AI模型测评平台工程化实战十二讲(第二讲:目标与指标:把“测评”这件事说清楚(需求到蓝图))
系列名:让结果说话:AI模型测评平台工程化实战十二讲
本篇以系统中真实落地的代码与数据结构为锚点,梳理“测评目标—指标体系—评分口径—流程蓝图—MVP边界—长期演进”的闭环,让“好不好”这件事从模糊判断,变成可执行、可复用、可追溯的工程规范。
为什么先讲目标与指标
做评测系统最怕“跑完才想指标”。一旦缺少目标的约束,评测流程就会在一次次临时需求中不断分叉,脚本和页面越写越多,口径越讲越散。我的经验是:在任何编码动作之前,把目标和指标说清楚,然后用工程化的方式固化为“系统配置与约束”。
在本系统里,目标与指标不是白板上的幻灯片,而是实打实落在代码与数据库上的“契约”:
- 目标驱动模型接入层、并发策略、提示词治理、结果汇总;
- 指标被映射为评分列、统计维度、导出字段、权限与分享的边界;
- 评分口径被表达为可配置“提示词”(文件级与默认两级),在评测引擎中被强制遵循;
- JSON 输出协议不是“软建议”,而是“硬约束+容错兜底”。
下文,我会从“谁在用”“评测什么”“怎么量化”“如何落地到代码”这四个层面展开。
1. 角色与场景:谁在用系统、用来做什么
对任何评测系统来说,最先要回答的是“谁在用、用来做什么”。我们的系统面向四类核心角色:
- 算法/数据角色:准备数据集(主观/客观)、提出评分口径建议(提示词/标准答案),关注“能否体现真实能力”。
- 工程角色:接入外部模型、治理并发/速率/错误、完善日志/追踪,关注“跑得起来且跑得稳”。
- 产品/项目角色:发起评测、查看与导出报告、对外分享,关注“可读、可比、可复用”。
- 管理/合规角色:看趋势、看可见性与权限、看审计追踪,关注“可治理、可落地”。
典型使用场景:
- 新模型引入前的 A/B 对比:用同一数据集、同一裁判口径,对候选模型进行多维评测;
- 回归评测:模型/提示词/阈值更新后,挂同一套历史基线数据跑回归;
- 专题报告:为某类题型(比如“信息抽取”或“政务问答”)出一份结构化对比报告;
- 联合评审:通过分享链接给外部伙伴只读访问,并在需要时开启少量人工复核入口。
这些角色与场景,被整合进系统“从首页到结果页”的端到端流程中:上传文件、选择模型与裁判、设置模式(自动/主观/客观)、发起评测、实时追踪、查看结果、导出报告、分享与权限控制。对应的路由与页面锚点分别在:
- 发起评测(API):
/start_evaluation与/api/start_evaluation - 任务状态:
/task_status/<task_id> - 结果查看:
/results/<result_id>与/view_results/<filename> - 导出报告:
/api/generate_report/... - 共享与可见性:统一由数据库模块与模板协作管理
代码参考:
"""
评测核心蓝图
处理模型评测的核心功能:开始评测、任务状态、结果查看等
从app.py迁移的评测相关路由
"""import os
import uuid
import threading
import pandas as pd
from datetime import datetime
from flask import Blueprint, request, jsonify, session, render_template, send_file, current_app
2. 评测对象与粒度:我们到底在“评”什么
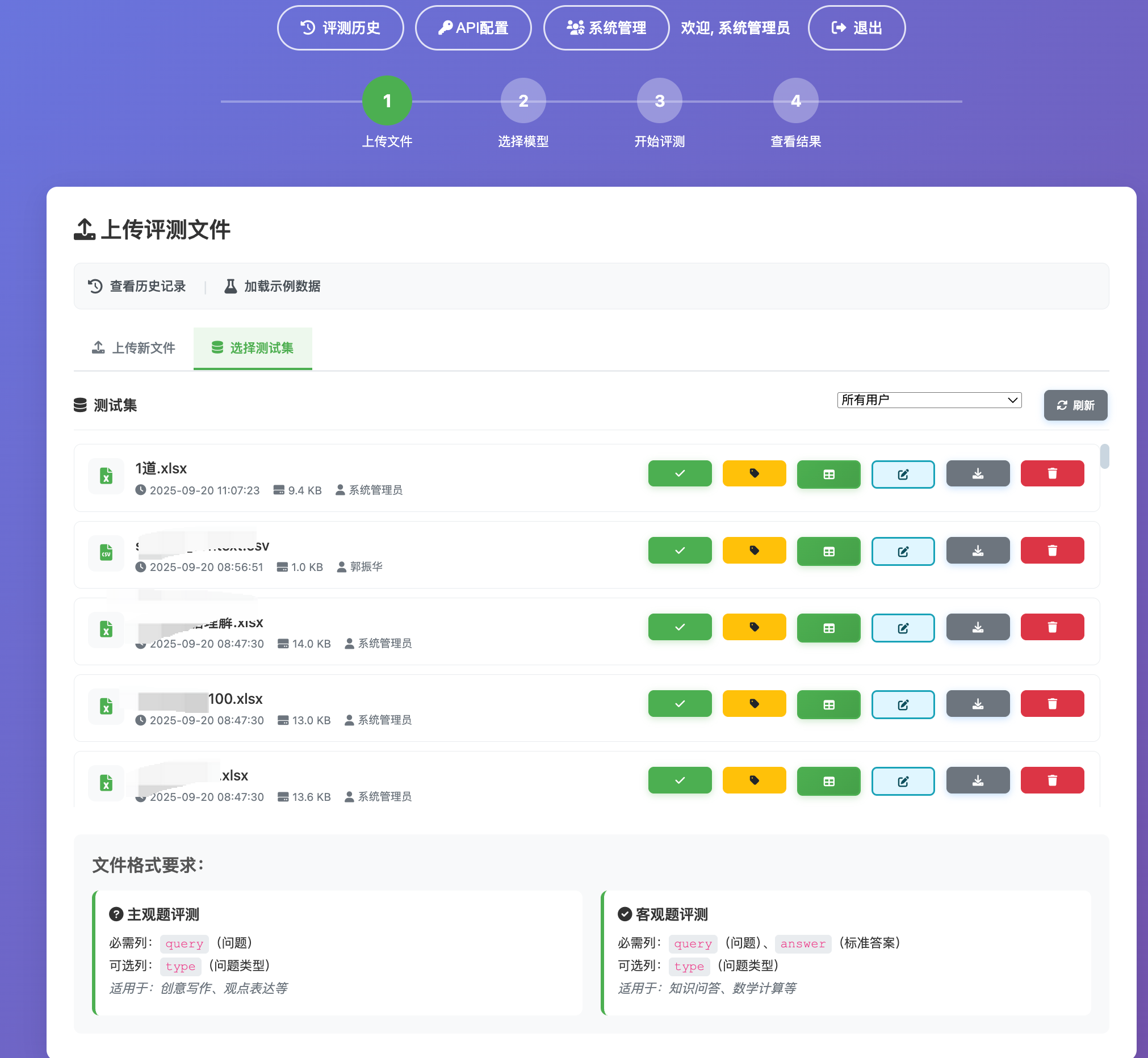
把“评什么”说清楚,才能保证后续的指标与实现不跑偏。本系统的评测对象与粒度包括:
- 评测数据集:一份 CSV/Excel,条目级别至少包含
query,客观题包含answer,可选type。 - 题目粒度:每一行被视为一条“题目”,在评测结果 CSV 中对应“序号、类型、query、标准答案(客观题)”。
- 模型粒度:同一题目可对应多个“被测模型”,以列的方式并列呈现,如
<model>_答案 / <model>_评分 / <model>_理由 /(客观题)<model>_准确性。 - 评测模式:主观题与客观题两条路径,分别有独立的评分口径治理与 JSON 输出协议。
- 裁判模型:一类特殊的模型,不产出“答案”,只对“被测模型的答案”进行评分与解释。
系统在发起评测时,会根据文件与选择项自动或手动确定模式:
- 自动模式:后端依据数据集列结构智能判定(如存在
answer列则默认客观题)。 - 强制模式:显式指定
subjective或objective,覆盖自动判定。
对应的后端逻辑:
@app.route('/api/start_evaluation', methods=['POST'])
@login_required
def start_evaluation():"""启动模型评测任务"""data = request.get_json()filename = data.get('filename', '').strip()selected_models = data.get('selected_models', [])custom_name = data.get('custom_name', '').strip()save_to_history = data.get('save_to_history', True)force_mode = data.get('force_mode', 'auto')...if force_mode == 'auto':mode = detect_evaluation_mode(df)else:mode = force_mode
以及蓝图中新的评测入口(包含裁判模型选择):
@evaluation_bp.route('/start_evaluation', methods=['POST'])
@login_required
def start_evaluation():"""开始评测"""data = request.get_json()filename = data.get('filename')selected_models = data.get('selected_models', [])judge_model = data.get('judge_model') # 裁判模型force_mode = data.get('force_mode') # 'auto', 'subjective', 'objective'...
3. 维度与指标:把“好不好”拆成“可度量”
针对大模型评测,我们将“好不好”拆解为六大类维度,映射到系统内具体的评分列、统计视图与导出字段:
- 能力与正确性(Accuracy/Quality)
- 主观题:裁判模型给出分数与“评分理由”。
- 客观题:在正确性基础上强调“准确性(Correct / Partial / Wrong)”。
- 系统映射:结果 CSV 中
<model>_评分与<model>_理由,客观题加<model>_准确性。
- 稳定性与鲁棒性(Stability/Robustness)
- 多次测评分布、异常率、非结构化输出率、JSON 格式错误率等。
- 系统映射:评测引擎的 JSON 解析失败计数、兜底使用率、重试统计(后续会加入更完备的日志与看板)。
- 时延与吞吐(Latency/Throughput)
- 单题平均时延、并发参数与速率限制下的吞吐。
- 系统映射:任务状态的进度与耗时,评测引擎的并发信号量配置。
- 成本(Cost)
- 调用成本估算、不同模型单次/批次的成本曲线。
- 系统映射:当前以“配置与接口调用”统计为主,后续可通过中间件估算 token 与费用。
- 安全与合规(Safety/Compliance)
- 内容安全、敏感信息处理、本地化策略合规。
- 系统映射:当前以“评分理由与人工抽检”为主,后续计划加入安全维度提示词与自动检查。
- 本地化与可读性(Localization/Readability)
- 语言一致性、术语统一、书面性/口语化适配。
- 系统映射:在主观题评分提示词中明确考察点,并在理由中要求具体证据。
这些维度并不是“写在文档里就好”,而是通过“评分口径(提示词)+ 输出协议(JSON)+ 统计视图”的组合,在系统中形成闭环。对于任何一次评测,我们都能从结果 CSV 与历史统计中追溯到“当时采用了哪些维度、由哪些提示词定义、以什么 JSON 契约产出”。
4. 评分口径:主观题/客观题两条路径,提示词是“第一公民”
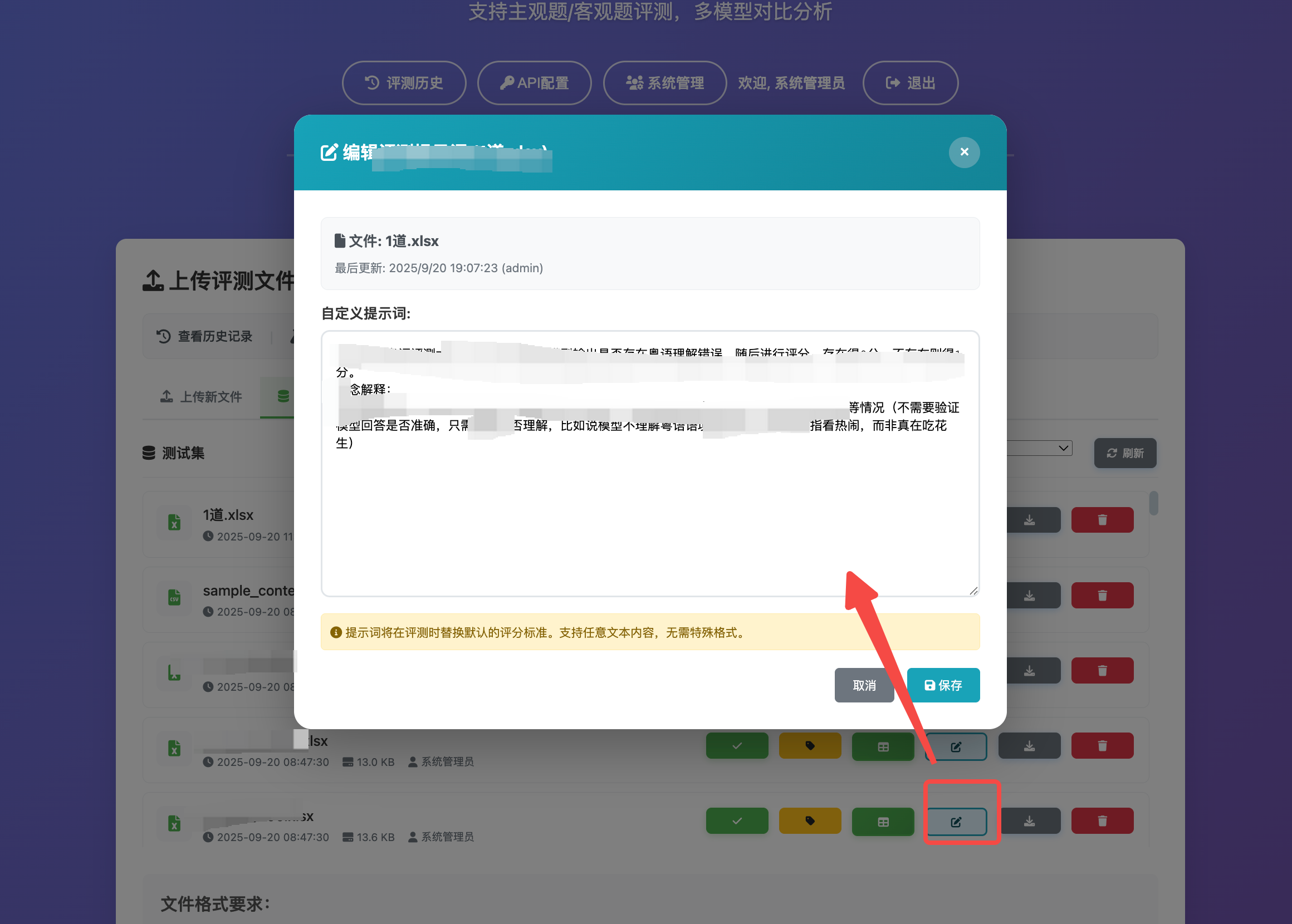
在本系统里,评分口径被视为“第一公民”。提示词不是“写在某个脚本里”的临时字符串,而是:
- 文件级自定义提示词:针对某个数据集(文件名)配置专属评分口径;
- 系统默认提示词:主观题与客观题分别维护默认口径;
- 获取优先级:文件级 > 系统默认;若缺失则抛出明确错误(避免“口径缺失但悄悄运行”);
- JSON 强约束:裁判模型的输出必须是严格 JSON,不允许前后注释、代码块包裹等。
对应的引擎实现(主观题):
def build_subjective_eval_prompt(query: str, answers: Dict[str, str], question_type: str = "", filename: str = None) -> str:...if filename:try:file_prompt = db.get_file_prompt(filename)if file_prompt:...custom_prompt = file_promptelse:...default_prompt = db.get_default_prompt('subjective')if default_prompt:custom_prompt = default_promptelse:raise ValueError(...)except Exception as e:...else:raise ValueError("主观题评测必须设置自定义评测提示词。...")
对应的引擎实现(客观题):
def build_objective_eval_prompt(query: str, standard_answer: str, answers: Dict[str, str], question_type: str = "", filename: str = None) -> str:...if filename:try:file_prompt = db.get_file_prompt(filename)if file_prompt:custom_prompt = file_promptelse:default_prompt = db.get_default_prompt('objective')if default_prompt:custom_prompt = default_promptelse:raise ValueError(...)except Exception as e:...else:raise ValueError("客观题评测必须设置自定义评测提示词。...")
JSON 输出协议(裁判模型)
为了让前端与导出稳定可用,裁判模型必须输出严格 JSON:
- 主观题:
{"模型1": {"评分": <number>, "理由": "..."}, ...} - 客观题:
{"模型1": {"评分": <number>, "准确性": "正确|部分正确|错误", "理由": "..."}, ...}
引擎会校验 JSON 并将对应字段映射到 CSV 列;若解析失败,使用兜底结构,保证整批任务不中断:
judge_raw = await call_judge_model(judge_model, prompt)
result_json = parse_json_str(judge_raw)
...
if model_key in result_json:row_data.append(result_json[model_key].get("评分", ""))row_data.append(result_json[model_key].get("理由", ""))if mode == 'objective':row_data.append(result_json[model_key].get("准确性", ""))
else:row_data.extend(["", ""]) # 评分、理由if mode == 'objective':row_data.append("") # 准确性
5. 端到端流程蓝图:从数据到报告的“流水线”
把流程讲清楚,是为了让“目标与指标”有地方落脚。我把系统的端到端流程拆成 6 个阶段:
- 准备与上传
- 数据集包含:主观题(
query,type可选)/客观题(query,answer,type可选)。 - 通过首页上传,选择被测模型与裁判模型,确定评测模式(自动/强制)。
- 任务生成与并发执行
- 后端生成
task_id,创建任务记录(内存与数据库双写),初始化进度。 - 第一阶段并发:批量获取各被测模型答案(受并发信号量与限流治理);
- 第二阶段并发:对每道题构建评分提示词,调用裁判模型,产出结构化 JSON;
- 每题完成时回填进度与状态到
/task_status/<task_id>与数据库。
- 结果落库与导出
- 将有效结果按题序写入 CSV,生成统一的列结构;
- 记录历史:文件路径、模型列表、模式、标签、元信息(开始/结束时间、题量、文件大小等)。
- 结果可视化页
- 加载 CSV 与高级统计(若可用),展示基础统计、分布、对比、下钻细节;
- 支持导出 CSV/Excel、筛选导出、查看评分理由。
- 共享与权限
- 根据结果记录中的创建者与可见性策略进行权限检查;
- 支持分享链接与密码(计划)、可设置有效期与只读视图。
- 回归与迭代
- 再次发起评测时沿用相同提示词口径或文件级定制,形成可比较的结果序列;
- 对比不同时间段、不同模型、不同口径的结果趋势。
流程在代码中的锚点:
- 任务发起与调度:
routes/evaluation.py的start_evaluation; - 被测模型答案获取:
utils.task_manager.get_multiple_model_answers; - 评分引擎:
utils/evaluation_engine.py的evaluate_models; - 任务状态:
/task_status/<task_id>; - 结果页:
/results/<result_id>与/view_results/<filename>; - 历史持久化:
database.py中save_evaluation_result与相关查询; - 导出与下载:
/api/generate_report/...、/download/<filename>。

6. MVP 边界:先解决“常见90%”的问题
为了尽快让系统“可用且可复用”,我们给 MVP 画出了清晰边界:
- 支持多模型并发评测与统一列输出;
- 支持主观/客观题两条路径,且口径通过提示词治理;
- 强制裁判模型 JSON 输出,解析失败有兜底;
- 做好任务进度与结果可视化,支持导出;
- 基础的历史持久化与权限校验;
- API Key 管理在 Web 界面可保存到
.env,减少环境门槛。
同时,保留“第二阶段”的扩展空间:
- 更丰富的统计与图表;
- 报告自动化:一键 Markdown/PDF(将在第 11 篇详述);
- 更细粒度的可见性与分享策略;
- 更智能的重试、退避、毒数据隔离机制;
- 成本与用量审计;
- 对外 API 与 Webhook(第 12 篇)。
7. 与代码的对齐:指标如何“变成代码与数据”
在这套系统里,目标与指标不是文档,而是通过以下方式落地:
- 评分提示词:通过
db.get_file_prompt(filename)和db.get_default_prompt(mode)获取; - JSON 契约:在引擎中构造标准 JSON 示例并放入提示词中,裁判模型被要求严格输出;
- 进度与统计:每题完成回填
task_status与db.update_task_progress; - 结果列结构:在引擎中按模型动态生成列名,确保导出字段稳定;
- 历史与共享:通过
save_evaluation_result与get_result_by_*形成“可回溯”的数据资产; - API Key 管理:
/save_api_keys路由把密钥直接保存到.env,并可通过services/model_api_service.py进行校验。
对应代码引用:
async def evaluate_models(data: List[Dict], mode: str, model_results: Dict[str, List[str]], task_id: str, judge_model: str, filename: str = None, results_folder: str = None) -> str:...model_names = list(model_results.keys())base_headers = ['序号', '类型', 'query']if mode == 'objective':base_headers.append('标准答案')# 动态生成模型相关的列eval_headers = []for i, model_name in enumerate(model_names, 1):eval_headers.extend([f'{model_name}_答案',f'{model_name}_评分',f'{model_name}_理由'])if mode == 'objective':eval_headers.append(f'{model_name}_准确性')headers = base_headers + eval_headers
8. 指标与可视化:从结果CSV到“讲故事”的页面
指标最终要“被看懂”。在结果页,我们提供了三种层次的信息:
- 基础统计:题量、模型数、列出模型;
- 模型表现:均分、分数分布、样本数;
- 对比与趋势:模型排名、胜负矩阵、题型分布(结合
type字段)。
当高级统计不可用时,系统会自动生成“基础统计后备方案”,保证页面可用:
if not advanced_stats:print(f"📝 [Results统一查看] 生成基础统计数据作为后备方案")...for model in model_columns:model_scores = []...if model_scores:advanced_stats['score_analysis']['model_performance'][model] = {'mean_score': sum(model_scores) / len(model_scores),'avg_score': sum(model_scores) / len(model_scores),'score_count': len(model_scores),'scores': model_scores}
9. 口径统一与复现性:把“为什么这么判”写进系统
“能复现”是评测系统的生命线。我们从三个方面保证复现性:
- 评分口径可配置:文件级自定义与系统默认提示词清晰可查;
- 结果结构稳定:每次评测输出的列字段遵循同一规则;
- 元信息保存:开始/结束时间、题量、文件大小、模型列表记录在案,支持回溯。
这意味着半年后你再回来,依旧可以知道“当时为什么这么判”“判了哪些维度”“用的是什么口径”。
10. 落地建议:把指标从文档搬进系统
如果你正准备把“目标与指标”落进一个评测系统,我的建议是:
- 先定角色与场景:明确主要用户是谁、用系统做什么;
- 明确评测对象与粒度:数据列、题目、模型、模式;
- 设计指标维度:能力/稳定/时延/成本/安全/本地化;
- 口径系统化:提示词成为可配置实体,并形成默认与文件级两级机制;
- JSON 契约化:裁判输出JSON化,解析失败兜底但绝不“悄悄忽略”;
- 流水线工程化:上传—并发执行—评分—落库—可视化—导出—分享;
- MVP 边界清晰:先把90%最常用的路打通,再优化;
- 数据长期主义:历史记录、权限与可见性、共享能力从第一天就准备;
- 可观测性留钩子:日志、进度、错误、限流参数,后续接入看板;
- 报告自动化与生态:把“讲故事”变成系统能力(第11和第12篇)。
12. 小结与展望
本篇从“谁在用、评什么、怎么量化、如何落地”四个层面把目标与指标说清楚,并与代码实现做了锚定:提示词是第一公民、JSON 是硬约束、并发与进度是工程保障、历史与共享是协作基石。下一篇(第 03 篇)我们将进入“架构落地”,把目录分层、路由与模板协作、评测引擎的原型路径讲清楚,并结合代码走一遍“从一张白纸到第一版可用原型”的过程。
—
附:相关文件与锚点
routes/evaluation.py:评测蓝图、任务状态、结果查看与评分编辑;utils/evaluation_engine.py:并发评测、提示词获取、JSON 协议与兜底;app.py:应用入口、全局蓝图注册、任务发起 API;services/model_api_service.py:API Key 管理的保存与校验;templates/results.html:结果页与统计模块;database/与database.py:数据持久化与历史记录相关接口。