NeurIPS 2025 spotlight Autonomous Driving VLA World Model FSDrive
🚗论文地址: https://arxiv.org/abs/2505.17685
🚀代码地址: https://github.com/MIV-XJTU/FSDrive
问大家一个问题:你开车时,脑子里在想什么?
当你在拥挤的十字路口准备左转,你是不是已经在脑海里“预演”了对向车流的空隙、行人可能的轨迹,甚至规划好了自己打方向盘的时机和速度?
这种对未来的预判和想象,是人类老司机区别于新手小白的核心能力。我们不只是被动地“看见”当前的路况,更是在主动地“脑补”接下来几秒钟会发生什么。
那么,问题来了:自动驾驶的AI,能学会这种“脑补”未来的能力吗?
过去,很多自动驾驶模型像一个只会背书的学生。它们看到图像,然后用一堆文字标签来“思考”:“前方有车,距离10米,速度30km/h,我应该减速。” 这种方式,就像把一幅生动的油画硬生生压缩成几行干巴巴的文字描述,丢失了太多细节和时空关系,既不直观,也容易出错。
现在,来自阿里巴巴高德和西安交通大学的研究者们给出了一个颠覆性的答案。在他们最新的论文 《FutureSightDrive: Thinking Visually with Spatio-Temporal CoT for Autonomous Driving》 中,他们提出了一种让AI“用视觉思考”的全新范式!
简单来说,他们教会了AI像我们一样,直接在“脑海”里生成一幅未来的动态画面,然后根据这幅“想象图”来做决策。
一、告别文字“碎碎念”,拥抱「时空思维链」(Spatio-Temporal CoT)
这篇论文最酷的概念,就是**“时空思维链”(Spatio-Temporal Chain-of-Thought)**。
传统的“思维链”(CoT)是让AI用文字一步步推理,比如:
“首先,我看到一个行人。然后,我判断他要过马路。所以,我应该减速。”
而FutureSightDrive的“时空思维链”完全不同,它让AI直接生成一幅包含未来时空信息的**“预测图”**。这幅图里有什么呢?
- 未来的空间骨架 (Spatial Relationship):AI会直接在未来的画面上“画”出关键信息,比如用红线标出车道线的走向、用3D框“框”出其他车辆未来几秒的位置。这就像给未来的场景打好了草稿,锁定了物理世界的规则。
- 未来的时间演化 (Temporal Relationship):除了骨架,AI还会填充完整的场景,“脑补”出整幅画面的动态演变。比如远处的车辆会变近,旁边的建筑光影会变化。
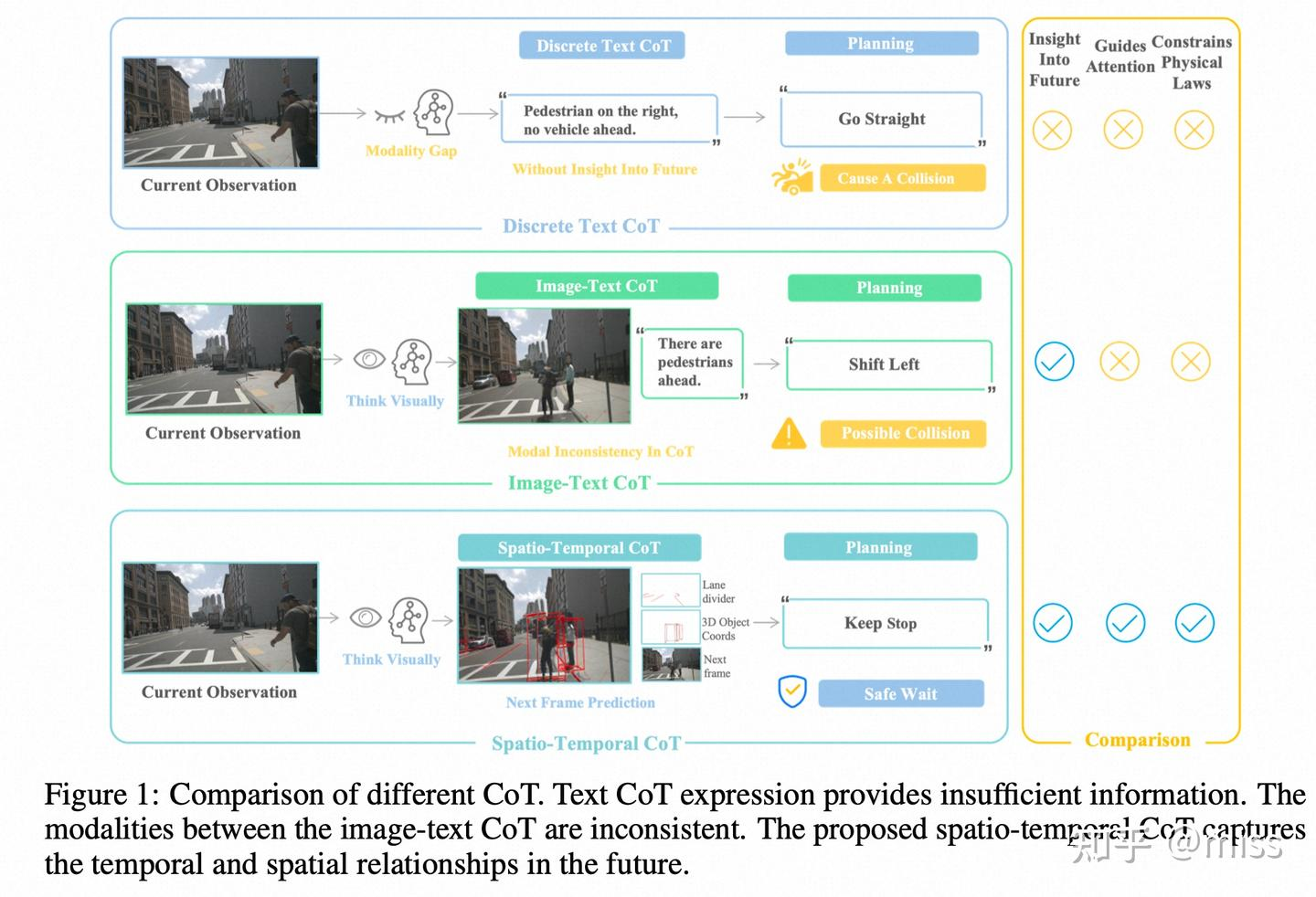
这样做的好处是什么?
- 信息无损:视觉到视觉,避免了“图像→文字→决策”的转换损耗。所有精细的、难以用语言描述的动态信息都被保留了。
- 物理真实:AI的“想象”不再是天马行空,而是被它自己预测的车道线、车辆位置等物理规则牢牢约束,更符合真实世界。
- 端到端视觉推理:整个过程形成了一个闭环的视觉推理管道,AI可以直接根据“看到的现在”和“想到的未来”进行因果判断,做出决策。
二、身兼两职:既是“世界模型”,又是“逆动力学模型”
在FutureSightDrive框架下,视觉语言模型(VLM)扮演了两个关键角色:
- 世界模型 (World Model):它是一个“预言家”,根据当前的观测,生成那幅包含时空思维链的“未来预测图”。
- 逆动力学模型 (Inverse Dynamics Model):它是一个“规划师”,看着“当前的状态”和自己“预测出的未来状态”,反向推导出自己需要执行什么动作(比如轨迹规划),才能从现在安全地抵达那个预测的未来。
这个过程,就好像你开车时,脑子里想着“3秒后我要到达那个车道空隙”,然后身体自动就完成了打方向、踩油门的一系列操作。知道了起点和终点,反推出过程,这是一种更高阶的智能。
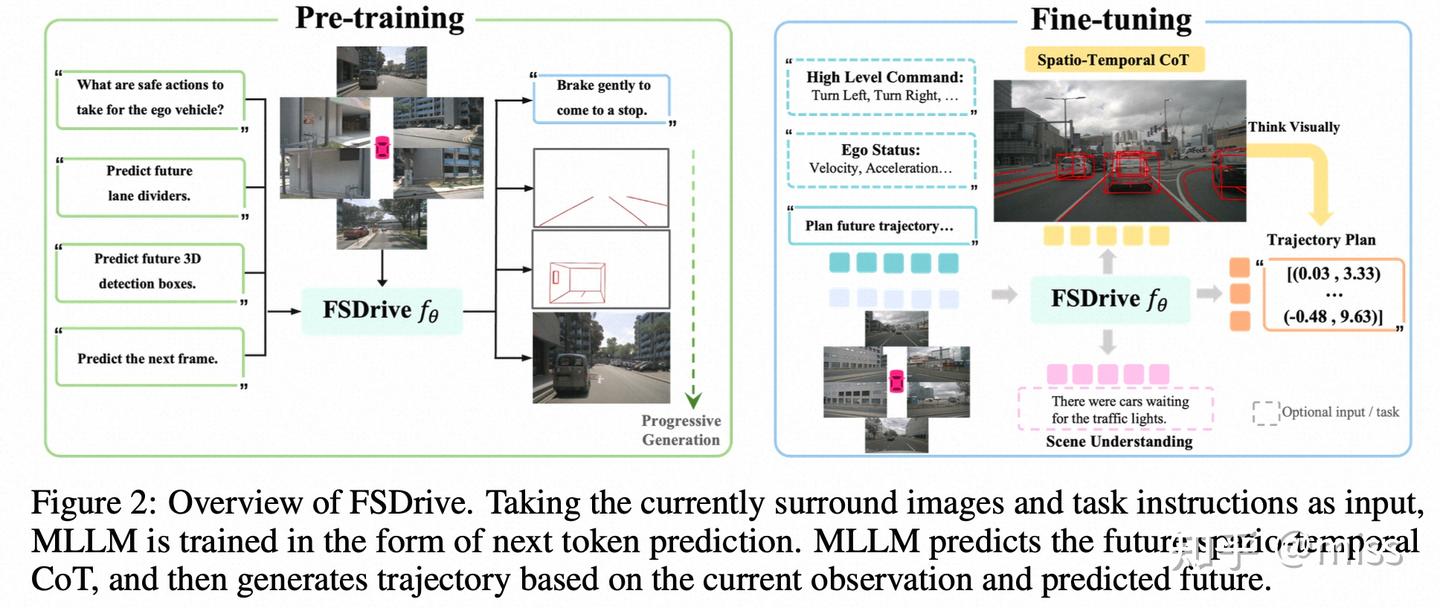
三、“点石成金”:低成本解锁模型的隐藏能力
“让模型生成图像”听起来很高大上,是不是需要海量数据从头训练一个新模型?
并不! 这也是这篇工作一个非常聪明的地方。他们提出了一套统一的视觉生成与理解预训练范式:
- 保留理解能力:通过传统的视觉问答(VQA)任务,确保模型对场景的理解能力不下降。
- 激活生成能力:巧妙地将图像的“视觉词元”(Visual Token)加入到语言模型的词汇表中,用极少的训练成本(仅为同类方法的0.3%!)就“解锁”了现有VLM的图像生成潜力。
而且,为了让AI的“脑补”更靠谱,他们还设计了**“渐进式生成”**策略:先从简单的车道线、3D框开始预测(由易到难),再基于这些物理约束去生成完整的未来画面,大大提高了预测的准确性。
四、实验效果:不只“想得美”,而且“开得好”!
空谈误国,实干兴邦。FutureSightDrive的效果怎么样?
论文在nuScenes等权威数据集上进行了大量实验,结果非常亮眼:
- 轨迹规划:在L2误差和碰撞率等核心指标上,FSDrive全面优于现有SOTA模型,尤其是在降低碰撞风险上表现突出。这证明“看得更远”确实能“开得更稳”。
- 未来画面生成:生成的未来画面质量(FID指标)媲美甚至超越了专门的扩散模型,说明它的“脑补”能力是实打实的。
- 场景理解:在DriveLM等场景理解榜单上也取得了顶尖成绩,证明获得生成能力的同时,理解能力也得到了加强。
更绝的是一个定性实验:研究者故意给模型一个错误的导航指令(比如让它在直行道上右转),没有“脑补”能力的模型会傻乎乎地撞墙,而FSDrive能通过对未来的视觉预测,意识到指令的错误,并规划出一条更安全、更合理的路径,成功“自救”!

总结:从“语言思考”到“视觉思考”的范式飞跃
FutureSightDrive的提出,可能代表了自动驾驶领域一次重要的范式转变。它不再满足于让AI用人类的语言符号去间接理解世界,而是赋予了AI一种更接近生物本能的、基于视觉想象的思考能力。
这让我们离真正安全、智能、像人的自动驾驶又近了一大步。当AI不仅能看懂“红灯停,绿灯行”,还能在脑海中预演出那个突然从路边冲出的小孩并提前减速时,自动驾驶的未来才真正值得我们期待。