基于AI分类得视频孪生鹰眼图像三维逆变换矫正算法
工具介绍
视频孪生为了将视频图像与三维引擎结合,同时将视频图像进行单帧矫正,再放入三维中,与三维结合,可以进行三维得旋转缩放,为静态得孪生系统增加了动态得视频。
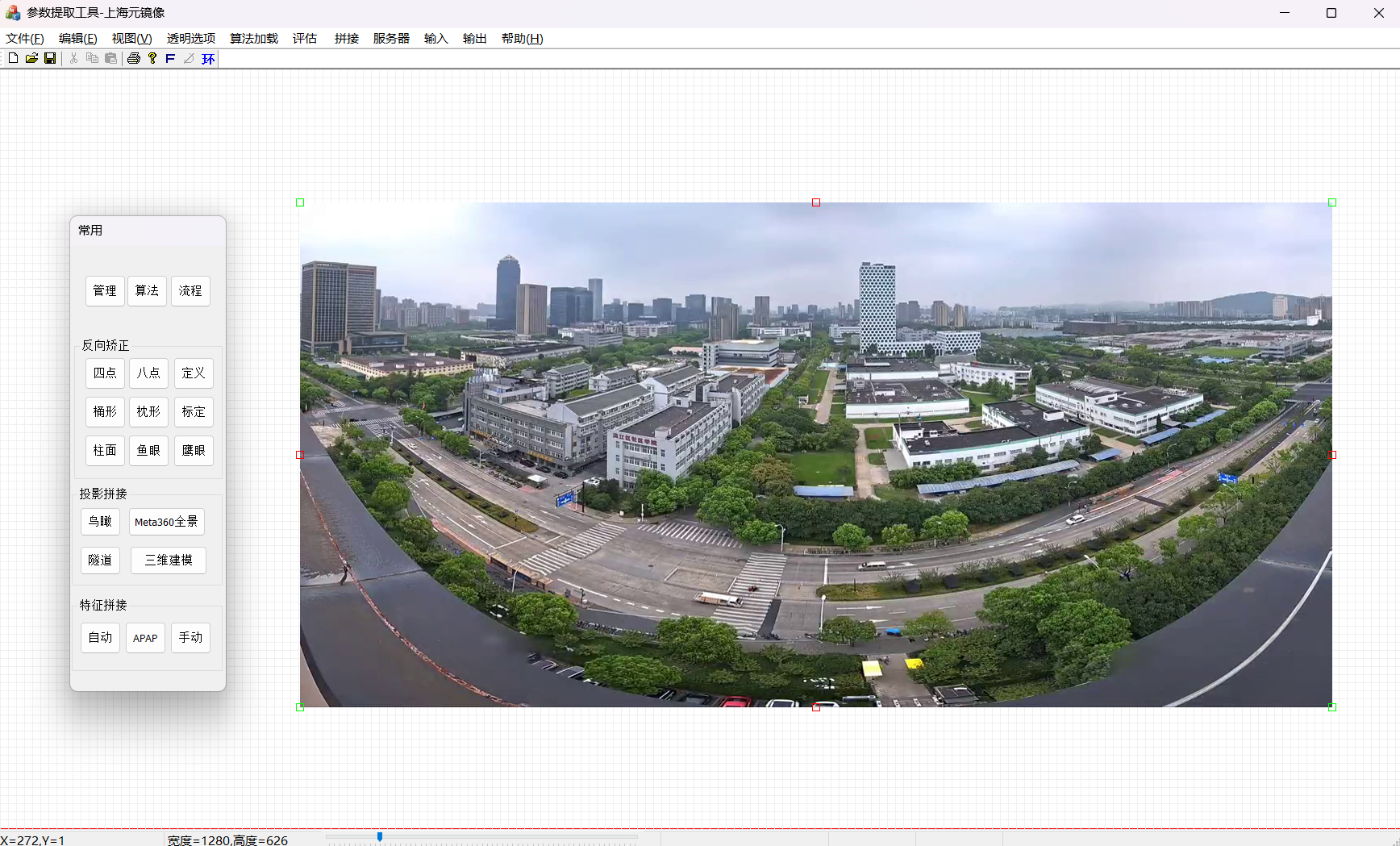
使用得三维投影矫正工具如下,内部定义了很多算法,根据AI来将不同得图像类型来分类,并且自动参数提取,我们来使用手动来做,最后再说明为何要使用AI?
1、室内鹰眼图像逆变换
我们来看室内得原图鹰眼图像

由于视野偏大,将走廊得两边都看到了,实际上这种鹰眼相机本身是拼接相机,我们来看看如何进行三维上得逆变换,需要进行三步做法:
- 1 三维球面投影 为了将y轴下方扩散得拼接左右直接投影缝合,这个必须在球面上做
- 2 柱面投影 为了将x轴视觉上弯曲得画面进行拉直
- 3 收缩投影 将发散得y轴上方进行投影收缩
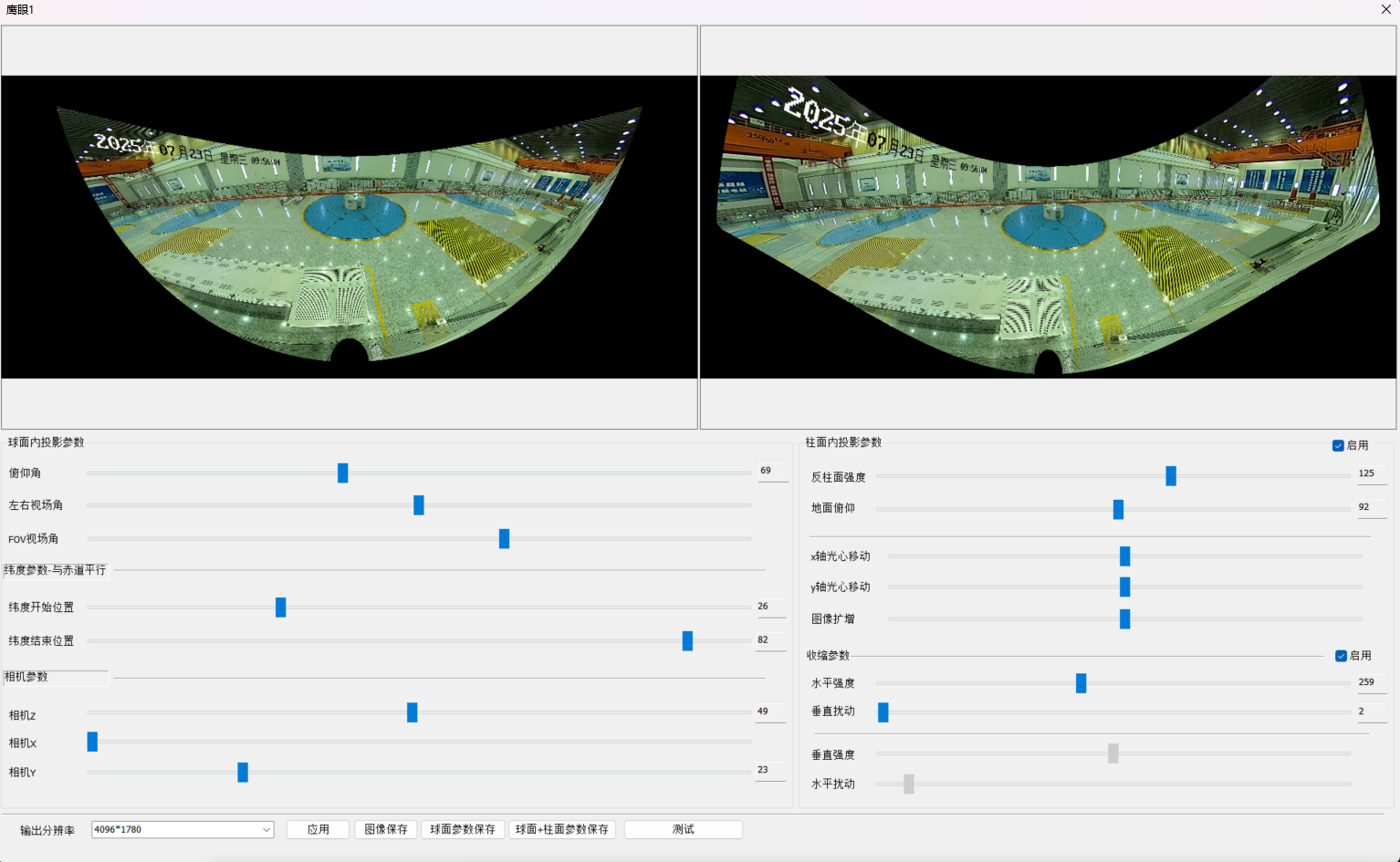

调整参数让鹰眼视频看清楚右边,由于现在程序还是不完善,
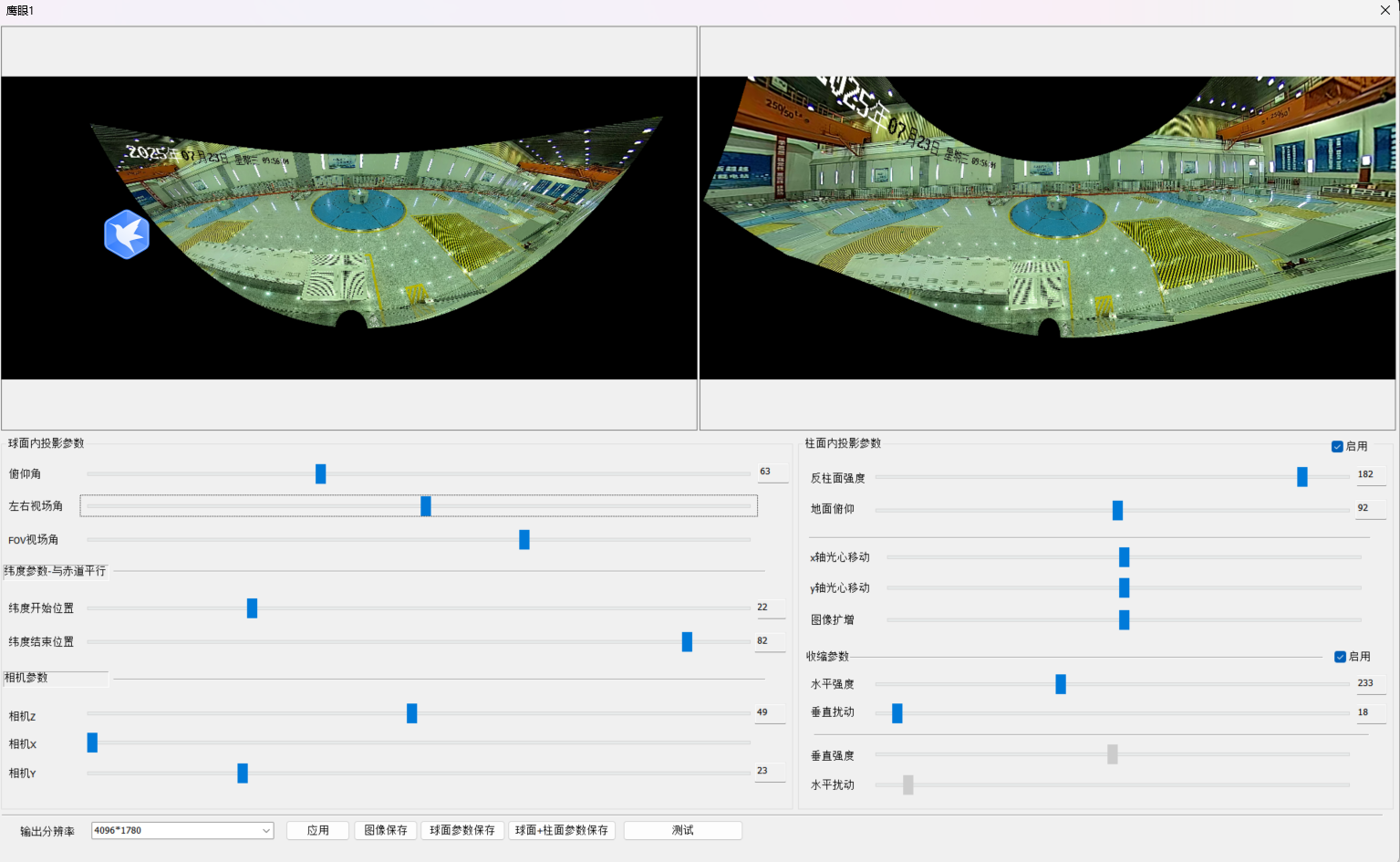

矫正前后比较,有瑕疵,不用纠结,没有好好拉参数,只是为了示意,这也说明了为什么要使用AI 来调整参数。

最后果然变成了一只飞鹰,名不虚传,重要得问题是:
- 1 参数非常多,非专业得人调整好比较难
- 2 图像类型特别多,可能不知道用什么方式来调整
2、室外鹰眼三维逆变换
观察下面这个这个图像,这是鹰眼相机在室外拍得,可以看到左右直得马路被弯曲了
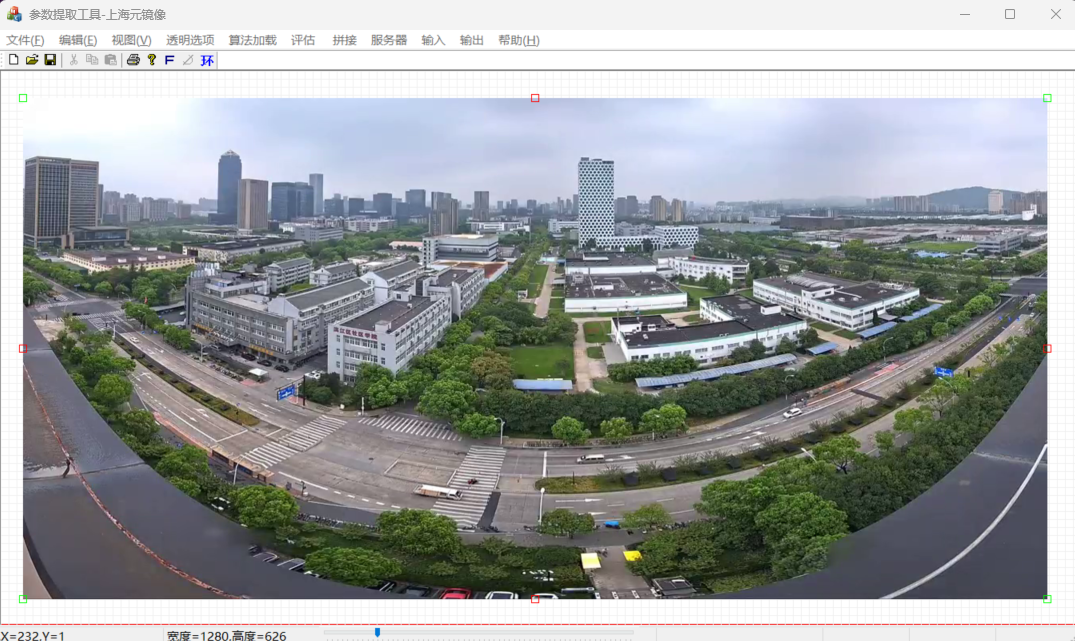
2.1 初步逆变换
球面逆变换
这个需要进行第一步得三维球形投影, 由于我们重点在马路上,接下去就是将马路拉直,如果不需要其他得,比如视频孪生得逆变换将马路放入三维模型,就可以将马路得画面截取出来,如果需要其他画面,我们继续进行逆变换

收缩逆变换
将扩散发散得远端重新逆向,恢复了近大远小得直线透视关系,注意我这里没有将摇摆角放入参数中考虑,画面稍有倾斜,因此矫正有瑕疵,忽略他,我们主要是为了讲清原理,收缩逆变换是将球面中发散倾斜得画面重新往回收缩。,保持中心不变。

图像裁切
根据孪生需要裁切图像

3、与AI 结合,自动调整参数
为什么要用AI结合
我们最终得目标一定是要去让AI来判别是什么样得图像,进行什么样得矫正, 以及使用什么样得参数是比较合适得,放入视频孪生时如何才是最合适得,这当然需要我们进行图像得收集和分类,训练AI来自行参数矫正和参数修订,从而能避免过多和复杂得手动参数选择,手动拉取参数确实是一种托底得保障,但是更好得是使用AI来选择参数,而人类只需要微调参数,我得做法是用几重神经网络来解决这个问题。
3.1 cnn分类网络
第一层网络采用轻量级 CNN 实现快速分类,将图像分成直线相机,枪机,鱼眼相机图像,鹰眼相机图像。枪机再分类成多种fov角度,鹰眼再分类成室内室外等多种模式,辅助图像分类得算法进行评估。
cnn 示例
import torch
import torch.nn as nn
import torchvision.transforms as transforms
from torch.utils.data import Dataset, DataLoader
from PIL import Image
import os# 数据预处理
transform = transforms.Compose([transforms.Resize((224, 224)),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])# 自定义数据集
class CameraDataset(Dataset):def __init__(self, root_dir, transform=None):self.root_dir = root_dirself.transform = transformself.classes = ['pinhole', 'fisheye', 'eagleeye']self.image_paths = []self.labels = []for label, cls in enumerate(self.classes):cls_dir = os.path.join(root_dir, cls)for img_name in os.listdir(cls_dir):self.image_paths.append(os.path.join(cls_dir, img_name))self.labels.append(label)def __len__(self):return len(self.image_paths)def __getitem__(self, idx):img_path = self.image_paths[idx]image = Image.open(img_path).convert('RGB')label = self.labels[idx]if self.transform:image = self.transform(image)return image, label# 轻量级分类网络
class CameraTypeClassifier(nn.Module):def __init__(self, num_classes=3):super().__init__()self.features = nn.Sequential(nn.Conv2d(3, 32, kernel_size=3, stride=2, padding=1),nn.ReLU(),nn.BatchNorm2d(32),nn.MaxPool2d(2),nn.Conv2d(32, 64, kernel_size=3, padding=1),nn.ReLU(),nn.BatchNorm2d(64),nn.MaxPool2d(2),nn.Conv2d(64, 128, kernel_size=3, padding=1),nn.ReLU(),nn.BatchNorm2d(128),nn.MaxPool2d(2),)self.classifier = nn.Sequential(nn.Flatten(),nn.Linear(128 * 14 * 14, 256),nn.ReLU(),nn.Dropout(0.5),nn.Linear(256, num_classes))def forward(self, x):x = self.features(x)x = self.classifier(x)return x# 训练代码示例
def train_classifier():train_dataset = CameraDataset('dataset/train', transform=transform)train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)model = CameraTypeClassifier()criterion = nn.CrossEntropyLoss()optimizer = torch.optim.Adam(model.parameters(), lr=1e-4)for epoch in range(20):model.train()total_loss = 0for images, labels in train_loader:optimizer.zero_grad()outputs = model(images)loss = criterion(outputs, labels)loss.backward()optimizer.step()total_loss += loss.item()print(f"Epoch {epoch+1}, Loss: {total_loss/len(train_loader):.4f}")torch.save(model.state_dict(), 'camera_classifier.pth')if __name__ == "__main__":train_classifier()
3.2 辅助图像分类评估算法
图像相似度 八种评估两幅图像相似度的指标实现方法,
- 均方根误差(RMSE)
- 峰值信噪比(PSNR)
- 结构相似性指数(SSIM)
- 基于信息论的统计相似性度量(ISSM)
- 特征相似性指数(FSIM)
- 信号重建误差比(SRE)
- 光谱角匹配器(SAM)
- 通用图像质量指数(UIQ)。
下面举例两种图像判别得算法:
1 均方根误差rmse ,rmse得公式为
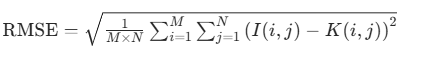
import numpy as np
import cv2def calculate_rmse(ref_img, dist_img):# 转换为float32类型并归一化到[0,1]区间ref = ref_img.astype(np.float32) / 255.0dist = dist_img.astype(np.float32) / 255.0# 计算均方误差并求平方根mse = np.mean((ref - dist) ** 2)rmse = np.sqrt(mse)return rmse# 示例用法
ref = cv2.imread("reference.jpg", cv2.IMREAD_GRAYSCALE) # 灰度参考图像
dist = cv2.imread("distorted.jpg", cv2.IMREAD_GRAYSCALE) # 失真图像
print(f"RMSE: {calculate_rmse(ref, dist):.4f}")
2. 峰值信噪比 psnr
(PSNR)定义:由均方误差(MSE)推导而来,用于衡量参考图像相对于失真图像的 “信号质量”。PSNR 值(单位:分贝,dB)越高,图像相似度越高。通常,PSNR > 30 dB 表示图像相似度良好。数学公式(\text{MAX}I):图像的最大像素值(8 位图像为 255)。(\text{PSNR} = 10 \times \log{10} \left( \frac{\text{MAX}_I^2}{\text{MSE}} \right))
Python 实现代码
def calculate_psnr(ref_img, dist_img, max_pixel=255.0):ref = ref_img.astype(np.float32)dist = dist_img.astype(np.float32)mse = np.mean((ref - dist) ** 2)if mse == 0: # 两幅图像完全相同return float('inf')psnr = 10 * np.log10((max_pixel ** 2) / mse)return psnr# 示例用法
print(f"PSNR: {calculate_psnr(ref, dist):.2f} dB")
3.3 畸变矫正网络
采用 U-Net 架构结合注意力机制,直接学习从畸变图像到矫正图像的映射,避免显式参数计算, 为了说明问题代码示例,当然代码需要和更多得参数进行结合,只是为了说明问题
import torch
import torch.nn as nn
import torch.nn.functional as Fclass AttentionBlock(nn.Module):def __init__(self, in_channels):super().__init__()self.conv = nn.Conv2d(in_channels, 1, kernel_size=1)self.sigmoid = nn.Sigmoid()def forward(self, x):attention = self.conv(x)attention = self.sigmoid(attention)return x * attentionclass DoubleConv(nn.Module):def __init__(self, in_channels, out_channels):super().__init__()self.double_conv = nn.Sequential(nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1),nn.BatchNorm2d(out_channels),nn.ReLU(inplace=True),nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1),nn.BatchNorm2d(out_channels),nn.ReLU(inplace=True))def forward(self, x):return self.double_conv(x)class Down(nn.Module):def __init__(self, in_channels, out_channels):super().__init__()self.maxpool_conv = nn.Sequential(nn.MaxPool2d(2),DoubleConv(in_channels, out_channels),AttentionBlock(out_channels))def forward(self, x):return self.maxpool_conv(x)class Up(nn.Module):def __init__(self, in_channels, out_channels, bilinear=True):super().__init__()if bilinear:self.up = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)self.conv = DoubleConv(in_channels, out_channels)else:self.up = nn.ConvTranspose2d(in_channels // 2, in_channels // 2, kernel_size=2, stride=2)self.conv = DoubleConv(in_channels, out_channels)self.attention = AttentionBlock(out_channels)def forward(self, x1, x2):x1 = self.up(x1)diffY = x2.size()[2] - x1.size()[2]diffX = x2.size()[3] - x1.size()[3]x1 = F.pad(x1, [diffX // 2, diffX - diffX // 2,diffY // 2, diffY - diffY // 2])x = torch.cat([x2, x1], dim=1)x = self.conv(x)return self.attention(x)class OutConv(nn.Module):def __init__(self, in_channels, out_channels):super(OutConv, self).__init__()self.conv = nn.Conv2d(in_channels, out_channels, kernel_size=1)def forward(self, x):return self.conv(x)class DistortionCorrector(nn.Module):def __init__(self, n_channels=3, n_classes=3, bilinear=False):super(DistortionCorrector, self).__init__()self.n_channels = n_channelsself.n_classes = n_classesself.bilinear = bilinearself.inc = DoubleConv(n_channels, 64)self.down1 = Down(64, 128)self.down2 = Down(128, 256)self.down3 = Down(256, 512)factor = 2 if bilinear else 1self.down4 = Down(512, 1024 // factor)self.up1 = Up(1024, 512 // factor, bilinear)self.up2 = Up(512, 256 // factor, bilinear)self.up3 = Up(256, 128 // factor, bilinear)self.up4 = Up(128, 64, bilinear)self.outc = OutConv(64, n_classes)# 相机类型嵌入层self.type_embedding = nn.Embedding(3, 64) # 3种相机类型self.type_fusion = nn.Conv2d(64 + 64, 64, kernel_size=1)def forward(self, x, camera_type):# 编码路径x1 = self.inc(x)# 融合相机类型信息type_feat = self.type_embedding(camera_type) # [batch_size, 64]type_feat = type_feat.unsqueeze(2).unsqueeze(3) # [batch_size, 64, 1, 1]type_feat = F.interpolate(type_feat, size=x1.shape[2:], mode='bilinear') # 匹配特征图尺寸x1 = torch.cat([x1, type_feat], dim=1)x1 = self.type_fusion(x1)x2 = self.down1(x1)x3 = self.down2(x2)x4 = self.down3(x3)x5 = self.down4(x4)# 解码路径x = self.up1(x5, x4)x = self.up2(x, x3)x = self.up3(x, x2)x = self.up4(x, x1)logits = self.outc(x)return logits# 训练矫正网络
def train_corrector():model = DistortionCorrector()criterion = nn.L1Loss() # 适合图像重建的损失函数optimizer = torch.optim.Adam(model.parameters(), lr=1e-4)# 假设已经有加载畸变/矫正图像对的DataLoader# train_loader = ...for epoch in range(50):model.train()total_loss = 0for distorted_imgs, corrected_imgs, camera_types in train_loader:optimizer.zero_grad()# camera_types是分类网络输出的相机类型标签outputs = model(distorted_imgs, camera_types)loss = criterion(outputs, corrected_imgs)loss.backward()optimizer.step()total_loss += loss.item()print(f"Epoch {epoch+1}, Loss: {total_loss/len(train_loader):.6f}")torch.save(model.state_dict(), 'distortion_corrector.pth')4、简单神经网络
除了u-net,我认为建立一个更简单得例如bp反馈网络来调整相机参数的思路是可行的,尤其适合处理参数维度不高的场景。这种 “参数预测” 思路相比端到端图像矫正更轻量,且能保留物理意义明确的相机参数. 是不是应该更方便和容易部署呢。
下面是示例代码
import numpy as np
import torch
import torch.nn as nn
from torch.utils.data import Dataset
import cv2# 假设需要预测的参数:针孔相机(k1,k2,p1,p2),鱼眼相机(k1,k2,k3,k4)
# 统一为6维向量(不足补0),便于网络通用化
class ParameterDataset(Dataset):def __init__(self, image_paths, param_list, img_size=(128, 128)):self.image_paths = image_pathsself.params = np.array(param_list) # 每行对应一个样本的参数self.img_size = img_sizedef __len__(self):return len(self.image_paths)def __getitem__(self, idx):# 读取并预处理图像img = cv2.imread(self.image_paths[idx])img = cv2.resize(img, self.img_size)img = img.transpose(2, 0, 1) / 255.0 # 归一化并转置为[C,H,W]# 获取参数(确保6维)params = self.params[idx]if len(params) < 6:params = np.pad(params, (0, 6-len(params)), mode='constant')return torch.FloatTensor(img), torch.FloatTensor(params)# 简单BP网络(全连接+卷积特征提取)
class BPParameterPredictor(nn.Module):def __init__(self, input_size=(3, 128, 128), param_dim=6):super().__init__()# 卷积特征提取self.features = nn.Sequential(nn.Conv2d(3, 16, kernel_size=3, stride=2, padding=1),nn.ReLU(),nn.MaxPool2d(2),nn.Conv2d(16, 32, kernel_size=3, stride=2, padding=1),nn.ReLU(),nn.MaxPool2d(2))# 计算特征维度(128→32→8→4,最终4x4特征图)self.fc_input_dim = 32 * 4 * 4 # 32通道,4x4尺寸# BP全连接层(参数预测头)self.regressor = nn.Sequential(nn.Linear(self.fc_input_dim, 128),nn.ReLU(),nn.Dropout(0.3),nn.Linear(128, 64),nn.ReLU(),nn.Linear(64, param_dim) # 输出6维参数)def forward(self, x):x = self.features(x)x = x.view(x.size(0), -1) # 展平特征params = self.regressor(x)return params# 训练代码
def train_bp_predictor():# 假设已准备好数据:图像路径列表和对应的参数列表# image_paths = [...] param_list = [[k1,k2,p1,p2,0,0], [k1,k2,k3,k4,0,0], ...]dataset = ParameterDataset(image_paths, param_list)dataloader = torch.utils.data.DataLoader(dataset, batch_size=32, shuffle=True)model = BPParameterPredictor()criterion = nn.MSELoss() # 回归任务用MSE损失optimizer = torch.optim.Adam(model.parameters(), lr=1e-4)for epoch in range(50):total_loss = 0for imgs, params in dataloader:optimizer.zero_grad()pred_params = model(imgs)loss = criterion(pred_params, params)loss.backward()optimizer.step()total_loss += loss.item()print(f"Epoch {epoch+1}, MSE Loss: {total_loss/len(dataloader):.6f}")torch.save(model.state_dict(), 'bp_param_predictor.pth')## 推理:用预测的参数进行矫正
def correct_with_params(image, pred_params, camera_type):h, w = image.shape[:2]# 相机内参矩阵(可固定fx/fy或同时预测,这里简化为已知)K = np.array([[w*0.8, 0, w/2], [0, h*0.8, h/2], [0, 0, 1]])# 根据相机类型选择畸变模型if camera_type == "fisheye":# 鱼眼模型:k1,k2,k3,k4dist_coeffs = pred_params[:4]corrected = cv2.fisheye.undistortImage(image, K, dist_coeffs, Knew=K)else:# 针孔模型:k1,k2,p1,p2dist_coeffs = pred_params[:4]corrected = cv2.undistort(image, K, dist_coeffs, None, K)return corrected
后记
还有很多需要做得,希望对视频和图像算法感兴趣得可以一起,加联系方式,研究更好得算法