【提示工程】Ch2-提示技术(Prompt Technique)
目录
- 提示技术(Prompt Technique)
- 1、通用提示(General Prompting)/ 零样本(Zero-Shot)
- 2、单样本(One-shot)和 少样本(few-shot)
- 3、系统提示、上下文(system、contextual)提示与角色提示(role prompting)
- (1)系统提示(system Prompting)
- (2)角色提示(Role Prompting)
- (3)上下文提示(Contextual Prompting)
- 4、逐步回溯提示(step back Prompt)
- 思维链 (CoT:chain of thought)
内容较长,耐心看完,定有收获!
提示技术(Prompt Technique)
大型语言模型(LLM)经过大规模数据训练并针对指令跟随进行了优化,使其能够理解用户提示并生成相应回答。然而,LLM 仍存在一定局限性:提示越清晰、越明确,模型生成准确文本的能力就越强。此外,结合对 LLM 训练方式与工作机制的理解,采用特定的提示技术能够进一步提升生成结果的相关性和质量。
在了解了提示工程的基本概念及其要素之后,接下来我们将深入探讨几种最重要的提示技术示例。
1、通用提示(General Prompting)/ 零样本(Zero-Shot)
“零样本”提示是最基本的一类提示方式。它仅通过任务描述和一段文本作为输入,引导大语言模型(LLM)开始生成。输入内容可以是问题、故事开头或指令等任意形式。“零样本”这一名称意指“不提供示例”。
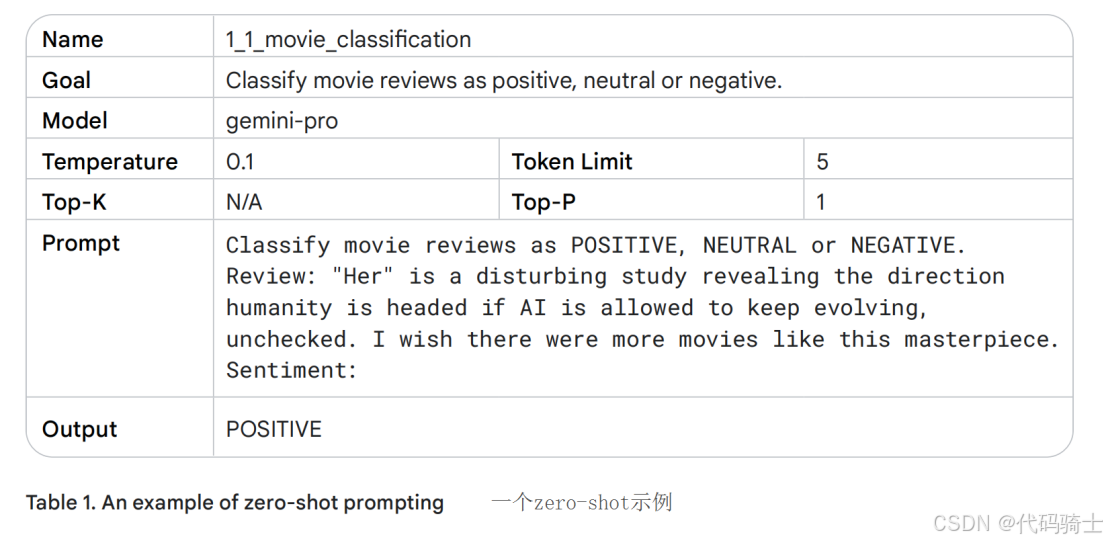
我们以 Vertex AI Studio(语言版)为例,该平台提供了一个用于测试提示的 Playground 环境。如表1所示,这是一个使用零样本提示对电影评论进行分类的示例。
采用如下表格格式是一种高效记录提示的方式。由于提示往往需经过多次迭代才能最终部署到代码库中,保持提示工程工作的结构化和系统性非常重要。关于该表格格式的更多说明、如何跟踪提示工程实验,以及提示开发流程的重要性,将在本章“最佳实践”部分(“记录各类提示尝试”)进一步讨论。
在本示例中,应将模型温度(Temperature)设置为较低值,因为该任务不需要创造性输出。我们使用 gemini-pro 模型默认的 Top-K 和 Top-P 参数,这些默认值实际上等效于禁用这两项设置(详见“LLM 输出配置”部分)。请注意生成的输出结果:由于“disturbing”和“masterpiece”这两个词出现在同一句话中,它们应使分类预测变得略微复杂。
当零样本提示效果不佳时,可以在提示中提供示范或具体示例,此时便引入了“单样本”(one-shot)和“少样本”(few-shot)提示方法。
2、单样本(One-shot)和 少样本(few-shot)
在为 AI 模型创建提示时,提供示例非常有帮助。这些示例可以帮助模型理解你所要求的内容。示例在你希望引导模型朝特定输出结构或模式发展时尤为有用。
单样本提示(One shot)提供单个示例,因此称为单样本。其理念是模型有一个可以模仿的示例来最好地完成任务。
少样本提示(few shot)⁷为模型提供多个示例。这种方法向模型展示它需要遵循的模式。其理念与单样本类似,但多个示例增强了模型遵循所需模式的可能性。
你需要的少样本提示(few shot)示例数量取决于几个因素,包括任务的复杂性、示例的质量以及你使用的生成式 AI(通用 AI)模型的能力。作为一般经验法则,你应至少使用三到五个示例进行少样本提示。然而,对于更复杂的任务,你可能需要使用更多示例;或者由于模型的输入长度限制,你可能需要使用更少的示例。
表 2 显示了一个少样本提示示例,让我们使用相同的 gemini-pro 模型配置设置,与之前相同,只是增加了Token限制以适应更长的响应需求。
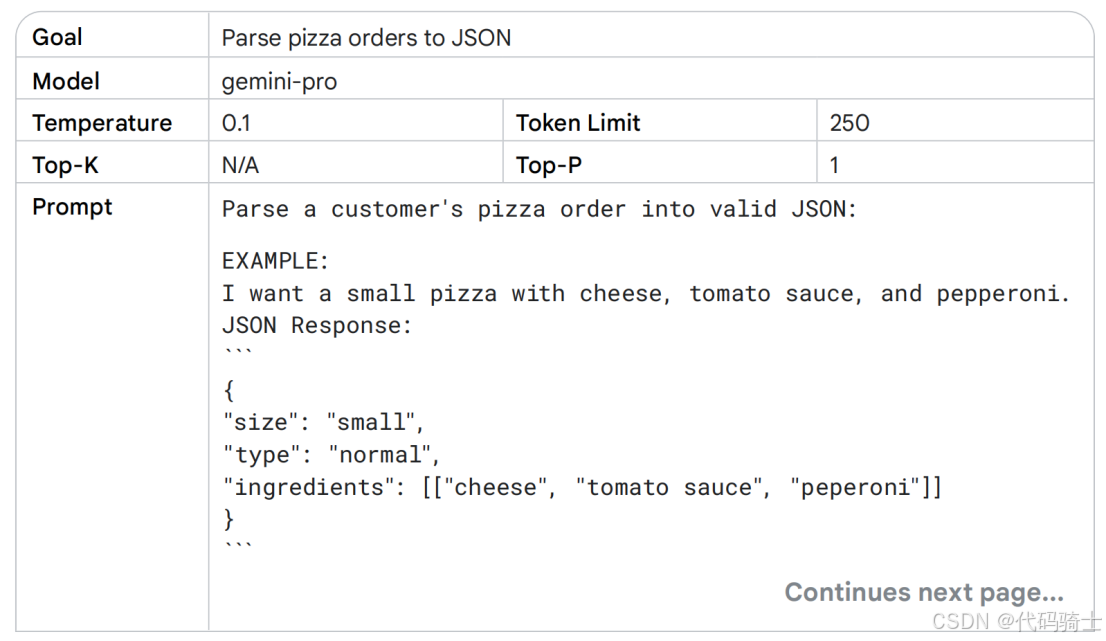

在选择提示中的示例时,应选用与目标任务高度相关的实例。这些示例应当具备多样性、高质量和规范的语言表达。即使是微小的错误也可能误导模型,导致产生不符合预期的输出。
若希望模型生成的输出对各种输入都具有良好的稳健性,则应在示例中涵盖边缘情况。边缘情况指那些异常或意外的输入类型,但仍期望模型能够正确处理它们。
3、系统提示、上下文(system、contextual)提示与角色提示(role prompting)
系统提示、上下文提示和角色提示都是用于引导大语言模型(LLM)生成文本的技术手段,但它们在功能和应用层面各有侧重:
- 系统提示用于设定语言模型的整体上下文与任务目标。它确立了模型的“全局视角”,明确其应完成的任务类型,例如翻译文本、对评论进行分类等。
- 上下文提示则提供与当前对话或任务直接相关的具体背景信息。它帮助模型理解当前输入的细微差异,从而生成更贴合情境的回应。
- 角色提示通过赋予语言模型一个特定的身份或角色,引导其生成符合该角色设定、知识背景和行为特征的文本。
尽管系统、上下文和角色提示在实际应用中可能存在重叠——例如,一个系统提示中可能同时包含角色设定和上下文信息——但三者仍具有不同的主要目标:
- 系统提示:界定模型的核心能力与整体任务框架;
- 上下文提示:提供与当前任务高度相关且动态变化的具体信息,以指导模型生成响应;
- 角色提示:塑造模型的输出风格与语言个性,增强回应的特定性和拟人化程度。
明确区分这三种提示类型,有助于设计意图清晰、结构良好的提示策略。它不仅允许灵活的组合方式,也使得分析各类提示对模型输出的影响变得更加可行。
接下来,我们将对这三种提示类型进行更深入的探讨。
(1)系统提示(system Prompting)
表3展示了一个系统提示,其中我明确规定了输出返回的具体方式。通过提高Temperature参数,模型获得了更高的创造性水平;同时,我还设置了更高的token数量限制以支持更长的生成内容。尽管采取了这些开放性设置,但由于对输出格式给出了清晰约束,模型并未产生任何冗余文本。
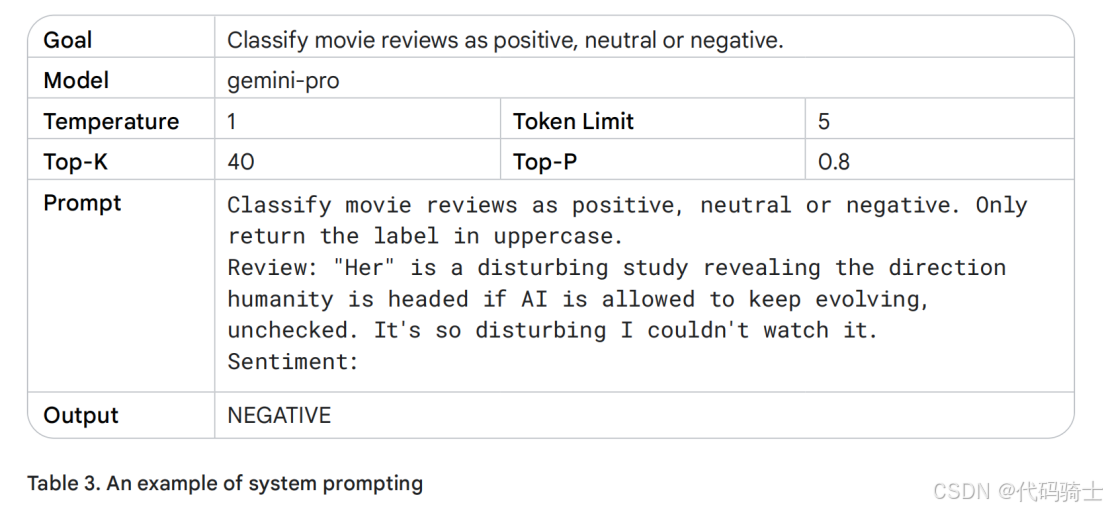
系统提示可用于生成符合特定需求的输出内容。“系统提示”这一名称本质上代表着“向系统提供附加任务指令”。举例来说,您可以通过系统提示生成与特定编程语言兼容的代码片段,或要求系统返回特定结构的数据。请参阅表 4,我在其中以 JSON 格式返回了相应的输出结果。
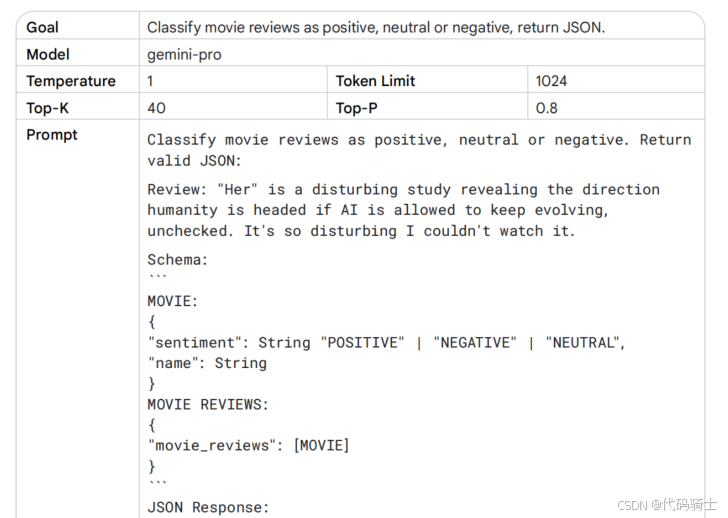

从提示中直接返回 JSON 对象具有多重优势。在实际应用中,这种方式避免了手动构建 JSON 结构的繁琐,可直接输出已按指定顺序排列的数据(在处理日期时间等对象时尤为便捷)。更重要的是,要求模型返回 JSON 格式能够有效约束其输出结构,显著减少幻觉内容的生成。
系统提示在增强安全性和控制有害内容方面同样具有重要价值。只需在提示中添加一句明确的指令,例如:“你应在回答中始终保持尊重”,即可有效引导模型生成符合伦理和安全标准的回复。
(2)角色提示(Role Prompting)
角色提示(Role Prompting)是提示工程中的一项关键技术,指为生成式 AI 模型设定特定角色,以引导其生成更贴合场景、信息更丰富的回复。通过赋予模型明确的角色身份,可以使其基于该角色的视角和语境调整输出内容,从而提升响应的相关性和准确性。
例如,可让生成式 AI 模型扮演图书编辑、幼儿园教师或励志演讲者等不同角色。一旦角色设定完成,用户即可提出与该角色相关的具体任务,如请教师角色生成可供审阅的课程计划。这种技术能够有效约束模型输出风格与内容范围,增强实际应用的针对性和可控性。请参考表 5,其中展示了模型作为旅游向导进行回复的示例。

上述示例展示了让 AI 扮演旅行代理人角色时的输出效果。若将角色调整为地理教师,你将发现其回应在内容和风格上均会有所不同。
为 AI 模型设定角色视角,实际上是为其提供了表达语气、行文风格和专业聚焦方向的蓝图。通过明确角色定位,可以有效引导模型生成更高质量、更具相关性且更符合实际需求的输出,从而显著提升回答的准确性和实用性。

(3)上下文提示(Contextual Prompting)
通过提供充分的上下文信息,你可以确保与 AI 的交互尽可能无缝且高效。模型能够更快速地理解你的请求,并生成更准确、更相关的响应。如表 7 的示例所示,恰当的上下文能够显著提升模型输出的质量和实用性。

4、逐步回溯提示(step back Prompt)
逐步回溯提示(Step-Back Prompting) 是一种技术,通过引导大语言模型(LLM)首先思考与特定任务相关的更广泛问题,然后将得到的答案作为后续具体任务提示的输入。这一“回溯”步骤能够激活 LLM 中相关的背景知识和推理机制,为其后续处理具体问题奠定基础。
通过关注更广泛、更具原则性的问题,LLM 能够生成更准确、更具洞察力的回答。逐步回溯提示鼓励模型进行批判性思考,并以创新方式运用其已有知识。该方法通过调动 LLM 参数中更多通常难以在直接提示中触发的知识,从而改变最终执行任务时的提示效果。
此外,采用逐步回溯提示还有助于减轻模型响应中的偏见,因为它将关注点从具体细节转向更具普遍性的原则,从而推动更中立的推理。
以下通过示例对比来进一步理解逐步回溯提示如何提升生成结果:首先分析一个传统提示案例(表 8),再与相应的逐步回溯提示(表 9)进行比较:

当你将温度参数设置为1时,模型可能会生成多样且富有创意的故事情节,但其结果往往具有较强的随机性,且内容容易显得泛化、缺乏独特性。让我们先退一步思考:

是的,这些主题看起来非常适合用于第一人称射击游戏。现在,让我们回到最初的提示,但这一次,我们会将逐步回溯所得到的答案作为上下文信息一并输入,观察模型会返回怎样的结果。

这看起来像是一款有趣的视频游戏!通过使用逐步回溯提示技术,你可以提高提示的准确性。
思维链 (CoT:chain of thought)
思维链(Chain-of-Thought, CoT)提示是一种通过引导大型语言模型(LLM)生成中间推理步骤以增强其推理能力的技术。该机制能够有效提升模型在复杂任务中的应答准确性。CoT 提示通常可与少样本提示结合使用,从而在需要多步推理的问题上取得更优性能,因为纯粹的零样本思维链推理仍具有一定挑战性。
CoT 提示具备多方面的优势。首先,该方法成本较低且效果显著,可直接应用于现成的预训练模型,无需额外微调。其次,借助 CoT,用户可以清晰观察模型生成答案的推理过程,从而更好地理解其决策逻辑。若出现错误,也更容易定位问题所在。此外,思维链提示在不同版本或规模的 LLM 之间表现出较强的鲁棒性,即提示效果受模型变动的影响相对较小,相比不引入推理链的方法更为稳定。当然,CoT 方法也存在一些局限,但这些缺点相对直观。
需要注意的是,CoT 推理通常会导致生成长度更长的响应,即消耗更多的输出 token,因此可能会带来更高的推理成本和更长的响应时间。
为具体说明 CoT 的应用,我们将在表 11 中首先构建一个不使用思维链提示的示例,以突显大型语言模型在缺乏中间推理引导时可能存在的不足。

这个答案显然是错的。实际上,大型语言模型(LLM)在处理数学问题时常常会遇到困难,甚至可能在像两数相乘这样简单的运算上出错。这主要是因为它们主要基于海量文本进行训练,而数学推理往往需要不同的思维方式和方法。接下来,我们看看引入中间推理步骤是否能够改善输出效果。
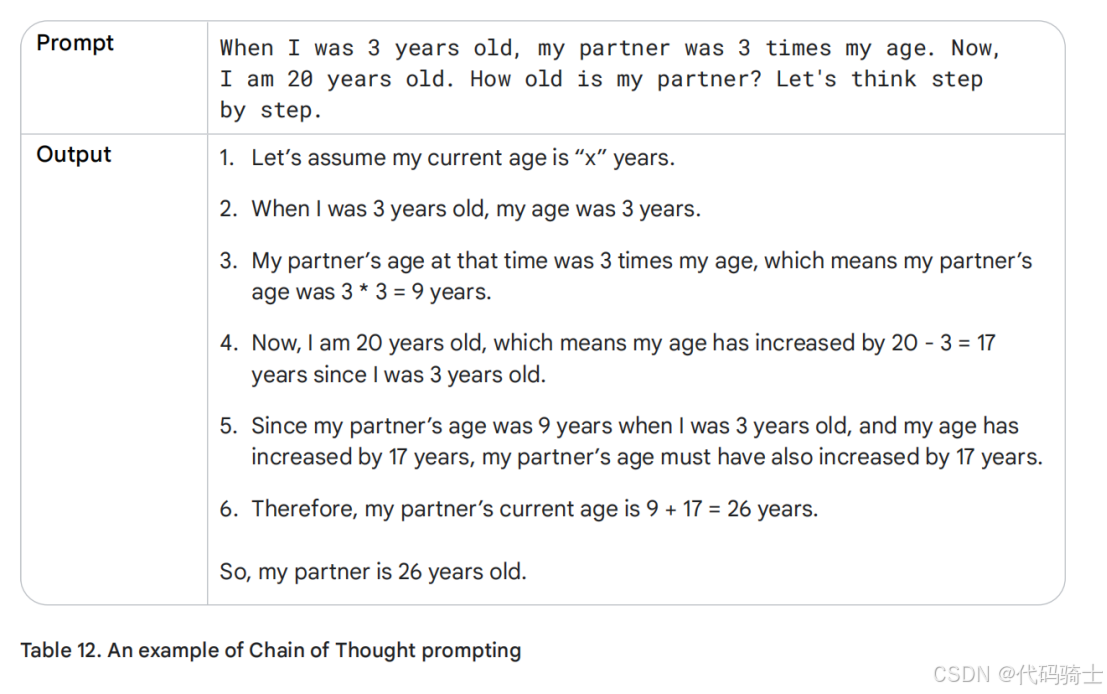
很好,现在最终答案正确了。这得益于我们明确指示大型语言模型(LLM)逐步解释推理过程,而非直接要求给出答案。有趣的是,模型采用了将17年的增量逐步累加的方式。如果是我自己计算,我会先算出我和伴侣之间的年龄差,然后再基于当前年龄进行求和,例如:20 + (9 - 3)。看来,我们还需要帮助模型更深入、更自然地“思考”,就像人类推理时那样。
表12展示了一个“零样本”思维链(Zero-shot Chain-of-Thought)的示例。而思维链提示在与单样本或少样本提示结合时,表现尤为强大,具体效果您可以在表13中看到。

思维链技术可广泛应用于多种场景。例如,在代码生成任务中,可以将需求拆解为多个步骤,并将每个步骤映射为具体的代码实现。又如,在合成数据生成场景中,若已拥有如“产品名称为XYZ”之类的种子数据,可通过引导模型基于给定标题生成假设性内容。一般而言,任何能够通过“分步说明”解决的任务,都适合采用思维链方法。如果你能够将问题的解决过程分解为清晰的步骤,不妨尝试运用思维链策略。
具体实践可参考托管于Google Cloud Platform GitHub存储库中的“Notebook”,其中对思维链提示技术进行了更详细的阐述:
在本章的最佳实践部分,我们将进一步探讨一些专门针对思维链提示的优化方法。
未完待续……