rook-ceph的ssd类osd的纠删码rgw存储池在迁移时的异常处理
背景
原本有个osd是ssd存储,现在新加入三个hdd的osd,想把数据迁移到hdd的osd上提高数据安全以及让ssd存储下线。
osd加入之后,正常来说把原本的osd权重设置为0后就会根据crush的默认规则把数据迁移到新加入的osd上。
把所有存储池的设置为副本2后,迁移都正常,然后只有纠删码迁移时出现了问题。
问题原因
# 列出所有 undersized 的 PG
ceph pg dump_stuck undersized # 列出所有 inactive 的 PG
ceph pg dump_stuck inactive
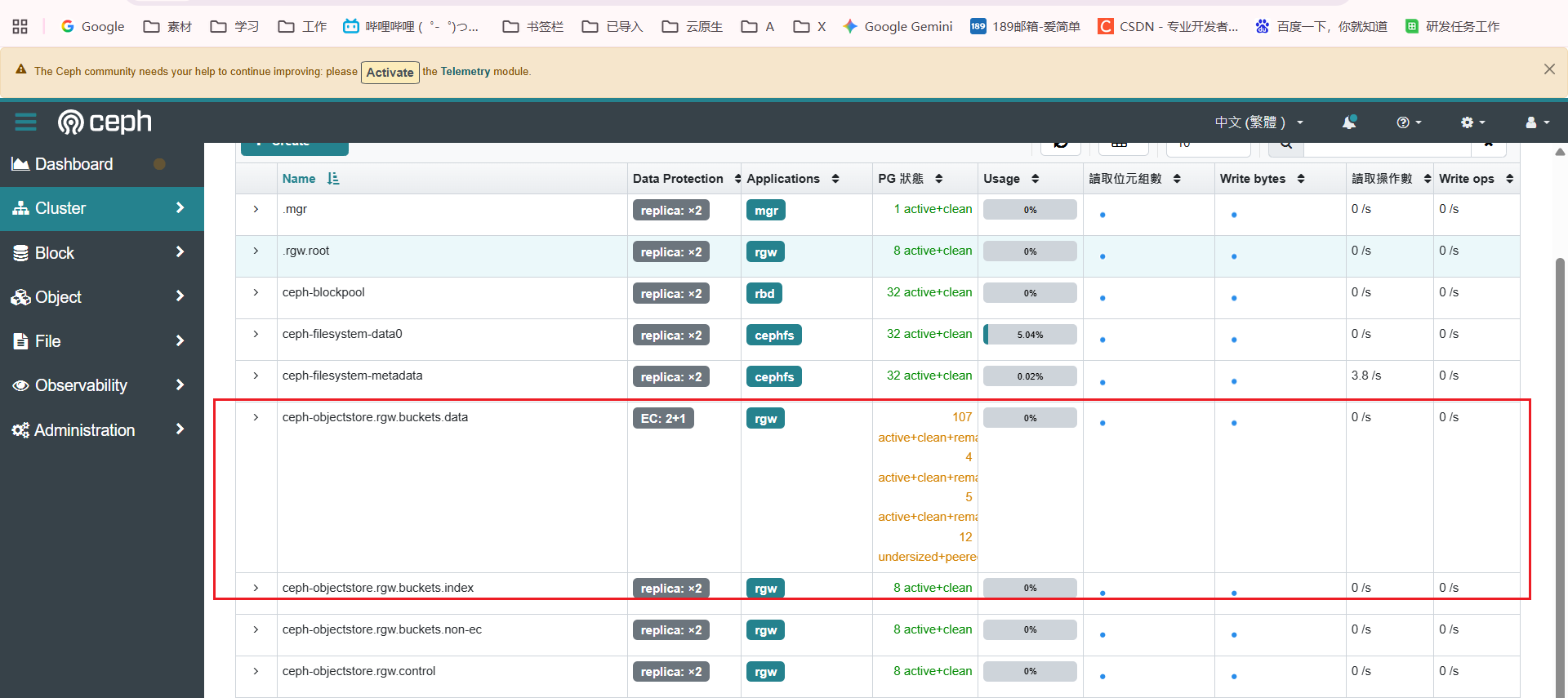
查看问题pg的报错提示的内容是osd数量不符合迁移策略
ceph pg 故障pgid query
核心异常点:state: “active+undersized”
undersized:表示 数据分片数量不足(不满足 Pool 配置的冗余策略,比如纠删码 “分片数 + 校验数” 要求、或副本池 “副本数” 要求)。
Pool 是纠删码(EC)池(如界面中显示 EC: 2+1),需满足 “2 个数据分片 + 1 个校验分片”,因此至少需要 3 个 OSD 承载分片。
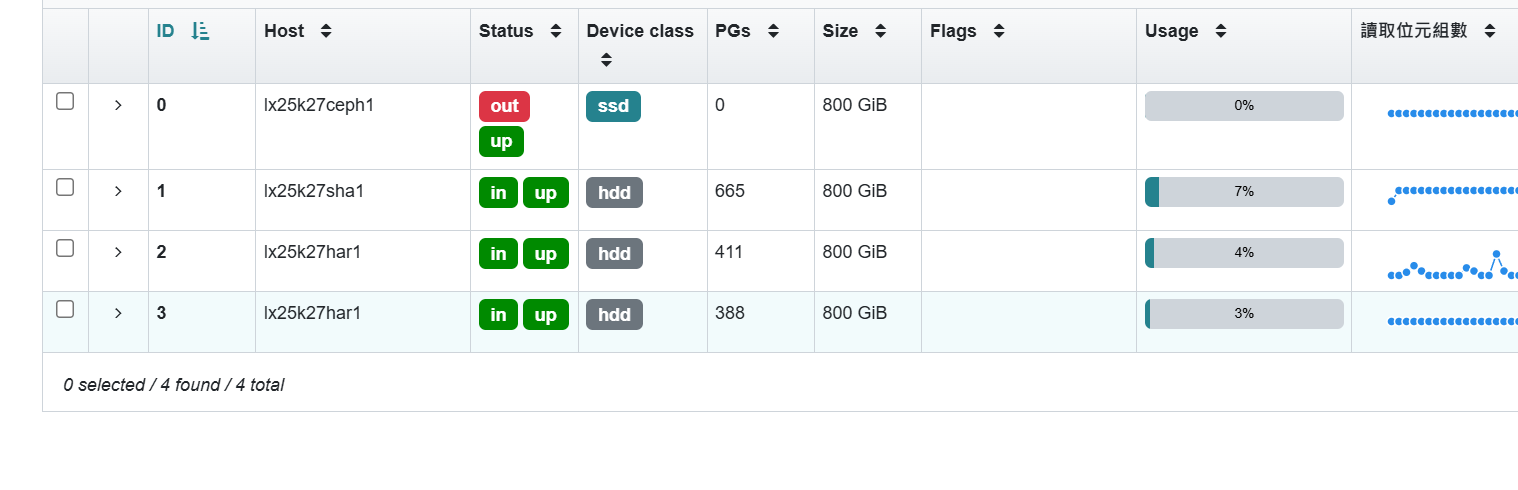
也确实有三个osd加进来,这条符合,继续查看具体的迁移策略
接着查看下纠删码的故障配置,找到目标纠删码 Pool 关联的 Erasure Code Profile 名称
ceph osd pool get <pool-name> erasure_code_profile
查看 Erasure Code Profile 的故障域配置
ceph osd erasure-code-profile get <profile-name>
例如
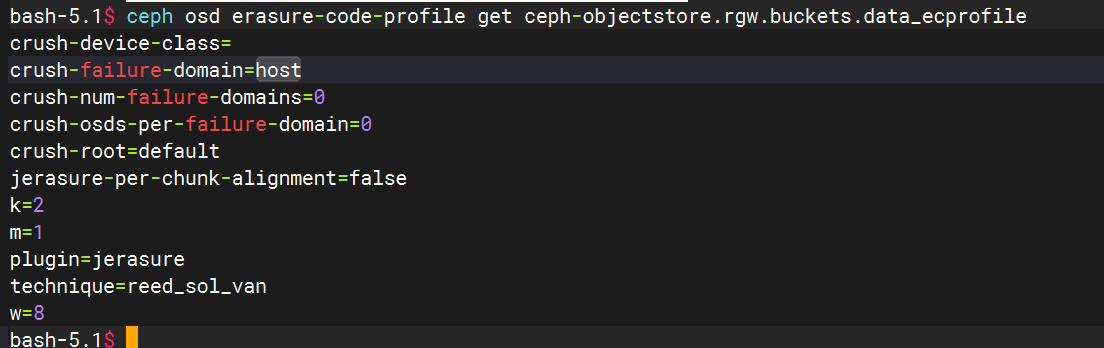
其中crush-failure-domain=host就是故障域配置,不同的类型表示不同的故障域数据迁移策略
故障域(crush-failure-domain):决定了纠删码分片的分布策略。常见取值为 host(默认,分片分布在不同主机的 OSD 上)、osd(分片可分布在同一主机的不同 OSD 上)、rack(分片分布在不同机架的主机上)等。
然后实际环境中是只有两台主机有三块盘做成的osd,也就是说crush-failure-domain=host是不符合要求的,需要把类型改成osd。
处理流程
创建名为 new-profile-233 的纠删码配置,匹配当前池的 EC 2+1 类型,并设置故障域为 osd
bash-5.1$ ceph osd erasure-code-profile set new-profile-233 \k=2 \m=1 \crush-failure-domain=osd
k=2:数据分片数为 2(对应 “EC 2+1” 的 “2”)。
m=1:校验分片数为 1(对应 “EC 2+1” 的 “+1”)。
crush-failure-domain=osd:故障域设为 OSD(数据分片分布到不同 OSD 上,提升冗余性)。
创建 CRUSH 规则(关联 Erasure Code Profile)
ceph osd crush rule create-erasure new-rule-233 new-profile-233
将目标 Pool 关联到新 CRUSH 规则
ceph osd pool set ceph-objectstore.rgw.buckets.data crush_rule new-rule-233
验证配置
查看 Erasure Code Profile 详情
ceph osd erasure-code-profile get new-profile-233
查看 CRUSH 规则详情
ceph osd crush rule dump new-rule-233
查看 Pool 关联的 CRUSH 规则
ceph osd pool get ceph-objectstore.rgw.buckets.data crush_rule
查看集群状态
ceph -s
重新再web上查看,数据全部过去,pool已经恢复正常
