通过调用deepseek大模型接口对千条评论信息进行文本分析/词频分析/情感分析
目录
一、设计思路:
1.情感分析方法
2.词频分析方法
3.结果输出
二、文档信息:
三、测试结果展示:
四、完整代码:
🌟 Hello,我是蒋星熠Jaxonic!
🌈 在浩瀚无垠的技术宇宙中,我是一名执着的星际旅人,用代码绘制探索的轨迹。
🚀 每一个算法都是我点燃的推进器,每一行代码都是我航行的星图。
🔭 每一次性能优化都是我的天文望远镜,每一次架构设计都是我的引力弹弓。
🎻 在数字世界的协奏曲中,我既是作曲家也是首席乐手。让我们携手,在二进制星河中谱写属于极客的壮丽诗篇!
话不多说我们开始吧~
一、设计思路:
1.情感分析方法
该程序的情感分析主要通过analyze_comment函数实现,具体方法如下:
- 1.基于大语言模型的分析方式:使用GlobalAI API调用Gemini-1.5-Flash模型进行情感分析。
- 2.结构化提示词设计:为每个评论构建包含以下元素的提示词:
-
要求返回JSON格式的分析结果
-
明确的分析维度(二级类别、三级指标、情感分析)
-
情感评分标准(0-1数值范围,三者之和为1)
-
三级指标参考体系(食物、环境、服务、情感四大类及其子指标)
-
- 3.情感分析维度:每个评论会获取以下情感相关数据:
-
正面情感:0-1的数值评分
-
负面情感:0-1的数值评分
-
中性情感:0-1的数值评分
-
主要情感:"正面"、"负面"或"中性"
-
情感强度:0-1的数值表示情感强烈程度
-
- 4.结果标准化处理:确保正面、负面、中性情感评分之和为1,提高结果的一致性。
- 5.API调用优化:
-
设置超时重试机制(最大3次重试)
-
指数退避延迟策略(1秒、2秒、4秒)
-
每处理5条评论后休息1秒,避免API调用过于频繁
-
2.词频分析方法
词频分析主要通过analyze_word_frequency和generate_word_frequency_report函数实现:
- 1.按类别分析:对食物、环境、服务、情感四个类别分别进行词频统计。
- 2.文本预处理流程:
-
筛选特定类别的评论内容
-
合并所有评论文本
-
使用正则表达式([一-龥]+)提取中文词语
-
过滤单字词语(仅保留长度>1的词语)
-
过滤常见停用词(如"的"、"了"、"在"等100多个高频无意义词汇)
-
- 3.词频计算与展示:
-
使用Python的Counter类计算词频
-
为每个类别生成前10个高频词的实时显示
-
为每个类别保存前30个高频词到最终结果
-
- 4.结果组织:将词频分析结果组织成包含"类别"、"词语"、"频次"三个字段的DataFrame。
3.结果输出
两种分析方法的结果最终会保存到同一个Excel文件的不同工作表中:
-
详细分析结果(包含每条评论的情感分析数据)
-
词频分析(按类别组织的高频词统计)
-
分析摘要(各类别统计和总体情感分布)
这种设计使分析结果既包含微观的单条评论情感分析,又提供宏观的词频统计,为评论内容分析提供了全面的数据支持。
二、文档信息:

有个好习惯,每次批量跑较大数据量时先测试前10条数据的结果如何,节省时间成本。
三、测试结果展示:
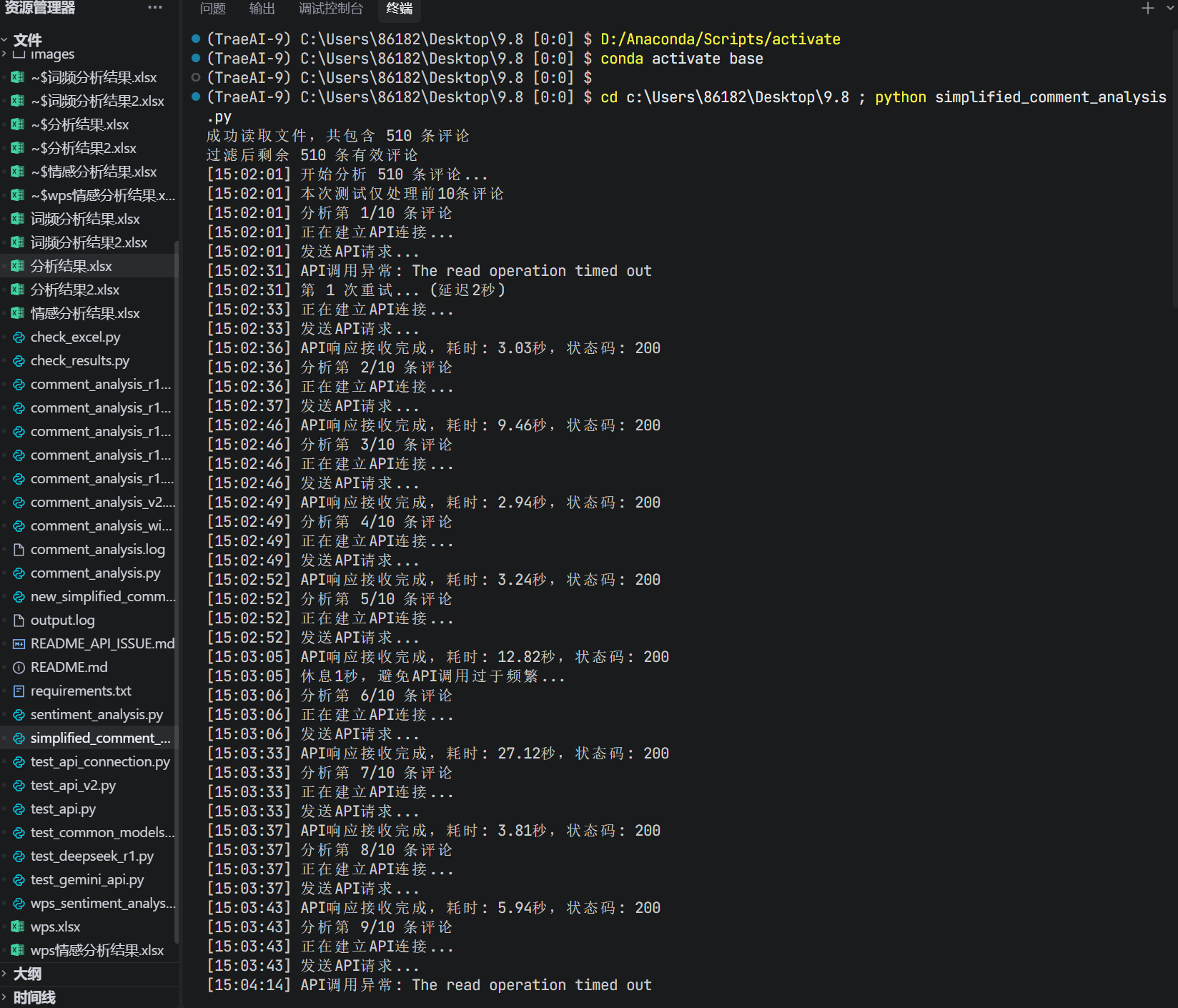
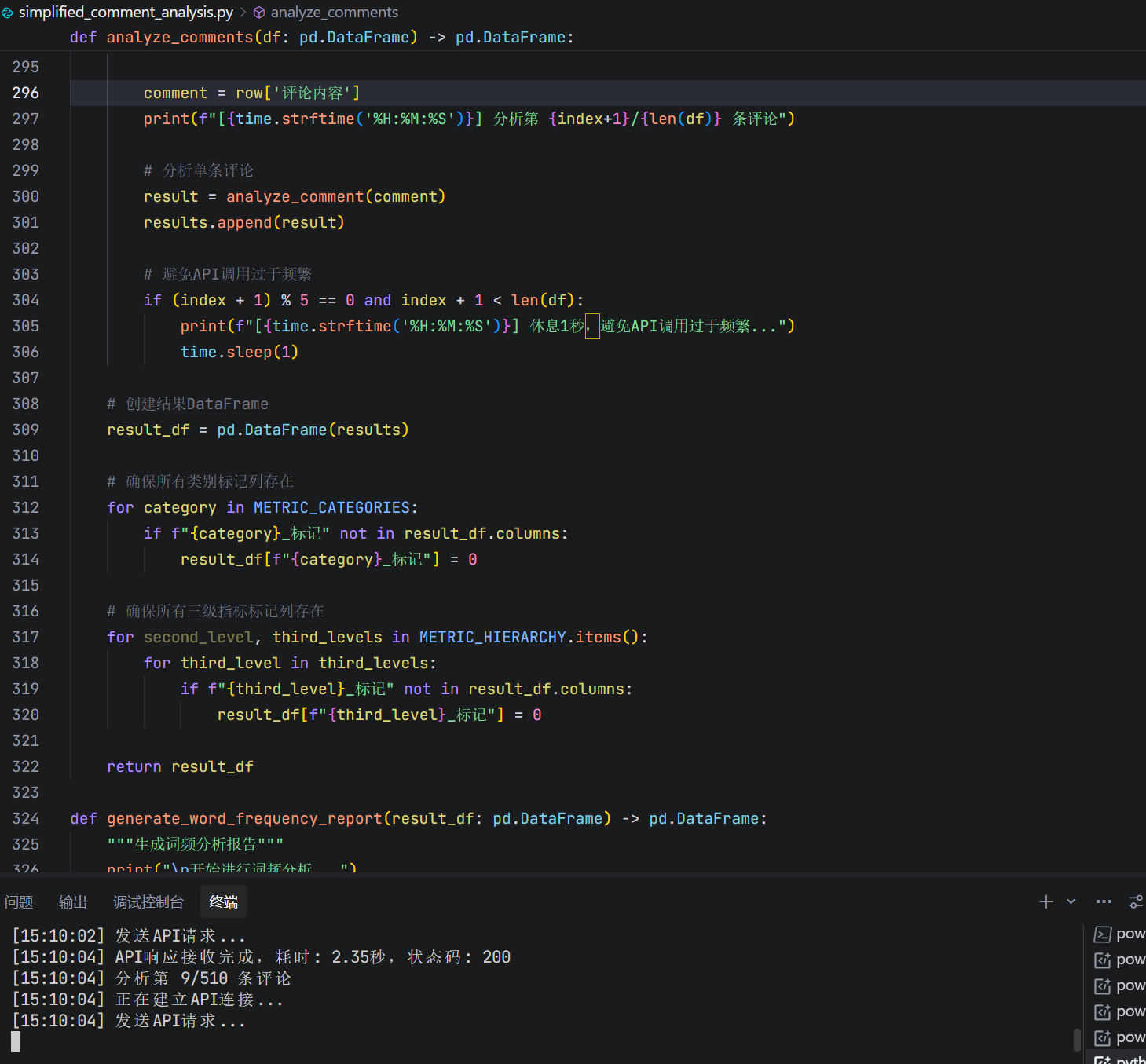
代码稳健性强,由于网络或者多个原因导致的大模型api调用错误可以多次尝试
博主的大模型api:
博主之前的代码稳健性不强,当某个评论有字符串格式错误或者大模型api网络问题调用失败会一直卡在那,通过多次调用可以让模型的稳定性增强。另外选用大模型的时候尽量用稳定的平台,像硅基流动(但是太贵了),全球ai还可以。如果你们用校园网跑,尽量换掉,换成其它稳定的网络或者直接用自己手机的热点。
还有就是用博主上面的代码,如果失败了多次尝试连接。
另外博主在实际的过程中还遇到一个问题是当去上课的时候电脑合盖进程会断掉:
这里有两个解决方法:
1.电脑设置关盖后仍然运行。
2.代码设置成当意外中断自动保存之前的处理过的信息,下一次运行从上一次的断点运行。
这里主要介绍第一种方法:
win+R:输入control,进入电源选项:

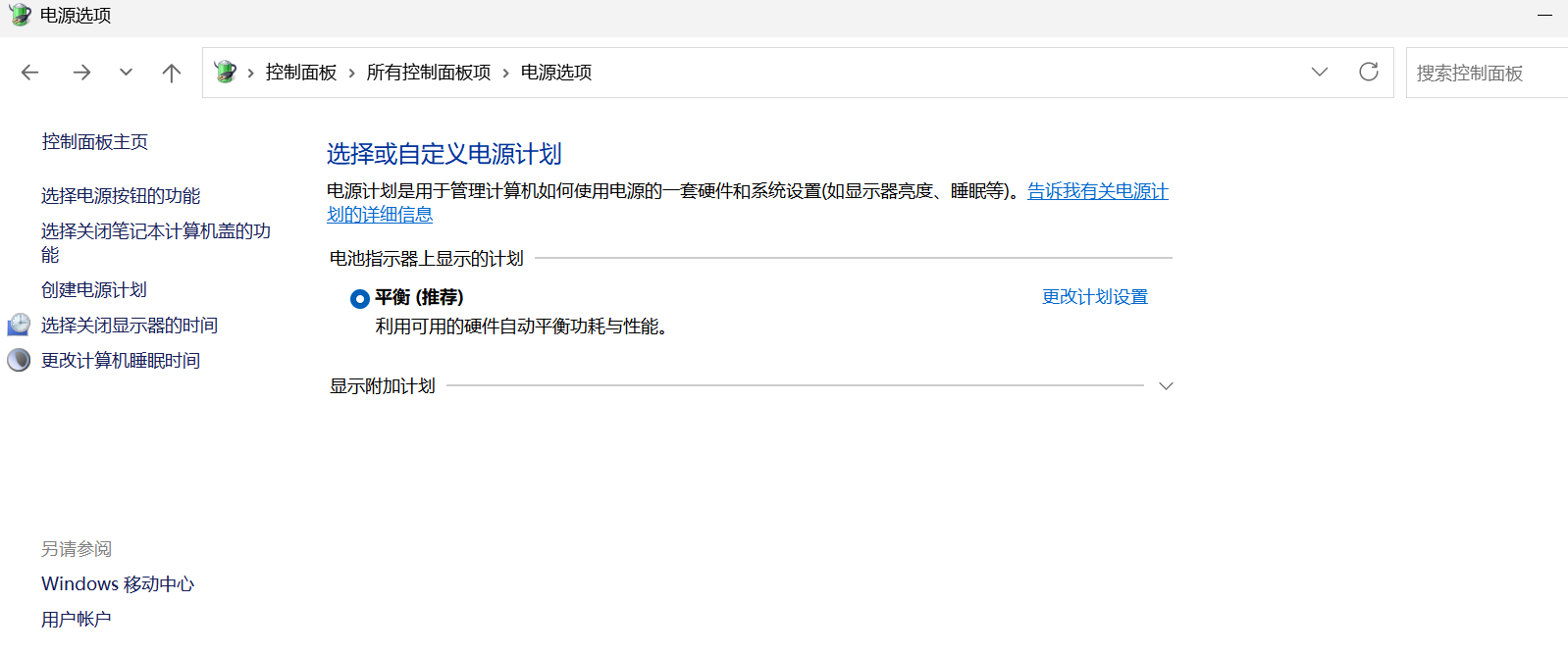
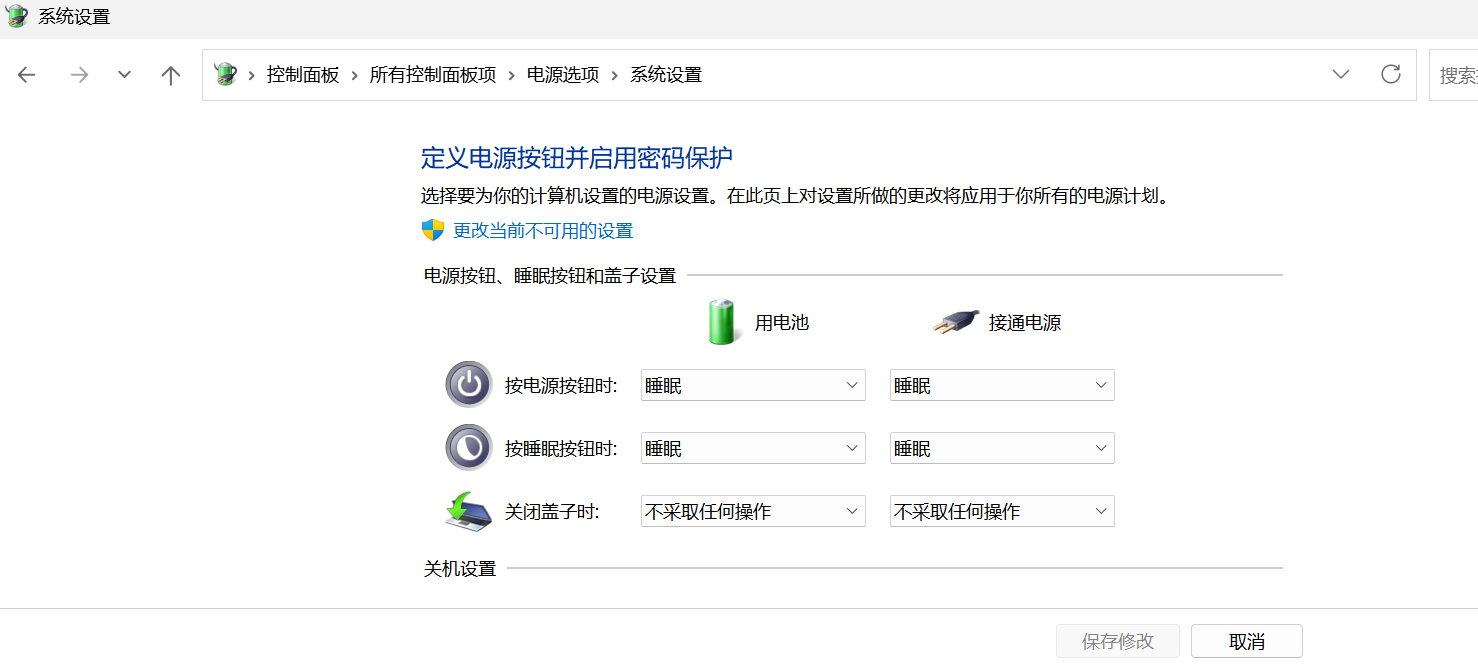
根据图片自己设置好
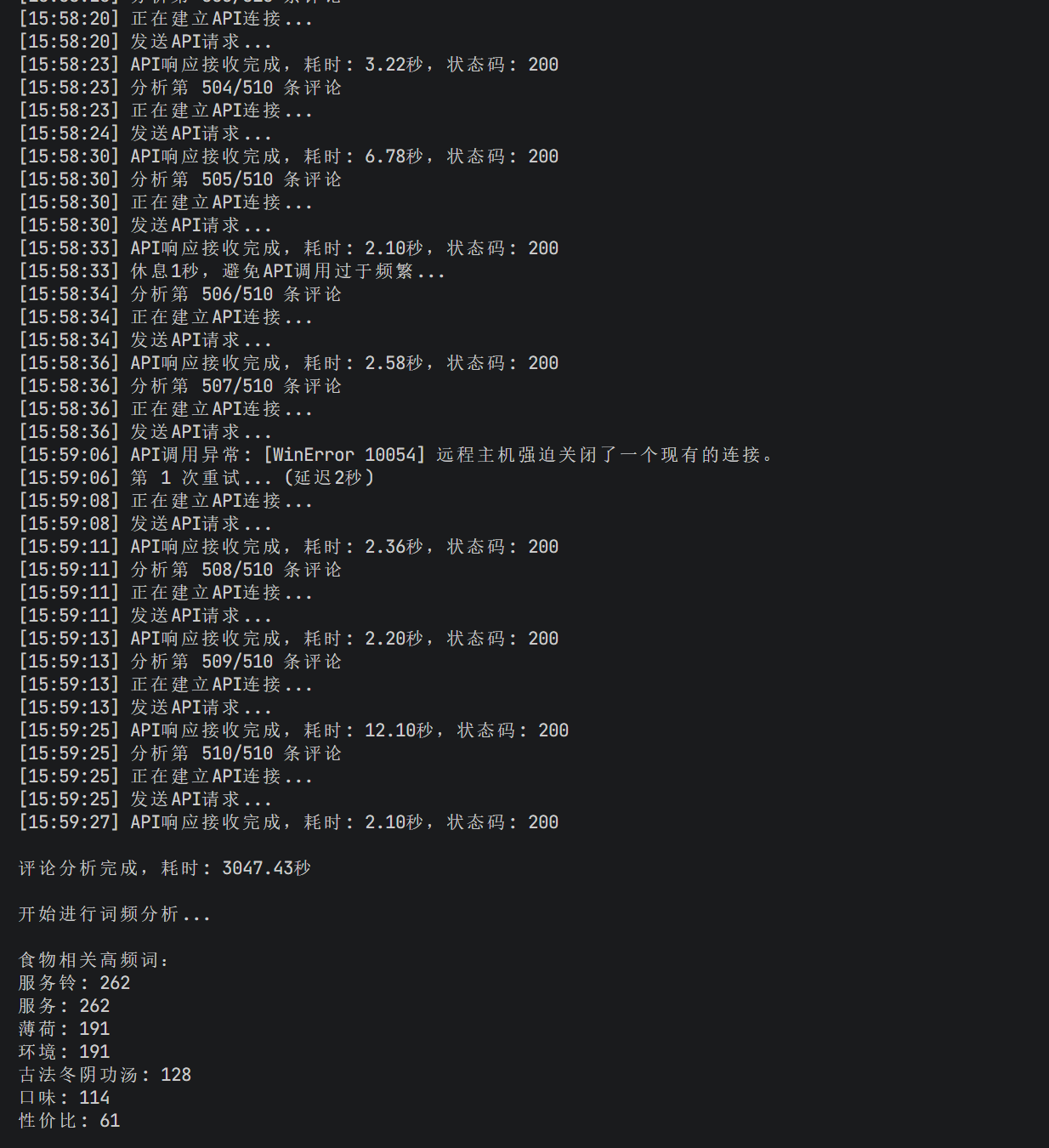
不得不说模型的效率稳健性和模型深度思考不可兼得,用deepseek-r1批量分析的时候虽然分析结果质量高但是慢的要死,还容易中途卡死调用失败,用gemini-1.5快的飞起,批量处理数据量大较简单的任务交给简单的模型吧还是。
结果有图有真相:
还有最后要注意文件放置位置不能重复,否则会报错,尤其是前面生成过的同名文件,同地址:
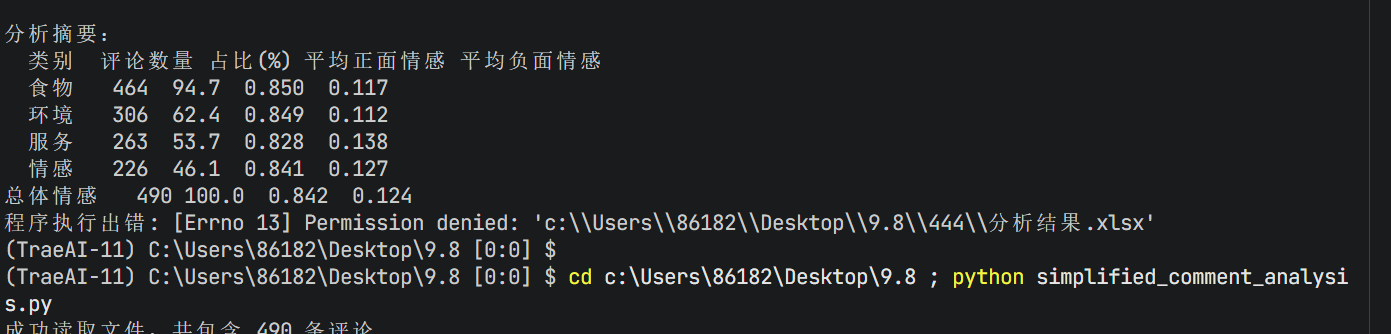
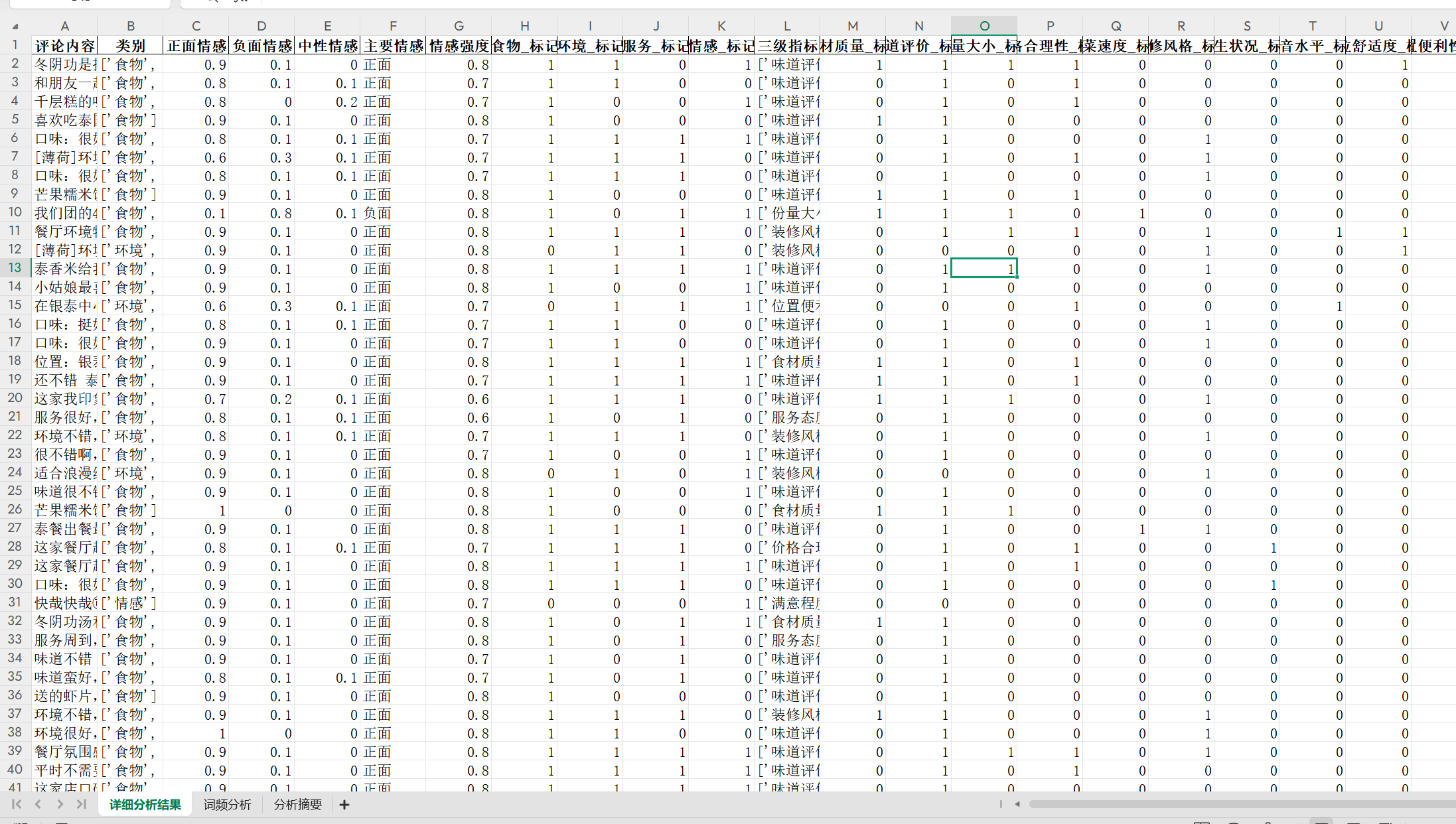

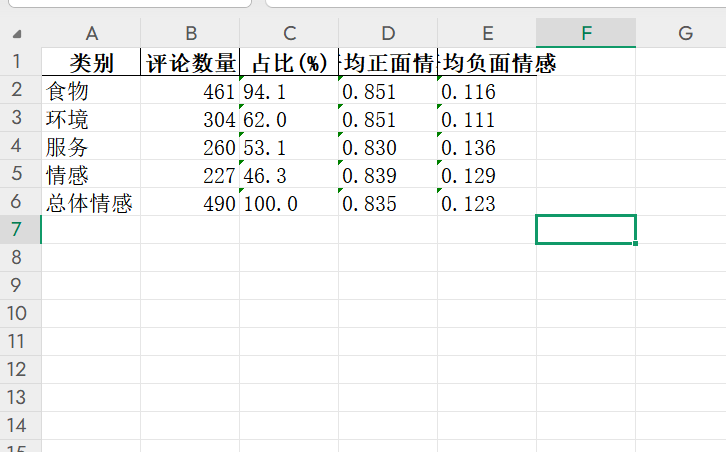
四、完整代码:
# -*- coding: utf-8 -*-
"""
简化版评论分析工具功能:读取Excel文件中的评论内容,使用DeepSeek R1模型进行情感分析和词频分析,输出分析结果表格。使用说明:
1. 确保已安装必要的Python库:pandas
2. 已配置提供的globalai API密钥
3. 将包含评论的Excel文件命名为'wps.xlsx',放在同一目录下
4. 运行脚本:python simplified_comment_analysis.py
"""import pandas as pd
import os
import re
import json
import time
import http.client
from collections import Counter
from typing import Dict, Any# 设置globalai API配置
GLOBALAI_API_KEY = "sk-IaeUjQeFNOSbrTFdYiczHHqfDC4ZkBk0z1rPM9xjCLRZMGAy"
GLOBALAI_API_HOST = "globalai.vip"
GLOBALAI_API_PATH = "/v1/chat/completions"# 定义二级指标和三级指标
METRIC_HIERARCHY = {'食物': ['食材质量', '味道评价', '份量大小', '价格合理性', '上菜速度'],'环境': ['装修风格', '卫生状况', '噪音水平', '座位舒适度', '位置便利性'],'服务': ['服务态度', '响应速度', '专业性', '沟通能力', '个性化服务'],'情感': ['满意程度', '推荐意愿', '体验惊喜', '价值感知', '品牌印象']
}# 提取所有二级指标作为列表,保持向后兼容性
METRIC_CATEGORIES = list(METRIC_HIERARCHY.keys())# 输出文件夹
OUTPUT_FOLDER = "c:\\Users\\86182\\Desktop\\9.8\\444"def ensure_output_folder():"""确保输出文件夹存在"""if not os.path.exists(OUTPUT_FOLDER):os.makedirs(OUTPUT_FOLDER)def load_excel_data(file_path='wps.xlsx'):"""读取Excel文件中的评论数据"""try:df = pd.read_excel(file_path, sheet_name='Sheet2')print(f"成功读取文件,共包含 {len(df)} 条评论")# 检查是否包含所需的评论内容列if '评论内容' not in df.columns:print("错误:文件中缺少'评论内容'列")exit(1)# 过滤掉空评论df = df.dropna(subset=['评论内容'])df = df.reset_index(drop=True)print(f"过滤后剩余 {len(df)} 条有效评论")return dfexcept Exception as e:print(f"读取文件失败: {e}")print("请确保'wps.xlsx'文件存在于当前目录下且包含Sheet1")exit(1)def call_api(prompt: str, model: str = "gemini-1.5-flash", timeout: int = 30) -> Dict:"""统一的API调用函数,简化代码并提高稳健性"""max_retries = 3retry_count = 0while retry_count < max_retries:try:# 创建连接并设置超时print(f"[{time.strftime('%H:%M:%S')}] 正在建立API连接...")conn = http.client.HTTPSConnection(GLOBALAI_API_HOST, timeout=timeout)# 准备请求数据payload = json.dumps({"model": model,"messages": [{"role": "system", "content": "专业评论分析助手"},{"role": "user", "content": prompt}],"temperature": 0.2 # 降低随机性,提高稳定性})headers = {'Accept': 'application/json','Authorization': f'Bearer {GLOBALAI_API_KEY}','Content-Type': 'application/json','Host': GLOBALAI_API_HOST}# 发送请求print(f"[{time.strftime('%H:%M:%S')}] 发送API请求...")start_time = time.time()conn.request("POST", GLOBALAI_API_PATH, payload, headers)res = conn.getresponse()data = res.read()conn.close()end_time = time.time()print(f"[{time.strftime('%H:%M:%S')}] API响应接收完成,耗时: {end_time - start_time:.2f}秒,状态码: {res.status}")# 解析响应response_data = json.loads(data.decode("utf-8"))# 检查响应状态if res.status != 200:print(f"[{time.strftime('%H:%M:%S')}] API调用失败,状态码: {res.status}")retry_count += 1continue# 安全获取内容if ('choices' in response_data and response_data['choices'] and 'message' in response_data['choices'][0] and 'content' in response_data['choices'][0]['message']):return {"success": True,"content": response_data['choices'][0]['message']['content']}else:print(f"[{time.strftime('%H:%M:%S')}] API响应格式不符合预期")return {"success": False, "error": "响应格式错误"}except json.JSONDecodeError:print(f"[{time.strftime('%H:%M:%S')}] JSON解析错误")return {"success": False, "error": "JSON解析错误"}except http.client.HTTPException as e:print(f"[{time.strftime('%H:%M:%S')}] HTTP异常: {e}")retry_count += 1except Exception as e:print(f"[{time.strftime('%H:%M:%S')}] API调用异常: {e}")retry_count += 1# 重试延迟,指数退避if retry_count < max_retries:delay = 1 * (2 ** retry_count) # 1s, 2s, 4sprint(f"[{time.strftime('%H:%M:%S')}] 第 {retry_count} 次重试... (延迟{delay}秒)")time.sleep(delay)return {"success": False, "error": "达到最大重试次数"}def extract_json(content: str) -> Dict:"""从文本中提取并解析JSON"""try:# 移除代码块标记(如果存在)if '```json' in content:json_start = content.find('```json') + 7json_end = content.rfind('```')if json_start < json_end:content = content[json_start:json_end]# 尝试直接解析return json.loads(content)except json.JSONDecodeError:# 尝试修复简单的JSON格式错误try:# 处理多余的双引号fixed = re.sub(r':\s*1"', ': 1', content)fixed = re.sub(r':\s*0"', ': 0', fixed)return json.loads(fixed)except:print("JSON解析失败,返回空结果")return {}def analyze_comment(comment: str) -> Dict[str, Any]:"""分析单条评论,同时获取分类和情感分析结果"""# 准备结果字典result = {"评论内容": comment,"类别": [],"正面情感": 0.0,"负面情感": 0.0,"中性情感": 1.0,"主要情感": "中性","情感强度": 0.0}# 构建综合分析提示词,包含三级指标结构prompt = f"""请分析以下评论并返回JSON对象,不要任何额外解释:
{{"二级类别": ["食物", "环境", "服务", "情感"中的相关类别],"三级指标": [与评论相关的三级指标名称],"情感分析": {{"正面情感": 0-1数值,"负面情感": 0-1数值,"中性情感": 0-1数值,"主要情感": "正面"/"负面"/"中性","情感强度": 0-1数值}}
}}重要说明:
1. 三级指标结构如下:- 食物: ['食材质量', '味道评价', '份量大小', '价格合理性', '上菜速度']- 环境: ['装修风格', '卫生状况', '噪音水平', '座位舒适度', '位置便利性']- 服务: ['服务态度', '响应速度', '专业性', '沟通能力', '个性化服务']- 情感: ['满意程度', '推荐意愿', '体验惊喜', '价值感知', '品牌印象']
2. 三级指标中只保留评论中涉及到的具体三级指标名称
3. 正面情感、负面情感、中性情感的数值之和必须为1
4. 根据评论内容真实反映情感倾向
5. 情感强度表示情感的强烈程度评论:{comment}
"""# 调用APIapi_result = call_api(prompt)if api_result["success"]:# 提取JSON结果analysis_data = extract_json(api_result["content"])# 填充类别信息if "二级类别" in analysis_data:result["类别"] = analysis_data["二级类别"]# 为每个二级类别创建标记列for category in METRIC_CATEGORIES:result[f"{category}_标记"] = 1 if category in analysis_data["二级类别"] else 0else:# 如果没有类别信息,为所有类别创建标记列为0for category in METRIC_CATEGORIES:result[f"{category}_标记"] = 0# 处理三级指标信息if "三级指标" in analysis_data:result["三级指标"] = analysis_data["三级指标"]# 为每个三级指标创建标记列for second_level, third_levels in METRIC_HIERARCHY.items():for third_level in third_levels:result[f"{third_level}_标记"] = 1 if third_level in analysis_data["三级指标"] else 0else:# 如果没有三级指标信息,为所有三级指标创建标记列为0for second_level, third_levels in METRIC_HIERARCHY.items():for third_level in third_levels:result[f"{third_level}_标记"] = 0# 填充情感分析信息if "情感分析" in analysis_data:sentiment = analysis_data["情感分析"]result["正面情感"] = float(sentiment.get("正面情感", 0.0))result["负面情感"] = float(sentiment.get("负面情感", 0.0))result["中性情感"] = float(sentiment.get("中性情感", 1.0))result["主要情感"] = sentiment.get("主要情感", "中性")result["情感强度"] = float(sentiment.get("情感强度", 0.0))# 确保情感值总和为1total = result["正面情感"] + result["负面情感"] + result["中性情感"]if total > 0:result["正面情感"] /= totalresult["负面情感"] /= totalresult["中性情感"] /= totalreturn resultdef analyze_word_frequency(df: pd.DataFrame, category_col: str, comment_col: str) -> Counter:"""对指定类别的评论进行词频分析"""# 筛选出属于该类别的评论category_comments = df[df[category_col] == 1][comment_col]if len(category_comments) == 0:return Counter()# 合并所有评论all_text = ' '.join(category_comments.dropna())# 使用正则表达式提取中文词语chinese_words = re.findall(r'[一-龥]+', all_text)# 过滤掉单字和常见停用词stop_words = {'的', '了', '在', '是', '我', '有', '和', '就', '不', '人', '都', '一', '一个', '上', '也', '很', '到', '说', '要', '去', '你', '会', '着', '没有', '看', '好', '自己', '这'}filtered_words = [word for word in chinese_words if len(word) > 1 and word not in stop_words]# 计算词频word_counts = Counter(filtered_words)return word_countsdef analyze_comments(df: pd.DataFrame) -> pd.DataFrame:"""批量分析所有评论"""print(f"[{time.strftime('%H:%M:%S')}] 开始分析 {len(df)} 条评论...")# 存储分析结果results = []# 批量处理全部评论for index, row in df.iterrows():comment = row['评论内容']print(f"[{time.strftime('%H:%M:%S')}] 分析第 {index+1}/{len(df)} 条评论")# 分析单条评论result = analyze_comment(comment)results.append(result)# 避免API调用过于频繁if (index + 1) % 5 == 0 and index + 1 < len(df):print(f"[{time.strftime('%H:%M:%S')}] 休息1秒,避免API调用过于频繁...")time.sleep(1)# 创建结果DataFrameresult_df = pd.DataFrame(results)# 确保所有类别标记列存在for category in METRIC_CATEGORIES:if f"{category}_标记" not in result_df.columns:result_df[f"{category}_标记"] = 0# 确保所有三级指标标记列存在for second_level, third_levels in METRIC_HIERARCHY.items():for third_level in third_levels:if f"{third_level}_标记" not in result_df.columns:result_df[f"{third_level}_标记"] = 0return result_dfdef generate_word_frequency_report(result_df: pd.DataFrame) -> pd.DataFrame:"""生成词频分析报告"""print("\n开始进行词频分析...")freq_data = []# 为每个类别进行词频分析for category in METRIC_CATEGORIES:word_freq = analyze_word_frequency(result_df, f"{category}_标记", "评论内容")if word_freq:print(f"\n{category}相关高频词:")# 显示前10个高频词for word, count in word_freq.most_common(10):print(f"{word}: {count}")# 保存前30个高频词到结果for word, count in word_freq.most_common(30):freq_data.append({"类别": category, "词语": word, "频次": count})# 创建词频分析结果DataFramefreq_df = pd.DataFrame(freq_data)return freq_dfdef generate_summary_report(result_df: pd.DataFrame) -> pd.DataFrame:"""生成分析摘要报告"""summary_data = []# 计算各类别统计for category in METRIC_CATEGORIES:count = result_df[f"{category}_标记"].sum()percentage = (count / len(result_df)) * 100 if len(result_df) > 0 else 0# 计算该类别评论的平均情感if count > 0:avg_positive = result_df[result_df[f"{category}_标记"] == 1]["正面情感"].mean()avg_negative = result_df[result_df[f"{category}_标记"] == 1]["负面情感"].mean()else:avg_positive = 0avg_negative = 0summary_data.append({"类别": category,"评论数量": count,"占比(%)": f"{percentage:.1f}","平均正面情感": f"{avg_positive:.3f}","平均负面情感": f"{avg_negative:.3f}"})# 添加总体情感统计if len(result_df) > 0:total_positive = result_df["正面情感"].mean()total_negative = result_df["负面情感"].mean()total_neutral = result_df["中性情感"].mean()# 主要情感分布sentiment_dist = result_df["主要情感"].value_counts().to_dict()summary_data.append({"类别": "总体情感","评论数量": len(result_df),"占比(%)": "100.0","平均正面情感": f"{total_positive:.3f}","平均负面情感": f"{total_negative:.3f}"})return pd.DataFrame(summary_data)def main():# 确保输出文件夹存在ensure_output_folder()try:# 1. 加载数据df = load_excel_data()if len(df) == 0:print("错误:没有有效的评论内容可供分析。")return# 2. 分析评论start_time = time.time()result_df = analyze_comments(df)end_time = time.time()print(f"\n评论分析完成,耗时: {end_time - start_time:.2f}秒")# 3. 生成词频分析报告freq_df = generate_word_frequency_report(result_df)# 4. 生成摘要报告summary_df = generate_summary_report(result_df)print("\n分析摘要:")print(summary_df.to_string(index=False))# 5. 保存结果到Excel文件output_file = os.path.join(OUTPUT_FOLDER, '分析结果.xlsx')# 创建ExcelWriter对象,支持多个工作表with pd.ExcelWriter(output_file, engine='openpyxl') as writer:# 保存详细分析结果result_df.to_excel(writer, sheet_name='详细分析结果', index=False)# 保存词频分析结果if not freq_df.empty:freq_df.to_excel(writer, sheet_name='词频分析', index=False)# 保存摘要报告summary_df.to_excel(writer, sheet_name='分析摘要', index=False)print(f"\n所有结果已成功保存到'{output_file}'文件中")except Exception as e:print(f"程序执行出错: {e}")if __name__ == "__main__":main()
有问题可以在评论区问我哦~也可以和我私信交流~
大家多多关注多多支持~