SpringBoot整合Kafka总结
SpringBoot整合Kafka总结
Kafka基本介绍
kafka是一个分布式的,分区的消息(官方称之为commit log)服务,是一个消息服务组件,使用场景有如下:
- 削峰平谷:处理大量消息写入(积分发送与消费)
- 消息广播:消息发送导不同平台(订单消息发送的不同应用)
Kafka相关术语与工作原理
| 名称 | 解释 |
|---|---|
| Broker | 消息中间件处理节点,一个Kafka节点就是一个broker,一个或者多个Broker可以组成一个Kafka集群 |
| Topic | Kafka根据topic对消息进行归类,发布到Kafka集群的每条消息都需要指定一个topic |
| Producer | 消息生产者,向Broker发送消息的客户端 |
| Consumer | 消息消费者,从Broker读取消息的客户端 |
| ConsumerGroup | 每个Consumer属于一个特定的Consumer Group,一条消息可以被多个不同的Consumer |
| Partition | 物理上的概念,一个topic可以分为多个partition,每个partition内部消息是有序的 |
Producers
生产者将消息发送到topic中去,同时负责选择将message发送到topic的哪一个partition中。通过round-robin做简单的负载均衡。也可以根据消息中的某一个关键字来进行区分。通常第二种方式使用的更多。
Consumers
传统的消息传递模式有2种:队列( queue) 和(publish-subscribe)
queue模式:多个consumer从服务器中读取数据,消息只会到达一个consumer。
publish-subscribe模式:消息会被广播给所有的consumer。
Kafka基于这2种模式提供了一种consumer的抽象概念:consumer group。
queue模式:所有的consumer都位于同一个consumer group 下。
publish-subscribe模式:所有的consumer都有着自己唯一的consumer group。
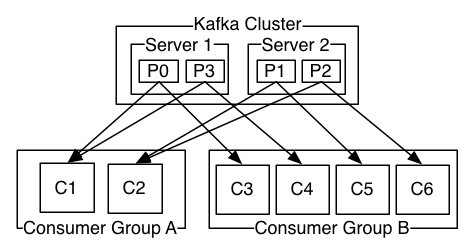
上图说明:由2个broker组成的kafka集群,某个主题总共有4个partition(P0-P3),分别位于不同的broker上。这个集群由2个Consumer Group消费, A有2个consumer instances ,B有4个。
通常一个topic会有几个consumer group,每个consumer group都是一个逻辑上的订阅者( logical subscriber )。每个consumer group由多个consumer instance组成,从而达到可扩展和容灾的功能。
消费顺序
一个partition同一个时刻在一个consumer group中只能有一个consumer instance在消费,从而保证消费顺序。
consumer group中的consumer instance的数量不能比一个Topic中的partition的数量多,否则,多出来的consumer消费不到消息。
Kafka只在partition的范围内保证消息消费的局部顺序性,不能在同一个topic中的多个partition中保证总的消费顺序性。
如果有在总体上保证消费顺序的需求,那么我们可以通过将topic的partition数量设置为1,将consumer group中的consumer instance数量也设置为1,但是这样会影响性能,所以kafka的顺序消费很少用。
集成使用
引入spring boot kafka依赖
<dependency><groupId>org.springframework.kafka</groupId><artifactId>spring-kafka</artifactId>
</dependency>
application.yml配置如下:
server:port: 8080spring:kafka:start: promotion: truebootstrap-servers: 10.0.12.95:9092producer:# 发生错误后,消息重发的次数。retries: 3#当有多个消息需要被发送到同一个分区时,生产者会把它们放在同一个批次里。该参数指定了一个批次可以使用的内存大小,按照字节数计算。batch-size: 16384# 设置生产者内存缓冲区的大小。buffer-memory: 33554432# 键的序列化方式key-serializer: org.apache.kafka.common.serialization.StringSerializer# 值的序列化方式value-serializer: org.apache.kafka.common.serialization.StringSerializer# acks=0 : 生产者在成功写入消息之前不会等待任何来自服务器的响应。# acks=1 : 只要集群的首领节点收到消息,生产者就会收到一个来自服务器成功响应。# acks=all :只有当所有参与复制的节点全部收到消息时,生产者才会收到一个来自服务器的成功响应。acks: 1#生产者生成的所有数据的压缩类型,此配置接受标准压缩编解码器('gzip','snappy','lz4'),#没有压缩以及保留生产者设置的原始压缩编解码器('uncompressed','producer'),默认值为producercompression-type: lz4consumer:# 指定默认消费者group idgroup-id: live-expand-java# 自动提交的时间间隔 在spring boot 2.X 版本中这里采用的是值的类型为Duration 需要符合特定的格式,如1S,1M,2H,5Dauto-commit-interval: 3# 该属性指定了消费者在读取一个没有偏移量的分区或者偏移量无效的情况下该作何处理:# latest(默认值)在偏移量无效的情况下,消费者将从最新的记录开始读取数据(在消费者启动之后生成的记录)# earliest :在偏移量无效的情况下,消费者将从起始位置读取分区的记录auto-offset-reset: latest# 是否自动提交偏移量,默认值是true,为了避免出现重复数据和数据丢失,可以把它设置为false,然后手动提交偏移量enable-auto-commit: true#消费者会话超时时间,默认10000sessionTimeout: 10000#心跳间隔,默认3000heartbeatInterval: 3000# 键的反序列化方式key-deserializer: org.apache.kafka.common.serialization.StringDeserializer# 值的反序列化方式value-deserializer: org.apache.kafka.common.serialization.StringDeserializer#设置批量消费数量max-poll-records: 50listener:# 在侦听器容器中运行的线程数。concurrency: 1#listner负责ack,每调用一次,就立即commit# ack-mode: manual_immediatemissing-topics-fatal: false
KafkaConfig配置
package com.vzan.config.kafka;import java.util.HashMap;
import java.util.Map;import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.boot.autoconfigure.condition.ConditionalOnProperty;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.annotation.EnableKafka;
import org.springframework.kafka.config.ConcurrentKafkaListenerContainerFactory;
import org.springframework.kafka.config.KafkaListenerContainerFactory;
import org.springframework.kafka.core.ConsumerFactory;
import org.springframework.kafka.core.DefaultKafkaConsumerFactory;
import org.springframework.kafka.core.DefaultKafkaProducerFactory;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.core.ProducerFactory;
import org.springframework.kafka.listener.ConcurrentMessageListenerContainer;@Configuration
@EnableKafka
@ConditionalOnProperty(value = "kafka.enable", havingValue = "true", matchIfMissing = true)
public class KafkaConfig {@Value("${spring.kafka.bootstrap-servers}")private String bootstrapServers;//生成者配置@Value("${spring.kafka.producer.retries}")private Integer retries;@Value("${spring.kafka.producer.batch-size}")private Integer batchSize;@Value("${spring.kafka.producer.buffer-memory}")private Integer bufferMemory;@Value("${spring.kafka.producer.compression-type}")private Integer compressionType;@Value("${spring.kafka.producer.key-deserializer}")private String producerKeyDeserializer;@Value("${spring.kafka.producer.value-deserializer}")private String producerValueDeserializer;@Value("${spring.kafka.producer.acks}")private String acks;//消费者配置@Value("${spring.kafka.consumer.group-id}")private String groupid;@Value("${spring.kafka.consumer.enable-auto-commit}")private String autoCommit;@Value("${spring.kafka.consumer.auto-commit-interval}")private String interval;// 默认消费者会话超时时间为10000ms,适当调大可以减少误判@Value("${spring.kafka.consumer.sessionTimeout:10000}")private String sessionTimeout;// 心跳间隔(默认 3s,建议设置为 session.timeout.ms 的 1/3)@Value("${spring.kafka.consumer.heartbeatInterval:3000}")private String heartbeatInterval;@Value("${spring.kafka.consumer.key-deserializer}")private String keyDeserializer;@Value("${spring.kafka.consumer.value-deserializer}")private String valueDeserializer;@Value("${spring.kafka.consumer.auto-offset-reset}")private String offsetReset;@Value("${spring.kafka.consumer.max-poll-records}")private String maxPollRecords;//监听配置@Value("${spring.kafka.listener.concurrency: 1}")private Integer concurrency;@Beanpublic KafkaTemplate<String, Object> kafkaV4Template() {return new KafkaTemplate(producerFactory());}@Bean("kafkaV4ContainerFactory")KafkaListenerContainerFactory<ConcurrentMessageListenerContainer<Integer, String>> kafkaContainerFactory() {ConcurrentKafkaListenerContainerFactory<Integer, String> factory =new ConcurrentKafkaListenerContainerFactory<>();factory.setConsumerFactory(consumerFactory());factory.setConcurrency(concurrency);//是否批量消费factory.setBatchListener(true);factory.getContainerProperties().setPollTimeout(3000);return factory;}private ProducerFactory<String, String> producerFactory() {return new DefaultKafkaProducerFactory<>(producerConfigs());}public ConsumerFactory<Integer, String> consumerFactory() {return new DefaultKafkaConsumerFactory<>(consumerConfigs());}/*** 生产者配置* @return*/private Map<String, Object> producerConfigs() {Map<String, Object> props = new HashMap<>();props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);props.put(ProducerConfig.RETRIES_CONFIG, retries);props.put(ProducerConfig.BATCH_SIZE_CONFIG, batchSize);props.put(ProducerConfig.BUFFER_MEMORY_CONFIG, bufferMemory);props.put(ProducerConfig.ACKS_CONFIG, acks);props.put(ProducerConfig.COMPRESSION_TYPE_CONFIG, compressionType);props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, producerKeyDeserializer);props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, producerValueDeserializer);return props;}/*** 消费组配置* @return*/private Map<String, Object> consumerConfigs() {Map<String, Object> props = new HashMap<>();props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,bootstrapServers);props.put(ConsumerConfig.GROUP_ID_CONFIG, groupid);props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, autoCommit);props.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, interval);props.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG,sessionTimeout);props.put(ConsumerConfig.HEARTBEAT_INTERVAL_MS_CONFIG,heartbeatInterval);props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, keyDeserializer);props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, valueDeserializer);props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG,offsetReset);props.put(ConsumerConfig.MAX_POLL_RECORDS_CONFIG,maxPollRecords);return props;}
}
发送者代码:
package com.kafka;import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;@RestController
public class KafkaController {private final static String TOPIC_NAME = "my-replicated-topic";@Autowiredprivate KafkaTemplate<String, String> kafkaTemplate;@RequestMapping("/send")public void send() {kafkaTemplate.send(TOPIC_NAME, 0, "key", "this is a msg");}}
消费者代码:
package com.kafka;import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.kafka.support.Acknowledgment;
import org.springframework.stereotype.Component;@Component
public class MyConsumer {/*** @KafkaListener(groupId = "testGroup", topicPartitions = {* @TopicPartition(topic = "topic1", partitions = {"0", "1"}),* @TopicPartition(topic = "topic2", partitions = "0",* partitionOffsets = @PartitionOffset(partition = "1", initialOffset = "100"))* },concurrency = "6")* //concurrency就是同组下的消费者个数,就是并发消费数,必须小于等于分区总数* @param record*/@KafkaListener(topics = "my-replicated-topic",groupId = "zhugeGroup")public void listenZhugeGroup(List<ConsumerRecord<String, String>> records, Acknowledgment ack) {for(ConsumerRecord<String, String> record: records){String value = record.value();System.out.println(value);System.out.println(record);//手动提交offsetack.acknowledge();}}/*//配置多个消费组@KafkaListener(topics = "my-replicated-topic",groupId = "tulingGroup")public void listenTulingGroup(List<ConsumerRecord<String, String>> records, Acknowledgment ack) {for(ConsumerRecord<String, String> record: records){String value = record.value();System.out.println(value);System.out.println(record);ack.acknowledge();}}*/
}