强化学习原理(一)
一、基本概念
State:描述的agent相对于环境的一个状态
State Space:所有状态的空间
Action:每一个状态可采取的一系列活动
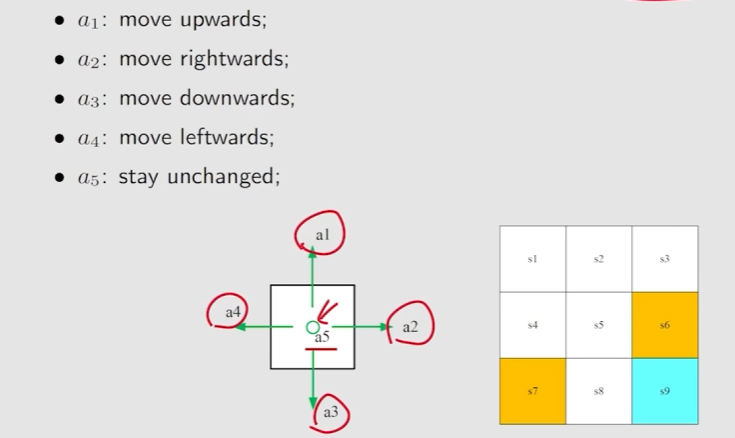
State transition:当采取action时,agent从一个state移动到另一个state

Forbidden area:进入某个区域后,agent会得到惩罚
State transition probability:使用概率来描述状态转移

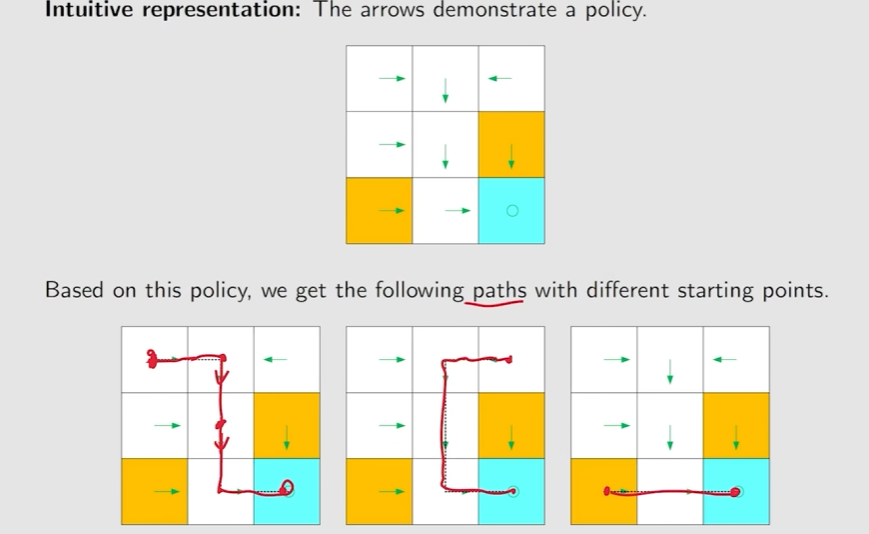
Policy:告诉agent如果在一个状态take哪个action
Mathematical representation:

Reward:是在才去一个action之后得到的实数
如果Reward是一个正数,代表对采取的action是鼓励的
如果Reard是一个负数,代表对采取的action是有惩罚的,不希望该行为的发生。

Trahectory:是一个state-action-reward的链
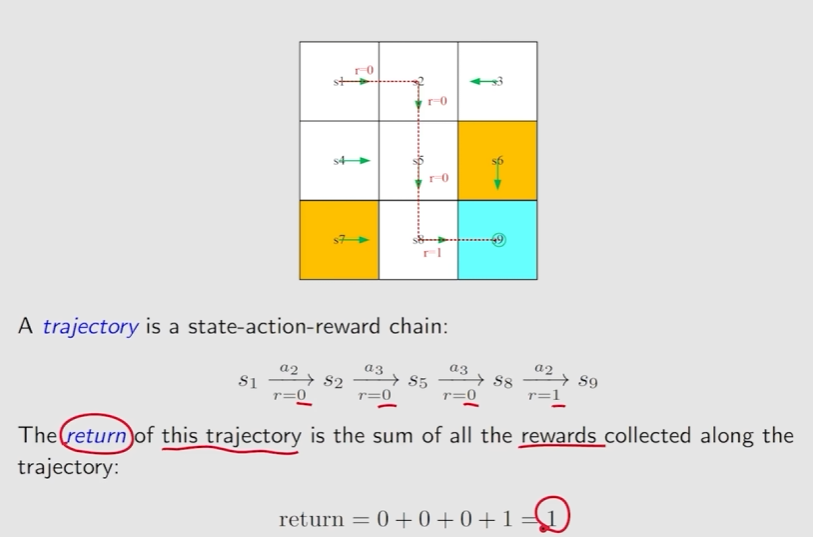
Discounted return 通过Discount rate

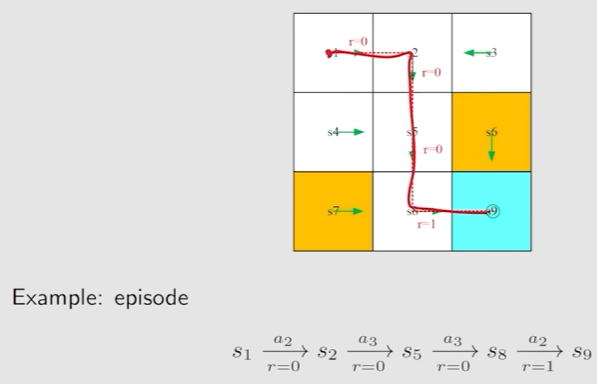
Episode:是有限步的
Markov decision process(MDP):

二、贝尔曼公式
Motivating examples:
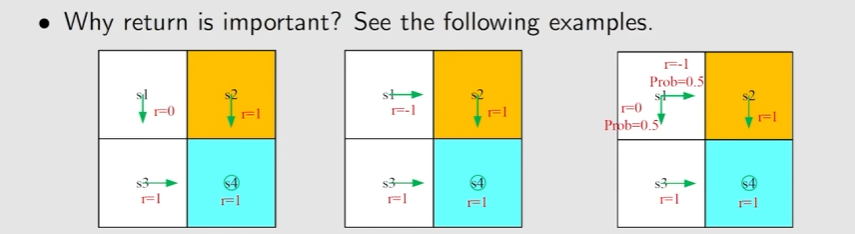
计算return是非常重要的,可以用来评估policy


将上方式子拆解成矩阵形式:

State value:一个trajectory 的discounted return 的期望值(平均值)

只有单一trajectory时,return等于state value。
贝尔曼公式的推导:
贝尔曼公式描述了不同状态的state value之间的关系

贝尔曼公式的矩阵和向量的形式:


Action value:agent从一个状态出发并且选择了一个action之后所得到的average return

