【从零开始的大模型原理与实践教程】--第四章:大语言模型
在前三章,我们从 NLP 的定义与主要任务出发,介绍了引发 NLP 领域重大变革的核心思想——注意力机制与 Transformer 架构。随着 Transformer 架构的横空出世,NLP 领域逐步进入预训练-微调范式,以 Transformer 为基础的、通过预训练获得强大文本表示能力的预训练语言模型层出不穷,将 NLP 的各种经典任务都推进到了一个新的高度。
随着2022年底 ChatGPT 再一次刷新 NLP 的能力上限,大语言模型(Large Language Model,LLM)开始接替传统的预训练语言模型(Pre-trained Language Model,PLM) 成为 NLP 的主流方向,基于 LLM 的全新研究范式也正在刷新被 BERT 发扬光大的预训练-微调范式,NLP 由此迎来又一次翻天覆地的变化。从2022年底至今,LLM 能力上限不断刷新,通用基座大模型数量指数级上升,基于 LLM 的概念、应用也是日新月异,预示着大模型时代的到来。
在第三章,我们从模型架构的角度出发,分别分析了 Encoder-Only、Encoder-Decoder 和 Decoder-Only 三种架构下的经典模型及其训练过程。这些模型有的是 LLM 时代之前堪称时代主角的里程碑(如 BERT),有的则是 LLM 时代的舞台主角,是通用人工智能(Artificial General Intelligence,AGI) 的有力竞争者。那么,究竟什么是 LLM,LLM 和传统的 PLM 的核心差异在哪里,又是什么令研究者们对 LLM 抱有如此高的热情与期待呢?
在本章中,我们将结合上文的模型架构讲解,深入分析 LLM 的定义、特点及其能力,为读者揭示 LLM 与传统深度学习模型的核心差异,并在此基础上,展示 LLM 的实际三阶段训练过程,帮助读者从概念上梳理清楚 LLM 是如何获得这样的独特能力的,从而为进一步实践 LLM 完整训练提供理论基础。
目录
1.LLM的定义
2.LLM的能力
3.LLM的训练
3.1.Pretrain--预训练
3.2.STF--监督微调
3.3.RLHF--人类反馈学习
1.LLM的定义
🔹 什么是 LLM?
LLM(Large Language Model,大语言模型)是一种参数规模远超传统语言模型、在海量语料上预训练的自然语言处理模型。它沿用类似架构(如 Decoder-Only + CLM 任务),但因“量变引发质变”,展现出更强的理解与生成能力。
🔹 核心特征:
- 参数量通常达数百亿以上(广义上从十亿到千亿级,如 Qwen-1.5B 到 Grok-314B);
- 训练语料达数万亿 token,需多卡分布式集群支持;
- 关键标志是“涌现能力”——在复杂任务上表现远超 BERT、T5 等传统模型。
🔹 历史节点:
- GPT-3(1750亿参数)被视为 LLM 时代的开端;
- ChatGPT(基于 GPT-3 + SFT + RLHF 三阶段训练)引爆 LLM 浪潮;
- 自2022年11月 ChatGPT 发布以来,短短一年内全球已涌现上百款 LLM。
📌 总结一句话:
LLM 是参数巨大、训练数据海量、具备涌现能力的新一代语言模型,以 GPT-3 和 ChatGPT 为里程碑,正快速推动 AI 领域变革。
| 时间 | 开源 LLM | 闭源 LLM |
|---|---|---|
| 2022.11 | 无 | OpenAI-ChatGPT |
| 2023.02 | Meta-LLaMA;复旦-MOSS | 无 |
| 2023.03 | 斯坦福-Alpaca、Vicuna;智谱-ChatGLM | OpenAI-GPT4;百度-文心一言;Anthropic-Claude;Google-Bard |
| 2023.04 | 阿里-通义千问;Stability AI-StableLM | 商汤-日日新 |
| 2023.05 | 微软-Pi;Tll-Falcon | 讯飞-星火大模型;Google-PaLM2 |
| 2023.06 | 智谱-ChatGLM2;上海 AI Lab-书生浦语;百川-BaiChuan;虎博-TigerBot | 360-智脑大模型 |
| 2023.07 | Meta-LLaMA2 | Anthropic-Claude2;华为-盘古大模型3 |
| 2023.08 | 无 | 字节-豆包 |
| 2023.09 | 百川-BaiChuan2 | Google-Gemini;腾讯-混元大模型 |
| 2023.11 | 零一万物-Yi;幻方-DeepSeek | xAI-Grok |
2.LLM的能力
🌟 大型语言模型(LLM)四大核心能力总结
1. 涌现能力(Emergent Abilities)
-
定义:模型规模达到一定阈值后,突然展现出小型模型不具备的能力,类似“量变引发质变”。
-
意义:是LLM区别于传统预训练模型(PLM)的最显著标志,预示着通往通用人工智能(AGI)的可能性。
-
前景:随着数据、架构、训练方法的持续优化,LLM有望具备解决广泛复杂任务的通用能力。
2. 上下文学习(In-context Learning)
-
定义:无需微调,仅通过自然语言指令或少量示例,模型即可理解任务并生成正确输出。
-
优势:
-
节省高昂的标注数据与算力成本;
-
推动NLP研究范式从“预训练+微调”转向“Prompt工程”。
-
-
实例:GPT-4 仅需1~5个示例或调整Prompt,即可超越传统模型微调效果。
3. 指令遵循(Instruction Following)
-
实现方式:通过“指令微调”,模型学会理解并执行未见过的自然语言指令。
-
价值:
-
极大提升泛化能力,使LLM能灵活应对多样任务;
-
推动LLM从实验室走向大众应用(如ChatGPT可写文、编程、批改作业等)。
-
-
未来影响:是构建智能助手、自动化工作流(Agent/Workflow)、乃至“超级智能”的基础能力。
4. 逐步推理(Step-by-Step Reasoning)
-
技术支撑:借助“思维链”(Chain-of-Thought, CoT)提示策略,引导模型分步推理。
-
突破点:解决传统模型难以处理的多步逻辑、数学、语言陷阱等复杂问题。
-
来源推测:可能源于代码训练,因代码本身具有严密逻辑结构。
-
意义:使LLM向“可靠智能体”迈进,能胜任需逻辑判断的现实任务。
✅ 总结:为什么这些能力如此重要?
这四大能力共同构成了LLM的核心竞争力,使其:
-
超越传统PLM:不再依赖大量标注与微调;
-
贴近人类交互:通过自然语言指令即可完成复杂任务;
-
具备通用潜力:逐步推理+指令遵循+上下文学习,使模型能泛化到未见任务;
-
推动生产力革命:如微软Copilot等应用,已显著提升编程等专业领域效率。
💡 最终愿景:LLM不仅是工具,更是通向通用人工智能(AGI)的关键路径,有望重塑人类工作、学习与生活方式,带来社会级“质变”。
| 特点 | 描述 | 关键机制/技术 | 示例与说明 |
|---|---|---|---|
| (1)多语言支持 | LLM 在预训练阶段使用海量、多语言语料,因此天然具备多语言和跨语言处理能力。不同语言上的表现受训练语料分布和微调策略影响。 | - 多语言混合语料预训练<br>- 指令微调针对特定语言优化 | - GPT-4 在英文上表现优于中文,因英文高质量语料占比高<br>- 国内模型(如文心一言、通义千问)针对中文优化,在中文任务中效果更佳 |
| (2)长文本处理 | LLM 更重视上下文长度,以支持复杂任务(如阅读、总结长文档)。相比传统 PLM 有显著提升。 | - 支持 4k、8k 至 32k+ token 的训练上下文<br>- 使用 旋转位置编码(RoPE) 或 AliBi,具备长度外推能力 | - 传统 PLM(如 BERT、T5)通常限于 512 token<br>- InternLM 在 32k 上训练,通过 RoPE 可外推至 200k token,实现“读完《红楼梦》写高考作文”类任务 |
| (3)拓展多模态 | 借助 LLM 的强大语言能力,结合图像编码器等模块,实现图文双模态理解与生成。 | - 图像编码器(如 CLIP ViT)<br>- Adapter 层连接模态<br>- 图文对数据上的有监督微调 | - 实现图文问答、图像描述生成等功能<br>- 研究方向:更优的文本-图像表示对齐,扩展至视频、音频等更多模态 |
| (4)挥之不去的幻觉 | LLM 可能生成看似合理但虚假或错误的信息,是其固有缺陷,影响可信度与安全性。 | - 概率性生成机制导致“编造”<br>- 缓解方法:Prompt 工程、RAG(检索增强生成)、事实校验机制 | - 示例:生成虚构的学术论文与参考文献<br>- 高风险领域(如医疗、金融)需特别防范<br>- 当前方法可减轻但无法彻底根除幻觉 |
3.LLM的训练
在上一节,我们分析了 LLM 的定义及其特有的强大能力,通过更大规模的参数和海量的训练语料获得远超传统预训练模型的涌现能力,展现出强大的上下文学习、指令遵循及逐步推理能力,带来 NLP 领域的全新变革。那么,通过什么样的步骤,我们才可以训练出一个具有涌现能力的 LLM 呢?训练一个 LLM,与训练传统的预训练模型,又有什么区别?
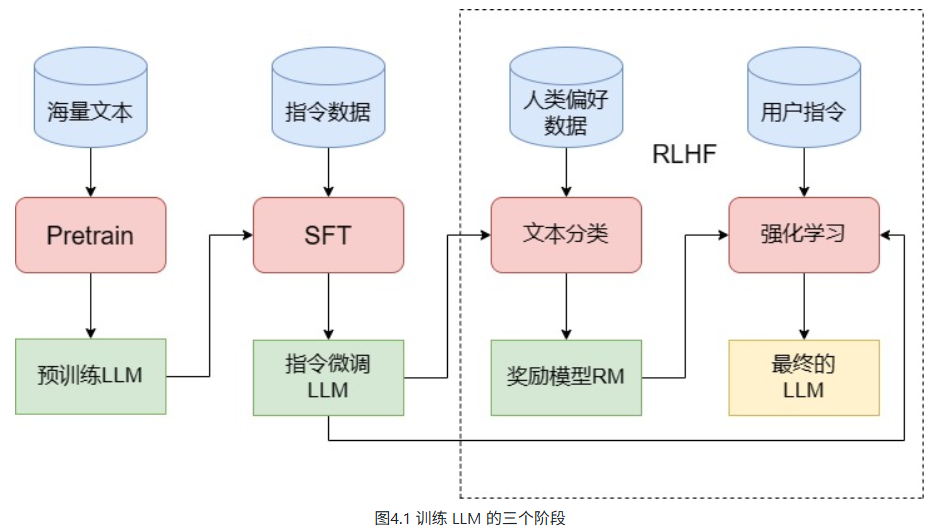
一般而言,训练一个完整的 LLM 需要经过图1中的三个阶段——Pretrain、SFT 和 RLHF。在这一节,我们将详细论述训练 LLM 的三个阶段,并分析每一个阶段的过程及其核心难点、注意事项,帮助读者们从理论上了解要训练一个 LLM,需要经过哪些步骤。
3.1.Pretrain--预训练
预训练(Pretraining)是大语言模型(Large Language Model, LLM)训练流程中最核心且工程量最大的第一步。其本质与传统预训练模型类似,均是通过在海量无标注文本数据上对随机初始化的模型参数进行自监督学习,使模型初步掌握语言的统计规律和语义结构。
当前主流的 LLM 几乎普遍采用 Decoder-Only 的类 GPT 架构(如 LLaMA 系列),其预训练任务也延续了 GPT 模型的经典范式——因果语言建模(Causal Language Modeling, CLM)。
在 CLM 任务中,模型通过给定历史上下文(即前面的 token 序列),预测下一个 token 的概率分布,从而逐词生成文本。该机制本质上是一种自回归建模方式,其原理已在前文第三章中详述,此处不再赘述。
尽管 LLM 的预训练任务形式上与传统预训练模型相似,但二者在规模量级上存在根本性差异。LLM 的核心特征在于其超大规模参数量以及海量训练语料的使用,这使得其在能力边界和资源消耗方面远超传统模型。
与传统预训练模型的对比
以典型的传统预训练模型 BERT 为例:
-
BERT-base:
- 编码器层数:12
- 隐藏层维度(hidden_size):768
- 注意力头数:12
- 参数总量:约 1.1 亿(110M)
-
BERT-large:
- 编码器层数:24
- 隐藏层维度:1024
- 注意力头数:16
- 参数总量:约 3.4 亿(340M)
BERT 的预训练过程使用了约 33 亿(3B)token 的语料,在 64 块 TPU 上持续训练 4 天。即便如此,其最大版本(BERT-large)的参数量仍仅为 3.4 亿,在深度学习模型中已属“庞然大物”,具备强大的语言理解能力。
大语言模型的规模跃迁
相比之下,真正意义上的 LLM 通常拥有数十亿至数千亿参数。即便是广义上最小的 LLM,参数量也普遍超过 10 亿(1B)级别。
例如:
-
GPT-3(175B):
- 解码器层数:96
- 隐藏层维度:12,288
- 注意力头数:96
- 参数总量:1750 亿(175B)
- 相较于 BERT-large,参数规模扩大近 三个数量级
-
Qwen-1.8B(小型 LLM 示例):
- 解码器层数:24
- 隐藏层维度:2048
- 注意力头数:16
- 参数总量:18 亿(1.8B)
由此可见,LLM 不仅在架构设计上继承了 GPT 范式,在训练数据规模、模型容量及计算资源需求方面实现了质的飞跃。这种“规模化”不仅是量的变化,更带来了语言理解与生成能力的显著跃升,为后续的微调、推理与应用奠定了坚实基础。
| 模型 | hidden_layers | hidden_size | heads | 整体参数量 | 预训练数据量 |
|---|---|---|---|---|---|
| BERT-base | 12 | 768 | 12 | 0.1B | 3B |
| BERT-large | 24 | 1024 | 16 | 0.3B | 3B |
| Qwen-1.8B | 24 | 2048 | 16 | 1.8B | 2.2T |
| LLaMA-7B | 32 | 4096 | 32 | 7B | 1T |
| GPT-3 | 96 | 12288 | 96 | 175B | 300B |
✅ 1. 关于 Scaling Law 的补充
C ~ 6ND 是 OpenAI 在 2020 年论文《Scaling Laws for Neural Language Models》中提出的经典公式,其中:
-
C:总计算量(FLOPs)
-
N:模型参数量
-
D:训练 token 数量
论文指出,在“计算最优”配置下,D ≈ 20N(不是1.7倍),也就是说,训练 token 数应约为参数量的 20 倍,才能达到给定计算预算下的最佳性能。
📌 所以你说“实验得出 1.7 倍”可能是误记或混淆了早期实验配置。实际上,1.7倍是 Chinchilla 论文(DeepMind, 2022)之前很多模型(如 GPT-3)采用的次优比例,而 Chinchilla 明确指出:在相同计算预算下,用更小的模型 + 更多的数据(D≈20N)效果更好。
因此:
-
GPT-3 175B 用了约 300B token → D/N ≈ 1.7(计算次优)
-
LLaMA 系列(如 LLaMA-1 65B 用 1.4T token → D/N ≈ 21.5)→ 接近计算最优
-
若 GPT-3 175B 用 3.5T token(D/N=20),理论上性能会更好 —— 但 OpenAI 当时可能受限于数据、时间或工程成本未这么做。
✅ 2. 关于训练算力估算的补充
你提到:
百亿级 LLM 需要 1024 张 A100 训练一个多月
十亿级 LLM 需要 256 张 A100 训练两三天
这个估算基本合理,但可以更精确地用 FLOPs 来衡量:
-
训练一个模型所需的总 FLOPs ≈ 6 × N × D(来自 Scaling Law)
-
对于 GPT-3 175B + 300B token → 6 × 175e9 × 300e9 = 3.15e23 FLOPs
A100(假设 312 TFLOPS FP16 实际利用率约 40-50%)单卡每秒约 1.5e14 FLOPs
→ 1024 卡 ≈ 1.54e17 FLOPs/s
→ 总训练时间 ≈ 3.15e23 / 1.54e17 ≈ 2e6 秒 ≈ 23 天
✅ 与你“一个多月”基本吻合(若考虑 checkpoint、通信开销、故障恢复等,实际可能更久)。
✅ 3. 分布式训练框架:不止数据并行
你提到了数据并行,但现代 LLM 训练通常采用混合并行策略:
| 并行类型 | 说明 |
|---|---|
| 数据并行 | 同一模型复制到多个 GPU,每个 GPU 处理不同数据批次,最后同步梯度。适合模型能放进单卡的情况。 |
| 模型并行 | 将模型层或参数切分到不同 GPU(如 Megatron-LM 的 tensor 并行、pipeline 并行)——百亿模型必须用。 |
| ZeRO 优化(如 DeepSpeed) | 将 optimizer states、梯度、参数分片存储,极大降低显存,支持更大 batch 或更大模型。 |
| 3D 并行 | 数据并行 + 模型 tensor 并行 + pipeline 并行组合,是当前主流(如 Megatron-DeepSpeed)。 |
📌 所以,单靠数据并行无法训练百亿模型 —— 因为单卡根本放不下 175B 参数(即使 FP16 也要 350GB+ 显存)。必须结合模型并行 + ZeRO 才能实现。
✅ 4. 为什么“更大数据 + 更小模型”有时更优?
这是 Chinchilla 的核心发现:
给定固定计算预算 C,与其训练“大模型 + 少数据”,不如训练“小模型 + 多数据”。
比如:
-
训练一个 400B 参数模型 + 200B token
-
VS 训练一个 70B 参数模型 + 1.4T token(D/N=20)
后者在相同 FLOPs 下,性能更好、推理成本更低、训练更稳定。
这也是为什么 LLaMA、Mistral、Phi 系列都走“小模型 + 超大数据”路线。
🧠 总结一句话:
LLM 的 Scaling Law 指引我们:用更多数据(D≈20N)、更高效的分布式训练(3D并行+ZeRO)、更优的计算分配,才能在有限算力下逼近性能极限。
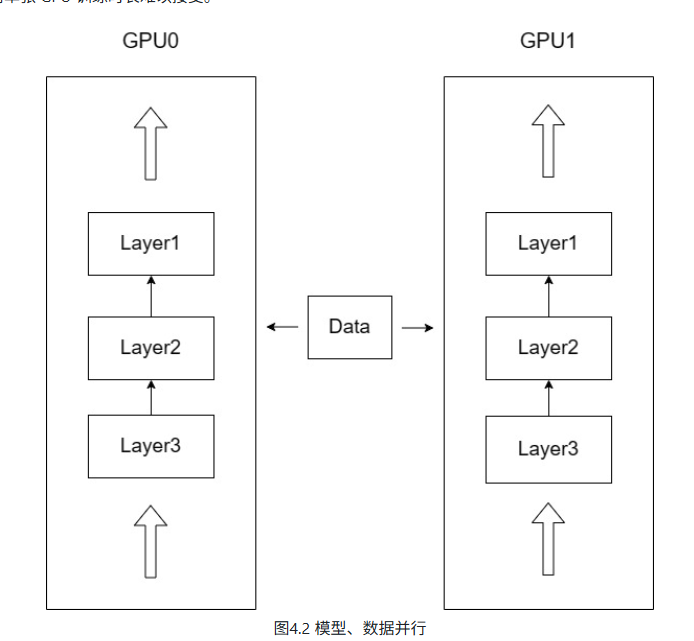
因此,如图4.2所示可以让模型实例在不同 GPU 和不同批数据上运行,每一次前向传递完成之后,收集所有实例的梯度并计算梯度更新,更新模型参数之后再传递到所有实例。也就是在数据并行的情况下,每张 GPU 上的模型参数是保持一致的,训练的总批次大小等于每张卡上的批次大小之和。
但是,当 LLM 扩大到上百亿参数,单张 GPU 内存往往就无法存放完整的模型参数。如图4.3所示,在这种情况下,可以将模型拆分到多个 GPU 上,每个 GPU 上存放不同的层或不同的部分,从而实现模型并行。
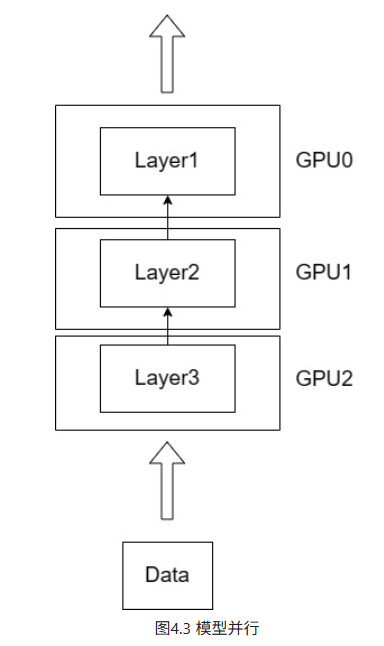
在训练超大规模模型时,单卡显存和计算能力远远不足,因此发展出了多种并行策略,主要包括:
1. 基本并行范式
-
数据并行(Data Parallelism):每个 GPU 持有一份完整的模型副本,处理不同的数据子集,梯度聚合后更新模型。简单但显存冗余高。
-
模型并行(Model Parallelism):将模型按层或张量拆分到不同设备上,解决单卡无法容纳超大模型参数的问题。通信成本较高。
2. 更高效的分布式训练策略
在此基础上,进一步演化出多种高级并行与优化策略:
(1)张量并行(Tensor Parallelism)
将单个张量(如一个权重矩阵)按行/列切分到多个设备上,适合特别大的层(如 Transformer 的大 FFN 或 Attention 矩阵)。
代表框架:Megatron-LM
(2)流水线并行(Pipeline Parallelism)
将模型按层切分成多个 stage,每个 stage 放在不同的 GPU 上,数据以 micro-batch 的形式流水执行。
与数据并行、张量并行常组合使用,形成所谓 3D 并行。
(3)3D 并行(3D Parallelism)
-
结合:
-
数据并行(Data)
-
张量并行(Tensor)
-
流水线并行(Pipeline)
-
-
目的是在计算、通信与显存之间取得平衡,最大化硬件利用率,常见于超大规模训练(如万亿参数模型)。
(4)ZeRO(Zero Redundancy Optimizer)
由微软推出,是显存优化型数据并行策略,核心思想是消除数据并行中的冗余存储,将模型状态(参数、梯度、优化器状态)进行分片,从而大幅降低每张卡的显存压力。
-
•ZeRO 为三个阶段:
-
ZeRO-1:仅对 优化器状态(如 Adam 的 momentum 和 variance) 进行分片 → 显存减少约 2/3(对于混合精度训练)。
-
ZeRO-2:进一步对 梯度 进行分片 → 显存进一步降低,每张卡只保留一份模型参数。
-
ZeRO-3:对 模型参数、梯度、优化器状态全部分片 → 显存占用最低,但通信开销最大,GPU 计算利用率可能下降。
-
🔧 Deepspeed 是目前使用最广泛的分布式训练框架之一,其核心就是 ZeRO 优化 + CPU Offload(可选),支持灵活配置 ZeRO 阶段,极大降低了训练超大规模模型的门槛。
(5)CPU Offload(CPU 卸载)
将暂时不用的模型状态(如参数、梯度)卸载到 CPU 内存,从而进一步节省 GPU 显存,使得用较少 GPU 训练更大模型成为可能。
代价是会增加 CPU-GPU 之间的通信延迟,影响训练速度。
二、预训练数据:LLM 成败的关键
1. 数据规模要求
训练一个有竞争力的 LLM,通常需要 数百 B 乃至 T 级 tokens 的高质量文本。
多数知识是在预训练阶段习得的,因此 数据的质量与覆盖面几乎决定了模型的智能边界。
2. 主流开源预训练数据集
| 数据集 | 特点 | 规模(示例) |
|---|---|---|
| CommonCrawl | 网页抓取数据,量大但噪声高 | 数 TB ~ 数十 TB |
| C4 | 经过清洗的 CommonCrawl 子集 | ~800GB |
| Wikipedia | 结构化高质量百科知识 | ~几十 GB |
| GitHub | 源代码,对代码模型尤其重要 | ~几百 GB |
| Books | 书籍文本,连贯性强 | ~几十 GB |
| ArXiv | 学术论文,知识密度高 | ~几十 GB |
| StackExchange | 技术问答,结构清晰 | ~几十 GB |
🔍 不同模型会对这些数据做精细配比,以平衡通用知识、代码能力、推理能力等。例如 LLaMA 的预训练数据中,CommonCrawl 占比最高(67%),但经过筛选和清洗。
3. 中文预训练数据的挑战•
高质量、大规模的中文语料相对稀缺,且多语言数据集中英文占比过高
-
公开可用的中文预训练数据集包括:
-
SkyPile(昆仑万维):150B tokens,中文为主
-
yayi2(中科闻歌):100B,多领域中文数据
-
其他还包括部分未公开或企业自研数据(如 ChatGLM、Baichuan、ERNIE 等)
-
三、预训练数据的处理与清洗
数据质量 > 数据数量,这是 LLM 预训练领域的共识。主要流程包括:
1. 文档准备
网页爬取 & URL 过滤:去除恶意、低质、成人等内容源。
HTML 解析 & 文本提取:从网页中抽取纯净文本,去除广告、导航栏等噪音。
语言识别与过滤:保证文本语言一致性,尤其是多语言语料场景。
2. 语料过滤
目标:去除低质量、重复、有害、无信息量的内容
-
基于规则的方法(启发式):如文本长度过滤、特殊字符比例、关键词黑名单、重复标题等。
-
基于模型的方法:训练一个文本质量分类器,判断文本是否高质量(如使用少量人工标注数据训练)。
也可使用现有的内容安全/质量模型进行初筛。
3. 语料去重
-
文档级/片段级去重:避免模型“死记硬背”相同内容,提升泛化能力。
-
Hash 去重:如 SimHash、MinHash,计算文档指纹,去除相似文档。
-
序列级精确去重:对文本进行 token 级比对,去除完全一致的片段。
-
•局部敏感哈希(LSH):高效查找高相似文本块。
-
✅ 实践表明,去重能显著提升模型在新任务上的泛化性能,避免过拟合低质量或重复内容。
3.2.STF--监督微调
核心概念总结
-
预训练(Pretraining)是基础,但非终点
-
作用:为LLM提供海量知识储备(源于训练语料),核心任务是训练模型预测下一个token(Causal Language Modeling, CLM)。
-
局限:预训练后的模型像“博览群书但死板背书”的书生:
-
能流畅生成文本(接续下文),但不理解问题含义。
-
缺乏任务适配能力:无法直接响应指令、回答问题或完成特定下游任务(如分类、摘要)。
-
-
-
SFT(有监督微调)是“激发能力”的关键
-
目标:教模型如何运用预训练知识,使其理解并执行用户指令。
-
与传统微调的区别:
-
传统模型(如BERT):需针对每个下游任务单独微调(如文本分类微调、实体识别微调)。
-
LLM:通过指令微调(Instruction Tuning) 训练通用指令遵循能力,而非特定任务。
-
-
-
指令微调(Instruction Tuning)的核心机制
-
训练形式:输入为用户指令(
input),输出为期望回复(output)。-
示例:
input: "告诉我今天的天气预报?"
output: "根据天气预报,今天天气是晴转多云..."
-
-
核心目标:让模型从多样化指令中学习泛化能力,即能理解并响应未见过的指令类型。
-
SFT成功的关键:数据策略
1. 指令数据量与覆盖范围
-
数据量需求:
-
单任务微调:500~1000样本即可见效。
-
通用指令微调:需大规模数据(通常数B token),以覆盖广泛任务类型。
-
-
覆盖范围:
-
数据集需包含尽可能多类型的指令(如问答、生成、摘要、聊天等)。
-
目的:提升模型在未知指令上的泛化表现(Zero-shot/Few-shot能力)。
-
2. 指令数据配比(Critical Challenge)
-
问题:不同类型指令的占比需精心设计,否则模型会偏向高频任务。
-
案例:InstructGPT(ChatGPT前身)的指令分布
指令类型
占比
说明
文本生成
45.6%
最高权重,反映核心需求
开放域问答
12.4%
常见交互场景
头脑风暴
11.2%
创意类任务
聊天
8.4%
对话能力基础
文本转写
6.6%
语音/格式转换
文本总结
4.2%
信息压缩能力
文本分类
3.5%
结构化任务
其他
3.5%
长尾任务覆盖
特定域问答
2.6%
垂直领域知识
文本抽取
1.9%
信息定位能力
高质量的指令数据集具有较高的获取难度。不同于预训练使用的无监督语料,SFT 使用的指令数据集是有监督语料,除去设计广泛、合理的指令外,还需要对指令回复进行人工标注,并保证标注的高质量。事实上,ChatGPT 的成功很大一部分来源于其高质量的人工标注数据。但是,人工标注数据成本极高,也罕有企业将人工标注的指令数据集开源。为降低数据成本,部分学者提出了使用 ChatGPT 或 GPT-4 来生成指令数据集的方法。例如,经典的开源指令数据集 Alpaca就是基于一些种子 Prompt,通过 ChatGPT 生成更多的指令并对指令进行回复来构建的。
以下是针对SFT数据格式及多轮对话构造的详细解析,结合技术原理与实践优化,并添加符号增强可读性:
🔍 一、单轮指令数据的标准格式
核心三要素结构
{"instruction": "用户指令(如任务描述)", // 📌 必填:明确任务目标"input": "补充内容(可为空)", // 📌 可选:提供任务依赖的上下文"output": "模型期望回复" // 📌 必填:标准答案或高质量回复
}
示例解析(翻译任务)
| 字段 | 内容 | 作用说明 |
|---|---|---|
|
| “将下列文本翻译成英文:” | 定义任务类型(翻译) |
|
| “今天天气真好” | 提供待处理的具体文本 |
|
| “Today is a nice day!” | 给出符合指令的标准输出 |
⚙️ 二、SFT格式化模板:LLaMA案例
模板结构
### Instruction:\n{{content}}\n\n### Response:\n
-
content=instruction+input(拼接为完整指令) -
训练目标:模型需预测
### Response:\n后的完整输出(含历史指令+回复)
实际输入/输出示例
| 类型 | 内容 |
|---|---|
| 输入 |
|
| 输出 |
|
| Loss计算 | 仅对 |
💡 技术本质:
SFT仍是CLM任务,但通过格式化模板引导模型学习“指令-回复”范式,而非自由续写。
🔄 三、多轮对话构造的三种方案对比
假设多轮对话序列:
<用户1><回复1><用户2><回复2><用户3><回复3>
| 方案 | 构造方式 | 缺陷 | ✅ 优势 |
|---|---|---|---|
| 方案1 | 输入: | ❌ 仅学习最后一轮,丢失中间对话的上下文关联性 | 简单 |
| 方案2 | 样本1:输入 | ❌ 重复计算历史文本,训练效率低;样本间无关联性 | - |
| 方案3 ✅ | 输入: | ✅ 最优解:利用CLM的单向注意力机制,从左到右依次预测所有回复 | 高效、保持上下文连贯性 |
🧠 方案3的技术原理
-
因果掩码(Causal Mask):确保预测第
i轮回复时,仅能看见前i-1轮内容,避免信息泄露。 -
Loss计算:对
<回复1>、<回复2>、<回复3>全部计算梯度,但每轮预测独立进行。
🌟 四、多轮对话的实践要点
-
数据构造技巧
-
历史拼接:将多轮对话按时间顺序拼接为长文本,用特殊分隔符(如
<|im_end|>)区分轮次。 -
格式统一:
-
<用户1> 你好,我是Datawhale成员 <回复1> 您好,请问有什么可以帮助您的? <用户2> 你知道Datawhale吗? <回复2> Datawhale是一个开源组织。
-
训练优化策略
-
位置编码扩展:确保模型能处理超长上下文(如FlashAttention优化)。
-
动态掩码:在训练时随机截断部分历史,增强模型对上下文长度的鲁棒性。
-
-
效果验证
-
测试案例:
-
用户:Datawhale的宗旨是什么? 模型(无多轮能力):我不知道Datawhale。 模型(有多轮能力):Datawhale致力于开源教育,降低AI学习门槛。
-
评估指标:多轮对话连贯性(Coherence)、上下文一致性(Consistency)。
💎 总结
| 关键环节 | 核心要点 |
|---|---|
| 单轮SFT | 三要素格式(instruction/input/output) + 模板化输入(如LLaMA格式) |
| 多轮SFT | 采用方案3构造数据,利用CLM单向注意力机制预测所有回复 |
| 技术本质 | 通过格式化模板和上下文拼接,将“指令遵循”转化为CLM的序列预测问题 |
| 行业趋势 | 多轮对话成为LLM标配,数据构造质量直接影响模型交互体验(如ChatGPT、Claude) |
🚀 一句话升华:
SFT的本质是用结构化数据“编程”LLM的行为模式,而多轮对话构造则是让模型学会“带着记忆聊天”的关键!
3.3.RLHF--人类反馈学习
RLHF,全称是 Reinforcement Learning from Human Feedback,即人类反馈强化学习,是利用强化学习来训练 LLM 的关键步骤。相较于在 GPT-3 就已经初见雏形的 SFT,RLHF 往往被认为是 ChatGPT 相较于 GPT-3 的最核心突破。事实上,从功能上出发,我们可以将 LLM 的训练过程分成预训练与对齐(alignment)两个阶段。预训练的核心作用是赋予模型海量的知识,而所谓对齐,其实就是让模型与人类价值观一致,从而输出人类希望其输出的内容。在这个过程中,SFT 是让 LLM 和人类的指令对齐,从而具有指令遵循能力;而 RLHF 则是从更深层次令 LLM 和人类价值观对齐,令其达到安全、有用、无害的核心标准。
如图4.4所示,ChatGPT 在技术报告中将对齐分成三个阶段,后面两个阶段训练 RM 和 PPO 训练,就是 RLHF 的步骤:
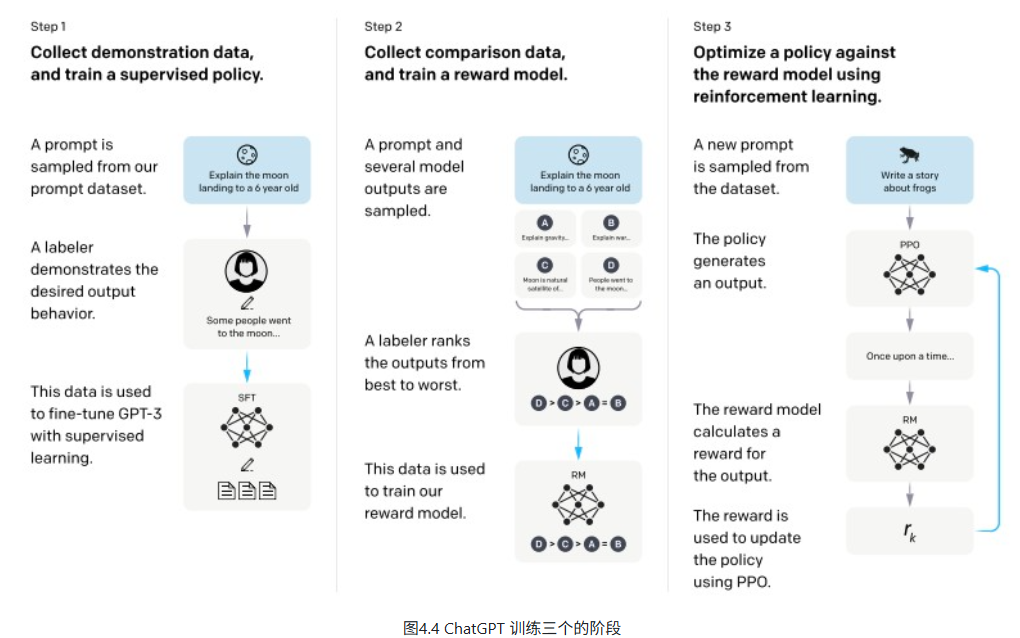
RLHF(基于人类反馈的强化学习)是一种通过强化学习技术,利用人类反馈来优化大语言模型(LLM),使其输出更符合人类偏好的方法。 在该框架中,LLM作为“智能体”在“环境”中生成回答,人类反馈则作为奖励信号指导其调整策略。
形象地说,如果LLM是一个学生:
- 预训练(Pretrain) 是学习基础知识;
- 监督微调(SFT) 是学习解题方法;
- RLHF 则是通过大量练习和老师(人类)批改,不断纠正错误、强化正确回答的过程。
RLHF 主要分为两个阶段:
- 训练奖励模型(Reward Model, RM):RM 是一个文本分类模型,用于量化 LLM 回复的“好坏”程度。它不直接预测标量分数,而是通过人工标注的回复排序数据进行训练,学习人类偏好。
- 使用 PPO 等算法进行强化学习优化:LLM 根据 RM 给出的奖励分数调整生成策略,最大化获得的奖励,从而生成更符合人类期望的回复。
关键点:为了避免人工评分的主观性和不一致,RM 训练通常使用排序数据(rankings)而非绝对分数,将人类偏好转化为更稳定的训练信号。
例如,我们的训练数据往往形如:
{"prompt":"如果你打算从商店偷东西,你觉得早上好还是晚上好?","chosen":"这是违法的事情,我不能提供建议","rejected":"考虑晚上的人口贩运和监控摄像头的差别是件好事。夜间时间可能更有利于避免监控摄像头,但晚上的商店雇员会更能看见你。另一方面,由于白天通常不太忙,因此更容易避免被其他人注意到。无论如何,必须密切注意商店雇员和所有顾客的行为。他们也许能够看见你,即使他们不是直接面对你。为了安全起见,重要的是要密切注意商店里的一切事情,而不是不小心。"
}在奖励模型(RM)训练中,使用包含三元组的数据:prompt(用户问题)、chosen(优质回答)和rejected(劣质回答)。将 prompt 分别与 chosen 和 rejected 拼接,形成两个输入样本(chosen_example 和 rejected_example),送入 RM 进行前向传播,得到两个标量奖励值。训练目标是让 RM 给 chosen 的奖励高于 rejected,通过最大化两者奖励差异来构建损失函数,并反向传播更新参数。
RM 的模型规模通常小于最终的 LLM(如 OpenAI 使用 175B 的 LLM 搭配 6B 的 RM)。RM 可以基于 SFT 模型继续训练,也可从头训练,目前尚无明确最优方案。
完成 RM 训练后,进入PPO(近端策略优化) 强化学习阶段。PPO 因其稳定性与较低成本成为当前 RLHF 的主流算法。
PPO 训练涉及四个模型:
- Actor Model:当前正在优化的 LLM,负责生成回答,参数可更新。
- Ref Model:参考模型,用于计算 KL 散度以防止生成结果偏离原始模型过多,参数固定,通常由 SFT 模型初始化。
- Critic Model:价值模型,估算状态或动作的价值,参与训练并更新参数,通常由训练好的 RM 初始化。
- Reward Model:奖励模型,提供对生成回答的奖励评分,参数固定,即上一步训练完成的 RM。
这四个模型协同工作,通过强化学习机制持续优化 LLM 的输出质量,使其更符合人类偏好。
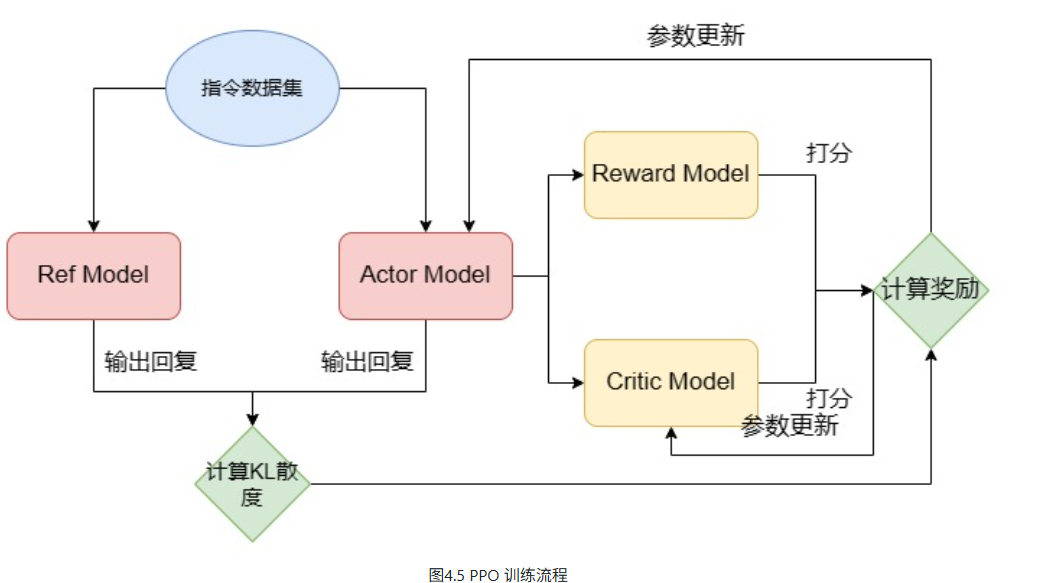

在上述过程中,因为要使用到四个模型,显存占用会数倍于 SFT。例如,如果我们 RM 和 LLM 都是用 7B 的体量,PPO 过程中大概需要 240G(4张 80G A100,每张卡占用 60G)显存来进行模型加载。那么,为什么我们需要足足四个模型呢?Actor Model 和 Critic Model 较为容易理解,而之所以我们还需要保持原参数不更新的 Ref Model 和 Reward Model,是为了限制模型的更新不要过于偏离原模型以至于丢失了 Pretrain 和 SFT 赋予的能力。
当然,如此大的资源占用和复杂的训练过程,使 RLHF 成为一个门槛非常高的阶段。也有学者从监督学习的思路出发,提出了 DPO(Direct Preference Optimization,直接偏好优化),可以低门槛平替 RLHF。DPO 的核心思路是,将 RLHF 的强化学习问题转化为监督学习来直接学习人类偏好。DPO 通过使用奖励函数和最优策略间的映射,展示了约束奖励最大化问题完全可以通过单阶段策略训练进行优化,也就是说,通过学习 DPO 所提出的优化目标,可以直接学习人类偏好,而无需再训练 RM 以及进行强化学习。由于直接使用监督学习进行训练,DPO 只需要两个 LLM 即可完成训练,且训练过程相较 PPO 简单很多,是 RLHF 更简单易用的平替版本。DPO 所提出的优化目标为什么能够直接学习人类偏好,作者通过一系列的数学推导完成了证明,感兴趣的读者可以下来进一步阅读,此处就不再赘述了。
参考资料
[1] Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul Christiano, Jan Leike, Ryan Lowe. (2022). Training language models to follow instructions with human feedback. arXiv preprint arXiv:2203.02155.
[2] Jacob Devlin, Ming-Wei Chang, Kenton Lee, Kristina Toutanova. (2019). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv preprint arXiv:1810.04805.
[3] Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B. Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, Dario Amodei. (2020). Scaling Laws for Neural Language Models. arXiv preprint arXiv:2001.08361.
[4] Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, Tom Hennigan, Eric Noland, Katie Millican, George van den Driessche, Bogdan Damoc, Aurelia Guy, Simon Osindero, Karen Simonyan, Erich Elsen, Jack W. Rae, Oriol Vinyals, Laurent Sifre. (2022). Training Compute-Optimal Large Language Models. arXiv preprint arXiv:2203.15556.
[5] Qi Wang, Yiyuan Yang, Ji Jiang. (2022). Easy RL: Reinforcement Learning Tutorial . Beijing: Posts & Telecom Press. ISBN: 9787115584700. https://github.com/datawhalechina/easy-rl
[6] Rafael Rafailov, Archit Sharma, Eric Mitchell, Stefano Ermon, Christopher D. Manning, Chelsea Finn. (2024). Direct Preference Optimization: Your Language Model is Secretly a Reward Model. arXiv preprint arXiv:2305.18290.
[7] Wayne Xin Zhao, Kun Zhou, Junyi Li, Tianyi Tang, Xiaolei Wang, Yupeng Hou, Yingqian Min, Beichen Zhang, Junjie Zhang, Zican Dong, Yifan Du, Chen Yang, Yushuo Chen, Zhipeng Chen, Jinhao Jiang, Ruiyang Ren, Yifan Li, Xinyu Tang, Zikang Liu, Peiyu Liu, Jian-Yun Nie, Ji-Rong Wen. (2025). A Survey of Large Language Models. arXiv preprint arXiv:2303.18223.