一篇关于MCP协议的介绍以及使用【详细篇】
1,MCP的通信机制:
根据MCP的规范,当前支持两种通信机制(传输方式):
1.1,stdio(标准输入输出):
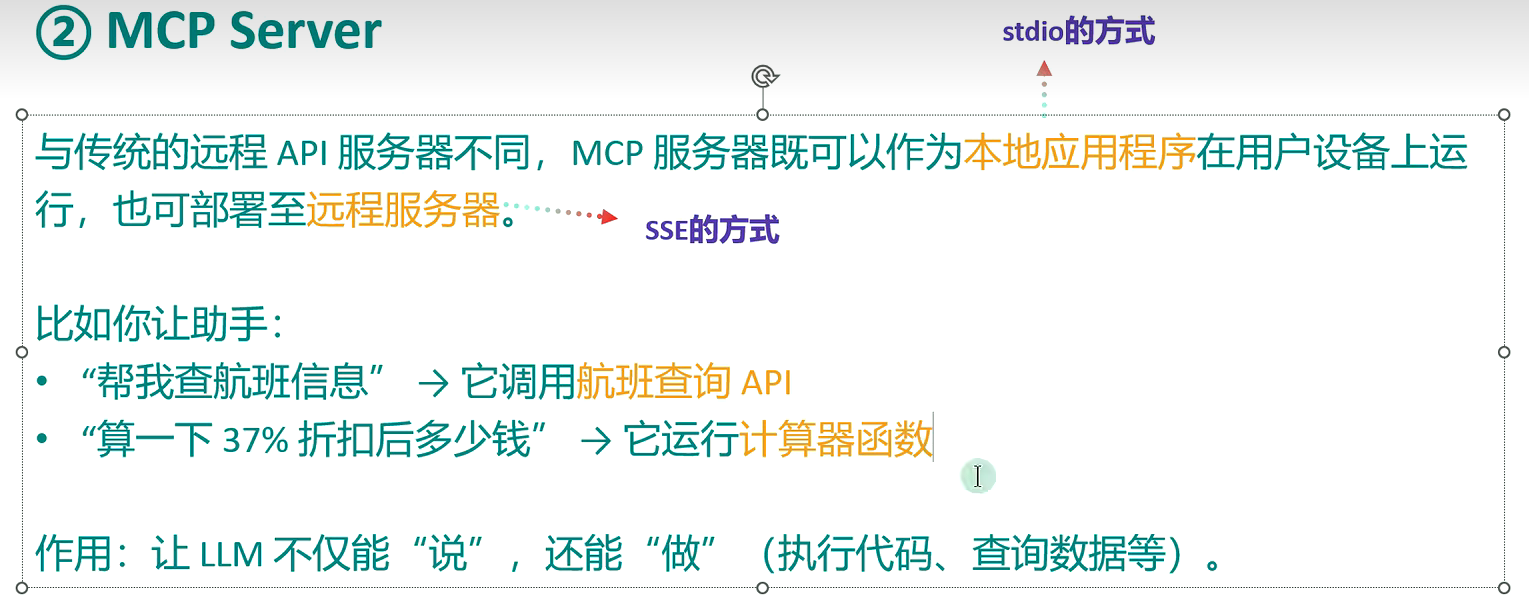
stdio(标准输入输出):主要用在本地服务上,操作你本地的软件或者本地的文件。比如 Blender 这种就只能用 Stdio 因为他没有在线服务。 MCP默认通信方式
【总的来说,就是客户端和服务端都在本地】

1.2,SSE(Server-Sent Events):
SSE(Server-Sent Events):主要用在远程通信服务上,这个服务本身就有在线的 API,比如访问你的谷歌邮件,天气情况等。
【总的来说,就是客户端和服务端,一个是本地,一个是外部】

2.前期准备工作
2.1 先配置本地的stdio环境
有两种编写,一般不同的mcp会支持不同的语言,这里我们都安装

2.2 python环境
确保有python环境后,运行以下指令
pip install uvuv --version2.3 TypeScript环境
下载node.js环境即可,验证环境是否可用:
node -vnpm -v2.4 cursor配置MCP server
cursor的下载网址:
https://cursor.com/cn
打开cursor:
点击设置,点击MCP
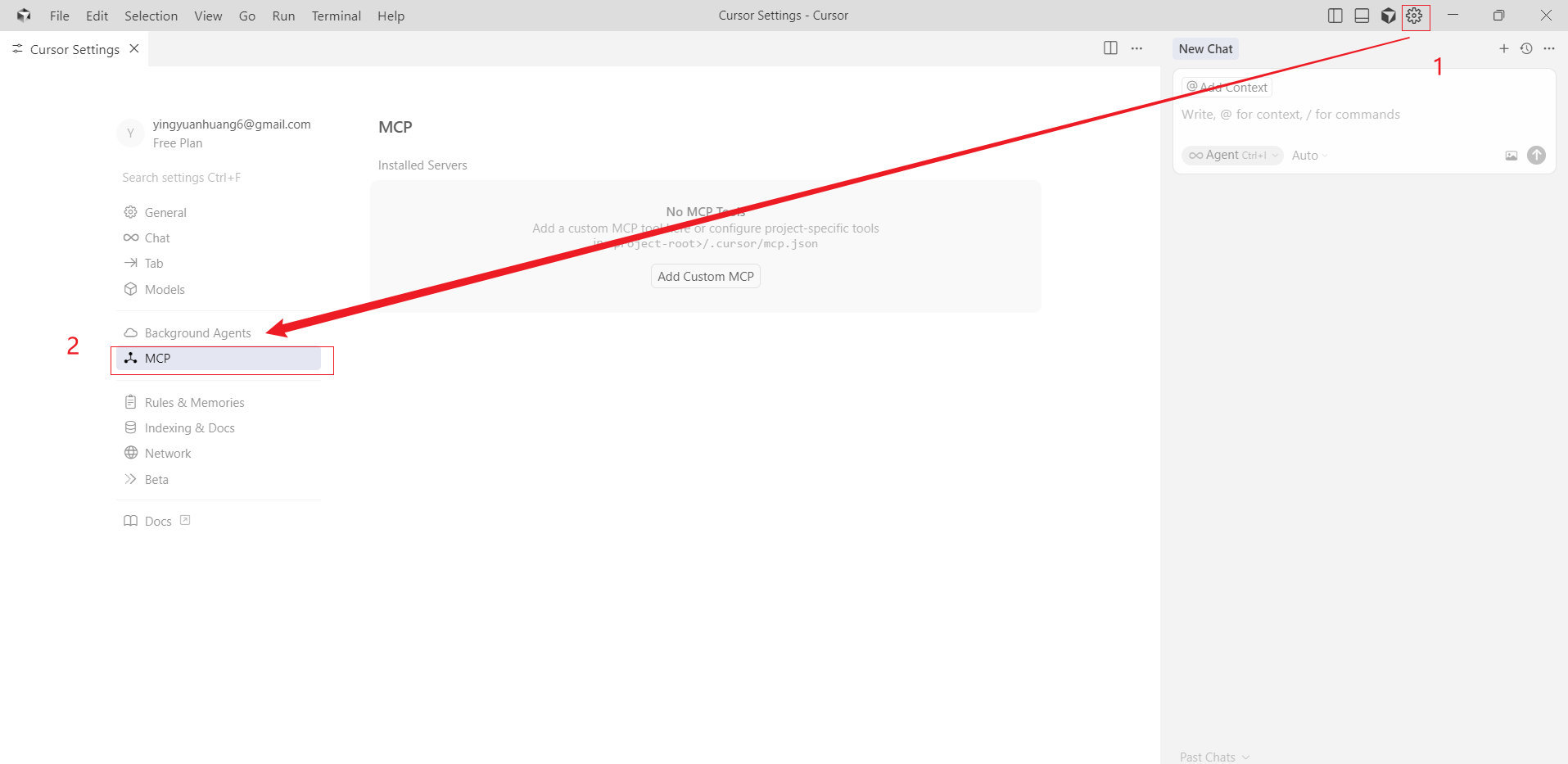
点击MCP页面的Add就会自动生成 mcp.json
2.4.1 MCP平台:
https://smithery.ai/
https://mcp.so/
2.4.2 MySQL_MCP 服务:
在MCP平台上去找到相关的MCP工具,然后进行配置导入即可:
搜索:
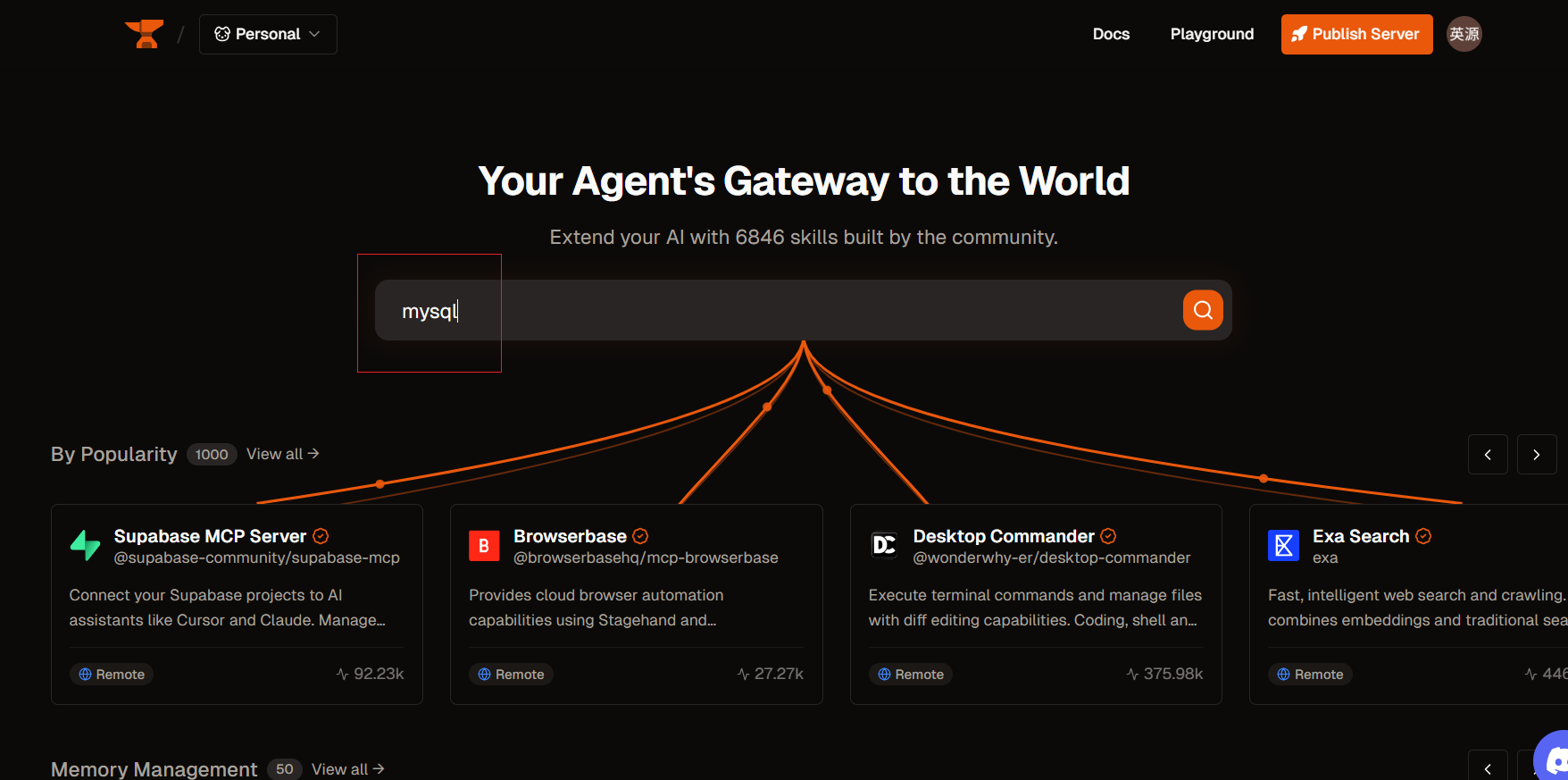
找到一个start最多的,然后点击:
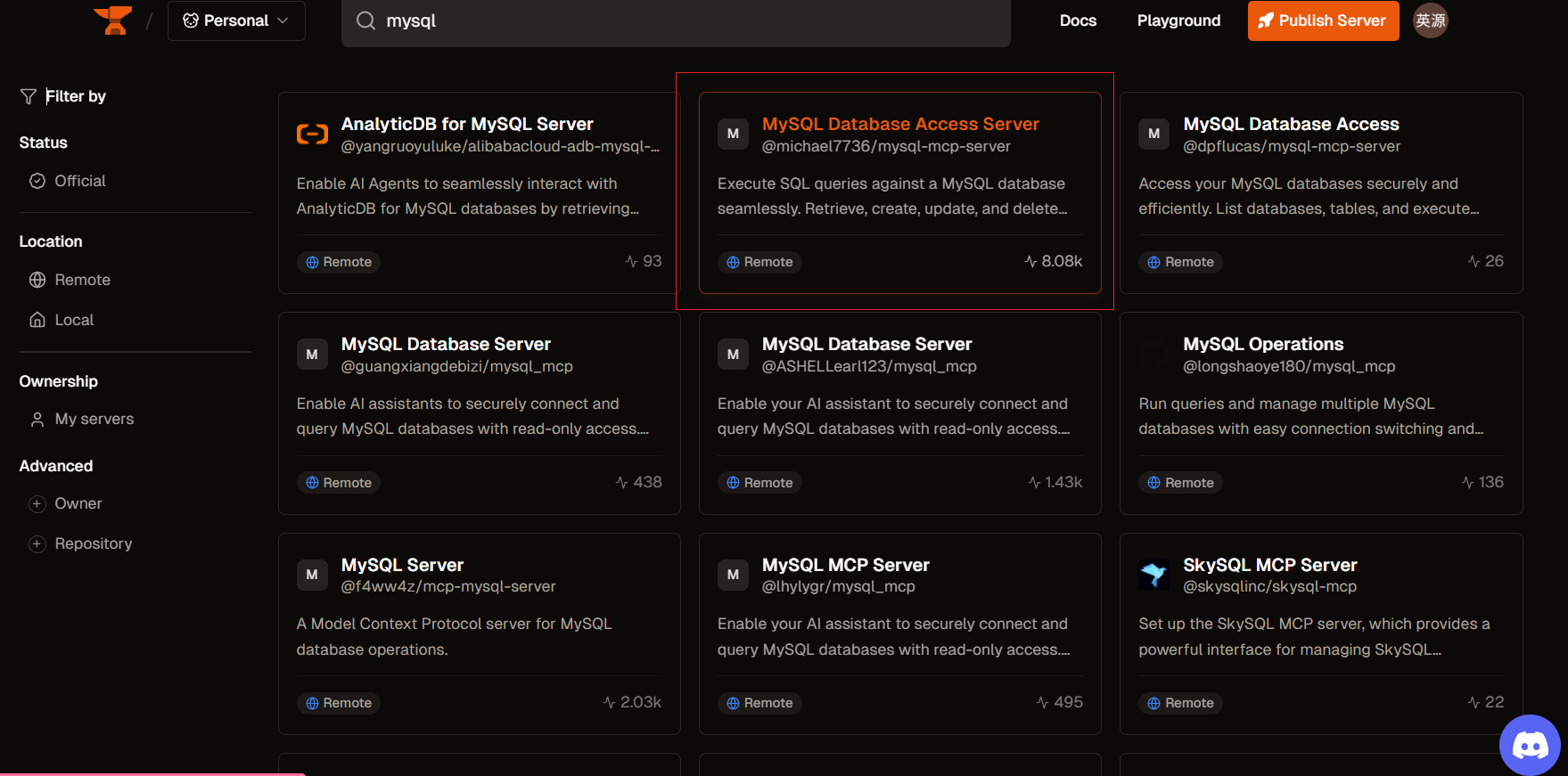
我这边用的是curser导入MCP,选择curser:
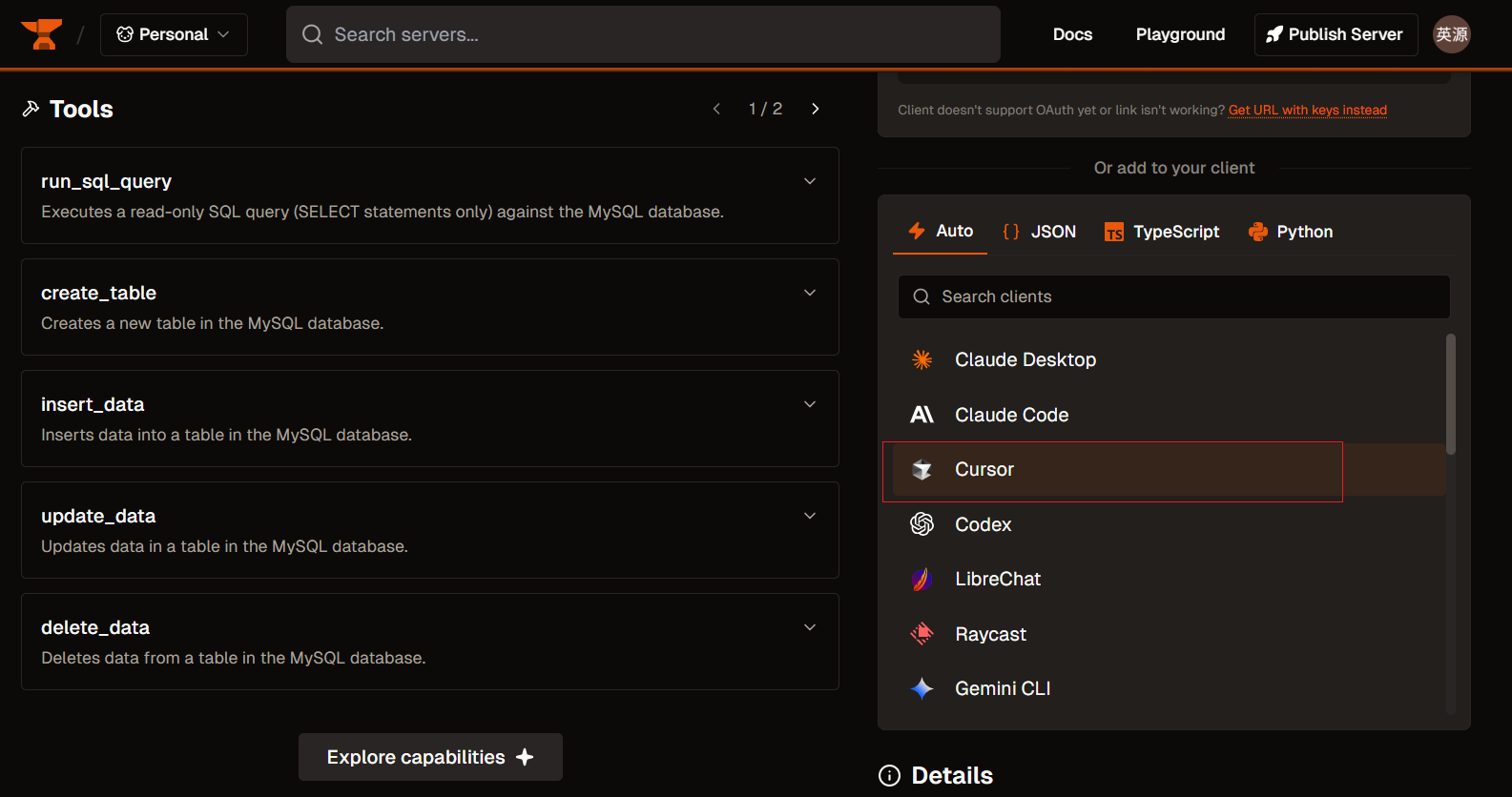
配置好相关的信息:
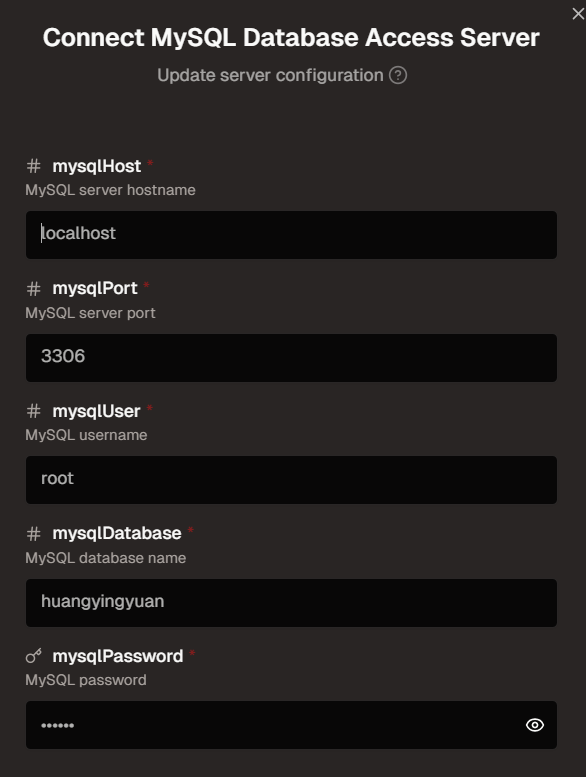
点击这个即可自动导入curser的mcp.json文件中:
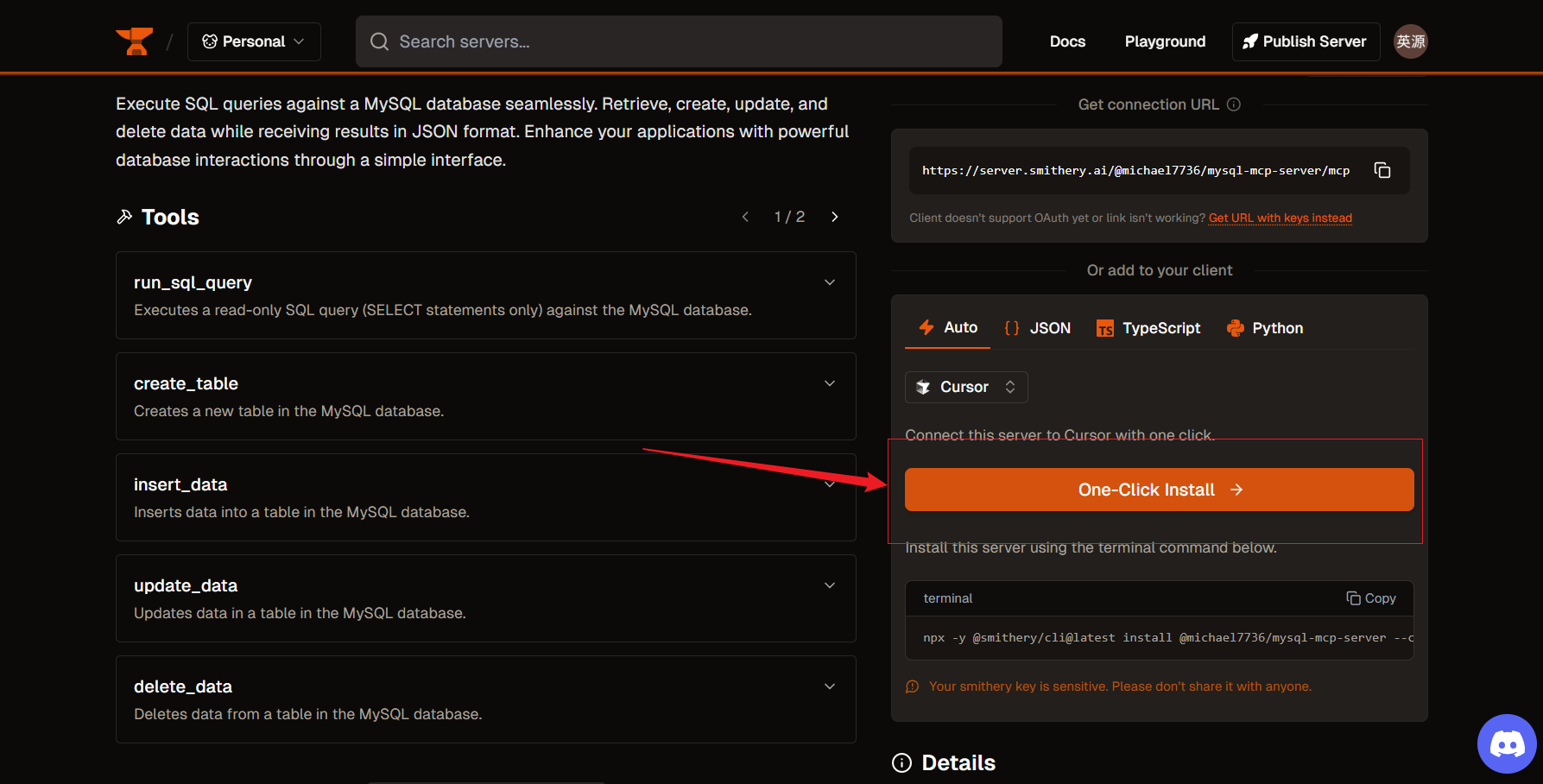
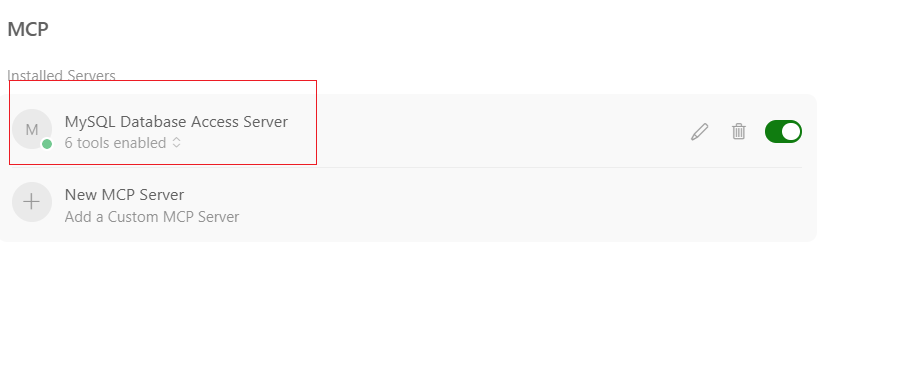
回到curser中去检查:
若点是红色的,则是配置失败,得检查一下mcp.json配置文件;
若点是绿色的,则配置成功。
2.4.3 高德地图_MCP服务:
https://mcp.so/ 在这个平台去找
然后点击复制这段信息:
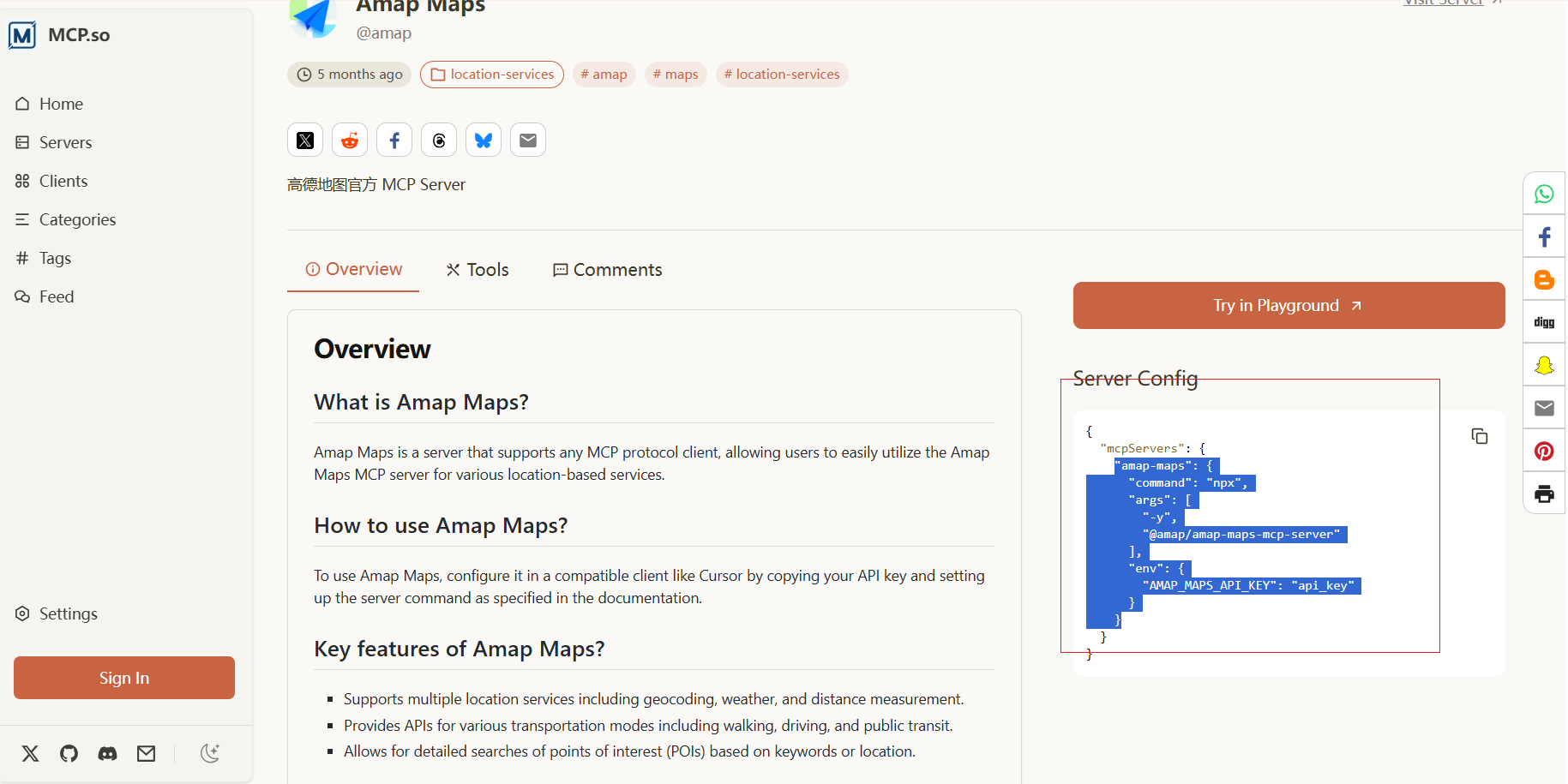
回到mcp.json中去配置信息:
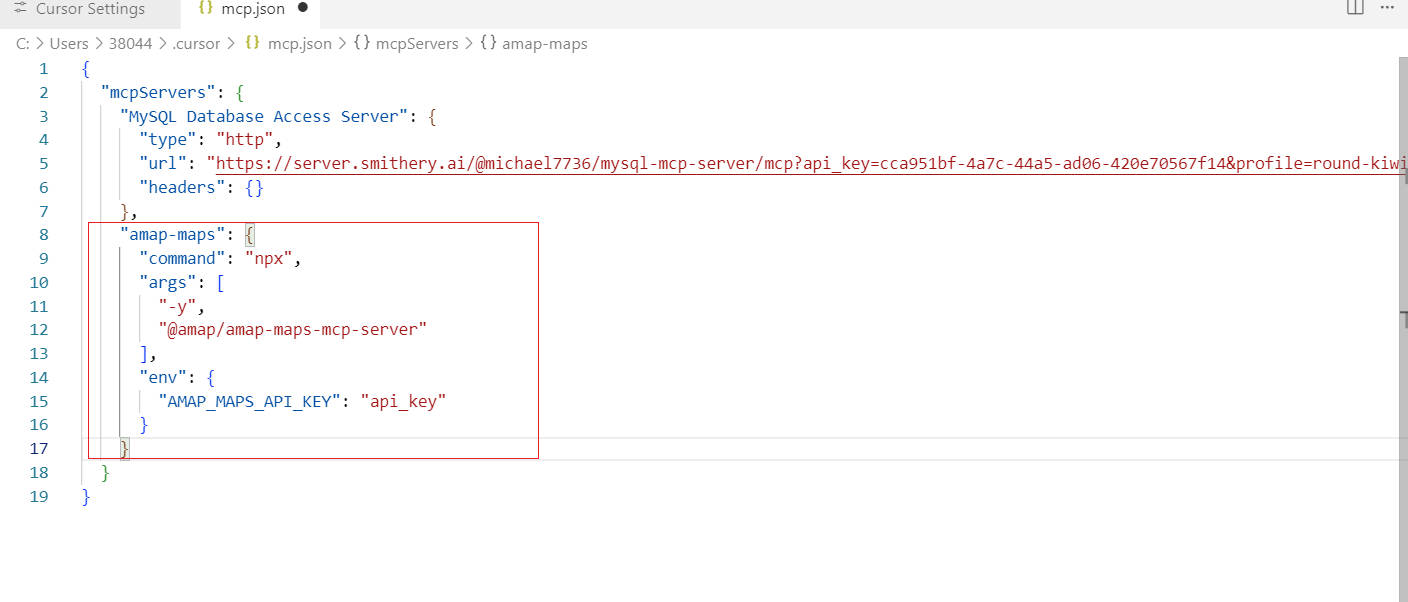
至于api_key的话,就是高德申请:https://console.amap.com/
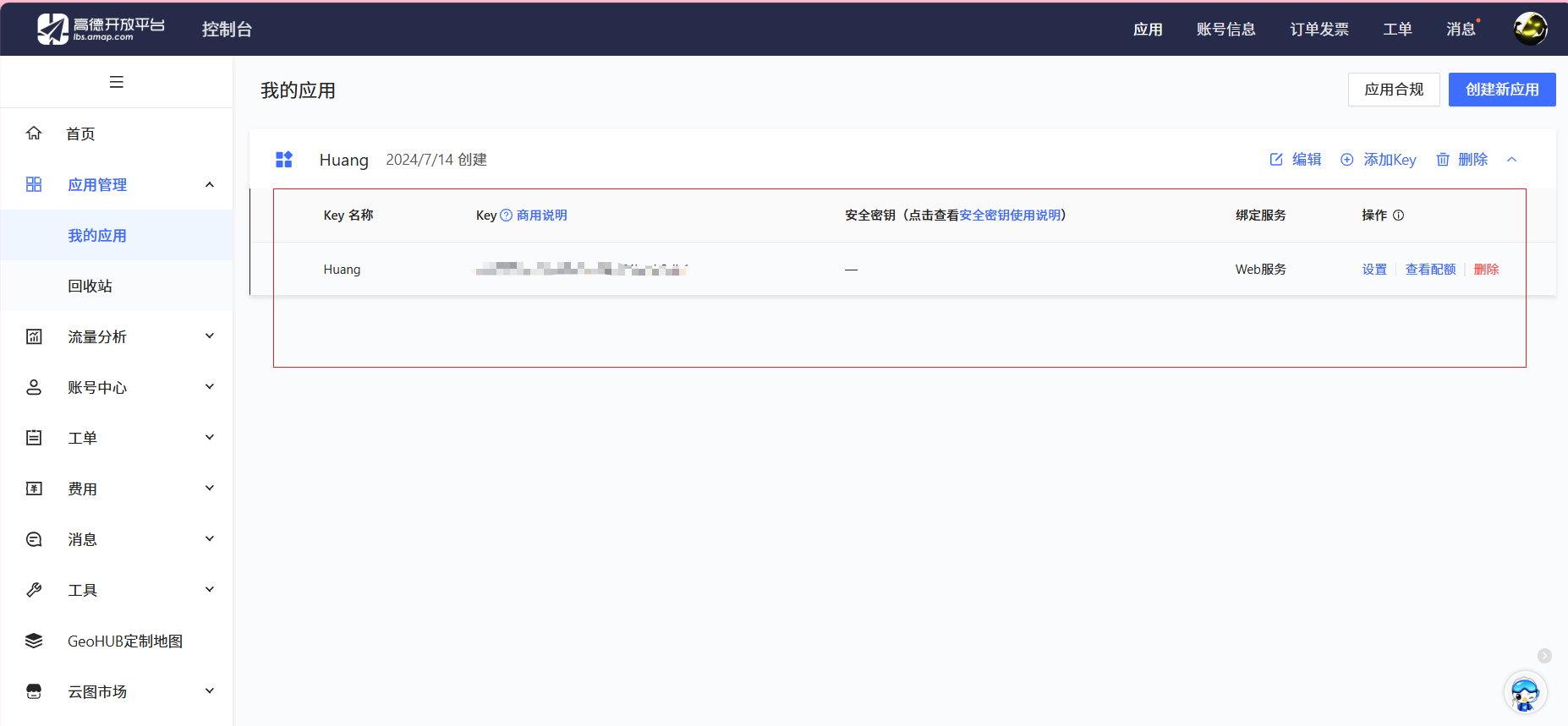
把申请完的key替换app_key即可
2.4.4 在cursor使用MCP服务:
在侧边栏打开聊天框,然后输入一下信息,测试:
现在交给你一个任务,编写一个北京一日游的出行攻略
1、从高德地图的MCP服务中获取北京站到天安门、天安门到颐和园、颐和园到南锣鼓巷的地铁线路,并在test数据库中去创建相应的表subway_trips,并将数据存取进去
2、从高德地图的MCP中获取颐和园、南锣鼓巷附件的美食信息,每处获取三家美食店铺信息,并将相应的信息存入表location foods中
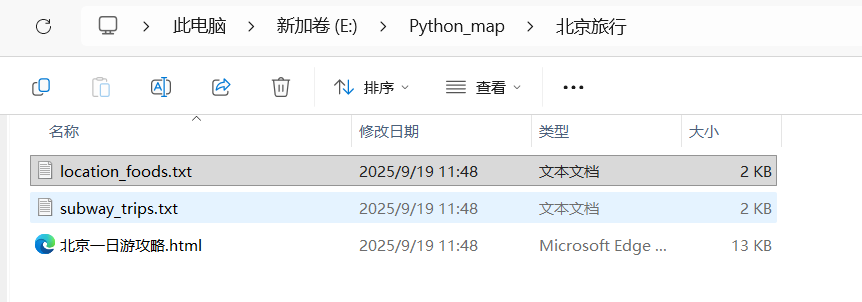
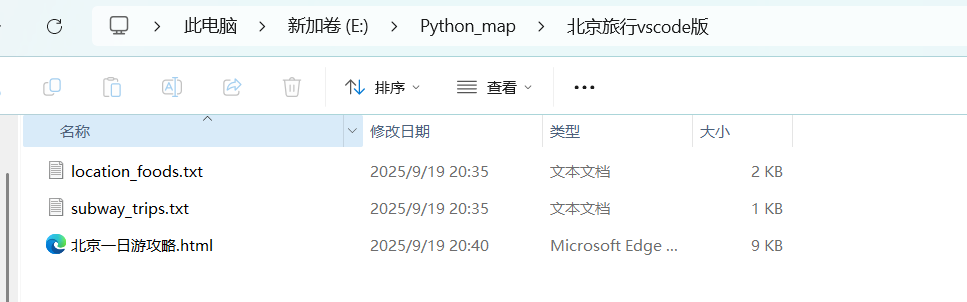
3、在工作目录E:\Python_map下创建一个新的文件夹,命名为“北京旅行"在其中创建两个txt,分别从数据库中将两个表的内容提取出存放进去。
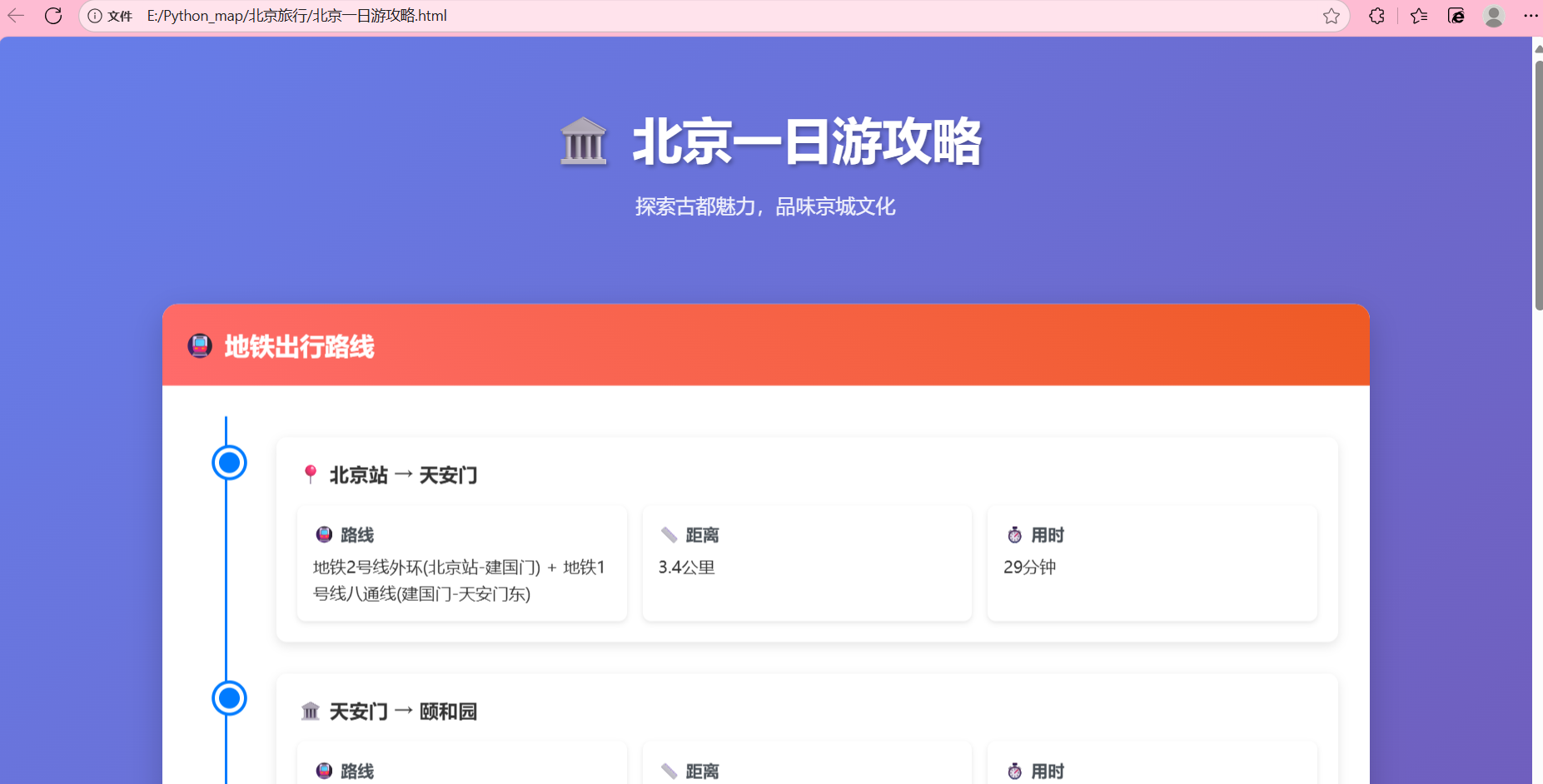
4、最后根据txt中的内容,生成一个精美的html前端展示页面,并存放在该目录下操作如图所示:
运行后,经过一番推理结果得到:
文件自动保存到相应位置:
数据存到相应的数据库表中:
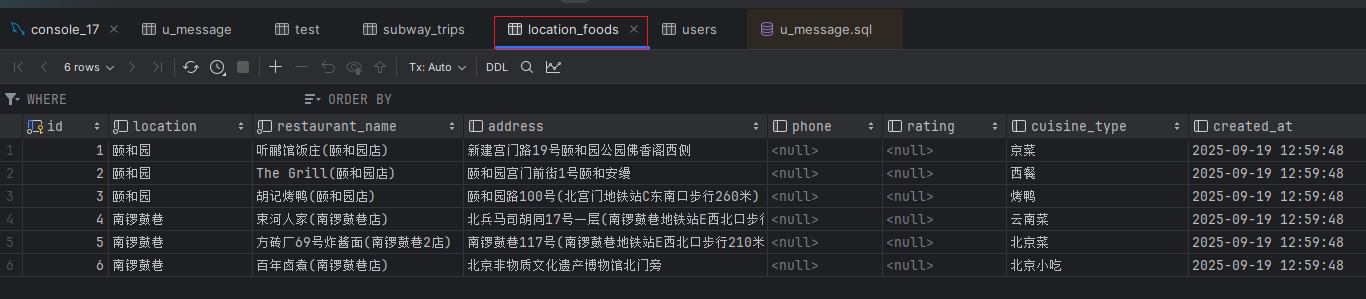

得到相应的可视化界面:
2.4.5 在CScode中如何使用插件Cline:
安装插cline件:
设置信息:
介绍相应的按键:
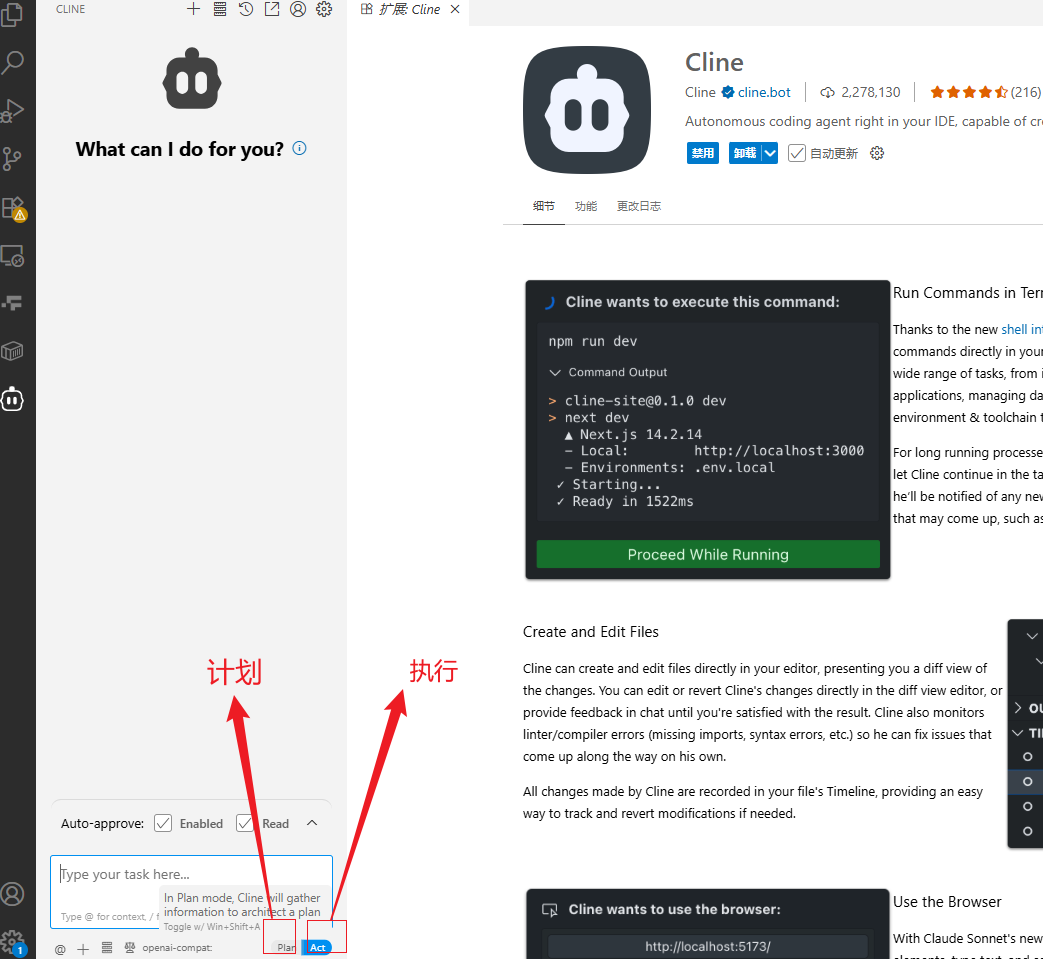
填写自己模型信息:
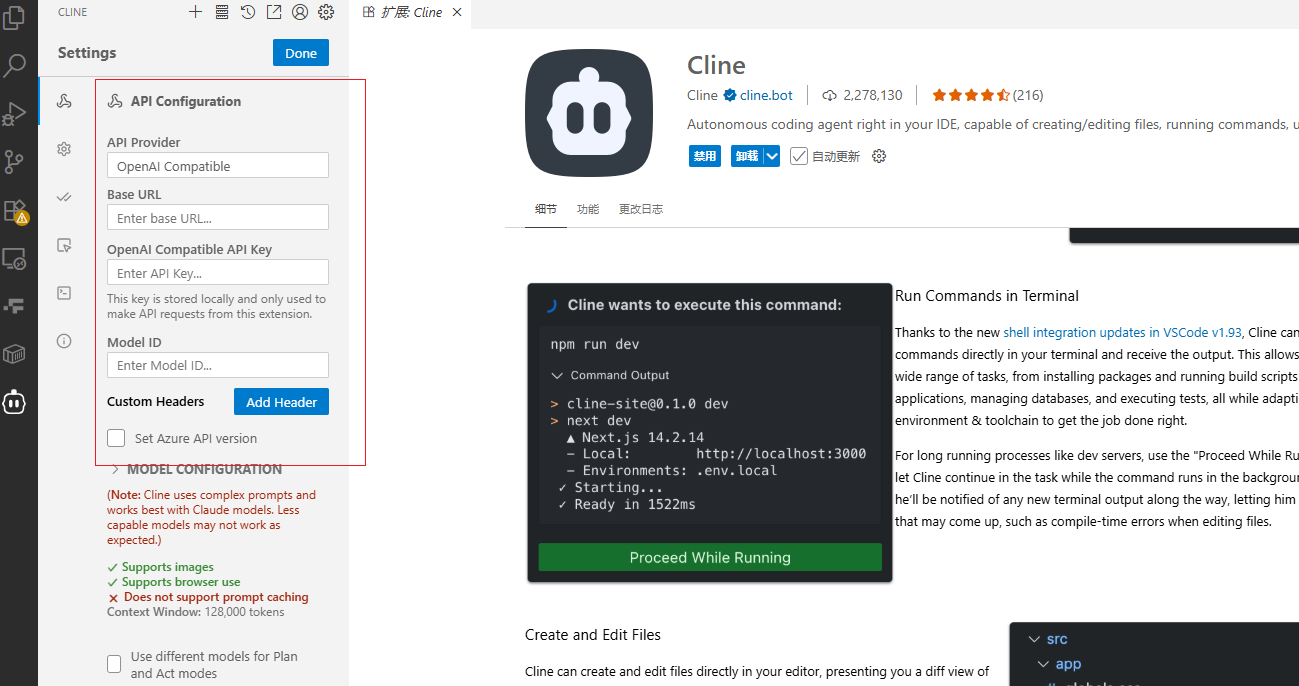
配置好基本模型的限制:
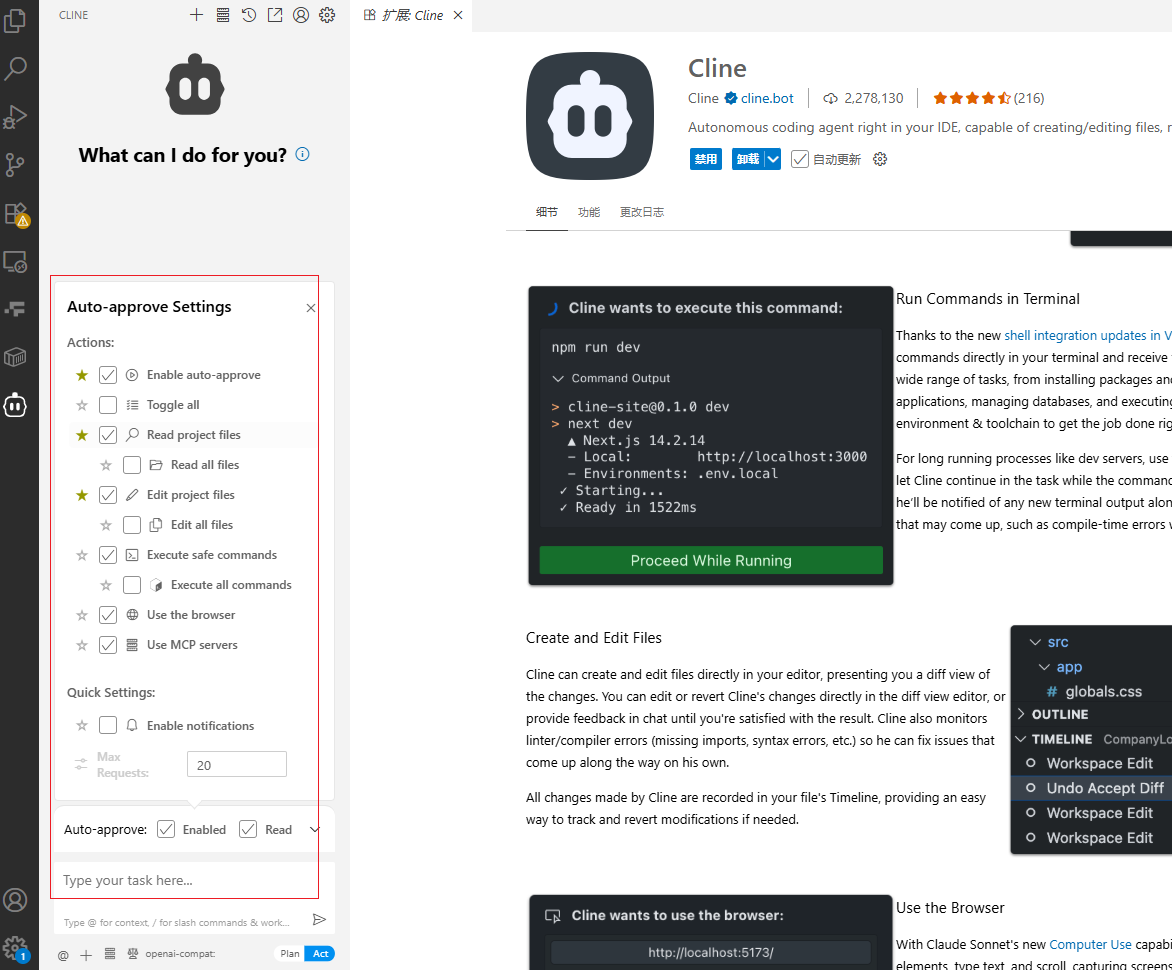
然后点击配置MCP:
然后就是一些基础的选项配置:
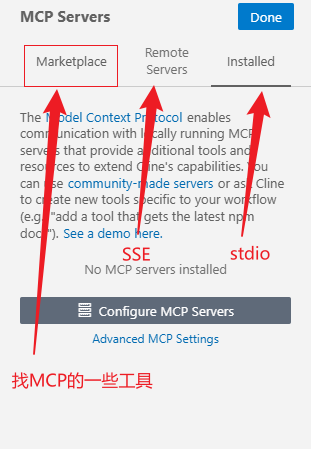
咱们选择stdio,然后根据之前的一些MCP平台选择想要的配置填写,出现绿点即可:
管理电脑文件MCP:
https://smithery.ai/server/@wonderwhy-er/desktop-commander
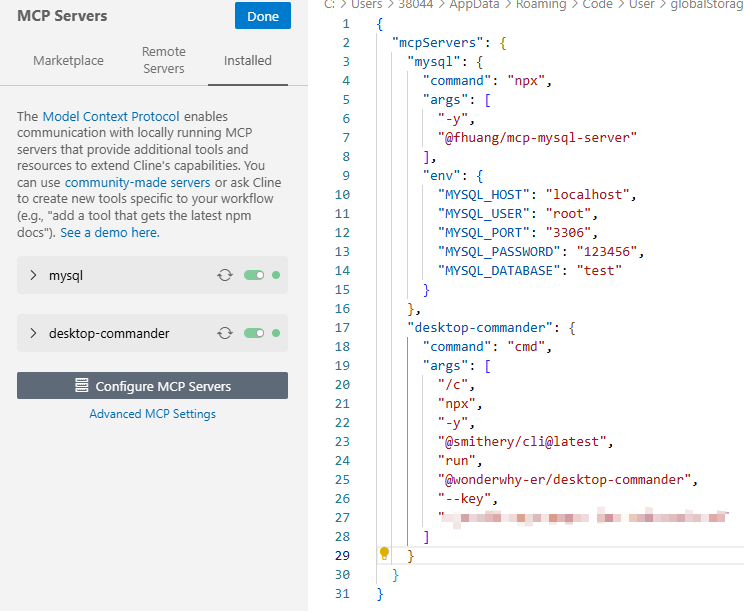
获取相应的模型接口然后,配置模型信息:
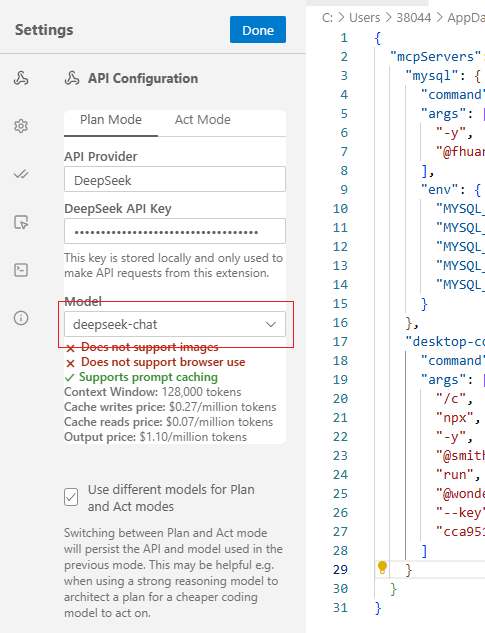
plan选择chat模型:
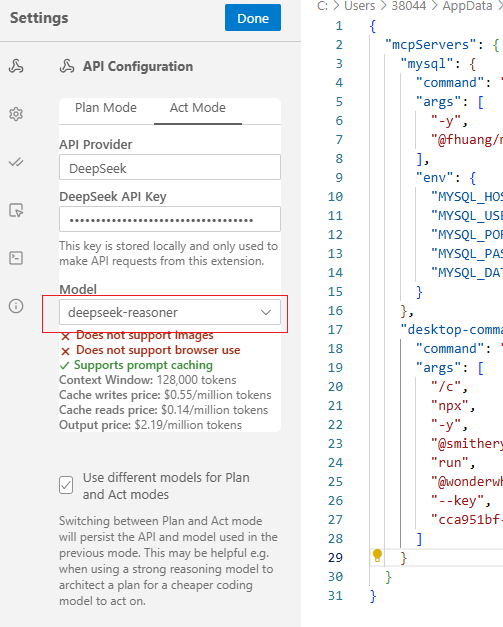
act选择reasoner推理模型:
输入需求,调用MCP完成相应的任务:
现在交给你一个任务,编写一个北京一日游的出行攻略
1、在工作目录E:\Python_map下创建一个新的文件夹,命名为"北京旅行vscode版"。分别从数据库test中获取表location_foods当地美食表、subway_trips地铁线路表的结构、数据信息。然后提取出其中的数据,放入两个txt中进行保存。
2、根据txt中的内容,生成一个精美的htm1前端展示北京地铁交通及周边美食的页面,并存放在该目录下点击plan启动后:
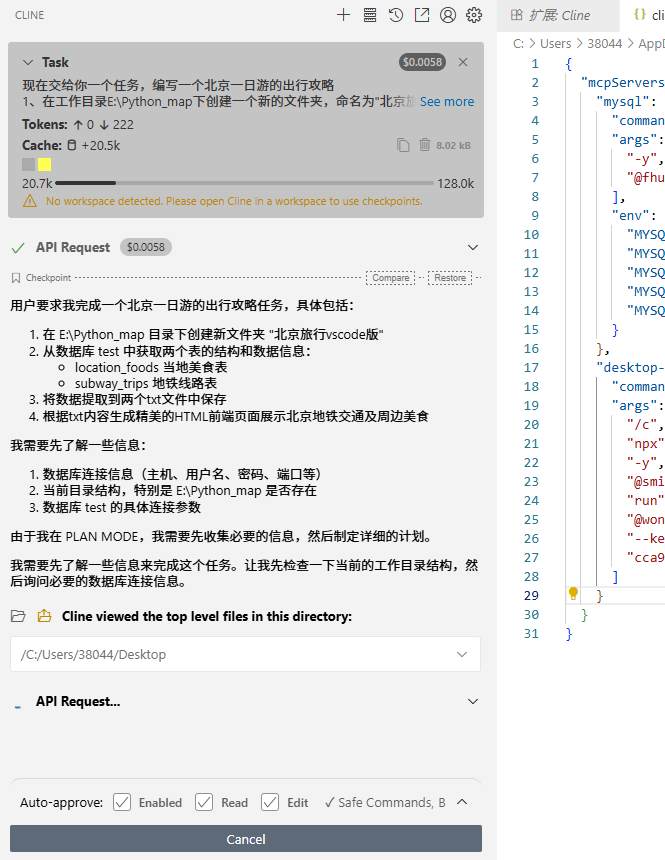
然后chat分析完后,我们可以选择act,执行分析流程:
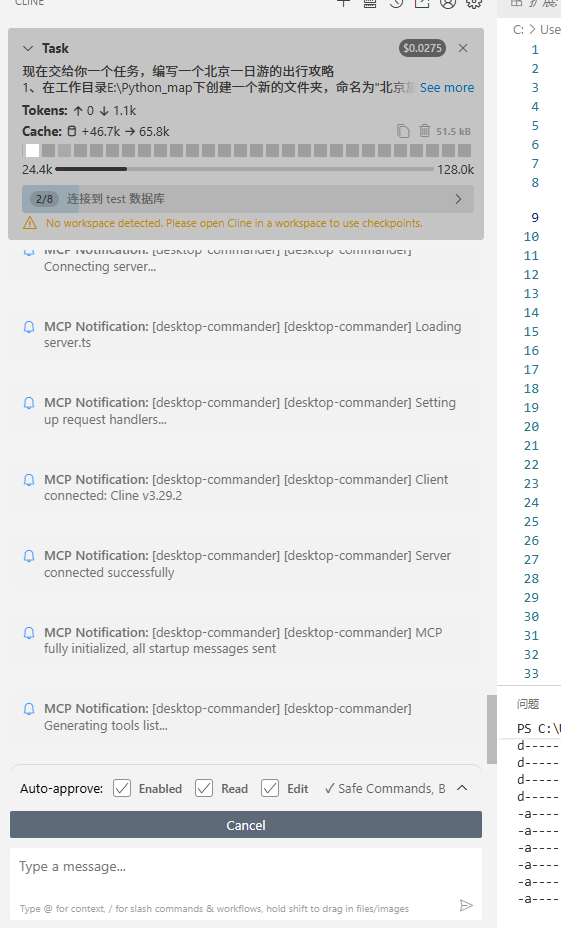
执行的结果如下:

3.MCP的C/S架构

官方给的结构:
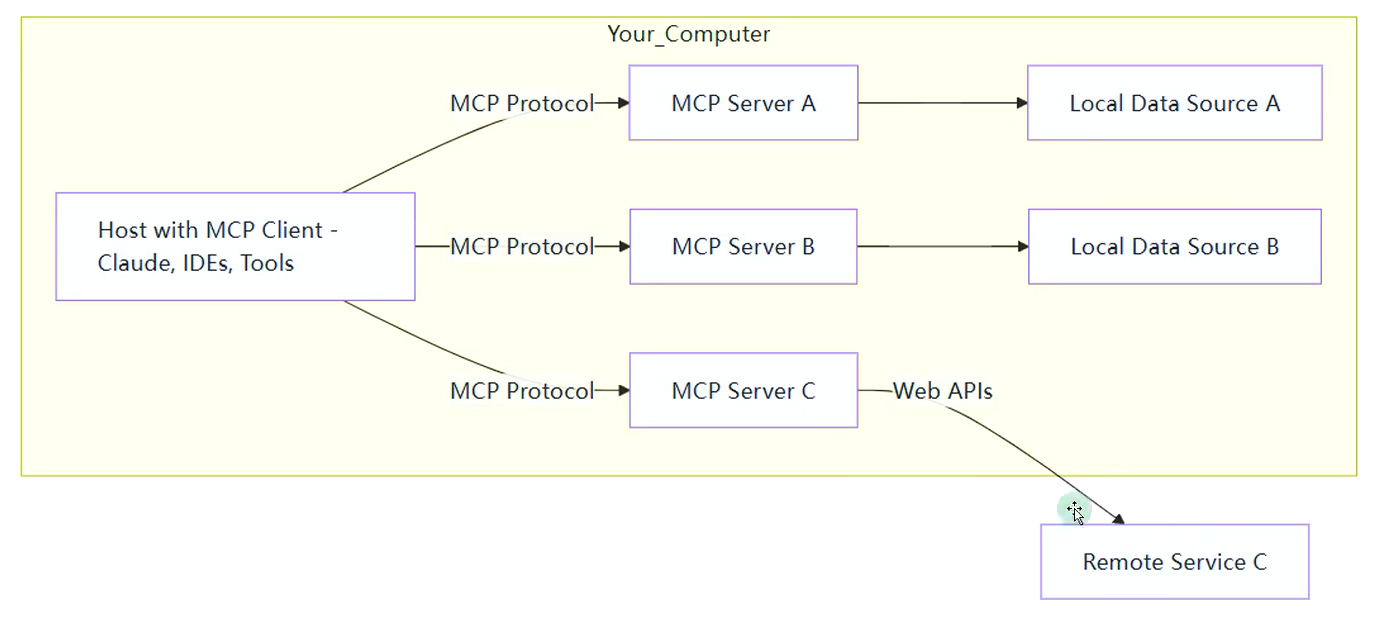
3.1 MCP Host
作为运行MCP的主应用程序,例如Claude Desktop、Cursor、Cline或AI工具。为用户提供与LLM交互的接口,同时集成MCP Client以连接MCP Server。
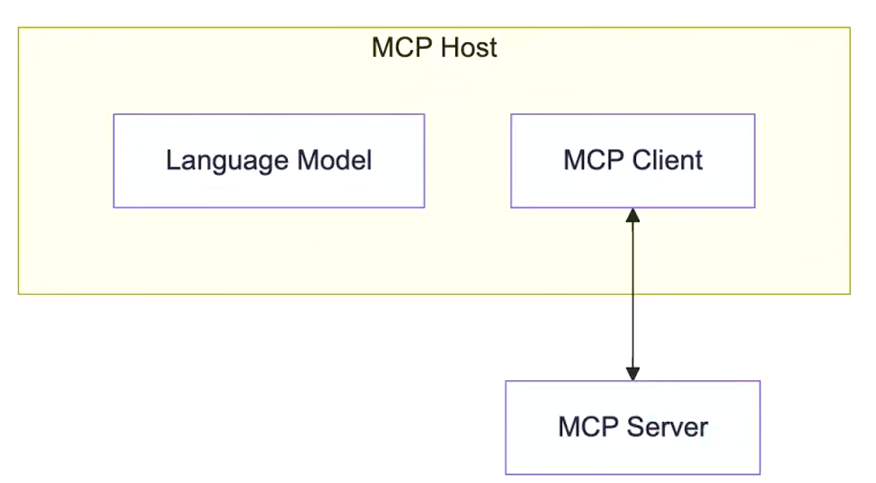
3.2 MCP Client
MCP client 充当 LLM 和 MCP server 之间的桥梁,嵌入在主机程序中,主要负责:
- 接收来自LLM的请求;
- 将请求转发到相应的 MCP server;
- 将 MCP server 的结果返回给 LLM。

有哪些常用的Clients
MCP 官网(https://modelcontextprotocol.io/clients)列出来一些支持 MCP 的 client。
分为两类:
- AI编程IDE:Cursor、Cline、Continue、Sourcegraph、Windsurf等
- 聊天客户端:Cherry Studio、Claude、Librechat、Chatwise等
更多的client参考这里
MCP Clients: https://www.pulsemcp.com/clientsAwesome
Awesome MCP Clients: https://github.com/punkpeye/awesome-mcp-clients/
3.3 MCP Server
每个 MCP 服务器都提供了一组特定的工具,负责从本地数据或远程服务中检索信息是 MCP 架构中的关键组件。
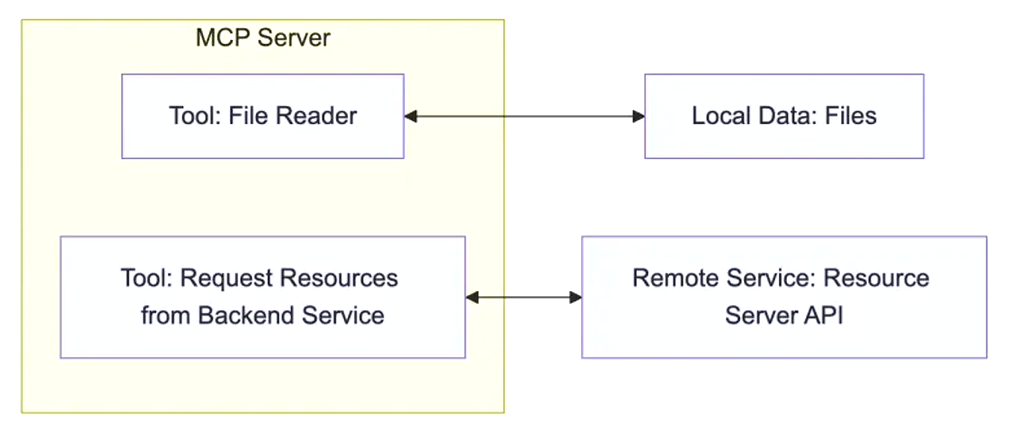
MCP Server 的本质
本质是运行在电脑上的一个nodejs或python程序。可以理解为客户端用命令行调用了电脑上的nodejs或python程序,
- 使用 TypeScript 编写的 MCP server 可以通过 npx 命令来运行
- 使用 Python 编写的 MCP server 可以通过 uvx 命令来运行。
3.4 总结
以下图是核心整体的核心流程:
先是MCP Host里包括MCP Client去跟MCP Server建立连接,MCP Server包括本地工具(stdio连接)或者远程工具(SSE连接)

4.MCP的工作流程
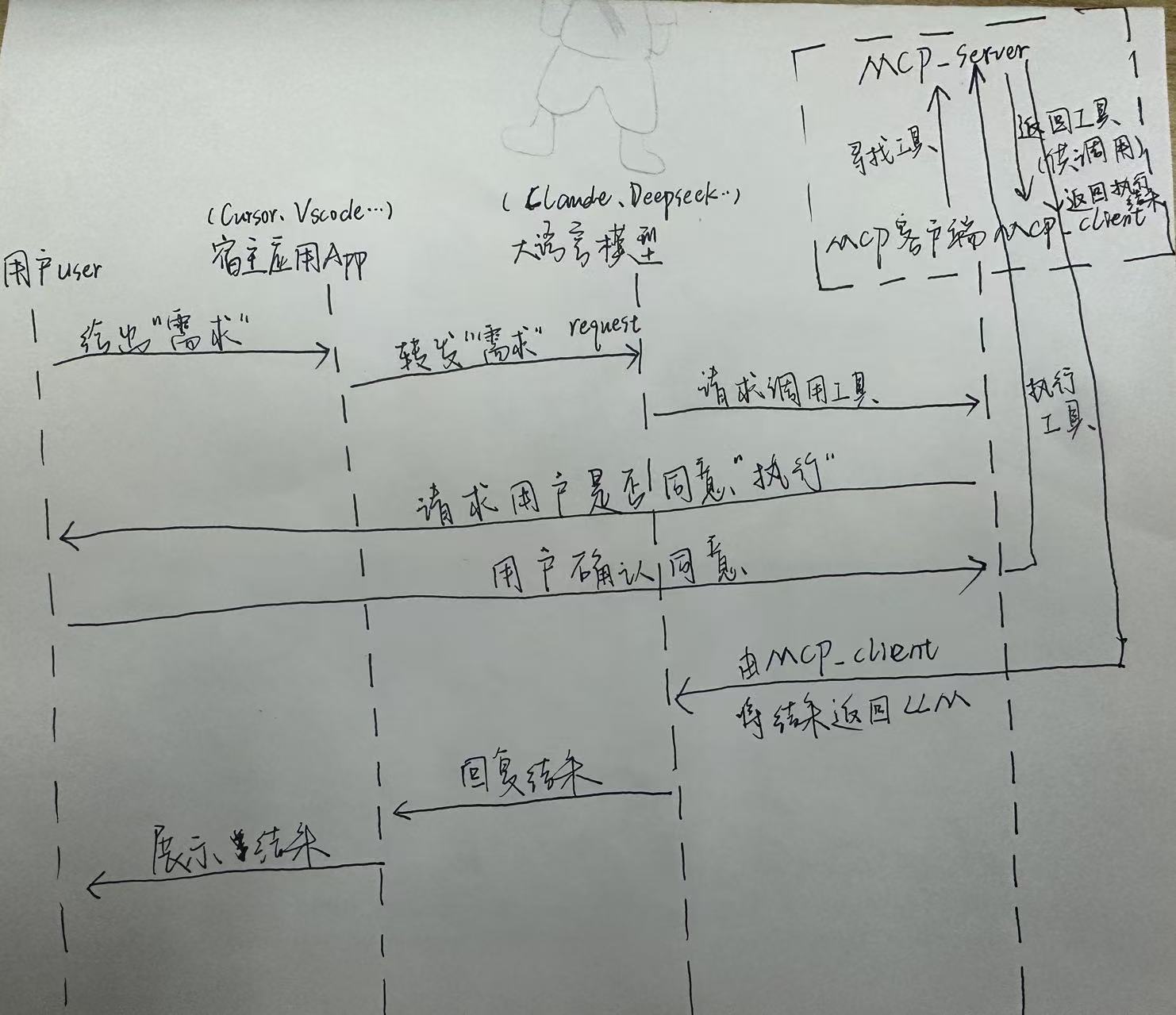
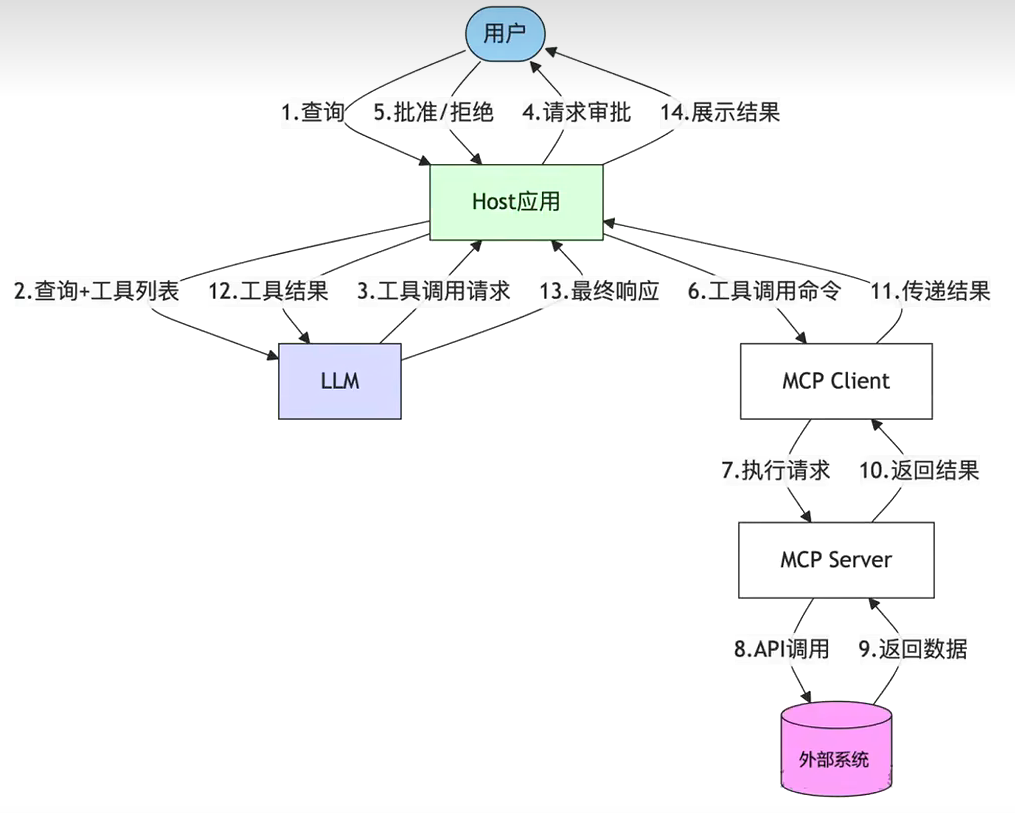
客户端User先启动,然后将MCP Client和MCP Server建立起联系(连接服务器【本地/远程】,然后确认连接后,去询问server有什么工具可以用,server接收到请求后,返回可用的工具给Client);
然后对用户需求给到LLM大模型进行分析,大模型分析后给出需要调用什么工具进行实操,将需求返回到MCP Client中,Client再对Server里面的工具进行工具调用,server执行完工具后,返回执行结果给client,最后client再将结果返回给LLM进行分析,进行文字总结返回给客户。
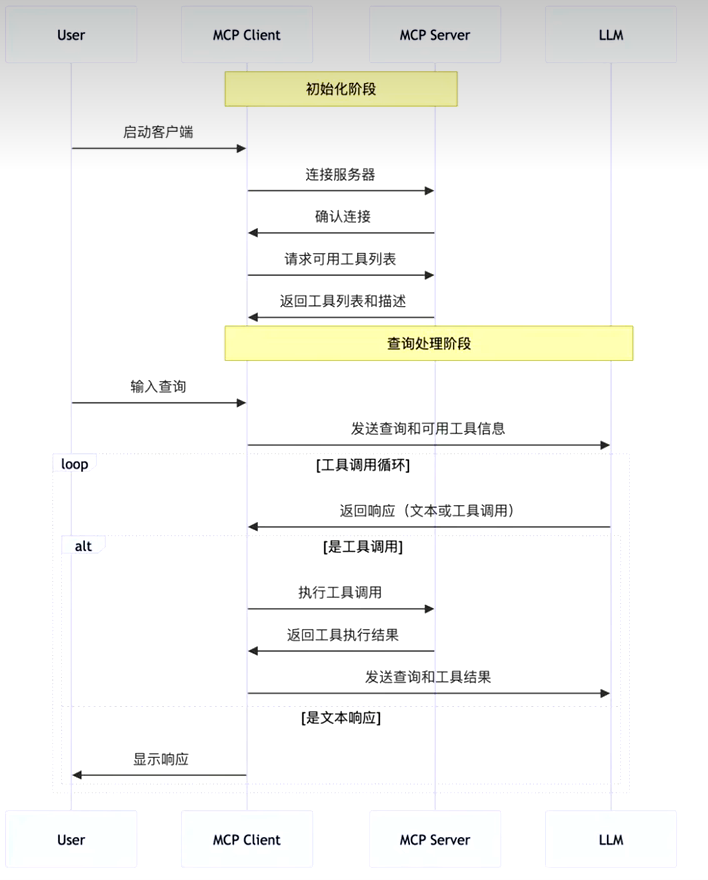
API 主要有两个:
- tools/list:列出 Server 支持的所有工具
- tools/call:client 请求 Server 去执行某个工具并将结果返回
4.1 例子
4.2数据流向
5.【重点】手动开发MCP项目(C/S)
需求去给到Client,然后给到Server,进行工具调用后再返回结果
5.1 案例需求
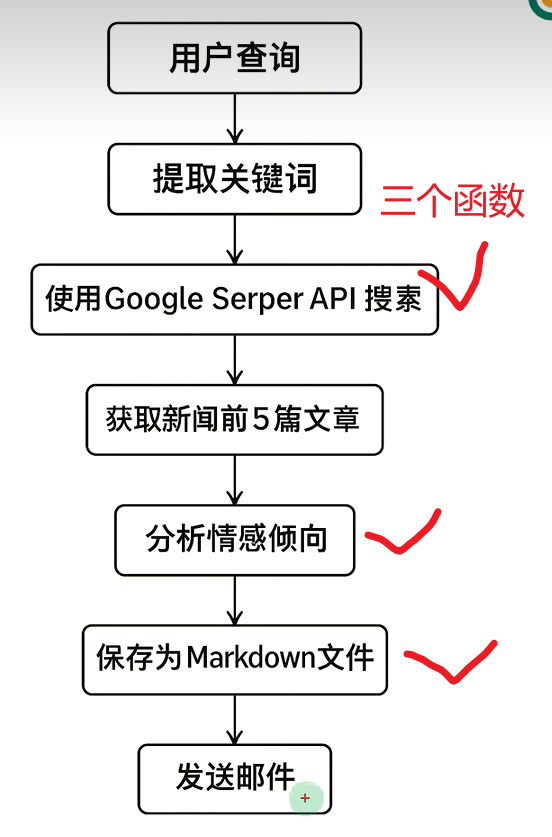
本项目旨在构建一个本地智能舆情分析系统,通过自然语言处理与多工具协作实现用户查询意图的自动理解、新闻检索、情绪分析、结构化输出与邮件推送。
5.2 需求总体流程
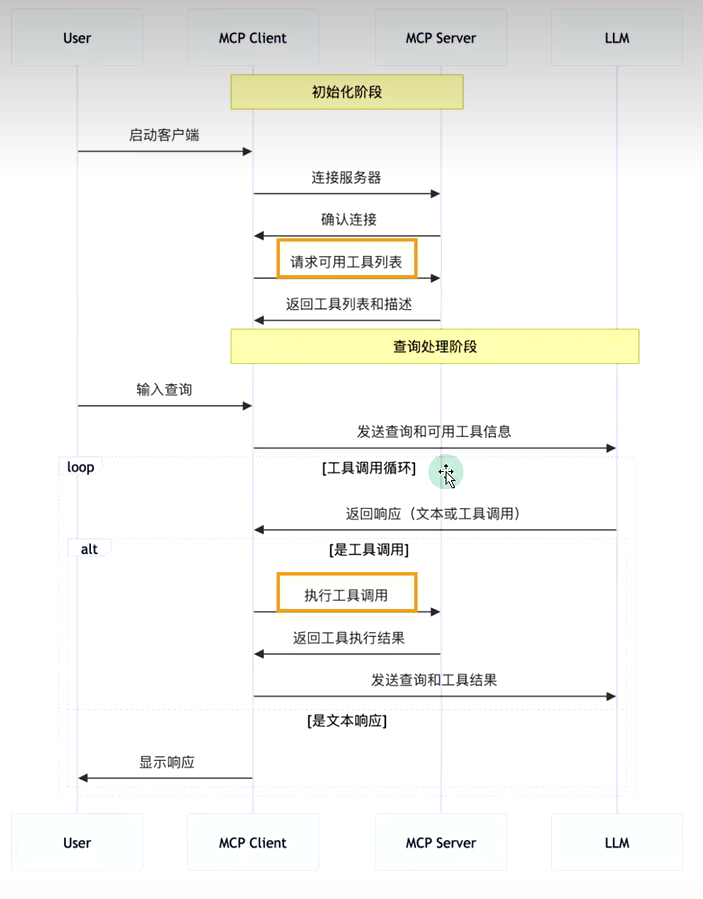
5.3 需求工作流程
API主要有两个
- tools/list:列出 Server支持的所有工具
- tools/call: client 请求 Server 去执行某个工具并将结果返回
5.4 开发ing
5.4.1 创建MCP项目
uv init mcp-project
然后相应的文件出现以下内容:
在该文件夹下创建必要的py;
5.4.2 .env配置文件的内容:
BASE_URL="https://dashscope.aliyuncs.com/compatible-mode/v1"
MODEL=qwen2.5-vl-32b-instruct
DASHSCOPE_API_KEY="你的模型密钥"SERPER_API_KEY="你的谷歌新闻密钥"
SMTP_SERVER=smtp.163 .com
SMTP_PORT=465
EMAIL_USER=你的发送邮箱的账号
EMAIL_PASS=你的账号密码5.4.3 client.py的编写
import asyncio
import os
import json
from typing import Optional, List
from contextlib import AsyncExitStack
from datetime import datetime
import re
from openai import OpenAI
from dotenv import load_dotenv
from mcp import ClientSession, StdioServerParameters
from mcp.client.stdio import stdio_client
load_dotenv()class MCPClient:def __init__(self):self.exit_stack = AsyncExitStack()self.openai_api_key = os.getenv("DASHSCOPE_API_KEY")self.base_url = os.getenv("BASE_URL")self.model = os.getenv("MODEL")if not self.openai_api_key:raise ValueError("❌ 未找到 OpenAI API Key,请在 .env 文件中设置 DASHSCOPE_API_KEY")self.client = OpenAI(api_key=self.openai_api_key, base_url=self.base_url)self.session: Optional[ClientSession] = Noneasync def connect_to_server(self, server_script_path: str):# 对服务器脚本进行判断,只允许是 .py 或 .jsis_python = server_script_path.endswith('.py')is_js = server_script_path.endswith('.js')if not (is_python or is_js):raise ValueError("服务器脚本必须是 .py 或 .js 文件")# 确定启动命令,.py 用 python,.js 用 nodecommand = "python" if is_python else "node"# 构造 MCP 所需的服务器参数,包含启动命令、脚本路径参数、环境变量(为 None 表示默认)server_params = StdioServerParameters(command=command, args=[server_script_path], env=None)# 启动 MCP 工具服务进程(并建立 stdio 通信)stdio_transport = await self.exit_stack.enter_async_context(stdio_client(server_params))# 拆包通信通道,读取服务端返回的数据,并向服务端发送请求self.stdio, self.write = stdio_transport# 创建 MCP 客户端会话对象self.session = await self.exit_stack.enter_async_context(ClientSession(self.stdio, self.write))# 初始化会话await self.session.initialize()# 获取工具列表并打印response = await self.session.list_tools()tools = response.toolsprint("\n已连接到服务器,支持以下工具:", [tool.name for tool in tools])async def process_query(self, query: str) -> str:# 准备初始消息和获取工具列表messages = [{"role": "user", "content": query}]response = await self.session.list_tools()available_tools = [{"type": "function","function": {"name": tool.name,"description": tool.description,"input_schema": tool.inputSchema}} for tool in response.tools]# 提取问题的关键词,对文件名进行生成。# 在接收到用户提问后就应该生成出最后输出的 md 文档的文件名,# 因为导出时若再生成文件名会导致部分组件无法识别该名称。keyword_match = re.search(r'(关于|分析|查询|搜索|查看)([^的\s,。、?\n]+)', query)keyword = keyword_match.group(2) if keyword_match else "分析对象"safe_keyword = re.sub(r'[\\/:*?"<>|]', '', keyword)[:20]timestamp = datetime.now().strftime('%Y%m%d_%H%M%S')md_filename = f"sentiment_{safe_keyword}_{timestamp}.md"md_path = os.path.join("./sentiment_reports", md_filename)# 更新查询,将文件名添加到原始查询中,使大模型在调用工具链时可以识别到该信息# 然后调用 plan_tool_usage 获取工具调用计划query = query.strip() + f" [md_filename={md_filename}] [md_path={md_path}]"messages = [{"role": "user", "content": query}]tool_plan = await self.plan_tool_usage(query, available_tools)tool_outputs = {}messages = [{"role": "user", "content": query}]# 依次执行工具调用,并收集结果for step in tool_plan:tool_name = step["name"]tool_args = step["arguments"]for key, val in tool_args.items():if isinstance(val, str) and val.startswith("{{") and val.endswith("}}"):ref_key = val.strip("{} ")resolved_val = tool_outputs.get(ref_key, val)tool_args[key] = resolved_val# 注入统一的文件名或路径(用于分析和邮件)if tool_name == "analyze_sentiment" and "filename" not in tool_args:tool_args["filename"] = md_filenameif tool_name == "send_email_with_attachment" and "attachment_path" not in tool_args:tool_args["attachment_path"] = md_pathresult = await self.session.call_tool(tool_name, tool_args)tool_outputs[tool_name] = result.content[0].textmessages.append({"role": "tool","tool_call_id": tool_name,"content": result.content[0].text})# 调用大模型生成回复信息,并输出保存结果final_response = self.client.chat.completions.create(model=self.model,messages=messages)final_output = final_response.choices[0].message.content# 对辅助函数进行定义,目的是把文本清理成合法的文件名def clean_filename(text: str) -> str:text = text.strip()text = re.sub(r'[\\/:*?\"<>|]', '', text)return text[:50]# 使用清理函数处理用户查询,生成用于文件命名的前缀,并添加时间戳、设置输出目录# 最后构建出完整的文件路径用于保存记录safe_filename = clean_filename(query)timestamp = datetime.now().strftime('%Y%m%d_%H%M%S')filename = f"{safe_filename}_{timestamp}.txt"output_dir = "./llm_outputs"os.makedirs(output_dir, exist_ok=True)file_path = os.path.join(output_dir, filename)# 将对话内容写入 md 文档,其中包含用户的原始提问以及模型的最终回复结果with open(file_path, "w", encoding="utf-8") as f:f.write(f"🗣 用户提问:{query}\n\n")f.write(f"🤖 模型回复:\n{final_output}\n")print(f"📄 对话记录已保存为:{file_path}")return final_outputasync def chat_loop(self):# 初始化提示信息print("\n🤖 MCP 客户端已启动!输入 'quit' 退出")# 进入主循环中等待用户输入while True:try:query = input("\n你: ").strip()if query.lower() == 'quit':break# 处理用户的提问,并返回结果response = await self.process_query(query)print(f"\n🤖 AI: {response}")except Exception as e:print(f"\n⚠️ 发生错误: {str(e)}")async def plan_tool_usage(self, query: str, tools: List[dict]) -> List[dict]:# 构造系统提示词 system_prompt。# 将所有可用工具组织为文本列表插入提示中,并明确指出工具名,# 限定返回格式是 JSON,防止其输出错误格式的数据。print("\n📤 提交给大模型的工具定义:")print(json.dumps(tools, ensure_ascii=False, indent=2))tool_list_text = "\n".join([f"- {tool['function']['name']}: {tool['function']['description']}"for tool in tools])system_prompt = {"role": "system","content": ("你是一个智能任务规划助手,用户会给出一句自然语言请求。\n""你只能从以下工具中选择(严格使用工具名称):\n"f"{tool_list_text}\n""如果多个工具需要串联,后续步骤中可以使用 {{上一步工具名}} 占位。\n""返回格式:JSON 数组,每个对象包含 name 和 arguments 字段。\n""不要返回自然语言,不要使用未列出的工具名。")}# 构造对话上下文并调用模型。# 将系统提示和用户的自然语言一起作为消息输入,并选用当前的模型。planning_messages = [system_prompt,{"role": "user", "content": query}]response = self.client.chat.completions.create(model=self.model,messages=planning_messages,tools=tools,tool_choice="none")# 提取出模型返回的 JSON 内容content = response.choices[0].message.content.strip()match = re.search(r"```(?:json)?\\s*([\s\S]+?)\\s*```", content)if match:json_text = match.group(1)else:json_text = content# 在解析 JSON 之后返回调用计划try:plan = json.loads(json_text)return plan if isinstance(plan, list) else []except Exception as e:print(f"❌ 工具调用链规划失败: {e}\n原始返回: {content}")return []async def cleanup(self):await self.exit_stack.aclose()async def main():server_script_path = "D:\\mcp-project\\server.py"client = MCPClient()try:await client.connect_to_server(server_script_path)await client.chat_loop()finally:await client.cleanup()if __name__ == "__main__":asyncio.run(main())5.4.4 server.py的编写
import os
import json
import smtplib
from datetime import datetime
from email.message import EmailMessageimport httpx
from mcp.server.fastmcp import FastMCP
from dotenv import load_dotenv
from openai import OpenAI# 加载环境变量
load_dotenv()# 初始化 MCP 服务器
mcp = FastMCP("NewsServer")# @mcp.tool() 是 MCP 框架的装饰器,表明这是一个 MCP 工具。之后是对这个工具功能的描述
@mcp.tool()
async def search_google_news(keyword: str) -> str:"""使用 Serper API(Google Search 封装)根据关键词搜索新闻内容,返回前5条标题、描述和链接。参数:keyword (str): 关键词,如 "小米汽车"返回:str: JSON 字符串,包含新闻标题、描述、链接"""# 从环境中获取 API 密钥并进行检查api_key = os.getenv("SERPER_API_KEY")if not api_key:return "❌ 未配置 SERPER_API_KEY,请在 .env 文件中设置"# 设置请求参数并发送请求url = "https://google.serper.dev/news"headers = {"X-API-KEY": api_key,"Content-Type": "application/json"}payload = {"q": keyword}async with httpx.AsyncClient() as client:response = await client.post(url, headers=headers, json=payload)data = response.json()# 检查数据,并按照格式提取新闻,返回前五条新闻if "news" not in data:return "❌ 未获取到搜索结果"articles = [{"title": item.get("title"),"desc": item.get("snippet"),"url": item.get("link")} for item in data["news"][:5]]# 将新闻结果以带有时间戳命名后的 JSON 格式文件的形式保存在本地指定的路径output_dir = "./google_news"os.makedirs(output_dir, exist_ok=True)filename = f"google_news_{datetime.now().strftime('%Y%m%d_%H%M%S')}.json"file_path = os.path.join(output_dir, filename)with open(file_path, "w", encoding="utf-8") as f:json.dump(articles, f, ensure_ascii=False, indent=2)return (f"✅ 已获取与 [{keyword}] 相关的前5条 Google 新闻:\n"f"{json.dumps(articles, ensure_ascii=False, indent=2)}\n"f"📄 已保存到:{file_path}")# @mcp.tool() 是 MCP 框架的装饰器,标记该函数为一个可调用的工具
@mcp.tool()
async def analyze_sentiment(text: str, filename: str) -> str:"""对传入的一段文本内容进行情感分析,并保存为指定名称的 Markdown 文件。参数:text (str): 新闻描述或文本内容filename (str): 保存的 Markdown 文件名(不含路径)返回:str: 完整文件路径(用于邮件发送)"""# 这里的情感分析功能需要去调用 LLM,所以从环境中获取 LLM 的一些相应配置openai_key = os.getenv("DASHSCOPE_API_KEY")model = os.getenv("MODEL")client = OpenAI(api_key=openai_key, base_url=os.getenv("BASE_URL"))# 构造情感分析的提示词prompt = f"请对以下新闻内容进行情绪倾向分析,并说明原因:\n\n{text}"# 向模型发送请求,并处理返回的结果response = client.chat.completions.create(model=model,messages=[{"role": "user", "content": prompt}])result = response.choices[0].message.content.strip()# 生成 Markdown 格式的舆情分析报告,并存放进设置好的输出目录markdown = f"""# 舆情分析报告**分析时间:** {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}---## 📥 原始文本{text}---## 📊 分析结果{result}
"""output_dir = "./sentiment_reports"os.makedirs(output_dir, exist_ok=True)if not filename:filename = f"sentiment_{datetime.now().strftime('%Y%m%d_%H%M%S')}.md"file_path = os.path.join(output_dir, filename)with open(file_path, "w", encoding="utf-8") as f:f.write(markdown)return file_path@mcp.tool()
async def send_email_with_attachment(to: str, subject: str, body: str, filename: str) -> str:"""发送带附件的邮件。参数:to: 收件人邮箱地址subject: 邮件标题body: 邮件正文filename (str): 保存的 Markdown 文件名(不含路径)返回:邮件发送状态说明"""# 获取并配置 SMTP 相关信息smtp_server = os.getenv("SMTP_SERVER") # 例如 smtp.qq.comsmtp_port = int(os.getenv("SMTP_PORT", 465))sender_email = os.getenv("EMAIL_USER")sender_pass = os.getenv("EMAIL_PASS")# 获取附件文件的路径,并进行检查是否存在full_path = os.path.abspath(os.path.join("./sentiment_reports", filename))if not os.path.exists(full_path):return f"❌ 附件路径无效,未找到文件: {full_path}"# 创建邮件并设置内容msg = EmailMessage()msg["Subject"] = subjectmsg["From"] = sender_emailmsg["To"] = tomsg.set_content(body)# 添加附件并发送邮件try:with open(full_path, "rb") as f:file_data = f.read()file_name = os.path.basename(full_path)msg.add_attachment(file_data, maintype="application", subtype="octet-stream", filename=file_name)except Exception as e:return f"❌ 附件读取失败: {str(e)}"try:with smtplib.SMTP_SSL(smtp_server, smtp_port) as server:server.login(sender_email, sender_pass)server.send_message(msg)return f"✅ 邮件已成功发送给 {to},附件路径: {full_path}"except Exception as e:return f"❌ 邮件发送失败: {str(e)}"if __name__ == "__main__":mcp.run(transport='stdio')
5.4.5 启动
启动client即可
温馨提醒,记得在大模型平台上去获取大模型的密钥以及谷歌的新闻获取密钥在.env上配置,这样子才能顺利运行。
最后以上的代码我会新开一个文章去逐行解释意思,这一篇MCP的学习就到此告一段落咯,咱们下期更多的新知识探索等你!!!