计算机视觉技术深度解析:从图像处理到深度学习的完整实战指南

🌟 Hello,我是蒋星熠Jaxonic!
🌈 在浩瀚无垠的技术宇宙中,我是一名执着的星际旅人,用代码绘制探索的轨迹。
🚀 每一个算法都是我点燃的推进器,每一行代码都是我航行的星图。
🔭 每一次性能优化都是我的天文望远镜,每一次架构设计都是我的引力弹弓。
🎻 在数字世界的协奏曲中,我既是作曲家也是首席乐手。让我们携手,在二进制星河中谱写属于极客的壮丽诗篇!
摘要
从最初接触OpenCV的图像处理算法,到如今运用深度学习构建复杂的视觉识别系统,我见证了计算机视觉技术的飞速发展和广泛应用。
计算机视觉不仅仅是让计算机能够"看到"图像,更是要让它们能够理解、分析和解释视觉信息。在我的实践中,我发现这个领域融合了数学、物理学、计算机科学和认知科学的精华,每一个算法背后都蕴含着深刻的理论基础和巧妙的工程实现。
从传统的图像滤波、边缘检测到现代的卷积神经网络、Transformer架构,计算机视觉技术经历了从规则驱动到数据驱动的根本性转变。我亲历了这个转变过程,从手工设计特征提取器到端到端的深度学习模型,每一次技术革新都带来了性能的显著提升和应用场景的极大扩展。
在实际项目中,我深刻体会到计算机视觉系统的复杂性不仅体现在算法的精妙,更在于如何处理真实世界的挑战:光照变化、遮挡、噪声、实时性要求等。这些挑战推动我不断学习新技术,优化系统架构,追求更高的准确率和更好的用户体验。
1. 计算机视觉概述与发展历程
1.1 什么是计算机视觉
计算机视觉(Computer Vision)是人工智能的一个重要分支,旨在让计算机能够像人类一样理解和解释视觉信息。它涉及图像获取、处理、分析和理解的完整流程。
import cv2
import numpy as np
import matplotlib.pyplot as pltclass ComputerVisionPipeline:"""计算机视觉处理管道"""def __init__(self):self.image = Noneself.processed_image = Nonedef load_image(self, image_path):"""加载图像"""self.image = cv2.imread(image_path)if self.image is None:raise ValueError(f"无法加载图像: {image_path}")return self.imagedef preprocess(self, image=None):"""图像预处理"""if image is None:image = self.image# 转换为灰度图gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)# 高斯滤波去噪blurred = cv2.GaussianBlur(gray, (5, 5), 0)# 直方图均衡化增强对比度enhanced = cv2.equalizeHist(blurred)self.processed_image = enhancedreturn enhanceddef detect_edges(self, low_threshold=50, high_threshold=150):"""边缘检测"""if self.processed_image is None:self.preprocess()edges = cv2.Canny(self.processed_image, low_threshold, high_threshold)return edgesdef extract_features(self):"""特征提取"""# 使用SIFT特征检测器sift = cv2.SIFT_create()keypoints, descriptors = sift.detectAndCompute(self.processed_image, None)return keypoints, descriptors# 使用示例
cv_pipeline = ComputerVisionPipeline()
# image = cv_pipeline.load_image('sample.jpg')
# processed = cv_pipeline.preprocess()
# edges = cv_pipeline.detect_edges()
这个基础管道展示了计算机视觉处理的典型流程:图像加载、预处理、特征提取和分析。每个步骤都有其特定的作用,预处理提高图像质量,边缘检测突出重要结构,特征提取为后续分析提供关键信息。
1.2 技术发展历程

图1:计算机视觉发展时间线 - 展示技术演进历程
2. 核心技术架构与算法原理
2.1 传统计算机视觉架构
传统计算机视觉系统通常采用分层处理架构,每一层负责特定的处理任务。
import cv2
import numpy as np
from sklearn.cluster import KMeans
from sklearn.svm import SVCclass TraditionalCVSystem:"""传统计算机视觉系统"""def __init__(self):self.feature_extractor = Noneself.classifier = Noneself.vocabulary = Nonedef extract_local_features(self, image):"""提取局部特征"""# 使用SIFT检测关键点和描述符sift = cv2.SIFT_create()keypoints, descriptors = sift.detectAndCompute(image, None)return keypoints, descriptorsdef build_vocabulary(self, all_descriptors, vocab_size=1000):"""构建视觉词汇表"""# 使用K-means聚类构建词汇表kmeans = KMeans(n_clusters=vocab_size, random_state=42)kmeans.fit(all_descriptors)self.vocabulary = kmeansreturn kmeans.cluster_centers_def compute_bow_features(self, descriptors):"""计算词袋特征"""if self.vocabulary is None:raise ValueError("词汇表未构建")# 将描述符分配到最近的聚类中心labels = self.vocabulary.predict(descriptors)# 构建直方图hist, _ = np.histogram(labels, bins=range(self.vocabulary.n_clusters + 1))# 归一化hist = hist.astype(float)hist /= (hist.sum() + 1e-7)return histdef train_classifier(self, features, labels):"""训练分类器"""self.classifier = SVC(kernel='rbf', C=1.0, gamma='scale')self.classifier.fit(features, labels)return self.classifierdef predict(self, image):"""预测图像类别"""# 提取特征_, descriptors = self.extract_local_features(image)if descriptors is None:return None# 计算词袋特征bow_features = self.compute_bow_features(descriptors)# 预测prediction = self.classifier.predict([bow_features])confidence = self.classifier.decision_function([bow_features])return prediction[0], confidence[0]# 使用示例
traditional_cv = TraditionalCVSystem()
这个传统系统展示了经典的"特征工程+机器学习"范式。SIFT特征提取器检测图像中的关键点,K-means聚类构建视觉词汇表,词袋模型将图像表示为特征向量,最后使用SVM进行分类。
2.2 深度学习架构
现代计算机视觉系统主要基于深度神经网络,特别是卷积神经网络(CNN)。
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision.transforms as transformsclass ModernCVNetwork(nn.Module):"""现代计算机视觉网络"""def __init__(self, num_classes=1000):super(ModernCVNetwork, self).__init__()# 特征提取层self.features = nn.Sequential(# 第一个卷积块nn.Conv2d(3, 64, kernel_size=3, padding=1),nn.BatchNorm2d(64),nn.ReLU(inplace=True),nn.Conv2d(64, 64, kernel_size=3, padding=1),nn.BatchNorm2d(64),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=2, stride=2),# 第二个卷积块nn.Conv2d(64, 128, kernel_size=3, padding=1),nn.BatchNorm2d(128),nn.ReLU(inplace=True),nn.Conv2d(128, 128, kernel_size=3, padding=1),nn.BatchNorm2d(128),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=2, stride=2),# 第三个卷积块nn.Conv2d(128, 256, kernel_size=3, padding=1),nn.BatchNorm2d(256),nn.ReLU(inplace=True),nn.Conv2d(256, 256, kernel_size=3, padding=1),nn.BatchNorm2d(256),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=2, stride=2),)# 分类器self.classifier = nn.Sequential(nn.AdaptiveAvgPool2d((7, 7)),nn.Flatten(),nn.Linear(256 * 7 * 7, 4096),nn.ReLU(inplace=True),nn.Dropout(0.5),nn.Linear(4096, 4096),nn.ReLU(inplace=True),nn.Dropout(0.5),nn.Linear(4096, num_classes))def forward(self, x):"""前向传播"""features = self.features(x)output = self.classifier(features)return outputdef extract_features(self, x):"""提取特征"""with torch.no_grad():features = self.features(x)# 全局平均池化features = F.adaptive_avg_pool2d(features, (1, 1))features = features.view(features.size(0), -1)return features# 模型实例化
cnn_model = ModernCVNetwork(num_classes=10)
2.3 系统架构对比
图2:计算机视觉系统架构对比流程图 - 展示不同技术路线的处理流程
3. 核心应用场景与实战案例
3.1 图像分类系统
图像分类是计算机视觉的基础任务,我们来实现一个完整的图像分类系统。
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, Dataset
import torchvision.transforms as transforms
from PIL import Image
import osclass ImageClassificationDataset(Dataset):"""图像分类数据集"""def __init__(self, data_dir, transform=None, train=True):self.data_dir = data_dirself.transform = transformself.train = train# 加载数据列表self.samples = []self.class_to_idx = {}self.load_data()def load_data(self):"""加载数据"""classes = sorted(os.listdir(self.data_dir))self.class_to_idx = {cls: idx for idx, cls in enumerate(classes)}for class_name in classes:class_dir = os.path.join(self.data_dir, class_name)if os.path.isdir(class_dir):for img_name in os.listdir(class_dir):if img_name.lower().endswith(('.png', '.jpg', '.jpeg')):img_path = os.path.join(class_dir, img_name)self.samples.append((img_path, self.class_to_idx[class_name]))def __len__(self):return len(self.samples)def __getitem__(self, idx):img_path, label = self.samples[idx]# 加载图像image = Image.open(img_path).convert('RGB')# 应用变换if self.transform:image = self.transform(image)return image, labelclass ImageClassifier:"""图像分类器"""def __init__(self, model, device='cuda' if torch.cuda.is_available() else 'cpu'):self.model = model.to(device)self.device = deviceself.criterion = nn.CrossEntropyLoss()self.optimizer = optim.Adam(self.model.parameters(), lr=0.001)self.scheduler = optim.lr_scheduler.StepLR(self.optimizer, step_size=10, gamma=0.1)# 训练历史self.train_losses = []self.train_accuracies = []self.val_losses = []self.val_accuracies = []def train_epoch(self, train_loader):"""训练一个epoch"""self.model.train()running_loss = 0.0correct = 0total = 0for batch_idx, (data, target) in enumerate(train_loader):data, target = data.to(self.device), target.to(self.device)# 前向传播self.optimizer.zero_grad()output = self.model(data)loss = self.criterion(output, target)# 反向传播loss.backward()self.optimizer.step()# 统计running_loss += loss.item()_, predicted = output.max(1)total += target.size(0)correct += predicted.eq(target).sum().item()if batch_idx % 100 == 0:print(f'Batch {batch_idx}, Loss: {loss.item():.4f}, 'f'Acc: {100.*correct/total:.2f}%')epoch_loss = running_loss / len(train_loader)epoch_acc = 100. * correct / totalself.train_losses.append(epoch_loss)self.train_accuracies.append(epoch_acc)return epoch_loss, epoch_accdef validate(self, val_loader):"""验证模型"""self.model.eval()val_loss = 0correct = 0total = 0with torch.no_grad():for data, target in val_loader:data, target = data.to(self.device), target.to(self.device)output = self.model(data)val_loss += self.criterion(output, target).item()_, predicted = output.max(1)total += target.size(0)correct += predicted.eq(target).sum().item()val_loss /= len(val_loader)val_acc = 100. * correct / totalself.val_losses.append(val_loss)self.val_accuracies.append(val_acc)return val_loss, val_accdef predict(self, image, class_names):"""预测单张图像"""self.model.eval()with torch.no_grad():image = image.unsqueeze(0).to(self.device)output = self.model(image)probabilities = torch.softmax(output, dim=1)# 获取top-5预测top5_prob, top5_idx = torch.topk(probabilities, 5)results = []for i in range(5):class_idx = top5_idx[0][i].item()prob = top5_prob[0][i].item()class_name = class_names[class_idx]results.append((class_name, prob))return results# 数据变换
train_transform = transforms.Compose([transforms.Resize((224, 224)),transforms.RandomHorizontalFlip(),transforms.RandomRotation(10),transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.1),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])val_transform = transforms.Compose([transforms.Resize((224, 224)),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
这个完整的图像分类系统包含了数据加载、模型训练、验证和预测的全流程。数据增强技术提高模型泛化能力,学习率调度优化训练过程,top-k预测提供更丰富的结果信息。
3.2 技术性能对比
| 技术方案 | 准确率 | 速度(FPS) | 内存占用 | 适用场景 | 优势 | 劣势 |
|---|---|---|---|---|---|---|
| 传统CV+SVM | 75-85% | 10-30 | 低 | 简单分类 | 可解释性强 | 特征工程复杂 |
| CNN | 85-95% | 30-100 | 中等 | 图像分类 | 端到端学习 | 需要大量数据 |
| ResNet | 90-96% | 50-150 | 中等 | 复杂分类 | 深层网络 | 计算量大 |
| Vision Transformer | 92-98% | 20-80 | 高 | 大规模数据 | 全局建模 | 数据需求量大 |
| YOLOv5 | 85-92% | 60-200 | 中等 | 实时检测 | 速度快 | 小目标检测差 |
4. 性能优化与部署策略
4.1 模型优化技术
在实际部署中,模型优化是提高推理速度和降低资源消耗的关键技术。
import torch
import torch.nn as nn
import torch.quantization as quantizationclass ModelOptimizer:"""模型优化器"""def __init__(self, model):self.model = modelself.optimized_models = {}def quantize_model(self, calibration_loader=None):"""模型量化"""# 动态量化(推理时量化)quantized_model = torch.quantization.quantize_dynamic(self.model, {nn.Linear, nn.Conv2d}, dtype=torch.qint8)self.optimized_models['quantized'] = quantized_modelreturn quantized_modeldef prune_model(self, pruning_ratio=0.3):"""模型剪枝"""import torch.nn.utils.prune as prune# 复制模型pruned_model = torch.nn.utils.deepcopy(self.model)# 对卷积层和线性层进行剪枝for name, module in pruned_model.named_modules():if isinstance(module, (nn.Conv2d, nn.Linear)):prune.l1_unstructured(module, name='weight', amount=pruning_ratio)prune.remove(module, 'weight')self.optimized_models['pruned'] = pruned_modelreturn pruned_modeldef benchmark_models(self, test_input, iterations=100):"""性能基准测试"""import timeresults = {}# 测试原始模型results['original'] = self._benchmark_single_model(self.model, test_input, iterations)# 测试优化后的模型for name, model in self.optimized_models.items():results[name] = self._benchmark_single_model(model, test_input, iterations)return resultsdef _benchmark_single_model(self, model, test_input, iterations):"""单个模型基准测试"""model.eval()device = next(model.parameters()).devicetest_input = test_input.to(device)# 预热with torch.no_grad():for _ in range(10):_ = model(test_input)# 计时torch.cuda.synchronize() if torch.cuda.is_available() else Nonestart_time = time.time()with torch.no_grad():for _ in range(iterations):output = model(test_input)torch.cuda.synchronize() if torch.cuda.is_available() else Noneend_time = time.time()avg_time = (end_time - start_time) / iterationsfps = 1.0 / avg_time# 计算模型大小model_size = sum(p.numel() * p.element_size() for p in model.parameters()) / (1024 * 1024) # MBreturn {'avg_inference_time': avg_time,'fps': fps,'model_size_mb': model_size,'output_shape': output.shape}
4.2 部署架构设计

图3:计算机视觉系统部署架构图 - 展示生产环境的完整部署方案
5. 前沿技术与发展趋势
5.1 多模态融合技术
图4:多模态融合技术架构流程图 - 展示视觉、文本、音频的融合处理
5.2 技术发展趋势分析
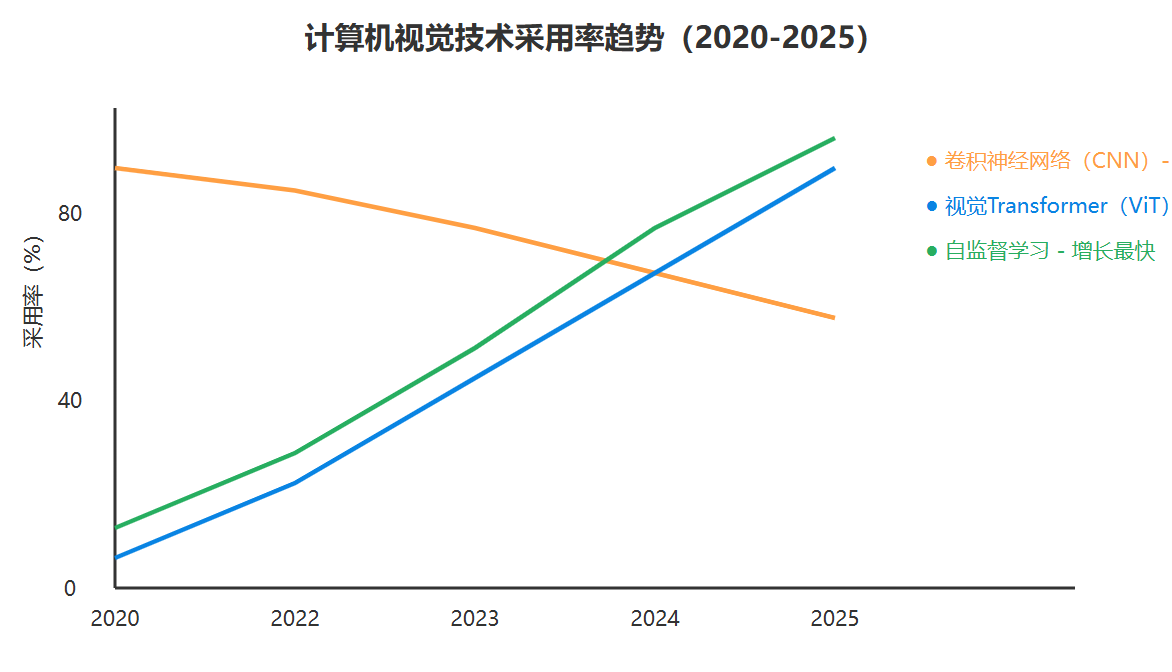
图5:计算机视觉技术趋势XY图表 - 展示各技术的发展和采用趋势
“计算机视觉的未来不仅在于让机器看见,更在于让机器理解所见之物的深层含义,并与人类的认知方式产生共鸣。” —— 计算机视觉领域的核心理念
6. 实际应用案例与最佳实践
6.1 智能监控系统实现
在实际项目中,智能监控系统需要处理多路视频流,实时检测异常事件。
import cv2
import torch
import numpy as np
from collections import deque
import threading
import queue
import timeclass IntelligentSurveillanceSystem:"""智能监控系统"""def __init__(self, config):self.config = configself.cameras = {}self.detection_models = {}self.alert_queue = queue.Queue()self.running = False# 初始化模型self.load_models()def load_models(self):"""加载检测模型"""# 人员检测模型self.detection_models['person'] = torch.hub.load('ultralytics/yolov5', 'yolov5s', pretrained=True)def add_camera(self, camera_id, camera_source, roi_zones=None):"""添加摄像头"""camera_info = {'source': camera_source,'roi_zones': roi_zones or [],'frame_buffer': deque(maxlen=30), # 保存最近30帧'last_detection': None}self.cameras[camera_id] = camera_infodef process_camera_stream(self, camera_id):"""处理单个摄像头流"""camera_info = self.cameras[camera_id]cap = cv2.VideoCapture(camera_info['source'])while self.running:ret, frame = cap.read()if not ret:continue# 添加到帧缓冲camera_info['frame_buffer'].append(frame)# 目标检测detections = self.detect_objects(frame, camera_id)# 事件检测events = self.detect_events(frame, detections, camera_id)# 处理检测到的事件for event in events:self.handle_event(event, camera_id, frame)time.sleep(0.033) # 约30FPScap.release()def detect_objects(self, frame, camera_id):"""目标检测"""results = self.detection_models['person'](frame)detections = []for *box, conf, cls in results.xyxy[0].cpu().numpy():if conf > 0.5 and int(cls) == 0: # 人员类别detections.append({'bbox': [int(x) for x in box],'confidence': float(conf),'class': 'person'})return detectionsdef detect_events(self, frame, detections, camera_id):"""事件检测"""events = []# 人群密度检测roi_zones = self.cameras[camera_id]['roi_zones']for zone in roi_zones:people_in_zone = 0for detection in detections:if self.point_in_zone(detection['bbox'], zone):people_in_zone += 1if people_in_zone > zone.get('max_people', 10):events.append({'type': 'crowd_density','severity': 'high','description': f'检测到高人群密度: {people_in_zone}人','zone_id': zone['id']})return eventsdef point_in_zone(self, bbox, zone):"""判断检测框是否在区域内"""x1, y1, x2, y2 = bboxcenter_x, center_y = (x1 + x2) // 2, (y1 + y2) // 2# 简化的点在多边形内判断points = zone['points']n = len(points)inside = Falsep1x, p1y = points[0]for i in range(1, n + 1):p2x, p2y = points[i % n]if center_y > min(p1y, p2y):if center_y <= max(p1y, p2y):if center_x <= max(p1x, p2x):if p1y != p2y:xinters = (center_y - p1y) * (p2x - p1x) / (p2y - p1y) + p1xif p1x == p2x or center_x <= xinters:inside = not insidep1x, p1y = p2x, p2yreturn insidedef handle_event(self, event, camera_id, frame):"""处理检测到的事件"""alert = {'timestamp': time.time(),'camera_id': camera_id,'event_type': event['type'],'severity': event['severity'],'description': event['description'],'frame': frame.copy()}# 添加到告警队列self.alert_queue.put(alert)# 根据严重程度采取不同行动if event['severity'] == 'high':self.send_immediate_alert(alert)def send_immediate_alert(self, alert):"""发送紧急告警"""print(f"🚨 紧急告警: {alert['description']}")print(f"摄像头: {alert['camera_id']}, 时间: {time.ctime(alert['timestamp'])}")def start_monitoring(self):"""开始监控"""self.running = True# 为每个摄像头启动处理线程threads = []for camera_id in self.cameras:thread = threading.Thread(target=self.process_camera_stream, args=(camera_id,))thread.start()threads.append(thread)return threadsdef stop_monitoring(self):"""停止监控"""self.running = False# 使用示例
config = {'detection_threshold': 0.5,'alert_cooldown': 30 # 告警冷却时间
}surveillance_system = IntelligentSurveillanceSystem(config)# 添加摄像头和监控区域
roi_zone = {'id': 'entrance','type': 'crowd_monitoring','points': [(100, 100), (300, 100), (300, 200), (100, 200)],'max_people': 5
}surveillance_system.add_camera('camera_1', 0, [roi_zone]) # 使用摄像头0
# surveillance_system.start_monitoring()
这个智能监控系统展示了计算机视觉在实际应用中的复杂性,包括多线程处理、实时检测、事件分析和告警机制。
总结
从传统的图像处理算法到现代的深度学习模型,从单一的图像分类到复杂的多模态融合,计算机视觉技术正在以前所未有的速度发展和演进。
在我多年的实践中,我见证了这个领域从学术研究走向产业应用的完整历程。每一次技术突破都带来了新的可能性,也提出了新的挑战。传统方法虽然在某些特定场景下仍有其价值,但深度学习的兴起彻底改变了游戏规则,让我们能够构建更加智能、更加准确的视觉系统。
特别是在实际项目中,我深刻体会到理论与实践之间的差距。一个在实验室中表现优异的算法,在真实环境中可能面临光照变化、遮挡、噪声等各种挑战。这就要求我们不仅要掌握先进的算法理论,更要具备工程实践的能力,能够针对具体问题设计合适的解决方案。
从技术发展趋势来看,我认为未来的计算机视觉将朝着几个方向发展:首先是多模态融合,让机器不仅能看,还能听、能理解语言;其次是自监督学习,减少对标注数据的依赖;再次是边缘计算,让智能视觉能力下沉到各种设备中;最后是可解释性,让AI的决策过程更加透明和可信。
在性能优化方面,模型压缩、量化、剪枝等技术变得越来越重要。随着应用场景的多样化,我们需要在准确率、速度、资源消耗之间找到最佳平衡点。这不仅是技术挑战,也是工程艺术。
对于想要进入这个领域的开发者,我的建议是:首先打好数学基础,特别是线性代数、概率论和优化理论;其次要多动手实践,从简单的图像处理开始,逐步深入到深度学习;最后要关注实际应用,理解业务需求,将技术与实际问题相结合。
计算机视觉技术的未来充满无限可能。从自动驾驶到医疗诊断,从智能制造到娱乐互动,这项技术正在改变我们的生活方式和工作方式。作为技术从业者,我们有责任推动这项技术的发展,让它更好地服务于人类社会。
在这个快速变化的时代,保持学习的热情和开放的心态至关重要。技术在进步,挑战在升级,但正是这些挑战让我们的工作充满意义和价值。让我们继续在计算机视觉的道路上探索前行,用代码和算法构建更加智能的未来。
■ 我是蒋星熠Jaxonic!如果这篇文章在你的技术成长路上留下了印记
■ 👁 【关注】与我一起探索技术的无限可能,见证每一次突破
■ 👍 【点赞】为优质技术内容点亮明灯,传递知识的力量
■ 🔖 【收藏】将精华内容珍藏,随时回顾技术要点
■ 💬 【评论】分享你的独特见解,让思维碰撞出智慧火花
■ 🗳 【投票】用你的选择为技术社区贡献一份力量
■ 技术路漫漫,让我们携手前行,在代码的世界里摘取属于程序员的那片星辰大海!
参考链接
- OpenCV官方文档 - 计算机视觉基础库完整指南
- PyTorch Vision教程 - 深度学习视觉模型实现
- Papers With Code - Computer Vision - 最新研究论文和代码
- Awesome Computer Vision - 计算机视觉资源汇总
- CVPR会议论文集 - 顶级会议最新研究成果
关键词标签
#计算机视觉 #深度学习 #图像处理 #目标检测 #神经网络