Sping AI接入deepseek-本地部署大模型-第二期
ollama-安装
RAG
Embedding Model-向量模型
SpringAl-Vector Database
SpringAl-调用本地大模型
1.安装Ollama
ollama 简介:开源跨平台大模型工具。在让用户能够轻松地在本地运行、管理和与大模型进行交互。
1.1安装curl命令
curl 命令在下载安装脚本使用,需要提前准备好。

1.2 下载安装脚本
ollama 官网为 Linux 系统提供了一键安装脚本,执行如下命令即可:
非常的慢,慢,慢!!!!!
curl -fsSL https://ollama.com/install.sh | sh
离线安装ollama:
整体大纲步骤:

安装包是0.3.9.tgz,
通过网盘分享的文件:ollama-linux-amd64-0.3.9.tgz
将install.sh(这个文件在这篇文章的资源绑定中)
bash install.sh
注意: 将安装包和install.sh放到一个文件夹中
解压压缩包
sudo tar -xzvf ollama-linux-amd64-0.3.9.tgz -C /usr
安装install.sh
bash install.sh
编辑文件:
sudo vim /etc/systemd/system/ollama.service
保证其他服务都可以访问
Environment="OLLAMA_HOST=0.0.0.0:11434" 添加到service下面
重新加载文件,配置生效 sudo systemctl daemon-reload
编辑sudo vim /etc/profile
再次添加Environment="OLLAMA_HOST=0.0.0.0:11434" 在最后一行,目的和上面的一样
重新加载,让配置生效:
source /etc/profile
后台启动ollama服务:
nohup ollama serve >> serve.log 2>&1 &
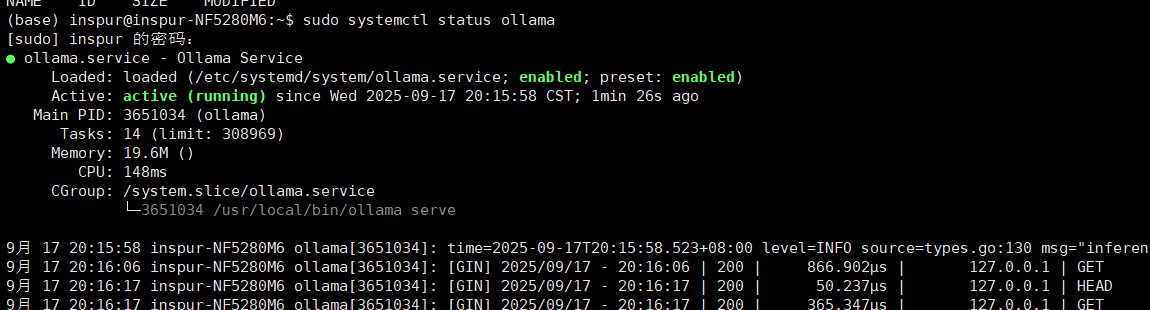
查看ollama状态如有是running转态则正常
模型的安装
ollama 官网
使用的是deepseek:r1
linux系统中指定存放模型的位置步骤:
1、停止ollama的服务
sudo systemctl stop ollama
2、创建保存模型的自定义目录:
/home/inspur/desktop/ollama 自定义的目录
sudo mkdir -p /home/inspur/desktop/ollama
3、修改自定义目录(逆归)的属主和属组为当前用户和当前组
#命令 whoami 查看用户名id 查看属组sudo chown -R 用户名:属组 /home/inspur/desktop/ollama/ollamaModels
4、赋予属主和属组读、写和执行权限
sudo chmod -R 775 /home/inspur/desktop/ollama
5、修改 ollama服务配置,添加模型路径
sudo systemctl edit ollama --full
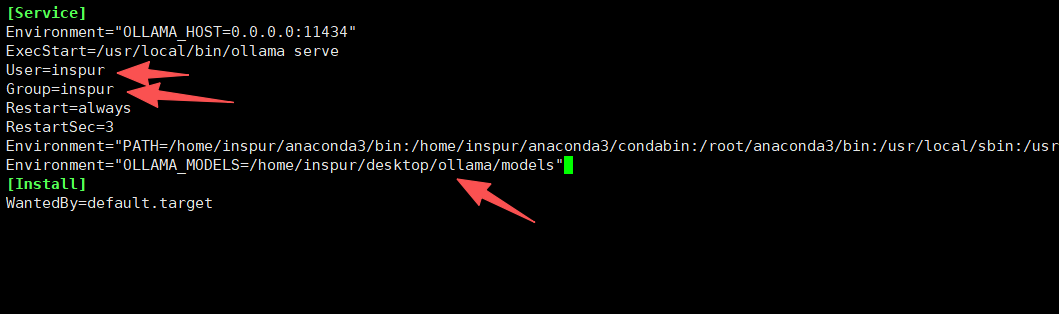
在service中 修改:
User=登录用户名称
Group=登录用户名称
在service中新添加
Environment="OLLAMA_MODELS=/home/inspur/desktop/ollama/models"
先按:ctrl+o 、 回车、 Ctrl+x。保存成功并退出。
6、重载服务配置
sudo systemctl daemon-reload
7、重启动ollama服务
sudo systemctl restart ollama
运行模型:
deepseek-r1:1.5b #1.1GB执行下面的命令:
ollama run deepseek-r1:1.5b
查看下载的模型:
ollama list
删除的已下载的模型
ollama rm deepseek-r1:1.5b
进行测试模型:

2、使用Spring-AI调用本地的模型
2.1引入ollama依赖
<dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-starter-model-ollama</artifactId></dependency><dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-bom</artifactId><version>1.0.0</version><type>pom</type><scope>import</scope></dependency>
注意:确保当前工程已正确的引入了"spring-ai-bom"
2.2 配置文件
spring:ai:ollama:base-url: http://ip:11434 # 设置 Ollama API 的基础地址,格式与 OpenAI 相同。chat:options:model: deepseek-r1:1.5b # 选择要调用的 Ollama 模型名称,必须与 Ollama 支持的模型列表匹配(如 llama2、mpt 等),不同模型可能有不同的性能和用途。temperature: 0.7 # temperature 值越高,AI 回答越随机和创意;值越低,回答越确定和保守。1.3 属于高值,适合需要发散性输出的场景,但可能牺牲准确性。2.3 聊天客户端
文件配置
@Configuration
public class SpringAIConfig {
// 本地部署@Bean(name="localClient")public ChatClient localClient(OllamaChatModel ollamaChatModel) {
// return builder
// .defaultSystem("你是项目经理")
// .defaultAdvisors(new SimpleLoggerAdvisor())//环绕通知
// .build();
// return builder.defaultSystem("你是项目经理")
// .build();return ChatClient.builder(ollamaChatModel).build();}}
2.4 Controller
package com.gj.controller;import com.alibaba.dashscope.exception.InputRequiredException;
import com.alibaba.dashscope.exception.NoApiKeyException;
import com.alibaba.dashscope.exception.UploadFileException;
import com.gj.config.User;
import com.gj.model.PhoneRecord;
import com.gj.model.PhoneRecordList;
import com.gj.model.PhoneRecordMap;
import com.gj.model.VideoQuest;
import com.gj.service.ZhipuAIVideoService;
import com.gj.tools.*;
import jakarta.annotation.Resource;
import jakarta.servlet.http.HttpSession;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.chat.memory.ChatMemory;
import org.springframework.ai.chat.messages.AssistantMessage;
import org.springframework.ai.chat.messages.Message;
import org.springframework.ai.chat.messages.SystemMessage;
import org.springframework.ai.chat.messages.UserMessage;
import org.springframework.ai.chat.prompt.ChatOptions;
import org.springframework.ai.chat.prompt.Prompt;
import org.springframework.ai.chat.prompt.PromptTemplate;
import org.springframework.ai.chat.prompt.SystemPromptTemplate;
import org.springframework.ai.image.ImageOptions;
import org.springframework.ai.image.ImageOptionsBuilder;
import org.springframework.ai.image.ImagePrompt;
import org.springframework.ai.image.ImageResponse;
import org.springframework.ai.zhipuai.ZhiPuAiImageModel;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Primary;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.http.ResponseEntity;
import org.springframework.util.MimeTypeUtils;
import org.springframework.web.bind.annotation.*;
import reactor.core.publisher.Flux;import java.io.IOException;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
import java.util.Map;/*** @author GJ* @date 2025/6/24 21:41*/
@RestController
@RequestMapping("/api")
public class LocalChatModelController {@Resource(name = "localClient")private ChatClient chatClient;@GetMapping(value = "/localChat",produces = "text/html;charset=UTF-8")public Flux<String> chat(@RequestParam(value = "msg",defaultValue = "deepseek") String msg) {
// 1、系统角色SystemMessage systemMessage = new SystemMessage("你是项目经理");
// 2、用户消息UserMessage userMessage = new UserMessage(msg);
// 3、模型参数ChatOptions chatOptions = ChatOptions.builder().temperature(0.5) //多样化系数// .maxTokens(500) //限制token用量,防止模型输出过长,这也导致可能输出内容的缺失.build();//4、进行组合Prompt prompt = new Prompt(List.of(systemMessage, userMessage), chatOptions);return chatClient.prompt(prompt) //设置请求上下文(如角色和内容).stream()//发送请求并获取模型生成的响应.content(); //获取响应内容}
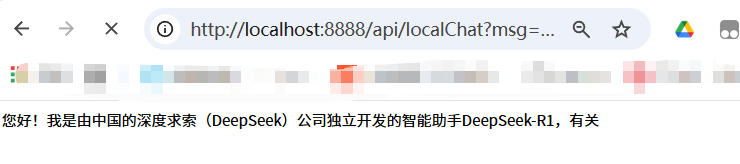
}2.5 调用本地大模型的效果
SpringAI-RAG
1、什么是RAG
RAG 即单词"Retrieval-Augmented Generation"首字母的组合,中文叫"检索增强生成"。当模型需要生成文本或者回答问题时,会先从一个庞大的文档集合中检索出相关的信息,然后利用这些检索到的信息来指导文本的生成,从而提高回答质量和准确性。
2、为什么需要RAG
众所周知,模型的知识库都是基于通用信息训练的,存在以下两个显著问题:
1.无法回答实时性的问题
模型训练都有截止日期,在截止日期之后的数据,模型无法回答
2.无法回答无法回答特定领域或私密问题
模型训练基于公开的通用数据,垂直领域或公司机密知识无法回答
解决上述问题的方法有两种:
1.模型微调:通过特定任务数据优化模型参数,使其适配新任务并提升性能。 比喻:考前突击复习
2. RAG:模型根据检索到的相关数据,生成高质量回答。比喻:考试中途可翻书(开卷考试)
模型微调方式,需付出大量时间和高额训练成本,因此RAG 成为迅速提升模型能力的首选方式。
3.RAG涉及的知识点
RAG 技术的实现涉及如下的知识点:
1、数据向量化:普通的文本、图形、音频和视频数据,均需转换为使用数字坐标表示的向量数据
2、向量模型:完成数据向量化的专用模型。
3、向量数据库:向量数据库提供给向量数据保存,并提供相似性检索功能
4、聊天模型+向量数据库:聊天模型结合向量数据库,完成相似性检索并为用户提供高度准确的回答
5、文档向量化:常见的PDF、word文档,都可作为RAG的知识库文档,将它们转换为向量并保存在向量库中供使用
SpringAI-Embedding Model
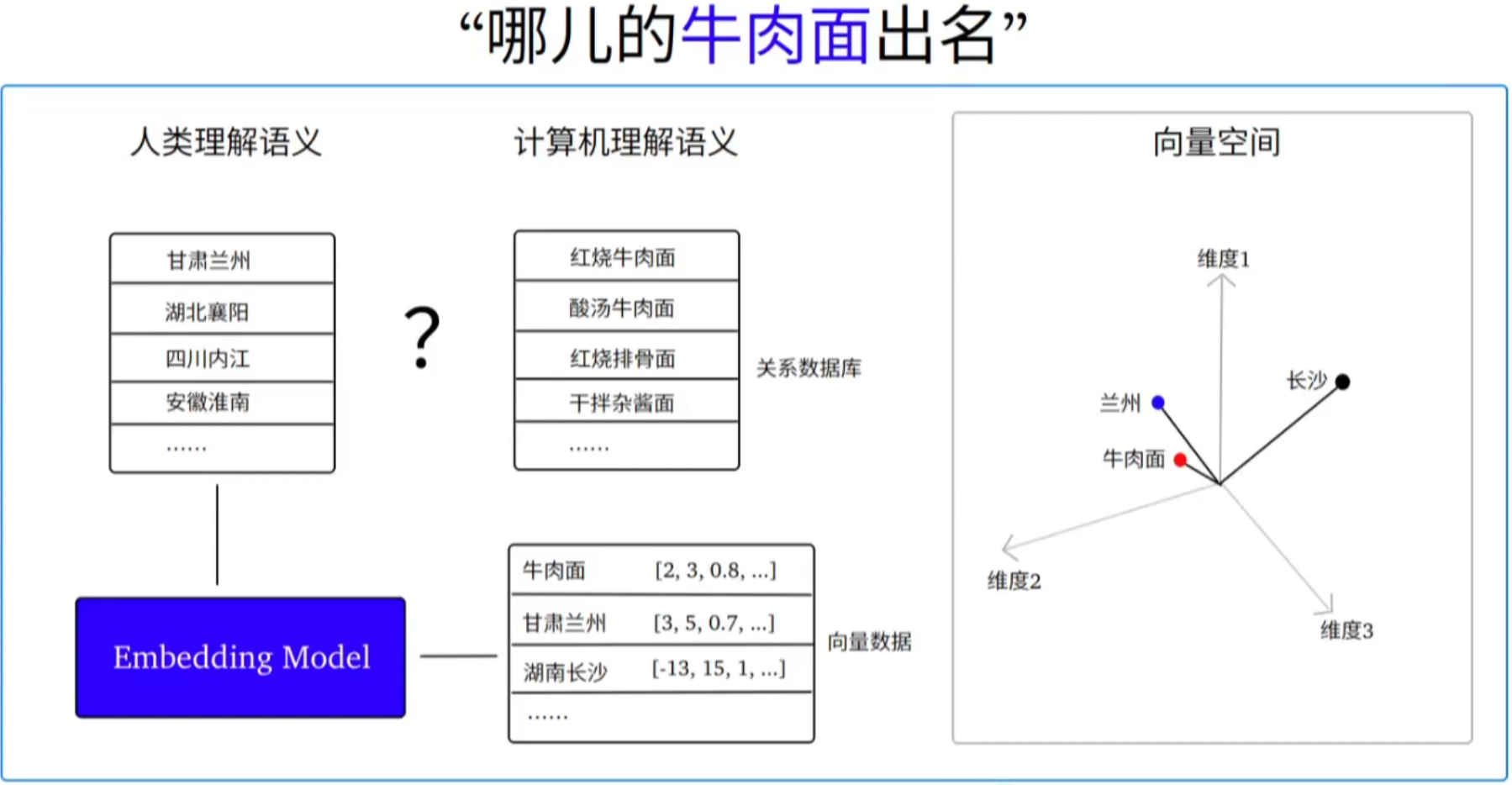
1.什么是Embedding Model
Embedding Model 即"嵌入模型",也叫"向量模型"。
1.将普通的数据(如文本、图像、音视频等等)转换为"向量数据"(Vector)的机器学习模型。
2."向量数据"能够通过不同的维度描述原始数据,维度越高能描述的特征或属性就越多。
3.数据"向量化"之后,可帮助模型轻松地实现在"向量空间"中找到"语义相似"的数据。
2. Embedding Model
Embedding Model 分不同领域的模型,例如:
 本次选择2025年6月6日开源的 qwen3-Embedding 模型,该模型支持 ollama 本地部署,以 owen3 基础模型为底座,提供了各种大小(0.6B、4B和 8B)的全面文本嵌入和重排序模型:
本次选择2025年6月6日开源的 qwen3-Embedding 模型,该模型支持 ollama 本地部署,以 owen3 基础模型为底座,提供了各种大小(0.6B、4B和 8B)的全面文本嵌入和重排序模型:
ollama 拉取模型维度是1024:
ollama pull ryanshillington/Qwen3-Embedding-0.6B
3. Embedding Model API
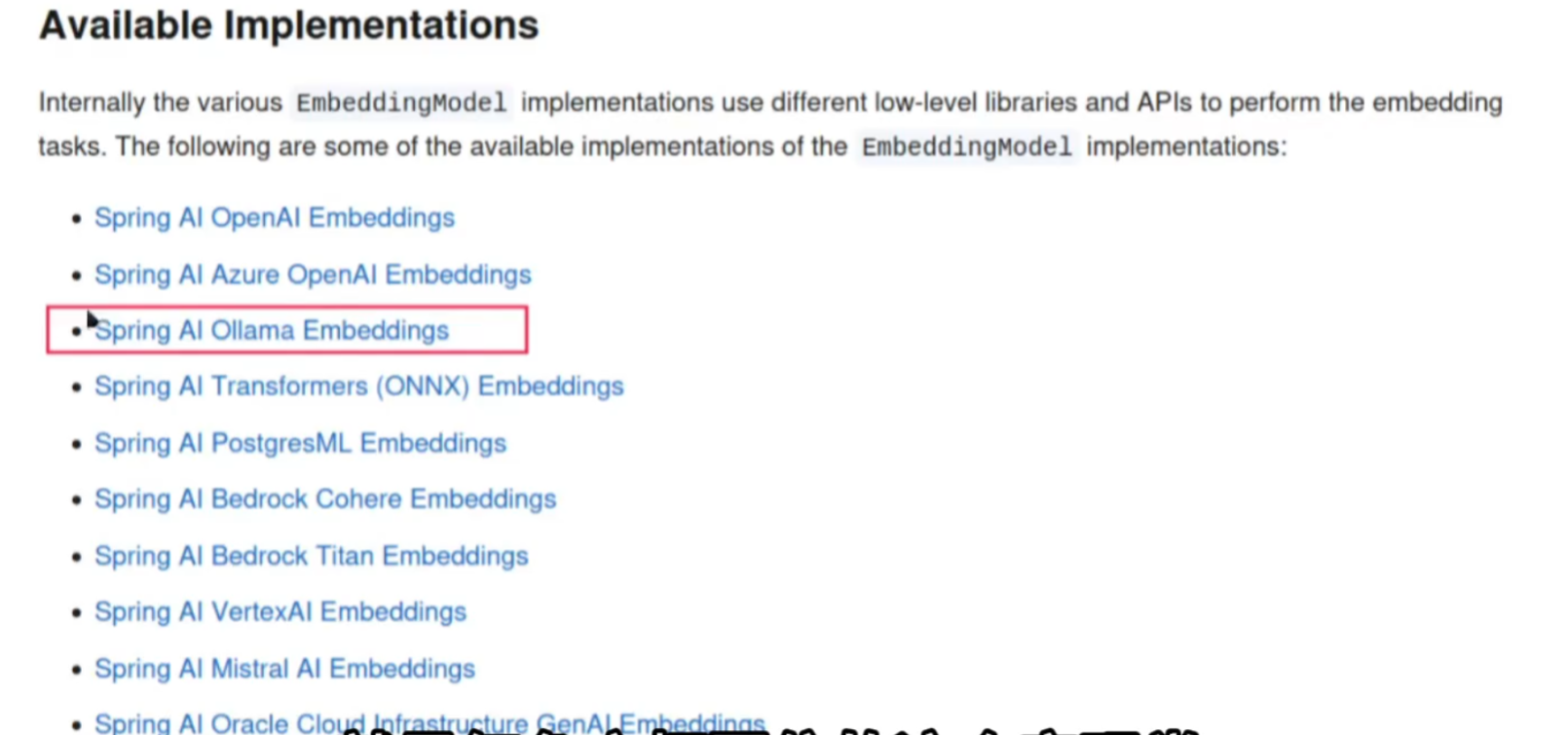
SpringAI 提供标准化接口 EmbeddingModel访问不同嵌入模型,通过简单的配置即可将嵌入功能集成到应用中。

spring 官方公布的 EmbeddingModel 接口可用实现包括:
4.实现数据向量化
4.1引入ollama依赖
<dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-starter-model-ollama</artifactId></dependency>
4.2配置文件
spring:ai:ollama:base-url: http://172.18.67.133:11434 embedding:model: ryanshillington/Qwen3-Embedding-0.6B:latest
4.3controller
package com.gj.controller;import jakarta.annotation.Resource;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.embedding.EmbeddingModel;
import org.springframework.ai.embedding.EmbeddingRequest;
import org.springframework.ai.embedding.EmbeddingResponse;
import org.springframework.ai.ollama.api.OllamaOptions;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import reactor.core.publisher.Flux;import java.util.List;
import java.util.Map;/*** @author GJ* @date 2025/6/24 21:41*/
@RestController
@RequestMapping("/api")
public class LocalChatModelController {@Resource(name = "localClient")private ChatClient chatClient;@GetMapping(value = "/localChat",produces = "text/html;charset=UTF-8")public Flux<String> chat(@RequestParam(value = "msg",defaultValue = "deepseek") String msg) {
//// 1、系统角色
// SystemMessage systemMessage = new SystemMessage("你是项目经理");
//// 2、用户消息
// UserMessage userMessage = new UserMessage(msg);
//// 3、模型参数
// ChatOptions chatOptions = ChatOptions.builder()
// .temperature(0.5) //多样化系数
// // .maxTokens(500) //限制token用量,防止模型输出过长,这也导致可能输出内容的缺失
// .build();
// //4、进行组合
// Prompt prompt = new Prompt(List.of(systemMessage, userMessage), chatOptions);
// return chatClient
// .prompt(prompt) //设置请求上下文(如角色和内容)
// .stream()//发送请求并获取模型生成的响应
// .content(); //获取响应内容System.out.println("本地调用+"+msg);return chatClient.prompt() //设置请求上下文(如角色和内容).user(msg)//设置用户输入消息.stream()//发送请求并获取模型生成的响应.content(); //获取响应内容}/***将文本转化成向量* @param msg* @return*///声明向量模型@Resource(name = "ollamaEmbeddingModel")private EmbeddingModel embeddingModel;// public LocalChatModelController( EmbeddingModel embeddingModel) {
// this.embeddingModel = embeddingModel;
// }@GetMapping(value = "/txt2Embedding")public Map txt2Embedding() {//查看下模型维度System.out.println("向量维度:"+embeddingModel.dimensions());EmbeddingResponse response = embeddingModel.call(new EmbeddingRequest(List.of("牛肉面"),OllamaOptions.builder().model("ryanshillington/Qwen3-Embedding-0.6B:latest") //局部配置模型.truncate(false)//遇到长文本不截断.build()));System.out.println("向量结果:"+response);System.out.println("向量结果:"+embeddingModel.embed(List.of("兰州","牛肉面")));return Map.of("data", response);}
}结果:

1.什么是Vector Database
Vector patabase 即"向量数据库",也叫"矢量数据库"。是专门设计用于存储、索引和管理高维向量数据的数据库系统,主要用于支持向量相似性检索。

2.安装Chroma数据库
本次采用 Docker方式部署 chroma 数据库【方便】
在linux上安装docker
yum install docker 或者使用 sudo apt install docker
问题:
如果执行systemctl start docker
docker.service不存在
ls /lib/systemd/system/docker.service
若文件不存在
1、卸载旧版本(若有):
sudo apt-get remove --purge docker docker-engine docker.io containerd runc
2、安装依赖:
sudo apt-get updatesudo apt-get install -y apt-transport-https ca-certificates curl gnupg-agent software-properties-common
3、添加Docker官方GPG密钥:
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /usr/share/keyrings/docker-archive-keyring.gpg
4、添加Docker软件源:
echo "deb [arch=$(dpkg --print-architecture) signed-by=/usr/share/keyrings/docker-archive-keyring.gpg] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
5、安装Docker:
sudo apt-get updatesudo apt-get install -y docker-ce docker-ce-cli containerd.io
6、验证安装
docker --version # 输出版本信息ls /lib/systemd/system/docker.service # 确认单元文件存在
7、启动docker:
# 重新加载systemd配置(若修改了单元文件)
sudo systemctl daemon-reload
# 启动Docker服务
sudo systemctl start docker
# 检查服务状态(确保“active (running)”)
sudo systemctl status docker
若文件存在
文件存在直接启动docker
# 启动Docker服务
sudo systemctl start docker
# 检查服务状态(确保“active (running)”)
sudo systemctl status docker
docker中拉取镜像:
sudo docker pull chromadb/chroma
拉取不到镜像:

国内可用镜像地址
sudo mkdir -p /etc/docker
sudo tee /etc/docker/daemon.json <<-'EOF'
{"registry-mirrors": ["https://ccr.ccs.tencentyun.com","https://docker.1ms.run"]
}
EOFsudo systemctl daemon-reload
sudo systemctl restart docker
重新拉取
后台运行ollama
-v 宿主机路径:容器路径docker run -d --name chroma -p 8000:8000 -v /home/inspur/desktop/chroma:/data chromadb/chroma
参数说明:
–rm: 容器退出后自动删除。
-it: 以交互模式运行容器。
-p 8000:8000: 将容器的 8000 端口映射到主机的 8000 端口。
3.VectorStore接口
spring AI 定义了 vectqrstore 接口与向量数据库进行交互。

官万公布的 Vectorstore 接口可用实现类

4.使用Chroma数据库
4.1 依赖与配置
<dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-starter-model-ollama</artifactId></dependency><dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-starter-vector-store-chroma</artifactId></dependency>
注意:向量数据库依赖于向量模型转换数据,所以必须引入向量模型,本例采用Ollama部署的向量模型!
spring:ai:ollama:base-url: http://172.18.67.133:11434 embedding:model: ryanshillington/Qwen3-Embedding-0.6B:latest
4.2 连接Chroma
spring:ai:vectorstore:chroma:client:host: http://172.18.67.133 #主机地址port: 8000 #端口号initialize-schema: true # 是否自动创建collection,默认falsecollection-name: springai #自定义collection名称,默认为“SpringAiCollection”
提示:Collection类似传统数据库中的"表",是一种数据聚合的组件。
4.3 添加文档
org.springframework.ai.document,Document 是 SpringAI 的标准文档类。主要属性说明如下:

package com.gj.controller;import jakarta.annotation.Resource;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.document.Document;
import org.springframework.ai.embedding.EmbeddingModel;
import org.springframework.ai.embedding.EmbeddingRequest;
import org.springframework.ai.embedding.EmbeddingResponse;
import org.springframework.ai.ollama.api.OllamaOptions;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import reactor.core.publisher.Flux;import java.util.List;
import java.util.Map;/*** @author GJ* @date 2025/6/24 21:41*/
@RestController
@RequestMapping("/api")
public class LocalChatModelController {@Autowiredprivate VectorStore vectorStore;@GetMapping(value = "/save")public Map<String,Object> save(){
// 1、唯一标识+文本内容+元数据Document doc001 = new Document("doc-001", " 以川渝一带为例,有“夫妻肺片”、“回锅肉”、“麻婆豆腐”、“水煮鱼”、“毛血旺”等名菜。以其独特的烹饪方法和口味特色,享有“美食王国”的美誉。",Map.of("source", "美食中国","category", "地方美食","created_at", System.currentTimeMillis()));Document doc002 = new Document("doc-002", " 自贡牛肉是当地的经典美食,主要有“火边子牛肉”和“冷吃牛肉”两种。其中“火边子牛肉”为卤制,需经过干腌和手工切片;而“冷吃牛肉”则更注重麻辣风味。此外,“火边子牛肉”是地理标志产品。",Map.of("source", "美食中国","category", "地方美食","created_at", System.currentTimeMillis()));Document doc003 = new Document("doc-003", " 湖北襄阳的牛肉面闻名遐迩,选用牛骨、牛肉、面条、豆腐和海带片,常佐以豆芽和香菜。当地人通常将其作为早餐,本地俗称“牛杂面”“牛肉面”“襄阳牛肉面”,深受食客喜爱。",Map.of("source", "美食中国","category", "地方美食","created_at", System.currentTimeMillis()));Document doc004 = new Document("doc-004", " 主要业务是买电脑,手机,平板,笔记本,台式机,打印机,复印机,扫描仪,投影仪,数码相机,摄像机,耳机,音响,游戏设备,智能家居,智能手表,智能眼镜,智能手环,智能音箱,智能门锁,智能灯泡,智能插座,智能窗帘,智能空调",Map.of("source", "bilibili","category", "数码产品","created_at", System.currentTimeMillis() + 24 * 1000 * 3600));List<Document> documents = List.of(doc001, doc002, doc003, doc004);vectorStore.add(documents);return Map.of("data", "保存成功");}//查看保存的数据@GetMapping(value = "/search")public Map search(String query){List<Document> documents = vectorStore.similaritySearch(query);return Map.of("data",documents);}}4.4 查询文档
查询都是基于"相似性"进行的查询,而非传统数据库那样的"内容匹配"查询。
4.4.1 基本查询
有2种查询方式:
第一种查询方式:
//查看保存的数据@GetMapping(value = "/search")public Map search(String query){List<Document> documents = vectorStore.similaritySearch(query);return Map.of("data",documents);}
结果:
通过结果可以看到获得score是和查询问题相关性的得分
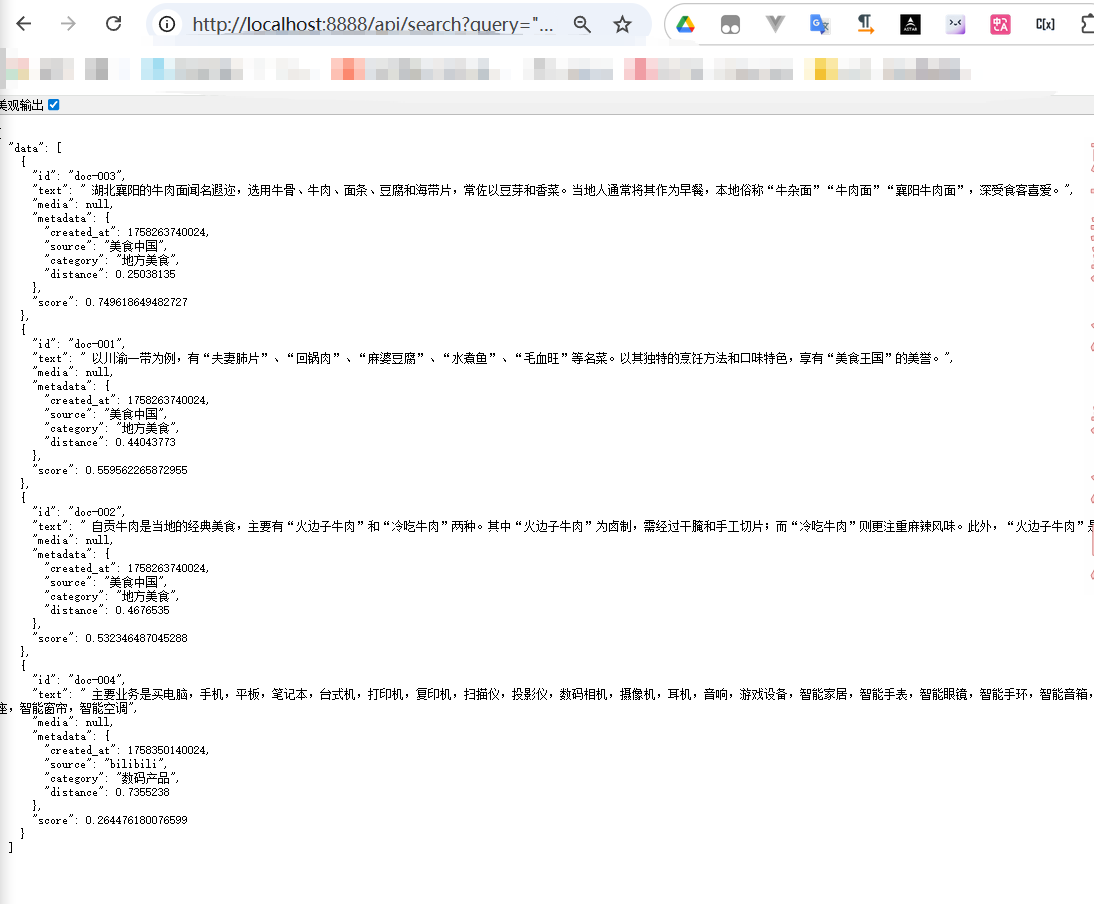
第二种查询方式:
//查看保存的数据@GetMapping(value = "/search2")public Map search2(String query){List<Document> documents = vectorStore.similaritySearch(SearchRequest.builder().similarityThreshold(0.5) //相似度阈值 >=0.5.query(query).build());return Map.of("data",documents);}//查看保存的数据@GetMapping(value = "/search2")public Map search2(String query){List<Document> documents = vectorStore.similaritySearch(SearchRequest.builder().similarityThreshold(0.5) //相似度阈值 >=0.5.topK(2) //返回前2个结果.query(query).build());return Map.of("data",documents);}结果:
没有添加topk条件
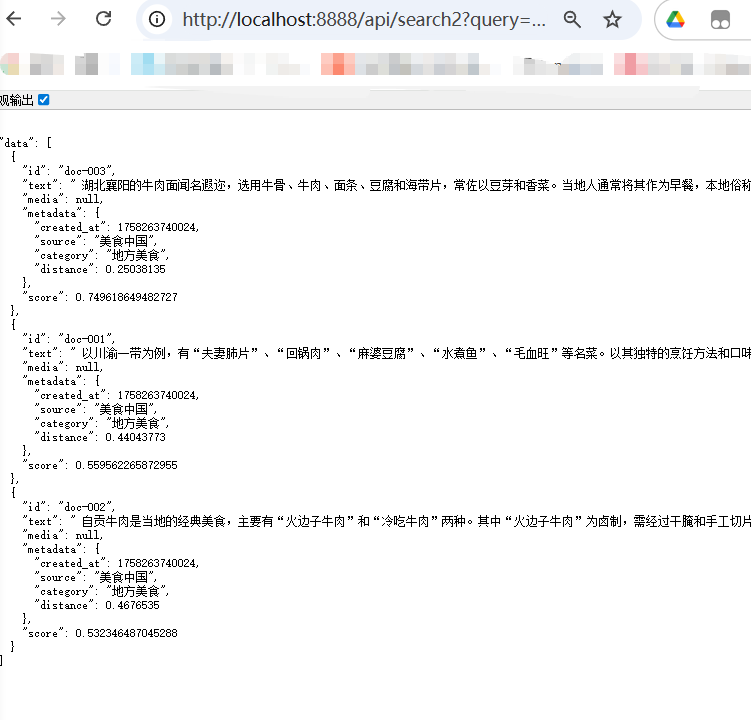
添加topK条件

4.4.2 元数据过滤
“元数据过滤” 即按照文档元数据的 key-value 来过滤,可以大幅度提高查询效率。又分字符串条件查询和条件表达式查询两种方式。
存储的形式是:

//通过元数据进行过滤查询String filterExpression1 = "source == '美食中国'";String filterExpression2 = "source == '美食中国'|| source == 'bilibili'";String filterExpression3 = "source in ['美食中国','bilibili']";String filterExpression4 = "source nin ['美食中国'] && category == '地方美食' ";@GetMapping(value = "/search3")public Map search3(String query){List<Document> documents = vectorStore.similaritySearch(SearchRequest.builder().similarityThreshold(0.5) //相似度阈值 >=0.5.filterExpression(filterExpression1).query(query).build());return Map.of("data",documents);}
结果:
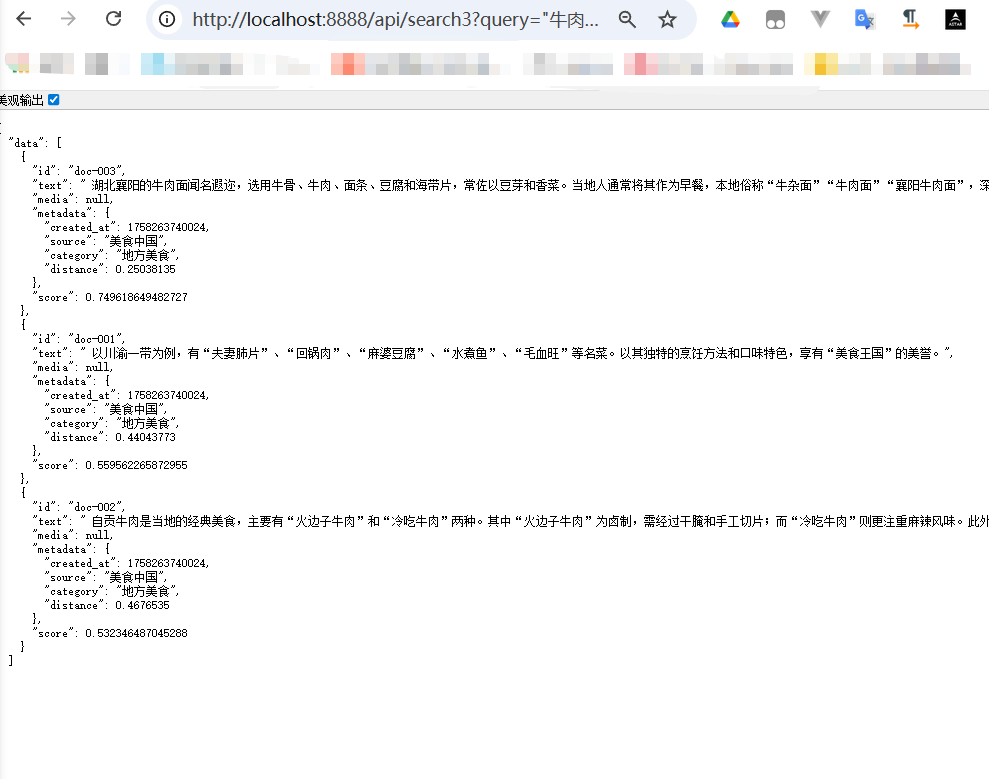
4.5 删除文档
@GetMapping(value = "/delete")public String delete(){//将id为doc-001和doc-002的文档删除vectorStore.delete(List.of("doc-001","doc-002"));return "删除成功";}
结果:
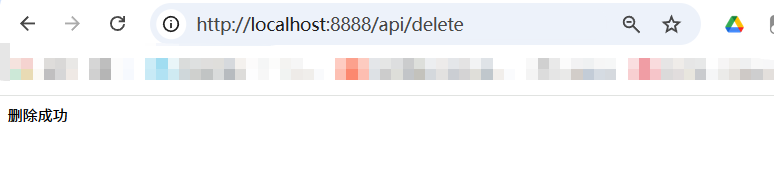
查询原来文档:发现doc-001,doc-002 已经删除掉了
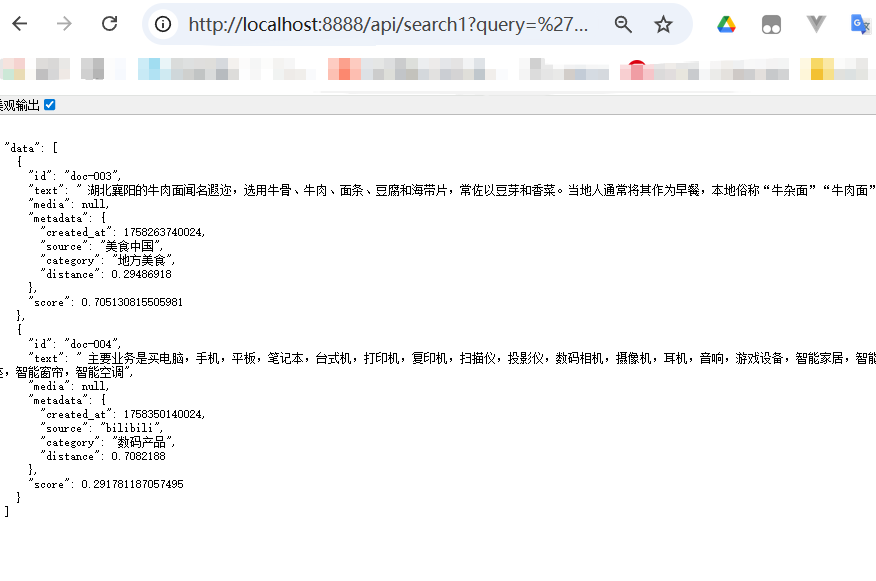
4.6修改文档
一旦向量生成,其值通常不会频繁变动;
修改向量意味着需要重新计算其位置并更新索引,这在高维空间中非常耗时!VectorStore 更倾向于不可变存储的设计哲学;
更常见的做法是删除旧向量并重新插入新向量,而不是原地修改。