探索大语言模型(LLM):Windows系统与Linux系统下的Ollama高级配置(修改模型地址、Service服务以及多卡均衡调用)
前言
在之前的探索大语言模型(LLM):Ollama快速安装部署及使用(含Linux环境下离线安装)中,已经介绍了ollama在Windows环境下和Linux环境下的安装,在本篇中将重点介绍Ollama的常用配置
修改模型存储地址
默认情况下,ollama在Linux系统中会将模型下载到/root/.ollama文件
夹中,windows系统会将模型下载到C:\Users\用户名\.ollama\models文件夹中,这种情况下模型占用的是系统盘的空间,所以最好换个路径保存。
Linux环境修改模型存储地址
vi ~/.bashrc
然后添加
export OLLAMA_MODELS=你想设置的路径
使环境变量生效
source ~/.bashrc
如果之前下载过模型,记得要把源地址的模型移动到新的路径下,如果不生效尝试重启一下ollama
sudo systemctl daemon-reload
sudo systemctl restart ollama
检查服务状态:
sudo systemctl status ollama
当无法直接通过 systemctl 重启时,可手动停止并重新启动。
查找占用端口的进程:
lsof -i :11434
终止相关进程:
kill -9 <PID>
重新启动服务:
ollama serve
Windows环境修改模型存储地址

然后点击环境变量
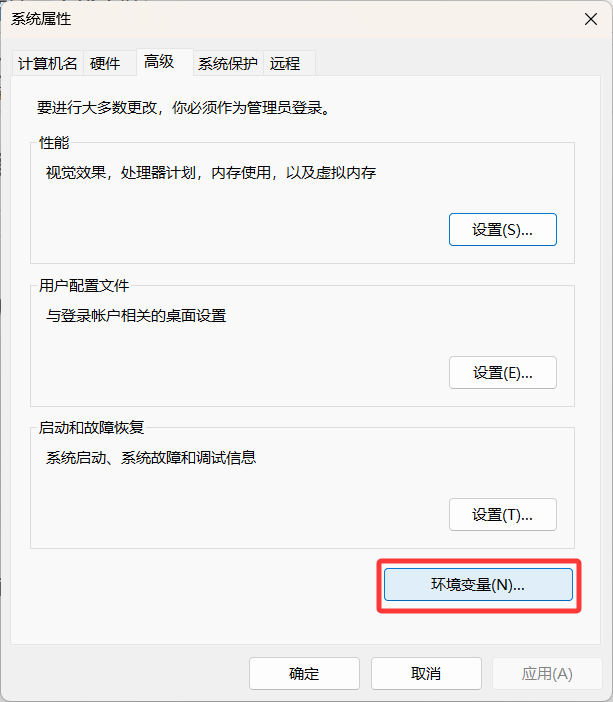
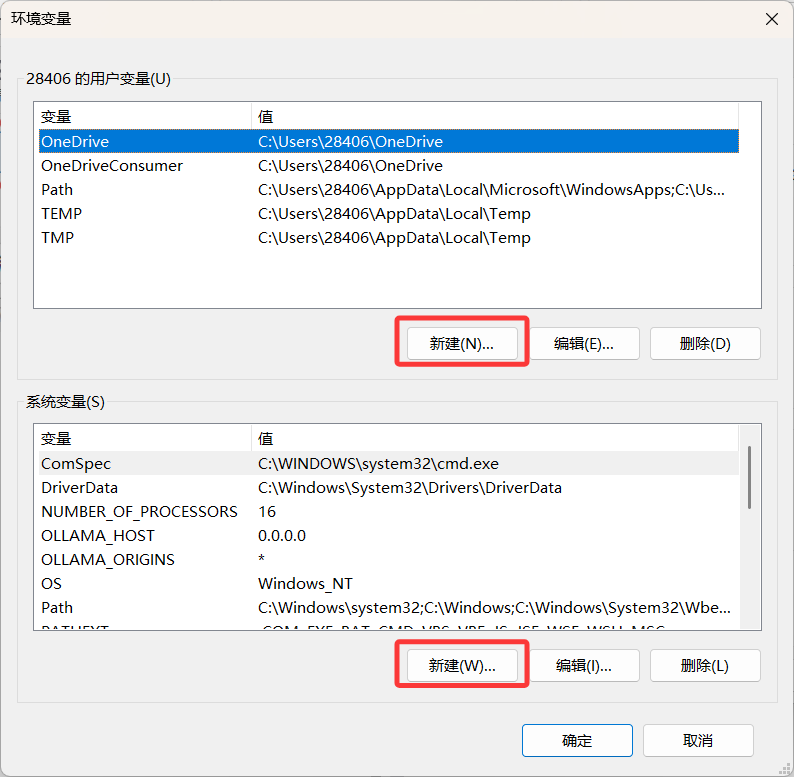
这里选任意一个就行
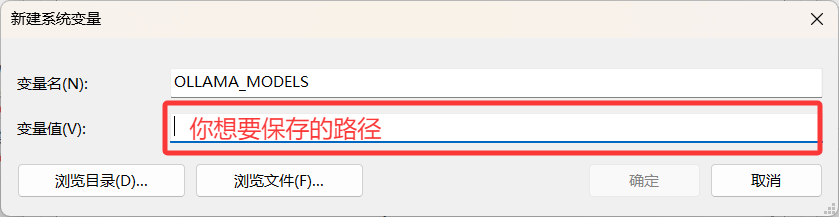
变量名为OLLAMA_MODELS
修改完保存即可
Service服务
如果需要局域网根据IP地址远程访问,需要修改ollama.service文件中的配置
systemctl edit ollama.service # 两个命令选一个就行,效果一致
sudo vi /etc/systemd/system/ollama.service # 两个命令选一个就行,效果一致
在 [Service] 部分添加环境变量:
Environment="OLLAMA_HOST=0.0.0.0"
Environment="OLLAMA_ORIGINS=*"
如果要修改端口,同样的是修改OLLAMA_HOST参数,参数修改形式如下(端口11434是ollama的默认端口,需要修改端口时只需更改这一参数即可)
Environment="OLLAMA_HOST=0.0.0.0:11434"
保存后重新加载配置并重启:
sudo systemctl daemon-reload
sudo systemctl restart ollama
验证服务状态
netstat -tulpn | grep 11434
多卡均衡
Environment="CUDA_VISIBLE_DEVICES=0,1,2,3" # 这里根据你自己实际的 GPU标号来进行修改
Environment="OLLAMA_SCHED_SPREAD=1" # 这个参数是做负载均衡
其中CUDA_VISIBLE_DEVICES填写的是GPU的编号,可以通过nvidia-smi查看相关的编号
OLLAMA_SCHED_SPREAD的作用是使得模型可以均匀的在多张显卡上运行,如果不加这个配置,模型会优先选择一个性能最佳的显卡,只有显存不足时才会占用其他显卡,为了保证运行的效率,建议将这个参数设置为1
保存退出后,重新加载systemd并重新启动Ollama服务使其配置生效
systemctl daemon-reload
systemctl restart ollama
其他参数
| 参数名 | 参数说明 |
|---|---|
| OLLAMA_NUM_PARALLEL | 设置Ollama每个模型最大并行请求数,默认依可用显存自动选4或1 |
| OLLAMA_MAX_QUEUE | 内存不足时新模型请求排队,按序处理,先前的模型闲置会卸载以腾空间 |
| OLLAMA_MAX_LOADED_MODELS | 设置最大加载模型数量,默认3*GPU数量,超量新请求会被拒 |