MIT新论文:数据即上限,扩散模型的关键能力来自图像统计规律,而非复杂架构
现在的文生图模型已经十分强大了,例如我们在输入框敲下 “a photorealistic astronaut riding a horse on the moon”,几秒钟后屏幕生成从未出现过的图像,细节丰富,几近完美。扩散模型(diffusion models)推动了这一切,早已将旧方法远远甩在身后。主流观点认为,这一成功依赖于像 U-Net 这类高度专门化的神经网络架构,以及它们内置的“归纳偏置”。但也许“魔法”并不在引擎,而在燃料:数据。
来自 MIT 与丰田研究院(Toyota Research Institute, TRI)的论文《Locality in Image Diffusion Models Emerges from Data Statistics(图像扩散模型中的局部性源自数据统计)》对这一说法提出挑战。作者给出证据表明,扩散模型一个被反复强调的属性——关注局部像素关系——并不需要依赖架构的巧妙设计,它可以从训练图像的统计规律中自然涌现。
“我们给出证据表明,深度扩散模型中的局部性,是图像数据集的统计属性所促成的,而不是卷积神经网络的归纳偏置所致。”
这意味着:模型并没有“发明”新的视觉范式,更像是把自然图像中最显而易见的统计模式学到了极致。下面我们详细说说这篇论文
我们以为的扩散模型工作
从清晰图像出发,逐步加噪直至完全随机;训练一个模型去逆转这个过程,逐步去噪,生成新图像。长期以来,U-Net 被视为是这里的主力,它承担“去噪器”的核心职责。我们也通常把它的“超能力”归因于架构:
- 局部性(Locality):卷积层像滑动的放大镜,以重叠小块处理图像,默认相邻像素的相关性更强。
- 平移等变(Shift Equivariance):同一只猫,放在左上角或右下角仍是猫。输入平移,表示随之平移,理解保持一致。
这些归纳偏置常被认为是模型在复杂视觉世界里“少走弯路”的关键。
“完美”的去噪器
扩散框架里存在一个理论上的“最优去噪器”。给定带噪声的图像,它能返回最可能的原始图像。但它对生成新图像没什么用,因为它是一个近乎完美的抄写者:在训练集中检索最近邻,然后再吐回去。它不会泛化、不懂组合与迁移,更像搜索引擎而不是生成模型者。你的数据里有猫和狗,它就能给你猫或狗,却永远想不出“狗猫”这个不存在的动物。
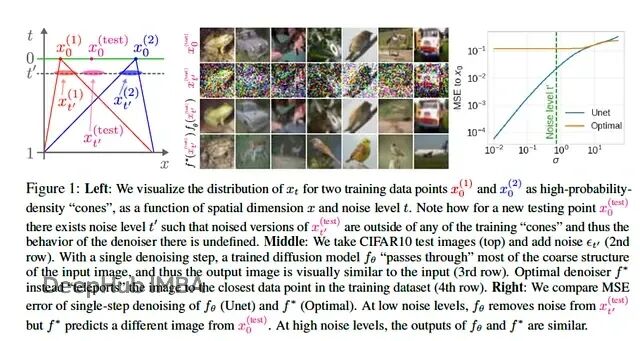
图 1,摘自论文。右侧的“最优”去噪器只是从记忆(训练集)里寻找最近的图像。深度去噪器会生成一个合理且新颖的图像。研究者试图解释的正是这两者之间的差距。
训练深度扩散模型(如 U-Net)的目标,是以一种“模糊”的方式逼近这一最优解,在保留统计一致性的同时获得创造性。这件事到底靠什么实现,一直是个谜。
关键不在发动机,而在燃料
MIT×TRI 的作者直接创建了一个几乎“反范式”的去噪器:不是深而复杂的网络,而是线性模型。它不内置任何关于局部性的假设,像一个“只看数据”的统计工具,唯一的任务是学习整个训练集里像素与像素之间的相关性结构。
如果 U-Net 像训练有素的画家,这个线性模型更像统计学家。它不懂“脸”是什么,但它知道两类像素几乎总是相邻(比如:眼睛与鼻子),另外一些几乎从不相邻(眼睛与鞋)。最终得到的结果是:这位统计学家的行为,越来越像那位画家。
让无形可见:它们到底“看”哪里
论文作者可视化了“去噪中心像素时,模型对其他像素的敏感度”——也就是所谓的敏感度场(sensitivity field)。先看标准 U-Net 去噪器的表现,高度局部。

图 2,摘自论文。热力图展示 U-Net 在为中心像素去噪时“看”的区域。关注呈现紧致、近似圆形的局部斑块,符合对深度去噪器局部性的共识。
再看一下没有任何局部性先验的线性模型:
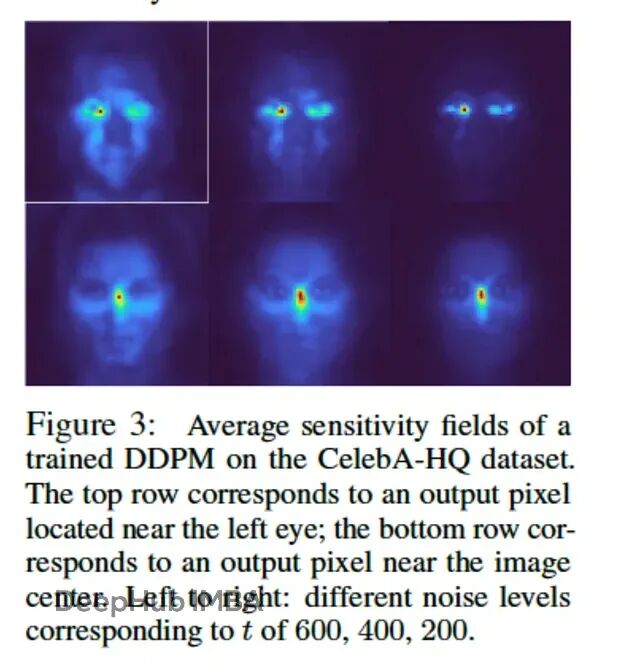
图 3,摘自论文。作者的简单线性去噪器仅凭数据统计就学会了“只看附近”。敏感度场与 U-Net 高度相似。
这就是论文的亮点时刻:不靠架构偏置,线性模型同样学到了“局部性”。原因不是架构多聪明,而是自然图像本身的统计规律推动了这种结果。天空总在地平线旁,眼睛总在鼻子附近,数据把答案写在了像素的联合分布里。
作者进一步在 CIFAR10(汽车、飞机等)上验证,敏感度场依然成立,有时甚至隐约勾勒出物体形状。
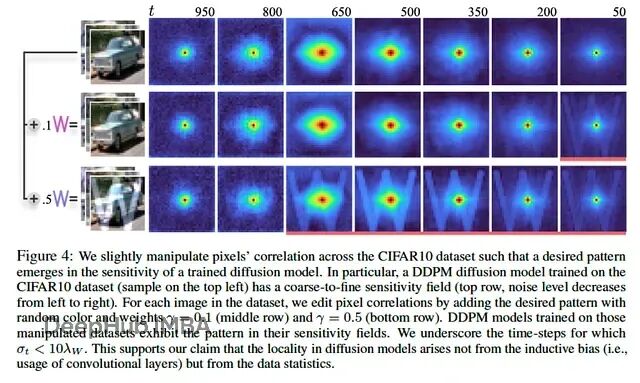
图 4,摘自论文。在 CIFAR10 上,敏感度场不只是一个斑块,而是有结构地反映了数据集的相关性。数据为王。
从统计到生成:简单模型能否“创作”
“聚焦”学会了,但是还能不能“生成”?作者把分析式(analytical)的线性模型与一个完全训练的最先进 DDPM 做了对比。

图 5,摘自论文。图中 “Wiener (linear)” 与 “Ours” 为解析型、数据驱动的模型。虽然不如完全训练的 DDPM 锐利,但生成结果结构稳定、语义轮廓清楚,并优于其他解析方法。
结果很直接:线性模型的图像偏模糊、细节不足,但并不是噪声,因为颜色、形状、纹理的基调是对的,面孔与动物的整体结构也站得住。这说明:生成中非常大的一部分,是可以仅从原始像素相关性中学习得到的,而不需要依赖手工设计的复杂架构。
对工程与产品的启示
在数据足够强的前提下,很多“归纳偏置”可能并非必要(这个好像ViT就已经验证了)。与其从复杂、难调的架构起步,不如先用更简单的模型把数据“看透”。用线性去噪器去体检数据集,先把统计结构摸清,再决定要不要堆更复杂的模型,这会更稳、更易调试、更可解释。
数据是第一资产。模型的智能上限和数据质量与统计属性呈强相关(还是数据为王)。
- 投入到数据策展。真正的壁垒往往不是最新模型,而是独特且干净的数据集。Garbage in, garbage out 从未过时。
- 直面数据偏差。模型会学到数据里所有的统计模式,包括不希望看到的那一类。
- 把数据当产品打磨。清洗、增强、分析统计属性,为其上的一切模型夯实地基。
总结
作者这次只看了二阶统计(像素两两相关)。高阶的统计(像素三元组、四元组)没准能继续放大简单模型的生成能力,这应该是论文可以后续进行研究的方向,这也说明了模型还是需要的。
另外换个角度看,“魔法”并不神秘:它是对视觉世界统计规律的大规模采样与利用。U-Net 与其说是天才画家,不如说是把统计学以深度方式高效落地的工具。论文的观点是这个“花哨”的工具都可能不是必需的,因为统计本身就足够强了。
这不是在贬低 DALL-E 3 或 Midjourney 背后的工程成就。而是重新界定“智能”的来源:也许我们会少花些时间在建造更华美的“教堂”(模型)上,而把更多精力用来理解石料(数据)的物性与纹理。这是不是也说明了现在的生成模型如果创造一个不存在的事物时通常不够好?
论文地址
https://avoid.overfit.cn/post/2de292b28a1c45a7859df94069855581
作者:Kaushik Rajan