RSS-2025 | 无地图具身导航新范式!CREStE:基于互联网规模先验与反事实引导的可扩展无地图导航
作者:Arthur Zhang, Harshit Sikchi, Amy Zhang, Joydeep Biswas
单位:德克萨斯大学奥斯汀分校
论文标题:CREStE: Scalable Mapless Navigation with Internet Scale Priors and Counterfactual Guidance
论文链接:https://arxiv.org/pdf/2503.03921
项目主页:https://amrl.cs.utexas.edu/creste/
代码链接:https://github.com/ut-amrl/creste_public
主要贡献
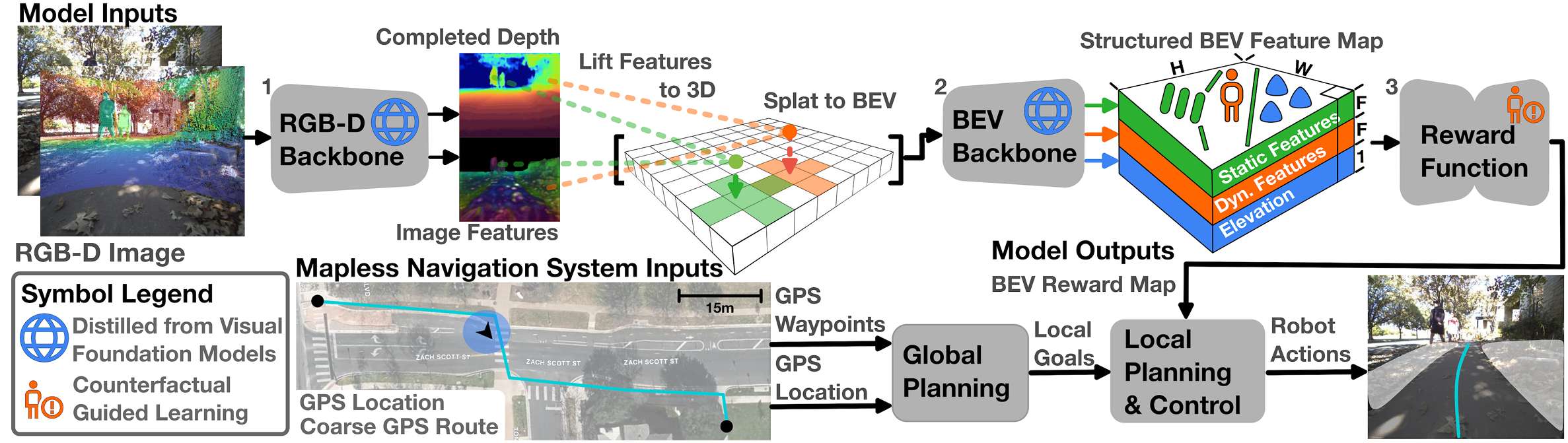
提出了可扩展的基于学习的无地图导航框架CRESTE,用于解决户外城市导航中的开放世界泛化和鲁棒性挑战。
提出了新的模型架构和蒸馏目标,用于从视觉基础模型中提取导航先验知识,学习开放集结构化的鸟瞰图(BEV)感知表示。
提出了一个主动学习框架和基于反事实的逆强化学习(IRL)公式,用于使用反事实和专家演示来对齐奖励函数。
研究背景
无地图导航任务是在没有高精地图和精确导航路点的情况下,仅依靠自身传感器(如RGB图像、点云、GPS)以及公共路径规划服务提供的粗略路点和卫星图像来规划路径,以到达用户指定的目标位置。这种导航方式具有可扩展性,能够泛化到未预见的因素(如路缘坡道和树叶)和动态实体(如行人和婴儿车),同时减少了地图维护开销和对预定义路线的依赖。
传统的仅基于几何的无地图导航方法在只考虑静态障碍物等几何因素时表现出良好的泛化能力,但在开放世界导航中,需要感知系统能够感知未知的开放集因素,包括地形偏好、语义线索等,并识别场景中最显著的特征及其对路径选择的影响。
基于学习的方法是一种可扩展的替代方案,需要克服数据稀缺性、鲁棒性和泛化挑战,以实现类似可靠性。现有的方法包括单因素感知、手工策划的多因素感知、端到端学习以及零样本预训练的大型语言模型(LLM)/视觉语言模型(VLM)迁移等,但这些方法都存在一定的局限性,如对未见类别泛化能力差、容易过拟合、对城市导航适应性差等问题。
无地图城市导航问题
无地图导航的路径规划
问题定义:在每个时间步,机器人根据当前观测 和全局坐标系中的姿态 ,规划一条从当前位置到目标位置 的有限轨迹 。目标是找到一个轨迹,使得最终状态 与目标位置 的距离最小化,并且路径规划的成本函数 也最小化。
成本函数:路径规划的成本函数 是一个加权的路径成本,其中权重为 。在城市环境中,由于机器人姿态 和目标 可能存在较大的噪声,因此 的重要性会随时间动态变化。
一般偏好对齐的成本函数
观测函数:定义了一个观测函数 ,将观测 映射到一个联合嵌入空间 ,这个空间包含了导航所需的一组相关因素。
成本函数的分解:成本函数 可以分解为几何成本、语义成本和社会成本的组合。这些成本函数分别考虑了路径的几何特性、语义信息(如道路类型、障碍物等)和社会规则(如行人优先等)。
真实成本函数:假设操作者有一个真实的成本函数 ,它将相关因素映射到标量成本值。这个函数通常是未知的,并且依赖于机器人的具体形态、环境和任务。
开放性挑战
学习感知表示:学习感知表示 是一个挑战,因为城市环境中导航所需的相关因素集合是未知的,并且这些因素之间的关系可能是高度非线性的。
学习成本函数:学习成本函数 也是一个挑战,尤其是在面对复杂的特征分布和非线性关系时。CRESTE通过从视觉基础模型中提取特征来学习感知表示,并提出了一种基于反事实的框架来学习成本函数。
方法
CRESTE模型架构
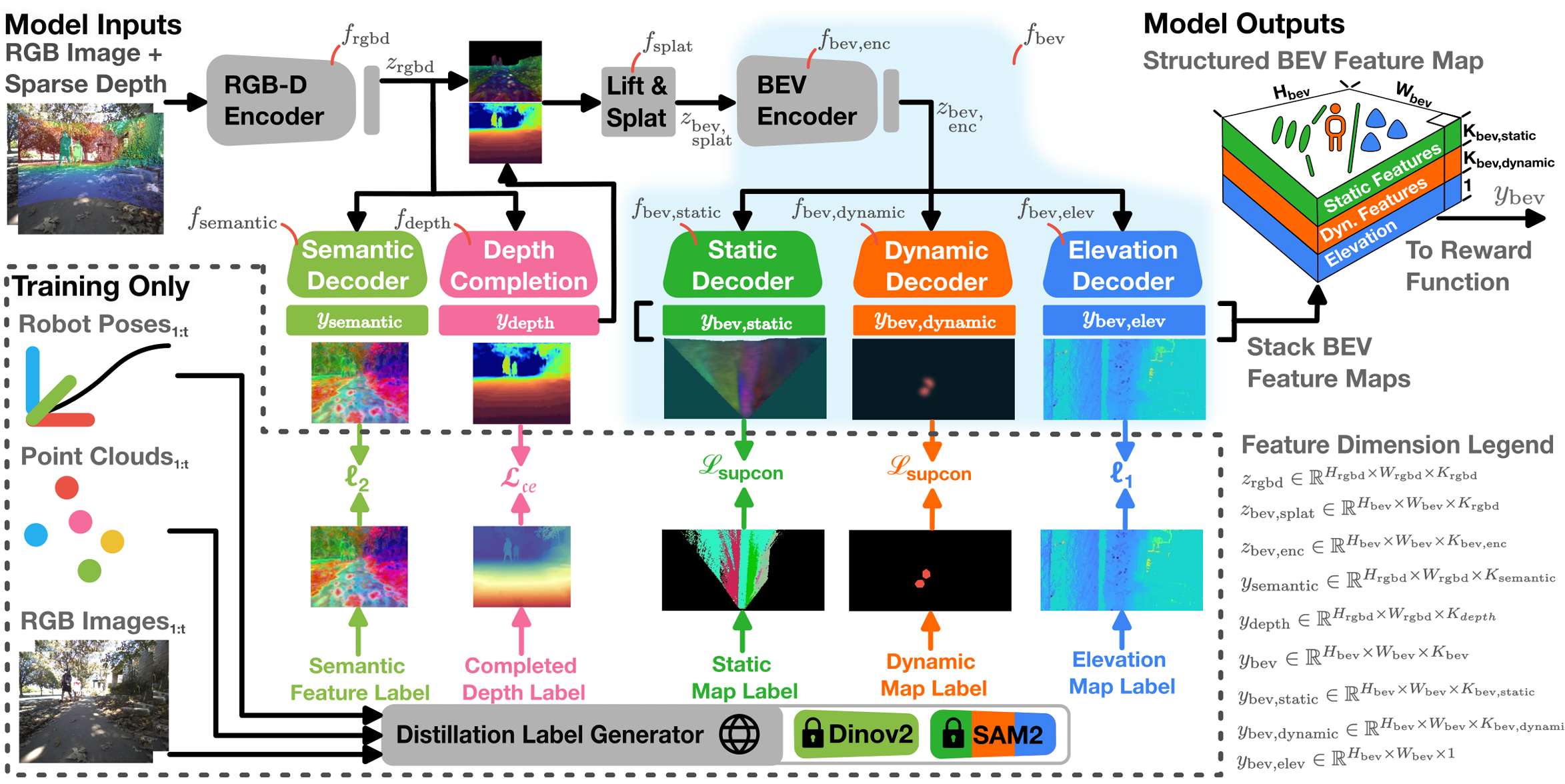
感知编码器模型架构
感知编码器 的目标是从机器人的当前 RGB 和稀疏深度观测中预测出完成的深度图像和结构化的鸟瞰图(BEV)特征图。其架构设计如下:
RGB-D 编码器():使用 EfficientNet-B0 作为基础架构,从 RGB 和深度图像中提取特征,生成一个潜在特征图 。
深度完成层():从 中预测出完整的深度图 。
提升和扩散模块():将 提升到 3D 空间,并将其“扩散”到一个非结构化的 BEV 特征图 。
BEV 修复骨干网络():使用共享的 U-Net 架构,将 修复为一个结构化的特征图,包含语义和高程层。
感知编码器的两个关键架构修改:
语义解码器():通过从 Dinov2 模型中回归图像特征,增强 RGB-D 编码器的语义和几何感知能力。这种设计类似于模型蒸馏,允许 RGB-D 编码器继承视觉基础模型(VFM)的属性,如对感知混淆的鲁棒性和开放集语义理解。
BEV 实例解码器( 和 ):确保预测的 BEV 特征图与 SegmentAnythingv2(SAM2)的 BEV 实例图一致。通过监督对比损失(Supervised Contrastive Loss)优化 ,使得属于同一实例的特征在嵌入空间中比属于不同实例的特征更接近。
最终,结构化的 BEV 特征图 由三个层组成:静态全景特征图、动态全景特征图和高程图。
奖励函数模型架构
奖励函数 的目标是将 BEV 特征图转换为标量奖励图。它使用多尺度全卷积网络(MS FCN)实现,以确保奖励函数具有空间不变性并考虑多尺度特征。奖励函数的输出是一个 BEV 标量奖励图 。
CRESTE训练过程
CRESTE 的训练过程分为两个阶段:首先优化感知编码器 ,然后冻结其参数,接着训练奖励函数 。整个学习目标可以表示为:
其中, 和 监督 的训练,而 监督 的训练。
训练感知编码器
感知编码器 的训练包括以下几个步骤:
RGB-D 编码器训练:通过语义解码器 和深度完成层 的反向传播来联合训练 。语义解码器使用均方误差(MSE)损失,深度完成层使用交叉熵分类损失。
其中, 和 是可调的超参数。
BEV 修复骨干网络训练:使用三个损失函数分别监督静态实例图、动态实例图和高程图的解码器层。使用监督对比损失(Supervised Contrastive Loss)来训练静态和动态实例图解码器,使用 L1 回归损失来训练高程图解码器。
其中,、 和 是可调的超参数。
为了可扩展地获得训练标签,论文设计了一个基于视觉基础模型(VFMs)的蒸馏标签生成模块,自动从序列化的 SE(3) 机器人姿态和同步的 RGB-点云对中生成训练标签。
训练奖励函数
在冻结感知编码器 后,使用基于反事实的逆强化学习(IRL)目标 来训练奖励函数 。反事实 IRL 的目标是最小化专家轨迹的回报,并确保次优轨迹的回报较低。这通过优化以下目标实现:
其中,、 和 分别表示专家、次优和当前策略的状态-动作访问分布, 是一个可调的超参数。
此外,论文提出了一个主动奖励学习框架,通过以下三个阶段迭代地从专家那里获取反事实标注,直到学习到的奖励函数与人类偏好对齐:
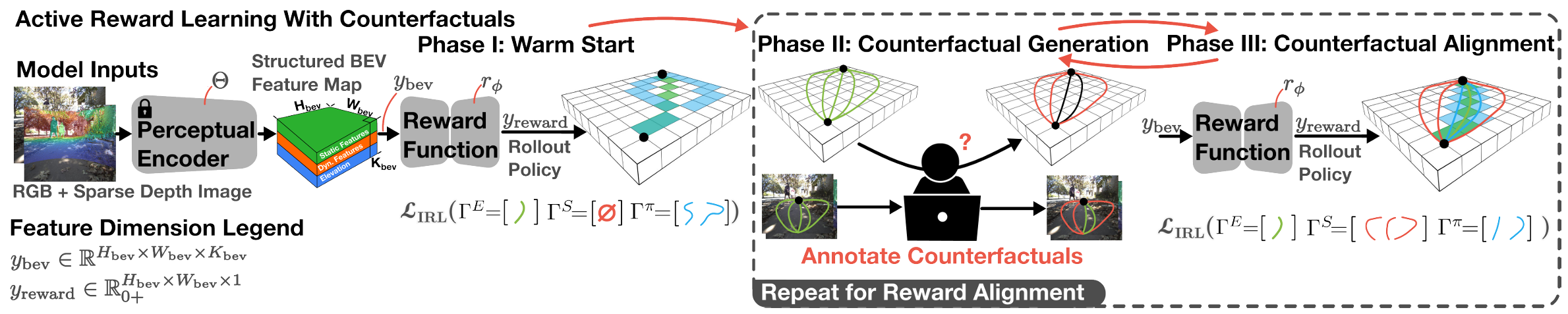
阶段 I:预热(Warmstart):仅使用专家演示来训练初始奖励函数。这可以通过将 设置为 0 来实现。
阶段 II:合成反事实生成(Synthetic Counterfactual Generation):使用学习到的奖励函数进行策略 rollout,并选择需要改进的训练样本。对于与专家演示差异较大的样本,生成候选轨迹,并由人类标注者选择违反偏好的轨迹作为反事实。
阶段 III:反事实奖励对齐(Counterfactual Reward Alignment):使用阶段 II 中的反事实标注和原始专家演示重新训练奖励函数。通过设置 为非零值来平衡它们的相对重要性。重复阶段 II 和 III,直到学习到的策略与专家行为收敛。
实现细节

全局规划模块:使用OpenStreetMap获取从用户指定的GPS终点到一系列粗略GPS子目标的路径。这些子目标每隔10米分布一次。通过计算机器人当前位置到终点以及每个子目标到终点的距离,选择距离终点最近且最远的子目标作为下一个局部规划的目标。
局部规划模块:采用动态窗口方法(DWA)风格的局部路径规划。通过枚举一组固定曲率的弧线(31条),从机器人自身坐标系出发,计算每条轨迹的成本。成本计算包括使用预测的奖励图计算的折扣成本,以及到达局部目标点的距离成本。通过调整这些成本的权重,选择成本最低的轨迹作为局部路径。
低级控制:使用一维时间最优控制方法生成低级动作,以跟踪选定的轨迹。
实验
论文通过一系列实验来评估CRESTE框架在无地图城市导航任务中的性能。实验旨在回答以下几个问题:
CRESTE在未见城市环境中进行无地图城市导航的泛化能力如何?
结构化的BEV感知表示对于下游策略学习的重要性如何?
反事实演示如何改善城市导航性能?
CRESTE在长距离无地图城市导航任务中与其他顶尖方法相比的表现如何?
机器人测试平台

实验使用Clearpath Jackal移动机器人进行,配备有RGB相机、3D激光雷达(LiDAR)和手机(用于获取GPS和磁力计读数)。机器人使用OpenStreetMap路由服务获取粗略导航航点。计算平台包括Intel i7-9700TE CPU和Nvidia RTX A2000 GPU。CRESTE以20Hz的频率运行,与以10Hz运行的无地图导航系统并行。

训练数据集
数据集包含3小时的专家导航演示,涵盖城市公园、市中心、住宅区和大学校园等多种环境。数据集还包括3%的反事实标注,用于训练CRESTE。数据集由同步的图像-LiDAR观测对和使用LeGO-LOAM算法计算的真实机器人姿态组成。
测试方法

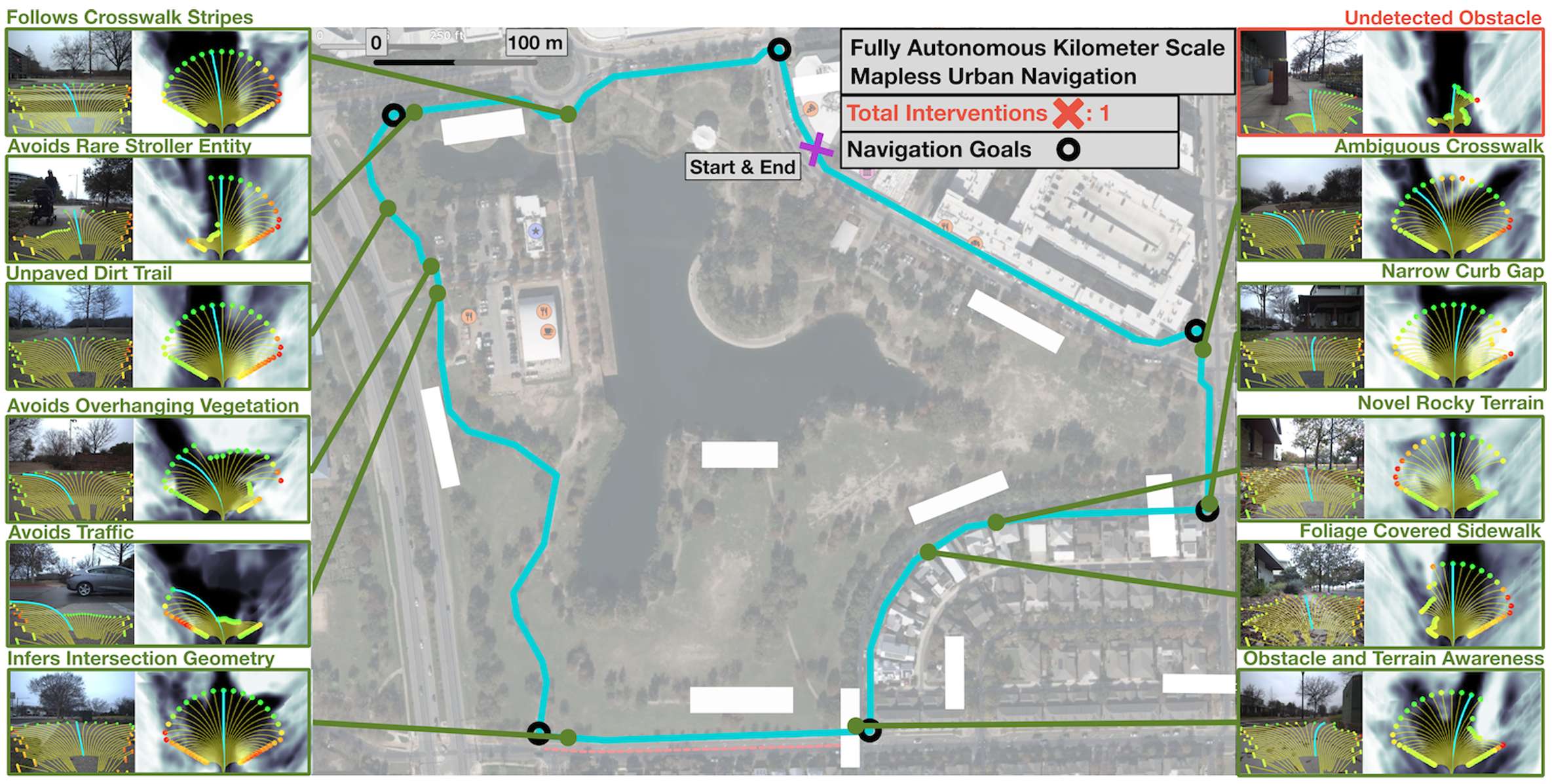
实验在城市环境中进行,包括短距离(约100米)和长距离(2公里)的无地图导航任务。测试地点包括2个已见环境和4个未见环境。对于每个方法,重复实验以评估性能。评估指标包括平均子目标完成时间(AST)、子目标到达百分比(%S)和每100米所需的干预次数(NIR)。
基线方法
论文将CRESTE与其他四种现有导航方法进行比较,包括:
ViNT:基于视觉的目标导航模型。
PACER+G:考虑地形和几何成本的多因素感知基线。
仅几何:仅考虑几何成本的DWA风格方法。
PIVOT:基于视觉语言模型(VLM)的导航方法。
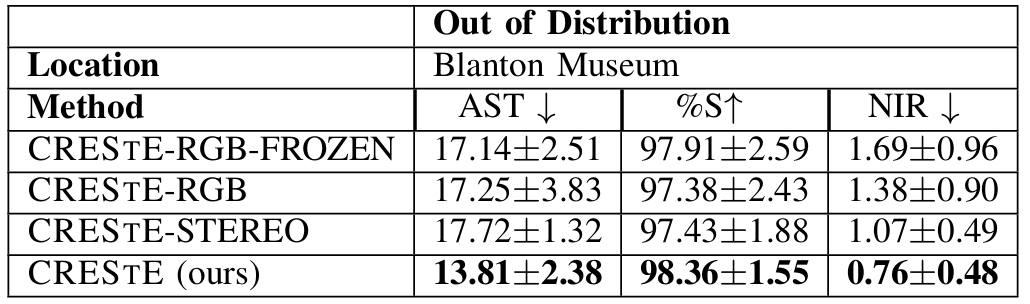
此外,论文还测试了CRESTE的不同变体,以评估不同输入模态和观察编码器的影响。
定量结果与分析
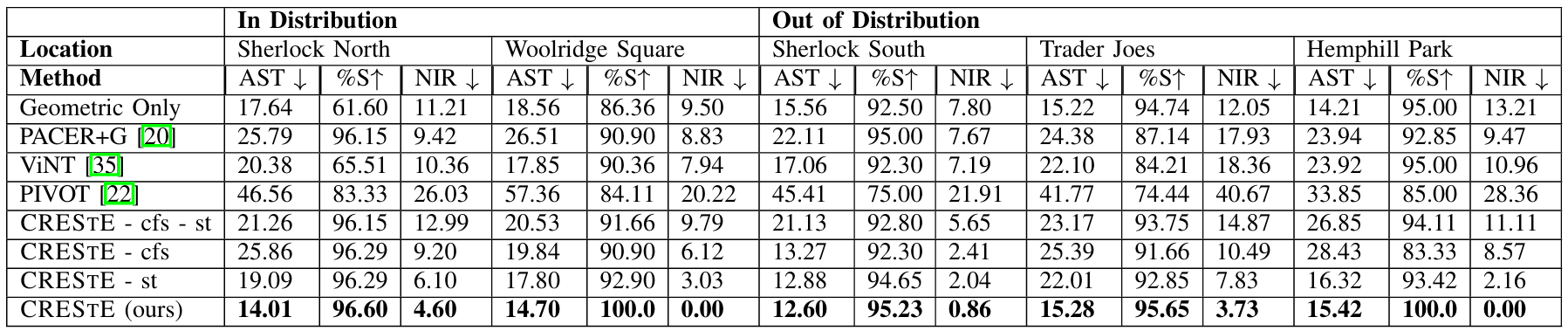
实验结果表明,CRESTE在所有评估指标上均优于现有方法。CRESTE在未见环境中表现出色,仅需少量干预即可完成任务。
此外,CRESTE的不同变体实验结果表明,使用RGB和LiDAR输入的CRESTE表现最佳,而仅使用RGB输入的变体在光照条件不佳时性能下降。
这些结果证明了CRESTE在无地图城市导航任务中的有效性和鲁棒性。

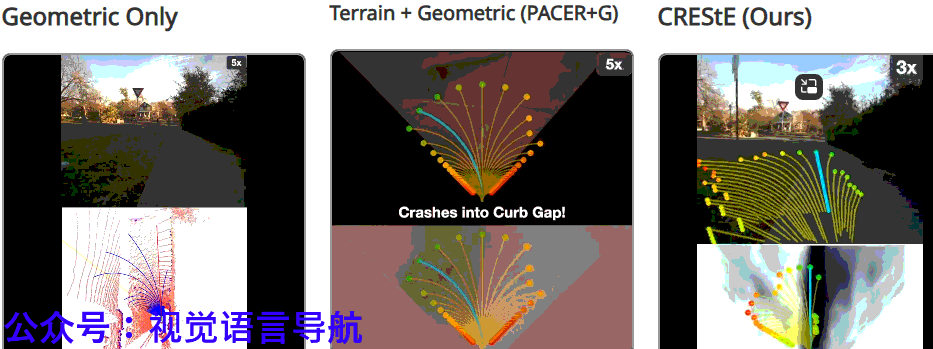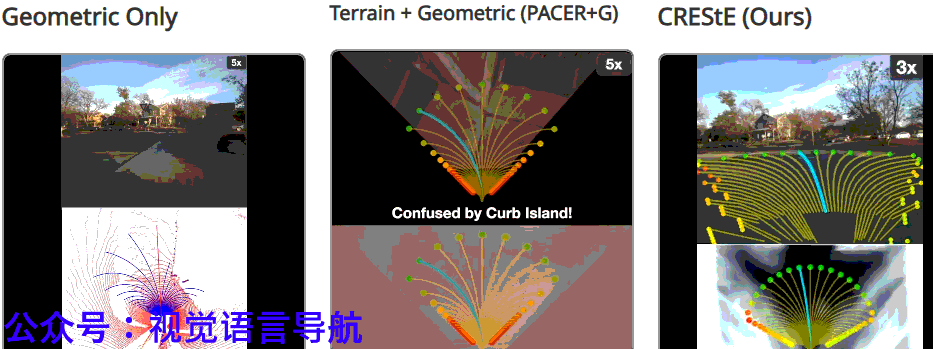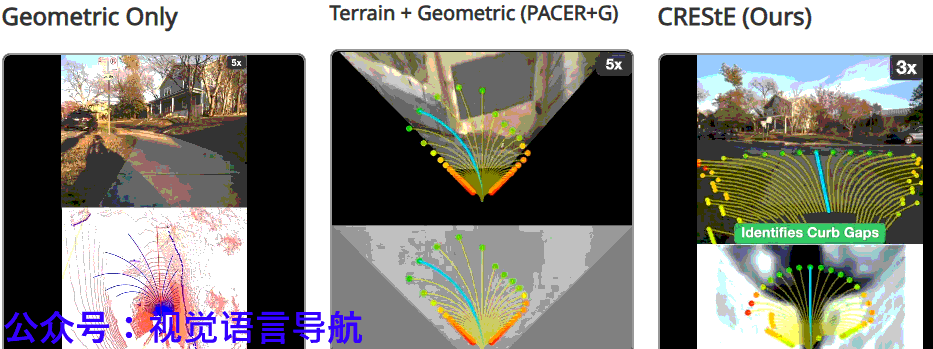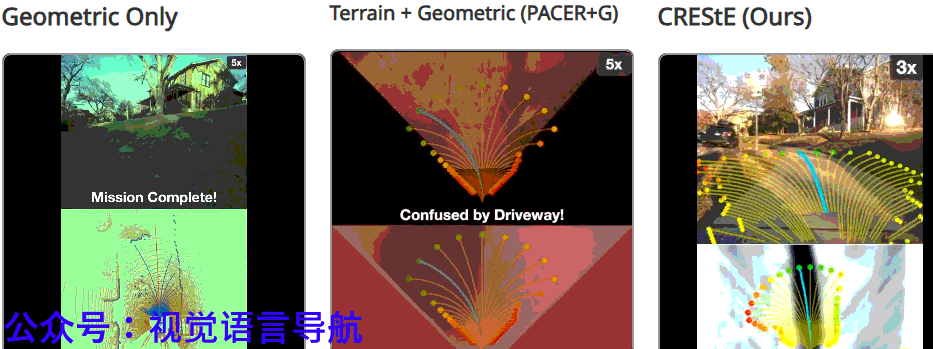
结论与未来工作
- 结论:
CRESTE通过从视觉基础模型中提取特征来学习鲁棒的、可泛化的感知表示,并引入基于反事实的损失函数和主动学习框架,使策略能够专注于最重要的因素并推断它们如何影响细粒度的导航行为。
RESTE在长视距无地图城市导航任务中显著优于现有方法,并在2公里的未见城市环境中仅需少量干预即可完成任务。
- 未来工作:
将CRESTE应用于不同机器人形态(如四足机器人和轮式机器人)的导航任务中,以验证其在不同机器人形态下的适应性;
扩展CRESTE以支持多步规划和推理,使其能够处理更复杂的导航任务,如从死胡同中恢复或在狭窄环境中导航;
探索自动化生成反事实标注的方法,以减少人工标注的工作量,提高CRESTE的可扩展性;
进一步扩展CRESTE的反事实IRL目标,使其能够学习如何在两个次优路径之间进行选择,以提高导航策略的灵活性和鲁棒性。
