java面试Day2 | mysql优化、索引、事务、并发事务、MVCC、主从同步、分库分表
目录
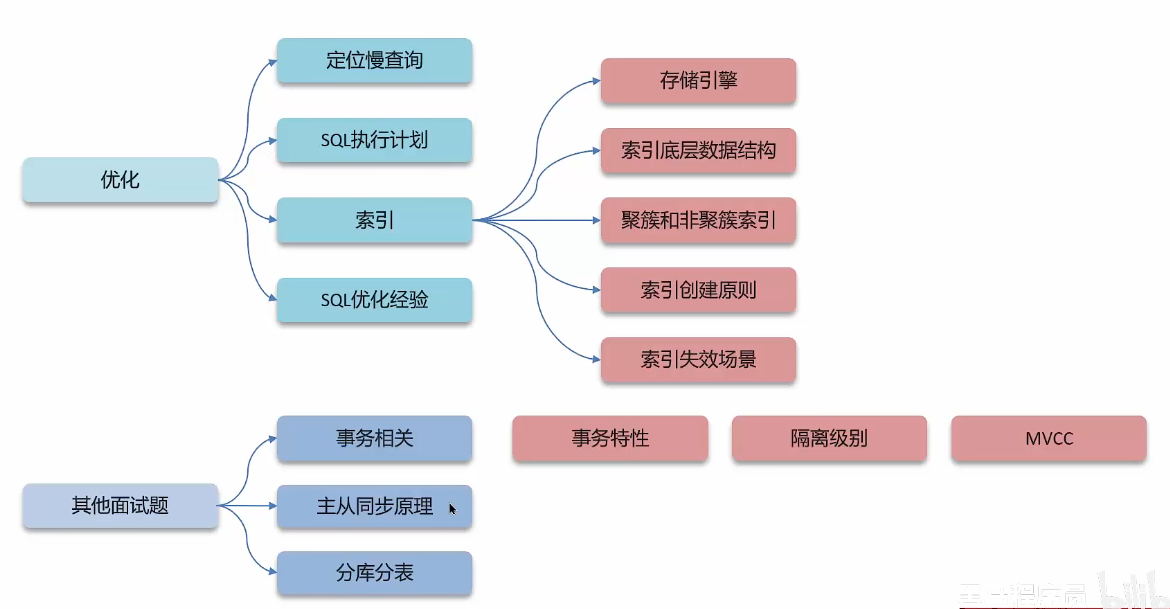
MySQL优化
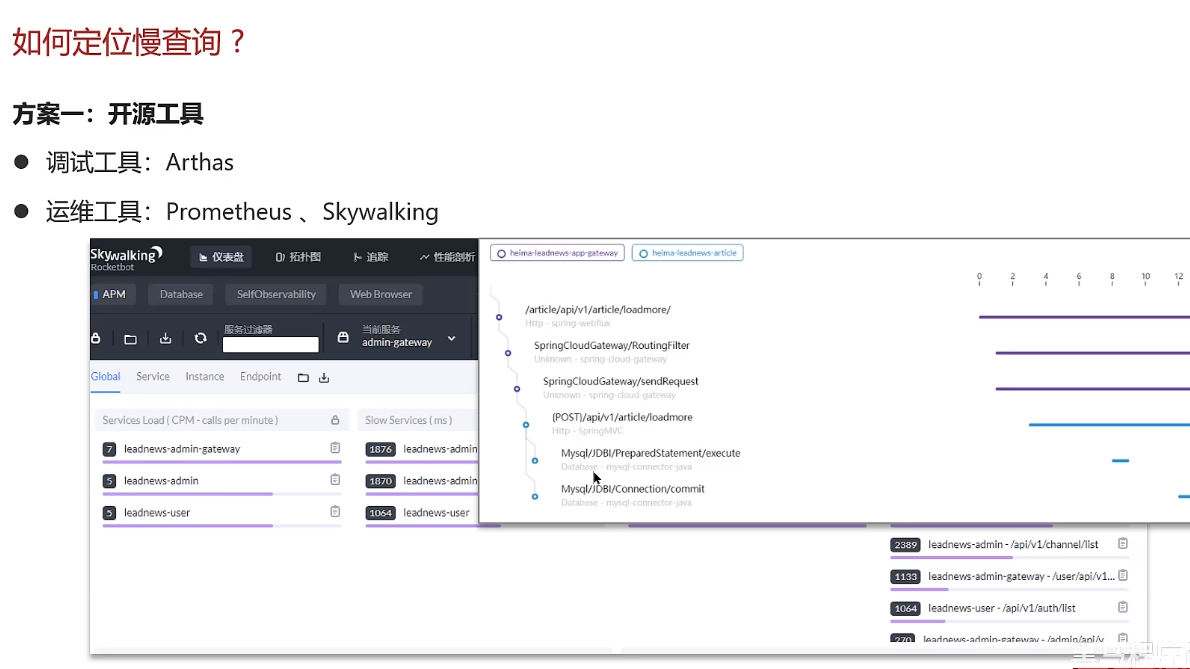
如何定位慢查询
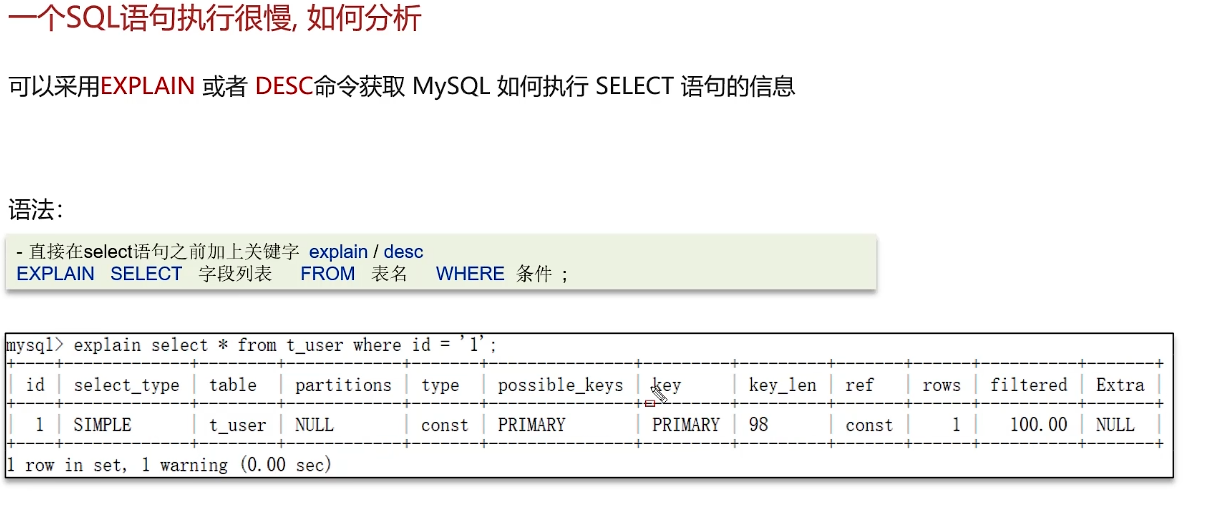
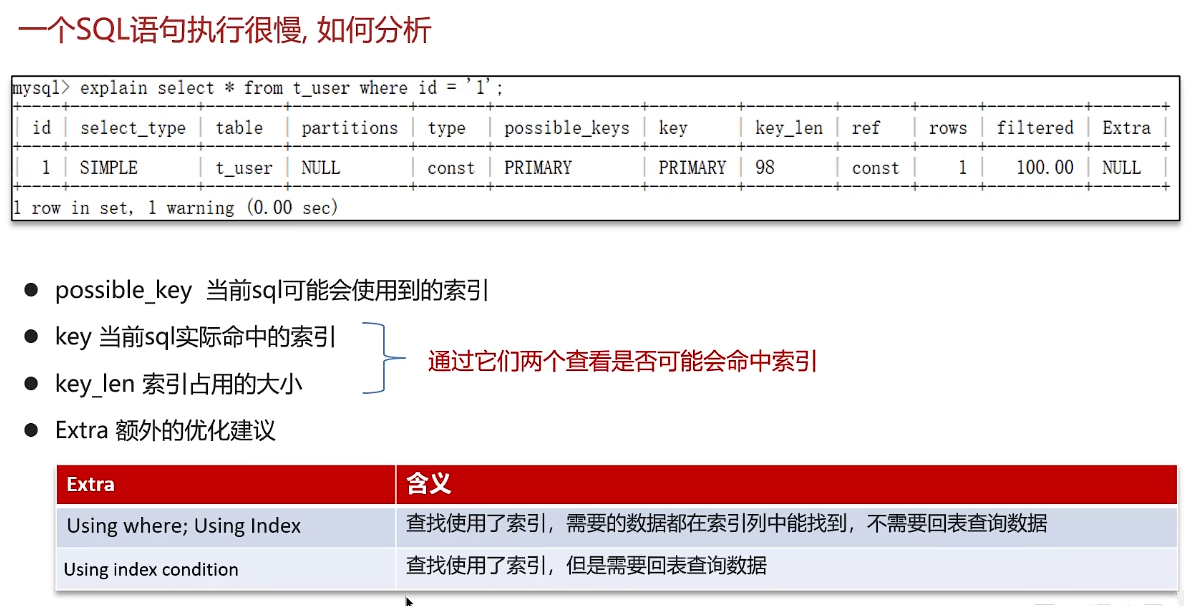
sql语句执行的很慢,如何分析?
索引概念及索引底层数据结构
聚簇索引、非聚簇索引、回表查询
覆盖索引、超大分页优化
索引创建的原则
什么情况下索引会失效
谈一谈你对sql优化的经验
事务
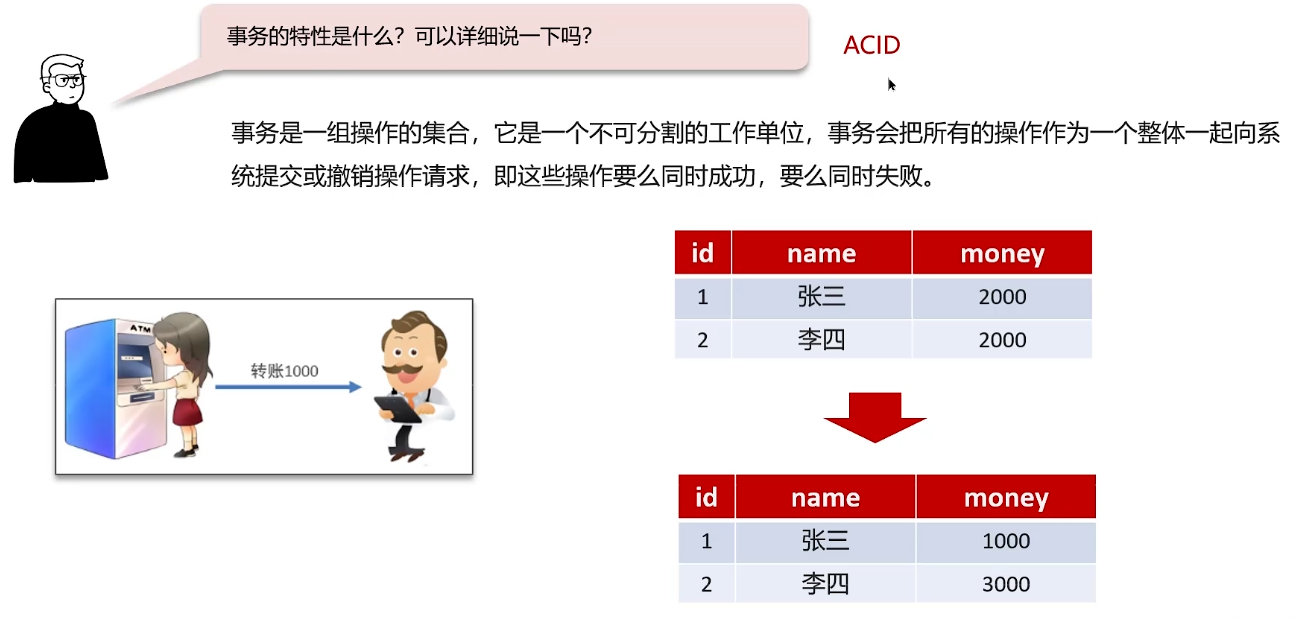
事务的特性
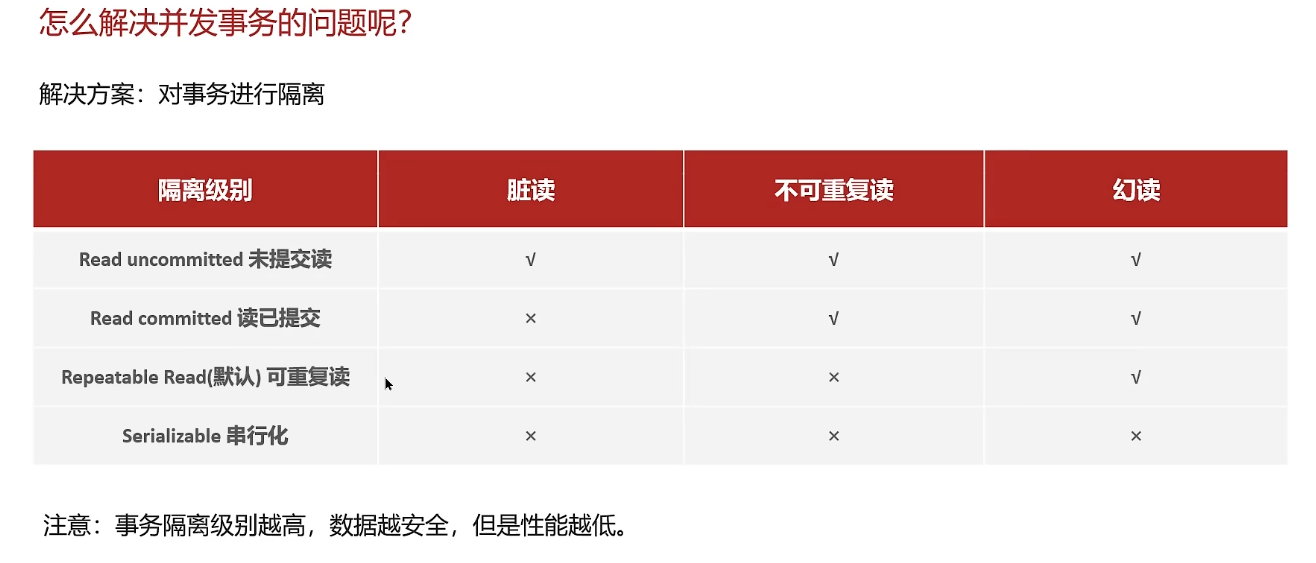
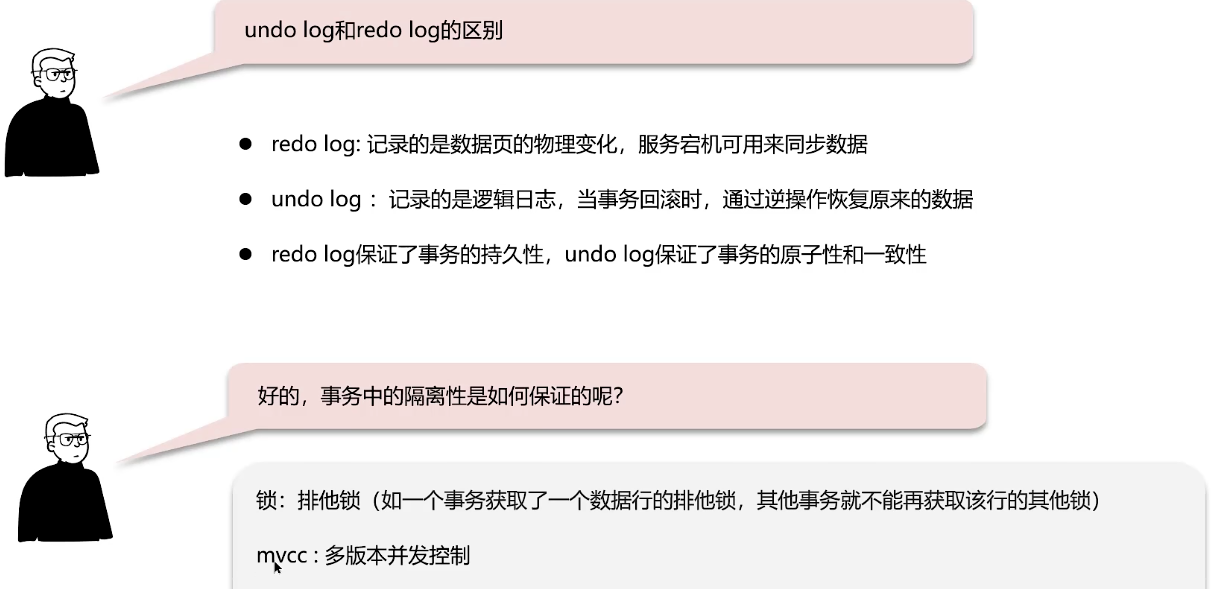
并发事务问题、隔离级别
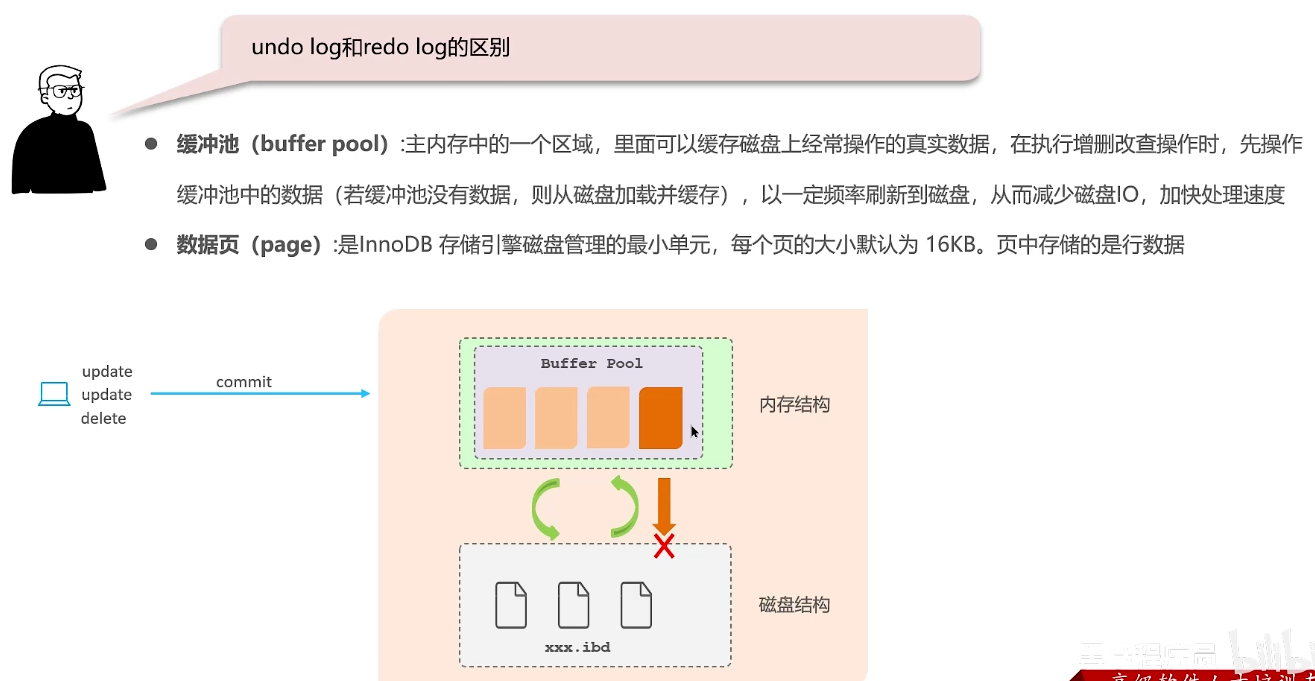
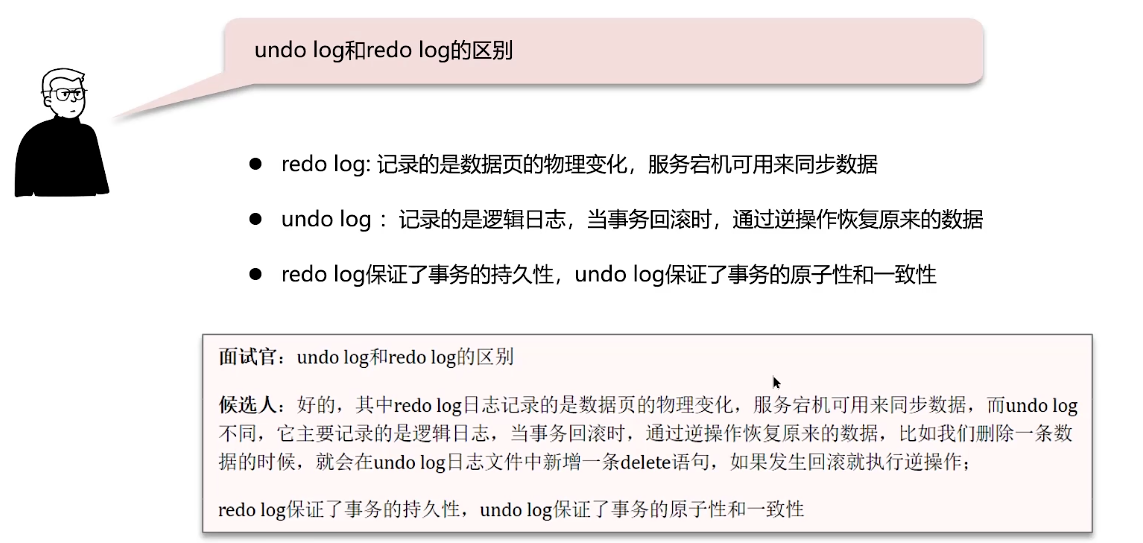
undo log 和 redo log 的区别
解释MVCC
MySQL主从同步原理
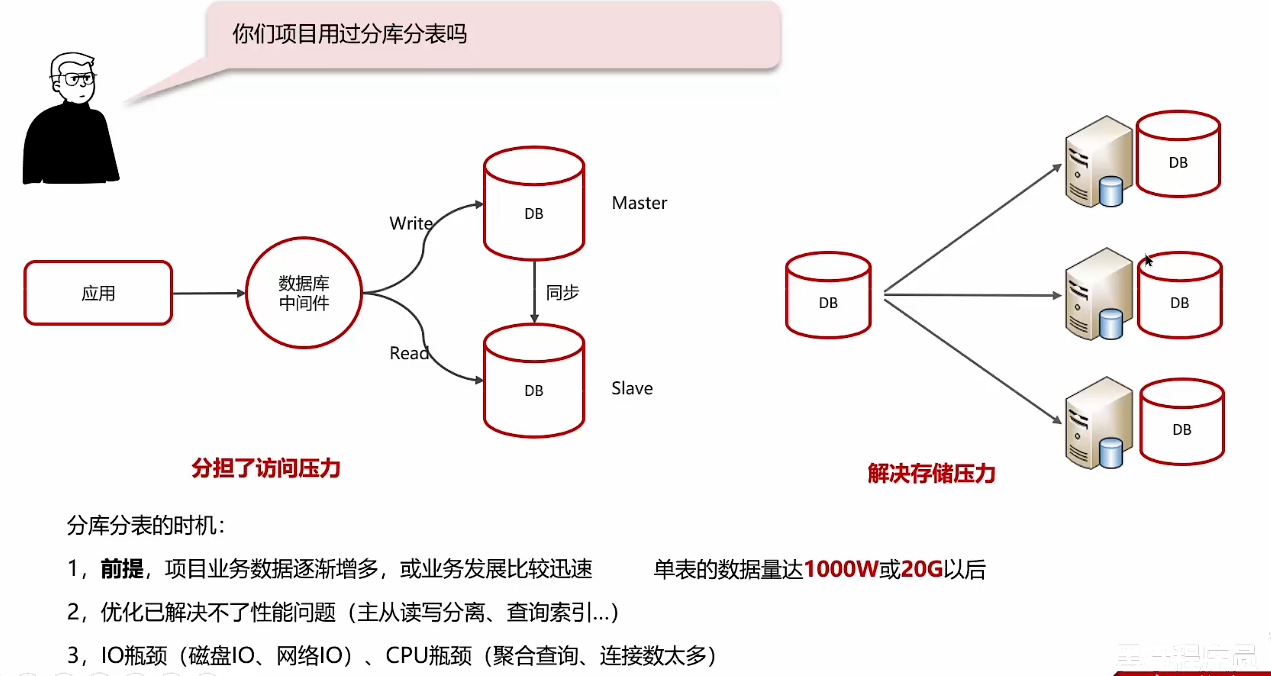
MySQL分库分表
补充:微服务是什么
一、微服务的核心特点(怎么判断一个架构是不是微服务?)
二、微服务 vs 传统 “单体架构”(为什么需要微服务?)
三、微服务的优势(为什么很多公司用它?)
四、微服务的挑战(不是所有项目都适合用!)
总结:微服务的本质是什么?
MySQL优化
如何定位慢查询



sql语句执行的很慢,如何分析?
聚合查询--新增临时表,多表查询--优化SQL语句结构,表数据量过大--添加索引,



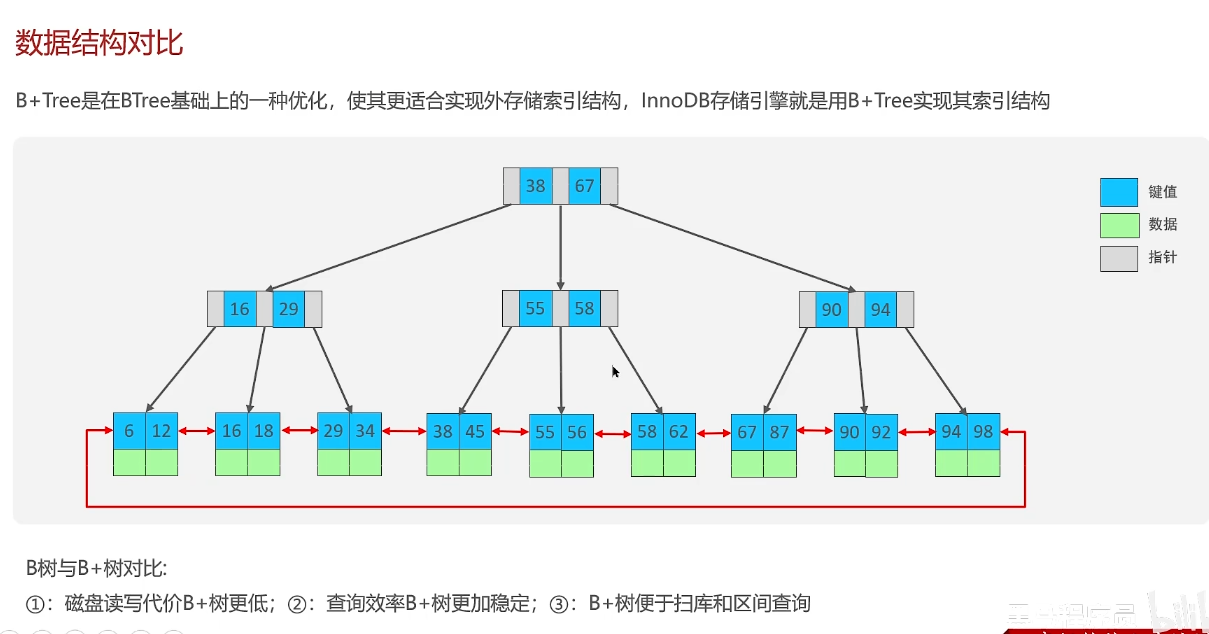
索引概念及索引底层数据结构
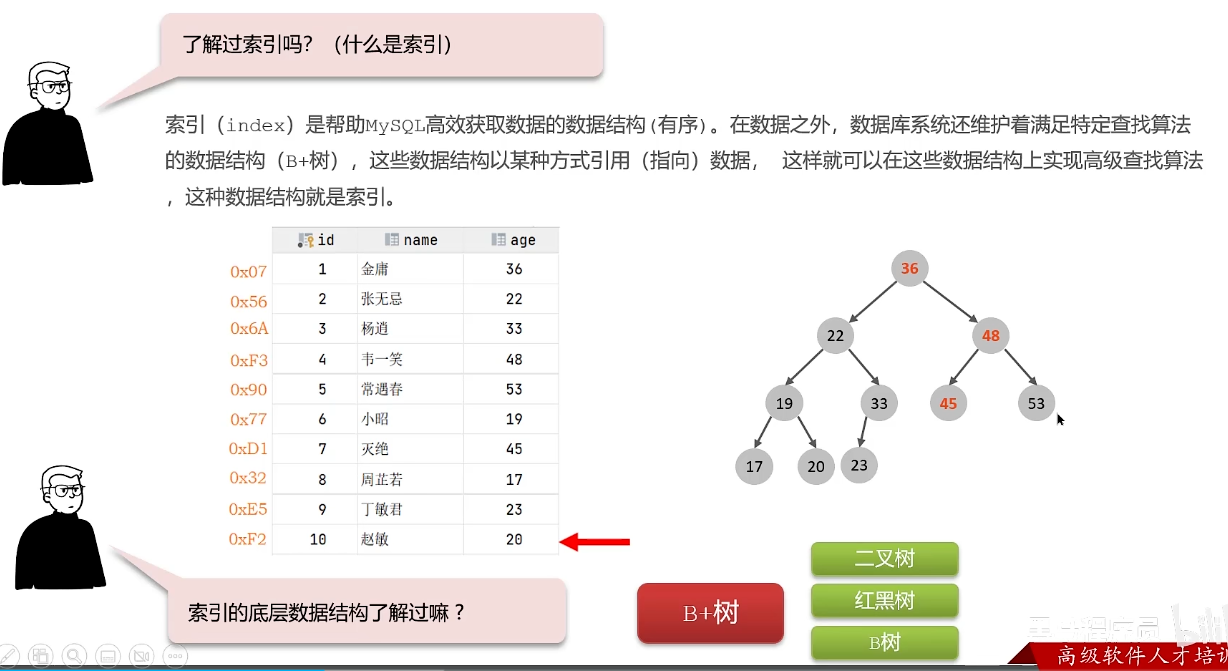
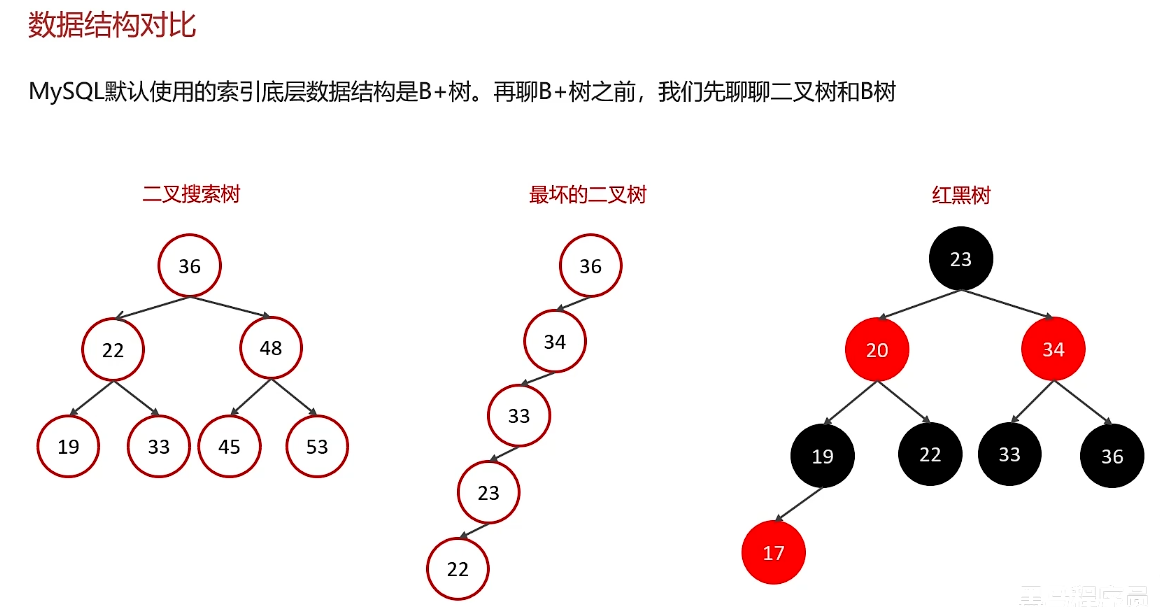
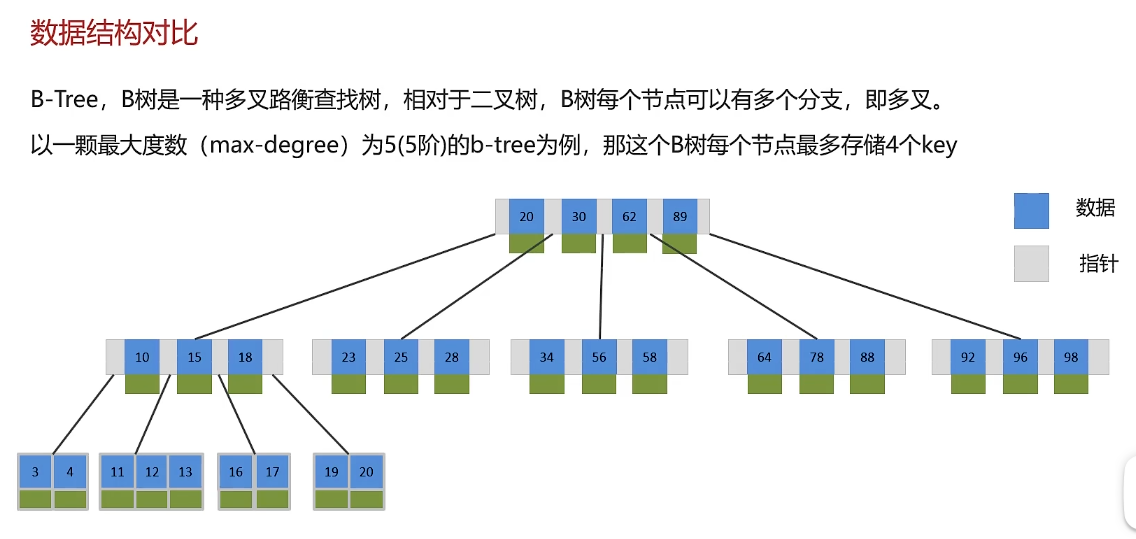
B+树:非叶子节点只存储指针,不存储数据,数据都在叶子节点


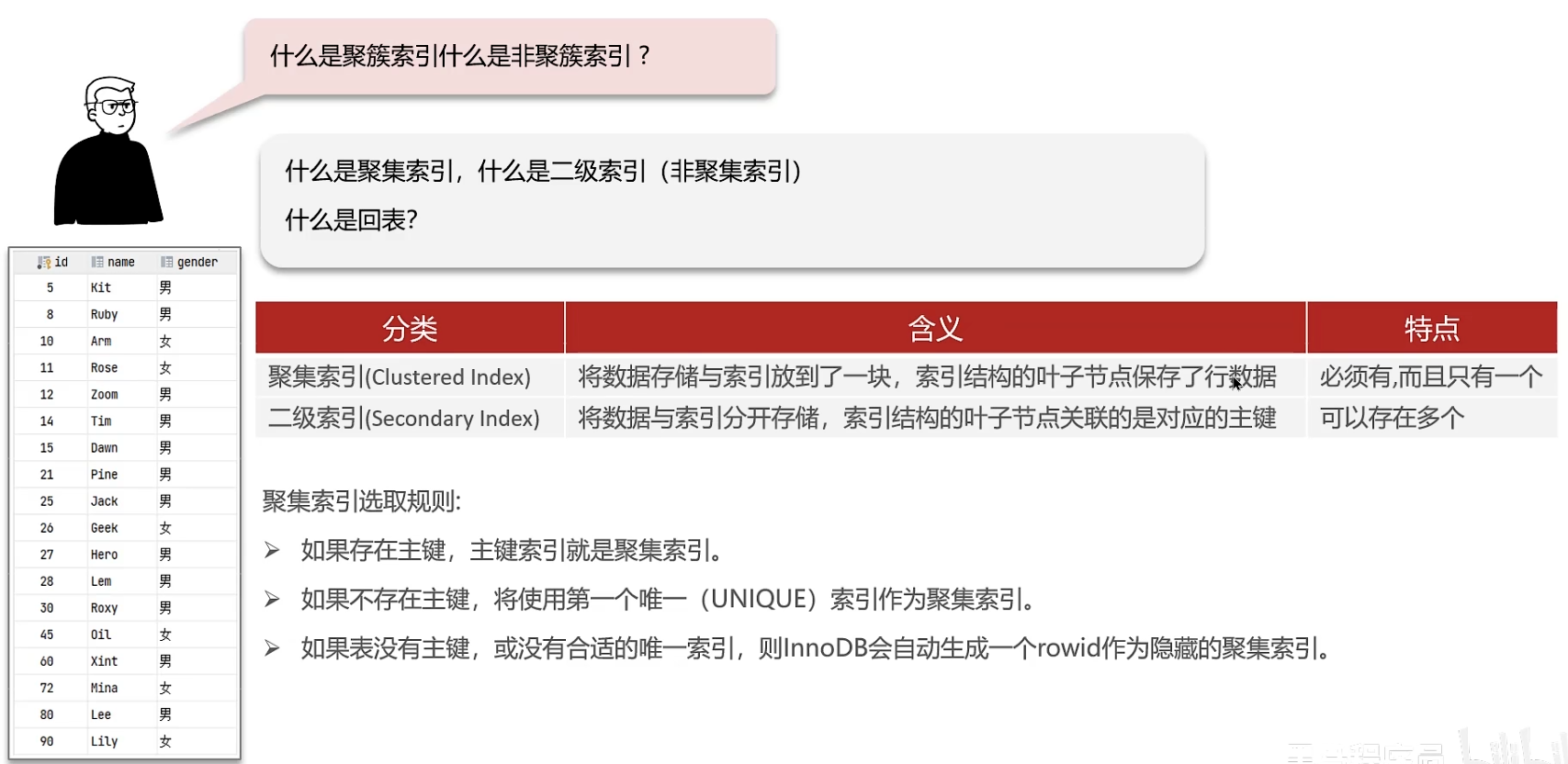
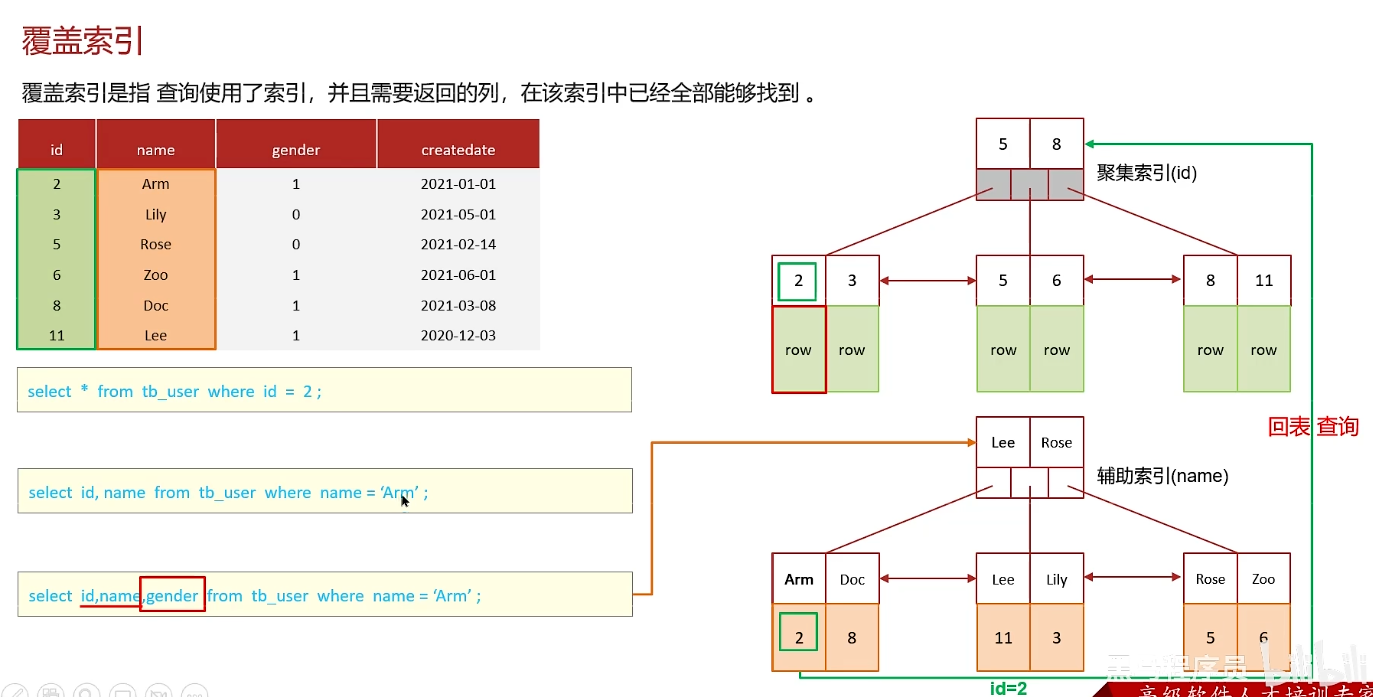
聚簇索引、非聚簇索引、回表查询
聚簇索引/聚集索引
非聚簇索引/二级索引
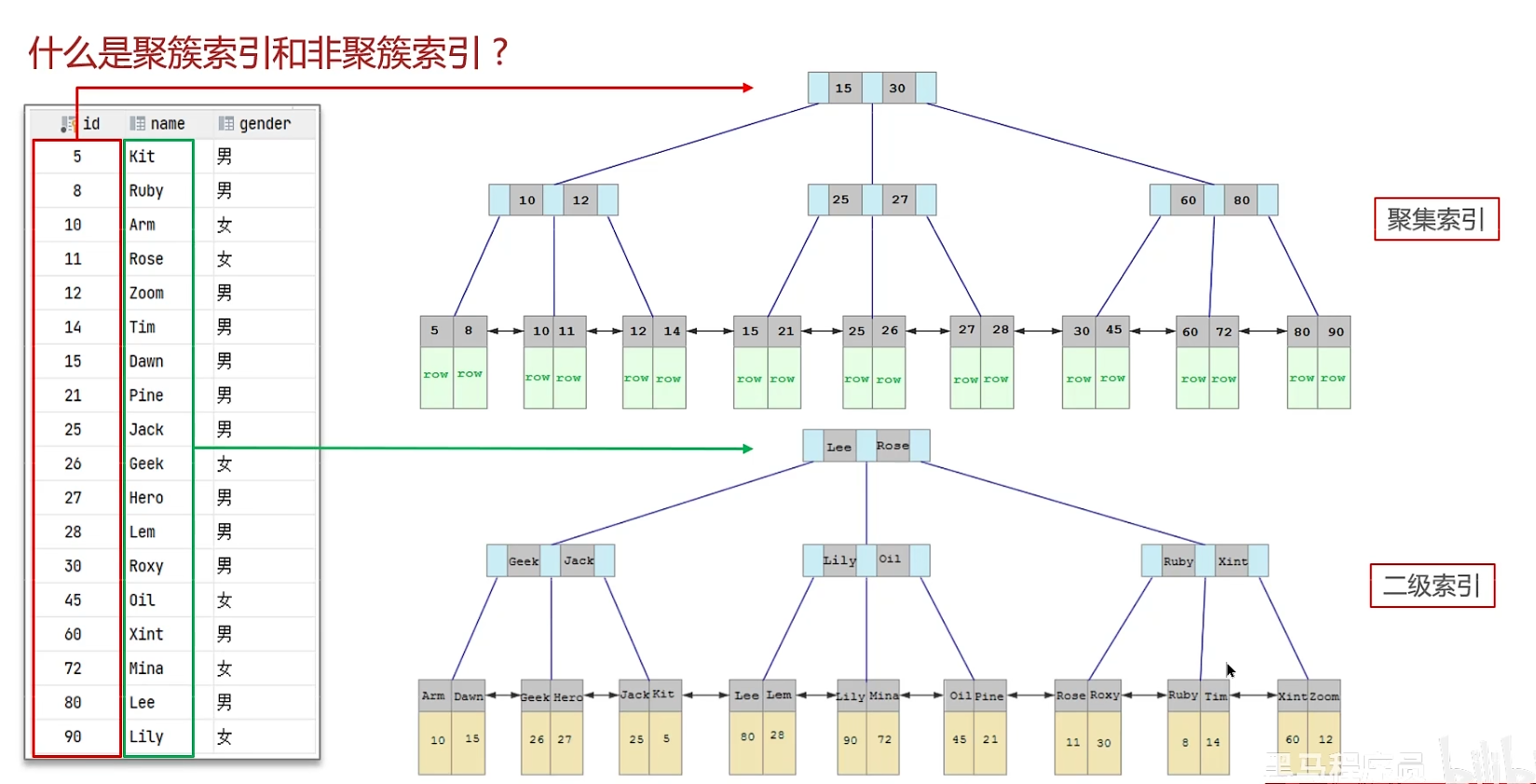
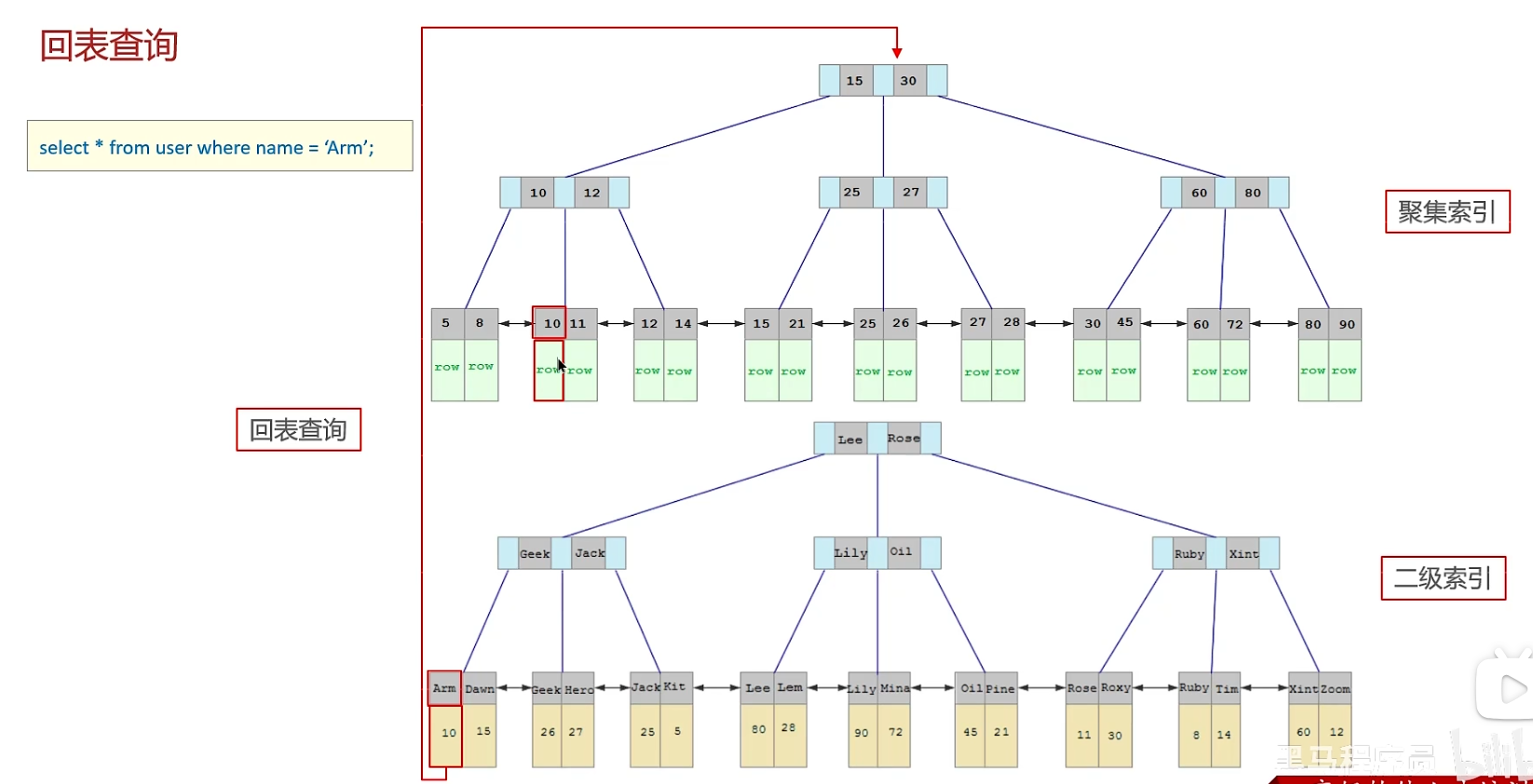
回表查询:先通过二级索引找到对应的主键值,在聚集索引找到主键值对应的一整行数据


覆盖索引、超大分页优化
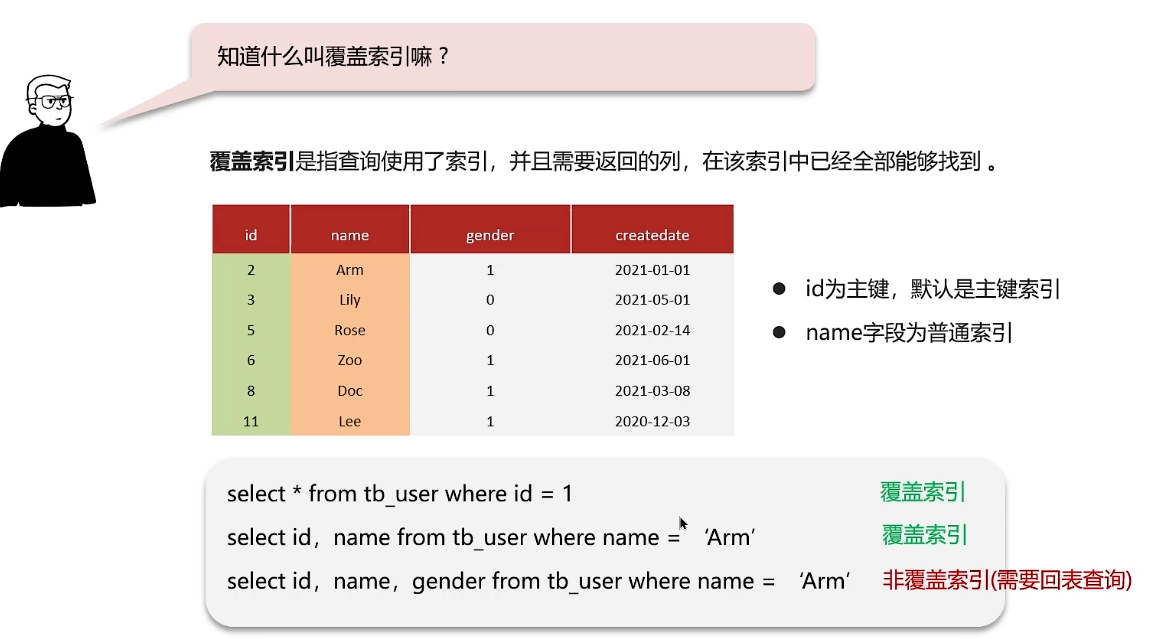
覆盖索引:查询使用了索引,并且需要返回的列,在该索引中已经全部都能找到
也就是查一次就能查到所有需要的信息的语句

select 列名 from 表名 limit [偏移量,] 行数
-- 跳过前 5 条记录,返回接下来的 10 条记录(即第 6-15 条)
SELECT * FROM users LIMIT 5, 10;
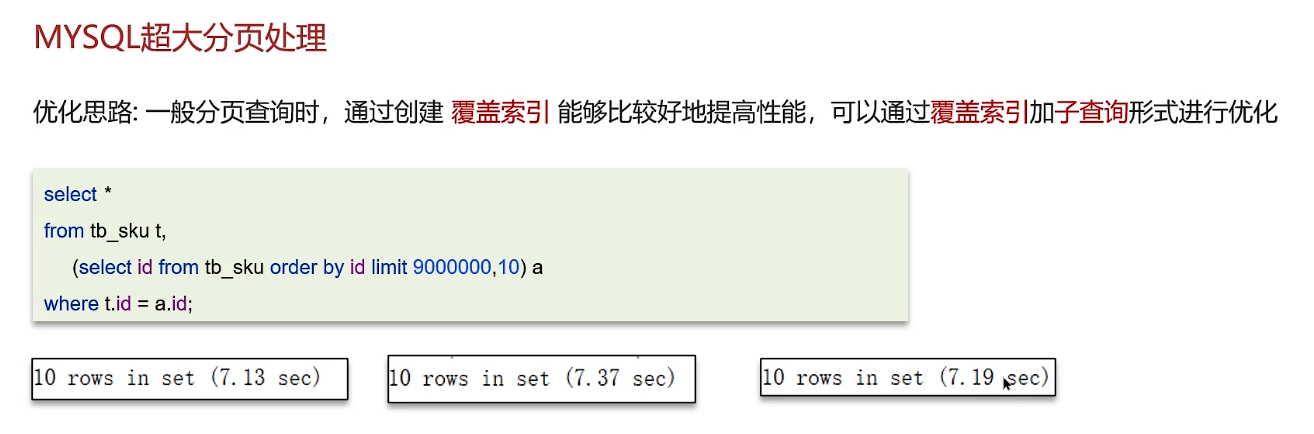
先分页查询获取表中的id,并且对表的id进行排序,就能筛选出分页后的id集合;
因为id是覆盖索引,所以操作id时效率是相对较高的;
最后通过id集合去原来的表中做关联查询,效率就得到提升了

索引创建的原则






复合索引:数据库中基于表中多个列创建的索引,也称为联合索引或组合索引。它与仅基于单个列的单列索引不同,复合索引同时使用多个字段作为索引键,以优化多列条件查询的性能。
复合索引由表中的2个或多个列组合而成,如:
-- 为 users 表的 name 和 age 列创建复合索引
CREATE INDEX idx_name_age ON users(name, age);复合索引的查询效率依赖于查询条件是否匹配索引的最左侧列。例如,对于 (name, age) 索引:
- 能有效优化的查询:
WHERE name = '张三' -- 匹配最左列 WHERE name = '张三' AND age = 25 -- 匹配全部列 - 无法有效利用索引的查询:
WHERE age = 25 -- 未使用最左列 name WHERE age = 25 AND name = '张三' -- 条件顺序不影响,但需包含最左列
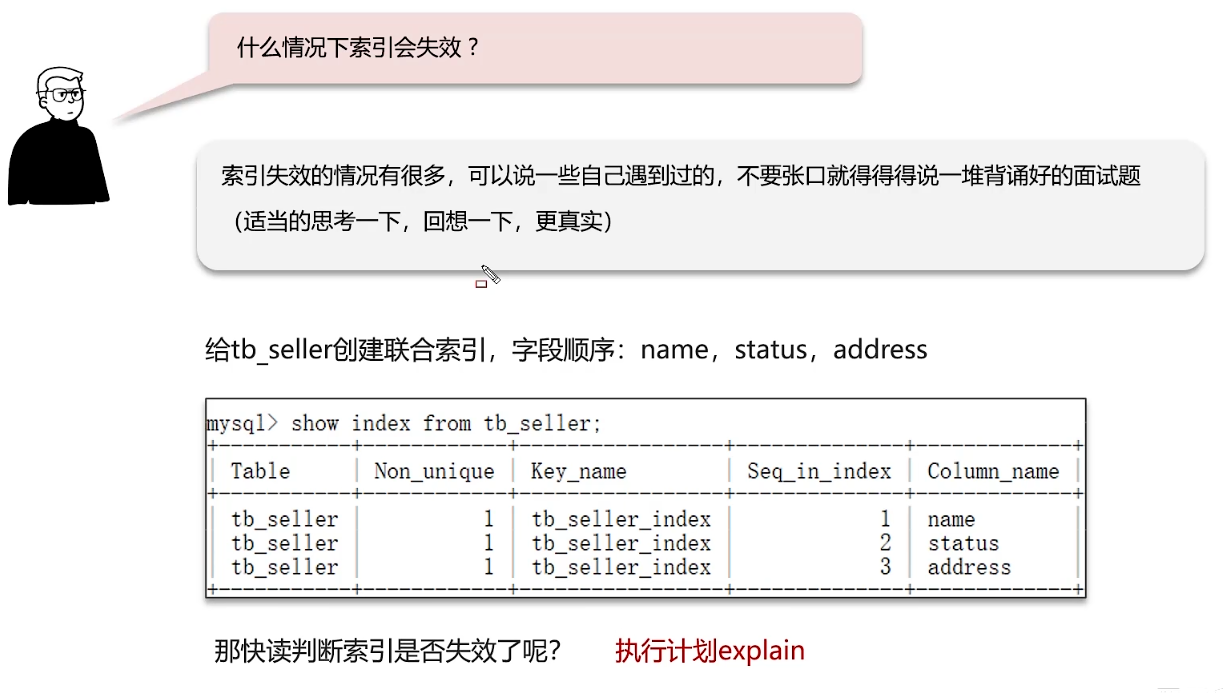
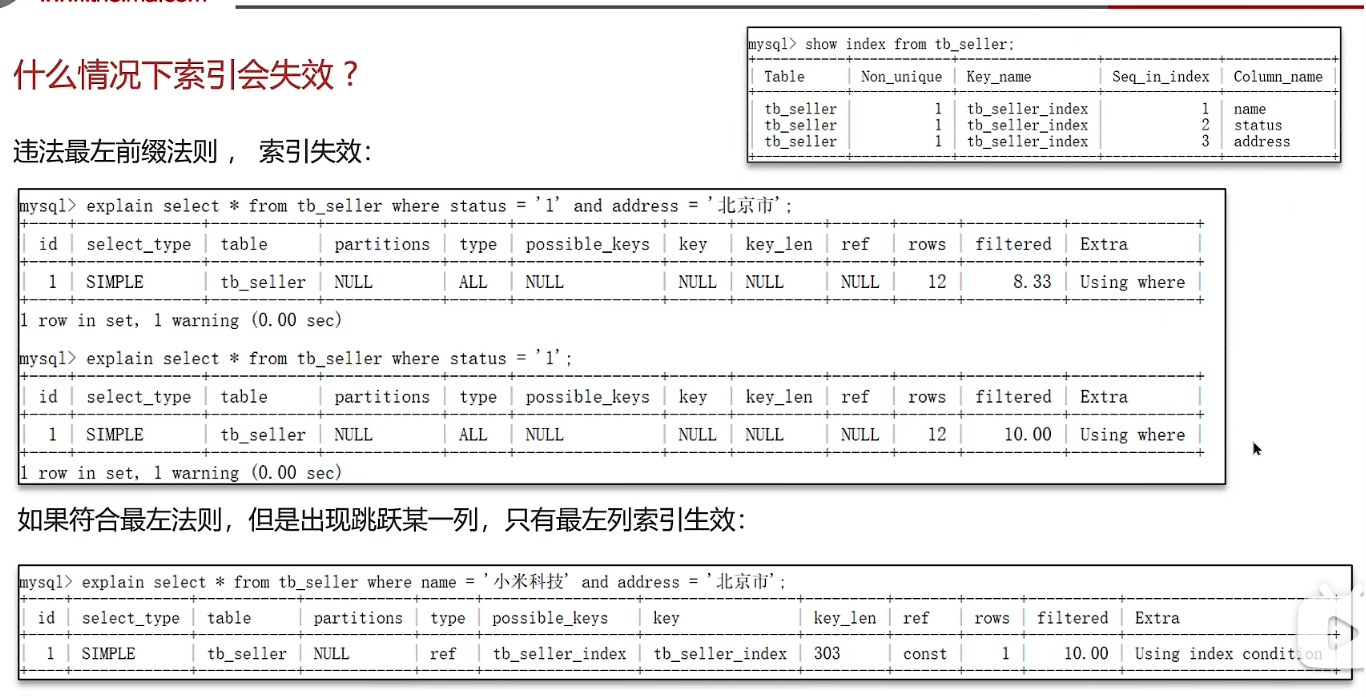
什么情况下索引会失效


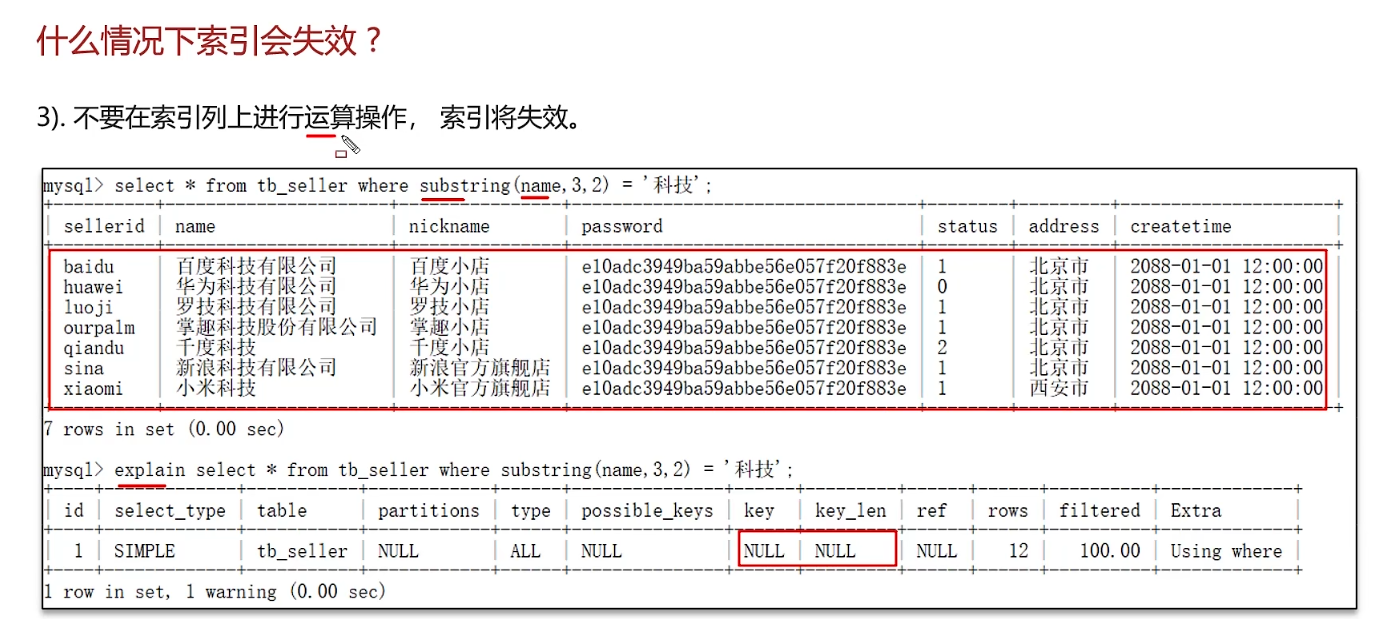

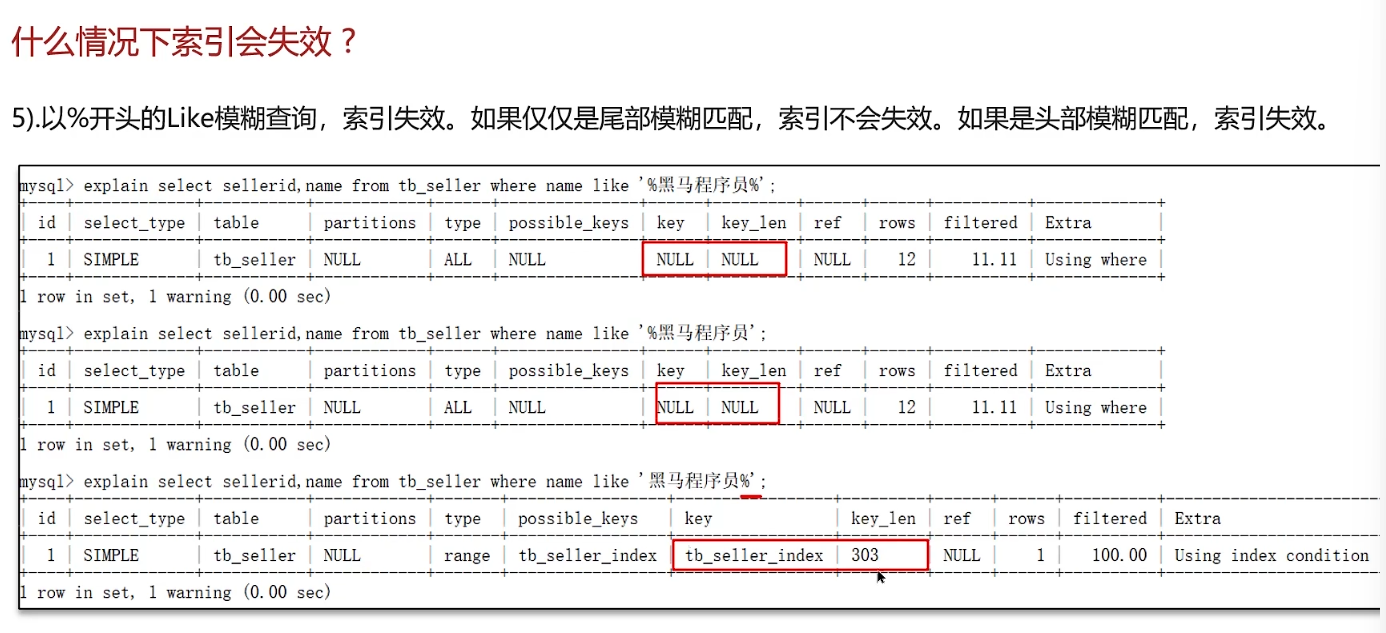


谈一谈你对sql优化的经验


如上面例子中,把小表放到外面,只需要进行3次数据库连接,所以外层用小循环更好
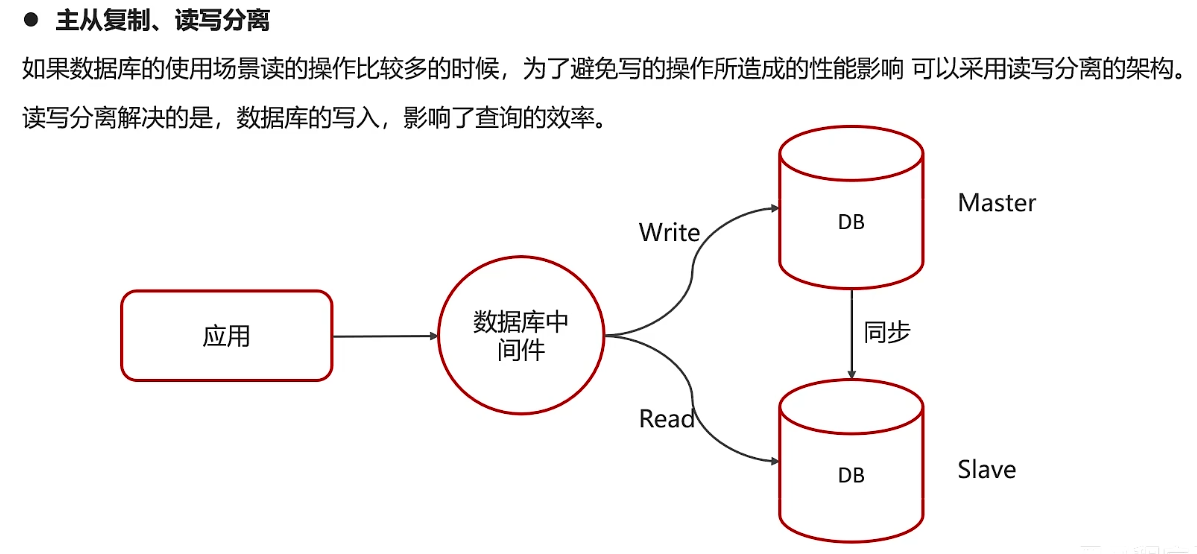
生产环境下一般都会搭建主从


事务
事务的特性


并发事务问题、隔离级别

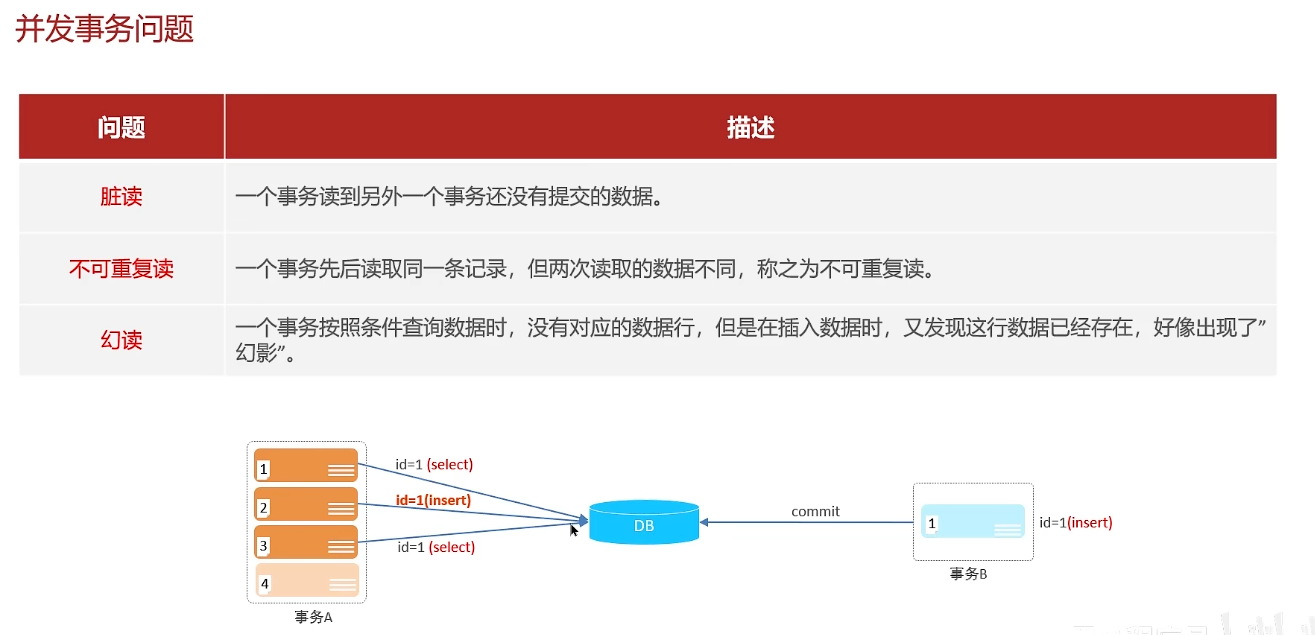
并发事务带来问题:脏读、不可重复读、幻读
解决问题:对事务进行隔离


undo log 和 redo log 的区别
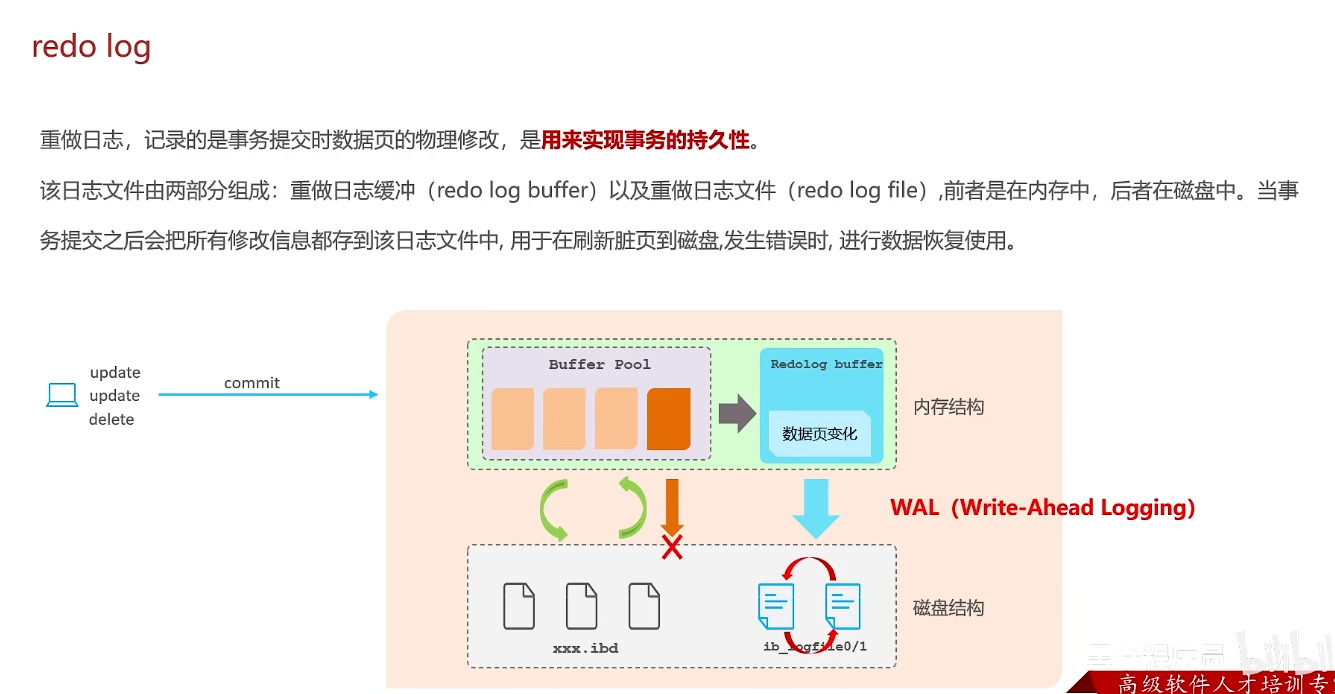
当刷新脏页数据到磁盘时,如果发生错误,就可以使用redo log进行数据恢复,可以实现数据持久性。
redo log 记录物理日志,保证持久性D
undo log 记录逻辑日志,保证原子性、一致性AC

解释MVCC
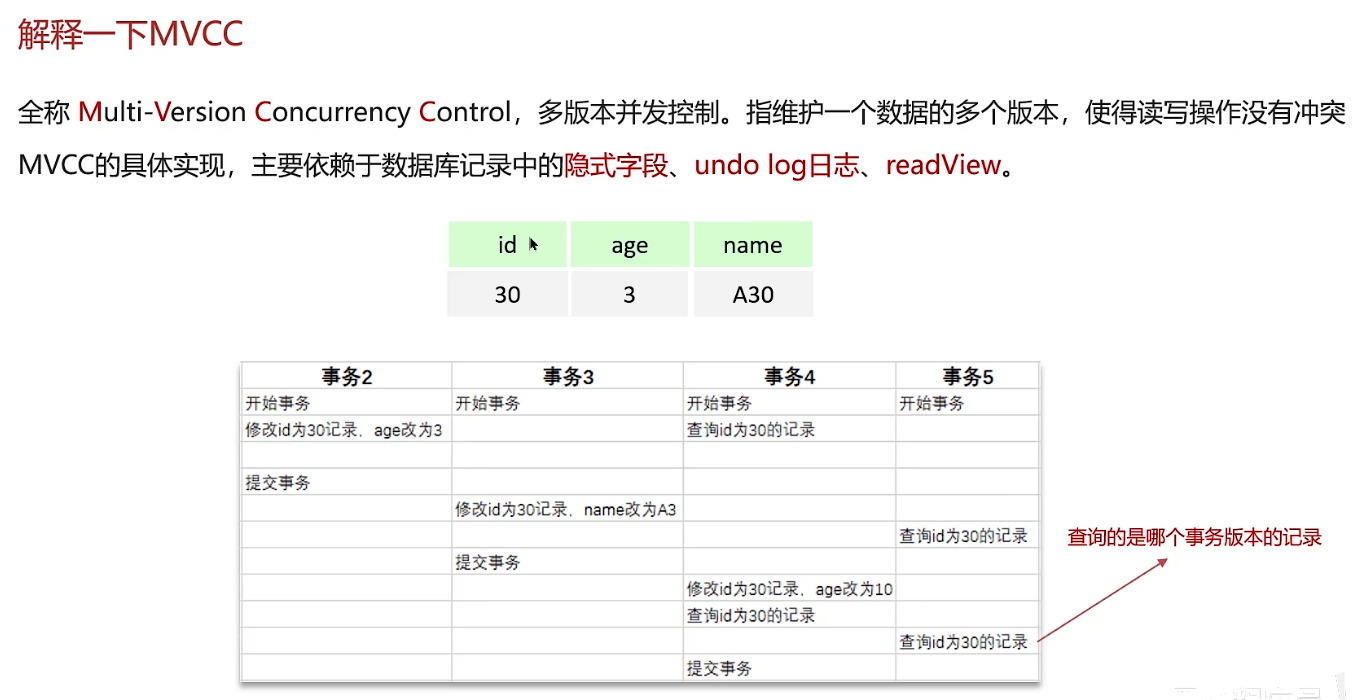
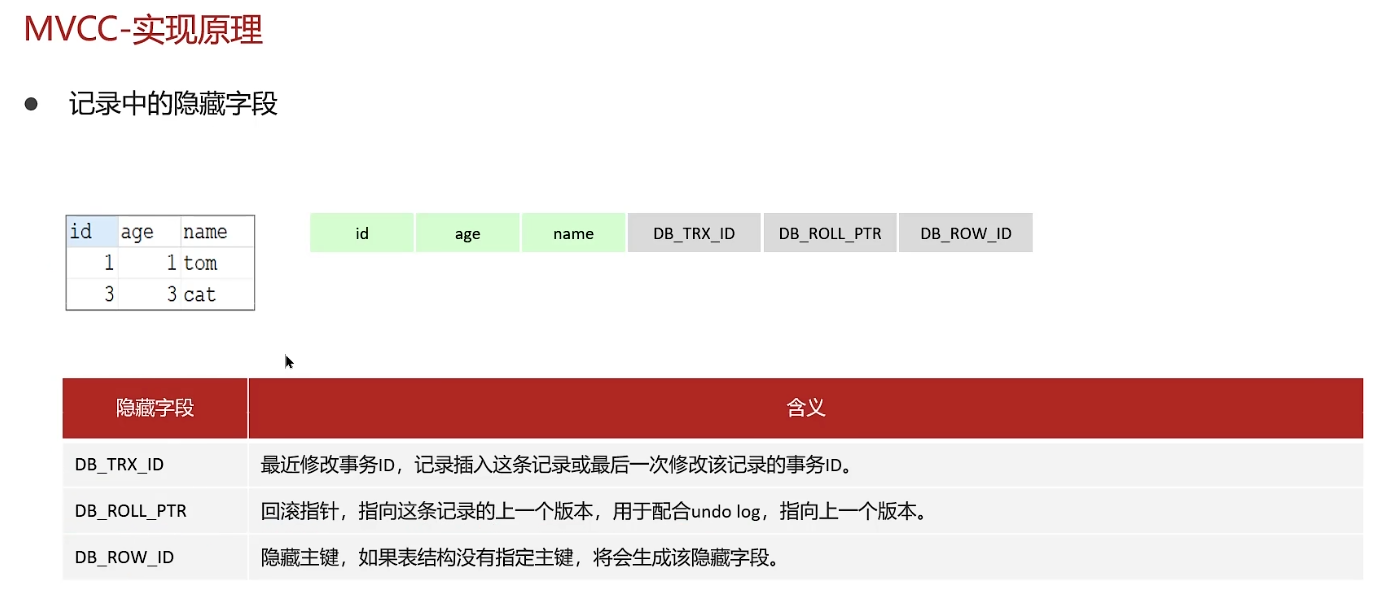

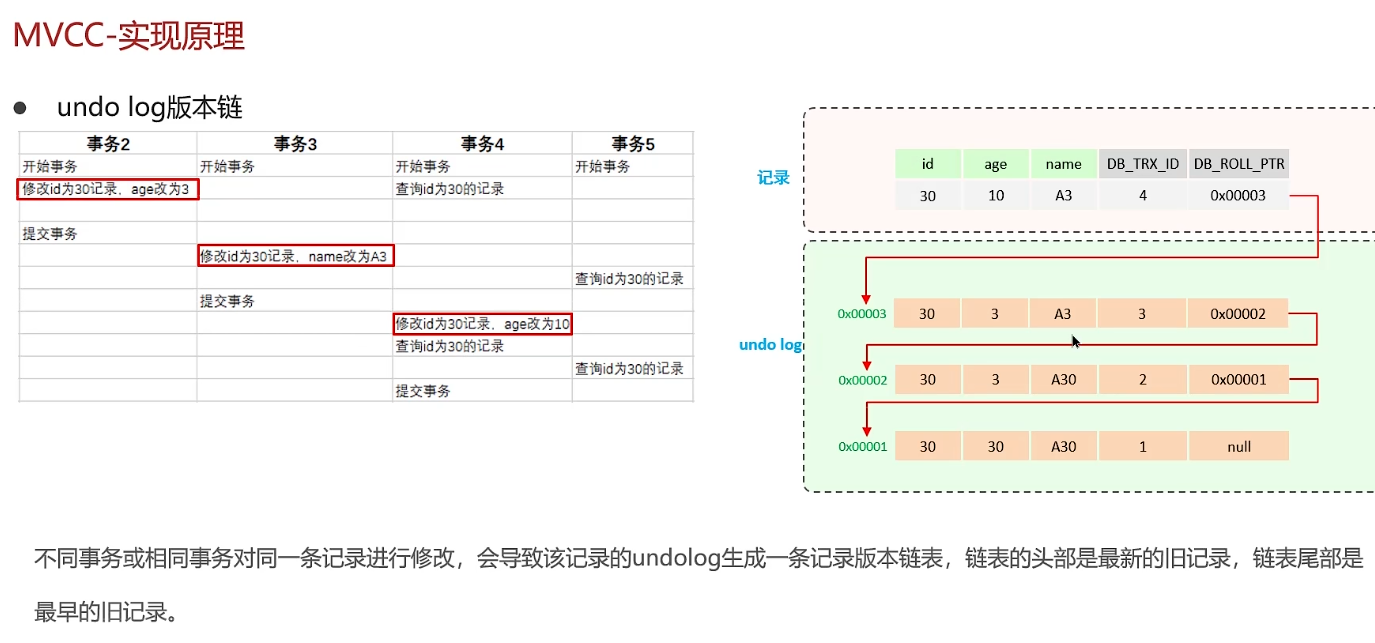
不同事务或相同事务对同一条记录进行修改,会导致该记录的undolog生成一条记录版本链表,链表的头部是最新的旧记录,链表尾部是最早的旧记录
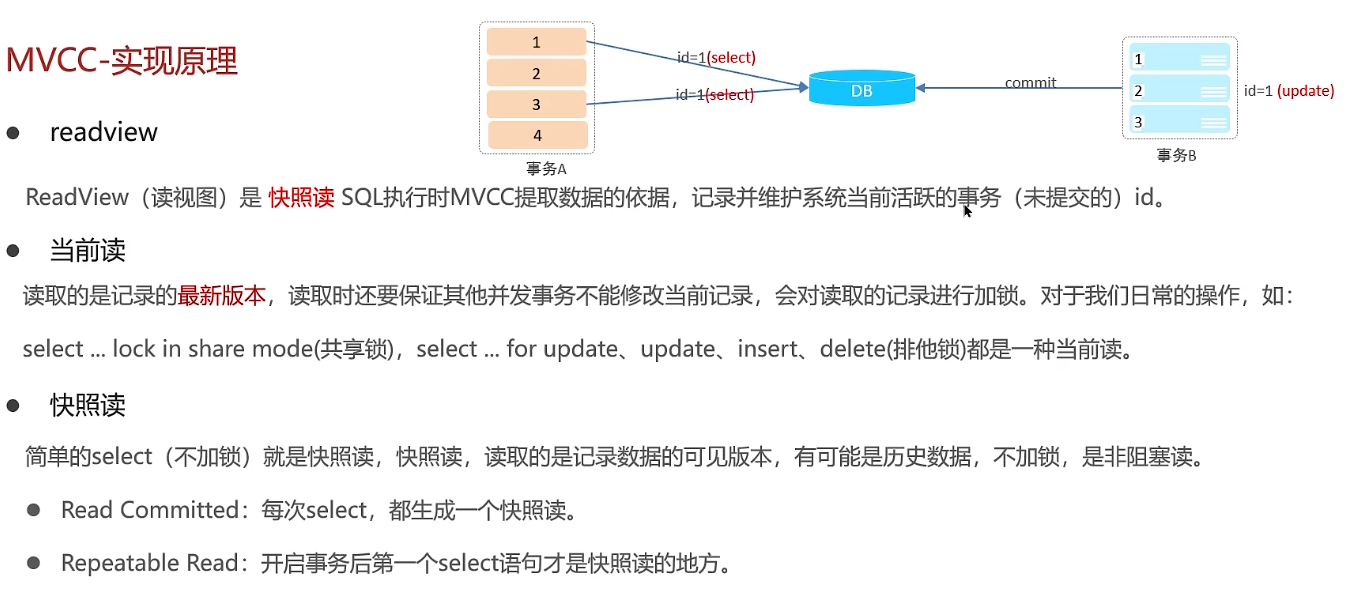
当前读一定会读到最新的数据
快照读:RC可以读到其他事务提交之后的数据,RR解决了可重复读的问题,同一个事务内两次读的一样
活跃的事务:未提交的事务
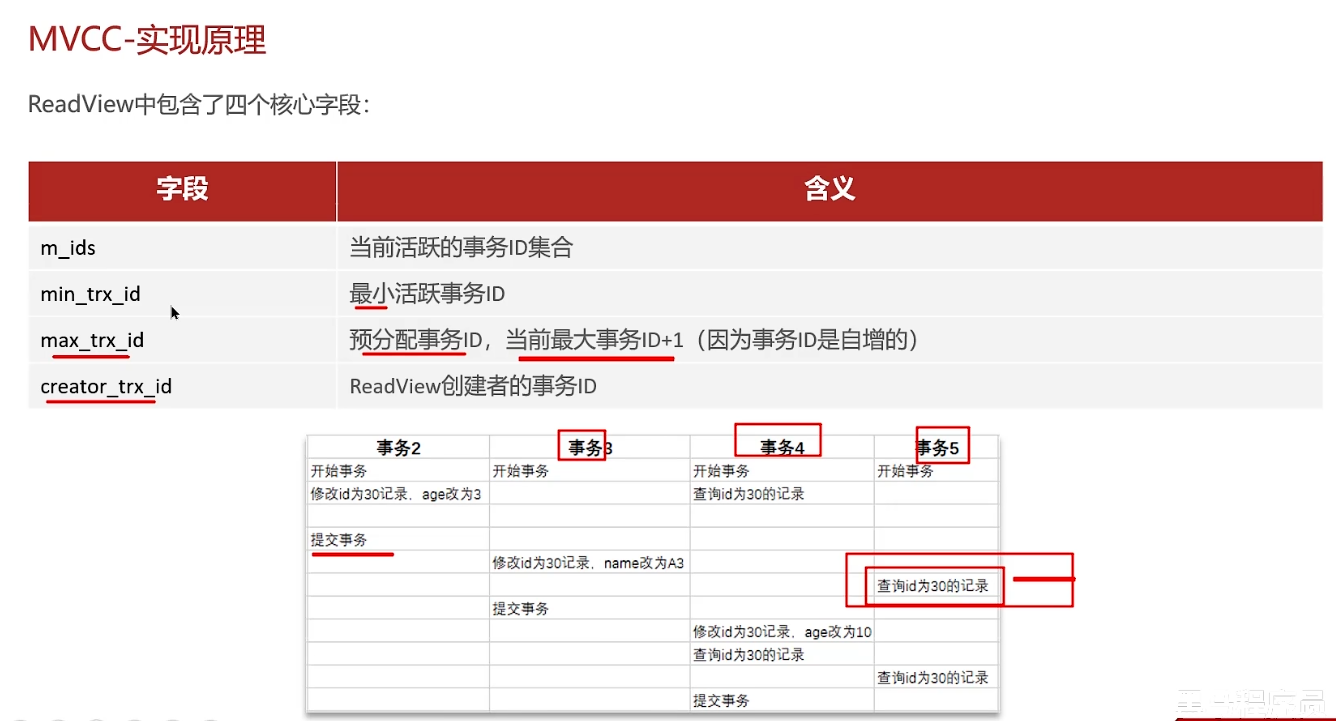

下面是在Read Committed级别下:在事务中每一次执行快照读时生成ReadView
下面是当前第一个ReadView,可以读取到的是事务2提交之后的数据
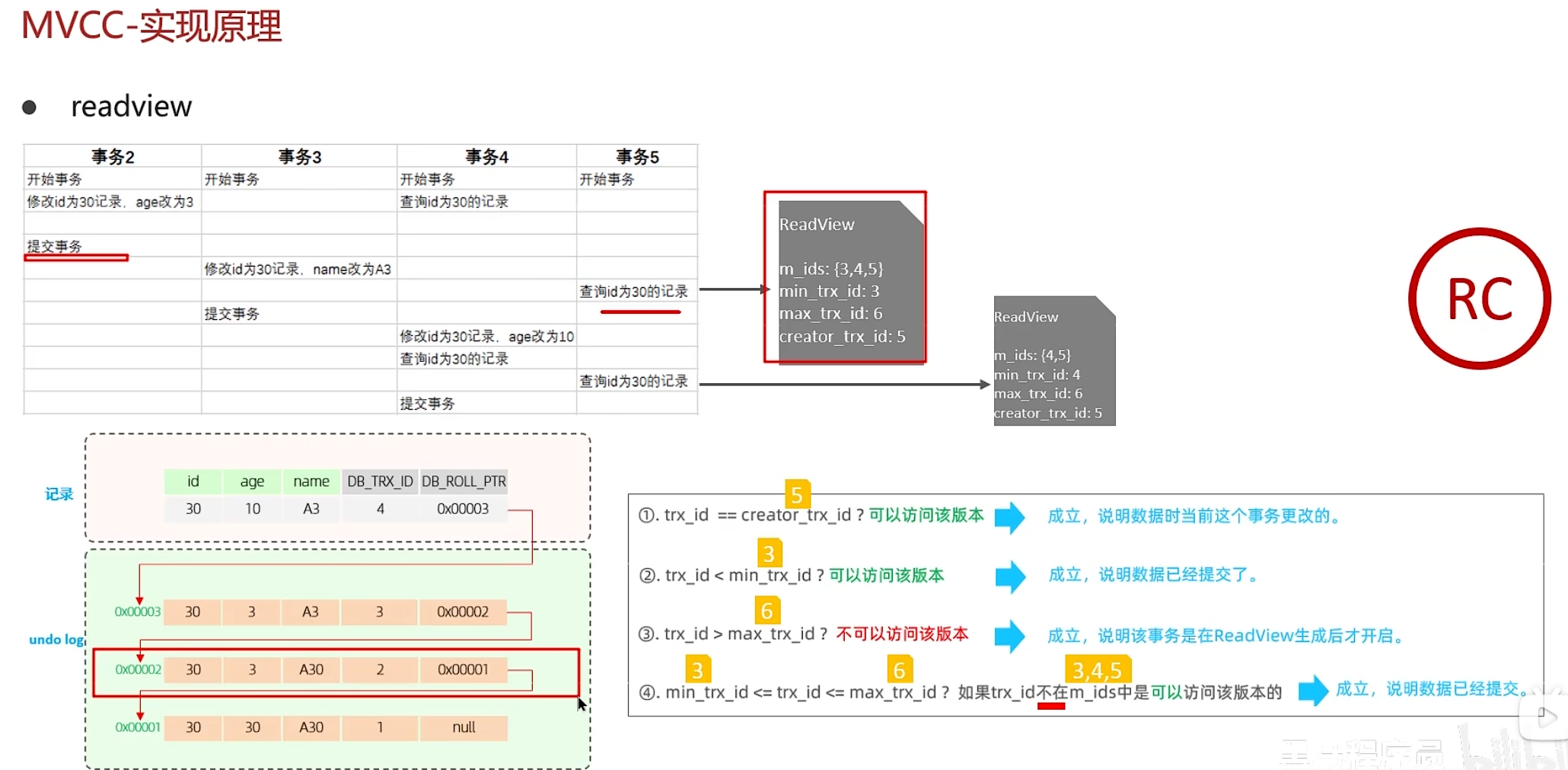
下面是第二次读,读到的是事务3提交之后的数据
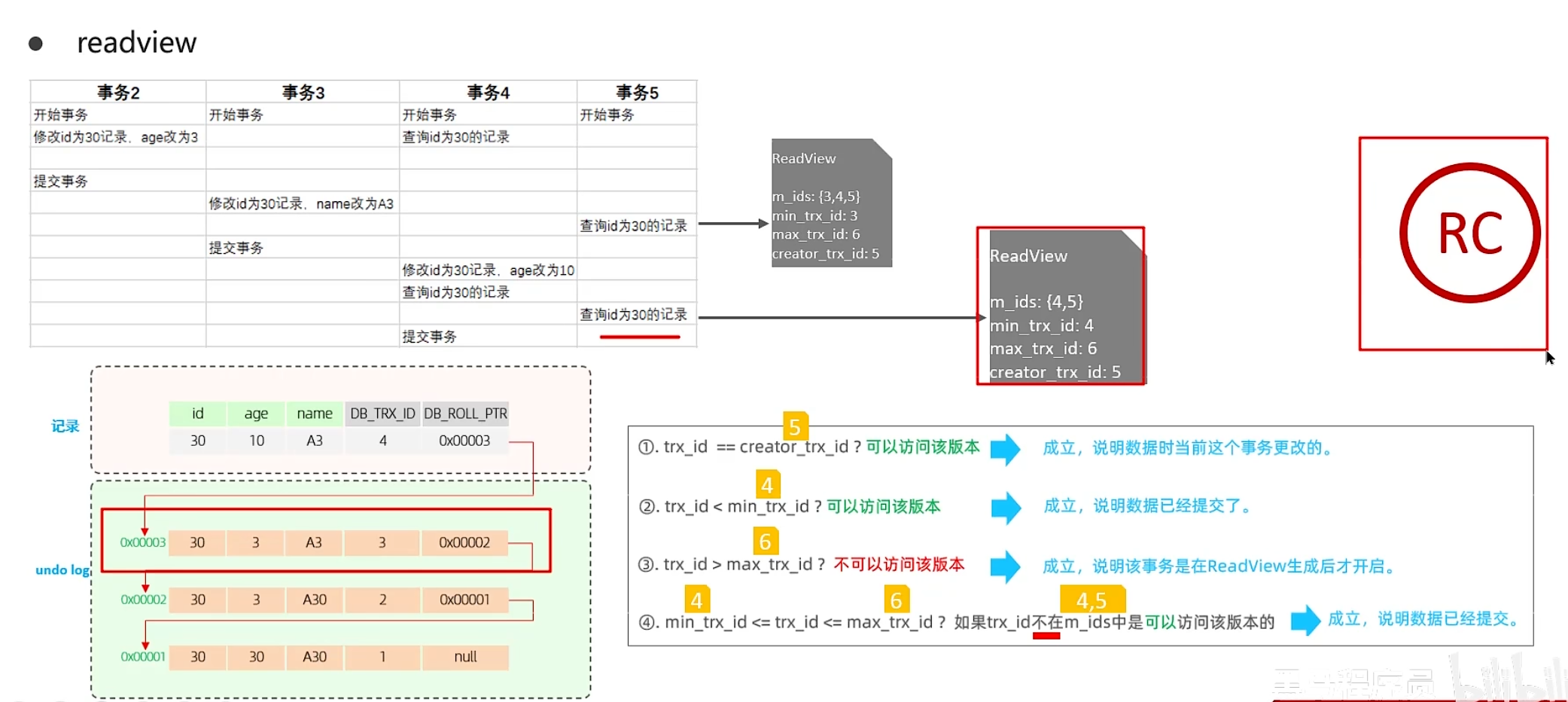
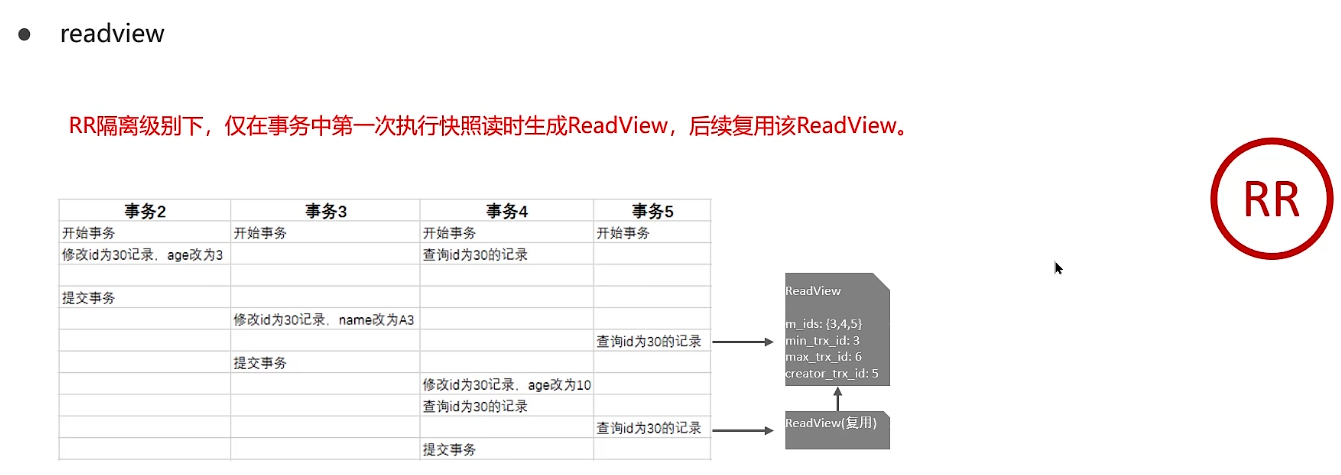
而在RR-Repeatable Read隔离级别下,仅在事务中第一次执行快照时生成ReadView,后序复用这个读视图


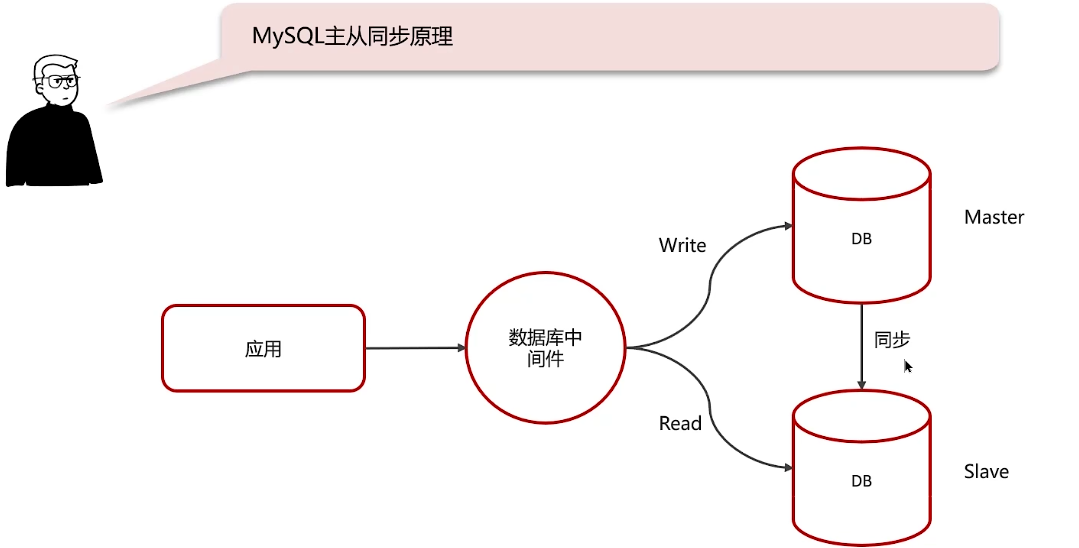
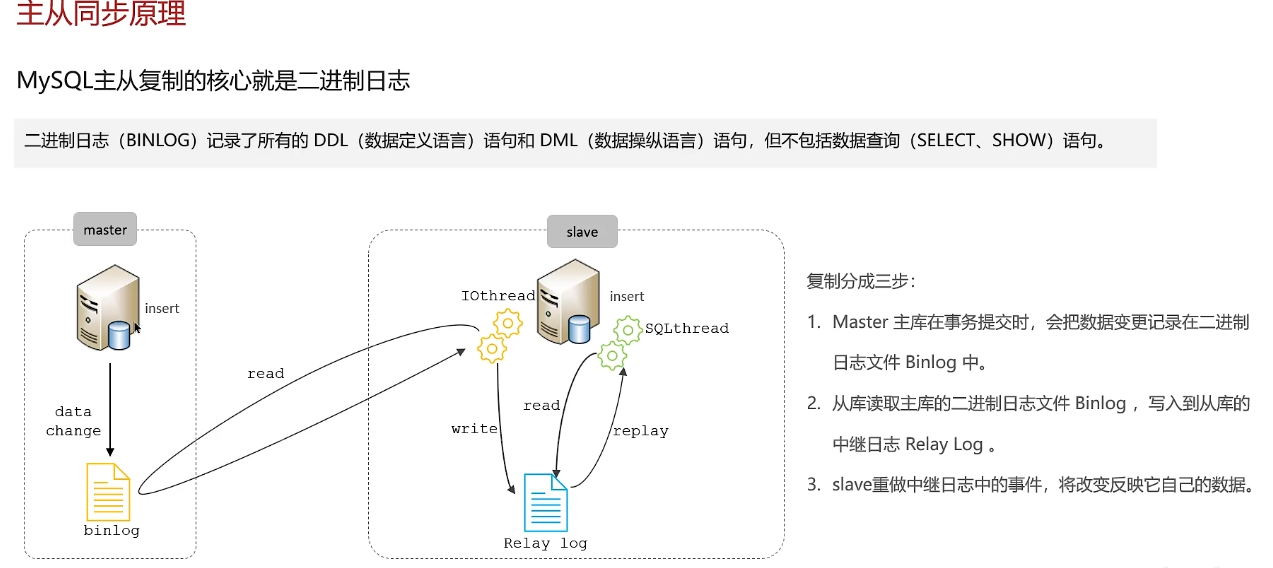
MySQL主从同步原理

MySQL分库分表
主从解决的是访问压力,分库分表解决存储压力
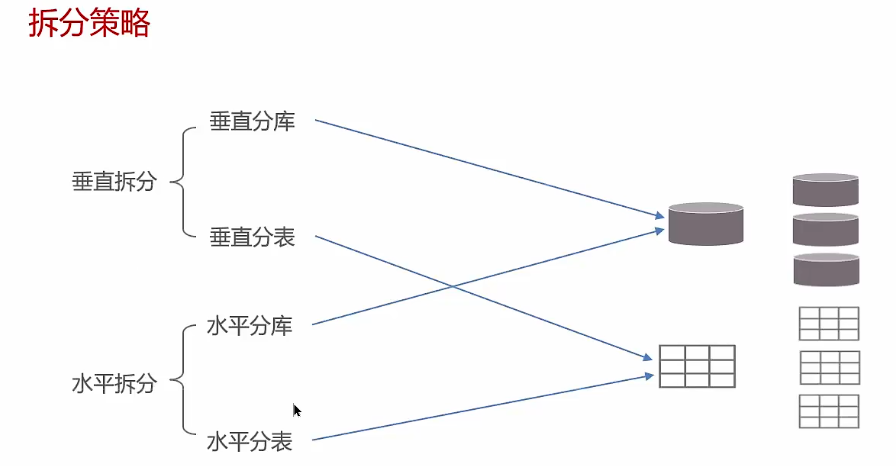
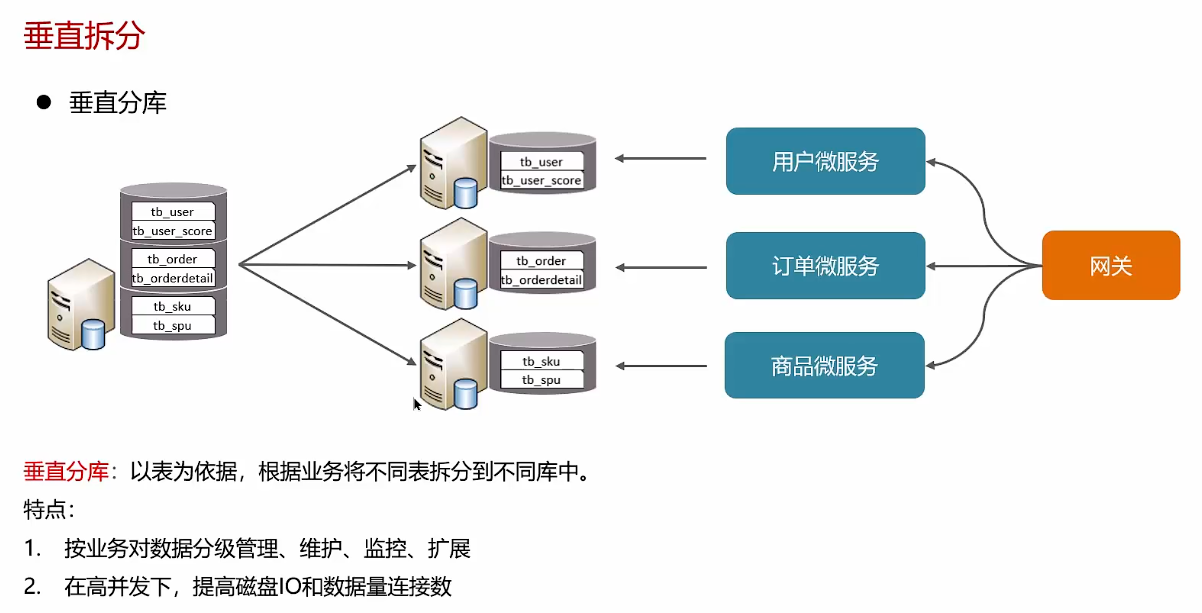
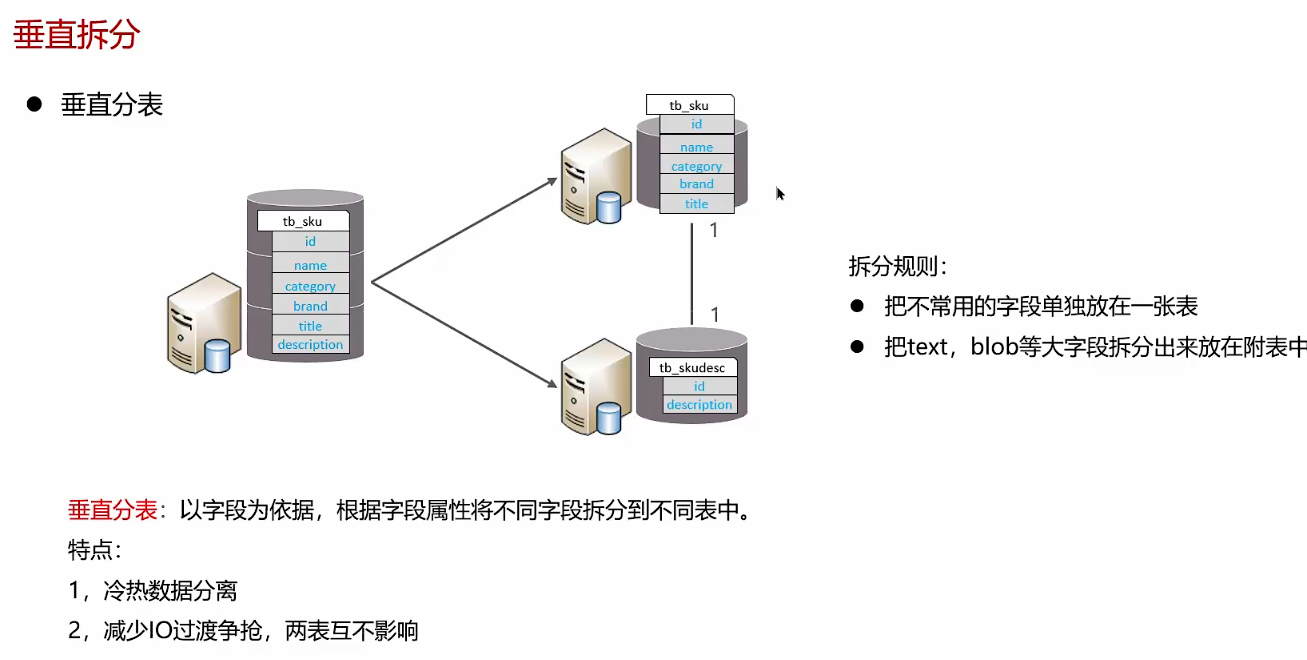
垂直分表后的数据可以在同一个库内
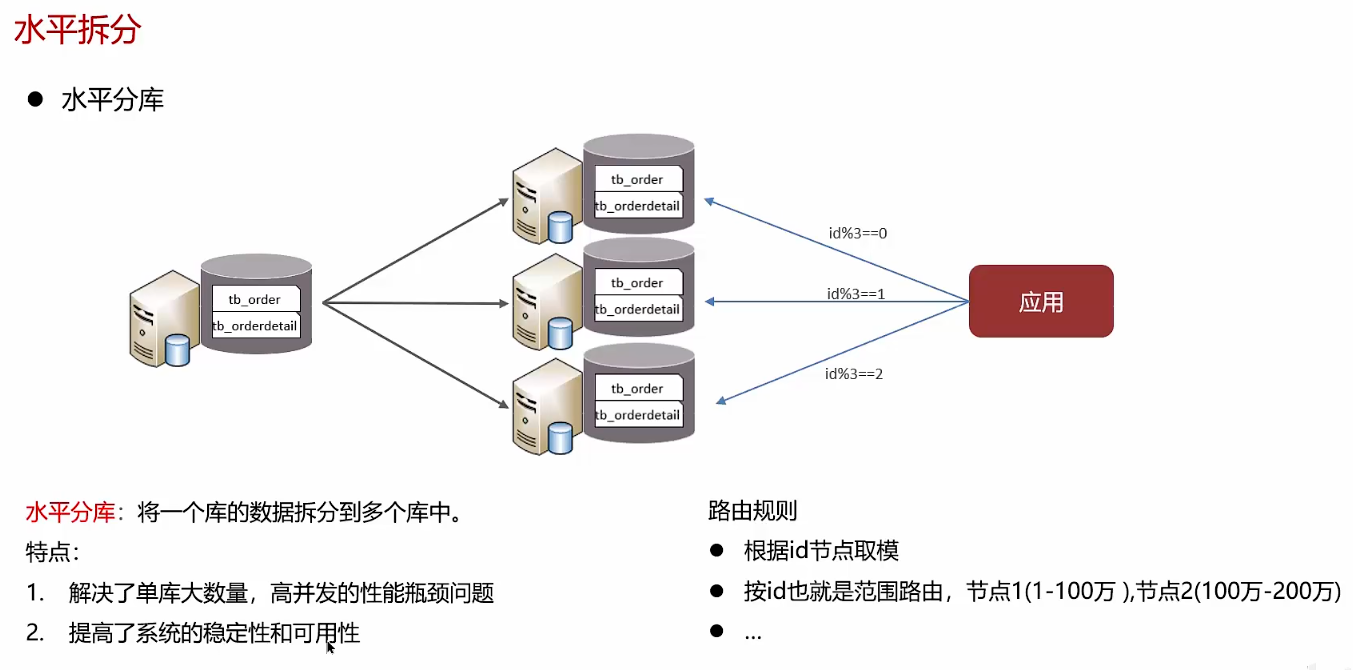
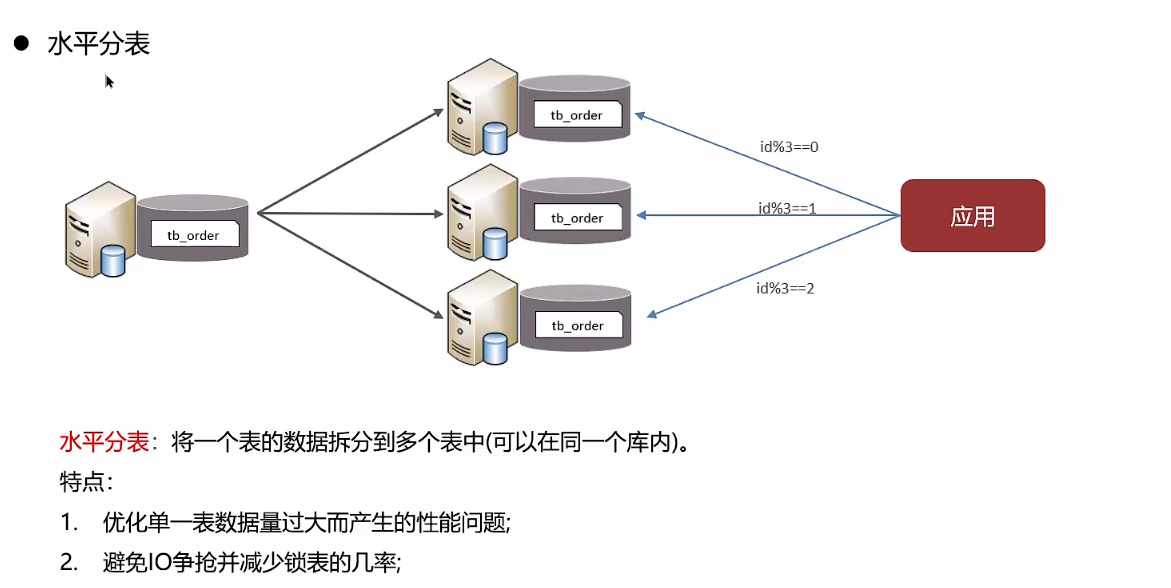
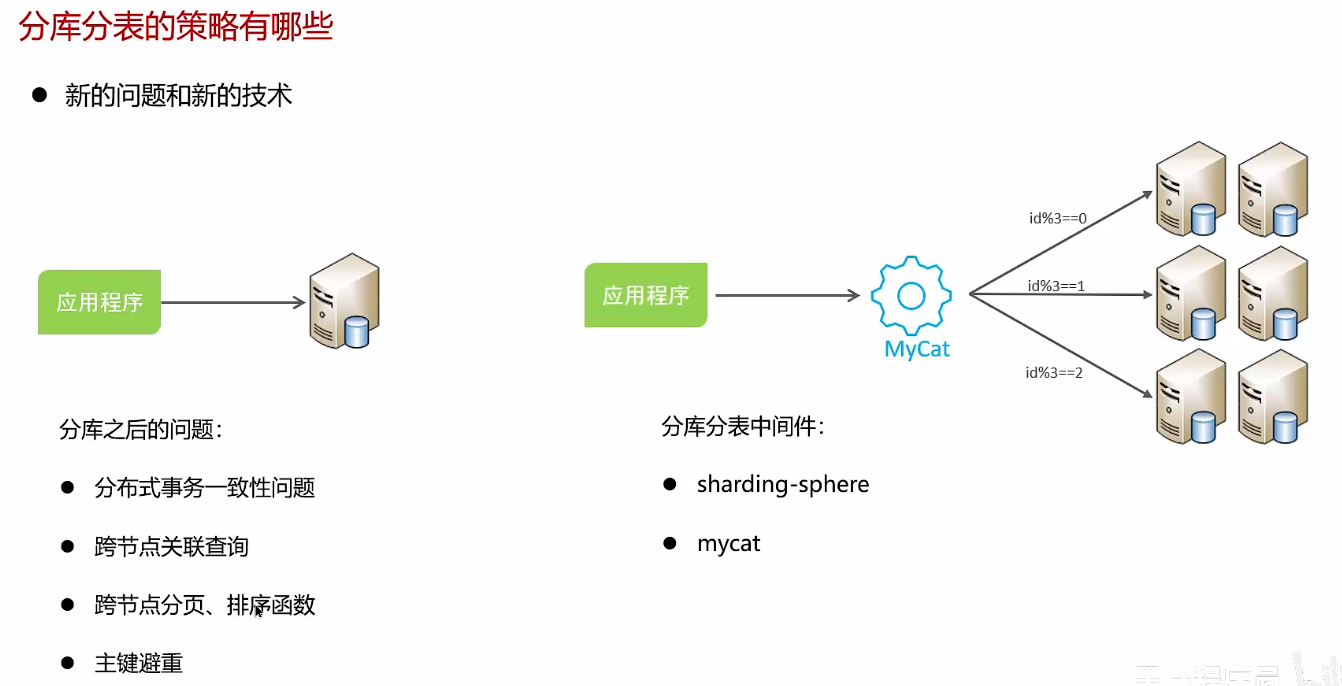
如果项目是微服务项目,通常会用到垂直分库

补充:微服务是什么
是一种软件架构设计风格,核心是把复杂的单体应用拆分成多个小型、独立的服务,每个服务专注解决一个特定业务问题,彼此通过轻量级通信(比如 HTTP/API)协作,最终共同完成整体业务功能。
简单来说,你可以把它理解成 “把大项目拆成多个小项目,各自独立干活、互相配合”,下面从核心特点、与传统架构的区别、优势和挑战几个方面,帮你彻底搞懂:
一、微服务的核心特点(怎么判断一个架构是不是微服务?)
-
服务 “小而专”
每个微服务只负责一个具体的业务领域(比如电商系统里,“用户管理”“商品库存”“订单支付”“物流跟踪” 分别是一个独立微服务),不做 “全能选手”。
比如:当用户下单时,“订单服务” 只处理订单创建逻辑,然后调用 “库存服务” 扣减库存,再调用 “支付服务” 处理付款,自己不管库存和支付的细节。 -
独立开发、部署、运维
每个微服务可以由单独的团队开发(用自己擅长的技术栈,比如 A 团队用 Java 写 “用户服务”,B 团队用 Python 写 “推荐服务”),开发完后能独立部署(改 “商品服务” 时,不用停掉整个电商系统),出问题时也能单独排查,不影响其他服务。 -
数据独立存储
每个微服务有自己专属的数据库(比如 “用户服务” 用 MySQL 存用户信息,“日志服务” 用 Elasticsearch 存日志),不共享数据库 —— 避免一个服务改数据库表结构,导致所有服务出问题。 -
轻量级通信
服务之间通过标准化的 API(比如 RESTful API、gRPC)互相调用,像 “打电话” 一样传递数据,不用依赖复杂的内部关联。
二、微服务 vs 传统 “单体架构”(为什么需要微服务?)
很多人刚开始接触的是 “单体架构”(把所有功能写在一个项目里,比如一个 Java 的 WAR 包包含所有业务),两者的区别很明显:
| 对比维度 | 传统单体架构 | 微服务架构 |
|---|---|---|
| 项目规模 | 所有功能打包成 1 个应用 | 拆成 N 个独立小服务 |
| 技术栈 | 全项目用同一种技术(比如全 Java) | 每个服务可选不同技术栈 |
| 部署方式 | 改一点就要重新部署整个应用 | 单个服务独立部署,不影响全局 |
| 故障影响 | 一个功能崩了,整个应用挂掉 | 单个服务崩了,其他服务正常 |
| 团队协作 | 多人改同一个项目,冲突多 | 团队按服务分工,独立协作 |
举个生活化的例子:
- 单体架构像 “一家小餐馆,老板又管收银、又管做菜、又管送菜”—— 一旦老板忙不过来,整个餐馆停转;
- 微服务像 “连锁餐厅,收银台(用户服务)、后厨(商品服务)、配送员(物流服务)各司其职”—— 收银台忙不过来,加个收银机(扩容收银服务)就行,不影响后厨做菜。
三、微服务的优势(为什么很多公司用它?)
-
灵活迭代,响应快
改某个业务时,只动对应的微服务(比如电商想加 “会员积分” 功能,只开发 “积分服务”,不用动 “订单”“商品” 服务),上线速度快,适合互联网产品 “快速试错、频繁更新” 的需求。 -
容错性强,不怕崩
比如 “推荐服务” 崩了,用户顶多看不到个性化推荐,但依然能正常浏览商品、下单 —— 不会像单体架构那样 “一崩全崩”。 -
支持大规模团队协作
大公司(比如阿里、腾讯)有上百个开发,不可能所有人改同一个单体项目;按微服务分工后,每个团队管 1-2 个服务,效率更高。 -
按需扩容,节省成本
哪个服务压力大,就单独给它加服务器(比如电商大促时,“订单服务” 压力大,就多开几台机器跑 “订单服务”),不用给整个应用扩容,减少资源浪费。
四、微服务的挑战(不是所有项目都适合用!)
微服务不是 “银弹”,拆成小服务后也会带来新问题:
- 复杂度变高:原来 1 个项目,现在要管 N 个服务,还要处理服务间调用失败、数据一致性(比如下单时 “订单服务” 创建了订单,但 “库存服务” 扣库存失败,怎么回滚?)等问题;
- 运维成本高:需要专门的工具监控每个服务的状态(比如用 Prometheus 看服务是否正常)、管理服务部署(比如用 K8s 调度服务),小团队可能扛不住;
- 适合 “大项目”:如果是一个简单的小工具(比如公司内部的考勤系统),拆成微服务反而麻烦 —— 不如单体架构简单直接。
总结:微服务的本质是什么?
一句话概括:“分而治之” —— 把复杂的问题拆成小问题,每个小问题用独立的服务解决,再通过协作完成整体目标,最终实现 “灵活、可靠、易扩展” 的软件系统。
常见的微服务落地案例:阿里的 “中台”(各个业务线拆成微服务,复用中台能力)、美团的外卖系统(订单、支付、配送、商家管理都是独立微服务)、抖音的推荐系统(用户行为分析、推荐计算、内容分发各成服务)。