WALL-OSS——点燃QwenVL 2.5在具身空间中的潜力:VL FFN可预测子任务及离散动作token,Action FNN则预测连续动作
前言
如此文《π0.5的KI改进版(已部分开源)——知识隔离:让VLM在不受动作专家负反馈的同时,输出离散动作token,并根据反馈做微调,而非冻结VLM》开头的最后所说,25年9.9日出差路上,惊喜的发现,π0.5做了部分开源
提到本次出差,确实是密集拜访客户、合作伙伴
- 周二南京(海因邦姚),周三上海(凯傅透)
9.11杭州(宇树)、徐州
2/3是见我司自己的客户,1/3是合伙商- 随后,9.15宁波,9.16无锡
在宁波的时候,除了拜访一工厂之外,还约见了两位在宁波做汽车的
1 他俩都因我博客认识,我当时还感慨,我博客也算是陪伴、帮助了好几代人,比如
10 11最早的数据结构、算法
12-22年的机器学习 深度学习
23年的大模型
24年起的具身智能,且如现场其中一位朋友所说的,现在车企会把具身模型迁移到自驾中
2 在无锡的时候,则约见了一做自动加油机器人的朋友,个人看好轮式人形在自动加油、充电场景中的应用,并准备把该方向作为我司具身落地的五大方向之一- 本来这周还计划去趟北京的,但因为这周末9 20/9 21,我司长沙分部将举办人形二次开发线下营,故改到下周 再去北京
巧的是,国内一家具身公司自变量机器人则于前一天开源了其自家的模型WALL-OSS,其与π0.5还是有一定的相似性的
本文特此来解读下
第一部分 点燃VLMs在具身空间中的潜力
1.1 引言与相关工作
1.1.1 引言
如原论文所说,在具身环境中,视觉–语言–动作(VLA)对齐数据稀缺且异质,使得从零开始的训练难以在动作模态以及跨模态关联中实现泛化。这一现状促使研究者将强大的视觉-语言模型(VLM)主干迁移到动作空间,例如 OpenVLA(39)和 π0(14),这些方法在学习跨模态对应关系的同时对连续动作建模,从而将视觉和语言先验(VL 先验)迁移到动作空间
一种简单的微调策略是:在预训练的视觉语言模型(VLM)上附加一个动作头,并通过机器人轨迹进行监督。然而,这通常会导致权重严重漂移,从而削弱原有的视觉语言先验
π0.5的“知识隔离”策略通过尽量减少对VLM参数的扰动来保留预训练能力;但这种松散耦合的架构设计限制了语义与控制之间的绑定关系,并且由于VLM本身在具身空间中的能力有限,在执行超出视觉语言先验范围的动作时表现较差
总体而言,利用当前VLM进行动作学习存在以下三个根本性鸿沟,因此面临巨大挑战:
- 模态和数据规模的差距
得益于计算机视觉的长期发展,视觉编码器能够提取特征,过滤高频噪声,同时保留高级语义;这些压缩后的视觉token,与已经高度压缩的文本模态一起,使得在经过大规模网页文本-图像/视频对训练后,可以通过CLIP及相关多模态模型和视觉语言模型(VLMs)实现对齐
相比之下,在具身空间中的动作在三维空间和时间上是连续的;与视觉模态相比,其特征提取缺乏长期表征研究,并且其与文本的高层语义对齐缺乏大规模数据的驱动
此外,在具身场景中,多种子任务和具体场景级动作描述通常被抽象为单一的高层指令,这进一步增加了跨模态关联的难度。基于流水线的智能体(先用大语言模型分解指令,再调用技能库(6,44))受限于不可微分接口和误差累积,在长时序任务中的成功率下降
此外,一些方法如3D-VLA(79)和PointVLA(41)尝试使用三维视觉模态作为二维视觉与动作之间的桥梁,但三维数据同样难以获取,而当前的三维视觉基础模型如VGGT(69)和π3(72)在细粒度动作预测所需的精度上仍然存在不足 - 预训练分布的差异
如图1所示,在大规模预训练之后,大型语言模型(LLM)在文本模态中基本能够满足具身语义的需求(如能够进行问答)

然而,对于视觉模态,具身数据通常包含第一人称视角、鱼眼成像以及自遮挡,这些特征与互联网图像有很大不同。即使经过大规模预训练,视觉语言模型(VLM)在具身场景(例如具身视觉问答)中的需求覆盖仍然有限
此前的分析也报告了其在空间推理、具身场景理解和进度跟踪等方面的不足(36,70) - 训练目标的差异
LLMs/VLMs 以离散序列的下一个 token 似然作为训练目标,而动作轨迹则是连续的高频信号,更适合采用条件生成目标(如扩散模型(32,22)或流匹配(46))进行建模,这些方法通过学习得分/速度场将基础分布迁移到动作分布
然而,将这些目标直接嫁接到 VLMs 上会加剧 token 化鸿沟和独立性假设,从而导致灾难性的性能下降,削弱了语言-动作的对齐与泛化能力。这一现象类似于当前图像/视频领域统一生成与理解时面临的挑战
一些方法(如 π0)尝试在自回归范式下对动作进行高层次离散化,以便将动作 token 与文本 token 对齐,随后通过扩散/流匹配中的动作噪声与中间VLM 表征的自注意力机制交互,生成连续动作信号(14)
然而,这类松散耦合的设计仍未能学到紧密的文本-动作绑定,导致指令跟随能力不足
为了解决上述问题,X SQUARE机器人团队提出了WALL-OSS,这是一个高度耦合的VLA基础模型及其训练方案
- 其对应的paper地址为:Igniting VLMs toward the Embodied Space
其对应的作者包括
Andy Zhai, Brae Liu, Bruno Fang, Chalse Cai, Ellie Ma, Ethan Yin, Hao Wang∗
Hugo Zhou, James Wang,Lights Shi, Lucy Liang†
Make Wang, Qian Wang, Roy Gan, Ryan Yu, Shalfun Li, Starrick Liu, Sylas Chen,
Vincent Chen, Zach Xu
†Project Lead,∗Correspondence - 其对应的项目地址为:x2robot.com/en/research
其对应的GitHub地址为:github.com/X-Square-Robot/wall-x
具体而言
- 他们首先引入了一种高度耦合的专家混合(MoE)架构与训练策略,在不同阶段根据不同的动作建模方法(离散或连续)激活不同的专家和权重,从而弥合训练目标的差距
说白了,即是两个专家团队共享一部分核心认知能力(比如注意力机制SA),但在执行各自任务时(或离散动作建模、或连续动作建模)会调用自己的专属网络——VL FFN或Action FFN
上图 没咋看明白 没事,具体下文会详解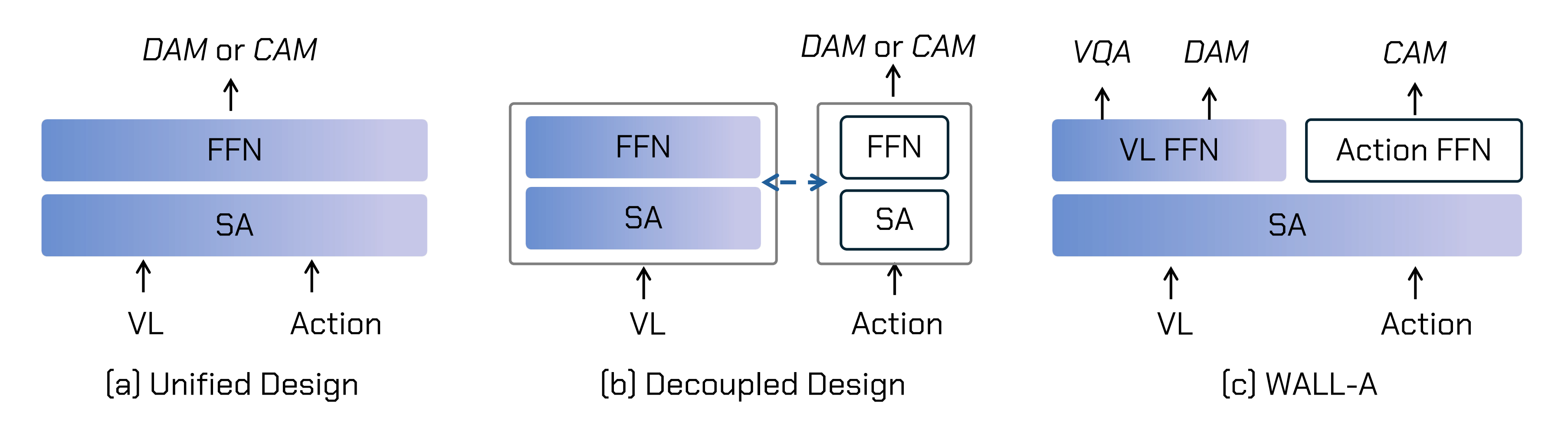
- 且将多模态任务与VQA任务及其针对具身、空间定位和进度建模定制的数据集相结合,以弥补VLM在具身场景下的不足,并在VLM输出空间中植入离散化的动作先验,实现粗粒度的动作监督,从而弥合VLM预训练分布的差异
基于这些设计,作者构建了统一的CoT前向映射,使模型能够将任务从高层语义分解到细粒度动作,促使模型理解该链条中各层级之间的关系,从而弥合模态间的差距
1.1.2 相关工作
首先,VLA 基线方法通过将动作编码为离散 token 或学习连续输出头,将 VLM与机器人控制对齐,涵盖了
- 扩散和流匹配等连续模型(如 DP、Octo、π0、π0.5 (23,65,14,33))
- 或采用压缩的离散 token 化方法(如 ACT、OpenVLA、FAST、RT-2 (78,39,57,84))
作者的方案遵循“离散先验→连续控制”的流程:首先将离散动作先验植入 VLM 的输出空间(启发阶段),随后为高频动作优化流匹配输出头(集成阶段),同时通过静态路由的紧耦合混合专家(MoE)机制,强化语言与动作的强绑定
其次,对于利用机器人数据进行多模态协同训练
- 为抵消机器人轨迹的成本与覆盖范围限制,多模态与跨源协同训练是一种有效方法。从视觉语言模型(VLM)初始化,并联合训练网络图片-文本、对话、长视频以及多种形态的机器人数据,能够在注入具身空间语义的同时,保持开放世界的语言-视觉能力
- 跨形态与跨环境的聚合进一步提升了迁移能力(25,65,14,33,35,11,15)
作者的方法强调以统一格式进行具身认知监督,将指令、推理、子任务与连续动作关联起来;通过系统性地统一开源动作数据,在两个阶段中采用分布混合与配额机制,限制模型漂移
并采用紧密耦合的专家混合模型(MoE)及静态路由,将异构监督转化为动作通道上的可控增益,从而提升模型在陌生场景及不同具身形态下的鲁棒性
最后,对于语言推理与子任务分解
- 对于长时序任务,将高层次推理与低层次控制相结合能够提升成功率。与采用流水线设计、将VLM规划器与独立控制器配对的方法不同(如SayCan(7)和Code-as-Policies(43);以及分层变体如Hi Robot(9)和GR00T N1(8))
- 作者采用了单一模型的Uni-CoT方案,实现从指令到CoT、子任务及连续动作的端到端映射。这种方法补充了分层与动作语法方法(如RT-H(13))、最新的CoT控制方法(77,76)和提示框架(53),以及面向动作的指令微调(54)与分层目标条件策略(42)
该模型可以包含或跳过中间步骤,并将推理与执行交错进行。结合他们的两阶段课程设计与紧密耦合的路由机制,这一统一架构减少了接口引发的误差累积,并增强了复杂长时序操作任务中的进度感知与指令遵循能力
1.2 WALL-OSS
1.2.1 模型架构
图2(a)和(b)展示了现有VLA模型的结构范式
- 在(a)中,混合设计直接将原始的 VLM 扩展为通过离散动作建模DAM——遵循下一个token预测范式,如 RT-2(84)和 OpenVLA(39)所示,或连续动作建模CAM来对动作进行建模
然而,动作监督会显著扰动原始视觉语言模型(VLM)的权重分布,导致动作指令跟随和泛化能力大幅下降,从而出现对动作的过拟合 - 在(b)中,解耦设计采用了一个独立的动作预测分支,该分支与 VLM 进行交互并提取信息,正如 π0(14)所示
其局限性在于,视觉和语言仅作为动作生成的辅助信号,这种松散耦合的架构削弱了动作预测的指令跟随能力——当然了,π0.5 改进了π0的指令遵循能力 - WALL-OSS的架构通过引入专家混合(MoE)(64)设计,并为不同训练任务分配专用的前馈网络(FFN),从而形成紧密耦合的跨模态结构,有效提升了模型的跨模态关联能力
下图图3展示了WALL-OSS的整体架构。作者采用QwenVL 2.5-3B作为主要骨干网络
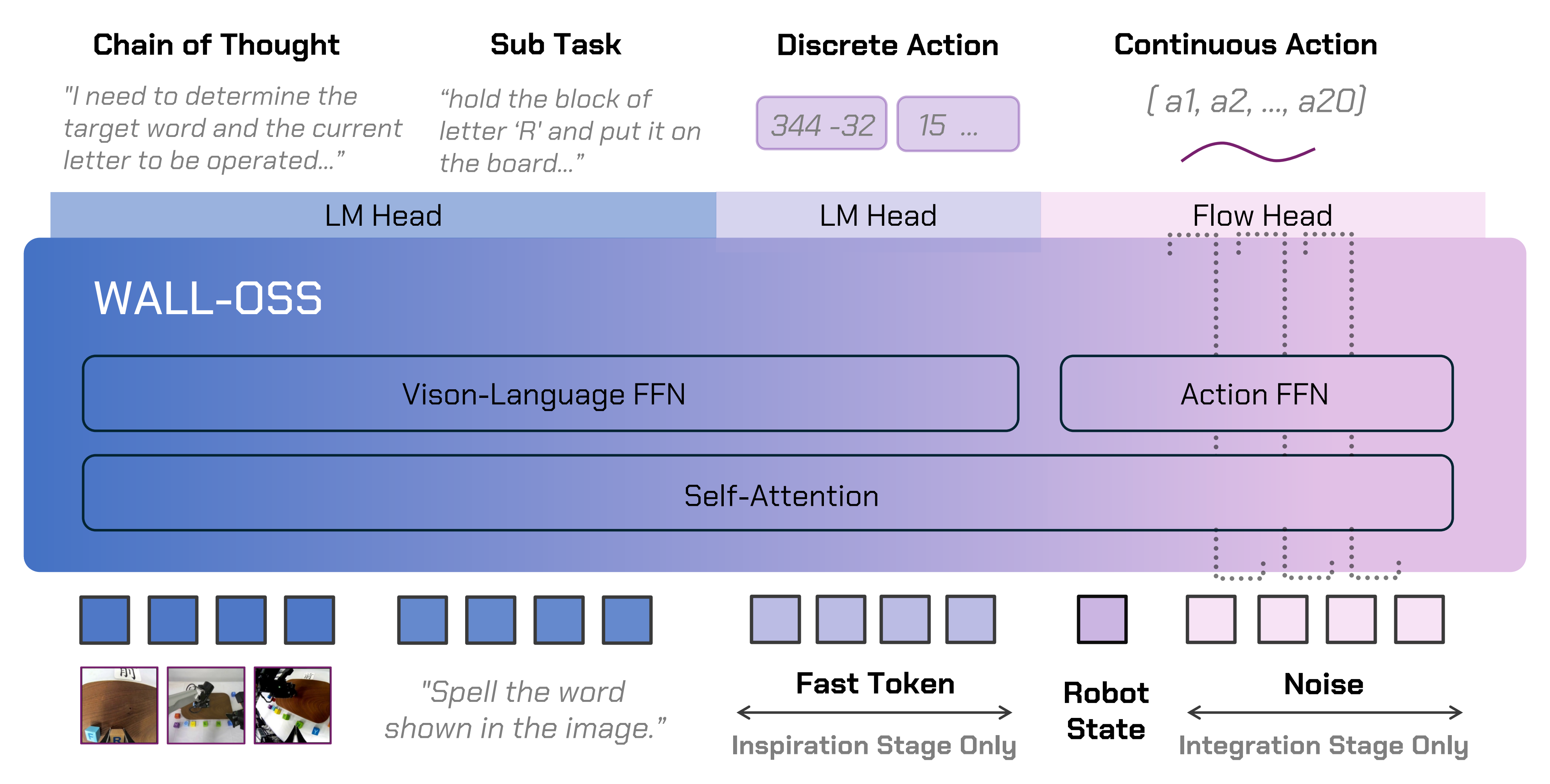
该模型以视觉输入(包括第一视角和手臂安装摄像头视角)以及文本指令作为输入,根据训练阶段生成不同的输出,同时始终以相同的多模态输入为条件。设,
分别表示输入对及其VLM编码
1.2.2 训练方法:先启发、后集成
在对VLMs进行预训练之后,作者的预训练过程包括两个主要部分:VLM的启发以及三模态(视觉-语言-动作)的集成,如下图图4所示
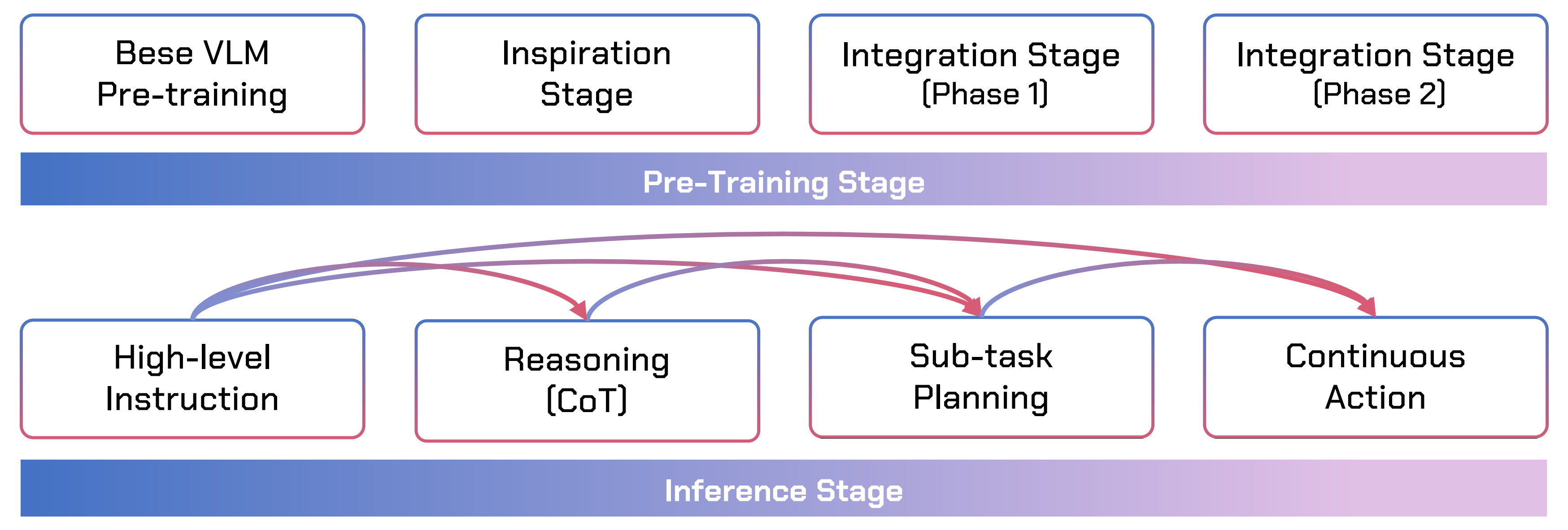
首先是启发阶段
作者首先复用预训练视觉语言模型(VLM)的原始前馈网络(FFN),并通过引入具身视觉问答(VQA)来增强机器人环境中的空间推理能力
- 训练目标包括掩码语言建模、图像/视频-文本对比学习、指令跟随以及时序顺序/因果关系建模,以构建强有力的具身视觉语言先验
- 同时,作者引入了一个离散动作目标,将文本token与通过FAST分词(参见π0-FAST (14))获得的离散动作token对齐:
该阶段使VLM具备粗略的、语义基础上的动作感知能力;其输出包括链式思维推理、子任务预测以及离散FAST动作token
比如
- 高级指令:“整理一下书桌”
- 思维链CoT:“我需要先识别哪些是垃圾,哪些是书本,然后把垃圾扔掉,再把书本摆放整齐”
- 子任务规划及离散动作token:
第一步,拿起桌上的废纸团
第二步,把它移动到垃圾桶上方
第三步,松开手爪
总之,具身VQA提升了VLM在具身环境中的空间理解能力,而FASTtoken预测则提供了粗略的动作理解。这为初始VLM注入了基本的具身推理与动作感知能力
其次是集成阶段
在已有先验的基础上,作者用流匹配实现的连续动作建模替代了离散动作预测,并将该阶段划分为两个阶段:
- 冻结VLM,仅训练Action FFN下的流头
- 解冻VLM,进行联合优化
在集成阶段,视觉、语言和动作表征通过注意力机制进行交互,同时采用静态路由器将以动作为中心的特征引导到Action FFN,将视觉-语言特征引导到Vision–Language FFN,而不是使用学习型的softmax/top-k路由器
在第一阶段——冻结VLM,仅训练Action FFN下的流头,作者生成带噪声的样本并回归速度场
通过梯度路由(对前一阶段的VLM执行停止梯度以缓解灾难性遗忘),以及
(仅优化flow head和Action FFN)
来自Inspiration阶段的监督在此稳定了跨模态注意力,保留了视觉-语言先验,并为连续动作提供了可靠的初始化
在第二阶段,作者采用相同的流匹配目标对两个模块进行联合优化,并通过梯度路由和
(解冻VLM并与动作分支联合训练)
这种集成方式使得在高度耦合的架构中能够输出细粒度的动作结果,促使模型融合多模态信息,高效完成多模态任务,从而实现不同模态间的对齐
此外,作者的方法将链式思维推理的概念从传统狭义的CoT(即大语言模型中的逐步文本推理)推广到广义的CoT,覆盖了从语义到感知-运动的完整谱系:指令→推理(CoT)→子任务规划→连续动作。这一统一的表述使得模型能够在分层抽象级别之间实现任意前向映射,从而在单一可微分框架内,无缝衔接高层推理与低层执行
- 毕竟现有方法通常将这些层级分解为流水线式或多模块系统,其中指令首先传递给规划器以生成高层次计划,随后由控制器执行,例如 Hi Robot(9)和 GR00T N1(8)
尽管这些范式在短期内能够显著降低训练和执行的难度,但它们引入了不可微分的接口,系统性能受限于各模块的能力,并且容易在各阶段累积误差- 相比之下,WALL-OSS采用了一个单一的端到端模型,该模型能够联合学习跨抽象层级的映射,支持灵活的正向任意映射
具体而言,该模型可以根据任务复杂性和上下文需求,自适应地利用完整的中间推理步骤,或直接将指令映射为动作形式上,设
表示视觉输入,
为语言指令,
为可选的思维链,
为目标动作轨迹。Uni-CoT 训练一个统一的预测器
,采用路径丢弃目标,使模型能够灵活地基于中间推理或跳过中间推理进行条件推断
其中
是一个具有监督
的具身感知 VQA 头。该公式使得在单一模型中同时实现全链路和直接
训练成为可能,从而确保端到端的可微分性,同时保留推理的灵活性
通过涵盖不同语义层级的映射,Uni-CoT
- 通过具身 VQA 增强了 VLMs 的空间理解能力,从而实现更强的定位和动作预测
- 显著提升了长时序任务的成功率和指令遵循能力
此外,如图 4 下部所示
在推理阶段,Uni-CoT 能够自适应地决定是否调用 CoT/子任务分解,甚至可以将推理与执行交替进行——在继续推理的同时,为已完成的子任务发出动作指令——从而为实时人机交互提供灵活的异步控制
// 待更