Qwen3技术之模型后训练
0. 引入
2025年5月,qwen推出了旗舰模型(flagship model)Qwen3-235B-A22B。并以Apache 2.0版权发布(可自由商业使用,修改代码和商用要包含原始版权)。本文对其技术报告中提到的后训练技术进行解读。
1. 后训练流程
后训练两个关键目标
(1)灵活控制think和no-think模式
(2)大模型生成数据,蒸馏小模型
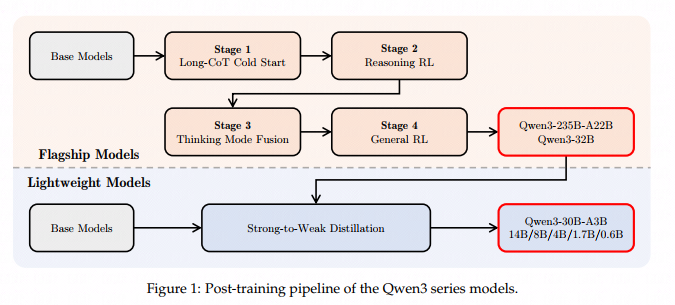
图1上半部分的4阶段训练:前2步为了think模式注入模型,后2步为了no-think模式。
四个Stage的目标:
Stage1:为模型灌输基础推理模式(instill foundational reasoning patterns);
Stage2:用GRPO对可验证结果的数据进行训练;
Stage3:think模式与no_think模式的混合;
Stage4:提高模型的能力与稳定性。
做蒸馏的目的:
(1)提高模型能力同时降低训练资源
(2)只需要四阶段训练的GPU的1/10
2. Long-CoT Cold Start
- 该阶段目标
为模型灌输基础推理模式(instill foundational reasoning patterns)。
- 高质量数据
包括多领域数据,包括代码、数学、逻辑推理、STEM。数据中都有answer(应该就是标注的sft数据,有question和answer)
数据集构造分为两个阶段:
(1)查询过滤,滤掉不易被验证的问题,比如含有多个子问题、太通用的文本生成。以及去掉qwen2.5自己不需要CoT就能回答正确的问题。最终根据标注获取平衡数据。
(2)阶段,生成问题对应的N个回复,并进行过滤:错误answer,重复,推理不充分,思考过程与记过不一致,语言混合或风格变化,与验证集过于相似。
该步骤使用最小的训练集数量与训练steps。
3. Reasoning RL
该步骤用GRPO对可验证结果的数据进行训练。RL步骤需要对结果进行验证,所以需要验证器(比如判断数学计算结果是否正确)。该步骤只用了3995条数据(侧面说明这样的数据难以获取?)
4. Thinking Mode Fusion
该步骤将think模式与no_think模式的混合。
- 构造SFT数据
think数据和no_think数据,混合为该阶段SFT数据。包括:
(1)think数据用stage2模型通过对stage1数据进行拒绝采样(无法回答的数据)获取到。
(2)no-think数据,使用多领域数据,自动验证选择高质量回答数据。
增加翻译任务数据比重
-
三类数据
(1)system或者prompt中含think
(2)含no-think
(3)不含tag,默认用think模式 -
Thinking Budget
两种数据混合训练带来的附加好处:think一半后进行回答。
推理长度到达用户限制的阈值后,终止继续think就输出最终结果:训练时也没期望达到这个效果,这是训练后自然而然达到的效果。
5. General RL
该步骤提高模型的能力与稳定性。用20多个任务打分做RL,包括如下部分任务:
- 指令跟随:生成用户指令中期望的内容、格式、结构化输出、对齐用户期望
- 格式跟随:
<think></think> - 偏好跟随:回答更有帮助,风格,更自然,满足用户期望
- 智能体能力:真实环境下的多轮工具调用交互
三类reward:
(1)规则
(2)模型:LLM根据标注答案与此时回答进行对比打分
(3)人类偏好打分
参考
- qwen3技术文档,https://github.com/QwenLM/Qwen3/blob/main/Qwen3_Technical_Report.pdf