蓝耘智算与DeepSeekR1:低成本高能AI模型

一、前言
在这个AI大模型盛行的时代,deepseek凭借其出色的深度思考能力,强大的推演能力,模型训练以及更少的资金培养横空出世,是近期爆火的开源大模型。然而,随着用户需求的增长,DeepSeek在大数据和高频访问的场景下经常面临服务器不稳定的问题。
当前Deepseek平台使用的弊端:
1. 技术局限性
事实性错误与“幻觉”:DeepSeek 和其他大语言模型一样,存在“AI 幻觉”(AI Hallucination),即可能会生成看似合理但事实上不准确或完全错误的信息。
多轮对话与上下文理解不足:它的长程记忆和多轮对话能力较弱。在对话轮次较多(如超过3轮)后,可能出现逻辑断裂、答非所问或完全偏离初始需求的情况,这降低了复杂任务中的连续交互体验。
专业领域适配性欠佳:在金融、医疗等高风险、高专业度领域,DeepSeek 的表现可能不尽如人意。
代码与数据精度问题:尽管DeepSeek在代码生成方面有一定能力,但此前版本(如V3.1)被曝出存在特定字符错误(如异常插入“极”字)的严重bug,官方曾建议立即停止在编码或数据精度要求高的场景使用。
2. 服务稳定性问题
服务器频繁宕机与不稳定:DeepSeek 曾多次出现服务器崩溃、API接口和网页端无法访问的情况。例如在2025年8月,其服务曾深夜瘫痪3小时,导致用户对话中断。这与其底层架构在高并发请求下的处理能力不足有关。
甚至在面临多用户的高频访问时,会出现“服务器繁忙,请稍后再试”的字样,对用户造成了不佳体验。
响应延迟与体验下降:在访问高峰期,用户经常遇到响应速度极慢、需要多次重试的情况,严重影响使用体验和工作效率。

3. 安全与隐私风险
-
数据泄露事件:DeepSeek 曾因云数据库错误配置,导致超过百万条包含系统日志、API密钥和用户聊天记录等敏感信息可被公开访问,暴露了其数据安全管理上的漏洞。
-
隐私收集与数据跨境风险:根据其隐私政策,DeepSeek 会收集用户的文本/语音输入、上传的文件和聊天记录,并将这些数据存储在中国境内的服务器上。这引发了对于数据跨境流动以及特定国家政府可能通过互动记录进行“思想捕捉与资讯诱导”的担忧。
因此,本文通过使用蓝耘智算搭建DeepSeek R1模型 以充分发挥DeepSeek的性能和稳定性。
二、DeepSeek R1 的核心优势
1.强大的复杂推理能力:
-
在数学(AIME 2025 87.5% 准确率)、编程(LiveCodeBench 接近 o3 水平) 和 复杂逻辑推理 任务上表现优异。
-
在高难度推理(如研究生级别数学题)上,甚至比 OpenAI o1 更快且更准确
2.极低的训练成本:
- DeepSeek R1的训练成本仅 29.4万美元,而竞争对手的训练成本可能高达数千万美元,使得 R1成为一个非常成本高效的模型。
3.幻觉大幅降低:
-
相较于旧版,R1在改写润色、总结摘要、阅读理解等场景中的幻觉率降低了45-50%,提供更可靠的结果。
4.自我进化与泛化能力:
-
采用纯强化学习(RL)训练,不依赖监督微调(SFT),使得模型可以自主提升推理能力,并在多个领域展现强大的泛化性能。
5.开源和可访问性:
-
完全开源(权重、训练方法、推理代码全部公开),吸引了大量研究者与开发者,在Hugging Face下载量超过1090万次。
DeepSeek R1 与其他模型的对比
| 对比维度 | DeepSeek R1 | OpenAI o1系列 | Google Gemini 2.5 Pro | DeepSeek V3 |
|---|---|---|---|---|
| 推理能力 | 极强(数学87.5%、编程接近o3) | 优秀(STEM、代码) | 强(多模态、长文本理解) | 较强(通用语言理解,推理能力不及R1) |
| 训练成本 | 极低(29.4万美元) | 极高 | 较高 | 较高 |
| 推理速度 | 较快 | 较慢 | 中等 | 较快 |
| 适用场景 | 数学、编程、复杂逻辑推理 | 通用推理、STEM | 多模态理解、长文档处理 | 通用任务、长文本处理 |
三、蓝耘智算平台是什么
蓝耘智算平台是北京蓝耘科技股份有限公司(简称蓝耘科技)推出的一款专注于提供智能算力(特别是GPU算力)云服务的平台。它致力于为人工智能(AI)训练、推理、科学计算、图形处理等计算密集型任务提供高性能、灵活易用且可按需获取的算力资源。
| 模块名称 | 核心功能 | 主要特点 |
|---|---|---|
| 智算算力调度 | 负责底层算力资源的统一管理、调度和分配。 | 支持裸金属调度(用户自主性强)和容器调度(敏捷高效) |
| 应用市场 | 提供预置的行业应用软件、主流AI框架、工具链和部分优化后的模型环境,减少用户环境配置的麻烦。 | 开箱即用,提升开发效率 |
| AI协作开发 | 为AI开发团队提供覆盖代码开发、模型训练、推理部署的全流程工具链和协作环境。 | 支持协同编码、资源共享和项目协同管理 |
通过蓝耘智算平台搭建DeepSeek-R1模型的优势:
-
算力支持:为DeepSeek的AI模型训练提供高性能计算资源。
-
技术融合:结合蓝耘的算力优化技术与DeepSeek的AI算法,提升模型效率。
-
行业解决方案:共同开发面向金融、医疗、教育等行业的AI应用。
四、使用蓝耘智算使用DeepSeek R1模型
首先我们需要通过https://console.lanyun.net/#/register注册
填写好我们的相关信息我们就能进行注册的操作
注册成功后,可以在此平台看到应用云,进行点击

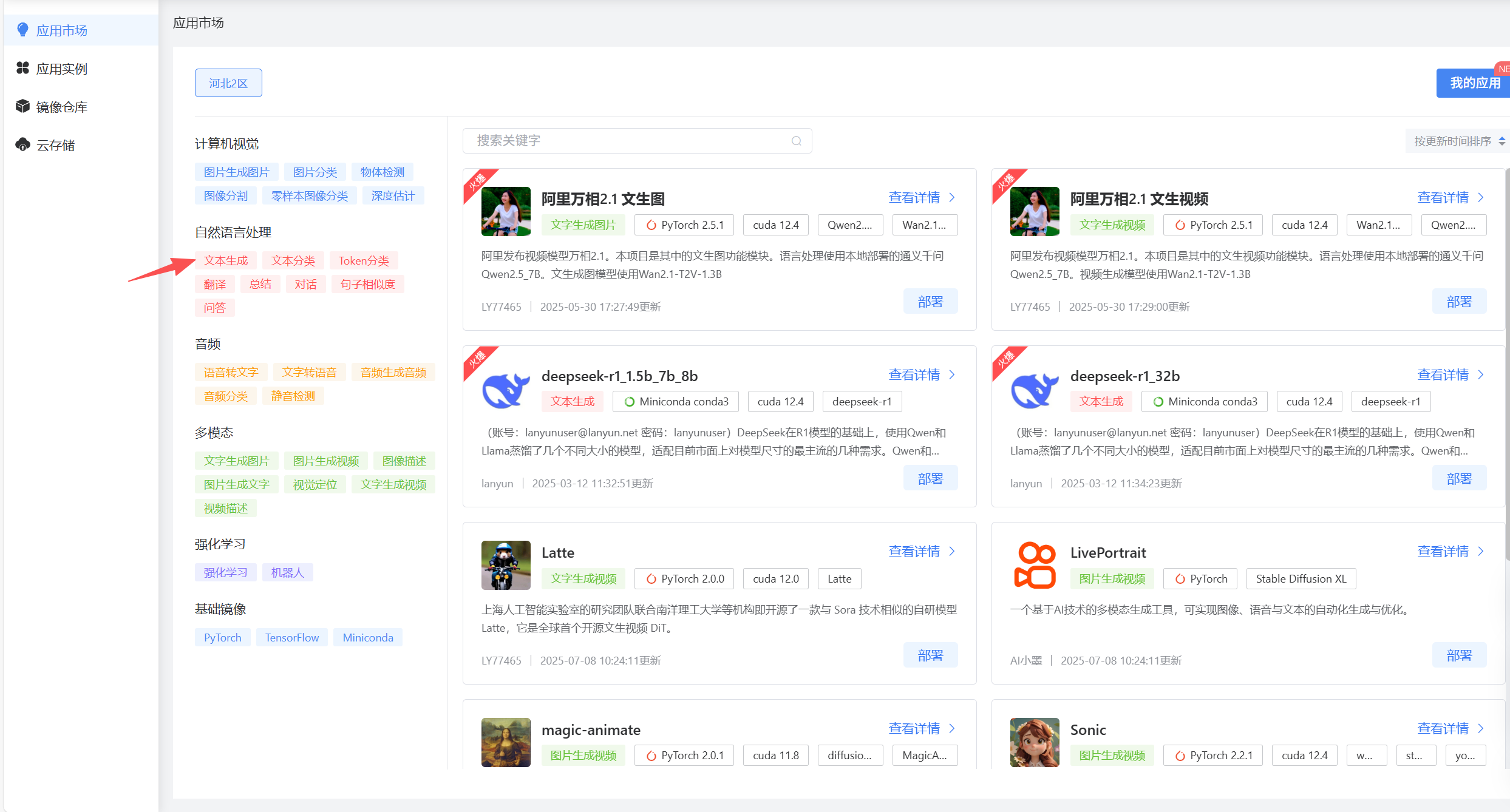
进入应用云后,就能看到DeepSeek-R1模型的部署,蓝耘平台将应用又分成了多个板块:计算机视觉、自然语言处理、音频、多模态、强化学习、基础镜像。
接着点击自然语言处理模块中的文本生成,即可筛选出我们本次要部署的deepseek-r1_1.5b_7b_8b模型。
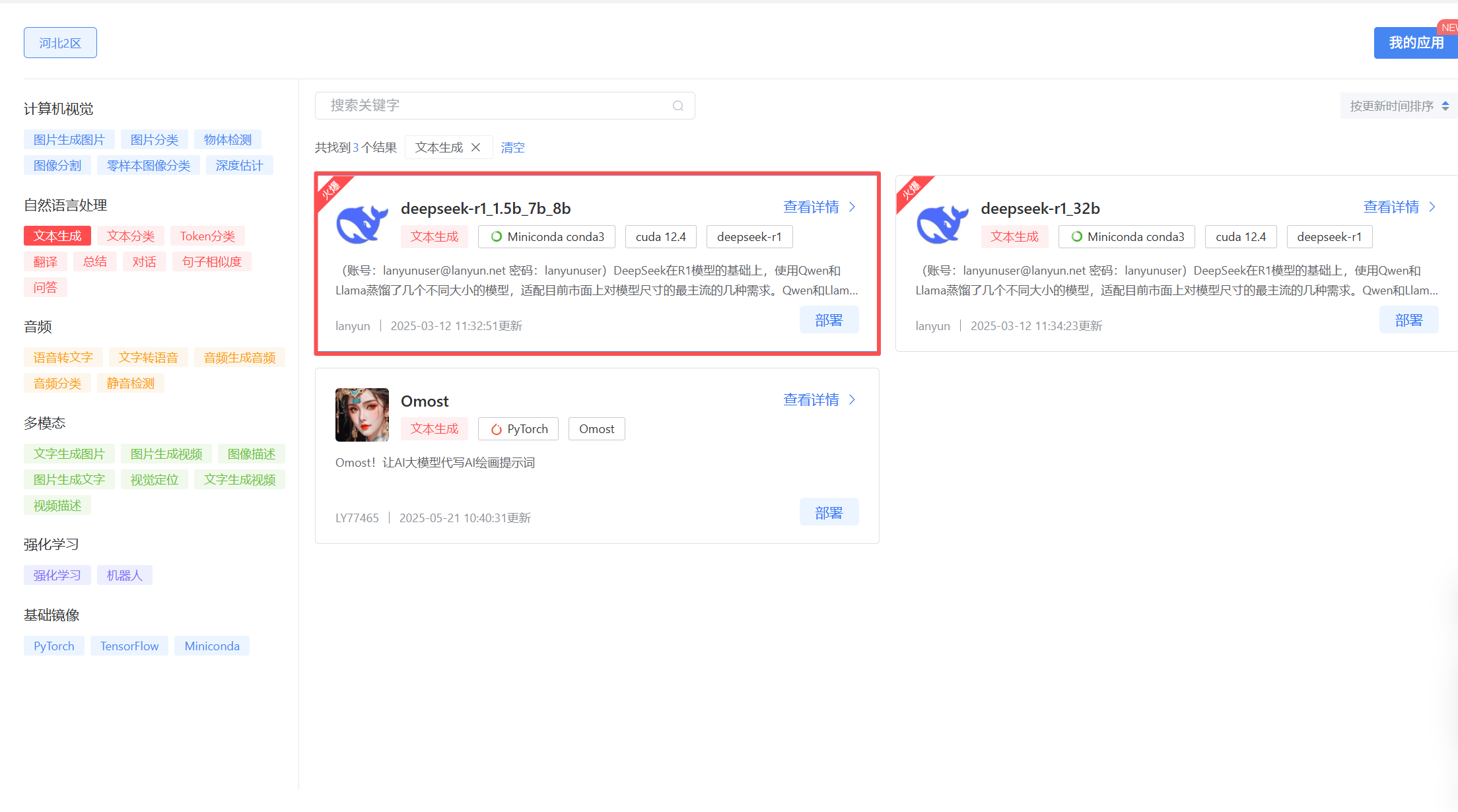
点击部署。
应用介绍:DeepSeek在R1模型的基础上,使用Qwen和Llama蒸馏了几个不同大小的模型,适配目前市面上对模型尺寸的最主流的几种需求。Qwen和Llama系列模型架构相对简洁,并提供了高效的权重参数管理机制,适合在大模型上执行高效的推理能力蒸馏。蒸馏的过程中不需要对模型架构进行复杂修改 ,减少了开发成本。【默认账号:lanyunuser@lanyun.net 密码:lanyunuser】
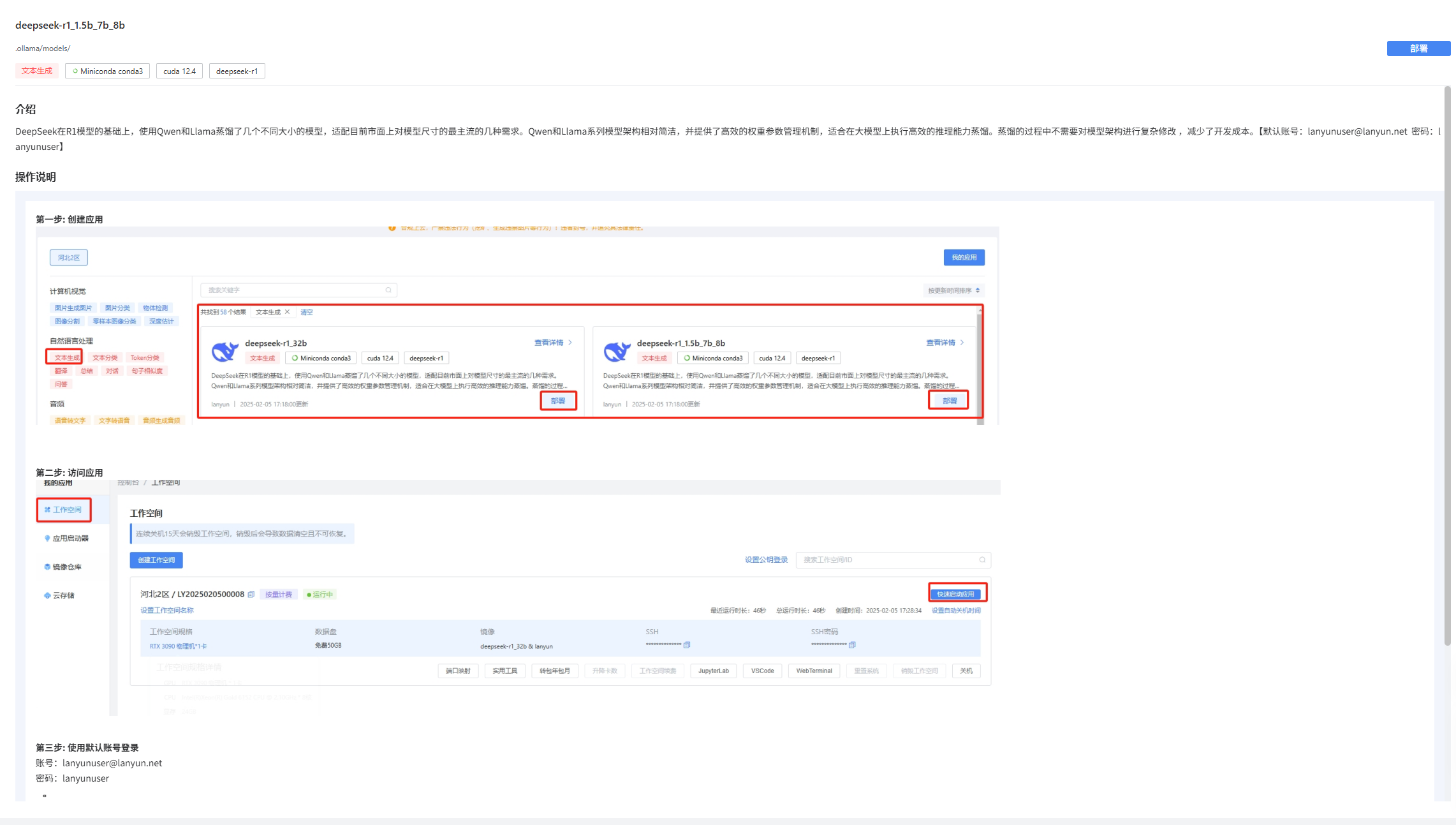
- 接下来进行部署操作,这里可以选择4090安装(同样适用非4090的电脑),按量计算,就是用多少算多少,可以降低用户成本以提高效率。
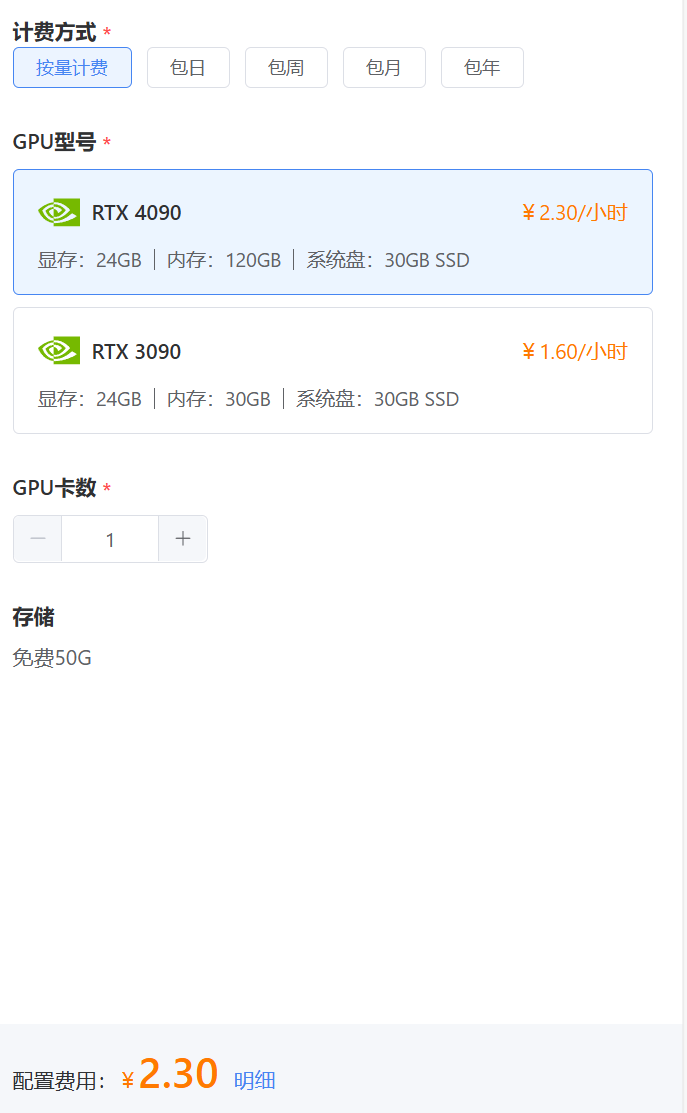
创建好便可使用我们的DeepSeek-R1模型
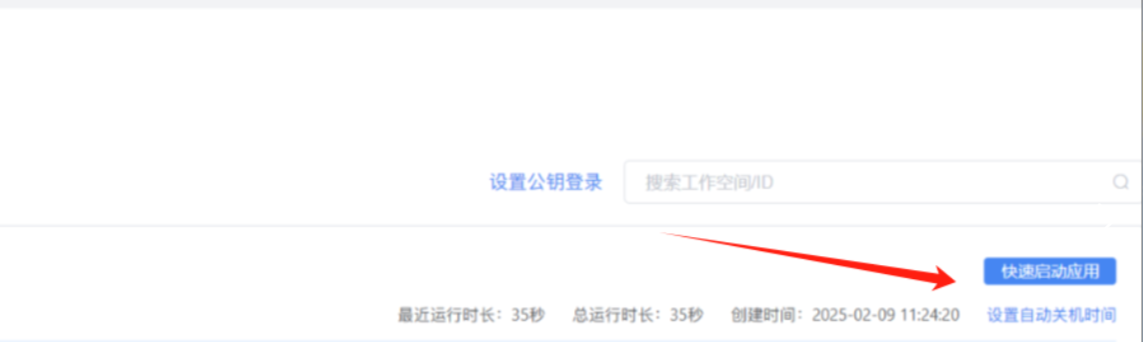
接下来就是登录
跟上面一样使用默认账号密码进行登录
默认账号:lanyunuser@lanyun.net 密码:lanyunuser
登录好了以后即可进入DeepSeek-R1模型的可视化界面
蓝耘智算平台在给我们降低使用成本的同时,也给我们使用该大模型效率带来了提高。
平台注册链接:https://console.lanyun.net/#/register