TGRS2025 | 视觉语言模型 | 文本驱动自适应网络实现高光谱跨场景零样本分类

TGRS2025 | 视觉语言模型 | 文本驱动自适应网络实现高光谱跨场景零样本分类
论文信息
**题目:**Text-Driven Adaptive Semantic Alignment Network for Cross-Scene Hyperspectral Image Classification
**出版:**TGRS
**日期:**2025-03-06
第一作者:Wenzhen Wang
**通讯作者: **Liang Xiao
**单位:**Nanjing University of Science and Technology
原文有丰富的实验细节以及模型解释,原文链接:TASA-Net
一、总结
1.1 概述
-What is the problem
不同场景中的土地覆被一般表现出场景不变的类别语义,通常以文本方式进行一致的表示和描述。
传统的跨场景分类方法通常将类别视为离散的类标签,忽略了其语义信息,或仅将类别名称作为辅助文本模态来增强土地覆被的判别表征。
然而,土地覆被类别语义的跨场景一致性仍未得到充分探索和利用。
-What is the work
为解决这一问题,本文提出了文本驱动自适应语义对齐网络(TASA-Net),用于跨场景高光谱图像分类。
-Features of the work
TASA-Net 利用手工制作的模板提示进行稳定的类别描述,并利用视觉引导的精细语义提示进行动态场景适应。通过双门控自适应机制,TASA-Net 可在共享空间中优化粗粒度和细粒度语义的权重,从而确保稳定且具有区分度的语义表示。
此外,跨模态语义对齐将视觉特征投射到共享语义空间,而软对齐策略则动态调整类别相关性,以增强类内一致性并减轻领域偏移。
最终,通过利用文本驱动的语义一致性表示,TASA-Net 实现了无监督分类的零样本跨场景传输。
-Results
实验证明了该技术在多个高光谱数据集上的卓越性能,验证了文本模式在增强模型稳健性和跨场景泛化能力方面的关键作用。
1.2 创新点
- TASA-Net利用文本模式开发稳健的语义表征,以应对跨场景 HSIC 中的数据分布多样性和显著领域差异等关键挑战
- VG-FSP可从高光谱视觉特征中动态提取细粒度、场景自适应的类别描述,增强语义适应性。
- DG-ASR采用双约束动态融合策略,平衡细粒度视觉语义和粗粒度文本语义,确保跨场景变化下的稳健表示。
- TASA-Net 实现了无监督分类的零样本跨场景传输,极大地提升了在已知类别上应对真实世界复杂变化(光照、季节、地域、传感器差异等)的能力
1.3 主要成就
- 设计了一个视觉引导的精细语义提示模块,从高光谱图像的关键视觉表征中挖掘精细语义,动态生成适应场景的类别描述。这大大增强了语义表征在不同场景中的适应性和辨别能力。
- 提出了双门控自适应语义表征模块(dual-gated adaptive semantic representation module)和双约束动态融合策略(dual-constrained dynamic fusion strategy),可自适应地调整来自visual prompts的细粒度语义和来自textual prompts的粗粒度语义的权重,从而实现跨场景变化下的稳健语义表征。
- 通过在共享语义空间中对齐视觉和文本模态,这项工作可为类别生成自适应语义权重,从而支持跨场景的零样本传输任务,而无需明确的分类器或领域适应性优化。
1.4 核心思想
TASA-Net从高光谱视觉特征中动态提取细粒度语义,并与手工模板生成的粗粒度语义进行自适应整合,增强了不同场景中类别表征的一致性和可辨别性。
二、研究目标
核心目标: 提升高光谱图像在固定已知类别上的跨场景鲁棒性
- 将类别文本视为离散的类标签,忽略了其语义信息
⟹\Longrightarrow⟹ 将类别标签与prompt templates相结合
- prompt templates文本输入的粗粒度特性难以捕捉土地覆盖类别的深层语义信息
⟹\Longrightarrow⟹ 使用参数学习模型自动生成适合特定任务的文本描述
- 简单的类别标签生成的语义空间难以适应高光谱的复杂特性
⟹\Longrightarrow⟹ 视觉引导精细语义提示和prompt templates动态融合
三、研究的背景以及问题陈述
Introduction
CROSS-SCENE 高光谱图像分类(HSIC)旨在利用源场景中的高光谱数据和类别标签,训练出一个具有强大泛化能力的模型,从而在数据类别一致但分布不同的目标场景中实现精确分类。
核心挑战在于数据分布的多样性和场景之间的显著领域差异。
传统的单模态视觉方法在面对场景变化和类别分布变化时,往往难以保持稳定的分类性能。这是因为来自高光谱图像的视觉信息可能会受到光照、环境和分辨率等因素的影响,导致视觉表征出现显著偏差,从而降低模型的泛化性能。
相比之下,文本模式具有相对稳定的语义特征,受场景条件变化的影响较小。它可以为视觉模式提供额外的语义约束,提高模型理解和一致表示不同场景中土地覆被的能力。因此,将文本模式纳入跨场景 HSIC 具有显著优势。
本文研究主要涉及两个关键问题:
- WHAT: 与文本模态相对应的概念空间(concept space formulation)在 HSIC 任务中的恰当表述是什么?
- HOW: 文本模态如何有效地将其语义信息注入视觉模态?
Key1 有效概念空间表示:
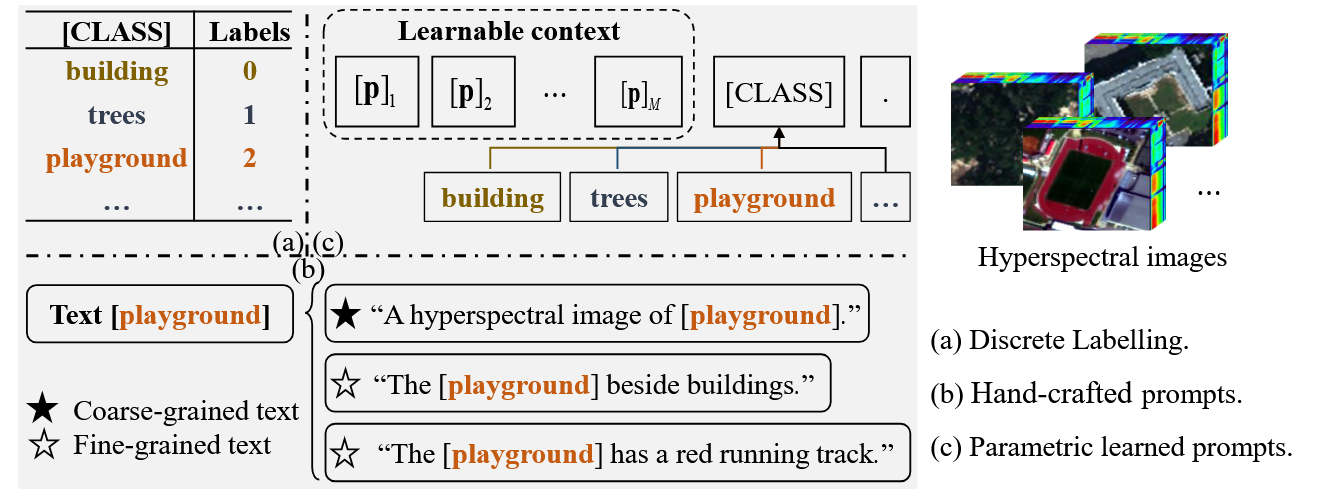
与高光谱图像相对应的文本模式类型。(a) 离散标签。文本类别标签被简单转换为离散标签,用于类别预测中的交叉熵损失计算。(b) 手工制作的prompt模板。类别标签与prompt模板相结合,以提供稳定的文本结构。© 参数学习提示。使用参数学习方法根据特定任务自动生成语义描述,以适应性地创建面向任务的文本模态输入。
(1) 在土地覆盖分类中,文本模态主要表现为类标签(如 “操场”、“建筑物”、“树木”),它们承载着土地覆盖对象的基本语义信息。
然而,在传统的视觉分类方法中,这些文本标签往往被简单地转换为离散标签(如图 1 (a)所示),在类预测中仅用于计算交叉熵损失。虽然这种方法在分类任务中具有一定的实用性,但它忽略了类别标签中包含的大量潜在语义信息,限制了模型理解和概括深层语义概念的能力。
(2) 受pretrained vision-language model启发,整合文本模态的多模态学习日益成为 HSIC 领域的研究热点。如图 1 (b)所示,许多研究将类别标签与prompt templates相结合,作为文本输入,提供稳定的语义结构。例如,"A hyperspectral image of [CLASS]."被用作模板,其中[CLASS]代表特定的类标签。这种方法为视觉模态提供了统一的语义背景,有助于模型更好地理解类别特征。
然而,由于模板的粗粒度特性,捕捉土地覆被的深层语义信息具有挑战性。因此,一些研究人员建议使用更精细的手工文本描述来优化类别的语义空间。通过为每个类别添加详细的语义描述,例如为 "playground"标签添加"The [playground] has a red running track."的详细描述,模型可以获得更丰富的语义信息,提高适应不同场景的能力。
(3) 不同的文字描述可以从不同角度表现同一幅高光谱图像,可能会强调土地覆被的不同特征或环境背景,如形状、颜色或空间位置。虽然手工制作的多样化文本描述丰富了土地覆被对象的语义信息,但也带来了巨大的设计成本和主观性。
为了解决这个问题,有些研究探索了自适应提示生成方法 ,如图 1 © 所示。这些方法使用参数学习模型,自动生成适合特定任务的文本描述,动态创建符合任务需求的文本输入。这避免了手工设计的主观性和局限性,生成的任务相关描述增强了文本和视觉模式之间的协同作用,提高了模型在复杂场景中的性能。
然而,由于高光谱图像的高维性和复杂性,高光谱图像通常比其相应的文本类别标签包含更丰富的语义。此外,同一土地覆被类别在不同场景中可能表现出不同的光谱和空间特征,这使得简单的类别标签生成的语义空间难以适应这些变化,并降低了泛化能力。
Key2 有效visual-text融合:
根据文本信息如何作用于视觉表征,文本数据和高光谱图像的多模态学习方法可归纳为三种范式:模态融合、模态交互和模态对齐。
(1) 模态融合范式是最常见、应用最广泛的范式,它利用文本模态作为辅助信息来丰富高光谱图像的视觉表征。通过concatenation, weighted averaging, attention mechanisms将特征结合起来,两种模态创建联合表征,从而增强对土地覆被对象的多模态理解。例如,FUS-MAE 方法如图 2 (a)所示,它对高光谱图像(文本标签)进行mask操作,以联合数据重建,从而实现深度多模态数据融合。这种模式主要是为了提高图像分类和物体检测性能,但可能无法彻底解决不同模态之间的深层次差异,尤其是当场景发生重大变化时。
(2) 模态交互范式通过交叉注意力机制或生成模型,促进文本与视觉图像之间的动态信息交换和转换。在这里,文本模态不仅能丰富视觉表征,还能引导视觉解码或文本生成,广泛应用于 image captionin and visual question answering等任务中。例如,DiffusionGeo 方法(如图 2 (b)所示)通过生成模型将文本描述转化为具有指定语义的高光谱图像,从而在跨模态任务中建立更深层次的交互。虽然这种范式在生成任务中表现出色,但它对分类任务的直接贡献相对有限,尤其是在处理跨场景的领域转换方面。
(3) 在模态对齐范式中,文本模态对齐高光谱图像的视觉表征,旨在将两种模态映射到一个共享的表征空间,以实现语义对齐。常见的方法包括对比学习或近邻聚类,可改善图像检索或文本图像匹配等跨模态任务。例如,图 2 ©所示的 RemoteCLIP 通过对比学习,在共享嵌入空间中对齐图像和相应文本,从而提高跨模态一致性和可解释性。这种范式对跨场景任务特别有效,因为它直接解决了跨场景视觉表征固有的不一致性问题。它减少了领域差异的负面影响,同时利用文本模态的稳定语义特征作为锚,引导不同场景中土地覆被对象的一致表征。然而,**仅仅关注将细粒度文本描述与视觉图像对齐可能会限制模型推广到不同文本描述的能力。**因此,基于这一范式的模型必须在文本描述多样性和一致性之间取得平衡,同时确保跨场景任务的泛化能力,以增强适应性和鲁棒性。
因此,我们的研究重点是利用文本模式开发稳健的语义表征,以应对跨场景 HSIC 中的数据分布多样性和显著领域差异等关键挑战。为此,本文特别提出了文本驱动自适应语义对齐网络(TASA-Net)。
首先,TASA-Net将不同场景中同一类别的特征多样性纳入语义空间构建中,根据光谱特征、空间关系和其他视觉语境生成精细的语义描述。这种方法不仅能动态捕捉高光谱图像中的复杂内容,还能为跨场景土地覆被表征提供更强大的泛化能力和一致性。
其次,TASA-Net采用双门控自适应策略,将视觉特征引导的细粒度语义与手工模板生成的粗粒度语义整合在一起,从而增强了不同场景中类别表征的一致性和可辨别性。
最后,该网络通过共享空间中的跨模态语义对齐机制,在未见(unseen)目标场景中实现了零样本转移分类。
四、模型详解
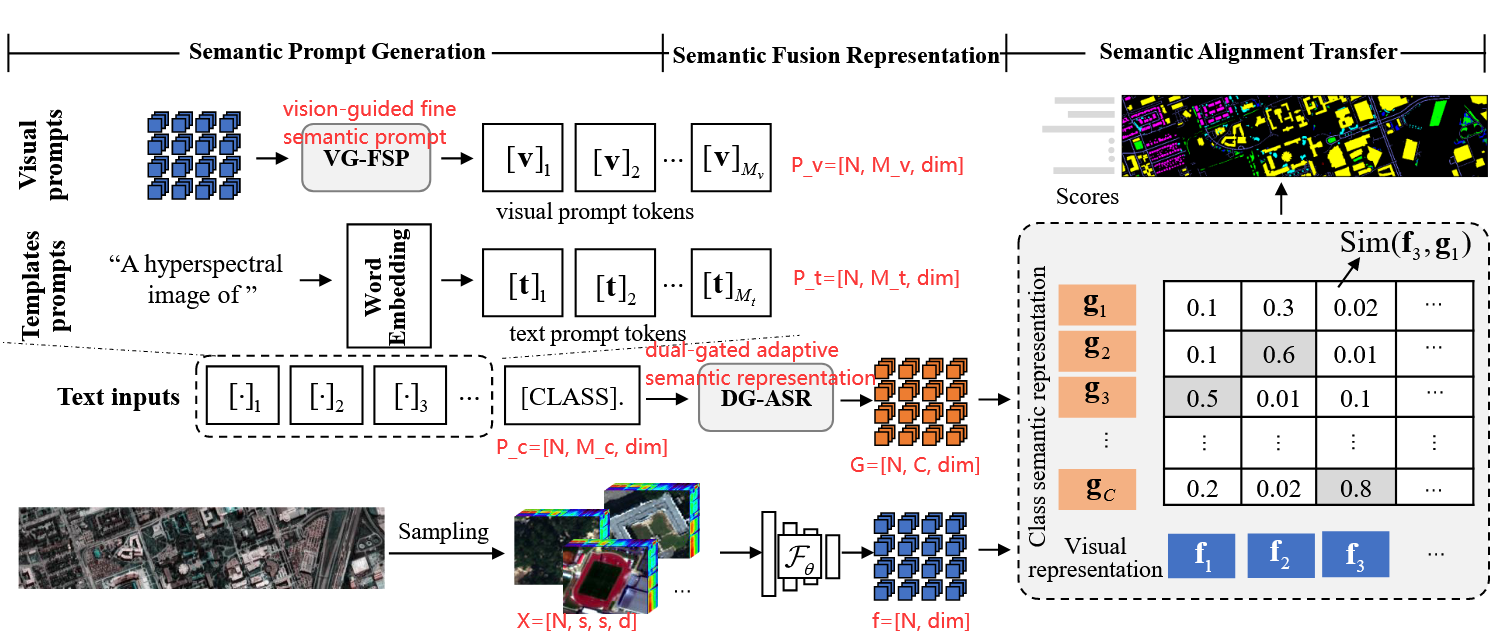
TASA-Net 流程图。
VG-FSP可从高光谱视觉特征中动态提取细粒度、场景自适应的类别描述,增强语义适应性。
DG-ASR采用双约束动态融合策略,平衡细粒度视觉语义和粗粒度文本语义,确保跨场景变化下的稳健表示。
这些模块共同实现了有效的语义对齐和转移,从而提高了分类性能。
4.1 概述
首先,在semantic prompt generation部分,统一的hand-crafted prompt模板和自适应生成的语境visual prompt优化了原始类别语义描述,增强了类别文本输入的稳定性和特异性。
其次,在semantic fusion representation部分,生成文本和视觉提示的类别语义描述以双门控自适应学习(DG-ASR)的方式进行整合,丰富了类别语义表征。
最后,semantic alignment transfer部分对视觉图像和类别文本的语义表征进行对齐,实现带有语义权重的转移和分类。
4.2 Semantic Prompt Generation
在Semantic Prompt Generation部分,进一步挖掘高光谱图像的光谱特征、空间关系和其他视觉上下文信息,为相应的类别标签生成精细的语义描述。此外,在类别文本的粗略语义描述中加入统一的手工制作的提示模板,以增强文本输入的稳定性。这种双提示方法进一步优化了语言与图像的一致性,确保了分类性能的稳健性和准确性。
1) Vision Prompts:
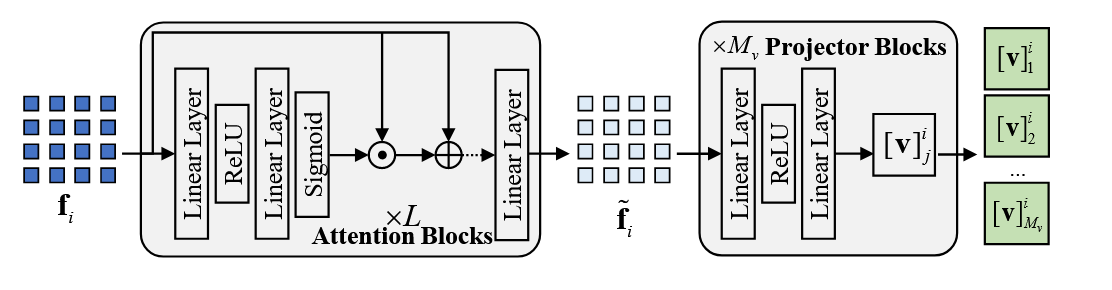
视觉引导精细语义提示(vision-guided fine semantic prompt, VG-FSP)模块。
通过多个注意力层提取高光谱图像特征,以捕捉关键的上下文信息。随后,多个投影块生成视觉提示标记,包含从高光谱图像补丁 XiX_iXi 中提取的精细语义描述信息,可动态生成更具指导性的分类文本视觉上下文提示。
2) Templates Prompt:
尽管视觉提示提供了精细的类别表示信息,但文本模板提示仍然必不可少。手工制作的模板为每个类别建立了一致的文本结构,增强了语义理解的一致性,并提供了一个稳定的文本框架,在不同场景和样本变化中保持更好的通用性。
Template: {"A hyperspectral image of xxx"}
4.3 Semantic Fusion Representation
为了实现视觉上下文提示和文本模板提示的高效融合,设计了一个双门控自适应语义表征(dual-gated adaptive semantic representation, DG-ASR)模块,以增强类别语义的辨别力和泛化表征能力。在该模块中,双约束动态融合策略(dual-constrained dynamic fusion strategy)可自适应地调整来自视觉上下文信息的细粒度语义和来自文本提示的粗粒度语义的权重,从而实现跨场景变化下的稳健语义表征。
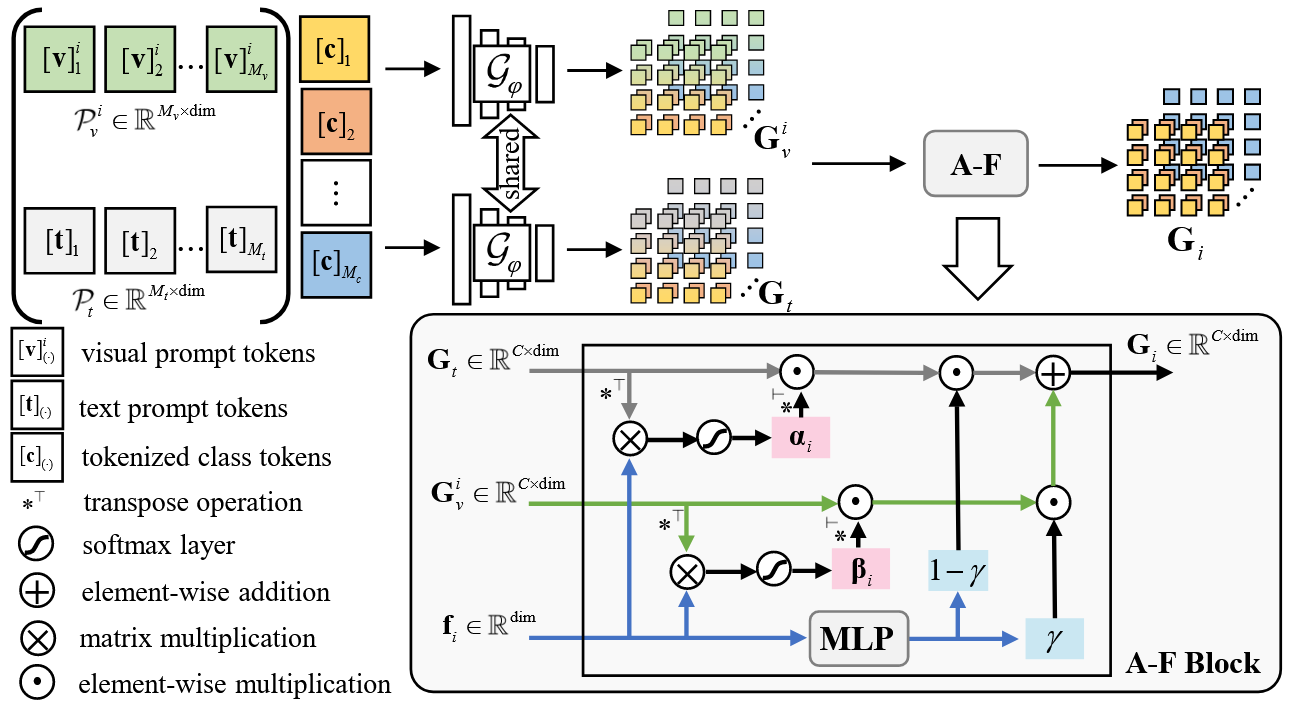
所设计的 DG-ASR 的enhancement-suppression weight架构。该机制可动态调整细粒度语义和粗粒度语义之间的权重,有效地融合视觉提示和类别文本提示,以提高跨场景土地覆被分类的鲁棒性和准确性。
1) Prompt-Based Semantic Encoding:
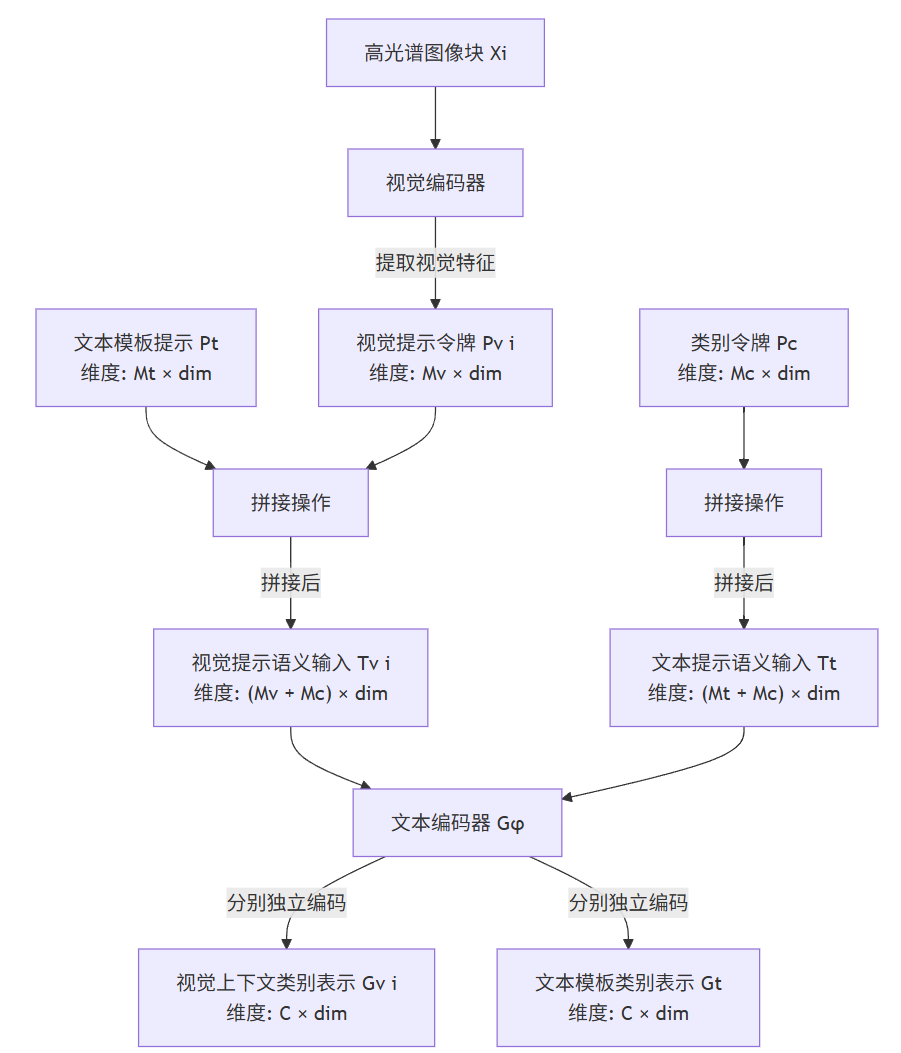
值得注意的是,动态生成的视觉提示标记与固定统一的文本提示标记一样,都会对每个类别标签的描述进行补充,即使当前视觉图像的类别是未知的。这一操作在为相同类别提供一致的详细信息的同时,也为不同类别引入了适当的扰动,从而增强了类别间的区分度。
2) Dual-Gated Adaptive Fusion:
产生的类别语义表征通过双门控自适应机制(A-F 模块)进行动态融合,采用了一种双约束自适应融合机制。它**可以调整从视觉提示中获得的细粒度语义和从文本提示中获得的粗粒度语义之间的融合权重。**这种调整以分类的不确定性和当前图像的视觉特征为指导,从而提高了跨场景 HSIC 的准确性和鲁棒性。
从本质上讲,我们希望视觉提示的细粒度语义能够捕捉局部语境和视觉细节。而当来自文本提示的粗粒度语义不足以进行准确分类时,它可以增强正确类别的语义匹配,同时削弱错误类别的匹配。为此,我们利用分类不确定性来定义这两种语义的增强-抑制权重(enhancement-suppression weight),动态调整它们对不同类别的贡献。分类不确定性由当前图像的视觉表示与所有类别的语义表示之间的相似性决定。
4.4 Semantic Alignment Transfer
本节通过视觉模态和文本模态之间的跨模态语义对齐,将视觉表征映射到共享的类别语义空间中。这种方法保持了不同场景中类别语义的稳定性,旨在减轻领域偏差对分类性能的影响。最后,通过为类别生成自适应语义权重,实现了跨场景的零样本转移。
1) Semantic Consistency Alignment:
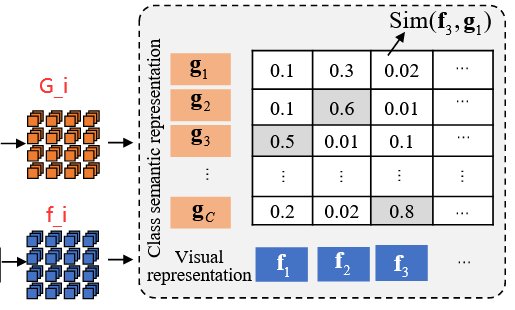
为了对齐视觉和文本模态,首先计算第 i 个Patch视觉表示$ f_i $与类别语义表示 GiG_iGi 之间的余弦相似度,从而得到第 i 个图像斑块与第 c 个类别语义之间的相似度。
Sim(f,G)=[N,C],N为样本数量,C为类别数Sim(f,G)=[N, C], N为样本数量,C为类别数 Sim(f,G)=[N,C],N为样本数量,C为类别数
传统的硬配准方法通常假定视觉特征与类别之间存在严格的一一对应关系,忽略了类内变化,从而限制了模型的泛化能力。相比之下,所提出的软配准机制(为稳定训练过程而引入的比例因子τττ)允许跨类别灵活匹配视觉表征,增强了对类内变化的适应性,同时减少了跨场景域转移效应。
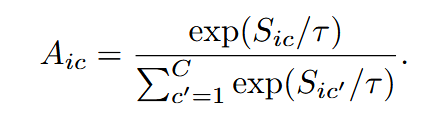
2) Zero-Shot Transfer:
我们的工作强调语义知识的跨场景适应性。在这里,语义权重矩阵不仅是已知类别的灵活匹配工具,也是可扩展到新场景的领域不变知识结构。通过使用生成的语义一致性表示,该模型在不同场景中保持了类别的高度概括性,具备了在未见场景中推断类别对齐的能力。
在推理过程中,目标场景的高光谱视觉图像被输入到模型中,模型根据当前视觉图像的上下文信息生成视觉提示语义。
然后与固定的文本模板语义融合,计算出与当前图像相对应的所有可能类别的语义空间。
最后,通过视觉嵌入和类别语义表征之间的相似性计算,选出概率最高的类别作为预测类别。
五、实验方法
5.1 数据集
(1) Houston 2013 and 2018:
Houston 2018 数据集作为目标场景,包含相同波长范围内的 48 个光谱带,空间分辨率为 1 米。为了对齐不同年份的场景,从Houston 2013 年数据集中提取了 48 个匹配的光谱带,并选择了一个 209×955 像素的重叠区域进行研究。两个数据集都包含7个一致的土地覆被类别。
(2) University of Pavia (PaviaU) and Pavia Center (PaviaC):
PaviaC作为目标场景; 为确保各场景光谱带数量的一致性,删除了 PaviaU 场景的最后一个光谱带,从而得到 103 个光谱带。两个场景都包含7个一致的土地覆被类别.
(3) HyRANK, Dioni and Loukia:
;Dioni 作为源场景,大小为 250×1376 像素;Loukia 作为目标场景,大小为 249×945 像素。两个场景都包含 12 个一致的土地覆被类别
5.2 实验设置
选取了两个无监督方法,五个cross-scene HSIC方法进行对比。
从训练集中**随机抽取 5%**的样本进行训练,并使用测试集中的所有样本进行模型评估。
在所提出的方法中,采用了双层3D residual CNN网络作为视觉编码器。考虑到计算复杂性,我们使用 CLIP 方法中文本编码器的前三层提取文本特征,并使用预训练的 ViT-B-32.pt 模型作为文本编码器的初始化。
对于休斯顿、帕维亚和 HyRANK 数据集,视觉引导细粒度语义提示模块中的注意块数量设置为 2,而投影块数量分别设置为 4、4 和 5。
模型输入的高光谱图像的Patch大小分别设置为 13、7 和 7,然后将"A hyperspectral image of [CLASS] "设计为文本提示模板。此外,还使用了 Adam 优化器,epochs 为 200,批量大小为 64,学习率分别为 0.01(Houston)、0.001(Pavia)和 0.001(HyRANK)。
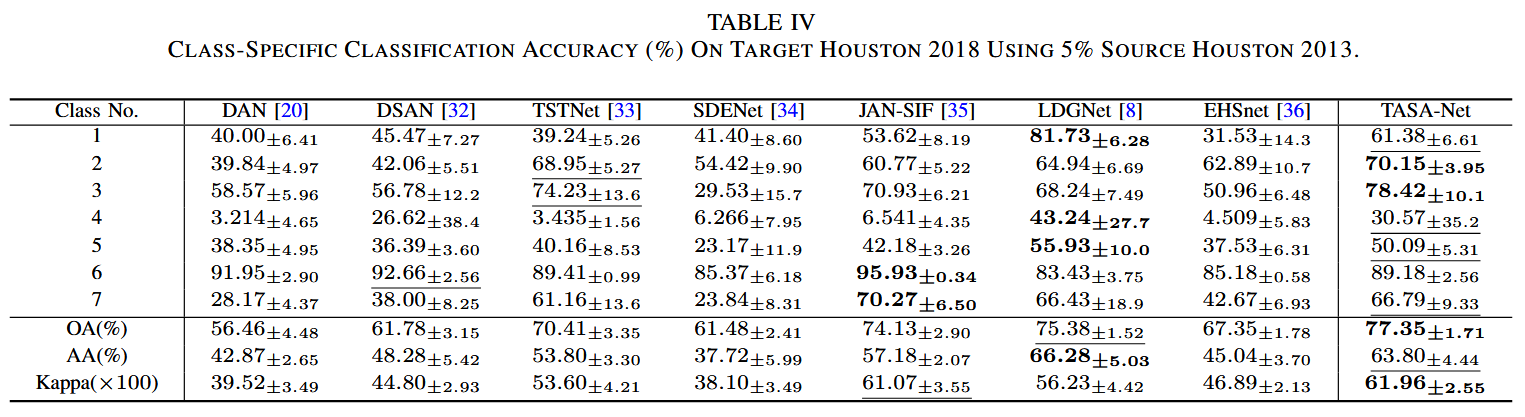
5.3 实验结果
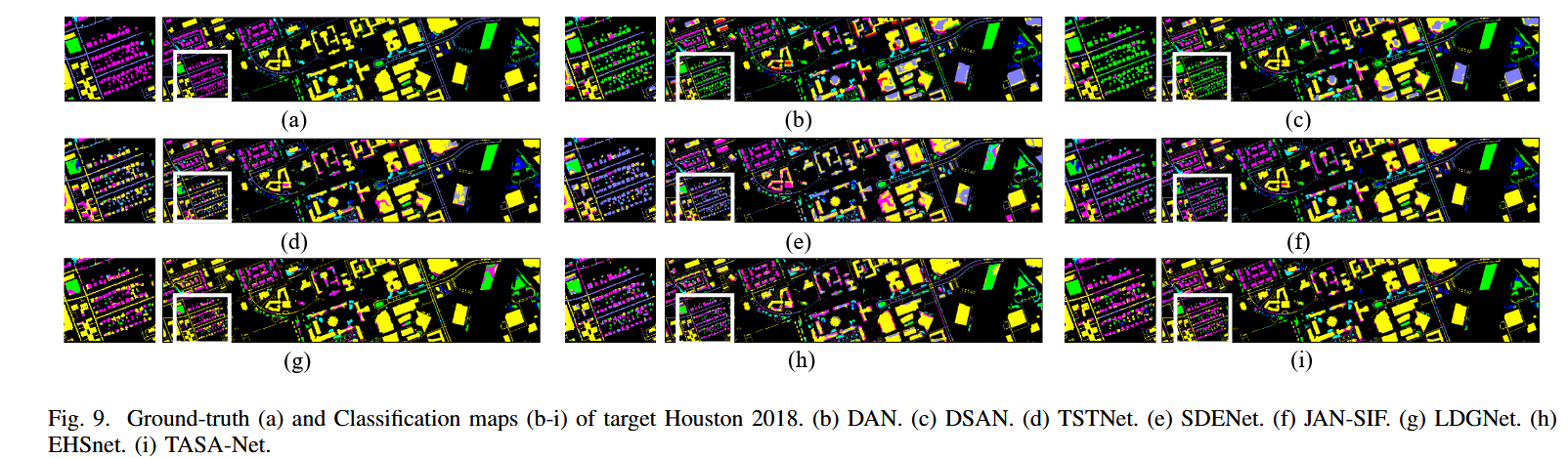
六、结论
本文介绍了名为 TASA-Net 的跨场景 HSIC 方法,强调了文本模态在应对跨场景挑战中的至关重要性。
通过整合手工制作的模板提示和视觉引导的精细语义提示,TASA-Net 可动态调整粗粒度和细粒度类语义,实现稳健的自适应语义融合。
此外,该模型还能在共享语义空间内调整视觉和文本模态,从而有效实现跨场景的零样本转移分类。在多个跨场景高光谱数据集上进行的广泛实验表明,TASA-Net 的性能明显优于现有方法,尤其是在解决边界模糊和分类语义相似类别方面。
然而,TASANet 在有效处理小样本类别方面仍面临局限,这突出表明需要进一步探索提高此类情况下性能的技术。
此外,所提出的方法基于一组封闭的类别构建语义空间,限制了其对开放世界场景的适应性以及有效识别未见类别的能力。**未来的研究可以探索更专业的遥感视觉语言模型,以加强跨场景分类,同时开发稳健的开放世界学习策略,以提高泛化性能和应用灵活性。