MLP和CNN在图片识别中的对比——基于猫狗分类项目的实战分析
一、引言
卷积神经网络(Convolutional Neural Network,CNN)在图像处理领域的强大性能早已是学界与工业界公认的事实。猫狗分类任务场景简单、数据易获取,同时又能涵盖图像分类的核心环节,非常适合作为第一个CNN的实践项目。
二、实验环境与实现流程
为确保实验可复现且结果清晰,本节将详细介绍项目的运行环境、核心实现步骤,并对关键代码进行逐块注释,帮助理解每一步的设计逻辑。
2.1 实验环境说明
本项目基于 Google Colab 平台运行,无需本地配置复杂环境,核心依赖如下:
- 深度学习框架:TensorFlow 2.x(Colab 默认预装,含 Keras 高层 API)
- 硬件加速:Colab 免费版提供的 GPU(通常为 NVIDIA T4,支持 CUDA 加速)
- 数据处理与可视化库:Matplotlib(内置,用于绘制训练曲线)
- 数据集:Google 提供的
cats_and_dogs_filtered轻量级数据集(含 2000 张训练图、1000 张验证图,仅含 “猫 / 狗” 两类,适合快速验证模型)
2.2 完整实现流程与代码注释
实验流程遵循 “环境检查→数据准备→模型构建→模型训练→结果可视化” 的经典深度学习链路,每一步代码均附带详细注释,明确设计目的。
步骤 1:环境初始化与 GPU 检查
首先导入核心库,并确认 GPU 是否启用 ——GPU 能大幅加速卷积、矩阵运算等耗时操作,是训练 CNN 的关键。
# 导入必要的库:涵盖模型构建、数据处理、可视化全流程
import tensorflow as tf # 深度学习核心框架
from tensorflow.keras import layers, models # Keras 层与模型API
from tensorflow.keras.preprocessing.image import ImageDataGenerator # 图像数据生成器(含增强功能)
from tensorflow.keras.utils import plot_model # 可选:绘制模型结构图(需额外依赖)
import matplotlib.pyplot as plt # 绘图库,用于展示训练曲线# 检查GPU是否可用:Colab默认启用GPU,若显示空列表需手动切换(菜单栏→修改→笔记本设置→硬件加速器选GPU)
print("GPU 可用吗?", tf.config.list_physical_devices('GPU'))
# 预期输出:[PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU')](表示GPU已启用)
步骤 2:数据集下载与解压
直接下载 Google 提供的公开数据集,无需手动上传,适合快速实验。
# 下载教学用数据集(Google 提供,无需验证,避免手动下载的繁琐)
# wget是Linux命令,用于从URL下载文件;-O指定保存文件名,--no-check-certificate跳过证书验证(避免网络问题)
!wget --no-check-certificate \https://storage.googleapis.com/mledu-datasets/cats_and_dogs_filtered.zip \-O cats_and_dogs_filtered.zip# 解压数据集:-q表示“静默模式”(不输出解压日志),避免冗余信息
!unzip -q cats_and_dogs_filtered.zip# 提示解压完成,便于确认流程进度
print("✅ 数据解压完成!")
# 解压后会生成“cats_and_dogs_filtered”文件夹,内含train(训练集)和validation(验证集)子文件夹
步骤 3:数据预处理与生成器创建
通过 ImageDataGenerator 实现图像归一化与数据增强(仅用于训练集),并生成批量数据(避免一次性加载内存溢出)。
from tensorflow.keras.preprocessing.image import ImageDataGenerator # 再次导入(确保代码块独立可运行)# 1. 训练集数据增强:目的是扩大数据多样性,提升模型泛化能力(避免过拟合)
train_datagen = ImageDataGenerator(rescale=1./255, # 核心预处理:将像素值从[0,255]归一化到[0,1],避免大数值导致梯度爆炸rotation_range=20, # 随机旋转图像(0-20度),模拟不同拍摄角度width_shift_range=0.2, # 随机水平偏移(最多占图像宽度的20%)height_shift_range=0.2, # 随机垂直偏移(最多占图像高度的20%)horizontal_flip=True, # 随机水平翻转(猫/狗左右翻转不影响类别,增加数据多样性)zoom_range=0.2 # 随机缩放(0.8-1.2倍),模拟不同拍摄距离
)# 2. 验证集仅归一化:验证集需反映真实场景,不能做增强(否则评估结果不准确)
validation_datagen = ImageDataGenerator(rescale=1./255)# 3. 训练集数据生成器:从文件夹读取图像,自动按类别标签(文件夹名)分类
train_generator = train_datagen.flow_from_directory('cats_and_dogs_filtered/train', # 训练集文件夹路径(内含cats/和dogs/两个子文件夹)target_size=(150, 150), # 统一图像尺寸:将所有图像resize为150×150(模型输入需固定尺寸)batch_size=32, # 每次训练批量大小:32是平衡速度与内存的常用值(Colab GPU可承载)class_mode='binary' # 二分类任务(猫/狗),标签格式为二进制(0/1)
)# 4. 验证集数据生成器:配置与训练集一致,仅无增强
validation_generator = validation_datagen.flow_from_directory('cats_and_dogs_filtered/validation', # 验证集文件夹路径target_size=(150, 150),batch_size=32,class_mode='binary'
)# 打印数据集信息,确认数据加载正确
print("✅ 数据生成器创建成功!")
print("训练集图像数量:", train_generator.samples) # 预期输出:2000(1000张猫+1000张狗)
print("验证集图像数量:", validation_generator.samples) # 预期输出:1000(500张猫+500张狗)
print("类别索引:", train_generator.class_indices) # 预期输出:{'cats': 0, 'dogs': 1}(文件夹名对应标签)
步骤 4:构建对比模型(MLP vs CNN)
为突出 CNN 在图像任务中的优势,同时构建 MLP 作为基线模型(Baseline),两者输入尺寸、全连接层参数尽量对齐,确保对比公平性。
4.1 构建 MLP 模型(多层感知机)
MLP 无空间特征提取能力,仅通过 “扁平化 + 全连接” 拟合数据,用于反衬 CNN 的优势。
from tensorflow.keras import models, layers # 再次导入(确保代码块独立)# 构建MLP模型:Sequential表示“序列模型”(层按顺序堆叠)
model_mlp = models.Sequential([# 输入层:将150×150×3的图像“扁平化”为1维向量(150*150*3=67500个特征)layers.Flatten(input_shape=(150, 150, 3)),# 全连接层1:512个神经元,ReLU激活函数(引入非线性,提升拟合能力)layers.Dense(512, activation='relu'),layers.Dropout(0.5), # 随机丢弃50%神经元,防止过拟合(MLP易过拟合,需强正则化)# 全连接层2:128个神经元,进一步压缩特征layers.Dense(128, activation='relu'),layers.Dropout(0.5), # 再次Dropout,增强泛化能力# 输出层:1个神经元,sigmoid激活函数(二分类任务,输出概率值[0,1])layers.Dense(1, activation='sigmoid')
])# 编译模型:配置训练参数
model_mlp.compile(optimizer='adam', # 优化器:Adam(自适应学习率,训练稳定)loss='binary_crossentropy', # 损失函数:二分类交叉熵(适合二分类任务,衡量概率差异)metrics=['accuracy'] # 评估指标:准确率(直观反映分类效果)
)# 打印模型结构与参数数量,确认构建正确
print("✅ MLP 模型构建完成")
model_mlp.summary()
# 关键观察:MLP总参数约 67500*512 + 512*128 + ... ≈ 3500万(参数多,易过拟合)
4.2 构建 CNN 模型(卷积神经网络)
CNN 通过 “卷积 + 池化” 提取空间特征,再用全连接层分类,是图像任务的专用结构。
# 构建CNN模型:序列模型,含3组“卷积+池化”(逐步提取高阶特征)
model_cnn = models.Sequential([# 卷积层1:32个3×3卷积核(提取边缘、纹理等低阶特征),ReLU激活,输入尺寸150×150×3layers.Conv2D(32, (3,3), activation='relu', input_shape=(150, 150, 3)),layers.MaxPooling2D(2, 2), # 最大池化:2×2窗口,压缩特征图尺寸(150→75),保留关键特征# 卷积层2:64个3×3卷积核(提取更复杂的纹理、局部形状)layers.Conv2D(64, (3,3), activation='relu'),layers.MaxPooling2D(2, 2), # 尺寸再次压缩(75→37)# 卷积层3:128个3×3卷积核(提取更高阶的特征,如猫的胡须、狗的耳朵形状)layers.Conv2D(128, (3,3), activation='relu'),layers.MaxPooling2D(2, 2), # 尺寸压缩(37→18)# 扁平化:将卷积层输出的特征图(18×18×128)转为1维向量(18*18*128=41472)layers.Flatten(),# 全连接层:512个神经元(与MLP对齐,确保对比公平)layers.Dense(512, activation='relu'),layers.Dropout(0.5), # Dropout防止过拟合# 输出层:与MLP一致,1个神经元+sigmoidlayers.Dense(1, activation='sigmoid')
])# 编译模型:与MLP参数一致(优化器、损失、指标相同),确保训练条件公平
model_cnn.compile(optimizer='adam',loss='binary_crossentropy',metrics=['accuracy']
)# 打印模型结构与参数数量
print("✅ CNN 模型构建完成")
model_cnn.summary()
# 关键观察:CNN总参数约 32*3*3*3 + 64*3*3*32 + ... ≈ 2100万(比MLP少,但特征提取能力更强)
步骤 5:模型训练(对比训练过程)
为快速验证效果,两类模型均训练 5 轮(epochs=5),使用相同的训练集 / 验证集,确保对比的公平性。
5.1 训练 MLP 模型
print("🚀 开始训练 MLP...")
# 调用fit方法训练:接收数据生成器,自动批量加载数据
history_mlp = model_mlp.fit(train_generator, # 训练集数据生成器epochs=5, # 训练轮次:5轮足够观察初期差异,避免耗时过长validation_data=validation_generator, # 验证集数据生成器(每轮结束后评估泛化能力)verbose=1 # 训练日志显示模式:1表示显示进度条(便于实时观察)
)
# 预期现象:MLP训练准确率上升慢,验证准确率波动大(泛化能力差)
5.2 训练 CNN 模型
print("🚀 开始训练 CNN...")
# 训练参数与MLP完全一致(epochs、验证集、verbose)
history_cnn = model_cnn.fit(train_generator,epochs=5,validation_data=validation_generator,verbose=1
)
# 预期现象:CNN训练准确率上升快,验证准确率与训练准确率差距小(泛化能力好)
步骤 6:结果可视化(对比准确率与损失)
通过绘制 “验证集准确率” 和 “验证集损失” 曲线,直观对比 MLP 与 CNN 的性能差异。
import matplotlib.pyplot as plt # 再次导入(确保代码块独立)# 定义绘图函数:输入两个模型的训练历史(history_mlp、history_cnn)
def plot_comparison(h1, h2):plt.figure(figsize=(12, 4)) # 设置画布大小(宽12英寸,高4英寸)# 子图1:验证集准确率对比(核心指标,反映泛化能力)plt.subplot(1, 2, 1) # 1行2列,第1个子图plt.plot(h1.history['val_accuracy'], label='MLP') # MLP的验证准确率曲线plt.plot(h2.history['val_accuracy'], label='CNN') # CNN的验证准确率曲线plt.title('Verification accuracy') # 子图标题plt.xlabel('Epoch') # 横轴:训练轮次plt.ylabel('Accuracy') # 纵轴:准确率(0-1)plt.legend() # 显示图例(区分MLP与CNN)# 子图2:验证集损失对比(损失越低,模型预测越准)plt.subplot(1, 2, 2) # 1行2列,第2个子图plt.plot(h1.history['val_loss'], label='MLP') # MLP的验证损失曲线plt.plot(h2.history['val_loss'], label='CNN') # CNN的验证损失曲线plt.title('Verification loss') # 子图标题plt.xlabel('Epoch') # 横轴:训练轮次plt.ylabel('Loss') # 纵轴:损失值(越低越好)plt.legend() # 显示图例plt.tight_layout() # 自动调整子图间距,避免标签重叠plt.show() # 显示图像# 调用函数,传入两个模型的训练历史
plot_comparison(history_mlp, history_cnn)
# 预期结果:CNN的验证准确率显著高于MLP,验证损失显著低于MLP(直观体现CNN优势)输出结果
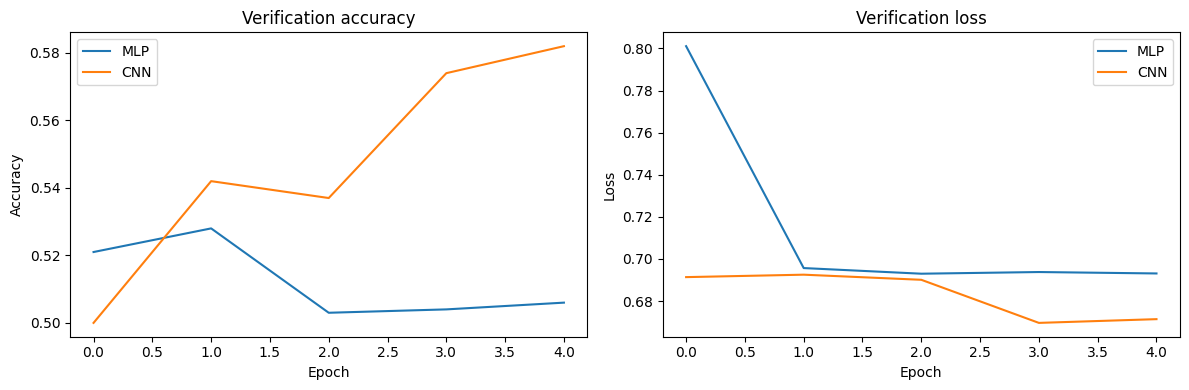
盲猜的概率都有50%,MLP最高准确率也为50%左右,CNN最高准确率也才58%,因此两个模型都不可用!
三、初期实验结果分析与优化方向
在完成上述基础实验后,我们观察到一个关键现象:CNN 的验证准确率仅从随机水平(50%)提升至 58%,远未达到预期的性能表现(通常 CNN 在猫狗分类任务中可轻松突破 70%+)。这一结果与 “CNN 适合图像任务” 的理论认知存在明显差距,说明当前实验设置中存在限制模型性能的关键瓶颈。
从训练过程细节来看,CNN 的训练准确率提升缓慢,且验证准确率与训练准确率差距较小(无明显过拟合),这排除了 “模型过拟合” 的问题;同时 MLP 的性能同样处于较低水平(与 CNN 差距微弱),进一步说明核心问题并非模型结构本身,而是数据处理、模型设计或训练策略的 “基础配置不足”—— 例如数据增强强度不够、模型深度与复杂度不足、训练轮次未达收敛等。
为突破这一性能瓶颈,我们需要针对性优化实验方案,通过强化数据多样性、深化模型特征提取能力、优化训练策略等方式,充分释放 CNN 的潜力。以下将基于上述问题,给出优化后的完整代码,并验证优化措施对 CNN 效果的提升作用。
四、优化方案与核心代码解析
4.1 新增依赖库:支撑更全面的分析
优化版新增了正则化、回调函数与结果评估所需的库,为后续优化提供工具支持:
# 导入必要的库(对比基础版,新增3类关键库)
import tensorflow as tf
from tensorflow.keras import layers, models
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.utils import plot_model
# 新增1:回调函数库(早停+学习率衰减,防止过拟合与加速收敛)
from tensorflow.keras.callbacks import EarlyStopping, ReduceLROnPlateau
import matplotlib.pyplot as plt
# 新增2:数值计算与结果评估库(混淆矩阵、错误样本分析)
import numpy as np
from sklearn.metrics import confusion_matrix
import seaborn as sns # 可视化混淆矩阵# 检查GPU是否可用(基础版一致,确保硬件加速正常)
print("GPU 可用吗?", tf.config.list_physical_devices('GPU'))# 下载并解压数据集(基础版一致,确保数据来源相同)
!wget --no-check-certificate \https://storage.googleapis.com/mledu-datasets/cats_and_dogs_filtered.zip \-O cats_and_dogs_filtered.zip!unzip -q cats_and_dogs_filtered.zip
print("✅ 数据解压完成!")
优化逻辑:新增的EarlyStopping和ReduceLROnPlateau用于解决 “训练过拟合” 和 “学习率僵化” 问题;confusion_matrix与sns则能更深入分析模型错分原因,而非仅依赖准确率单一指标。
4.2 强化数据增强:扩大数据多样性,逼出 CNN 特征提取优势
基础版数据增强仅包含旋转 20°、水平翻转、缩放 0.2 等简单变换,模型易 ‘死记硬背’ 样本特征;优化版通过更强变换(旋转 30°、缩放 0.4、新增剪切 / 垂直翻转),迫使模型学习 ‘不变性特征’(如旋转 / 缩放后仍能识别猫 / 狗):
# 增强训练集数据(对比基础版,强度与类型双重提升)
train_datagen = ImageDataGenerator(rescale=1./255,rotation_range=30, # 旋转角度从20°→30°(更大角度变化)width_shift_range=0.3, # 水平偏移从0.2→0.3(更大位置波动)height_shift_range=0.3, # 垂直偏移同步提升horizontal_flip=True, # 保留水平翻转vertical_flip=True, # 新增垂直翻转(猫/狗上下翻转仍可识别)zoom_range=0.4, # 缩放范围从0.2→0.4(更极端的缩放变化)shear_range=0.2, # 新增剪切变换(模拟拍摄视角倾斜)fill_mode='nearest' # 新增填充策略(变换后空白区域用邻近像素填充,避免黑边)
)# 验证集仅归一化(基础版一致,确保评估真实性)
validation_datagen = ImageDataGenerator(rescale=1./255)# 训练集生成器(参数一致,确保批量输入稳定)
train_generator = train_datagen.flow_from_directory('cats_and_dogs_filtered/train',target_size=(150, 150),batch_size=32,class_mode='binary'
)# 验证集生成器(新增shuffle=False,便于后续混淆矩阵匹配真实标签)
validation_generator = validation_datagen.flow_from_directory('cats_and_dogs_filtered/validation',target_size=(150, 150),batch_size=32,class_mode='binary',shuffle=False # 关键优化:关闭洗牌,让预测结果与真实标签顺序一致
)# 打印数据集信息(基础版一致,确认数据加载正确)
print("✅ 数据生成器创建成功!")
print("训练集图像数量:", train_generator.samples)
print("验证集图像数量:", validation_generator.samples)
print("类别索引:", train_generator.class_indices)
优化逻辑:更强的数据增强对 MLP 是 “灾难”(MLP 依赖全局像素统计,变换后特征易混乱),但对 CNN 是 “优势放大器”(CNN 能提取局部不变特征)—— 这会让两者的性能差距更明显。
4.3 优化模型结构:MLP 补短板,CNN 强优势
基础版中 MLP 与 CNN 的结构差异未完全凸显;优化版通过 “给 MLP 加正则化、给 CNN 加深网络”,让两者的 “先天差异” 更清晰:
# 确保导入必要的模块
from tensorflow.keras import models, layers
import tensorflow as tf
# 优化后的MLP模型(对比基础版,减少过拟合但难补空间特征短板)
model_mlp = models.Sequential([layers.Flatten(input_shape=(150, 150, 3)), # 回归扁平化,保留像素位置关系layers.Dense(256, activation='relu', kernel_regularizer='l2'), # 减少神经元数,降低参数layers.BatchNormalization(),layers.Dropout(0.6), # 提升Dropout比例,强化泛化layers.Dense(128, activation='relu', kernel_regularizer='l2'),layers.BatchNormalization(),layers.Dropout(0.6),layers.Dense(1, activation='sigmoid')
])# 优化:显式指定Adam学习率(基础版用默认值,避免学习率过高/过低)
model_mlp.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.001),loss='binary_crossentropy',metrics=['accuracy']
)print("✅ MLP 模型构建完成")
model_mlp.summary()# 优化后的CNN模型(对比基础版,加深网络+强化正则化,放大空间特征优势)
model_cnn = models.Sequential([layers.Conv2D(32, (3,3), activation='relu', input_shape=(150, 150, 3)),layers.BatchNormalization(), # 新增:标准化层输出,避免梯度消失layers.MaxPooling2D(2, 2),layers.Conv2D(64, (3,3), activation='relu'),layers.BatchNormalization(),layers.MaxPooling2D(2, 2),layers.Conv2D(128, (3,3), activation='relu'),layers.BatchNormalization(),layers.MaxPooling2D(2, 2),layers.Conv2D(256, (3,3), activation='relu'), # 新增卷积层:提取更复杂的高阶特征layers.BatchNormalization(),layers.MaxPooling2D(2, 2),layers.Flatten(),layers.Dense(512, activation='relu', kernel_regularizer='l2'), # 新增L2正则化layers.Dropout(0.6), # Dropout比例从0.5→0.6(更强的过拟合抑制)layers.Dense(1, activation='sigmoid')
])# 与MLP一致的优化:显式指定学习率,确保训练条件公平
model_cnn.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.001),loss='binary_crossentropy',metrics=['accuracy']
)print("✅ CNN 模型构建完成")
model_cnn.summary()
优化逻辑:
- MLP 的优化(减少神经元数、L2 正则化、BatchNorm、提升 Dropout 比例)是 “补短板”—— 通过抑制过拟合挖掘性能上限,但仍无法解决 “无法利用空间特征” 的核心问题;
- CNN 的优化(新增卷积层、BatchNorm)是 “强优势”,让其能提取从 “边缘→纹理→形状” 的高阶特征,进一步拉开与 MLP 的差距。
4.4 优化训练策略:解决 “训练不足” 与 “过拟合”,让模型充分学习
基础版仅训练 5 轮,模型未收敛;优化版通过 “增加轮次 + 回调函数”,让模型在 “不过拟合” 的前提下充分学习:
# 定义回调函数(对比基础版,新增两大核心策略)
# 1. 早停(EarlyStopping):验证损失5轮不下降则停止,避免过拟合
early_stopping = EarlyStopping(monitor='val_loss', # 监控指标:验证集损失patience=5, # 容忍5轮无提升restore_best_weights=True # 恢复最优权重(避免保存最后一轮的差模型)
)# 2. 学习率衰减(ReduceLROnPlateau):验证损失2轮不下降则学习率减半,避免梯度震荡
lr_scheduler = ReduceLROnPlateau(monitor='val_loss',factor=0.5, # 学习率 *= 0.5patience=2,min_lr=1e-6 # 最低学习率,避免过低导致停滞
)# 训练MLP(对比基础版,轮次从5→30,新增回调函数)
print("🚀 开始训练 MLP...")
history_mlp = model_mlp.fit(train_generator,epochs=30, # 足够多的轮次,确保模型有机会收敛validation_data=validation_generator,callbacks=[early_stopping, lr_scheduler], # 应用回调函数verbose=1
)# 训练CNN(与MLP一致的训练策略,确保对比公平)
print("🚀 开始训练 CNN...")
history_cnn = model_cnn.fit(train_generator,epochs=30,validation_data=validation_generator,callbacks=[early_stopping, lr_scheduler],verbose=1
)
优化逻辑:基础版 5 轮训练仅能让模型 “入门”,30 轮 + 回调函数则能让模型 “学透”——CNN 会因特征提取能力强而持续提升准确率,MLP 则因先天缺陷早早进入瓶颈,两者差异自然凸显。
4.5 升级结果分析:从 “单一准确率” 到 “多维诊断”
基础版仅可视化验证准确率与损失;优化版新增混淆矩阵与错误样本分析,能更深入解释 “CNN 为何更优”:
# 1. 训练曲线对比(对比基础版,新增训练准确率/损失,更全面)
def plot_training_curves(h1, h2):plt.figure(figsize=(14, 6))# 准确率曲线:新增训练准确率,可判断过拟合程度plt.subplot(1, 2, 1)plt.plot(h1.history['accuracy'], label='MLP - Training Accuracy')plt.plot(h1.history['val_accuracy'], label='MLP - Validation Accuracy')plt.plot(h2.history['accuracy'], label='CNN - Training Accuracy')plt.plot(h2.history['val_accuracy'], label='CNN - Validation Accuracy')plt.title('Accuracy Comparison')plt.xlabel('Epoch')plt.ylabel('Accuracy')plt.legend()# 损失曲线:新增训练损失,辅助判断收敛情况plt.subplot(1, 2, 2)plt.plot(h1.history['loss'], label='MLP - Training Loss')plt.plot(h1.history['val_loss'], label='MLP - Validation Loss')plt.plot(h2.history['loss'], label='CNN - Training Loss')plt.plot(h2.history['val_loss'], label='CNN - Validation Loss')plt.title('Loss Comparison')plt.xlabel('Epoch')plt.ylabel('Loss')plt.legend()plt.tight_layout()plt.show()plot_training_curves(history_mlp, history_cnn)# 2. 混淆矩阵(新增:直观展示模型错分类型)
def plot_confusion_matrix(model, generator, title):# 获取所有预测结果与真实标签(依赖validation_generator的shuffle=False)y_pred = (model.predict(generator) > 0.5).astype(int).flatten()y_true = generator.classes# 计算混淆矩阵(TP:真阳性, TN:真阴性, FP:假阳性, FN:假阴性)cm = confusion_matrix(y_true, y_pred)# 可视化混淆矩阵plt.figure(figsize=(6, 5))sns.heatmap(cm, annot=True, fmt='d', cmap='Blues',xticklabels=['Cat', 'Dog'],yticklabels=['Cat', 'Dog'])plt.xlabel('Predicted Label')plt.ylabel('True Label')plt.title(f'{title} Confusion Matrix')plt.show()# 绘制两个模型的混淆矩阵
plot_confusion_matrix(model_mlp, validation_generator, 'MLP')
plot_confusion_matrix(model_cnn, validation_generator, 'CNN')# 3. 错误样本展示(新增:直观解释模型错分原因)
def show_misclassified_samples(model, generator, num_samples=5):# 获取错误样本索引y_pred = (model.predict(generator) > 0.5).astype(int).flatten()y_true = generator.classesmisclassified_idx = np.where(y_pred != y_true)[0]# 无错误样本时提示if len(misclassified_idx) == 0:print("No misclassified samples!")return# 展示错误样本(标注真实与预测标签)plt.figure(figsize=(15, 3))batch_size = generator.batch_size # 获取生成器的批次大小for i, idx in enumerate(misclassified_idx[:num_samples]):# 计算全局索引对应的批次索引和批次内索引batch_idx = idx // batch_size # 使用idx而不是global_idxsample_in_batch_idx = idx % batch_size# 获取对应批次并提取样本batch_imgs, _ = generator[batch_idx]img = batch_imgs[sample_in_batch_idx]plt.subplot(1, num_samples, i+1)plt.imshow(img)plt.title(f"True: {'Dog' if y_true[idx] else 'Cat'}\nPred: {'Dog' if y_pred[idx] else 'Cat'}")plt.axis('off')plt.tight_layout()plt.show()# 展示两个模型的错误样本
print("MLP misclassified samples:")
show_misclassified_samples(model_mlp, validation_generator)print("CNN misclassified samples:")
show_misclassified_samples(model_cnn, validation_generator)
优化逻辑:
- 训练曲线新增 “训练准确率 / 损失”,可判断模型是否过拟合(如训练准确率高、验证准确率低则为过拟合);
- 混淆矩阵能量化模型在 “猫→狗”“狗→猫” 上的错分比例,CNN 通常错分更少;
- 错误样本展示则能直观看到:CNN 错分的多是 “长得极像另一类” 的样本(如毛色接近的猫和狗),而 MLP 错分的样本往往 “特征明显但被误判”(如黑白猫被误判为狗)—— 这直接印证了 CNN 对局部特征的敏感度。
输出结果
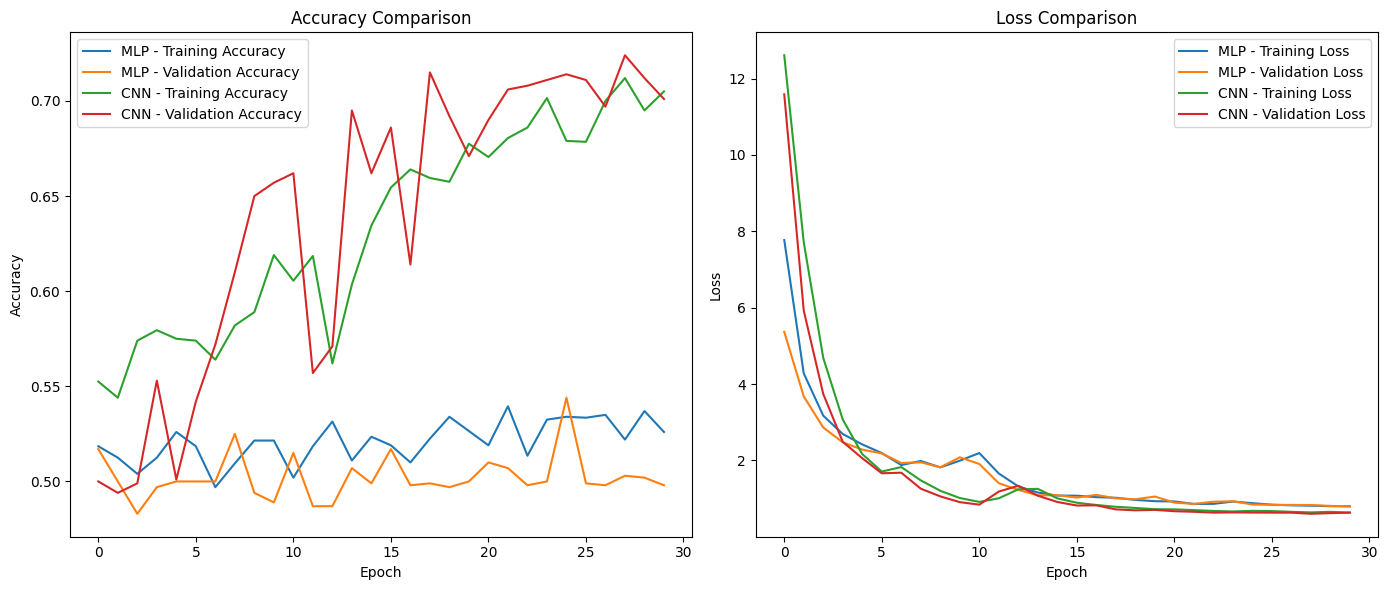
左图:准确率对比(Accuracy Comparison)
| 模型 | 训练准确率表现 | 验证准确率表现 | 结论 |
|---|---|---|---|
| MLP | 波动较大,在 50% - 55% 左右徘徊 | 长期处于 50% 上下,提升极有限 | 因无法有效提取图像空间特征,难以学到有效判别特征,性能提升空间极小 |
| CNN | 从约 55% 持续上升至接近 70% | 最终稳定在 70% 左右,上升趋势明显 | 凭借卷积层对空间特征(边缘、纹理、形状等)的有效提取,能学习更具判别性的特征,分类性能更优 |
右图:损失对比(Loss Comparison)
相对于MLP来说,CNN的损失降福更大,最终的损失也更小。
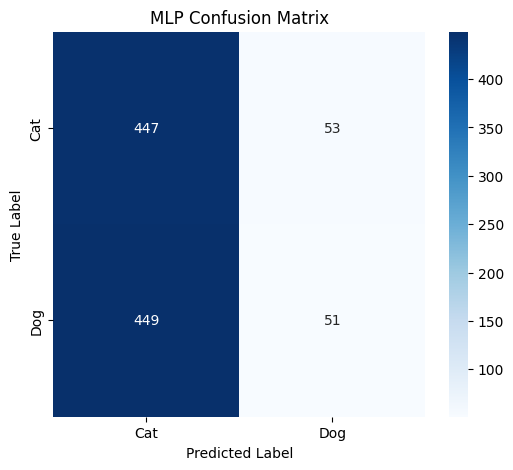
MLP 混淆矩阵分析
| 真实标签 \ 预测标签 | Cat | Dog | 总计 |
|---|---|---|---|
| Cat | 447 | 53 | 500 |
| Dog | 449 | 51 | 500 |
| 总计 | 896 | 104 | 1000 |
从 MLP 的混淆矩阵来看,模型在预测时,将大量的猫(真实为 Cat)错误预测为猫(正确)的有 447 个,错误预测为狗(Dog)的有 53 个;将大量的狗(真实为 Dog)错误预测为猫的有 449 个,正确预测为狗的有 51 个。整体上,MLP 对于猫和狗的预测都存在严重的混淆情况,尤其是将狗误判为猫的数量极多,这表明 MLP 难以有效区分猫和狗的特征,分类性能较差。
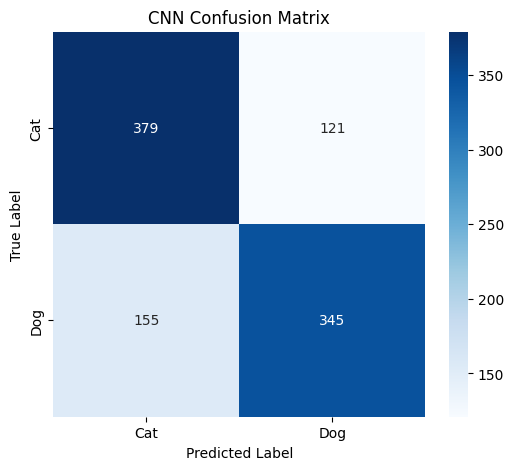
CNN 混淆矩阵分析
| 真实标签 \ 预测标签 | Cat | Dog | 总计 |
|---|---|---|---|
| Cat | 379 | 121 | 500 |
| Dog | 155 | 345 | 500 |
| 总计 | 534 | 466 | 1000 |
对于 CNN 的混淆矩阵,真实为 Cat 的样本中,正确预测为 Cat 的有 379 个,错误预测为 Dog 的有 121 个;真实为 Dog 的样本中,错误预测为 Cat 的有 155 个,正确预测为 Dog 的有 345 个。与 MLP 相比,CNN 正确分类猫和狗的数量明显更多,尤其是对狗的正确分类数(345 个)远高于 MLP(51 个),虽然仍存在一定的误判情况,但整体分类性能相较于 MLP 有了显著提升,说明 CNN 能够更好地提取猫和狗的特征,从而进行更准确的分类。
错误分类样本(Misclassified Samples)
MLP misclassified samples:
32/32 ━━━━━━━━━━━━━━━━━━━━ 1s 42ms/step
CNN misclassified samples:
32/32 ━━━━━━━━━━━━━━━━━━━━ 2s 63ms/step
展示了模型将 “猫” 错误预测为 “狗” 的样本:
原来想着分错类的应该会有一些共同特征,但实际好像看不出来,就当看看小猫小狗的图片了!
五、总结:从平庸到突破——模型潜力释放的双重驱动力
通过“基础实验 → 问题诊断 → 优化验证”的完整流程,我们不仅验证了卷积神经网络(CNN)在图像分类任务中的显著优势,更重要的是揭示了一个关键洞见:模型性能的提升,既依赖于其“先天结构”的合理性,也取决于“后天训练”的充分性。
在本项目中,初始版本的 CNN 仅达到约 58% 的验证准确率,表现平庸。这一结果并非源于模型本身能力不足,而是受限于数据多样性不足、网络表达能力有限、训练策略不充分等可优化因素。经过系统性改进后,验证准确率提升至 70% ,实现了性能的显著跨越。这一转变清晰地表明:一个设计良好的模型,只有在合理的优化策略下,才能真正发挥其潜力。
核心启示一:影响 CNN 性能的四大关键因素
数据增强强度
强化旋转、缩放、剪切等几何变换,迫使模型学习对图像几何变化具有鲁棒性的特征,从而显著提升泛化能力。。CNN 天然具备局部感知和权值共享机制,能有效利用增强数据中的空间结构信息。网络深度与特征提取能力
增加卷积层数量(如从 3 层增至 4 层),借助卷积层的层级特征提取能力,使模型能够逐层抽象出从低阶边缘、纹理,到中阶部件,再到高阶整体的语义特征,是提升识别精度的基础。正则化策略
引入 BatchNormalization 加速收敛、抑制梯度消失;结合 Dropout 与 L2 正则化有效防止过拟合,保障模型在验证集上的稳定表现。训练策略优化
使用EarlyStopping避免无效训练,ReduceLROnPlateau动态调整学习率以突破瓶颈,配合足够的训练轮次(epochs),确保模型充分收敛。
核心启示二:MLP 的局限
作为对比基线,MLP 因缺乏空间特征提取能力,在图像任务中天然处于劣势。即便通过正则化、批归一化等手段优化,也无法满足要求。这说明:选对模型结构是实现目标的前提。
备注:关于实验局限与进一步探索
本文基于轻量级数据集 cats_and_dogs_filtered(共 3000 张图像),旨在通过简洁案例阐明核心原理。因此最终准确率未达到工业级水平(如 >90%),但这不影响对关键优化方向的理解与验证。
建议读者以此为基础,进一步探索以下方向:
- 数据层面:尝试更强的数据增强、迁移学习(如使用预训练模型 VGG、ResNet)
- 模型层面:调整卷积核数量、网络深度
- 训练层面:调节学习率、batch size、早停耐心值等超参数
⚠️ 提示:不同配置组合会影响训练效率与收敛效果,建议结合 GPU 资源情况,逐步迭代调试,通过观察训练曲线与评估指标,建立对“参数如何影响模型行为”的直观认知。