DeepSeek的GPU优化秘籍:解锁大规模AI训练的底层效率
在AI领域,大规模模型训练正变得越来越复杂和资源密集。DeepSeek作为一家领先的AI研究机构,通过创新的GPU编程技术和优化方法,成功训练了如DeepSeek-V3(1750亿参数)和DeepSeek-Ultra(万亿参数)等前沿模型,并在受限硬件环境下实现了效率突破。根据公开资料和播客笔记(如Lex Fridman与Dylan Patel的对话),DeepSeek的实践不仅降低了训练成本,还将计算效率提升了数倍。本文将基于DeepSeek的真实案例,深入剖析GPU编程的核心优化技巧,提供可操作的业界实践指导,帮助开发者在实际项目中应用这些策略。
如果你是AI工程师、研究者或GPU编程爱好者,这篇文章将为你揭示从硬件定制到PTX底层优化的全栈路径。让我们从基础开始,一步步拆解。
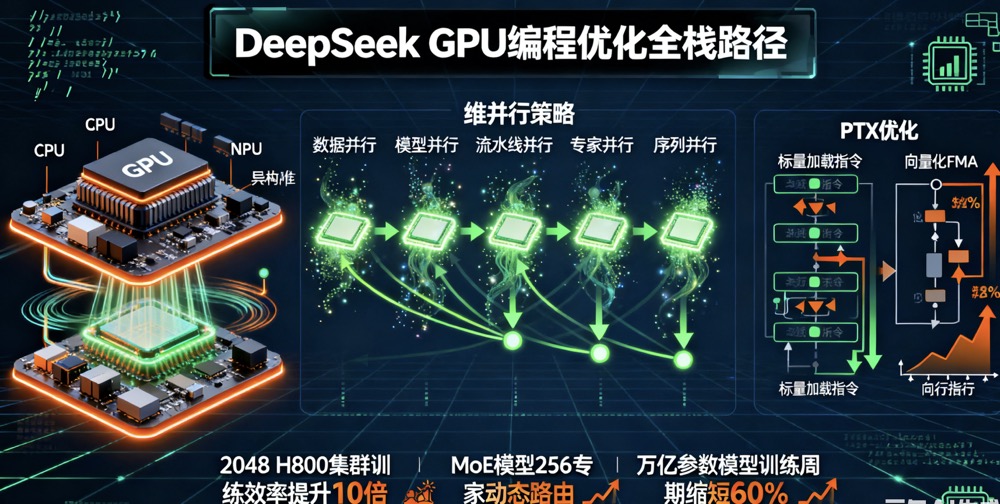
为什么GPU优化在AI训练中至关重要?
传统GPU训练大型语言模型(LLM)时,常面临内存瓶颈、通信延迟和计算利用率低的问题。DeepSeek的创新在于将GPU编程从高层框架(如PyTorch)深入到低级指令集(如PTX),实现了“纳米级”精度优化。例如,在2048个H800 GPU集群上,他们仅用两个月训练出6710亿参数的MoE模型,效率比许多顶尖实验室高出10倍。这不是靠硬件堆砌,而是通过技巧和策略——正如乒乓球比赛中,智慧胜过蛮力。
关键启示:GPU优化不是可选,而是必需。英伟达的CUDA生态强大,但DeepSeek证明,通过PTX等底层工具,可以绕过部分限制,甚至在国产GPU(如寒武纪MLU或昇腾NPU)上实现90%的效率对标。
1. 硬件架构的极限定制:融合异构计算
DeepSeek从硬件层面入手,构建异构架构来突破传统GPU瓶颈。他们将CPU、GPU和专用加速器融合,形成动态资源调度网络。
- 3D堆叠内存:在DeepSeek-V3训练中,将HBM内存垂直集成GPU核心,单卡容量从80GB提升至256GB,减少内存带宽瓶颈。
- 光互连网络:采用NVIDIA Quantum-2,将节点间延迟压缩至纳秒级,提升多节点协同效率。
- 实践指导:在你的项目中,使用CUDA MPS(Multi-Process Service)实现GPU时分复用。以下是简单配置示例:
nvidia-smi -i 0 -c EXCLUSIVE_PROCESS
nvidia-cuda-