多模态知识图谱
摘要
背景:
知识图谱(KG)作为一种大规模语义网络,已广泛应用于文本理解、推荐系统、问答等任务。
现有的知识图谱大多基于符号化文本,缺乏与真实世界感知信息的连接。
问题:
单纯的符号表示(文字)不足以让机器真正理解实体或概念的含义。
需要将符号与真实世界的多模态信息(如图像、声音、视频)进行“符号落地”(grounding),才能更好地表达和理解。
动机:
多模态知识有助于改善许多任务,例如:
关系抽取:图像能帮助识别文本难以描述的关系(如 partOf、colorOf)。
文本生成:借助图像和MMKG,机器能生成更精确的实体级描述。
因此,随着应用需求增加,MMKG的研究和应用快速发展。
贡献:
本文是首个系统性综述MMKG(以文本+图像为主)的研究。
主要从两个方面进行总结:
构建:从图像到符号、以及从符号到图像的双向构建方式。
应用:分为 In-MMKG 应用(改善MMKG自身的质量与融合)和 Out-of-MMKG 应用(为多模态任务提供支持)。
论文目标是:
提供全面综述;
对方法优劣进行深入分析;
揭示未来研究的机会和方向。
引言
定义
回顾知识图谱(KG)的定义
传统KG是一个有向图,由实体、关系、属性及其对应的三元组组成。
三元组分为关系三元组 (s, p, o) 和属性三元组 (s, p, o)。
引入多模态知识图谱(MMKG)
MMKG是在传统KG的基础上,把部分符号知识与非文本模态(如图像、声音、视频)关联起来。
举例:一个关系三元组 (s, p, o) 可以配上一张描述关系的图像。
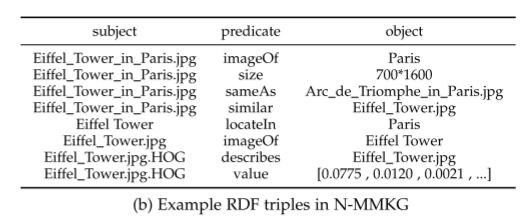
两种主要的MMKG表示方式
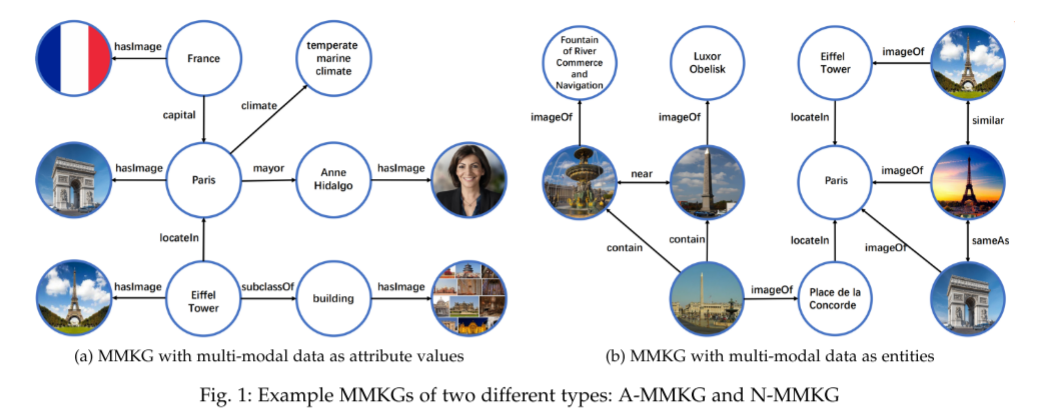

A-MMKG:把多模态数据当作实体的属性值(例如 “Eiffel Tower — hasImage — Eiffel Tower.jpg”)。
N-MMKG:把多模态数据本身当作新的实体,引入更多跨模态和模态内的关系(如 contain、nearBy、sameAs、similar),并且通常会用图像描述符(HOG、CLD等)来表示图像特征
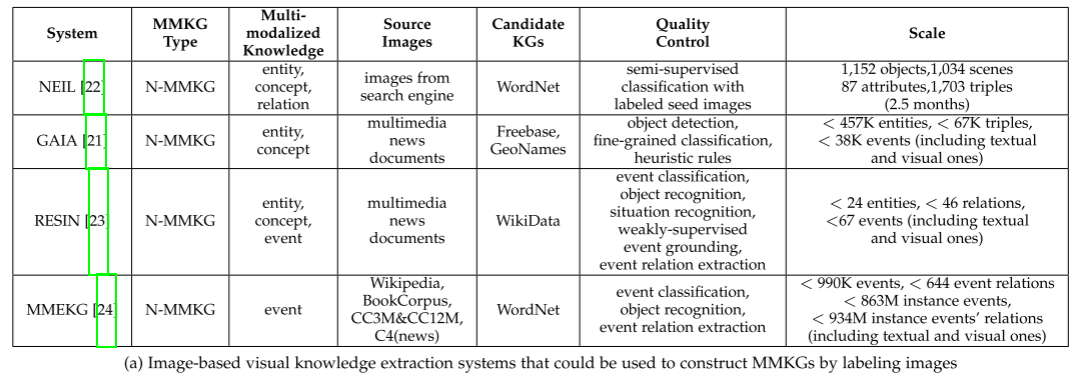
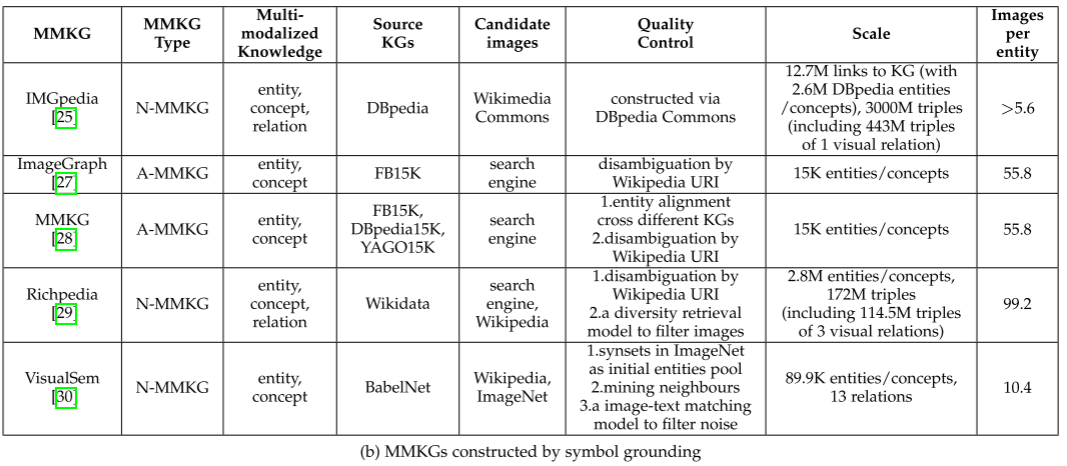
主流MMKG构建方法与代表性系统
基于视觉知识抽取:如 NEIL、GAIA、RESIN、MMEKG 等,主要通过图像识别和分类来获取视觉实体和关系。
基于符号对齐(symbol grounding):如 IMGpedia、ImageGraph、MMKG、Richpedia、VisualSem 等,通过将图像与已有KG中的实体对齐(例如来自维基百科、搜索引擎),并进一步考虑图像的多样性和实体的可视化性。
技术知识
多模态的定义
在计算机科学与AI中,如果一个问题涉及多种模态的数据(如图像 + 文本),就是多模态问题。
常见任务:图像描述 (image caption)、视觉问答 (VQA)、跨模态检索 (cross-modal retrieval)。
多模态学习(Multi-Modal Learning)的五大方向
表示(Representation):学习不同模态的特征表示,可以投射到统一空间或保持独立空间但满足某些约束。
翻译(Translation):从一种模态翻译到另一种模态(例:图像→文本)。
对齐(Alignment):找出模态之间的对应关系,可直接用于视觉定位、或作为预训练任务。
融合(Fusion):将多模态信息结合起来完成预测任务,常用注意力机制建模交互。
协同学习(Co-Learning):利用资源丰富的模态来弥补另一模态的低资源问题。
视觉-语言预训练模型(VL-PTMs)
近几年大型公司和研究机构(如 OpenAI、微软、华为)都在推动 VL-PTMs 的发展。
代表:CLIP(基于 4 亿图文对训练),显著提升了图像分类和跨模态检索性能。
VL-PTMs 的关键在于:
使用大规模图文数据 + 自监督预训练任务(如 MLM、图文对齐、遮掩预测)。
加入更细粒度的跨模态任务(如对象对齐、关系对齐)来增强跨模态理解。
讨论
背景
尽管已有很多多模态学习和 VL-PTMs 的研究,但引入 MMKG 仍是一个新趋势。
MMKG 能在多个方面增强多模态任务。
五大优势
丰富表示:提供充足的背景知识,尤其能增强长尾实体/概念的表示。
理解未见对象:通过符号知识帮助识别统计模型难以处理的新对象。
支持可解释推理:例如 OK-VQA,需要外部知识才能回答的问题,MMKG 能提供推理支持。
补充NLP任务特征:图像可辅助解决歧义(如判断“Rocky”是狗还是人名)。
补充VL-PTMs:VL-PTMs 学到的是隐式跨模态知识,而 MMKG 能提供显式、细粒度、长尾和背景知识。
总结
仅靠多模态数据或 VL-PTMs 的信息仍有限。
如果能利用大规模 MMKG,多模态任务的表现将得到进一步提升。
如何构建多模态知识图谱
MMKG 构建的本质:就是把传统知识图谱中的符号知识(实体、概念、关系等)与对应的图像关联起来。
两种主要方法:
从图像到符号:给图像打上来自知识图谱的标签;
从符号到图像:把知识图谱中的符号落地到对应的图像。
从图像到符号
核心思路
借助计算机视觉(CV)中的 图像标注技术,把图像和知识图谱中的结构化符号(概念、实体等)关联起来。
示例:NEIL 把图像链接到 WordNet,ImageSnippets 把图像链接到 DBpedia。
实现方式
图像标注模型通过学习图像内容与标签集(对象、场景、实体、属性、关系、事件等)的映射来完成任务。
训练依赖人工标注数据集(众包标注边界框、图像区域及标签),如图示例(Figure 2)。
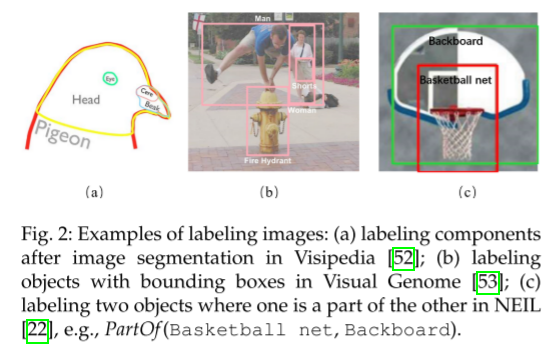
代表性系统
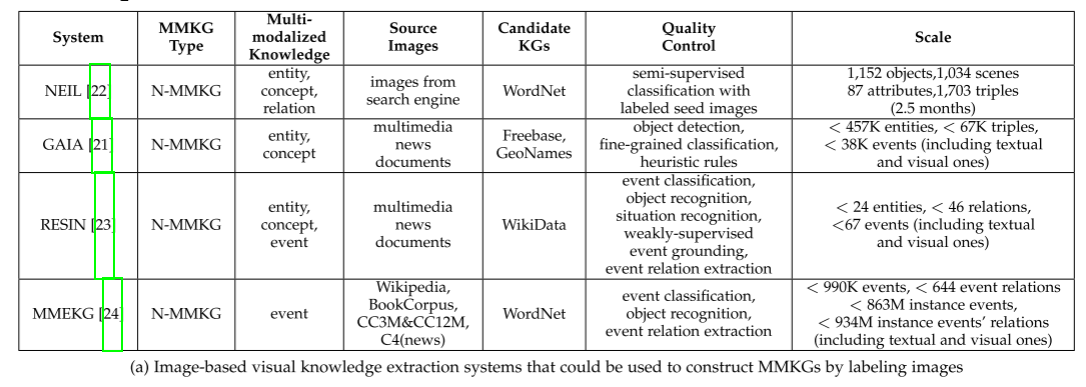
文中提到一些已有的图像视觉知识抽取系统(列在 Table 2(a)),可以作为 MMKG 构建的基础。
细分任务
将图像链接到符号的过程可拆分为:
视觉实体/概念抽取 (Sec. 3.1.1)
视觉关系抽取 (Sec. 3.1.2)
视觉事件抽取 (Sec. 3.1.3)
图像的实体抽取
任务定义
在图像中检测并定位目标视觉对象,并将其标注为知识图谱中的实体或概念符号。
挑战
需要大规模、细粒度且高质量的标注数据集,但现有图像数据大多是粗粒度的,难以满足 MMKG 构建需求。
现有进展
两类方法:
目标识别(Object Recognition)
通过检测器 + 分类器标注图像中的对象。
依赖人工标注数据集(如 MSCOCO、Flickr30k)。
问题:只能识别有限预定义类别,精度有限(如 GAIA 在 MSCOCO 上仅 43%)。
视觉对齐(Visual Grounding)
不依赖标注框,而是利用图文对(image-caption pairs)进行弱监督学习。
通过注意力或显著性方法定位图像区域,输出视觉实体/概念。
在 GAIA 上精度更高(约 69.2%),但存在语义尺度不一致的问题(如 troops 被映射成个体士兵)。

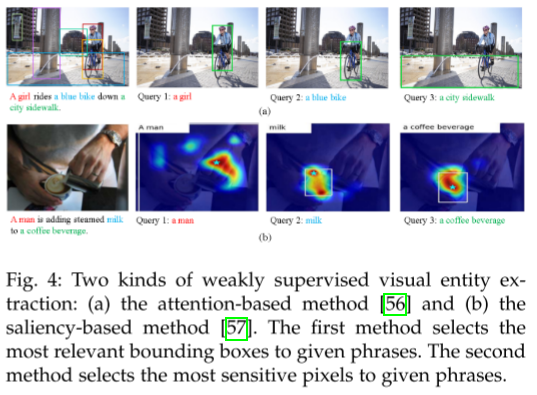
机会(Opportunities)
VL-PTMs 驱动的抽取:如 CLIP、ViLT 等大规模视觉-语言预训练模型,可以直接通过注意力映射识别实体,精度高。

分类体系扩展(Taxonomy Extension):
图像常有多级合理标签(如 Boy/Man/Person),需要结合层级词汇表(taxonomy)来选择最合适的语义层级,避免歧义。
总结:这一段主要讲了 视觉实体/概念抽取的定义、数据挑战、两类主流方法(目标识别 vs 视觉对齐)的优缺点,并指出未来可通过 VL-PTMs 和分类体系优化 来提升效果。
图像的关系抽取
1. 任务定义
目标:识别图像中视觉实体/概念之间的语义关系,并将其映射到知识图谱中的关系。
区别:CV 社区的视觉关系检测通常是表层的(如 (Person, standing on, Beach)),而 MMKG 构建需要更通用、更抽象的 KG 级关系(如 (Jack, spouse, Rose))。
2. 挑战
当前方法提取的多为场景关系,难以对齐到 KG 中更抽象的语义关系。
3. 现有进展
两类主要方法:
基于规则的方法
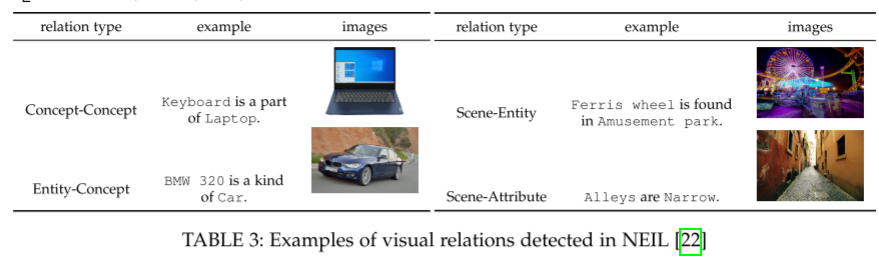
专注于空间关系、动作关系等,通过预定义规则和启发式特征判断关系。
优点:精度高(如 NEIL 系统平均检测精度 79%)。
缺点:需要大量人工规则,难以大规模应用。
基于统计的方法
将视觉、空间、统计特征编码为向量,利用分类模型预测关系。
借助语言先验(如 subject+predicate≈object,或用语言模型约束)来提高准确率,但视觉信息贡献较小。
结合图结构(GCN、图更新机制)提升推理效果。
现状:谓词检测的 recall@50 可达 85.6%,但三元组检测 recall@50 < 23%,性能有限。
长尾与细粒度关系抽取
问题:训练数据分布不均,模型偏向预测频繁关系。
解决方向:度量学习、迁移学习、少样本学习、对比学习,但仍局限于特征层融合。
细粒度关系(如 sit on / walk on / lay on)常被预测为粗粒度 on。
新方法:反事实因果推理(减少上下文偏差)、层级分类(由具体到泛化关系逐级预测)。
4. 机会(未来方向)
视觉知识关系判别:区分“图像场景信息”与“被广泛接受的知识”,避免把仅属于某一图像的关系当作普遍知识。
基于推理的关系检测:不仅依赖特征融合,而是利用推理链进行显式预测。例如根据身体部位动作推理 (Person, kick, Football)。
难点:现有方法多依赖人工构建数据集,需要自动化总结推理链。
图像事件抽取
1. 任务定义
事件包括:触发词(trigger) + 论元(arguments)及其角色(roles)。
子任务:
预测事件类型;
定位并抽取事件论元(对象/概念)及其角色。
与 情境识别(situation recognition) 不同:后者只识别事件类别,不抽取论元。
2. 挑战
事件类型需要预定义 schema,但实际存在大量未定义的视觉事件 → 如何自动挖掘事件模式?
如何从图像或视频中抽取事件的论元?
3. 现有进展
(1) 视觉事件 Schema 挖掘
借助大规模图像-文本对,利用触发词检索事件相关图像 → 候选图像区域通过视觉定位标注。
使用频繁项集挖掘(如 Apriori)找到高频视觉模式,自动生成事件 schema。
可以修正人工 schema 的缺漏(如 Attack 事件中,实际数据里 Smoke、Police 更常见)。
(2) 视觉事件论元抽取
根据图像全局特征分类事件类型,再通过目标识别或视觉定位抽取论元。
MMEKG 在实例级评估中,视觉事件与跨模态三元组的精度约为 64%。
需要保证视觉论元与文本论元在关系上对齐(如对齐情境图 situation graph 与 AMR 图)。
视频比图片更适合事件抽取:事件往往跨越多个帧。已有方法简化为从关键帧抽取论元。
4. 机会(未来方向)
长视频中的序列事件抽取:如何从包含多个事件的长视频中分割并提取事件。
复杂事件的子事件分解:如 Making Coffee → 一系列子事件(清洗机器、放咖啡豆、开启机器),需要时间轴化的顺序抽取。
符号到图像
核心概念
符号落地(Symbol Grounding):将知识图谱中的符号(实体、概念或关系三元组)与合适的多模态数据(如图像)对应起来。
现有成果
一些典型通过符号落地构建的 MMKG 已列在 Table 2(b)。
子任务划分
符号落地过程可细分为三个任务:
实体落地(Entity Grounding)
概念落地(Concept Grounding)
关系落地(Relation Grounding)
实体落地
1. 任务定义
将知识图谱中的实体与其对应的多模态数据(主要是图像,有时也包括视频和音频)关联起来。
2. 挑战
如何低成本地找到足够多的高质量图像?
如何从大量候选图像中选择最匹配实体的图像?
3. 现有方法
两大图像来源:
在线百科(如 Wikipedia/DBpedia)
优点:容易获取初步大规模 MMKG。
缺点:
很多实体没有图像(仅 6.7% 实体有 ≥3 张图像,79.35% 没有图像)。
图像质量和相关性参差不齐(非视觉化实体可能引入误图)。
覆盖率有限。
搜索引擎
优点:覆盖率高,可通过关键词查询获取大量图像。
缺点:容易引入噪声,需要消歧(如 “Bank” 会同时返回河岸和银行)。
解决策略:扩展查询词(父类词或实体类型)、图像多样性检索模型去重、选择最相关的图像。
综合方法

通常结合百科和搜索引擎两种方法,既保证质量又提高覆盖率。
实体与视觉特征解耦,可区分视觉相似的实体,便于构建细粒度或领域定向的 MMKG(如电影、产品、军事领域)。
4. 机会(未来方向)
典型图像选择:每个实体有多张图像,如何确定最能代表实体的子集?
多上下文多重落地(Multiple Grounding):实体在不同上下文下需要关联不同图像(如 Donald Trump 在不同事件或时期的照片)。
文本-图像检索:如果有大规模图文语料,可将实体落地转化为文本-图像检索问题(如电商领域的应用)。
概念落地
1. 任务定义
将知识图谱中的概念(Concept)与代表性的、多样化的、可区分的图像关联起来。
与实体落地不同,概念落地面对的是更抽象、更广泛的类别(如“Princess”“Happiness”)。
2. 挑战
并非所有概念都可视化(如“irreligionist”难以对应具体图像)。
如何从多样化的图像中选出最具代表性和区分性的图像?
例如,“Princess”可能有迪士尼公主、历史公主、现代公主等不同图像。
3. 现有方法
研究主要分为三个任务:
可视化概念判断(Visualization Concept Judgment)
自动判断哪些概念可视觉化。
方法包括:基于语法/语义的判断、搜索引擎图片数量或相似性、手动标注等。
挑战:抽象概念仍难准确判断。
代表性图像选择(Representative Image Selection)
从候选图像中挑选最具代表性和可区分性的图像。
方法包括:
聚类方法(K-means、谱聚类),选择类内方差小的图像。
结合语义信息(图像标签、标题)进行重排和区分。
图像多样化(Image Diversification)
确保所选图像在多样性和相关性上平衡。
方法包括:
基于多样性分数和相关性分数的排序(Max-Min 方法)。
图算法(动态规划、马尔可夫随机游走)寻找最优图像序列。
目标:覆盖尽可能多的不同视觉子类或主题。
4. 未来研究机会
抽象概念落地(Abstract Concept Grounding)

情感或抽象概念(如 Happiness、Anger、Love、Beauty)可以通过固定视觉符号或词语聚类表示。
动名词概念落地(Gerunds Concept Grounding)
如 dancing、wrestling,可通过身体姿态、表情、关节位置等特征关联图像。
通过实体间接落地不可视化概念(Non-visualizable Concept via Entity Grounding)
对于不可直接视觉化的概念,可通过其典型实体的图像间接表示(如用 Einstein 的照片表示 Physicist)。
面临的问题:
典型实体的主观性差异。
如何选择多实体图像总结概念。
是否抽象多实体图像的共性视觉特征。
关系落地
1. 任务定义
将知识图谱中的关系(Relation)与能够体现该关系的图像关联起来。
输入:一个或多个三元组(subject, relation, object);
输出:与关系语义最相关的图像(例如,将
(Justin Bieber, couple, Selena Gomez)对应到“亲吻”的图像,而不是“健身”场景)。
2. 挑战
图像检索时,顶端结果通常偏向与三元组的主体或客体相关,而非反映关系本身。
如何找到真正能体现语义关系的图像,而不仅仅是包含主体或客体?
3. 现有方法
基于共现的方法
假设如果在 Wikipedia 描述中两实体存在某关系,那么它们的视觉对象也存在该关系。
局限:现实中两个对象未必同时出现在一张图像中,或者图像中呈现的关系可能不是预期的。
图结构匹配方法
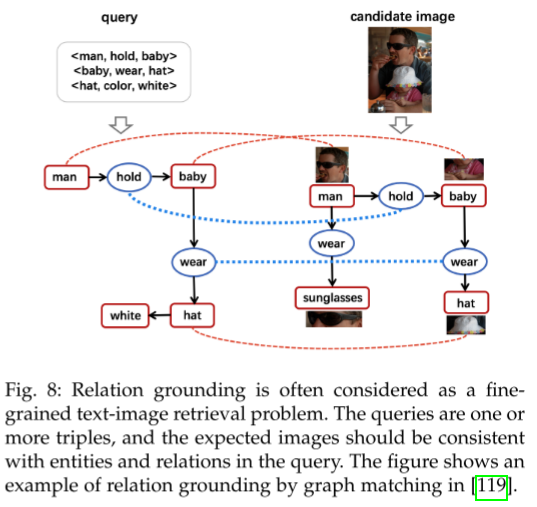
将关系三元组作为查询,将图像表示为多
(subject, predicate, object)组合的场景图(scene graph)。使用多分支 CNN 或 GCN 提取图像的结构特征。
通过对象节点与关系节点的匹配计算文本三元组与图像的相似度,实现细粒度匹配。
细粒度文本-图像检索
相比全局跨模态嵌入匹配,更注重对象与关系的逐项匹配(item-by-item matching)。
可以将文本和图像都表示为图,然后做图匹配。
4. 未来机会
目前主要关注可视化的空间关系和动作关系(如 leftOf、on、ride、eat)。
大多数语义关系(如 isA、Occupation、Team、Spouse)在图像中不易直接观察,缺乏训练数据,难以检索对应图像。
有潜力利用一些结合文本实体与视觉关系的数据集来辅助训练。
两种方式比较
1. 适用场景 (Applicable Scenarios)
图像标注方式更适合:当多模态数据是核心知识时,例如:
甲骨文识别系统中的甲骨照片
教学服务中的课堂音频
深度视频理解任务中的电影视频
符号落地方式更适合:当多模态数据冗余或噪声多时,可以依赖已有的精炼符号来匹配图像,例如:
电影本体在推荐系统
电商对话系统的产品本体
学术信息检索中的论文本体
“第一公民”取决于知识需求:想分析论文与地图关系,论文是第一公民;想分析地图与地图中区域关系,地图是第一公民。
2. 效率 (Efficiency)
符号落地:通常是基于检索的方法,效率高,适合从零开始构建 MMKG。
图像标注:通常依赖分类和检测方法,提取实体、概念和关系耗时较长。
例:NEIL 先用 NELL 本体检索图片,再提取图像中的对象和关系。
3. 质量 (Quality)
图像标注问题:粗粒度标注、语义层次不合理。
符号落地问题:缺失或错误匹配图像,尤其是长尾实体可能没有合适图像。
总体:符号落地在语义精度上更优,但图像覆盖仍可能不完全。
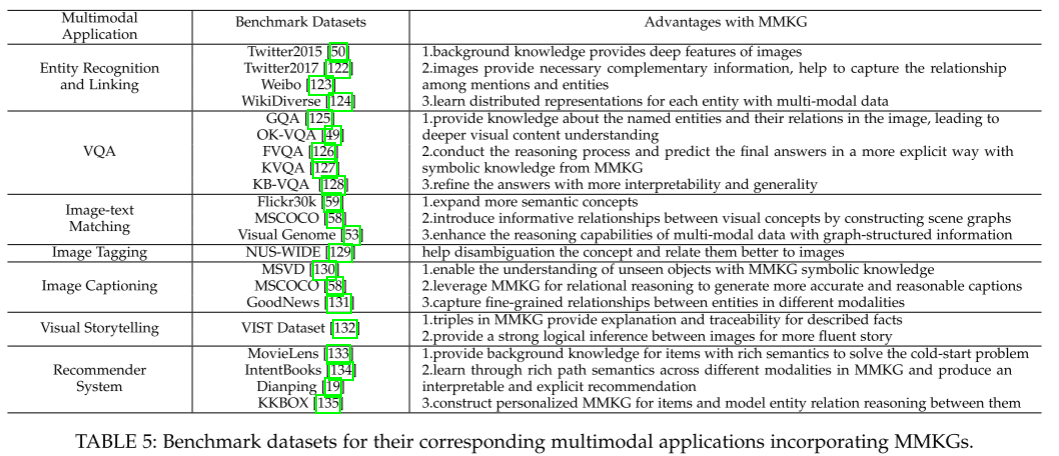
应用
概览:表格列出了主流应用任务、对应的基准数据集以及 MMKG 带来的好处。
分类:将应用分为三类:
KG 内部应用 (in-KG applications)
KG 外部应用 (out-of-KG applications)
特定领域应用 (domain applications)
多模态知识图谱内部应用
定义:In-MMKG 应用是指在 MMKG 内部进行的任务,此时实体、概念和关系的嵌入已经被学习好。
嵌入基础:介绍了 MMKG 嵌入(embedding)的来源和方法:
基于语义匹配的模型:如 RESCAL,通过向量空间计算三元组的存在可能性。
基于平移距离的模型:如 TransE,假设
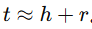
多模态处理问题:
视觉编码器:用 CNN 或 Transformer 提取图像的隐藏特征作为视觉嵌入,传统显式特征(如 GHD、HOG、CLD)难以利用。
知识融合:可通过向量拼接、平均池化、SVD/PCA 等方法组合不同模态,或将不同模态投影到统一空间进一步学习统一嵌入。
后续任务:引入四类典型的 In-MMKG 应用:
链接预测(link prediction)
三元组分类(triple classification)
实体分类(entity classification)
实体对齐(entity alignment)
链接预测
任务定义:
预测三元组 (h, r, t) 中缺失的实体或关系,例如 (?, r, t)、(h, r, ?) 或 (h, ?, t)。
与传统 KG 相似,通常通过对候选实体或关系进行打分和排序来完成。
MMKG 的特点:
在 MMKG 中,实体和关系的嵌入融合了图像等多模态信息,从而提供额外的视觉知识。
例如,一个人的图像可以提供年龄、职业或头衔等信息,丰富实体表示。
方法和应用:
IMAGEgraph:处理“视觉-关系查询”,可预测未见过图像之间的关系,实现零样本(zero-shot)关系预测。
MMKG 数据集:通过多模态(数值+图像)信息进行 sameAs 链接预测,验证多模态信息对任务的互补性。
三元组分类
任务定义:
判断一个三元组 (h, r, t) 是正确的还是错误的,即区分正三元组和负三元组。
可视为知识图谱补全(KG completion)的一种形式。
方法:
利用在 MMKG 上学习到的嵌入模型,计算每个三元组的能量分数 E(h,r,t)。
为每种关系 r 设定阈值 δr,如果能量分数高于 δr,则预测该三元组为负样本。
训练时通过替换三元组中的 h、r 或 t 来生成负样本,用于模型学习。
实体分类
实体分类的定义
将知识图谱中的实体(Entity)划分到不同的语义类别(concepts)。
可以视为一种特殊的链接预测任务:关系为 IsA,尾实体是一个概念。
传统方法与局限
传统知识图谱(KG)中有很多实体分类模型,这些模型可以用于 MMKG。
但是,多模态知识图谱(MMKG)中实体和概念包含丰富的多模态信息(如文本、图像、音频等),如果没有好的 MMKG 嵌入模型,这些信息难以充分利用。
多模态嵌入模型
一些工作尝试从多种模态中学习实体和概念的嵌入,然后映射到统一的表示空间(joint representation space)。
但纯粹的节点嵌入方法可能不足以解决 MMKG 的任务,需要同时考虑图结构信息。
评测基准
[140] 提出了一套高质量、多模态的基准数据集,用于精确评估 MMKG 上的节点分类(node classification)任务。
实体对齐
实体对齐的定义与目的
实体对齐旨在将不同 MMKG 中表示同一现实世界实体的节点对应起来。
当两个 MMKG 存在重叠时,实体对齐可以将它们整合成一个统一的图谱。
核心方法
学习不同知识图谱中实体的表示(embedding),然后计算跨图谱实体对的相似度。
传统 KG 的实体嵌入特征:
图内上下文信息:如 OWL 属性语义、邻居节点共现、属性值兼容性
外部信息:如外部词典、维基百科链接
多模态知识图谱(MMKG)中的扩展
引入了多模态特征(图像、文本等),需要专门的 MMKG 实体对齐嵌入模型。
方法包括:
分别编码不同模态的特征向量,然后通过知识融合技术合并为实体最终表示。
[156] 使用 ranking loss 训练嵌入。
[157] 设计了一个多模态互补损失函数:
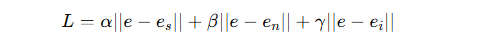
其中
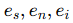 分别是三种模态的嵌入,eee 是实体的最终嵌入,
分别是三种模态的嵌入,eee 是实体的最终嵌入,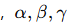 是权重超参数。
是权重超参数。
另一种方法:Product of Experts (PoE)
用于处理跨图谱的查询(如
(h?, sameAs, t)或(h, sameAs, t?))。将视觉特征整合进端到端学习框架,比简单拼接或集成方法效果更好。
外部应用
多模态实体识别和连接
Out-of-KG 应用的定义
指那些不局限于知识图谱内部,而是可以借助 MMKG 提升效果的下游任务。
本段重点关注 如何利用 MMKG 以及它相比其他方法的优势。
多模态实体识别(MNER)
传统 NER 只使用文本,但实体提及存在歧义和多样性问题。
MNER 利用文本和图像,图像提供补充信息来辅助识别。
MMKG 的优势:
提供实体的视觉特征,增强文本或图像表示。
利用实体的两跳邻居或图像信息进行消歧。
提供更多标签或相关词,提高跨模态交互效果。
多模态实体链接(MEL)
将文本中歧义的实体提及映射到知识图谱中的实体。
MMKG 的使用方式:
提供目标实体候选集合。
学习多模态分布式表示,计算提及与实体之间的相关性。
面临的挑战:
图像中的无关信息可能引入噪声,影响表示学习。
解决方法:
两阶段图文相关性机制过滤无关图像。
多头注意力机制捕捉关键特征,通过查询候选实体的多跳邻居增强表示。
视觉问答
VQA 的挑战
需要对问题进行准确语义解析,并理解图像中不同对象和场景之间的关系。
很多 VQA 数据集(如 GQA、OK-VQA、KVQA)的问题需要结合 视觉信息和外部知识 进行推理。
例如,“图中的毛绒玩具对应哪位美国总统?”需要先识别“Teddy Bear”,再通过知识图谱推理出“Theodore Roosevelt”。
MMKG 在 VQA 中的三大作用
提供外部知识:关于图像中实体及其关系的信息,帮助理解视觉内容。
辅助答案推理:将图像实体和问题中的文本实体与 MMKG 中的事实结合,重新加权答案,通过统一的多模态表示(图像、问题、结构化知识)增强推理能力。
图结构表示与显式推理:将 MMKG 中的多模态实体和关系三元组表示为异构图的节点和边,便于使用启发式规则、SPARQL 查询或图神经网络(GNN)进行推理。
MMKG 构建与应用示例
MMKG 可通过结合现有知识图谱和标注图像数据集构建。
例如,[51] 中的显式知识来源包括:
hasPart 三元组(hasPart KB)
hasPart/isA 三元组(DBpedia)
常识三元组(ConceptNet)
视觉对象的位置信息(Visual Genome)
将 MMKG 的显式知识与视觉语言预训练模型(VL-PTMs)的隐式知识结合,能显著优于仅使用 VL-PTMs 的方法,而且两者知识大多不重叠。
图文匹配
图文匹配任务概述
任务目标:计算输入图像与文本对之间的语义相似度,用于图文检索或文本图像检索。
一般方法:将图像和文本映射到一个 联合语义空间,学习统一的多模态表示,再进行相似度计算。
传统方法:利用多标签检测模块提取图像语义概念,并与全局上下文融合。
问题:预训练的检测模型难以发现长尾概念,导致表示受限,性能下降。
MMKG 的作用
扩展视觉与语义概念:利用多模态实体间关系补充检测模型难以捕捉的长尾概念。
构建场景图(Scene Graphs):通过 MMKG 中频繁共现的概念对(如 house-window, tree-leaf)增强图像概念表示,提供语义上下文信号。
对齐跨模态表示:利用图结构信息表示图像和文本的高层语义,有助于本地和全局特征对齐,提高推理和解释能力。
统一多模态表示:MMKG 提供的结构化知识帮助图像和文本学习更一致的多模态表示,增强匹配精度。
多模态生成任务
图像标注(Image Tagging)
问题:传统方法受限于标签分布偏差、噪声和不准确标签。
MMKG 的优势:
提供结构化概念层级(同义词、上位词、下位词等)。
提供概念对应的代表性和区分性图像。
通过 MMKG 可生成更精确的候选标签并减少歧义,优于 ConceptNet、WebChild、ImageNet 等方法。
图像描述(Image Captioning)
问题:
过度依赖目标检测器,导致对象/关系和文本描述语义不一致。
无法描述未见过的新对象或概念。
MMKG 的优势:
利用语义图进行关系推理,使生成的描述更准确合理。
利用符号化知识理解未见对象,通过多标签分类器将视觉对象与知识库实体关联,扩展图像表示。
命名实体感知图像描述(Entity-aware Image Captioning)
MMKG 可实现跨模态对齐,将文本中的命名实体与图像中的视觉对象匹配,提高描述的精确性和信息量。
利用结构化知识显著提升 BLEU、METEOR、ROUGE、CIDEr 和实体 F1 分数。
视觉故事讲述(Visual Storytelling)
问题:传统方法把任务当作顺序图像描述,忽略图像间关系,故事单调,且受限于单一训练数据集的知识。
MMKG 的优势:
通过 distill-enrich-generate 三阶段框架,将连续图像的词汇与 MMKG 查询匹配,丰富语义三元组。
利用图谱关系进行逻辑推理,使生成故事更连贯,效果优于不使用 KG 的方法。
多模态推荐系统
多模态推荐系统背景
目标:根据用户历史数据推荐用户可能喜欢的物品,同时兼顾准确性、新颖性、多样性和稳定性。
多模态场景:推荐系统中存在图像、文本等多种模态信息,需要联合利用这些信息。
MMKG 的作用
丰富物品表示:MMKG将不同模态的数据整合为层级结构,使物品表示更加丰富,从而解决协同过滤中的冷启动问题。
逻辑推理和可解释推荐:MMKG的图结构可用于设计基于层级的注意力路径(hierarchy-based attention path),减少动作空间,并聚焦于关键中间实体,从而生成更明确、可解释的推荐。
实验结果与优势
利用 MMKG 的结构化文本和视觉知识,能够显著提升推荐系统的推荐质量。
一般领域应用
一般领域应用
除了电影推荐系统和电商问答系统,MMKG 还被应用于多模态任务,例如跨模态检索、对话系统和目标检测。
具体案例
地理与学术检索:利用地理学术 MMKG,实现多跳查询,如检索特定地理位置相关的论文和机构信息。
学术代码检索:利用论文与代码构建的学术 MMKG,实现代码级别的检索。
医疗领域:结合 X 光、CT、超声等图像与文本描述,增强实体表示,改进 COVID-19 医患对话系统的性能,同时降低接触风险。
考古学:辅助甲骨文检测与识别,不仅分析物理特征(边缘、纹理、裂纹等),还提供相关文献、位置和机构信息,帮助决策。
优势
MMKG 可以整合多模态信息(图像 + 文本),提升检索、识别和决策的精确性和可用性。
问题与挑战
1. 复杂符号知识的落地(Complex Symbolic Knowledge Grounding)
问题:不仅需要单一实体、概念或关系,还需要处理多关系的子图或路径的落地。例如,涉及特朗普家族的多关系子图,需要找到能够表达整个家庭关系的图片。
挑战:多关系之间通常交错复杂,难以找到一张或几张图像同时准确地表达所有关系。
2. 质量控制(Quality Control)

MMKG 特有问题:除了传统知识图谱的准确性、完整性、一致性和新鲜度,MMKG 的图片可能存在特殊问题:
实体图片混淆:相互关联的实体容易混在一起(如某鸟和鳄鱼共生)。
著名实体干扰:知名实体的图片可能误出现在相关实体的落地结果中(如刘慈欣的书籍)。
抽象概念难以可视化:如“傲慢”等抽象概念,难以固定视觉特征,容易得到无关图片。
3. 效率问题(Efficiency)
构建效率:处理多模态数据增加了构建成本和复杂度。例如,NEIL 收集 40 万张图片就需要约 35 万 CPU 小时,而典型 KG 需要落地数十亿条实例。
在线应用效率:MMKG 在实时应用中也必须高效,否则无法满足实时响应需求。
扩展性问题:尤其是视频数据的落地,会进一步放大效率和可扩展性挑战。