Qwen3-Next深度解析:阿里开源“最强性价比“AI模型,如何用3%参数超越全参数模型?
🌟时间回到2025年9月11日,阿里巴巴通义千问团队重磅发布了下一代基础模型架构——Qwen3-Next,这款模型仅用3%的参数激活率,就实现了媲美旗舰级模型的性能,训练成本暴降90%,推理速度提升10倍,这款模型以其创新的混合架构设计、极致的稀疏化程度和卓越的性价比表现,被业界誉为阿里模型的"DeepSeek时刻"!
看到这你可能感觉很惊讶,究竟如何,我们继续往下看!
名人说:博观而约取,厚积而薄发。——苏轼《稼说送张琥》
创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊)
目录
- 一、什么是Qwen3-Next?一场AI效率革命的开始
- 1.Qwen3-Next简介
- 2. 两个主版本,满足不同需求
- 二、核心黑科技:混合注意力机制如何让AI"既快又准"?
- 1. Gated DeltaNet:高效的"长期记忆管理员"
- 2. Gated Attention:精准的"细节捕手"
- 3. 黄金配比:75%+25%的完美组合
- 三、超稀疏MoE架构:512个专家中只激活11个的智慧
- 1. 什么是MoE架构?
- 2. Qwen3-Next的超稀疏设计
- 四、Multi-Token Prediction:让AI"未卜先知"
- 1. MTP的工作原理
- 2. MTP带来的双重收益
- 五、性能表现:用数据说话的"性价比之王"
- 1. 训练效率的巨大突破
- 2. 推理性能的惊人表现
- 3. 模型能力的全面对比
- 预训练
- 后训练
- 六、简单实测:参数小能力强
- 1.文本创作
- 2.图像生成
- 3.网站开发
- 4.实时搜索
- 5.计划制定
- 七、如何使用Qwen3-Next:从零到上手的完整指南
- 1. 快速体验
- 2. 本地部署示例
- 3. 专业推理框架
- 总结:开启AI模型的"效率时代"
很高兴你打开了这篇博客,更多AI知识,请关注我、订阅专栏《AI知识图谱》,内容持续更新中…
大家好,我是流苏👋,今天我们一起了解一下阿里近期发布的新架构模型——Qwen3-Next。
Qwen-Chat官网:https://chat.qwen.ai/

一、什么是Qwen3-Next?一场AI效率革命的开始
1.Qwen3-Next简介
想象一下,如果你有一个拥有800个专业技能的超级团队,但每次只需要调用其中30个人就能完成以前需要整个团队才能做的工作,这就是Qwen3-Next的核心理念!

Qwen3-Next是阿里巴巴于2025年9月发布的全新架构AI模型,它最大的特点就是"大且不全激活":
- 总参数量:800亿(80B)
- 实际激活:仅30亿(3B),激活率仅3.7%
- 性能表现:媲美千问3旗舰版235B模型
- 成本控制:训练成本比Qwen3-32B降低90%
这就像是拥有一座巨大的图书馆,但每次查询时只需要打开几本相关的书籍,既保证了知识的全面性,又极大提升了查找效率!
2. 两个主版本,满足不同需求
Qwen3-Next家族包含三个成员:
- Base版本:基础预训练模型,适合二次开发
- Instruct版本:指令微调模型,适合对话交互
- Thinking版本:推理思考模型,在AIME25数学推理评测中获得87.8分,超越了谷歌Gemini-2.5-Flash-Thinking
huggingface🤗 中关于 Qwen3-Next 的收藏夹:https://huggingface.co/collections/Qwen/qwen3-next
二、核心黑科技:混合注意力机制如何让AI"既快又准"?
传统的AI模型就像一个"健忘症患者",每次回答问题都要重新翻遍所有历史对话,计算量随着对话长度呈平方级增长。而Qwen3-Next采用了革命性的混合注意力机制,彻底改变了这一局面。
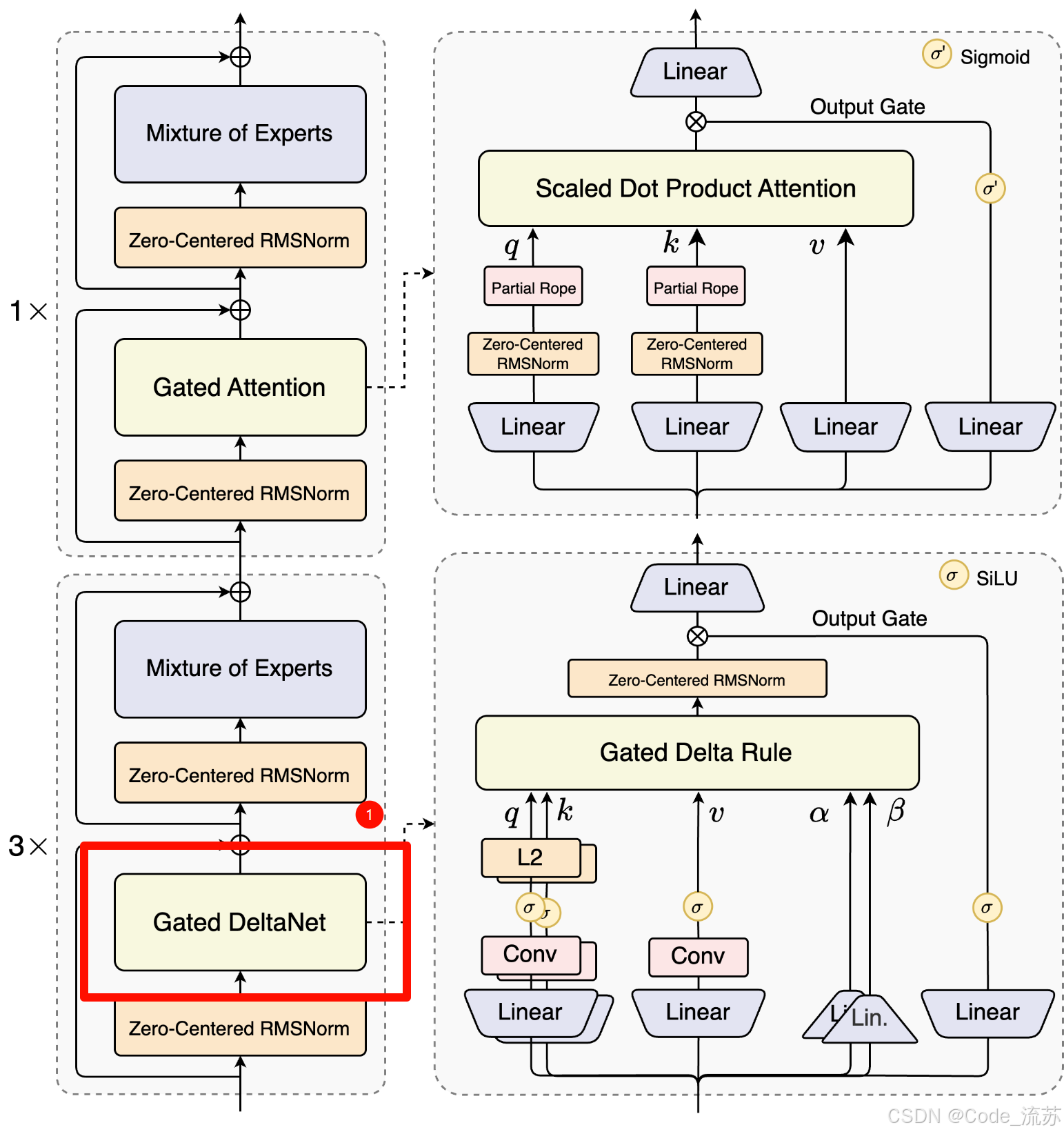
1. Gated DeltaNet:高效的"长期记忆管理员"
Gated DeltaNet采用线性注意力机制,专门负责长程信息扫描,并可及时清除无关历史信息。就像一个智能的记忆管理员,能够:
- 快速扫描:线性复杂度,处理长文本效率极高
- 智能筛选:自动过滤无关信息,保留关键内容
- 动态更新:实时更新重要信息的权重
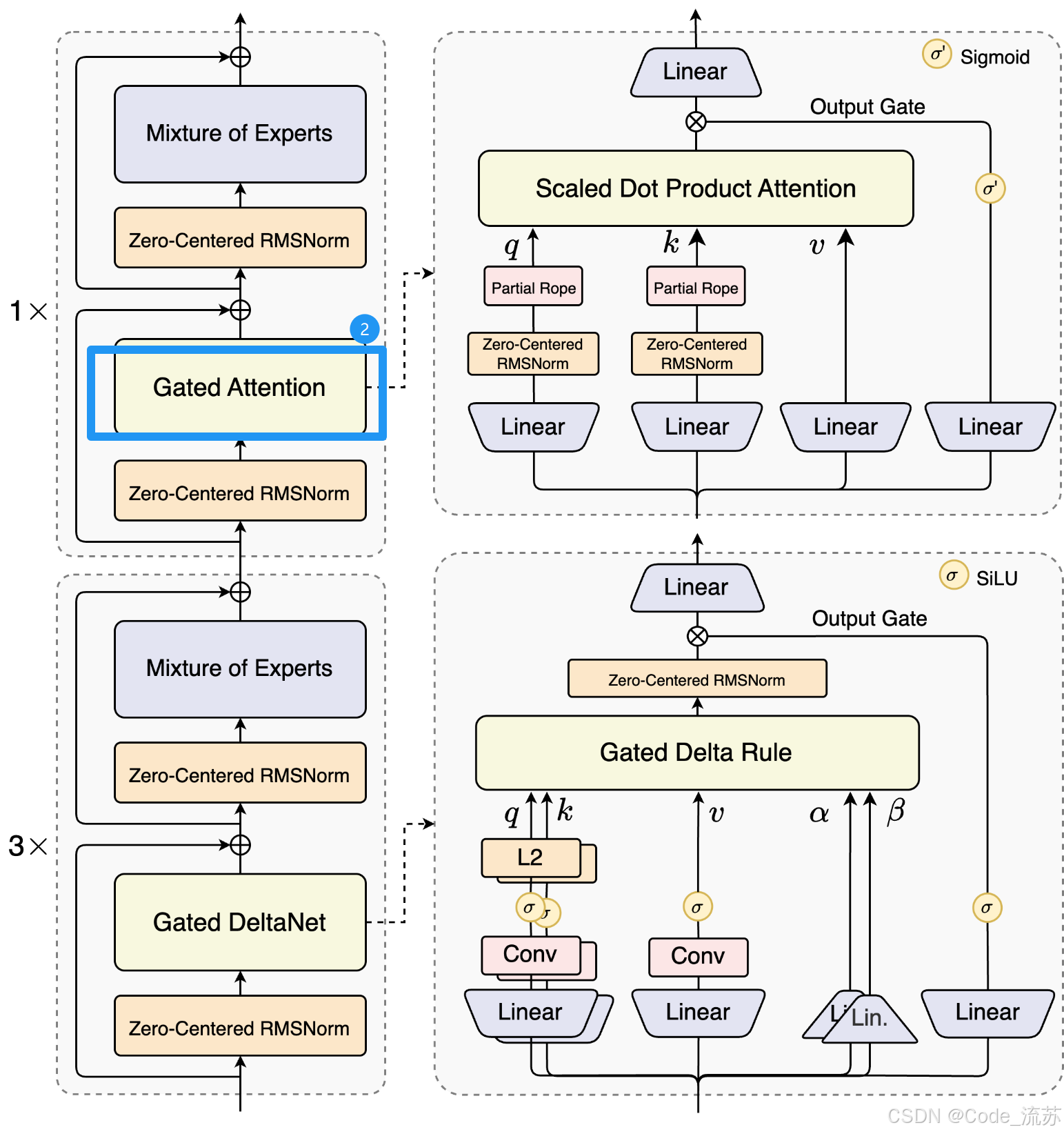
2. Gated Attention:精准的"细节捕手"
阿里自研的Gated Attention则专注捕获关键局部信息,负责处理需要精确理解的复杂内容。
3. 黄金配比:75%+25%的完美组合
通过大约一年的持续探索和"大量试错",团队最终确定了75%线性注意力+25%标准注意力的黄金配比:
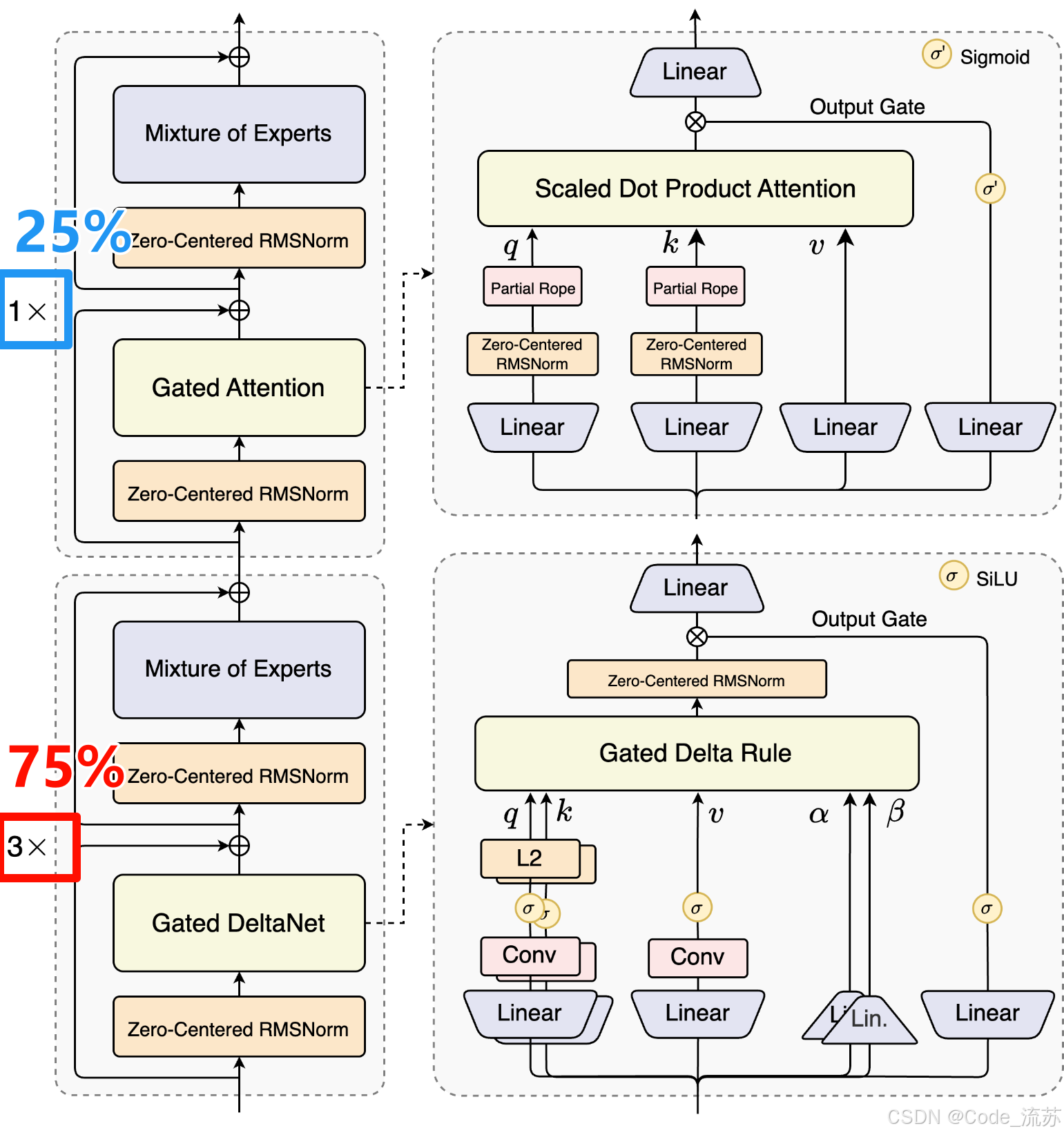
模型层分配策略:
├── 75% 使用 Gated DeltaNet (线性注意力)
│ ├── 处理长序列信息
│ ├── 维护全局上下文
│ └── 高效过滤无关信息
└── 25% 保留标准注意力 ├── 捕获精细局部特征├── 确保信息完整性└── 保证模型准确性
这种设计让模型既能高效处理长文本,又不失精准理解能力!
三、超稀疏MoE架构:512个专家中只激活11个的智慧
如果说混合注意力是大脑的"思考方式",那么超稀疏MoE(混合专家模型)就是大脑的"知识储存结构"。
1. 什么是MoE架构?
想象你是一家咨询公司的老板,雇佣了512位各领域专家,但每次处理客户问题时,你只需要召集10-11位最相关的专家来解决,这就是MoE架构的精髓!
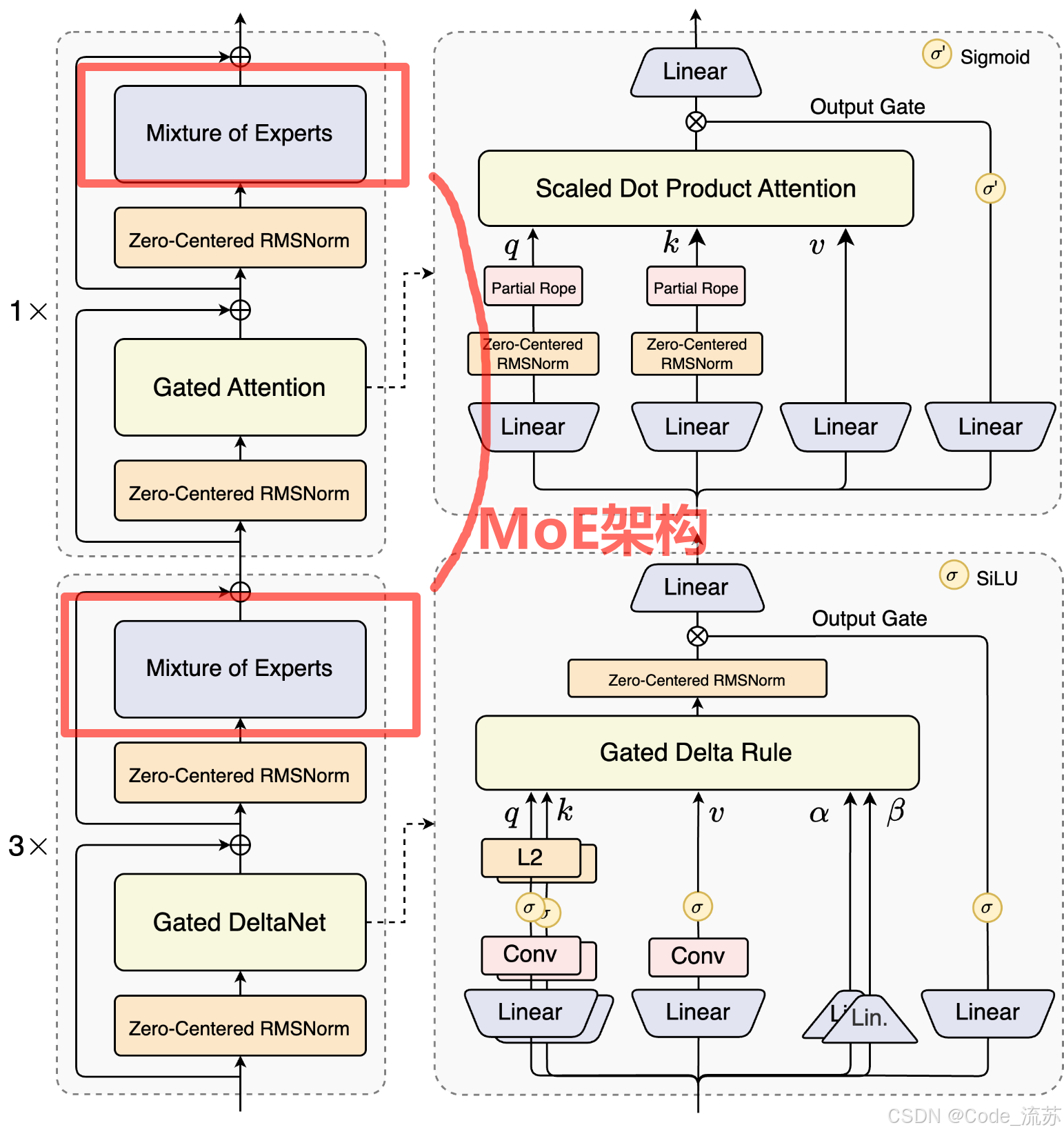
2. Qwen3-Next的超稀疏设计
相比Qwen3 MoE的128个总专家和8个路由专家,Qwen3-Next扩展到了512总专家,10路由专家与1共享专家的组合:
| 对比项 | Qwen3 MoE | Qwen3-Next MoE |
|---|---|---|
| 总专家数 | 128 | 512 |
| 路由专家 | 8 | 10 |
| 共享专家 | 0 | 1 |
| 激活比例 | ~6.25% | 3.7% |
这种设计的好处是:
- 专业化更强:每个专家术业有专攻
- 协作更高效:智能路由选择最合适的专家组合
- 资源利用最优:大幅减少计算资源消耗
四、Multi-Token Prediction:让AI"未卜先知"
传统AI模型生成文本就像"挤牙膏",一个词一个词地蹦,而Qwen3-Next引入了Multi-Token Prediction(MTP)机制,让AI具备了更具有可能性的"预测"的能力!
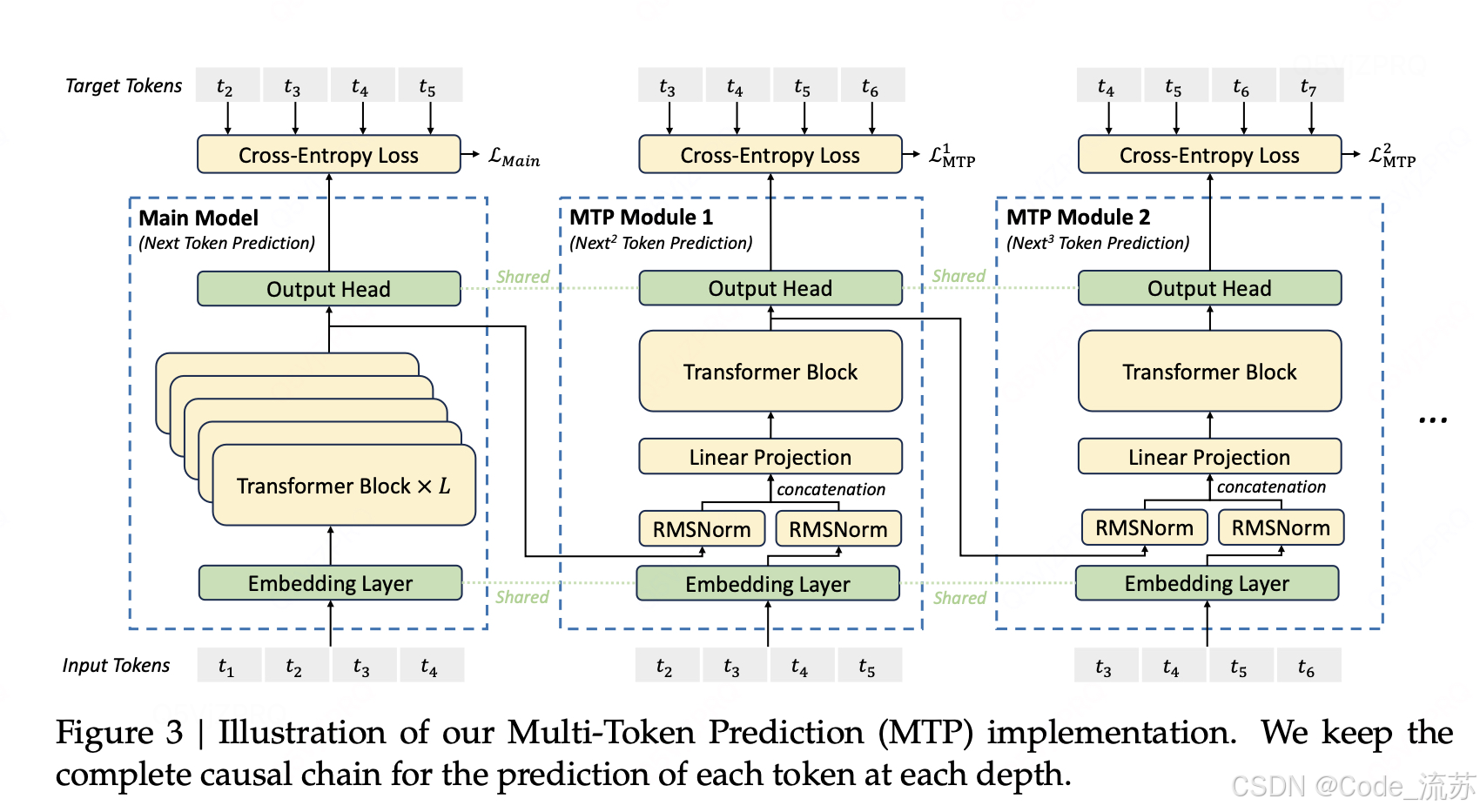
1. MTP的工作原理
传统模式:今天天气 → 很 → 好
MTP模式:今天天气 → [很, 好, ,, 适合] (一次预测多个token)
2. MTP带来的双重收益
- 推理加速:通过MTP机制达到100+ tokens/秒的推理速度,达到国际先进水平
- 性能提升:多步预测训练提升了模型整体性能
- 应用优化:为Speculative Decoding(投机解码)提供高接受率模块
五、性能表现:用数据说话的"性价比之王"
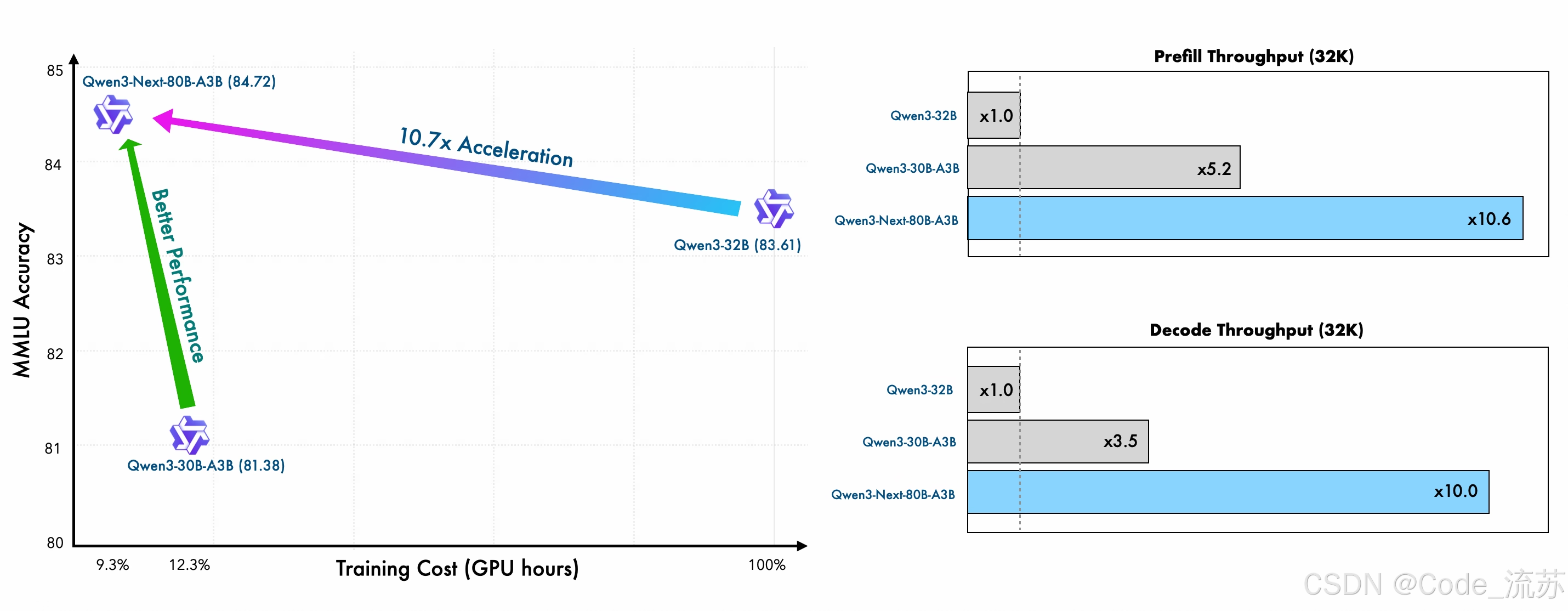
1. 训练效率的巨大突破
Qwen3-Next采用Qwen3 36T预训练语料的15T token均匀采样子集,训练消耗的GPU Hours不到Qwen3-30A-3B的80%,而与Qwen3-32B相比,仅需9.3%的GPU计算资源,这意味着:
- 成本优势:训练成本直降90%
- 时间优势:训练周期大幅缩短
- 资源优势:显著降低硬件门槛
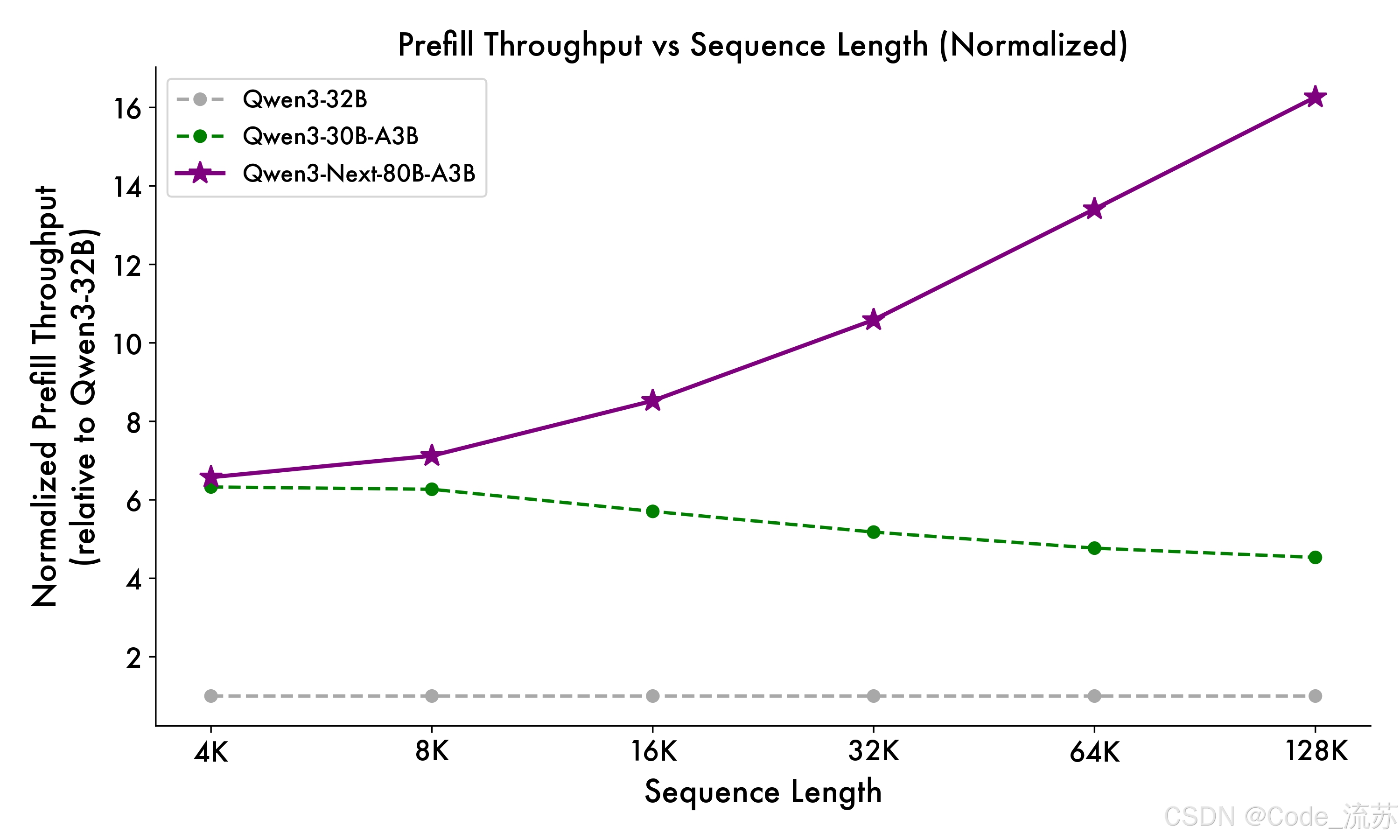
2. 推理性能的惊人表现
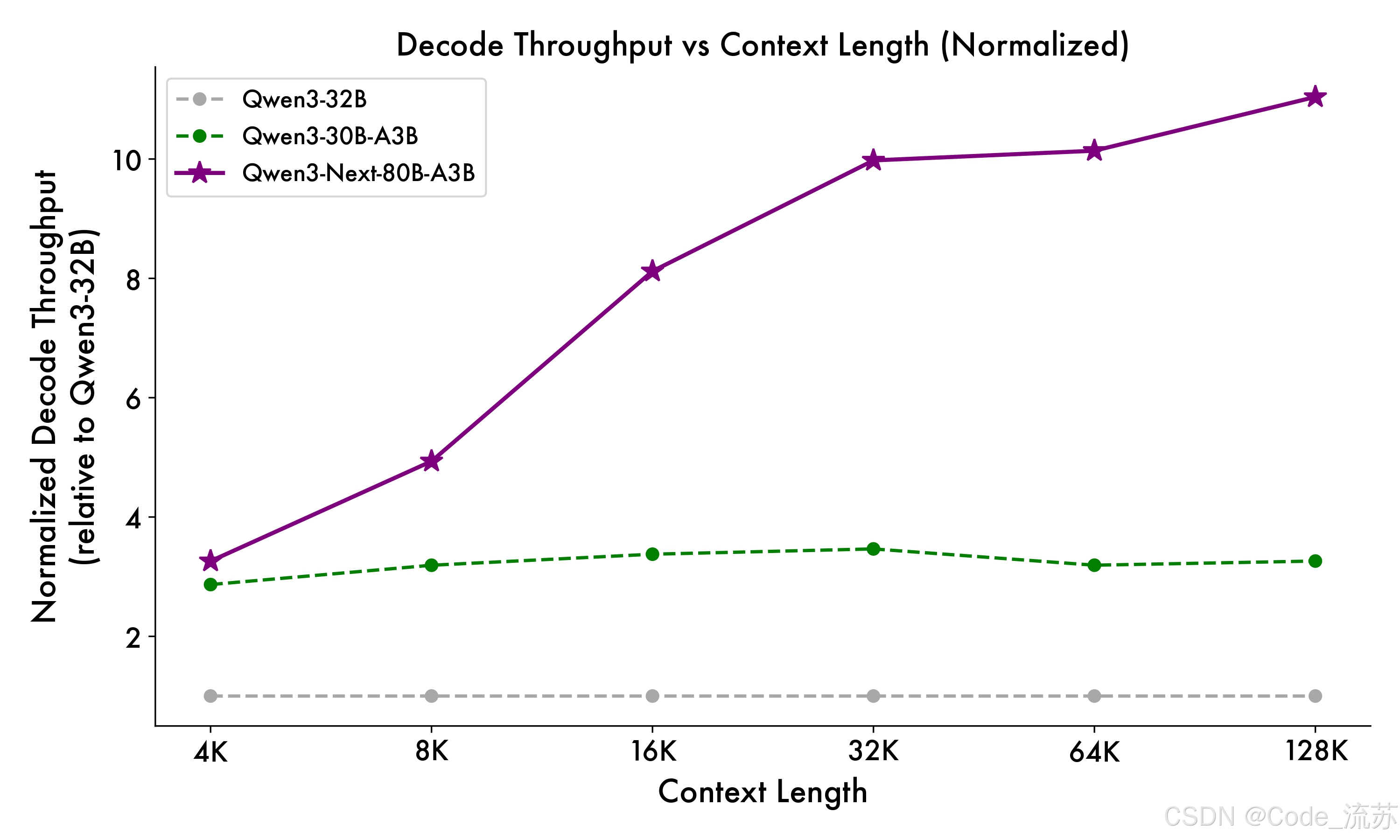
与 Qwen3-32B 相比,Qwen3-Next-80B-A3B 在预填充(prefill)阶段展现出卓越的吞吐能力:在 4k tokens 的上下文长度下,吞吐量接近前者的七倍;当上下文长度超过 32k 时,吞吐提升更是达到十倍以上。
在解码(decode)阶段,该模型同样表现优异——在 4k 上下文下实现近四倍的吞吐提升,而在超过 32k 的长上下文场景中,仍能保持十倍以上的吞吐优势。
| 场景 | 上下文长度 | 性能提升倍数 |
|---|---|---|
| 预填充阶段 | 4K tokens | 7倍 |
| 预填充阶段 | 32K+ tokens | 10倍+ |
| 解码阶段 | 4K tokens | 4倍 |
| 解码阶段 | 32K+ tokens | 10倍+ |
3. 模型能力的全面对比
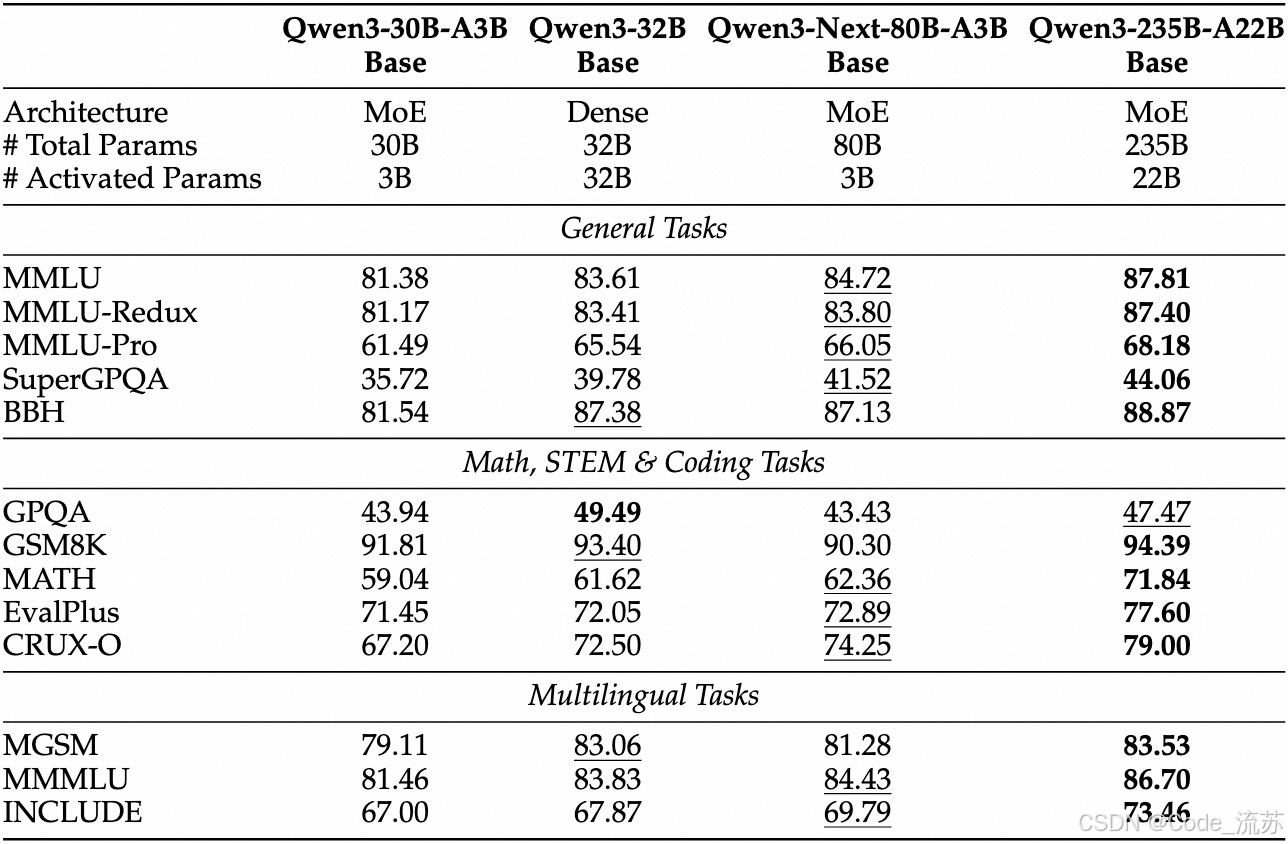
预训练是Base版本,后训练是Instruct版本和Thinking版本。
预训练
Base版本表现:
- Qwen3-Next-80B-A3B-Base 仅使用十分之一的 Non-Embedding 激活参数
- 在大多数基准测试中已超越 Qwen3-32B-Base,且显著优于 Qwen3-30B-A3B
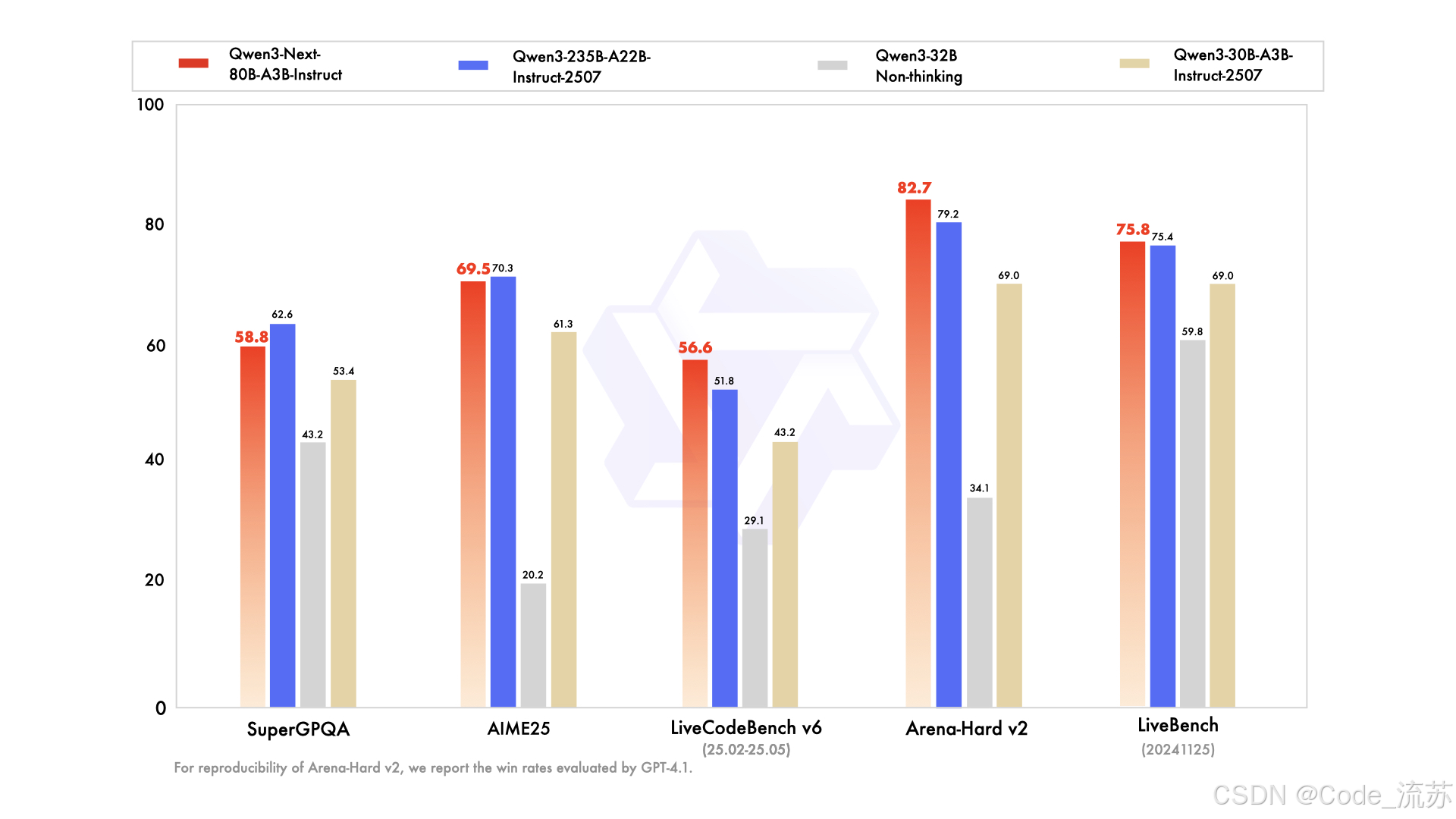
后训练
Instruct版本表现:
- 在多项基准测试中媲美Qwen3-235B旗舰模型
- 在RULER长上下文测试中,256K范围内表现优异

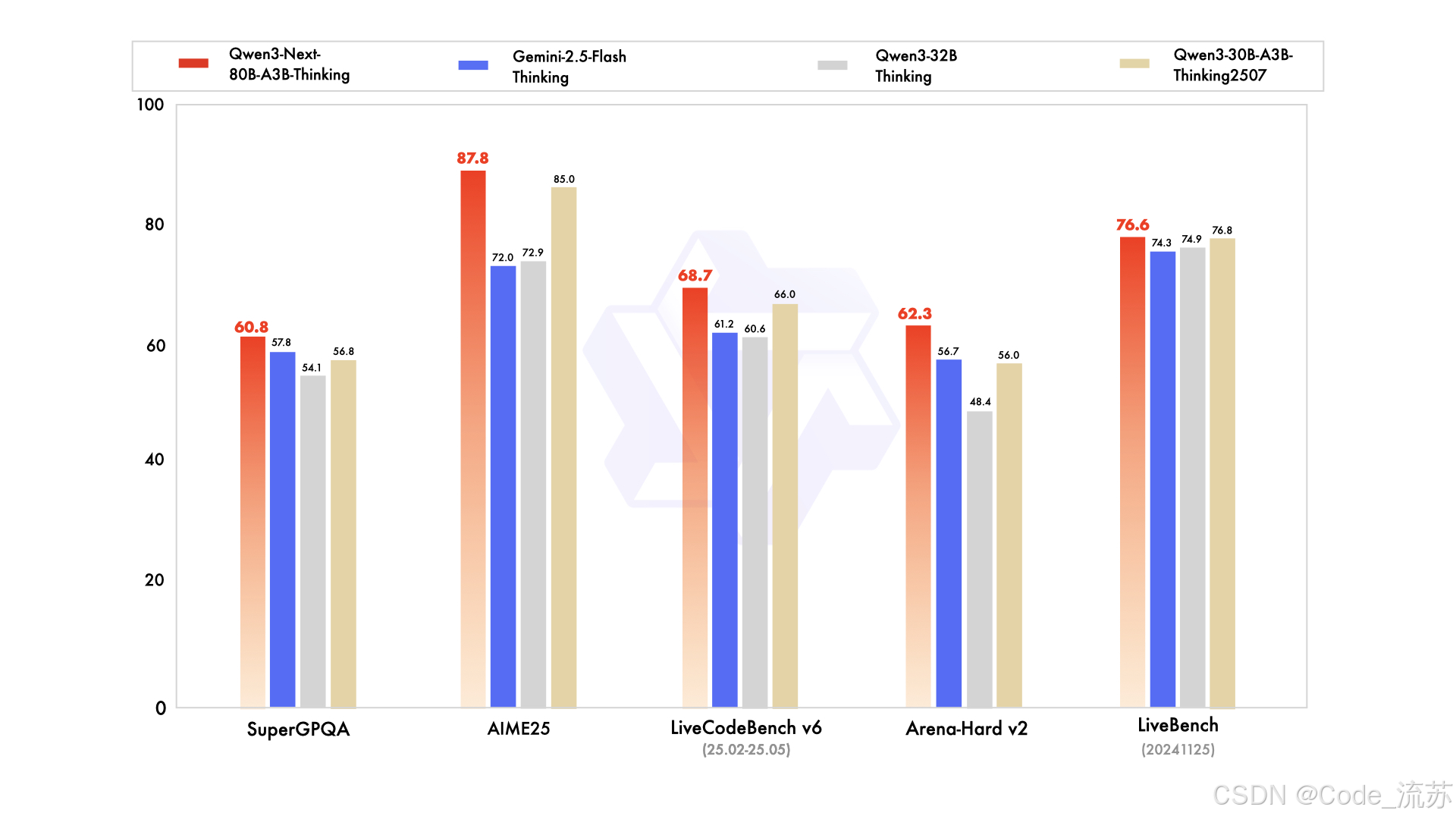
Thinking版本表现:
- 超越谷歌Gemini-2.5-Flash-Thinking
- 在复杂推理任务上表现卓越
- 部分指标接近Qwen3-235B-Thinking旗舰版
六、简单实测:参数小能力强
1.文本创作
Q1:帮我写一首关于秋天树叶的诗。

2.图像生成
Q2:画一只小猫在草坪上奔跑的图像
有一说一画图能力真不错,与描述的也比较准。

3.网站开发
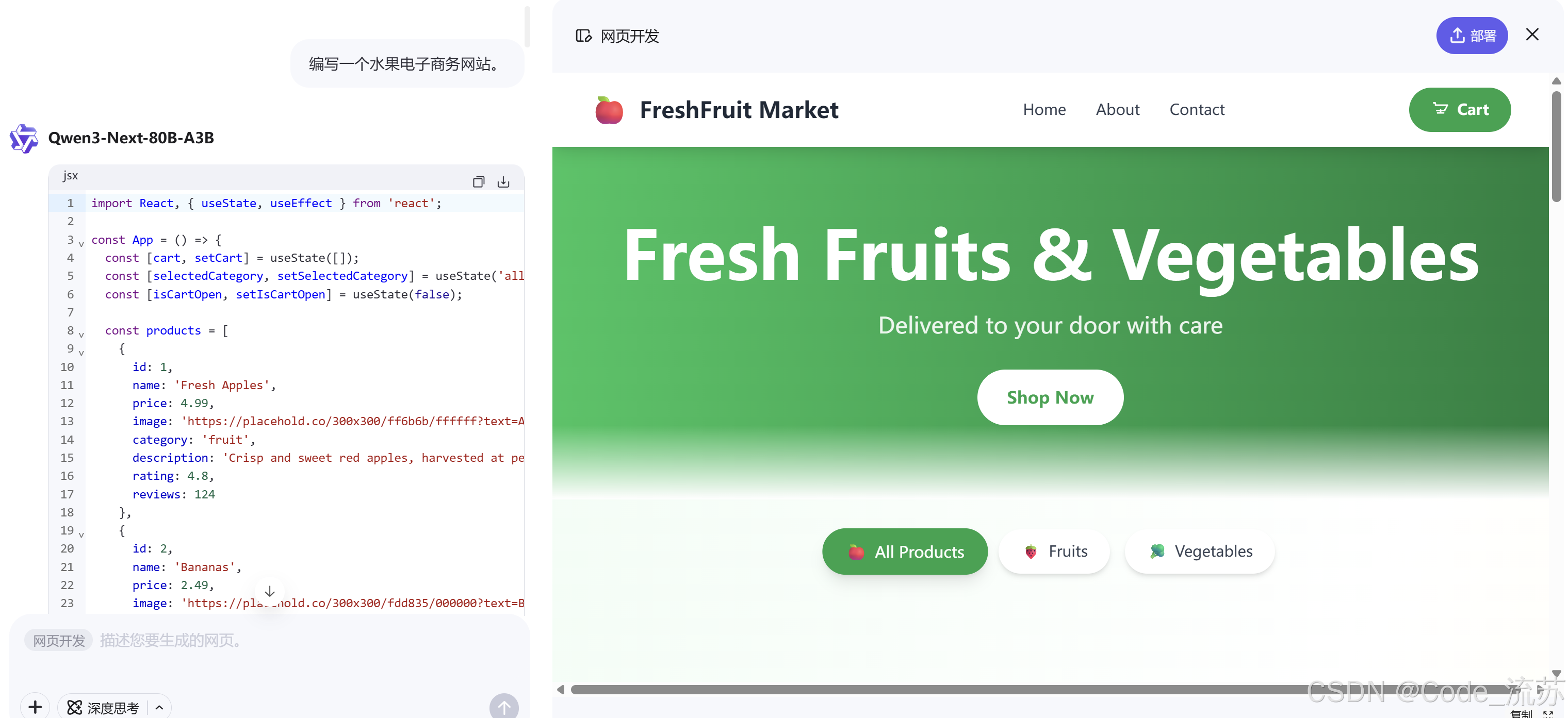
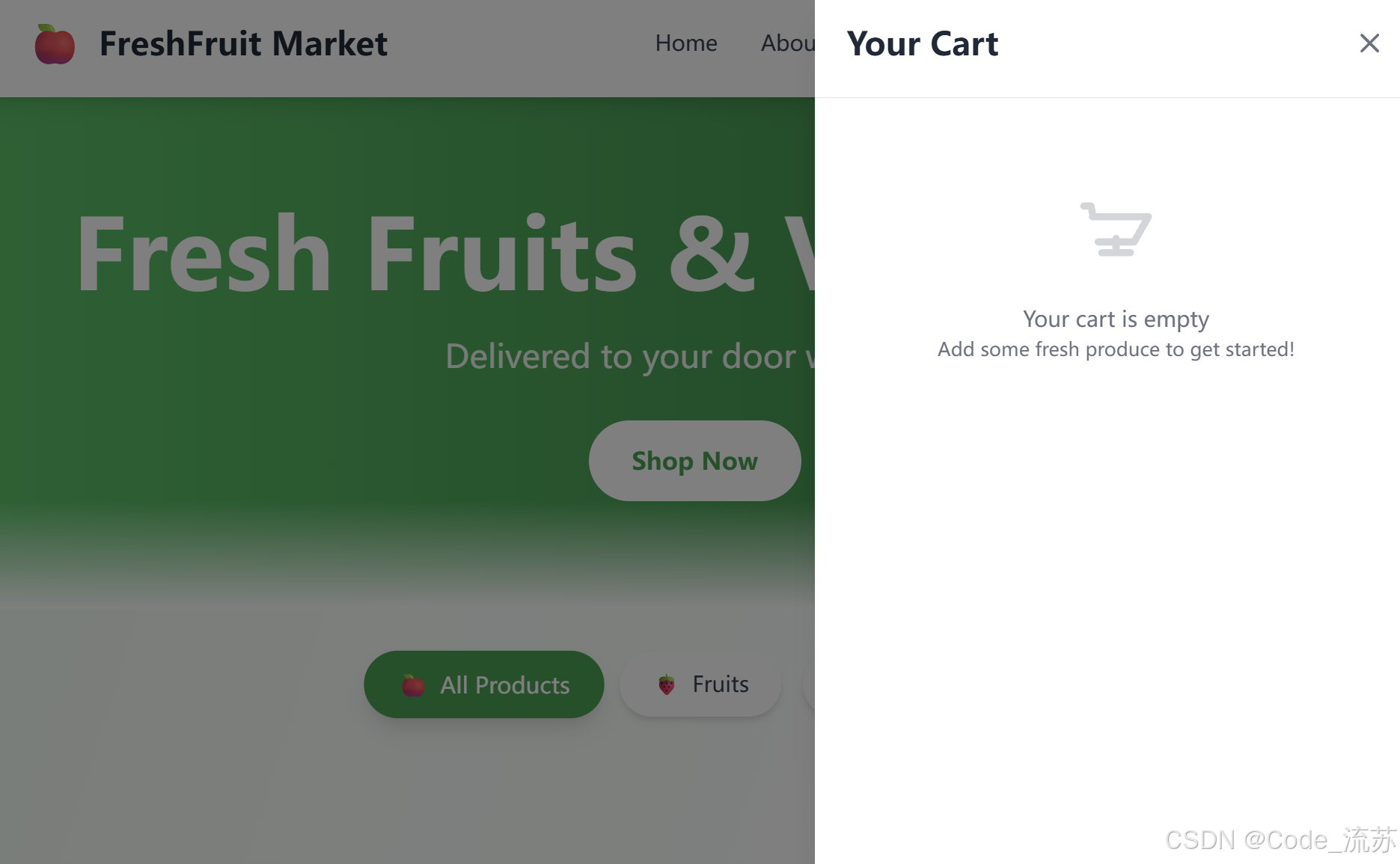
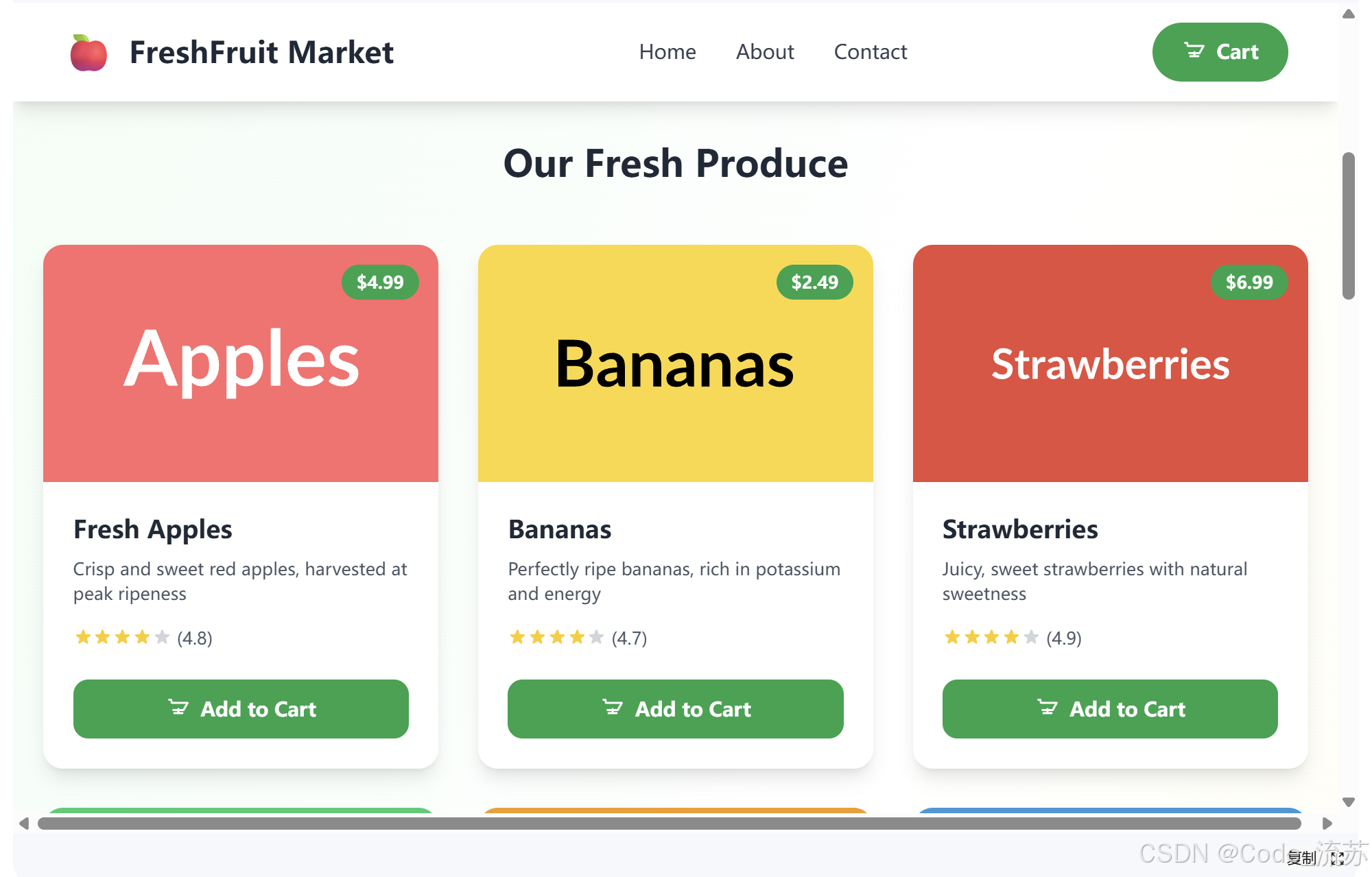
Q3:编写一个水果电子商务网站。
写网站响应很快,写出的网站还有购物车功能,有动效浮动。
4.实时搜索
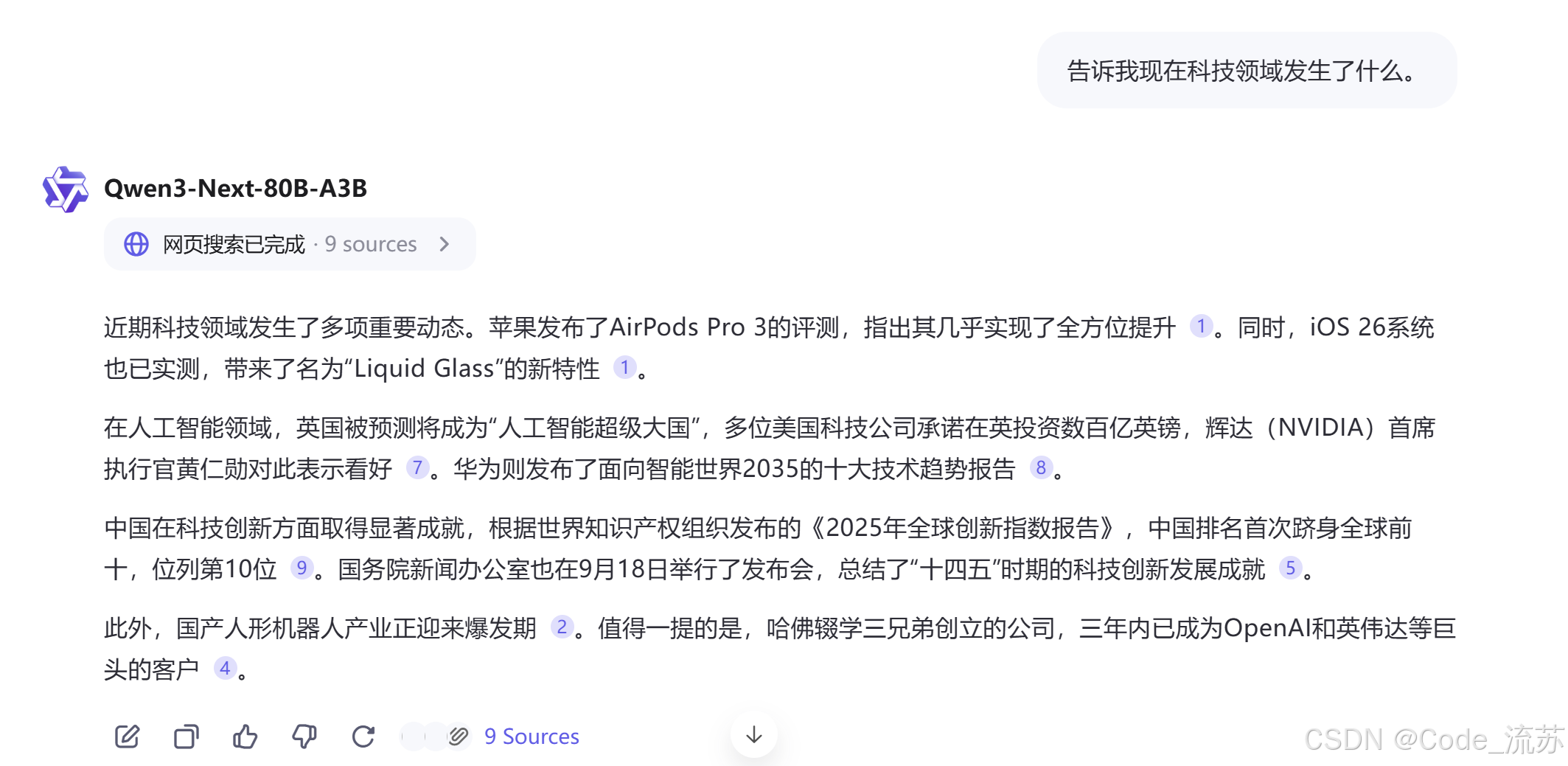
Q4:告诉我现在科技领域发生了什么。
这句话和Qwen3-Next说了之后,它会自动打开搜索功能,确保信息的实时性,回复也是最近的热点信息。
5.计划制定
Q5:帮我制定一个健康生活方式的计划。
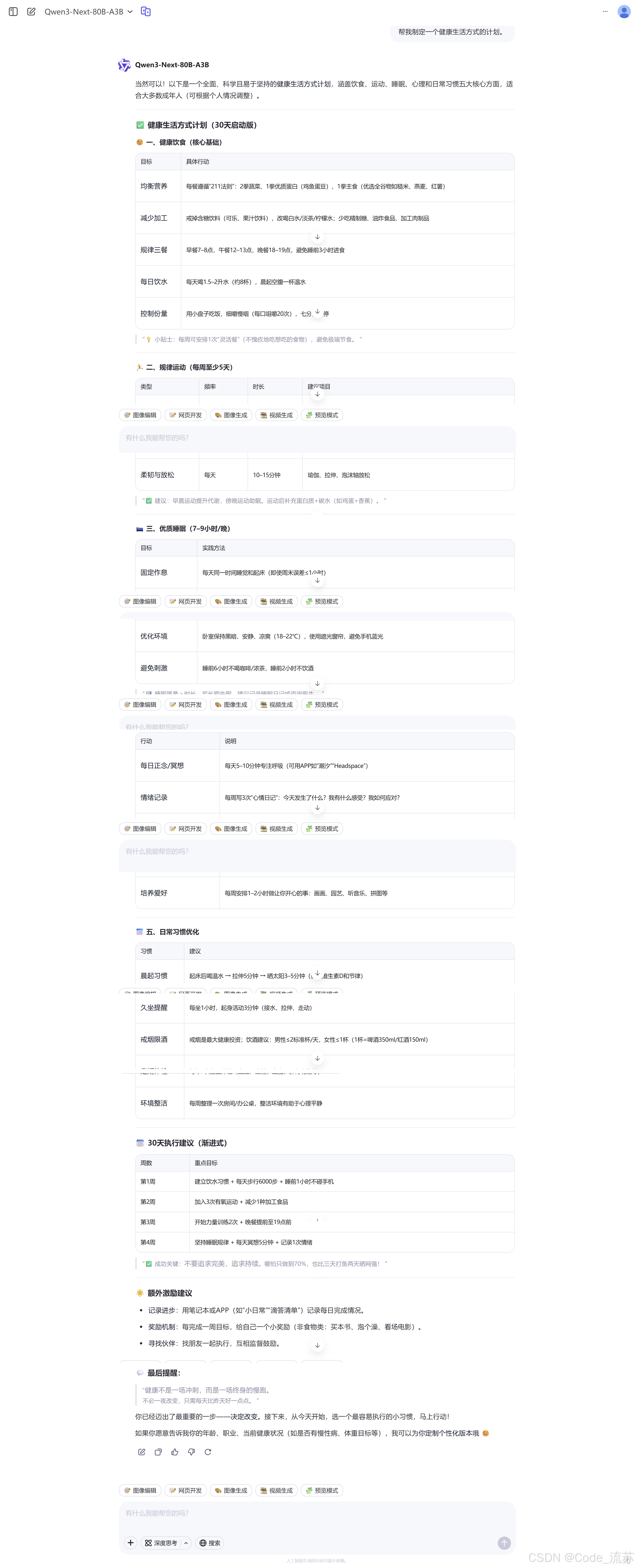
关于健康生活计划,Qwen3-Next回答的很详细,最后还来了个特别好的提醒:“健康不是一场冲刺,而是一场终身的慢跑。”

简单测试之后,总结下来就是,这个模型虽然参数小,但能力不弱于很多全参数模型👍👍👍,响应很快,缺点是相对于全参数的检索范围没有那么全面和具体。
七、如何使用Qwen3-Next:从零到上手的完整指南
1. 快速体验
在线体验:
- 官方聊天界面:https://chat.qwen.ai/
- 阿里云百炼平台:https://www.aliyun.com/product/bailian
开源获取:
- HuggingFace:https://huggingface.co/Qwen
- ModelScope:https://modelscope.cn/organization/Qwen
2. 本地部署示例
from transformers import AutoModelForCausalLM, AutoTokenizer# 加载模型和分词器
model_name = "Qwen/Qwen3-Next-80B-A3B-Instruct"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name,dtype="auto",device_map="auto",
)# 准备输入
messages = [{"role": "user", "content": "解释一下什么是人工智能?"}]
text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)# 生成回答
inputs = tokenizer([text], return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_new_tokens=512)
response = tokenizer.decode(outputs[0][len(inputs.input_ids[0]):], skip_special_tokens=True)print(response)
3. 专业推理框架
对于生产环境,推荐使用专业推理框架:
SGLang部署:
# 安装SGLang
pip install 'sglang[all] @ git+https://github.com/sgl-project/sglang.git@main'# 启动服务(4卡并行,256K上下文)
SGLANG_ALLOW_OVERWRITE_LONGER_CONTEXT_LEN=1 python -m sglang.launch_server \--model-path Qwen/Qwen3-Next-80B-A3B-Instruct \--port 30000 --tp-size 4 --context-length 262144
vLLM部署:
# 安装vLLM
pip install vllm --pre --extra-index-url https://wheels.vllm.ai/nightly# 启动服务
VLLM_ALLOW_LONG_MAX_MODEL_LEN=1 vllm serve Qwen/Qwen3-Next-80B-A3B-Instruct \--port 8000 --tensor-parallel-size 4 --max-model-len 262144
总结:开启AI模型的"效率时代"
Qwen3-Next的发布标志着AI模型正式进入"效率优先"的新时代。它通过混合注意力机制、超稀疏MoE架构和Multi-Token Prediction等创新技术,实现了以下突破:
1️⃣ 技术突破:
- 混合注意力解决长上下文处理难题
- 极致稀疏化实现"大模型小激活"
- MTP机制大幅提升推理速度
2️⃣ 成本优势:
- 训练成本降低90%
- 推理效率提升10倍
- 硬件门槛显著下降
3️⃣ 应用前景:
- 支持256K-1M超长上下文
- 完善的开源生态支持
- 广泛的部署平台兼容
目前,Qwen3-Next已经在NVIDIA平台上得到优化支持,可以通过NVIDIA NIM、SGLang等框架部署,这为AI技术的普及和应用打下了坚实基础。
Qwen3-Next不仅仅是一个新模型,更是AI发展方向的重要指引——在追求更强能力的同时,如何让AI变得更加高效、经济、实用。这种"用更少资源做更多事情"的设计理念,必将推动整个AI行业向着更加可持续的方向发展!
📝 写在最后:技术的进步不应该是资源的堆砌,而应该是智慧的结晶。Qwen3-Next正是这种理念的完美体现,它告诉我们,AI的未来不在于"更大",而在于"更智能"!
创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊)
本文基于阿里巴巴通义千问团队官方技术报告和权威技术资讯整理,确保信息准确性和时效性。