MoPKL模型学习(与常见红外小目标检测方法)
红外小目标检测研究方向
1. 传统方法
形态学滤波方法:Top-hat 变换
差分滤波方法:LoG 滤波(Laplacian of Gaussian),DoG 滤波(Difference of Gaussian)
局部对比度与统计方法:局部对比度测量(LCM),局部熵(Local Entropy)
低秩 + 稀疏分解方法:RPCA(Robust PCA),LRR(Low-Rank Representation)
局部黑白场景的混合方法:滤波(DoG/LoG)+ 局部对比度:先增强,再做目标与背景差异检测;Top-hat + 局部熵:同时利用形态学与统计信息,提高鲁棒性;RPCA 结果再经过对比度增强,减少伪目标。
传统方法的缺陷:参数依赖强、对复杂背景不鲁棒、缺乏对弱小目标的适应能力、实时性与通用性不足
2. 基于运动信息的方法
帧差法(Frame Difference):小目标在移动 → 差分后留下亮点;静态背景抵消。
光流法(Optical Flow):计算像素点的运动向量场 (u,v),小目标对应的光流方向/速度往往与背景不同。
时空滤波 / 三维卷积:把视频看作三维数据(x, y, t),设计时空滤波器或 3D 卷积:3D DoG/LoG:在三维空间提取局部亮点;ST-CNN / 3D-CNN:直接学习时空特征。
多帧积累 / 堆栈:累计帧差;滑动时间窗能量图;加权累计
运动先验建模:MoPKL / iMoPKL
3. 基于深度学习的单帧检测
改进的 U-Net / DenseNet / ResNet 编解码器;注意力机制;多尺度特征融合。
4. 基于多模态与跨模态的方法
可见光 + 红外;语言先验驱动;知识蒸馏。
5. 基于生成与对抗的方法
Related Works
单帧方法
1. MDvsFAcGan
站在 生成对抗网络 的角度,把检测中的错误类型(漏检、虚警)分解出来,用 GAN 学习更鲁棒的检测能力。
2. ACM
采用 编码器-解码器 网络(类似 U-Net),先得到多层次的特征映射;用 非对称结构 来融合它们(不是简单拼接,而是针对不同特征赋予不同权重/处理方式),得到一个更高效的综合表征。
3. AGPCNet
做了一个上下文金字塔,在多尺度上聚合上下文信息;并用注意力引导哪些上下文更有用。
AGCB:在特征图里同时建 局部关系(块内)和 全局关系(跨块),再用注意力引导。小范围抑制纹理噪声,大范围减少伪目标;
CPM:把多个尺度的 AGCB 并联,汇聚不同感受野的上下文。小目标大小多变,用多尺度金字塔保证都能被捕捉到。
AFM:在解码阶段,把浅层(定位强)和深层(语义强)特征用 不同机制融合。浅层靠空间注意守住位置,深层靠通道注意强化语义,两者互补。
4. DNANet
采用密集的、嵌套式的跳连(可理解为 U-Net++/Dense 连接风格),让高分辨率浅层细节与深层语义多次融合,降低小目标细节的损失。
5. RDIAN + IRDST 数据集
6. RPCANet
多帧方法
1. 相邻帧差分(Inter-frame Difference)
用两帧(或多帧)做差,持续运动的目标在差分图上被凸显,静稳背景被抵消。
2. *4-D STT 模型(Spatio-Temporal Tensor Train)
在每帧内提取局部 patch,按时间顺序串接,形成 4D 张量(通常是 的高阶结构)。对 4D 张量做 Tensor-Train (TT) 分解,并配合 ring unfolding(环展开) 把高阶张量按环式规则展开成矩阵/更低阶张量以便于求解,低秩部分对应时空相关的背景,残差/稀疏部分对应小目标。利用分解后的稀疏/残差能量图(或显著图)阈值化得到目标。
3. SSTNet(Sliced Spatio-Temporal Network)
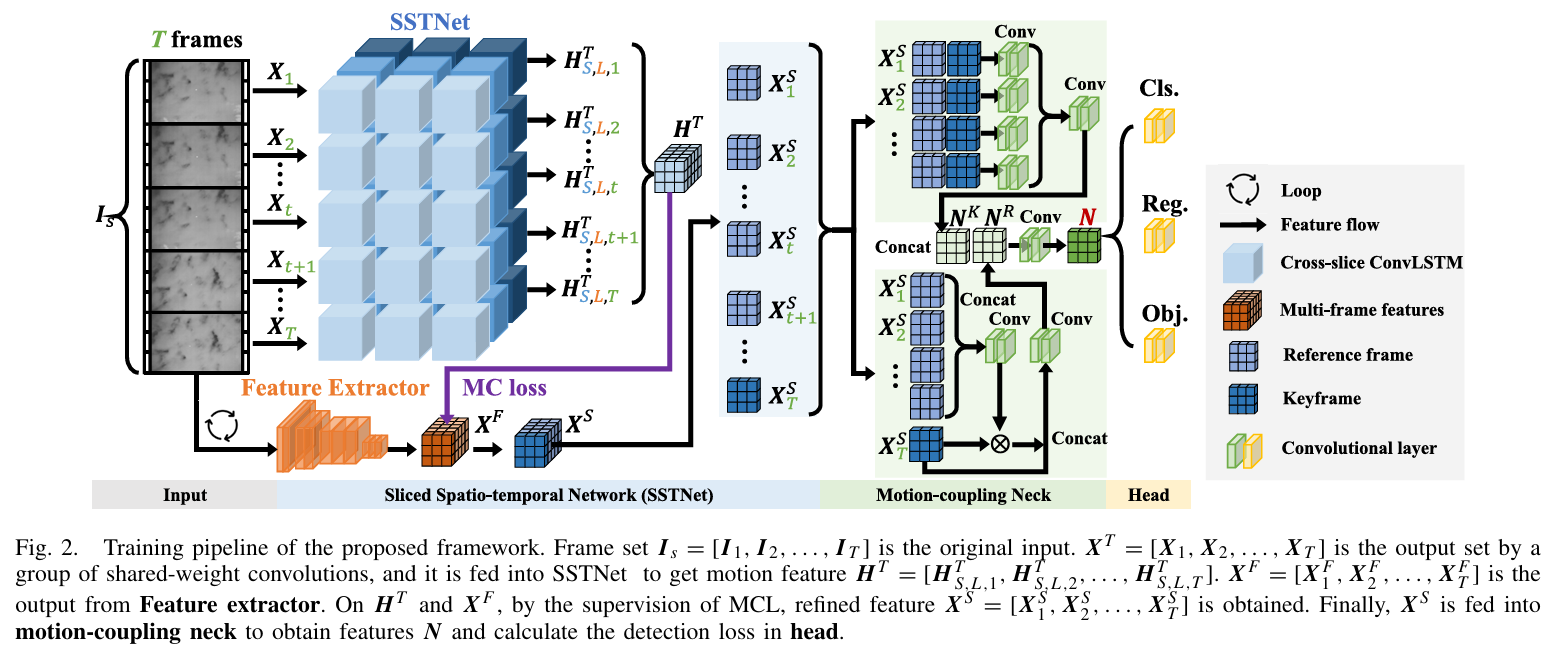
(1)切片(Sliced)
将连续 帧分成若干子序列(slice);每个 slice 都含多帧(如以当前关键帧为中心的窗口),用于“近域”运动建模。
(2)空间编码(Backbone)
各帧先经2D CNN提取空间特征,输出得到逐帧特征图序列,送往时序模块。
(3)跨切片 ConvLSTM(Cross-slice ConvLSTM Node,SSTNet的关键)
切片内:像标准 ConvLSTM 一样,利用门控在子序列内部聚合短时运动信息;
切片间:新增“跨切片”连接,让来自过去/未来其他 slice 的隐状态也参与当前更新,相当于“多条时间支路”之间的信息交换;
这样既保留了近邻时序的稳定性,又引入更长程、更全局的运动上下文。
(4)Motion-Coupling Neck(运动耦合颈部)
在骨干与检测头之间加入一个“Neck”模块,显式把运动特征与空间特征耦合/融合,帮助下游检测头更好地利用多帧运动信息(而不是只看当前帧的静态特征)。
在上图中,橙色部分相当于对每一帧做的共享卷积,得到多帧空间特征;蓝色部分相当于切片 + 跨切片的 ConvLSTM 部分,它处理输入的多帧特征
,生成时序运动特征
;紫色的 MC loss 则是把 Feature Extractor 输出的空间特征
和 SSTNet 输出的运动特征
做监督约束,让运动特征和空间特征保持一致性(防止时序建模漂移),得到更稳定的 融合特征
;最后绿色部分再显式地把运动信息和空间特征融合,输入给检测头。
VLM
VLM(如 CLIP)靠“图像—文本(类别)”对齐,在有明确语义类别的任务上很强;而 ISTD 没有清晰类别、目标极小且依赖多帧运动线索,与 VLM 的训练范式天然不匹配。所以我们需要为 ISTD 量身定制新的框架。
MoPKL
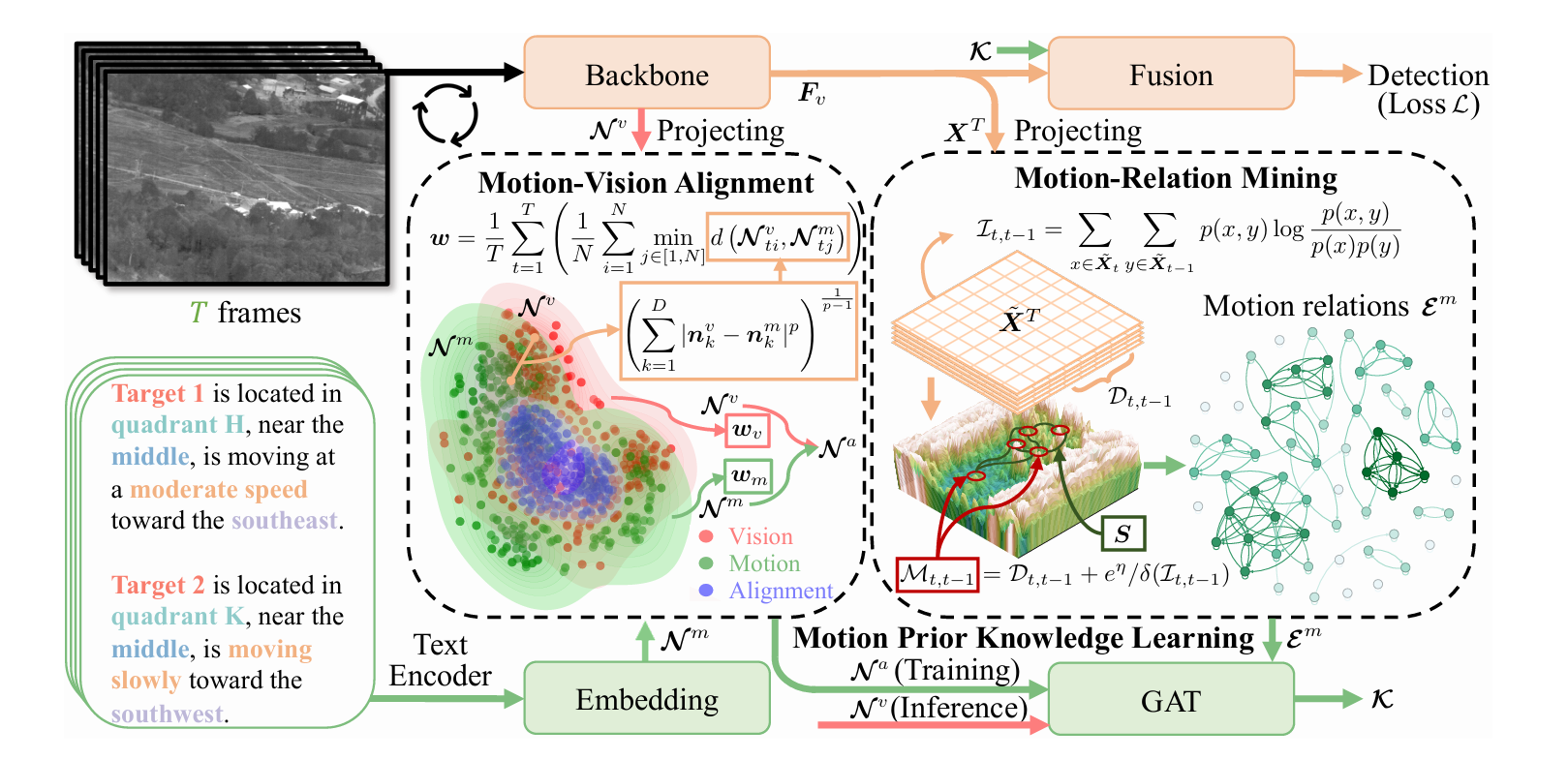
1. Backbone(视觉特征提取)
使用标准卷积主干(如 ResNet、CSPDarknet 等)提取多尺度空间特征,输出每一帧的空间特征图 。
2. Homogeneous Language Descriptions(同质语言描述生成)
MoPKL把“获取细粒度运动特征”的问题转成构造结构化文本的问题:先把图像按空间划分出目标的位置,再用相邻两帧的位置计算速度与方向,从而得到统一格式的描述。完整描述应包含五个元素:target, quadrant, region, speed, direction。
象限(quadrant):以图像中心为极点,将方位离散化为若干扇区。iMoPKL 对该设计作了明确量化:将平面分成 12 个象限(每个 30°)。
区域(region):按与中心的径向距离再细分“中心—外围”的等级。iMoPKL 给出为 5 个等级(示意图中常见 4 环:Center/Core/Middle/Perimeter,论文后续版本进一步形式化为 5 级)。
速度(speed):用相邻两帧目标中心的位移长度刻画,并离散成 4 档:stationary / slowly / moderate / quickly。
方向(direction):用相邻两帧中心的水平/垂直位移确定主方向,按角度离散为 8 类(每 45° 一类)。
把上面的五个元素按固定模板拼成句子(例如:“Target i is in quadrant H, near the middle, moving at a moderate speed toward the southeast.”),这样每个目标都有同构文本。
接下来把这些模板句输入文本编码器得到语言嵌入,用作“运动先验”的表征。
3. Motion-Vision Alignment(运动-视觉对齐)
Backbone 提取多帧视觉特征 后,投影得到
与
;文本经 GloVe 编码得到
。这一步让两种模态在同一语义子空间内可比较。

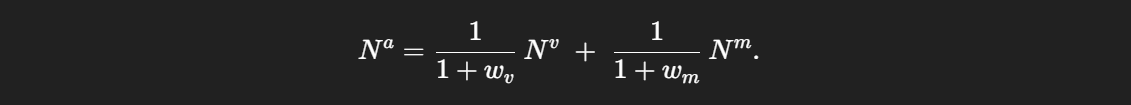
这一步相当于归一化了所有视觉模态和文本模态各自相较于对方的距离,以便做跨模态对齐。
4. Motion-Relation Mining(运动关系挖掘)
从骨干网络得到中分辨率多帧特征 ,把每一帧按接近目标框尺度的
网格切成
个子块,得到
(其中
)
对相邻帧 的每个子块,融合两类信息:
帧间差分 :对子块内所有通道和像素求绝对差并累加,衡量“具体的变化量”。
互信息 :由单帧熵
、联合熵
得到,衡量统计依赖而非仅仅差分。
将两者相加得到子块的运动信息。

基于上面的成对距离,为每个区域选择最相近的若干关系:引入阈值 ,把“前
强(最小距离)的关系”置为 1,其余为 0,得到二值邻接矩阵。这就是“潜在目标区域之间”的运动关系边。
随后,用对齐后的节点特征 (来自前面的 Motion-Vision Alignment)和这里得到的边
组图
,输入 GAT 学习“运动先验知识”特征
。再回灌增强检测分支。
5. Detection Head(检测头)
基础检测损失包括:
回归 (框回归)、分类
(目标/非目标)、IoU/Objectness
。
MoPKL 总损失在基础检测损失之上,再加运动关系损失 与运动对齐损失
:
MoPKL 采用 解耦式检测头(decoupled head):分类分支与回归/IoU 分支分开,有利于收敛与性能。