一文读懂大数据
什么是大数据?为什么要这么定义?
定义
大数据不是单纯 “数据量大”,而是指:当数据规模达到 TB~PB 级,传统数据库和 单机处理能力不足时,需要依靠分布式存储与计算 来进行管理和分析的技术体系。
4V 特征
-
Volume(体量大):TB/PB 级海量数据。
-
Velocity(速度快):数据产生和处理速度极快。
-
Variety(多样性):结构化 + 半结构化 + 非结构化。
-
Value(价值密度低):海量数据中有价值的信息比例低,需要强大的计算能力提炼。
👉 本质:大数据定义的意义,是因为 传统数据库在规模和分析能力上遇到了瓶颈。
大数据 vs 传统数据库(关系型 / 非关系型)
| 特性 | 传统关系型数据库(MySQL/Oracle) | NoSQL(MongoDB/Redis/HBase) | 大数据体系(HDFS + Hive/Spark/Flink) |
|---|---|---|---|
| 数据规模 | 百万 ~ 亿级 | 亿级 ~ 百亿级 | TB ~ PB 级 |
| 数据模型 | 结构化(行存储、表结构固定) | 半结构化/非结构化 | 结构化 + 半结构化(灵活) |
| 处理模式 | OLTP(事务型,实时读写) | 高并发读写、键值/文档/列存 | OLAP(分析型,批/流处理) |
| 一致性事务 | 强一致性,支持事务(ACID) | 多数弱一致性/最终一致性 | 批处理为主,事务支持有限 |
| 扩展方式 | 垂直扩展(加 CPU/内存) | 水平扩展(分片/副本) | 分布式扩展(集群规模无限增长) |
| 典型场景 | 核心业务系统(订单、支付) | 高并发缓存、灵活存储 | 数仓、日志分析、推荐、风控、大屏展示 |
❓ 为什么 MySQL 没有发展成大数据方案?
-
定位不同:MySQL 是 OLTP(事务型),强调事务、点查询;大数据体系是 OLAP(分析型),强调批量统计。
-
存储瓶颈:MySQL 单实例通常 <1TB,分库分表成本高;大数据通过 分布式文件系统(HDFS) 轻松扩展。
-
计算瓶颈:MySQL 查询是单机执行;大数据用 分布式计算引擎(Spark/Flink) 并行处理海量数据。
-
发展方向不同:
-
MySQL + 分布式(RDS、TiDB) → 扩展事务能力(OLTP)。
-
大数据生态 → 专注分析(OLAP)。
-
MySQL 适合做事务型业务数据库,而 大数据体系才是大规模分析的解决方案。
大数据解决的核心问题
-
海量存储:PB 级数据如何存放? → HDFS/Kudu。
-
分布式计算:如何高效分析? → Spark(批)、Flink(流)。
-
数据采集:如何汇聚多源数据? → Kafka、Sqoop、Flume、DataX、Canal。
-
查询接口:如何让用户用 SQL 操作? → Hive、Impala、Doris/StarRocks。
-
实时 & 离线:不同业务需求对应不同处理模式。
大数据知识链路与架构
知识链路
-
存储层:HDFS、Kudu。
-
计算层:Spark(批/流一体)、Flink(实时流)。
-
查询层:Hive(离线)、Impala(交互式)、Doris/StarRocks(实时 OLAP)。
-
消息层:Kafka、Canal。
-
同步层:Sqoop、Flume、DataX。
-
调度治理:Airflow、Azkaban、DolphinScheduler。
-
应用层:BI、报表、大屏、推荐、风控。
架构图(文本版)
数据源(DB/日志/API)│
采集/同步(Sqoop/Flume/Canal/DataX)│
消息队列(Kafka)│
存储层(HDFS/Kudu)│
计算层(Spark 批处理 / Flink 流处理)│
查询/数仓(Hive/Impala/Doris/StarRocks)│
应用层(BI/报表/大屏/推荐/风控)
大数据生态与选型指南
生态组合
1. 经典 Hadoop 生态(离线为主)
-
存储:HDFS
-
计算:MapReduce
-
查询:Hive
-
消息:Kafka
-
同步:Sqoop/Flume
-
特点:稳定但慢,适合传统报表。
2. Hadoop + Spark 生态(主流离线数仓)
-
存储:HDFS/Kudu
-
计算:Spark
-
查询:Hive on Spark、Impala
-
消息:Kafka
-
同步:DataX、Sqoop
-
特点:批处理主流方案。
3. 实时数仓生态(新一代)
-
存储:HDFS + Kudu
-
计算:Flink
-
查询:Flink SQL、Doris/StarRocks
-
消息:Kafka + Canal
-
同步:Flink CDC、DataX
-
特点:低延迟,适合实时大屏、风控。
4. 云原生大数据(免运维)
-
存储:对象存储(S3/OSS)
-
计算:Spark/Flink on K8s
-
查询:Snowflake/Redshift/MaxCompute
-
消息:云 Kafka
-
同步:Glue/DataX Cloud
-
特点:按需付费,适合中小企业。
查询层工具详解与选型
对比表
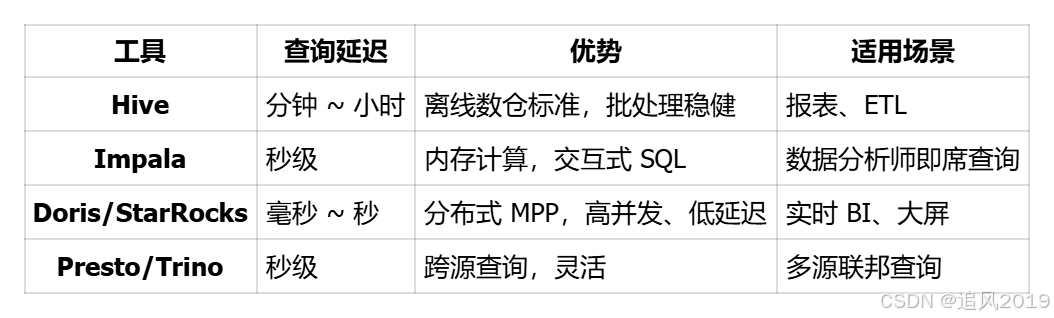
推荐
-
离线报表 / ETL → Hive on Spark。
-
即席查询 / 数据探索 → Impala / Presto。
-
实时 BI / 大屏 → Doris / StarRocks。
-
云环境 → 云数仓(Snowflake、Redshift)。
👉 为什么多个选择?
因为查询需求不同:有的场景能忍延迟(Hive),有的需要实时反馈(Impala/Doris)。
选型建议(场景导向)
-
报表统计 → Hive + Spark + HDFS
-
实时监控/风控 → Flink + Kafka + Doris
-
推荐系统 → Flink(实时特征计算)+ OLAP 引擎
-
中小企业 → 云厂商大数据平台(免运维)
总结
-
大数据的定义 = 用分布式方式解决海量存储和计算瓶颈。
-
和传统数据库的区别 = OLTP vs OLAP,点查 vs 批量分析。
-
核心问题 = 存储、计算、采集、查询、实时性。
-
知识链路 = 存储 → 计算 → 查询 → 消息 → 同步 → 应用。
-
生态选型 = Hadoop(老)、Spark(主流)、Flink(实时)、云数仓(新)。
-
查询层之所以有多工具 = 针对 离线/交互式/实时/多源 不同场景优化。