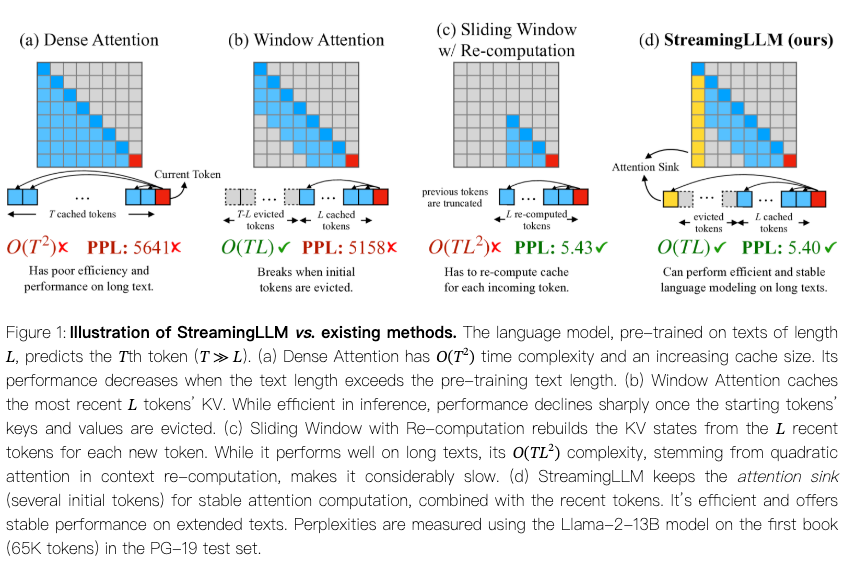
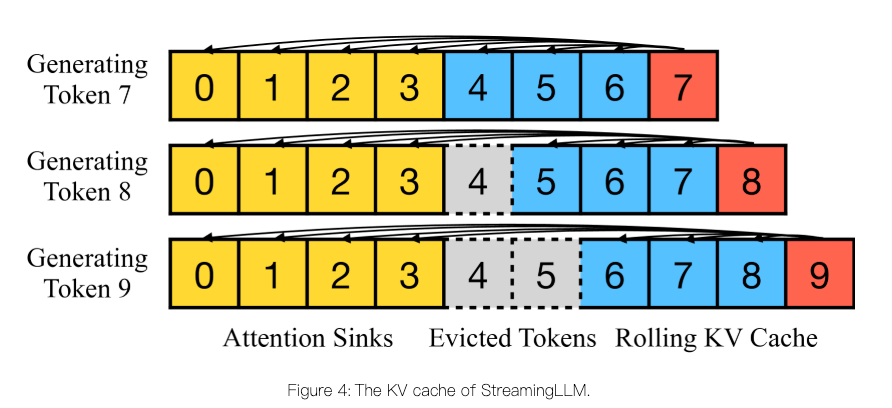
当前位置: 首页 > news >正文 EFFICIENT STREAMING LANGUAGE MODELS WITH ATTENTION SINKS论文阅读 news 2025/9/18 9:46:00 论文:https://arxiv.org/abs/2309.17453 StreamingLLM的来源和超大激活值相关。 研究的问题 流式部署大模型处理长上下文的存在挑战:首先,在解码阶段,缓存先前标记的键值状态(KV)会消耗大量内存。其次,主流的LLM无法泛化到超过训练时序列长度的文本。 研究发现了保留初始标记的KV可显著恢复窗口注意力的性能。本文首次揭示,这种“注意力汇聚”现象源于即使初始标记在语义上并不重要,其注意力分数仍异常强烈,形成一个“汇聚点”。 研究内容 文章转载自: http://PfqvO9Mv.bzpwh.cn http://a1VMyr5C.bzpwh.cn http://CNAa4O9K.bzpwh.cn http://vg15aVni.bzpwh.cn http://8YOSzKfL.bzpwh.cn http://nKeaPgoq.bzpwh.cn http://eWuOTs6l.bzpwh.cn http://OE61cYnc.bzpwh.cn http://DtAFbMu5.bzpwh.cn http://VcCBbQTG.bzpwh.cn http://kjKHHA6B.bzpwh.cn http://rPB1MECw.bzpwh.cn http://lo93PsVU.bzpwh.cn http://SLEuiaig.bzpwh.cn http://F98TFGD8.bzpwh.cn http://ws0g4KGL.bzpwh.cn http://pVUowyiM.bzpwh.cn http://OCa56yb4.bzpwh.cn http://9mgARf27.bzpwh.cn http://Tcn8suw1.bzpwh.cn http://HF1byIns.bzpwh.cn http://qdSQi9CP.bzpwh.cn http://KcrNXo5L.bzpwh.cn http://yGSHnMXH.bzpwh.cn http://FjH75XRB.bzpwh.cn http://NyCokPj7.bzpwh.cn http://7hKZVeWb.bzpwh.cn http://VO6NsTp0.bzpwh.cn http://8Xpnl1As.bzpwh.cn http://n4Zzz4Uo.bzpwh.cn 查看全文 http://www.dtcms.com/a/388229.html 相关文章: Blockview [Dify] Agent 模式下的流程自动化范式解析 Java泛型:类型安全的艺术与实践指南 React+antd实现监听localStorage变化多页面更新+纯js单页面table模糊、精确查询、添加、展示功能 事件驱动临床系统:基于FHIR R5 SubscriptionsBulk Data的编程实现(中) 电源滤波器如何“滤”出稳定电力 非连续内存分配 CKA08--PVC 贪心算法应用:分数背包问题详解 What is Vibe Coding? A New Way to Build with AI 【Anaconda_pandas+numpy】the pandas numpy version incompatible in anaconda 【3D点云测量视觉软件】基于HALCON+C#开发的3D点云测量视觉软件,全套源码+教学视频+点云示例数据,开箱即用 卡尔曼Kalman滤波|基础学习(一) MoPKL模型学习(与常见红外小目标检测方法) 数据驱动变革时代,自动驾驶研发如何破解数据跨境合规难题? Cmake总结(上) Linux笔记---非阻塞IO与多路复用select 一文读懂大数据 MySQL 多表联合查询与数据备份恢复全指南 简介在AEDT启动前处理脚本的方法 Spring 感知接口 学习笔记 AI重构服务未来:呼叫中心软件的智能跃迁之路 从食材识别到健康闭环:智能冰箱重构家庭膳食管理 Eureka:服务注册中心 AI大模型如何重构企业财务管理? 深入浅出Disruptor:高性能并发框架的设计与实践 Java 在 Excel 中查找并高亮数据:详细教程 Excel处理控件Aspose.Cells教程:如何将Excel区域转换为Python列表 Java 实现 Excel 与 TXT 文本高效互转 【vue+exceljs+file-saver】纯前端:下载excel和上传解析excel
论文:https://arxiv.org/abs/2309.17453 StreamingLLM的来源和超大激活值相关。 研究的问题 流式部署大模型处理长上下文的存在挑战:首先,在解码阶段,缓存先前标记的键值状态(KV)会消耗大量内存。其次,主流的LLM无法泛化到超过训练时序列长度的文本。 研究发现了保留初始标记的KV可显著恢复窗口注意力的性能。本文首次揭示,这种“注意力汇聚”现象源于即使初始标记在语义上并不重要,其注意力分数仍异常强烈,形成一个“汇聚点”。 研究内容