小杰机器学习高级(four)——基于框架的逻辑回归
1. 实验原理
1.1 数据输入
本实验中,给出了如下两类散点,其分布如下图所示:
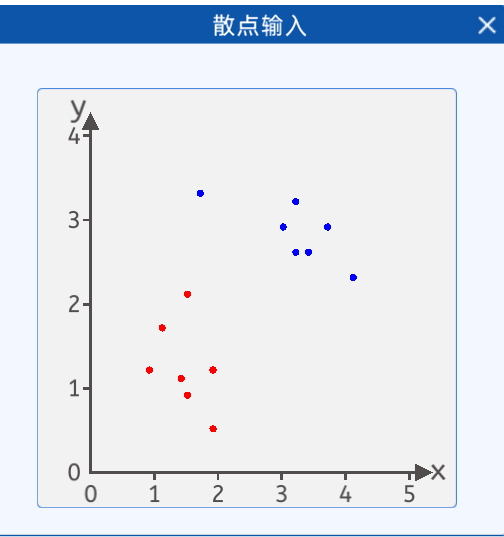
1.2 定义前向模型
准备好数据之后,接着就是定义前向过程,从上一章节可以知道,逻辑回归算法实现分类时,有两个输入特征,即公式为:![]() 。因此在“定义前向模型”组件中,需要保证输入特征数量为2,输出1个特征,使用Sigmoid()函数分成两类,即
。因此在“定义前向模型”组件中,需要保证输入特征数量为2,输出1个特征,使用Sigmoid()函数分成两类,即 ![]() 是一类,
是一类, ![]()
是一类。

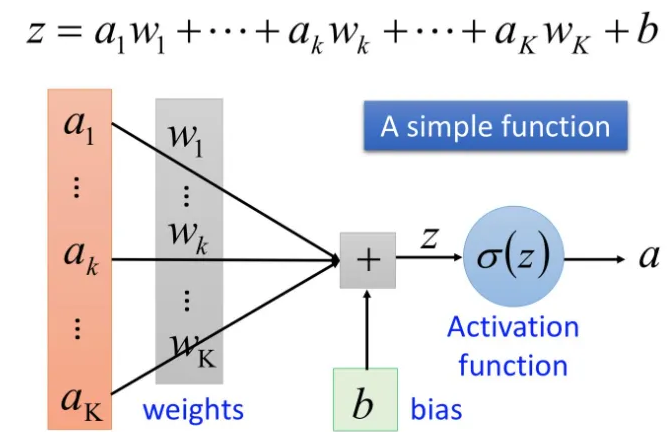
当输入是两个节点的时候,会有两个w1和w2
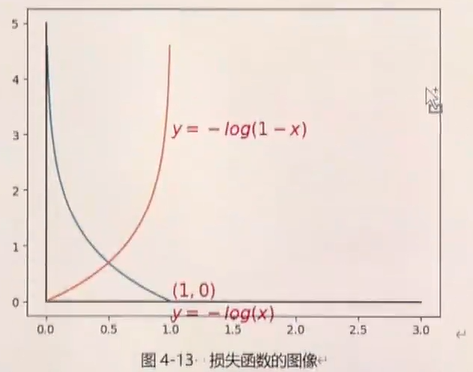
讲解一下为什么二元交叉熵为可以做损失函数?

讲解一下逻辑回归+二元交叉熵 和softmax+多分类交叉熵的区别?
逻辑回归+二元交叉熵
逻辑回归神经网络示意图
对计算出的结果结合二分类交叉熵进行计算损失。
eg: 实际标签为 0,预测值为0.1
计算方式:
![]()
eg: 实际标签为 1,预测值为0.8
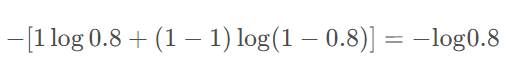
二分类交叉熵
在二分类情况下,模型最后需要预测的结果只有两种情况,对于每个类别我们的预测得到的概率为p和1-p,此时表示式为(log的底数为e):

softmax+普通交叉熵
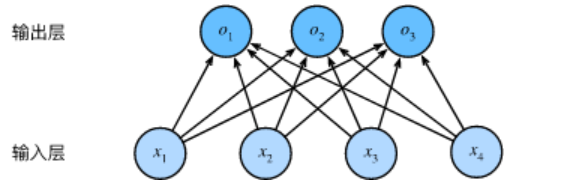
输出计算公式
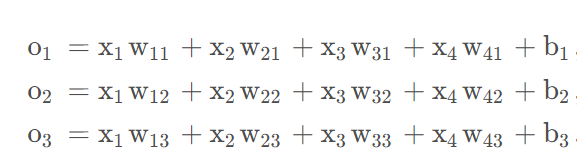
使用softmax对输出进行计算概率
对计算出的结果结合多分类交叉熵进行计算损失。
多分类交叉熵
多分类交叉熵就是对二分类的交叉熵的扩展,在计算公式中和二分类稍微有些区别,但是还是比较容易理解,具体公式如下所示:
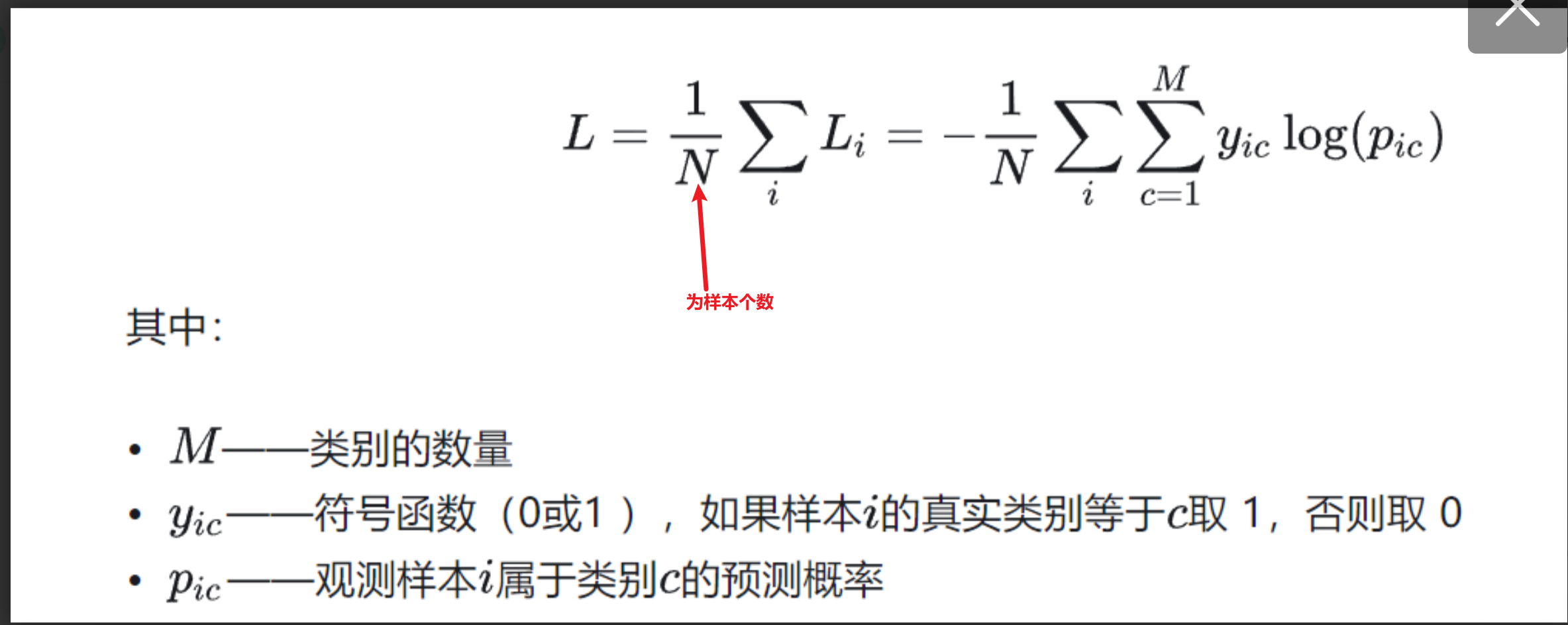
例子:
比如分三类有猫、狗、牛三类,真实标签是狗的话,可以表示为[0,1,0] onehot编码。真实标签是猫的话,可以表示为[1,0,0] onehot编码,真实标签是牛的话可以表示为[0,0,1]
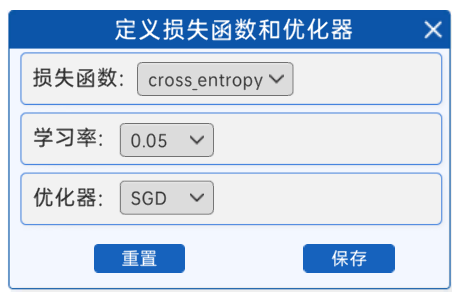
1.3 定义损失函数和优化器
在选择好前向模型后,需要接着选择使用哪种损失函数和优化器,在“定义损失函数和优化器”组件中,提供的损失函数是交叉熵,优化器是SGD(随机梯度下降),学习率有多个选项,比如0.5、0.1、0.05…,建议选择较大的学习率,可以很快获得分类结果。
1.5 更新模型参数并显示
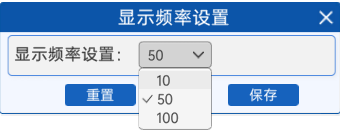
选择好迭代次数后,就需要设置一个显示频率,用来观察迭代过程中参数和损失值的变化,如下图所示:
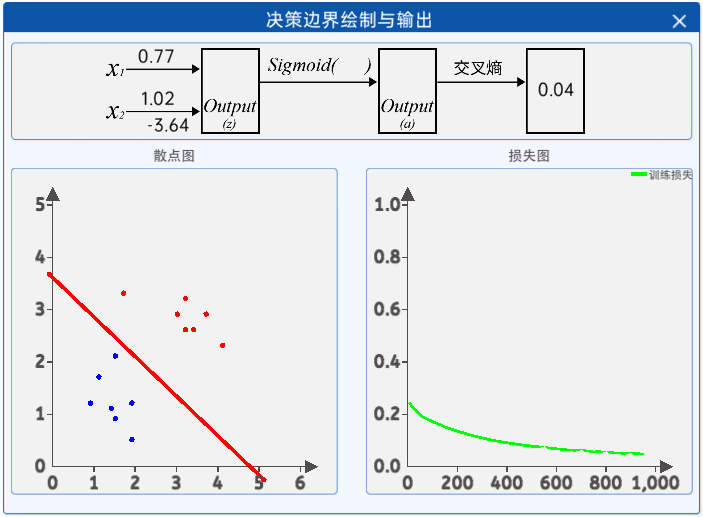
接着就是观察迭代过程中参数和损失值的变化,通过“决策边界绘制与输出”组件即可观察,其内容如下:

代码
pytroch 框架的逻辑回归(sigmoid)无图)
import torch
import torch.nn as nn
import numpy as np
import torch.optim as optimizer# 1.散点输入 包含蓝色点和红色点
class1_points=np.array([[1.9,1.2],[1.5,2.1],[1.9,0.5],[1.5,0.9],[0.9,1.2],[1.1,1.7],[1.4,1.1]])
class2_points=np.array([[3.2,3.2],[3.7,2.9],[3.2,2.6],[1.7,3.3],[3.4,2.6],[4.1,2.3],[3.0,2.9]])
#不用单独提取出x1_data和x2_data,框架会根据输入特征数自动提取
x_train=np.concatenate((class1_points,class2_points),axis=0)
y_train=np.concatenate((np.zeros(len(class1_points)),np.ones(len(class2_points))),axis=0)
#转成张量
x_train_tensor=torch.tensor(x_train,dtype=torch.float32)
y_train_tensor=torch.tensor(y_train,dtype=torch.float32)
print(y_train_tensor.shape)#定义前向传播模型
#设置一下随机数种子
seed=42
torch.manual_seed(seed)
class LogisticRegreModel(nn.Module):def __init__(self):#继承父类super(LogisticRegreModel,self).__init__()#定义层 全连接层self.fc=nn.Linear(2,1)def forward(self,x):x=self.fc(x)x=torch.sigmoid(x)return x
#实例化网络
model=LogisticRegreModel()
#定义损失函数
cri=nn.BCELoss()
#定义优化器
#学习率为超参数
lr=0.05
optimizer=optimizer.SGD(model.parameters(),lr=lr)#迭代
epoches=1000
for epoch in range(1,epoches+1):y_pre=model(x_train_tensor)#计算损失函数loss=cri(y_pre,y_train_tensor.unsqueeze(1))#反向传播和清理梯度optimizer.zero_grad()# 第二步反向传播loss.backward()#第三步参数更新optimizer.step()print(loss.item())pytroch 框架的逻辑回归(sigmoid)有图)
#导入包
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optimizer
import matplotlib.pyplot as plt
# 1.散点输入
class1_points=np.array([[1.9,1.2],[1.5,2.1],[1.9,0.5],[1.5,0.9],[0.9,1.2],[1.1,1.7],[1.4,1.1]])
class2_points=np.array([[3.2,3.2],[3.7,2.9],[3.2,2.6],[1.7,3.3],[3.4,2.6],[4.1,2.3],[3.0,2.9]])
#不用单独提取出x1_data 和x2_data
#框架会根据输入特征数自动提取
x_train=np.concatenate((class1_points,class2_points),axis=0)
y_train=np.concatenate((np.zeros(len(class1_points)),np.ones(len(class2_points))))
#转化为张量
x_train_tensor=torch.tensor(x_train,dtype=torch.float32)
y_train_tensor=torch.tensor(y_train,dtype=torch.float32)
print('s')
#2.定义前向模型
# 使用类的方式
# 先设置一下随机数种子
seed=42
torch.manual_seed(seed)
class LogisticRegreModel(nn.Module):def __init__(self):#继承父类super(LogisticRegreModel,self).__init__()#定义层 全连接层self.fc=nn.Linear(2,1)#定义forwarddef forward(self,x):x=self.fc(x)#调用激活函数sigmoid获得返回值x=torch.sigmoid(x)return x
#实例化网络
model=LogisticRegreModel()
#3.定义损失函数和优化器
# 导入优化器的包
#定义二分类交叉熵损失函数
cri=nn.BCELoss()
#定义优化器
#需要输入模型参数和学习率
lr=0.05
optimizer=optimizer.SGD(model.parameters(),lr=lr)
# 最后画图
fig,(ax1,ax2)=plt.subplots(1,2)epoch_list=[]
epoch_loss=[]
#4.开始迭代
epoches=1000
for epoch in range(1,epoches+1):y_pre=model(x_train_tensor)# cri前面是预测值,后面是目标值#将y_train_tensor 处理成和模型输出一样的维度loss=cri(y_pre,y_train_tensor.unsqueeze(1))#反向传播和优化# 第一步优化器清零optimizer.zero_grad()#第二步反向传播loss.backward()#第三步参数更新optimizer.step()if epoch%50==0 or epoch==1:print(f"epoch:{epoch},loss:{loss.item()}")w1,w2=model.fc.weight.data[0]b=model.fc.bias.data[0]#画左图# 使用斜率和截距画直线#目前将x2当作y轴 x1当作x轴# w1*x1+w2*x2+b=0#求出斜率和截距slope=-w1/w2intercept=-b/w2#绘制直线 开始结束位置x_min,x_max=0,5x=np.array([x_min,x_max])y=slope*x+interceptax1.clear()ax1.plot(x,y,'r')#画散点图ax1.scatter(x_train[:len(class1_points),0],x_train[:len(class1_points),1])ax1.scatter(x_train[len(class1_points):, 0],x_train[len(class1_points):, 1])#画右图ax2.clear()epoch_list.append(epoch)epoch_loss.append(loss.item())ax2.plot(epoch_list,epoch_loss,'b')plt.pause(1)pytroch 框架的逻辑回归(softmax)无图)
import torch
import torch.nn as nn
import numpy as np
import torch.optim as optimizer# 1.散点输入 包含蓝色点和红色点
class1_points=np.array([[1.9,1.2],[1.5,2.1],[1.9,0.5],[1.5,0.9],[0.9,1.2],[1.1,1.7],[1.4,1.1]])
class2_points=np.array([[3.2,3.2],[3.7,2.9],[3.2,2.6],[1.7,3.3],[3.4,2.6],[4.1,2.3],[3.0,2.9]])
#不用单独提取出x1_data和x2_data,框架会根据输入特征数自动提取
x_train=np.concatenate((class1_points,class2_points),axis=0)
y_train=np.concatenate((np.zeros(len(class1_points)),np.ones(len(class2_points))),axis=0)
#转成张量
x_train_tensor=torch.tensor(x_train,dtype=torch.float32)
y_train_tensor=torch.tensor(y_train,dtype=torch.long)
print(y_train_tensor.shape)#定义前向传播模型
#设置一下随机数种子
seed=42
torch.manual_seed(seed)
class LogisticRegreModel(nn.Module):def __init__(self):#继承父类super(LogisticRegreModel,self).__init__()#定义层 全连接层#使用softmax输出的特征为2self.fc=nn.Linear(2,2)def forward(self,x):x=self.fc(x)x=torch.softmax(x,dim=1)return x
#实例化网络
model=LogisticRegreModel()
#定义损失函数
cri=nn.CrossEntropyLoss()
#定义优化器
#学习率为超参数
lr=0.05
optimizer=optimizer.SGD(model.parameters(),lr=lr)#迭代
epoches=1000
for epoch in range(1,epoches+1):y_pre=model(x_train_tensor)#计算损失函数loss=cri(y_pre,y_train_tensor)#反向传播和清理梯度optimizer.zero_grad()# 第二步反向传播loss.backward()#第三步参数更新optimizer.step()print(loss.item())
pytroch 框架的逻辑回归(softmax)有图)
#导入包
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optimizer
import matplotlib.pyplot as plt
# 1.散点输入
class1_points=np.array([[1.9,1.2],[1.5,2.1],[1.9,0.5],[1.5,0.9],[0.9,1.2],[1.1,1.7],[1.4,1.1]])
class2_points=np.array([[3.2,3.2],[3.7,2.9],[3.2,2.6],[1.7,3.3],[3.4,2.6],[4.1,2.3],[3.0,2.9]])
#不用单独提取出x1_data 和x2_data
#框架会根据输入特征数自动提取
x_train=np.concatenate((class1_points,class2_points),axis=0)
y_train=np.concatenate((np.zeros(len(class1_points)),np.ones(len(class2_points))))
#转化为张量
x_train_tensor=torch.tensor(x_train,dtype=torch.float32)
#标签得是整型
y_train_tensor=torch.tensor(y_train,dtype=torch.long)
print('s')
#2.定义前向模型
# 使用类的方式
# 先设置一下随机数种子
seed=42
torch.manual_seed(seed)
class LogisticRegreModel(nn.Module):def __init__(self):#继承父类super(LogisticRegreModel,self).__init__()#定义层 全连接层 sigmoid的输出特征是1# 使用softmax编程输出特征是2self.fc=nn.Linear(2,2)#定义forwarddef forward(self,x):x=self.fc(x)#调用激活函数softmax获得返回值#dim指定softmax在那个维度进行softmax,等于1是第2个维度,列上进行softmax#保持每一行的列元素和为1x=torch.softmax(x,dim=1)return x
#实例化网络
model=LogisticRegreModel()
#3.定义损失函数和优化器
# 导入优化器的包
#定义多分类交叉熵损失函数
cri=nn.CrossEntropyLoss()
#定义优化器
#需要输入模型参数和学习率
lr=0.05
optimizer=optimizer.SGD(model.parameters(),lr=lr)
# 最后画图
fig,(ax1,ax2)=plt.subplots(1,2)epoch_list=[]
epoch_loss=[]
#4.开始迭代
epoches=1000
for epoch in range(1,epoches+1):y_pre=model(x_train_tensor)# cri前面是预测值,后面是目标值#将y_train_tensor 处理成和模型输出一样的维度loss=cri(y_pre,y_train_tensor)#反向传播和优化# 第一步优化器清零optimizer.zero_grad()#第二步反向传播loss.backward()#第三步参数更新optimizer.step()if epoch%50==0 or epoch==1:print(f"epoch:{epoch},loss:{loss.item()}")# 画左图# w是矩阵这里是2x2的矩阵# 直接画决策边界# 画决策边界需要数据ax1.clear()xx, yy = np.meshgrid(np.arange(0, 6, 0.1), np.arange(0, 6, 0.1))# 做成(x,y)对 前需要先对xx 和yy进行展平# 将输入的对象按照 np.c_ 按照第2个轴拼接grid_xy = np.c_[xx.ravel(), yy.ravel()]# print(xx)# 放进模型进行预测 前先转化为tensorgrid_xy_tensor = torch.tensor(grid_xy, dtype=torch.float32)y_pre = torch.softmax(model(grid_xy_tensor), dim=1)# 获得标签值# detach().numpy()用于将一个Tensor从计算图中分离出来,并将其转换为一个NumPy数组pre_lables = np.argmax(y_pre.detach().numpy(), axis=1).reshape(xx.shape)#画等高线ax1.contour(xx, yy, pre_lables)# 画散点图ax1.scatter(x_train[:len(class1_points), 0], x_train[:len(class1_points), 1])ax1.scatter(x_train[len(class1_points):, 0], x_train[len(class1_points):, 1])#画右图ax2.clear()epoch_list.append(epoch)epoch_loss.append(loss.item())ax2.plot(epoch_list,epoch_loss,'b')plt.pause(1)print('s')#5.显示频率设置
plt.show()
print('y')