DCM项目wan 1.3b T2V模型comfyui改造流程尝试
DCM项目中dit权重地址:https://hf-cdn.sufy.com/cszy98/DCM/tree/main/DCM_WAN/transformer
本文主要针对DCM模型推理时,将sem模型与det模型通过lora参数的lora来进行区分,故尝试将其分开为2个模型。并尝试将其改造为标准WanVideo_comfy kj wan模型权重。最后搭建工作流实现模型推理,推理效果低于预期,应该是Scheduler没有能迁移到WanVideo_comfy 中。
1、代码差异分析
经过博客论文项目:DCM代码阅读分析,可以发现DCM蒸馏后,在原来模型的参数基础上新增了以下三个模块。
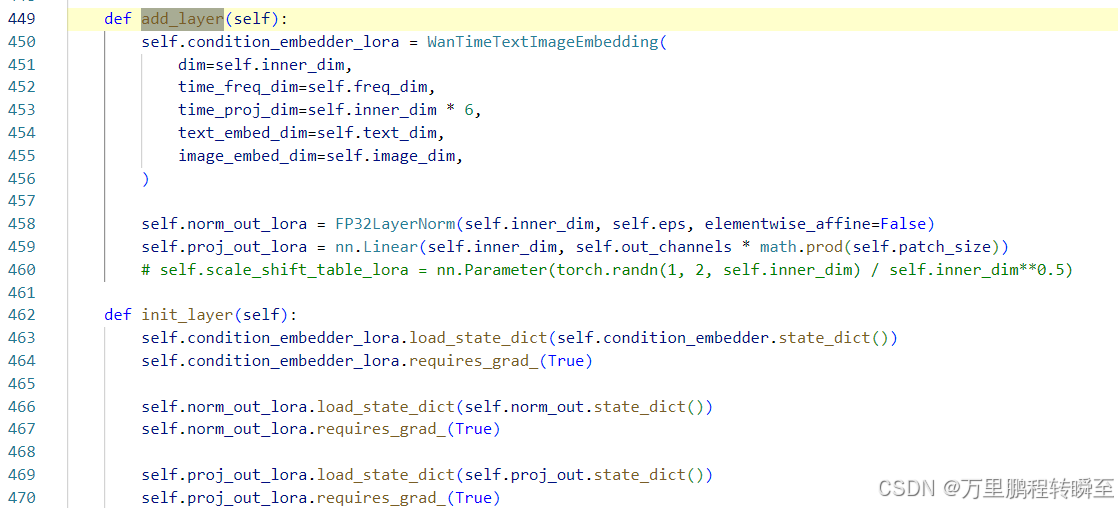
在推理时的timestep小于981时,走新链路(及前面的新增参数-lora参数);否则走原来的参数流程。在推理过程中timestep,是从大到小
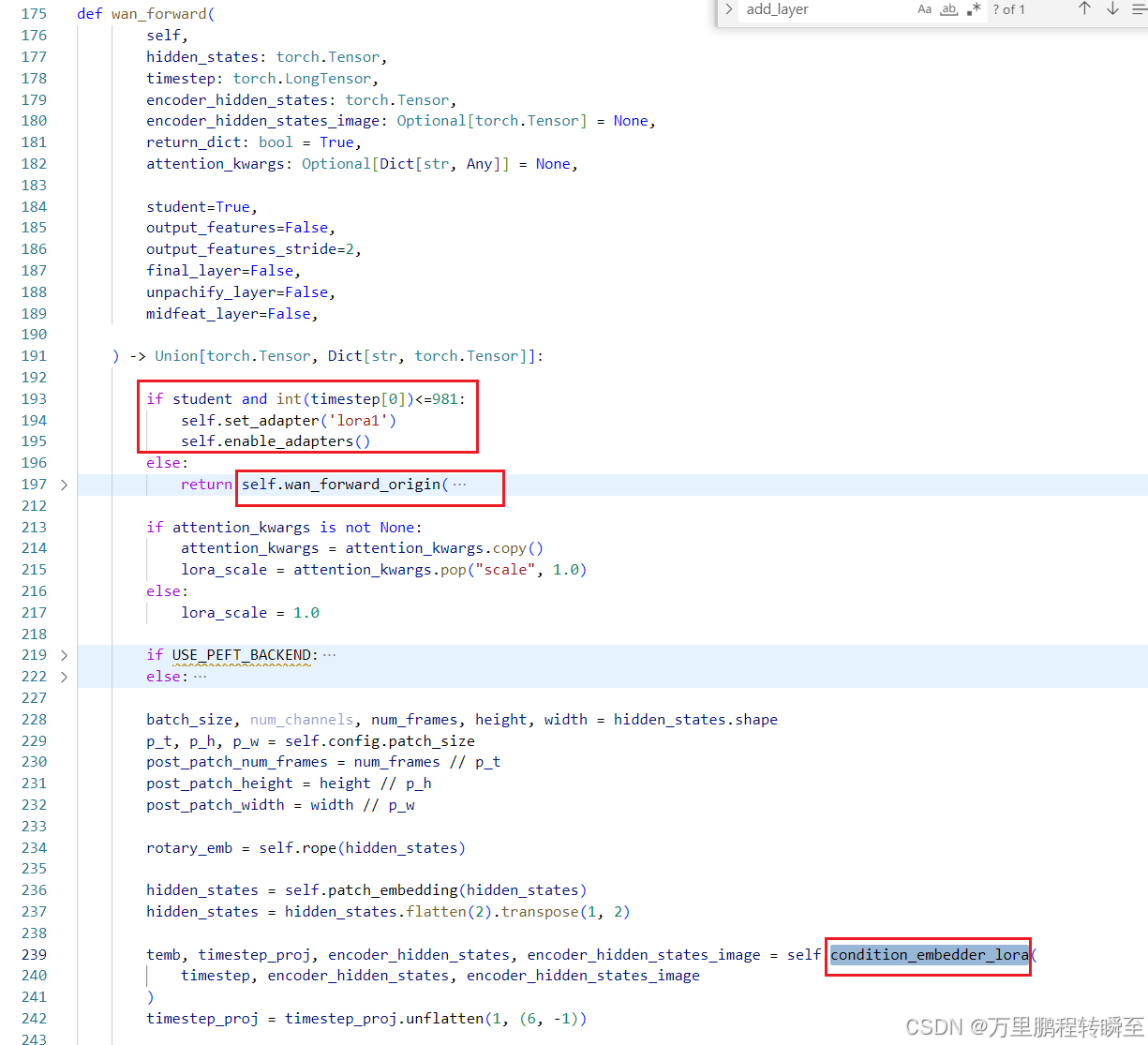
2、DCM模型推理时设置分析
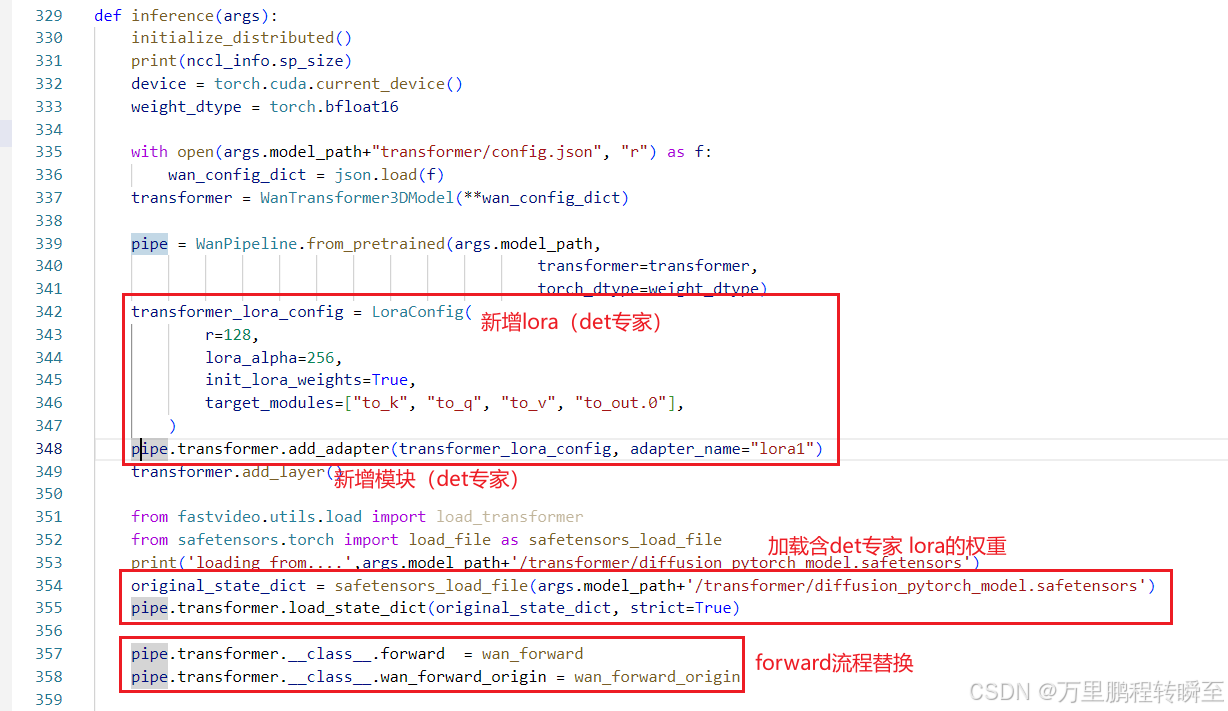
基于 DCM-main\fastvideo\sample\inference_wan.py 可以分析发现,模型在加载权重前有新增det专家网络结构的部分;在权重加载后,对forward流程进行替换。这里的wan模型是根据fastvideo库(基于diffusers库的规范)定义的
同时在推理时,覆盖了原有的采样器,并指定了时间步数。【这里需要注意,采样器还负责根据模型预测出的噪声,对input进行去噪操作】
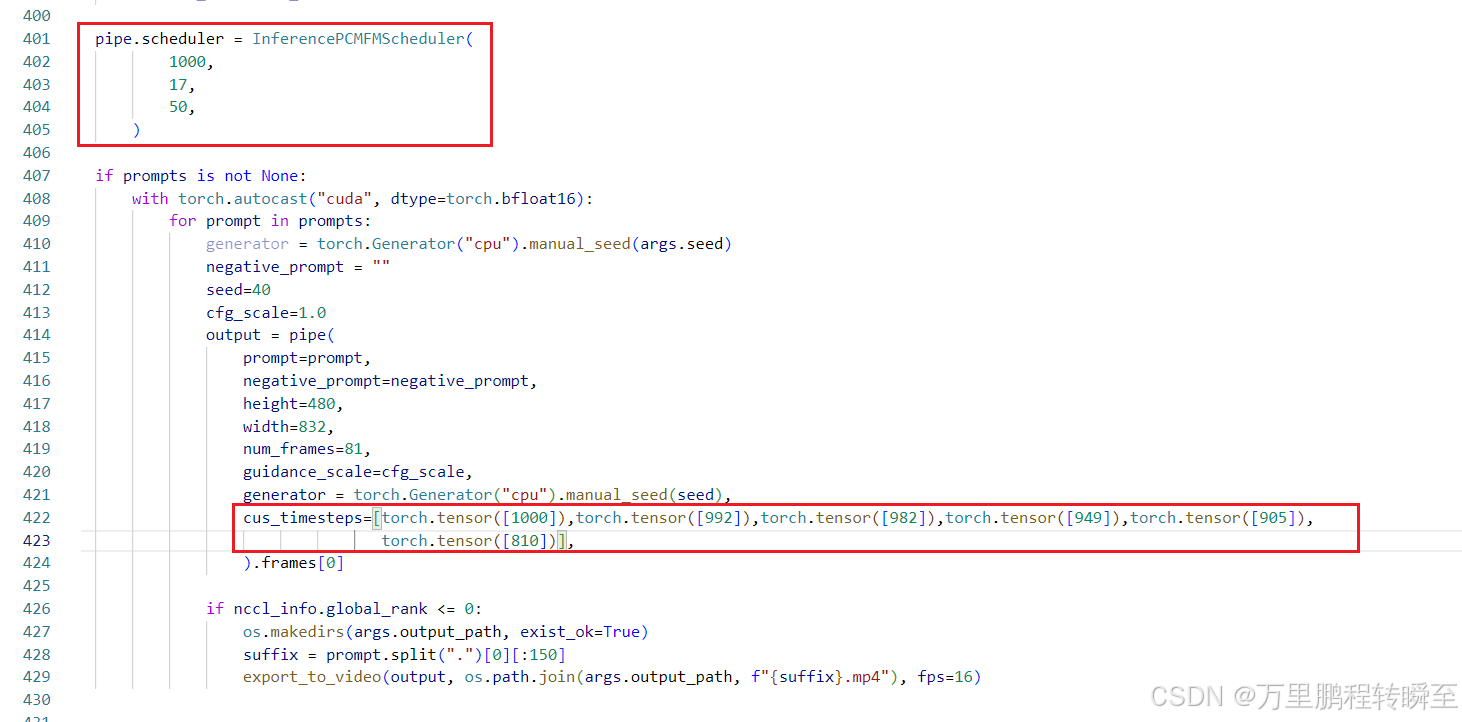
在wan2.1 官方代码中,时间步是根据采样器计算的。
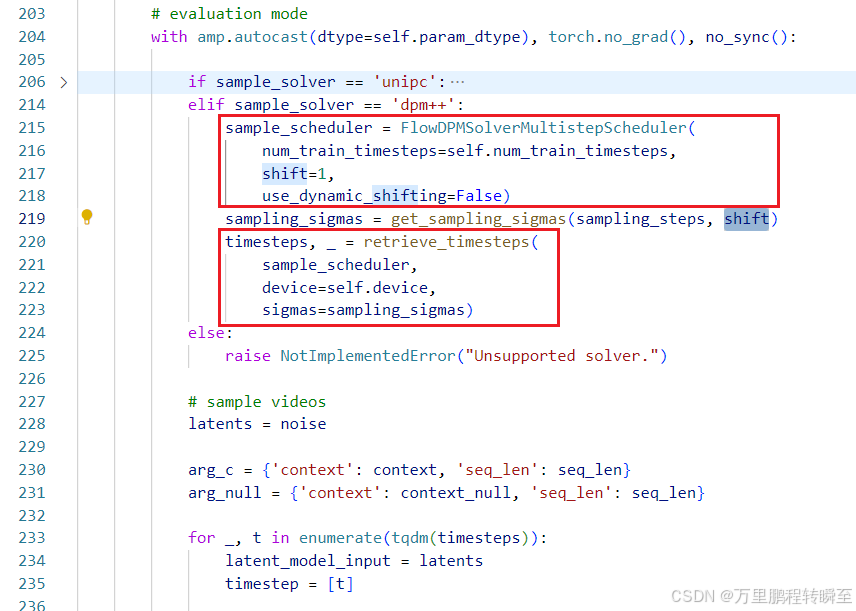
3、参数对应关系梳理
在wan2.1 官方代码包中,dit模型中forward流程如下所示,1跟6为patch与unpath操作,步骤2涉及到了rope的计算为时间编码,3为文本编码,4为dit-block中的slef-attn与cross-atten,5为时间编码与x的交互。
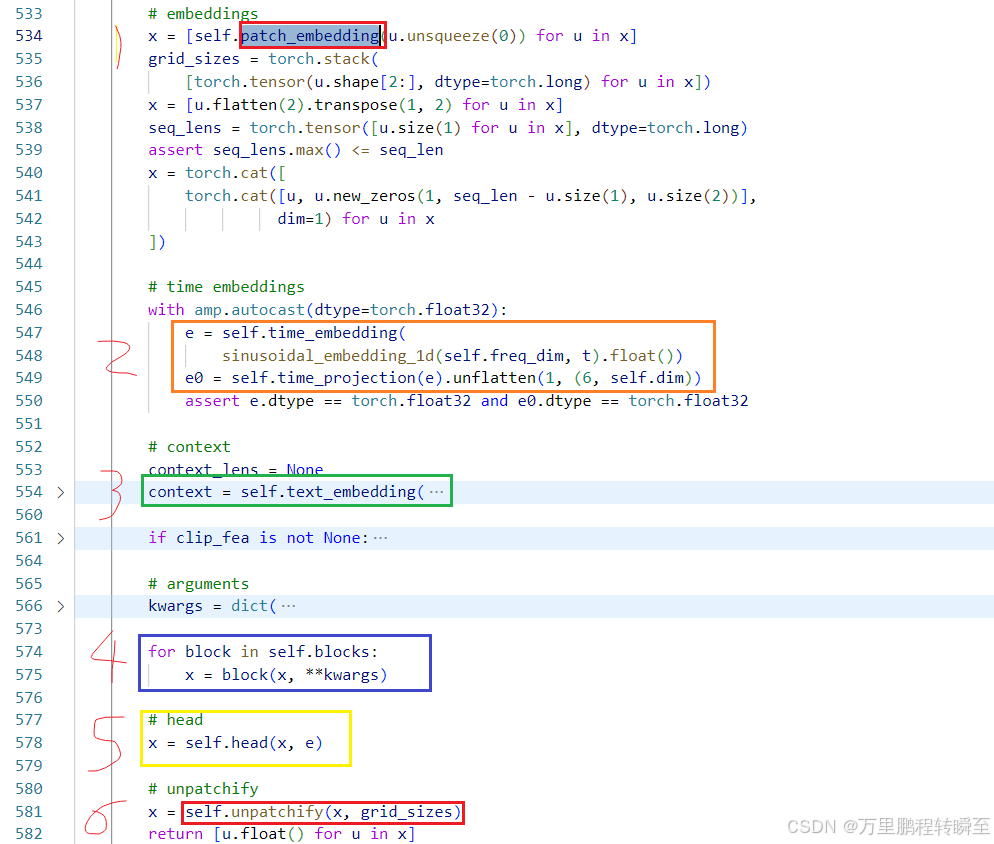
在DCM中,wan2.1的forward流程如下,开始跟结束都是patch相关操作,然后是时间步计算,然后是dit-block过程,再是时间编码与x的交互。
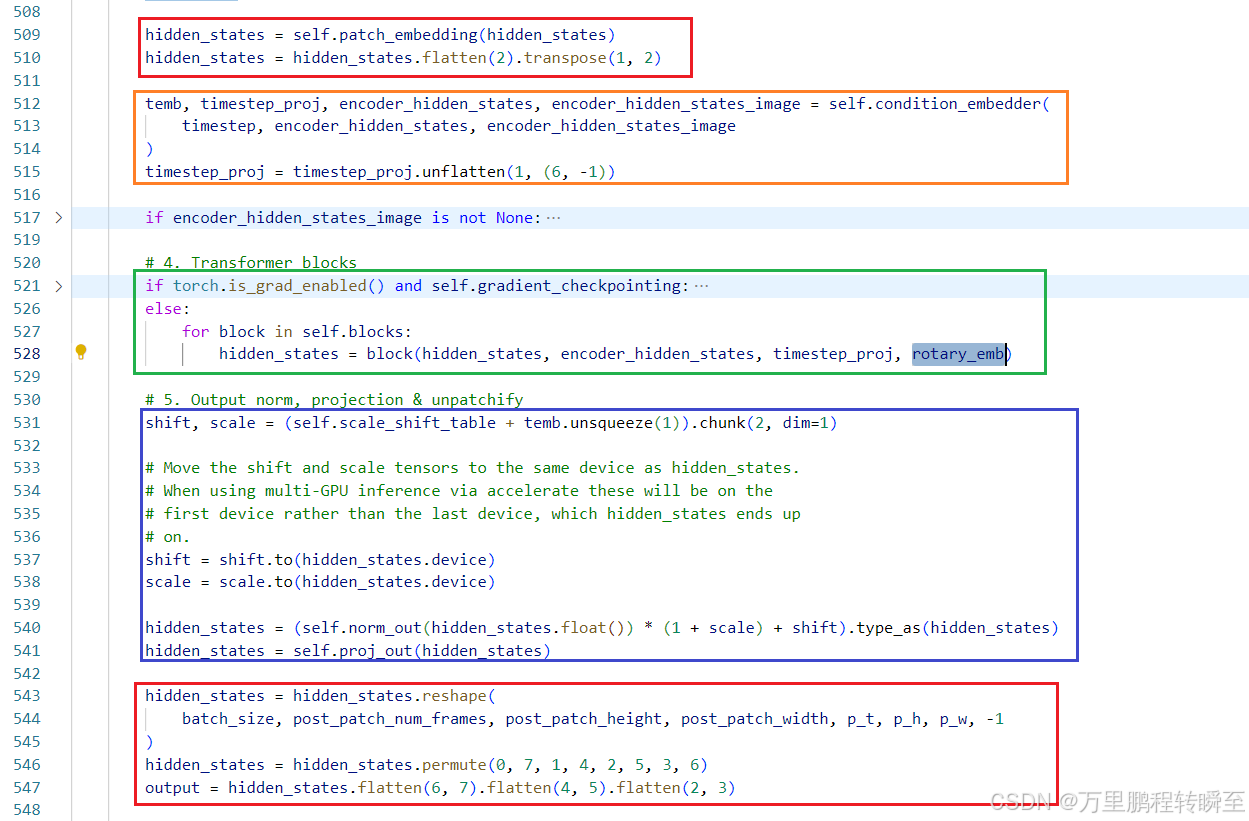
同时,可以通过DiffSynth库中的代码观察到wan2.1在两个代码包中的命名变化
https://github.com/modelscope/DiffSynth-Studio/blob/main/diffsynth/models/wan_video_dit.py#L421
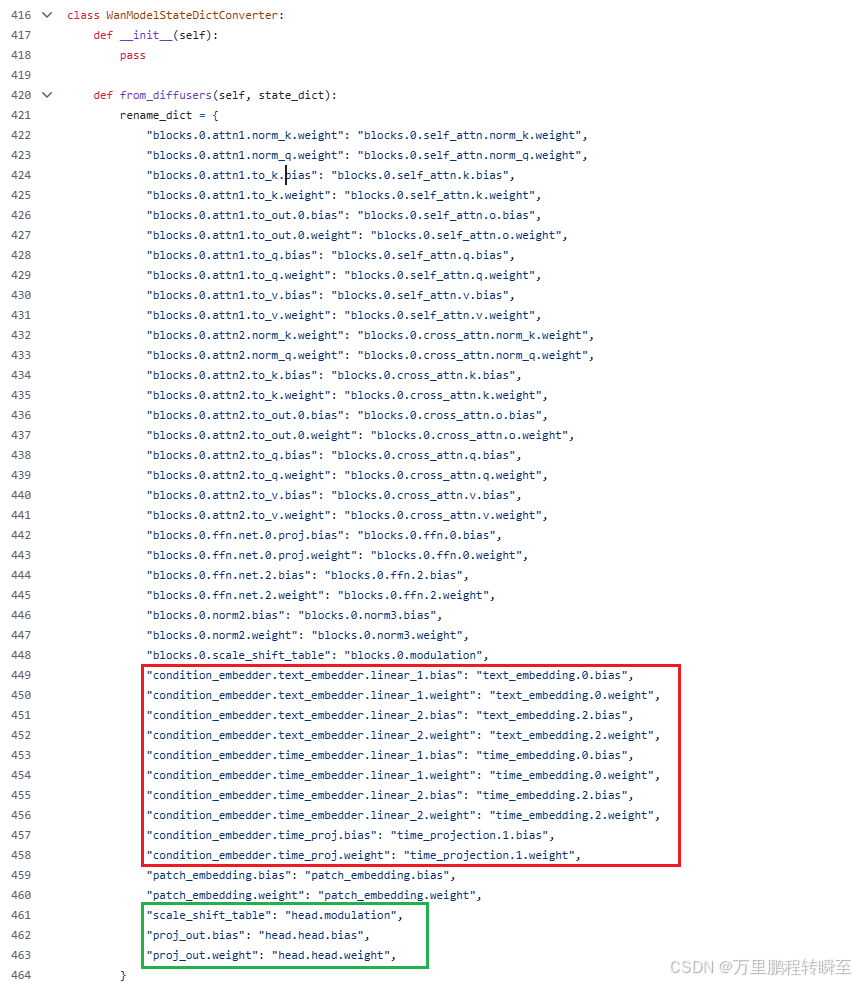
通过对项目官方的权重进行分析,可以发现仅多以下两个参数,没有其他lora权重。condition_embedder对应到wan官方代码里面的text_embedding与time_projection,proj_out对应原来的head.head。
condition_embedder_lora应该对应新增text_embedding_lora、time_projection_lora,proj_out_lora对应head_lora.head
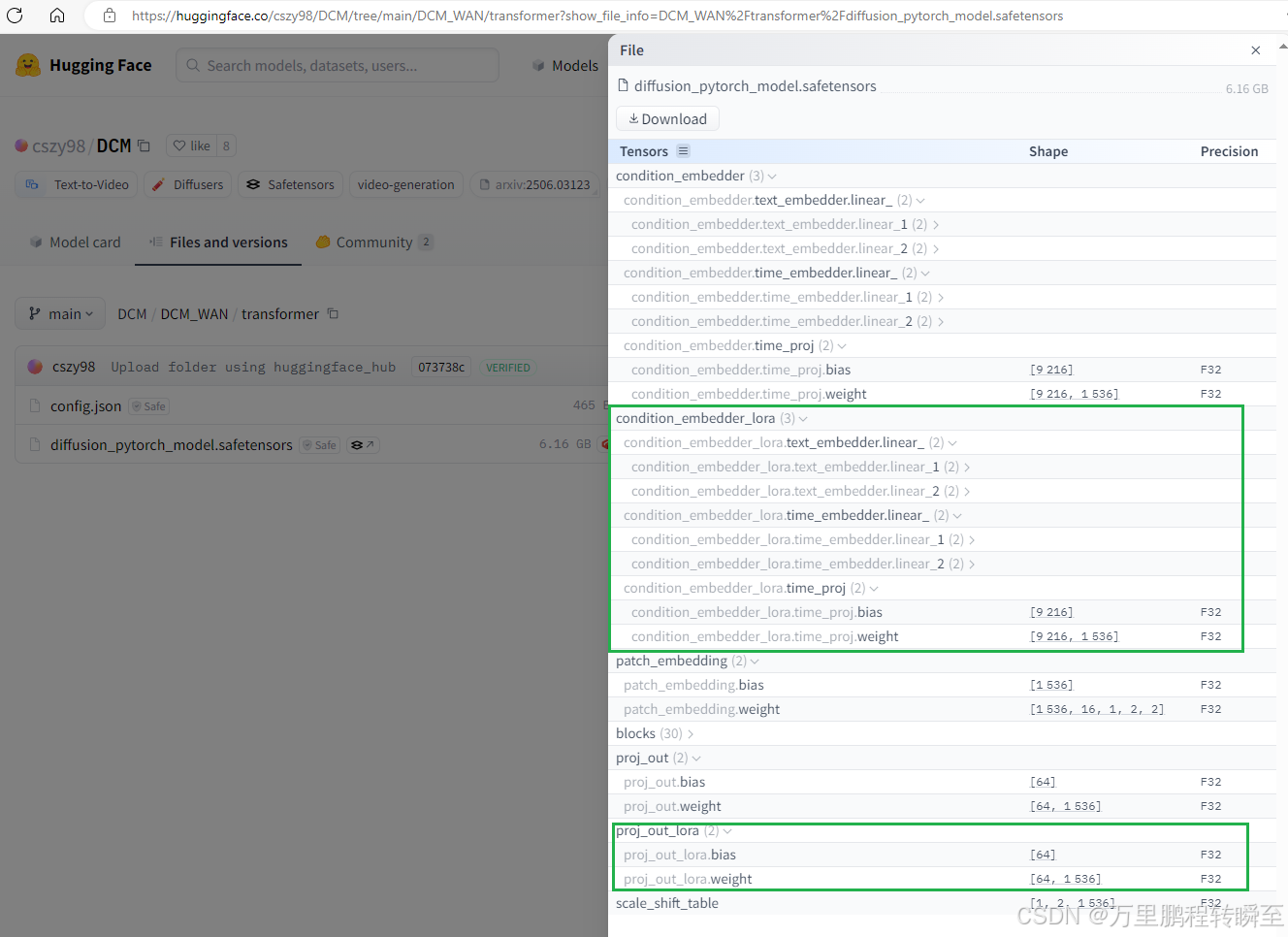
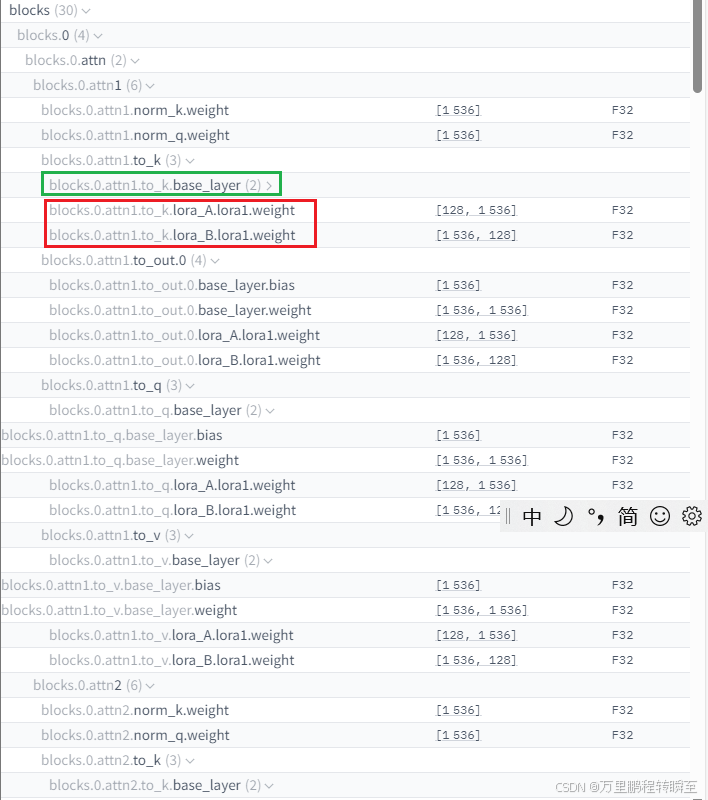
同时可以发现每一个dit-block中都有lora权重,对应推理代码里面的【self.set_adapter(‘lora1’)+condition_embedder_lora,det专家】等操作
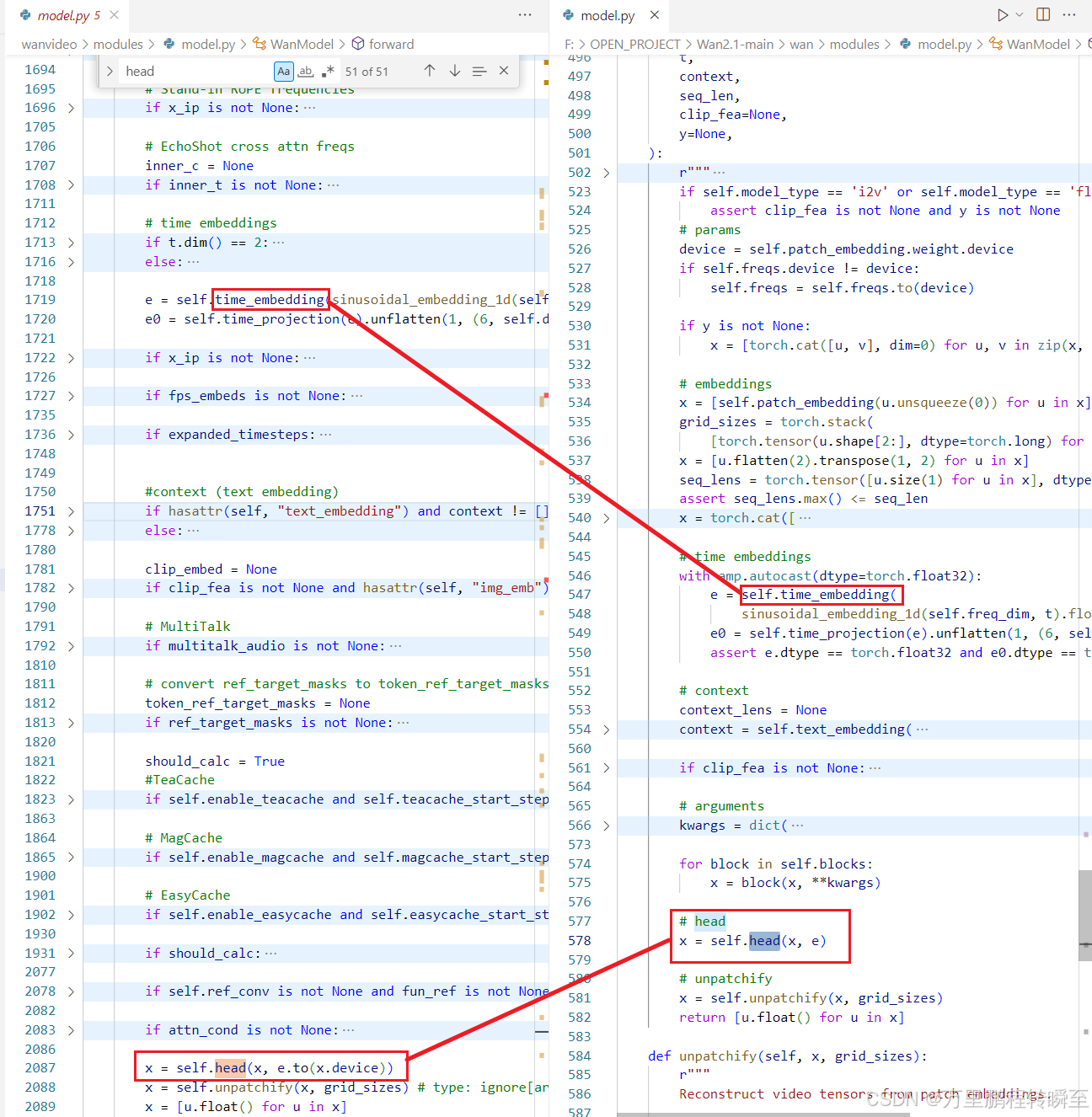
通过对比ComfyUI-WanVideoWrapper下wanvideo\modules\model.py与Wan2.1官方代码下\wan\modules\model.py,可以发现ComfyUI-WanVideoWrapper下代码虽然复杂很多,但是time_embedding与head的应用都是可以对应的。
4、将sem与det模型从DCM模型中提取出来
加载原始模型两次,分别命名为sem模型,det模型
import sys #change 1
sys.path.append(r"f:\OPEN_PROJECT\DCM-main")
from fastvideo.models.wan_hf.modeling_wan import WanTransformer3DModel
from peft import LoraConfig
import json
if __name__=="__main__":model_path="DCM_WAN_1.3b" #下载的模型路径with open(model_path+"/transformer/config.json", "r") as f:wan_config_dict = json.load(f)transformer_lora_config = LoraConfig(r=128,lora_alpha=256,init_lora_weights=True,target_modules=["to_k", "to_q", "to_v", "to_out.0"],)from safetensors.torch import load_file as safetensors_load_fileprint('loading from....',model_path+'/transformer/diffusion_pytorch_model.safetensors')original_state_dict = safetensors_load_file(model_path+'/transformer/diffusion_pytorch_model.safetensors')sem_model = WanTransformer3DModel(**wan_config_dict)sem_model.add_adapter(transformer_lora_config, adapter_name="lora1")#from peft import get_peft_model#sem_model = get_peft_model(sem_model, transformer_lora_config, adapter_name="lora1")sem_model.add_layer()sem_model.load_state_dict(original_state_dict, strict=True)#sem_model.base_model.model.load_state_dict(original_state_dict, strict=True)det_model = WanTransformer3DModel(**wan_config_dict)det_model.add_adapter(transformer_lora_config, adapter_name="lora1")#from peft import get_peft_model#det_model = get_peft_model(sem_model, transformer_lora_config, adapter_name="lora1")det_model.add_layer()det_model.load_state_dict(original_state_dict, strict=True)
插入调试代码,可以看到初始化后的模型都是lora结构
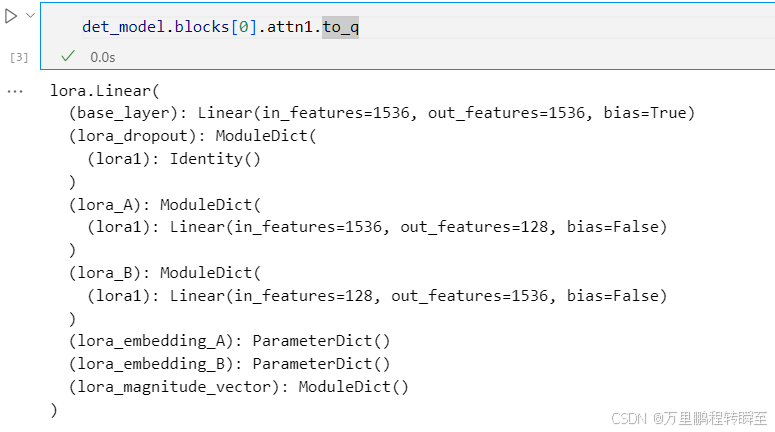
sem模型保存
sem_model.unload_lora() #移除lora权重
sem_model.blocks[0].attn1.to_q #检验模型结构
#确认参数是一致的
#sem_model.blocks[0].attn1.to_q.weight-det_model.blocks[0].attn1.to_q.base_layer.weight
#保持sem模型权重
from safetensors.torch import save_file
save_file(sem_model.state_dict(), f"wan2._1.3B_t2v_sem.safetensors")
这里可以验证下模型参数是否一致
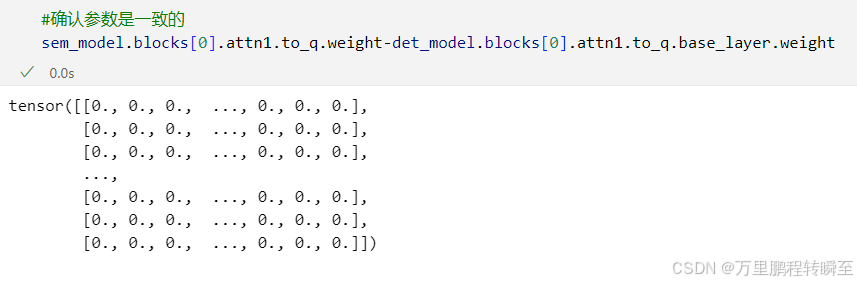
det模型保存
det_model.fuse_lora(adapter_names=["lora1"]) #合并lora权重到主模型
det_model.unload_lora() #移除lora权重det_model.condition_embedder=det_model.condition_embedder_lora
det_model.norm_out=det_model.norm_out_lora
det_model.proj_out=det_model.proj_out_loradel det_model.condition_embedder_lora
del det_model.norm_out_lora
del det_model.proj_out_lora
save_file(det_model.state_dict(), f"wan2._1.3B_t2v_det.safetensors")#确保lora权重已经合并到主模型中
#sem_model.blocks[0].attn1.to_q.weight-det_model.blocks[0].attn1.to_q.weight
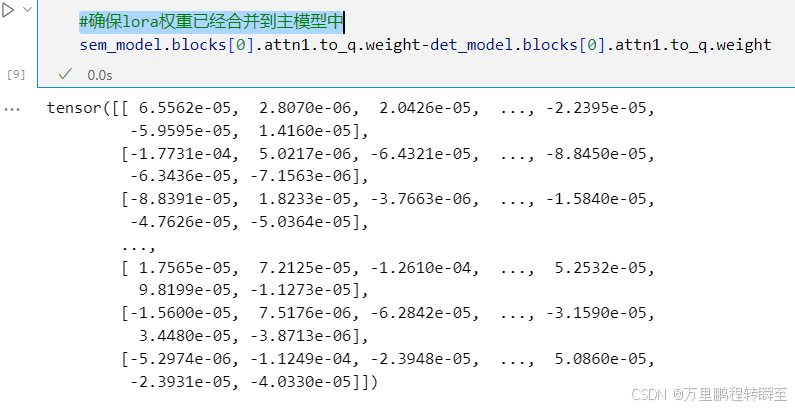
这里可以验证下lora权重是否加载到主模型中(sem的权重与det的权重此时应该是不一样的)
权重格式修改,以下代码可以将地方diffusers库的wan2.1 格式权重修改为WanVideo_comfy工作流支持的格式。
import torch
class WanModelStateDictConverter:def __init__(self):passdef from_diffusers(self, state_dict):rename_dict = {"blocks.0.attn1.norm_k.weight": "blocks.0.self_attn.norm_k.weight","blocks.0.attn1.norm_q.weight": "blocks.0.self_attn.norm_q.weight","blocks.0.attn1.to_k.bias": "blocks.0.self_attn.k.bias","blocks.0.attn1.to_k.weight": "blocks.0.self_attn.k.weight","blocks.0.attn1.to_out.0.bias": "blocks.0.self_attn.o.bias","blocks.0.attn1.to_out.0.weight": "blocks.0.self_attn.o.weight","blocks.0.attn1.to_q.bias": "blocks.0.self_attn.q.bias","blocks.0.attn1.to_q.weight": "blocks.0.self_attn.q.weight","blocks.0.attn1.to_v.bias": "blocks.0.self_attn.v.bias","blocks.0.attn1.to_v.weight": "blocks.0.self_attn.v.weight","blocks.0.attn2.norm_k.weight": "blocks.0.cross_attn.norm_k.weight","blocks.0.attn2.norm_q.weight": "blocks.0.cross_attn.norm_q.weight","blocks.0.attn2.to_k.bias": "blocks.0.cross_attn.k.bias","blocks.0.attn2.to_k.weight": "blocks.0.cross_attn.k.weight","blocks.0.attn2.to_out.0.bias": "blocks.0.cross_attn.o.bias","blocks.0.attn2.to_out.0.weight": "blocks.0.cross_attn.o.weight","blocks.0.attn2.to_q.bias": "blocks.0.cross_attn.q.bias","blocks.0.attn2.to_q.weight": "blocks.0.cross_attn.q.weight","blocks.0.attn2.to_v.bias": "blocks.0.cross_attn.v.bias","blocks.0.attn2.to_v.weight": "blocks.0.cross_attn.v.weight","blocks.0.ffn.net.0.proj.bias": "blocks.0.ffn.0.bias","blocks.0.ffn.net.0.proj.weight": "blocks.0.ffn.0.weight","blocks.0.ffn.net.2.bias": "blocks.0.ffn.2.bias","blocks.0.ffn.net.2.weight": "blocks.0.ffn.2.weight","blocks.0.norm2.bias": "blocks.0.norm3.bias","blocks.0.norm2.weight": "blocks.0.norm3.weight","blocks.0.scale_shift_table": "blocks.0.modulation","scale_shift_table": "head.modulation","patch_embedding.bias": "patch_embedding.bias","patch_embedding.weight": "patch_embedding.weight","condition_embedder.text_embedder.linear_1.bias": "text_embedding.0.bias","condition_embedder.text_embedder.linear_1.weight": "text_embedding.0.weight","condition_embedder.text_embedder.linear_2.bias": "text_embedding.2.bias","condition_embedder.text_embedder.linear_2.weight": "text_embedding.2.weight","condition_embedder.time_embedder.linear_1.bias": "time_embedding.0.bias","condition_embedder.time_embedder.linear_1.weight": "time_embedding.0.weight","condition_embedder.time_embedder.linear_2.bias": "time_embedding.2.bias","condition_embedder.time_embedder.linear_2.weight": "time_embedding.2.weight","condition_embedder.time_proj.bias": "time_projection.1.bias","condition_embedder.time_proj.weight": "time_projection.1.weight","proj_out.bias": "head.head.bias","proj_out.weight": "head.head.weight",}state_dict_ = {}for name, param in state_dict.items():if name in rename_dict:state_dict_[rename_dict[name]] = paramelse:name_ = ".".join(name.split(".")[:1] + ["0"] + name.split(".")[2:])if name_ in rename_dict:name_ = rename_dict[name_]name_ = ".".join(name_.split(".")[:1] + [name.split(".")[1]] + name_.split(".")[2:])state_dict_[name_] = paramreturn state_dict_from safetensors.torch import load_file,save_file
import ipdb
if __name__=="__main__":weight_path="wan2._1.3B_t2v_sem.safetensors"w=load_file(weight_path)convert=WanModelStateDictConverter()new_weight=convert.from_diffusers(w)save_file(new_weight, weight_path.replace(".safetensors","_convert.safetensors"))weight_path="wan2._1.3B_t2v_det.safetensors"w=load_file(weight_path)convert=WanModelStateDictConverter()new_weight=convert.from_diffusers(w)save_file(new_weight, weight_path.replace(".safetensors","_convert.safetensors"))#"blocks.0.attn1.to_k.weight": "blocks.0.self_attn.k.weight"
5、comfyui工作流
工作流地址:
https://gitcode.com/a486259/mbjc/blob/main/wan2.1_1.3b_dcm_t2v.json
同时需要到:https://www.modelscope.cn/models/Kijai/WanVideo_comfy/files 下载vae、t5(文本编码器)、clip模型
工作流基于wan2.1 i2v kj工作流改造,sem相当于原来的low模型,det相当于原来的high模型。但是由于推理时的scheduler无法指定为官方代码里面的InferencePCMFMScheduler,故推理效果存在偏差。
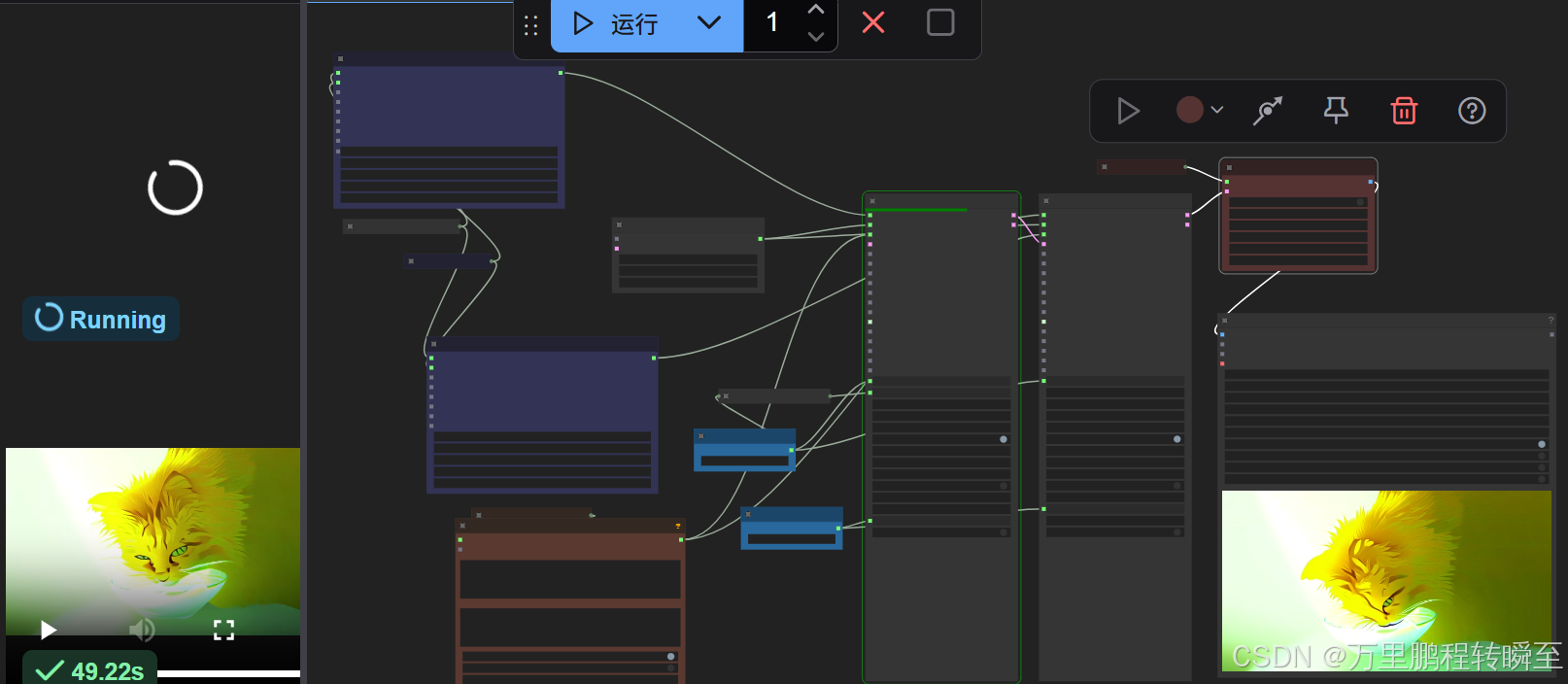
提示词:In a futuristic setting, Iron Man, clad in his iconic red and gold armor,
stands on a neon-lit stage, gripping a sleek, high-tech electronic guitar. As
he strums the guitar, sparks fly, and holographic musical notes float around
him, creating a mesmerizing visual symphony. His helmet’s eyes glow
intensely, syncing with the rhythm of the electrifying music

提示词:A graceful individual, dressed in a flowing shirt and black leggings,
stands in a serene, sunlit room with wooden floors and large windows. She
begin to bend slowly, her movements fluid and controlled. The sunlight
filters through the windows, casting a warm glow on their form. The room’s
minimalist decor, with a few potted plants and a yoga mat
