Hive内部表外部表分区分桶数据类型
整体架构图
一、Hive表
1、Hive内部表(Internal Table)
由Hive完全管理数据生命周期,删除表时会同时删除元数据和底层数据(HDFS);
2、外部表(External Table)
仅管理元数据,删除表时只删除元数据,底层数据(HDFS)保留。
3、二者核心区别如下:
1) 数据控制权
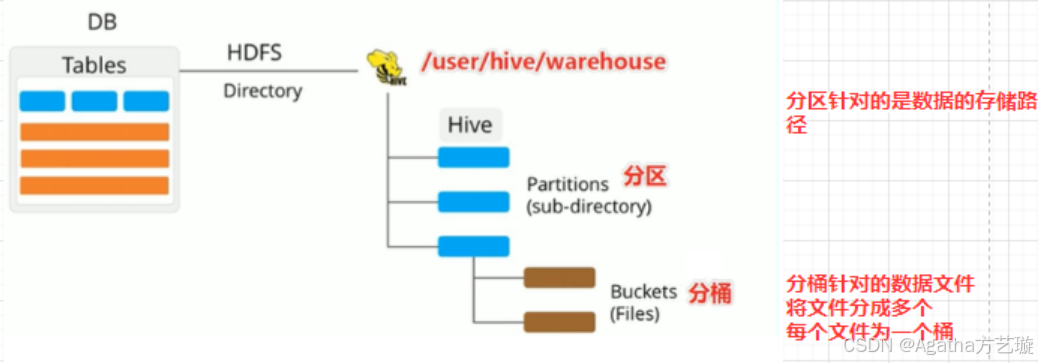
内部表:数据存储在Hive默认仓库目录(如 /user/hive/warehouse/ ),Hive拥有绝对控制权。
外部表:数据存储在用户指定的自定义路径,Hive不独占数据,其他工具可共享访问。
2)删除操作影响
内部表:执行 DROP TABLE 时,元数据和底层HDFS数据会被同时删除。
外部表:执行 DROP TABLE 时,仅删除元数据(表结构),HDFS上的原始数据不会被删除。
3)数据加载逻辑
内部表:使用 LOAD DATA 时,默认将数据移动(Move)到Hive仓库目录,原路径数据消失。
外部表:使用 LOAD DATA 时,默认将数据复制(Copy)到指定路径,原数据保留(也可通过 LOCATION 直接关联已有数据,无需加载)。
4)适用场景
内部表:适合数据仅由Hive使用、无需共享的场景(如临时中间表、测试表)。
外部表:适合数据需多工具共享(如Spark、Flink)、需长期保留或多表关联同一数据源的场景。
二、Hive分区
Hive分区是将大表数据按指定列(如日期、地区)拆分存储的机制,核心目的是缩小查询扫描范围,提升查询效率。
1、核心原理
通过在创建表时指定 PARTITIONED BY 子句,Hive会在HDFS上为每个分区创建独立的子目录(格式: 分区列=值/ )。查询时指定分区条件,可直接定位到对应目录,避免全表扫描。
通俗一点分区就是通过某一个数据分类条件创建不同的文件夹分开分类存储,查询数据的时候直接搜指定文件夹不用扫描整个表。
再简单一点,分区就是拆文件夹
2、两种分区类型
1)静态分区(Static Partitioning)
定义:加载数据时需手动指定分区列的值。
适用场景:分区数量较少、分区值固定的场景(如按“国家”分区:中国、美国)
2)动态分区(Dynamic Partitioning)
定义:加载数据时,Hive会根据查询结果自动推断分区列的值并创建分区。
适用场景:分区数量多、分区值不固定的场景(如按“日期”分区:2024-01-01、2024-01-02…)。
三、Hive分桶
Hive分桶是将表数据按指定列的哈希值(Hash)拆分为多个文件的细粒度数据组织方式,核心目的是优化join、抽样和聚合查询性能。
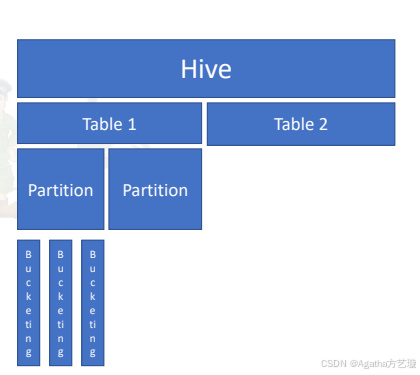
1、核心原理
通过 CLUSTERED BY 指定分桶列,Hive会根据分桶列的哈希值对数据进行取模运算( hash(列值) % 分桶数 ),将数据均匀分配到固定数量的桶(文件)中。每个桶对应HDFS上的一个数据文件。
通俗一点,就是按余数把一个表文件的数据拆成几个文件存储
再简单一点,分桶就是拆文件
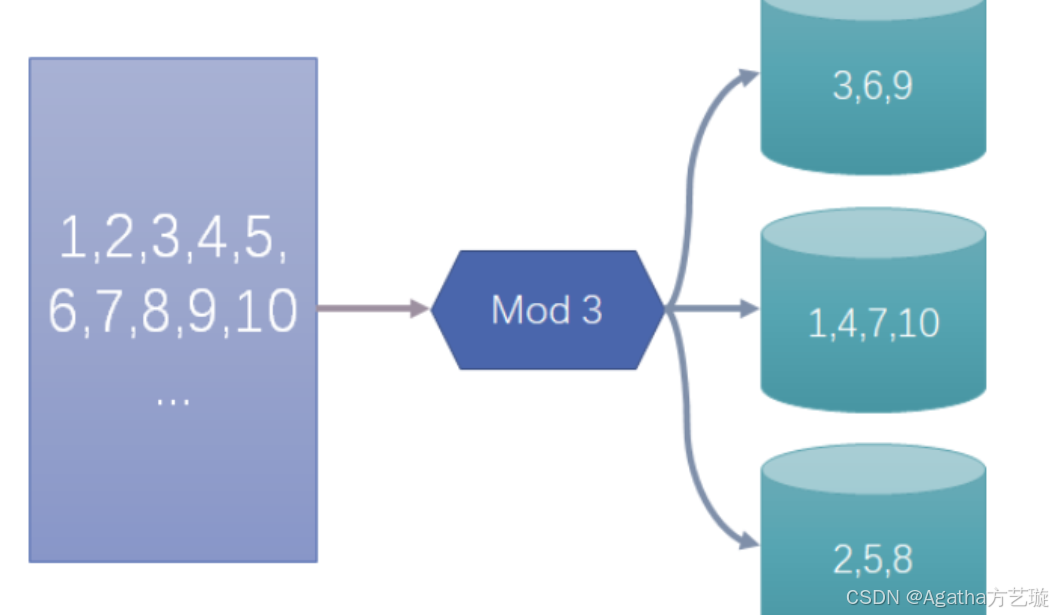
例子如下:
假设需要对一个表格分三个桶,哈希数据假设是1 2 3 4 5 6 7 8 9 10,分别除三看余数,那么 3,6,9 余数为0,在一个桶(0),1,4,7,10 余数为1,在一个桶(1),2,5,8 余数为2,在一个桶(2)
四、Hive 数据类型
Hive 数据库支持多种数据类型,包括原始数据类型和复杂数据类型。原始数据类型主要包括数值型、布尔型、字符串和时间戳,而复杂数据类型则包括数组(ARRAY)、映射(MAP)、结构(STRUCT)和联合(UNION)。
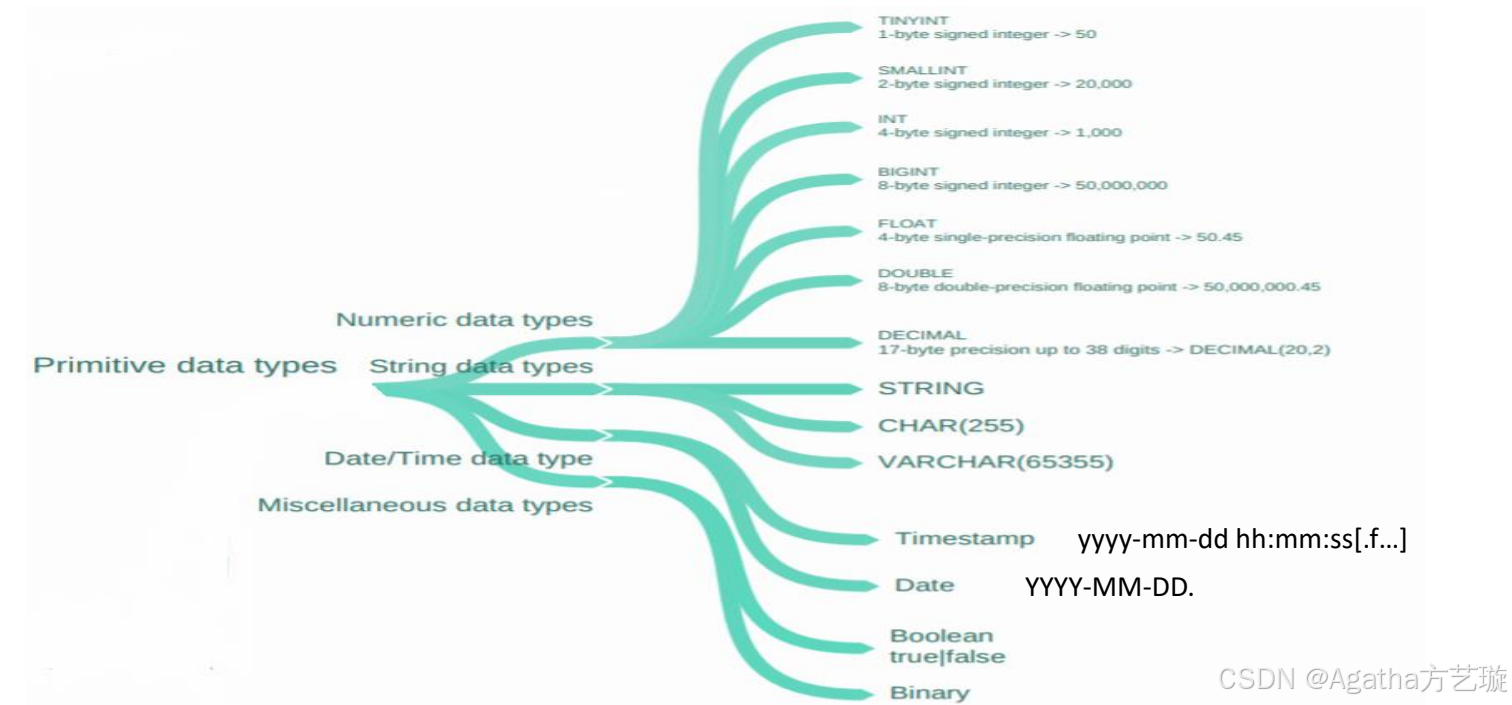
1、原始数据类型
原始数据类型是构建 Hive 表时最基本的数据类型,它们包括:
数值型:如整数(INT、TINYINT、SMALLINT、BIGINT)和浮点数(FLOAT、DOUBLE)以及任意精度的小数(DECIMAL)。
布尔型(BOOLEAN):表示真(TRUE)或假(FALSE)。
字符串:包括变长字符串(STRING、VARCHAR)和固定长度字符串(CHAR)。
二进制(BINARY):用于存储二进制数据。
时间戳(TIMESTAMP):存储纳秒级别的时间戳。
日期(DATE):表示年月日。
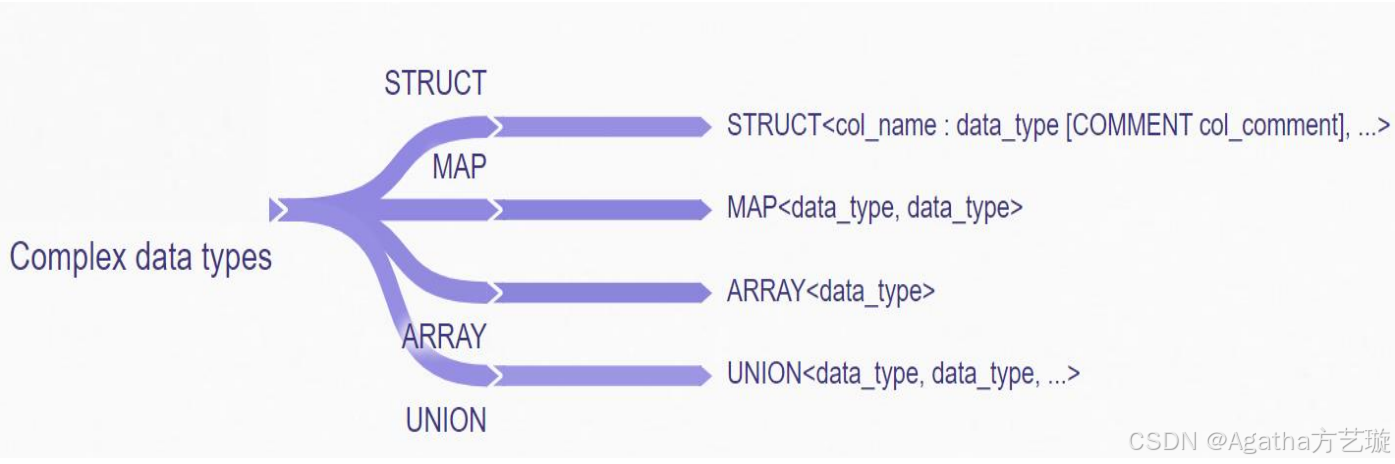
2、复杂数据类型
复杂数据类型允许在 Hive 表中存储更为复杂的数据结构:
数组(ARRAY):表示同一数据类型的有序集合,可以通过索引访问。
映射(MAP):存储键值对,键必须是原始数据类型,值可以是任意类型。
结构(STRUCT):类似于 C 语言中的结构体,可以封装不同数据类型的字段集合。
联合(UNION):可以在有限的数据类型范围内存储任意一种类型的值。