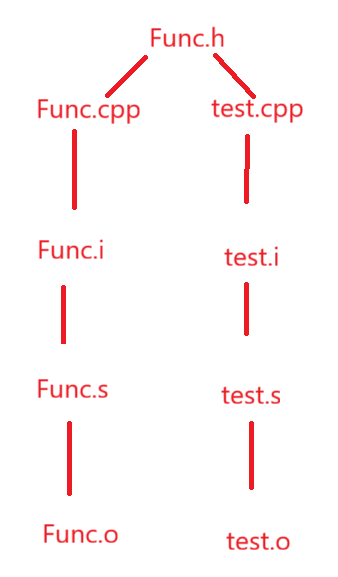
不妨我们来细细的画一下几个文件的编译,最基本的,明确编译的基本单位是.cpp文件:
预处理阶段:(展开头文件 宏替换 条件编译)
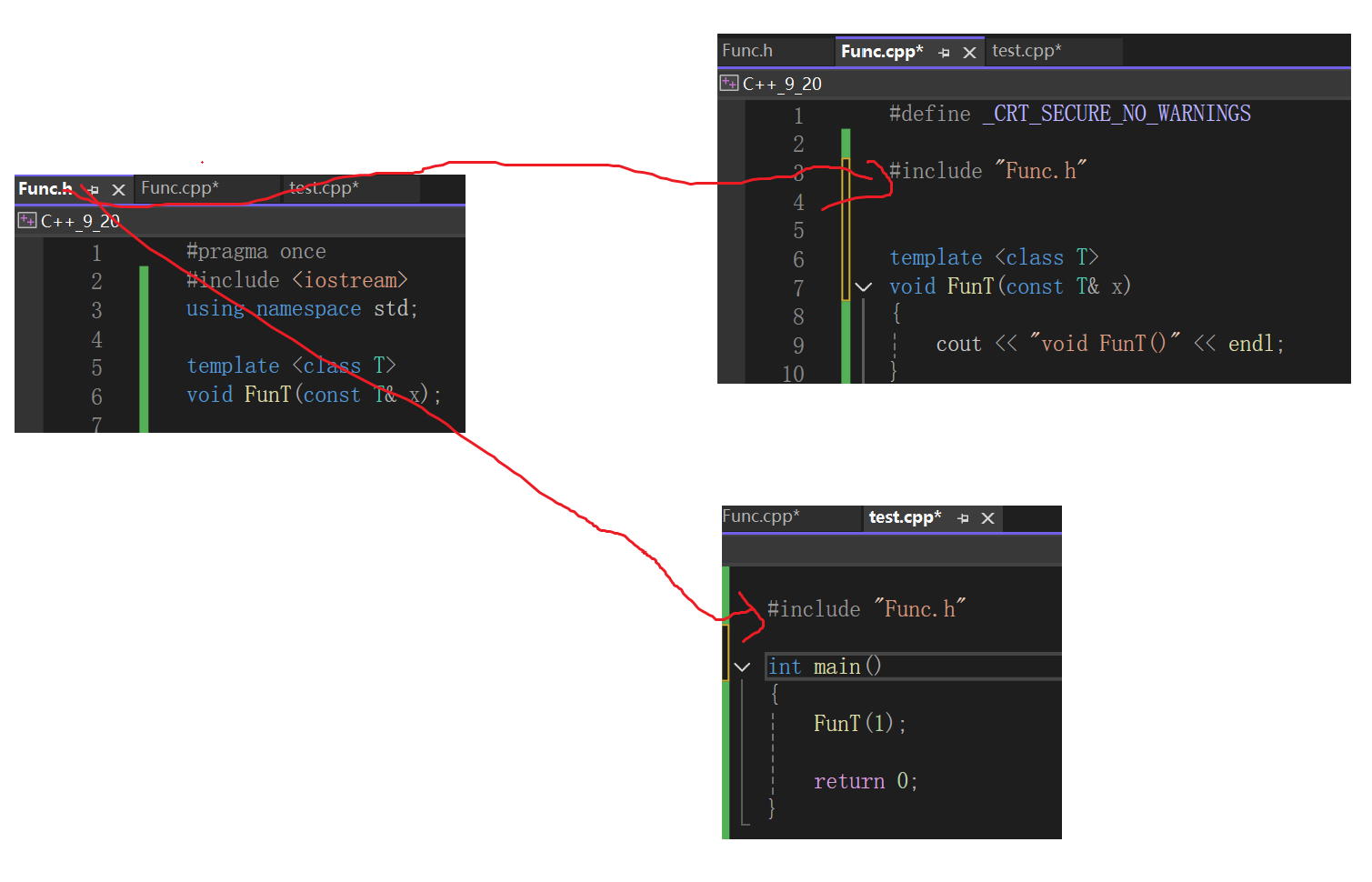
编译:(转成汇编代码)(检查语法 句法)
头文件展开以后,Func.i和test.i文件就是上述的情景,在这种情况下,main函数存在函数的调用,编译器往上一直找,最后只能找到函数模板的声明,找不到函数模板的定义,遇见这种情况,编译器会留个疑问,因为找不到定义就没有函数的地址,没有函数的地址就会调用失败,预示着在链接阶段必须想办法去找函数的定义。
汇编:(转成二进制)
链接:(未找到函数定义的,只有函数声明的互相找)
但是这里就出现了问题:
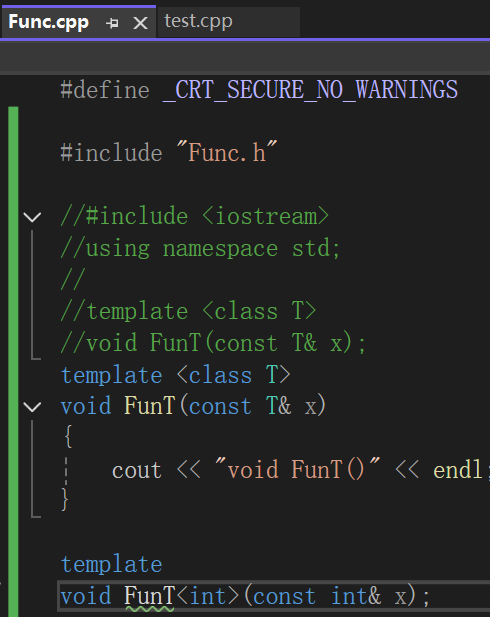
在test.cpp中对于模板本来应该进行模板的实例化,但是因为只有声明没有定义,所以就暂时搁置了,只停留在函数调用的阶段。
Func.cpp文件中确实有模板的定义,但是由于链接前,每个cpp文件是没有交汇的,Func.cpp的编译过程就不会实例化。也就是说本应test.cpp里进行的实例化因为只有声明没有进行,Func.cpp中没有实例化的需求,最后链接阶段test.o文件有函数调用没有实现,Func.o中又没有实例化,也就没有函数可以给test.o调用,最后发生链接错误。
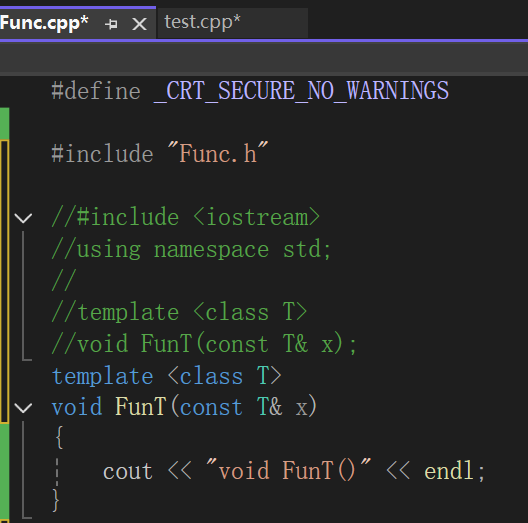
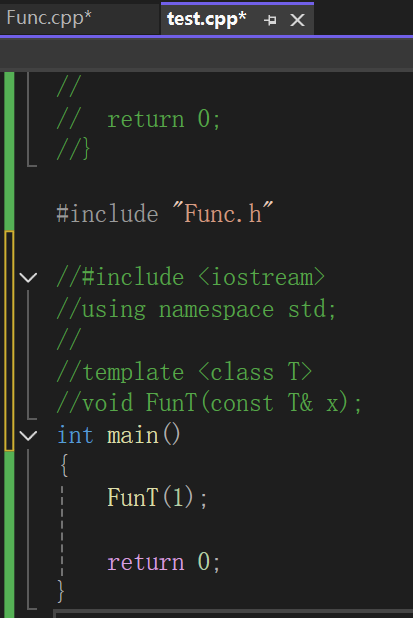
所以解决办法呼之欲出,强制显式实例化去:
至于为什么函数模板的声明实例化是这样的,你也别问我,语法就这么规定的,而且特别要小心,可别跟模板的特化互相缠绕到一起。
缺陷
上述做法的缺陷,其实也非常明显,那就是模板本身就是为了泛型编程的方便设计出来的,你所谓的这种显式实例化,如果少了还能接受,多了以后你写的模板的意义还有什么呢?
就算你把能想到的常用的类型全部都显式实例化了,那么程序员搞个自己写的自定义类型,你不还是出事。
因此,有两句话评价这事:
- 模板同样支持声明和定义的分离,只需要在定义部分对所用类型进行显式实例化
- 模板不建议声明和定义的分离,因为实在是平添麻烦,一般建议直接把声明和定义都塞到头文件里
2.类模板声明和定义的分离
其实都没必要拿出来讲,因为类比就行了:
template<class T>
class stack
{
public:void push(const T& x);};如果类去做声明和定义的分离,是不是还是做类的成员函数的声明和定义的分离,那不又回到函数的声明和定义的分离上面了嘛。
四、模板总结
优点
- 模板使得代码复用率高,维护代码的通用逻辑只需要注意维护一处
- 模板在编译时检查类型,更加安全
- 泛型编程的基础
缺点
- 模板会导致代码膨胀问题,导致编译时间变长
- 出现模板编译错误,报错非常凌乱,甚至错误,不易定位错误
除了复用,可以说模板编译错误真是恶心死了,这个玩意我真是切身体会,好几次自己模拟实现的时候感觉天都塌了,因为报错信息根本不准,有种宏的美感。