C++:入门基础(2)
本章代码见:https://gitee.com/jxxx404/cpp-language-learning/commit/ff688eaf2475edd2485100b9295f20bfaf817dda
上一章文章:https://blog.csdn.net/2401_86123468/article/details/151836484?spm=1001.2014.3001.5501
大略复习上一章文章:注意using namespace std;的使用,在算法竞赛中换行推荐使用'\n',若使用endl;会更新缓冲区,影响效率。以及在竞赛中可以先添加下面三行代码:
#include<iostream>
using namespace std;int main()
{// 在io需求比较高的地方,如部分大量输入的竞赛题中,加上以下3行代码// 可以提高C++IO效率ios_base::sync_with_stdio(false);cin.tie(nullptr);cout.tie(nullptr);return 0;
}1.缺省参数
1.1
缺省参数是声明或定义函数时为函数的参数指定一个缺省值。在调用该函数时,如果没有指定实参则采用该形参的缺省值,否则使用指定的实参,缺省参数分为全缺省和半缺省参数。(有些地方把缺省参数也叫默认参数)
1.2
全缺省就是全部形参给缺省值,半缺省就是部分形参给缺省值。C++规定半缺省参数必须从右往左依次连续缺省,不能间隔跳跃给缺省值。
1.3
带缺省参数的函数调用,C++规定必须从左到右依次给实参,不能跳跃给实参。
1.4
函数声明和定义分离时,缺省参数不能在函数声明和定义中同时出现,规定必须函数声明给缺省值。
#include<iostream>
using namespace std;void Func(int a = 0)//赋予参数值,此为缺省值,a为缺省参数
{cout << a << endl;
}int main()
{Func(); // 没有传参时,使⽤参数的默认值 Func(10); // 传参时,使⽤指定的实参 return 0;
}
得到的结果:
0
10全缺省:
#include<iostream>
using namespace std;
// 全缺省
void Func1(int a = 10, int b = 20, int c = 30)
{cout << "a = " << a << endl;cout << "b = " << b << endl;cout << "c = " << c << endl << endl;
}int main()
{Func1(1, 2, 3);Func1(1, 2);Func1(1);Func1();return 0;
}得到的结果:
a = 1
b = 2
c = 3a = 1
b = 2
c = 30a = 1
b = 20
c = 30a = 10
b = 20
c = 30半缺省:
#include<iostream>
using namespace std;
// 半缺省
void Func2(int b, int c = 20, int a = 10)
{cout << "a = " << a << endl;cout << "b = " << b << endl;cout << "c = " << c << endl << endl;
}int main()
{Func2(1);Func2(1, 2);Func2(1, 2, 3);return 0;
}
得到的结果:
a = 10
b = 1
c = 20a = 10
b = 1
c = 2a = 3
b = 1
c = 2// Stack.h
#include <iostream>
#include <assert.h>
using namespace std;
typedef int STDataType;
typedef struct Stack
{STDataType* a;int top;int capacity;
}ST;
void STInit(ST* ps, int n = 4);// Stack.cpp
#include"Stack.h"
// 缺省参数不能声明和定义同时给
void STInit(ST* ps, int n)//在定义时要写好
{assert(ps && n > 0);ps->a = (STDataType*)malloc(n * sizeof(STDataType));ps->top = 0;ps->capacity = n;
}// test.cpp
#include"Stack.h"
int main()
{ST s1;STInit(&s1);// 确定知道要插⼊1000个数据,初始化时⼀把开好,避免扩容 ST s2;STInit(&s2, 1000);return 0;
}
2.函数重载
C++支持在同一作用域中出现同名函数,但是要求这些同名函数的形参不同,可以是参数个数不同或者类型不同。这样C++函数调用就表现出了多态行为,使用更灵活。C语言是不支持同一作用域中出现同名函数的。
2.1参数类型不同
#include<iostream>
using namespace std;int Add(int left, int right)
{cout << "int Add(int left, int right)" << endl;return left + right;
}
double Add(double left, double right)
{cout << "double Add(double left, double right)" << endl;return left + right;
}int main()
{cout << Add(1, 2) << endl;cout << Add(1.1, 2.2) << endl;return 0;
}结果为:
int Add(int left, int right)
3
double Add(double left, double right)
3.32.2参数个数不同
#include<iostream>
using namespace std;void f()
{cout << "f()" << endl;
}
void f(int a)//1个int参数
{cout << "f(int a)" << endl;
}int main()
{f();f(10);return 0;
}结果为:
f()
f(int a)2.3参数类型顺序不同
#include<iostream>
using namespace std;void f(int a, char b)
{cout << "f(int a,char b)" << endl;
}
void f(char b, int a)
{cout << "f(char b, int a)" << endl;
}int main() {f(10, 'A'); // 调用参数为「int, char」的版本f('B', 20); // 调用参数为「char, int」的版本return 0;
}
结果为:
f(int a,char b)
f(char b, int a)注意:
1.返回值不同不能作为重载条件,因为调用时无法区分
#include<iostream>
using namespace std;// 返回值不同不能作为重载条件,因为调⽤时也⽆法区分
void fxx()
{return 0;
}
int fxx()
{return 0;
}int main()
{// 调用时无法确定要调用哪个fxx();return 0;
}2.下面两个函数构成重载,但是不传参调用时,存在调用歧义。
//此时是错误代码
#include<iostream>
using namespace std;void f1()
{cout << "f()" << endl;
}void f1(int a = 10)
{cout << "f(int a)" << endl;
}
int main()
{//f1(1);f1();
}3.引用
3.1引用的概念和定义
引用不是新定义一个变量,而是给已存在变量取了一个别名,编译器不会为引用变量开辟内存空间
它和它引用的变量共用同一块内存空间。
类型&引用别名=引用对象;
#include<iostream>
using namespace std;int main()
{int a = 0;// 引⽤:b和c是a的别名 int& b = a;int& c = a;// 也可以给别名b取别名,d相当于还是a的别名 int& d = b;++d;// 这⾥取地址我们看到是⼀样的 cout << &a << endl;cout << &b << endl;cout << &c << endl;cout << &d << endl;return 0;
}
结果为:
000000D9471BF854
000000D9471BF854
000000D9471BF854
000000D9471BF854

3.2引用的特性
1.引用在定义时必须初始化
2.一个变量可以有多个引用
3.引用一旦引用一个实体,再不能引用其他实体
#include<iostream>
using namespace std;int main()
{int i = 1;int& j = i;cout << &i << endl;cout << &j << endl;++j;// 一个变量可以有多个引用int& k = j;k = 10;// 引用在定义时必须初始化/*int& x;x = i;*/// 引用一旦引用一个实体,再不能引用其他实体int m = 20;k = m;//此时是赋值return 0;
}3.3引用的使用
1.
引用在实践中主要是于引用传参和传引用返回中减少拷贝(深拷贝)提高效率和改变引用对象时同时改变被引用对象。
2.
引用传参跟指针传参功能是类似的,引用传参相对更方便一些。
#include<iostream>
using namespace std;// 指针
// 引用
// 大部分场景去替代指针,部分场景还是离不开指针void Swap(int* rx, int* ry)
{int tmp = *rx;*rx = *ry;*ry = tmp;
}void Swap(int& rx, int& ry)
{int tmp = rx;rx = ry;ry = tmp;
}int main()
{int x = 0, y = 1;cout << x << " " << y << endl;// Swap(&x, &y);cout << x << " " << y << endl;Swap(x, y);cout << x << " " << y << endl;return 0;
}结果为:
0 1
0 1
1 0也可以这样:
typedef struct SeqList
{//...
}SL;//void SLInit(SL* psl, int n = 4)
void SLInit(SL& psl, int n = 4)
{//...
}对于二级指针,可以这样:
void Swap(int** pp1, int** pp2)
{int* tmp = *pp1;*pp1 = *pp2;*pp2 = tmp;
}void Swap(int*& rp1, int*& rp2)
{int* tmp = rp1;rp1 = rp2;rp2 = tmp;
}
int main()
{int x = 0, y = 1;cout <<x<<!<< y << endl;Swap(&x, &y);cout << x<<<< y << endl;Swap(x, y);cout <<x<<""<< y << endl;SL s;SLInit(s) ;int* pl = &x, * p2 = &y;Swap(&p1, &p2);Swap(pl, p2);//区别
}3.传引用返回
引用返回值的场景相对比较复杂,这里先只简单讲一下场景。
错误做法:
注意下方演示:若返回局部变量的引用,会因局部变量生命周期结束导致 “野引用”,是错误用法。
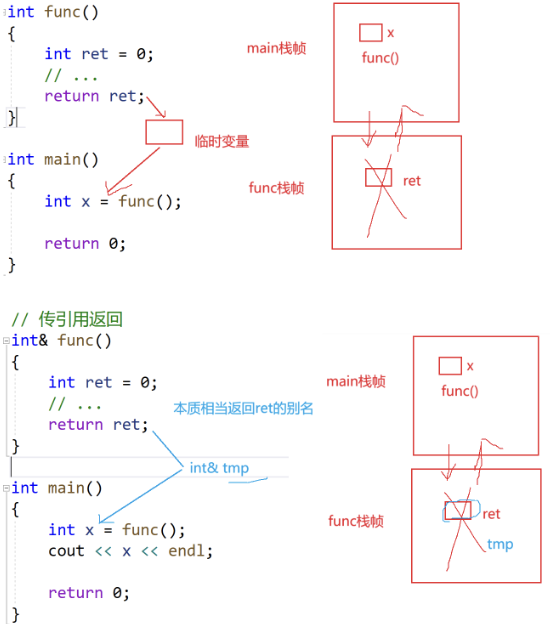
以及下面的代码,即使在return ret后被销毁,但仍可能结果相同。
因为局部变量的生命周期仅限于函数执行期间:当函数返回后,其栈帧(包含局部变量的内存)会被 “释放”(不再受程序控制),但内存空间本身不会立即 “清空”,只是标记为 “可复用”。此时,main 中的 x 作为引用,指向的是一块已释放的栈内存(野引用),后续对 x 的访问属于未定义行为(结果不可预测)。
int& func1()
{int ret = 0;// ...return ret;
}int& func2()
{int y = 456;// ...return y;
}int main()
{int& x = func1();cout << x << endl;func2();cout << x << endl;return 0;
}正确做法:加static。
int& func1()
{static int ret = 0;// ...return ret;
}int& func2()
{int y = 456;// ...return y;
}int main()
{int& x = func1();cout << x << endl;func2();cout << x << endl;return 0;
}通过修改顺序表第i个位置的值,了解引用的特性:语法简洁、无需解引用、必须初始化,以及它与指针在内存和使用上的不同。
指针写法:
#include"SeqList.h"int main()
{// 1. 定义顺序表对象s,并初始化(初始容量为10)SL s;SLInit(&s, 10); // 初始化顺序表,分配初始空间// 2. 向顺序表尾部插入10个元素(0~9)for (size_t i = 0; i < 10; i++){SLPushBack(&s, i); // 尾插操作:将i插入到顺序表s的末尾}// 3. 打印顺序表中的所有元素for (size_t i = 0; i < 10; i++){// SLat函数:获取顺序表s中第i个位置的元素cout << SLat(&s, i) << " "; }cout << endl; // 输出结果:0 1 2 3 4 5 6 7 8 9// 4. 修改顺序表中指定位置的元素int i = 0, x = 0;cin >> i; // 输入要修改的位置(假设输入3)cin >> x; // 输入新值(假设输入100)// 关键操作:通过SLat函数的返回值直接修改元素// 前提:SLat函数的返回类型必须是int&(元素的引用)SLat(&s, i) = x; // 等价于修改顺序表第i个元素的值为x// 5. 再次打印顺序表,验证修改结果for (size_t i = 0; i < 10; i++){cout << SLat(&s, i) << " "; }cout << endl; // 若输入i=3、x=100,输出:0 1 2 100 4 5 6 7 8 9return 0;
}引用写法:
#include<iostream>
using namespace std;int main()
{int i = 0; // 定义int变量i,初始值为0// 1. 引用的定义:r1是i的别名(必须初始化,且绑定后不可更改指向)// 引用不占用额外内存空间,与i共享同一块内存int& r1 = i; // 2. 指针的定义:p存储i的地址(可以先定义后初始化,可更改指向)// 指针本身占用内存(32位系统4字节,64位系统8字节)int* p = &i; // 3. 通过引用操作原始变量ir1++; // 等价于i++,i的值变为1// 4. 通过指针操作原始变量i(*p)++; // 指针需解引用(*)才能访问i,等价于i++,i的值变为2return 0; // 最终i的值为2
}4.
引用和指针在实践中相辅相成,功能有重叠性,但是各有特点,互相不可替代。C++的引用跟其他语言的引用(如Java)是有很大的区别的,除了用法,最大的点,C++引用定义后不能改变指向,
Java的引用可以改变指向。
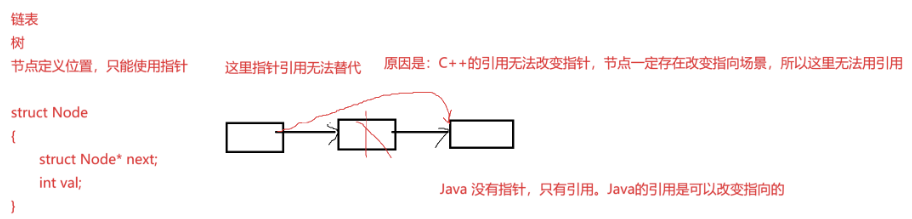
5.
一些主要用C代码实现版本数据结构教材中,使用C++引用替代指针传参,目的是简化程序,避开复杂的指针。
void SeqPushBack(SLT& sl, int x)
{//...
}typedef struct ListNode
{int val;struct ListNode* next;
}LTNode, *PNode;// 指针变量也可以取别名,这⾥LTNode*& phead就是给指针变量取别名
// 这样就不需要⽤⼆级指针了,相对⽽⾔简化了程序
//void ListPushBack(LTNode** phead, int x)
//void ListPushBack(LTNode*& phead, int x)void ListPushBack(PNode& phead, int x)
{PNode newnode = (PNode)malloc(sizeof(LTNode));newnode->val = x;newnode->next = NULL;if (phead == NULL){phead = newnode;}else{//...}
}int main()
{PNode plist = NULL;ListPushBack(plist, 1);return 0;
}
有些C语言书上是运用了引用的知识
typedef struct SListNode
{int val;struct SListNode* next;
}SLTNode,* PSLTNode;具体这样理解更清楚:

本章完。