RL知识回顾
一
1.状态转移随机性

2.占用度量(这个概念第一次认识
衡量交互过程中数据的分布,如果两个策略交互展示出来的数据分布一致可以认为策略相同;
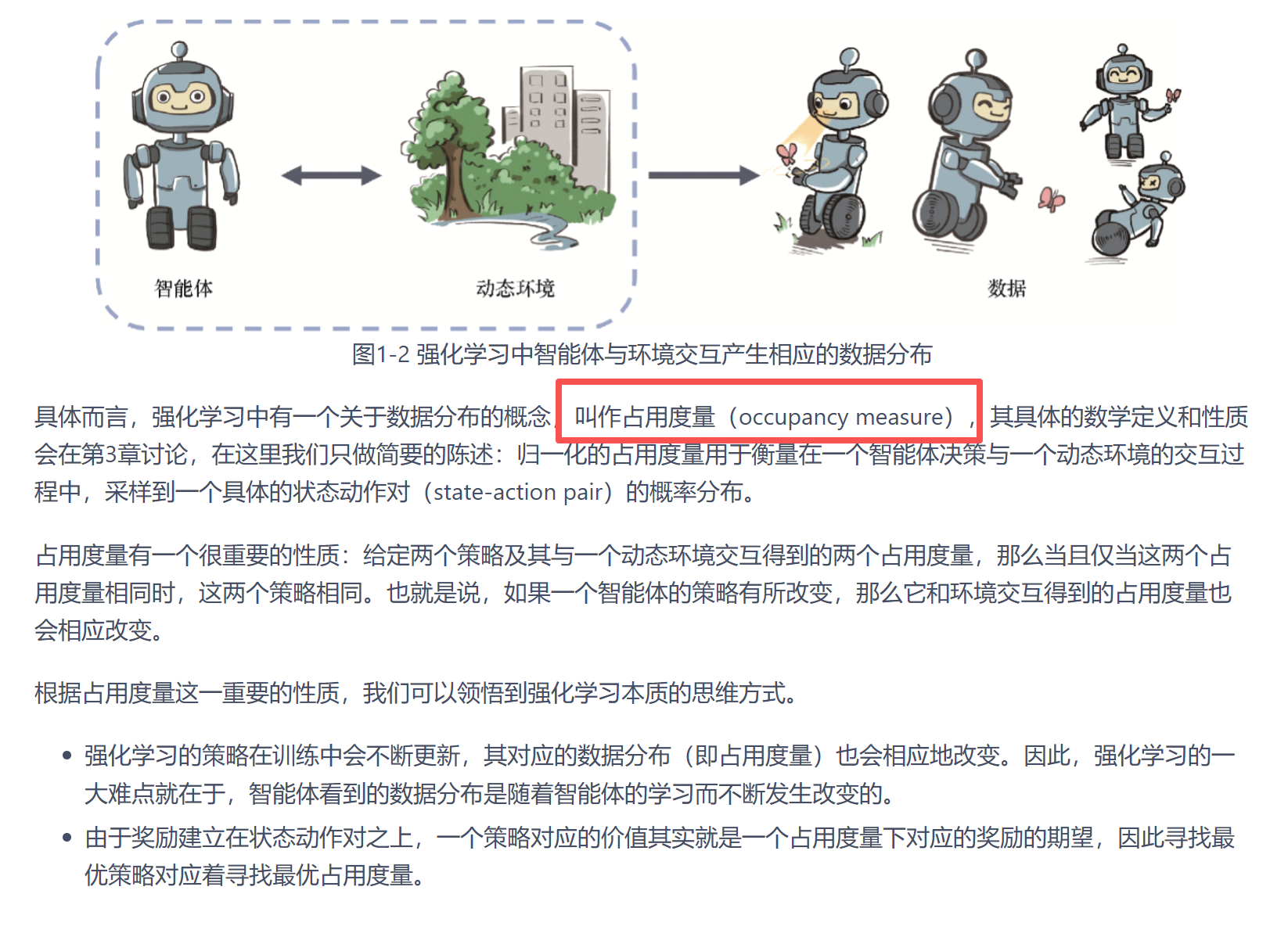
从数据角度来看,就是最优化数据分布;

总结
监督学习认为数据独立同分布,RL认为数据分布本身都是就存在2种随机性质。因此,学习过程RL将面临更加混沌的环境,学习难度也因此增加。

二 MAB

MAB问题中,动作并不会影响状态。但他仍然是一个RL问题,就是因为
即使在多臂老虎机(MAB)问题中,环境的状态是固定的,不会因为代理的动作而改变,但代理仍然需要通过与环境的交互来学习最优的策略。这种学习过程和内部状态的更新机制是强化学习(RL)的核心特征。因此,MAB问题仍然被认为是RL问题。


其实就是分为两部分奖励和状态,即使交互过程不影响o但是会影响奖励分布的计算,所以也符合RL问题的定义






MAB属于单步决策???




为什么MAB这类单步决策任务也有相应算法?




这一章关于多步决策和单步决策,之前就存在疑问:
如果在单步决策任务中,动作不影响环境状态,并且奖励分布也不需要明确求出,那么这个任务确实可以退化为一个监督学习(Supervised Learning)问题,而不是典型的强化学习(Reinforcement Learning, RL)问题。在这种情况下,深度学习(DL)方法可以非常适用,因为问题的核心变成了从输入到输出的映射学习。

如果不需要与环境进行交互来学习,就退化成了dl任务。


三 MDP



价值函数解析解求法


MC

四 DP

值迭代和策略迭代



策略迭代



4. 总结
值迭代和策略迭代都是动态规划中用于解决MDP问题的重要方法。值迭代通过直接更新值函数来逼近最优值函数,而策略迭代通过交替进行策略评估和策略改进来逼近最优策略。值迭代实现简单,但收敛速度可能较慢;策略迭代收敛速度通常更快,但实现复杂度较高。在实际应用中,选择哪种方法取决于具体问题的复杂性和计算资源的限制。
问题:也就是说策略迭代中包含了值迭代?