【Linux】LRU缓存(C++模拟实现)
目录
1.缓存的定义
2.以OJ题为例,模拟实现LRU缓存
LeetCode 146. LRU 缓存
分析
构造函数
get函数
put函数
完整代码
提交结果
牛客网 REAL600 LRU Cache
完整代码
提交结果
3.拓展资料
1.缓存的定义
广义上,由于CPU和内存之间、内存和磁盘之间读写速度相差较大,因此会在中间设置缓存用来提高整体的读写速度,乃至在硬盘与网络之间也有某种意义上的缓存──称为Internet临时文件夹或
网络内容缓存等之前在98.【C语言】存储体系结构文章提到过这个两个图:
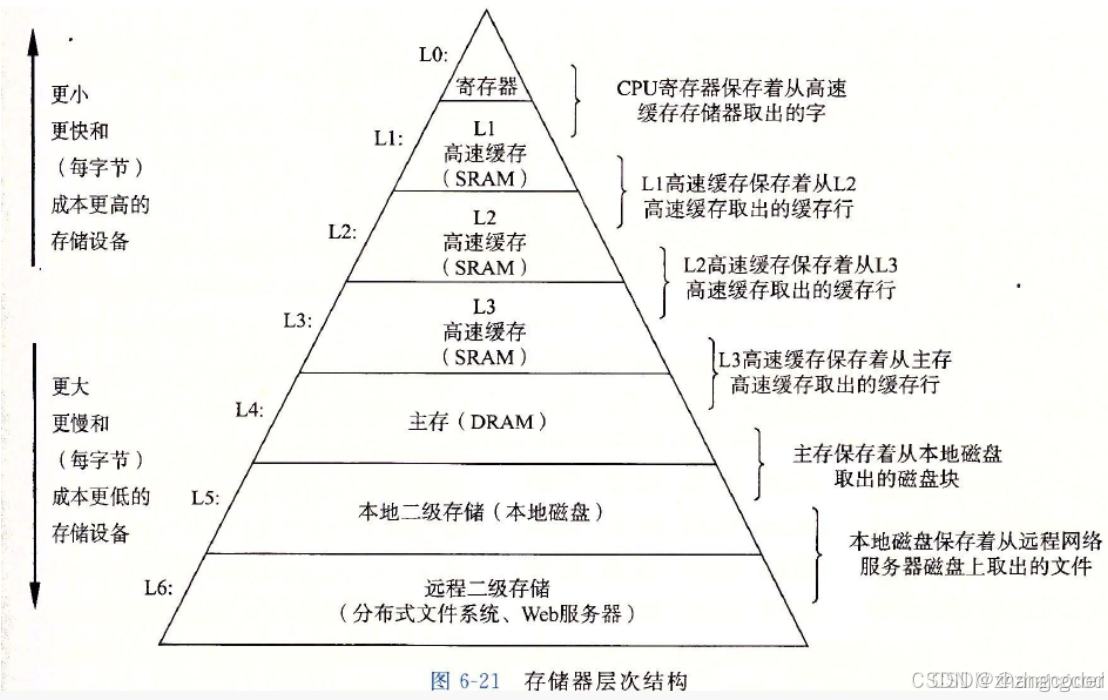
上图摘自《深入了解计算机系统》
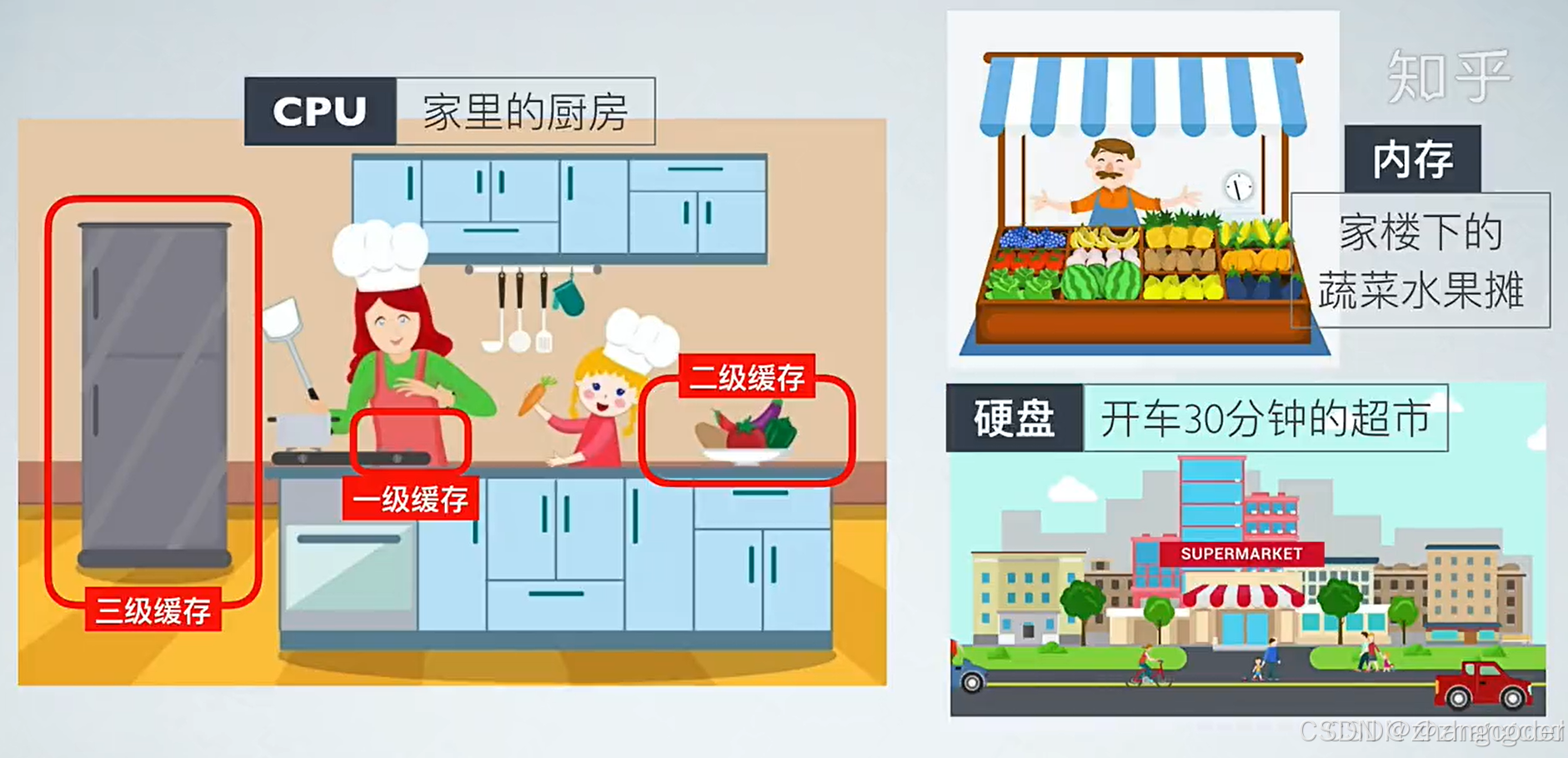
上图摘自知乎大佬文章
注:狭义上的缓存指的是位于CPU和主存间的快速RAM,通常它不像系统主存那样使用DRAM技术,而使用昂贵但较快速的SRAM技术
2.以OJ题为例,模拟实现LRU缓存
由于缓存的空间是有限的,满了以后那么缓存中的数据不能一直占着,肯定要有一些新的数据进入缓存供CPU使用,就要按某种算法淘汰掉一些缓存,例如淘汰掉LRU缓存
LRU缓存的全称是Least Recently Used缓存,即最近最少使用缓存,是一种常用的页面置换算法,选择最近最久未使用的页面予以淘汰,以确保缓存中始终存储着最新和最频繁使用的页面
也可以这样说:当缓存空间不足时,淘汰最近最久未被使用的数据,以确保缓存中始终存储着最新和最频繁使用的数据
其实,LRU译成最久未使用会更形象, 因为该算法每次替换掉的就是一段时间内最久没有使用过的内容
要设计出一个LRU缓存不难,但要设计出一个高效LRU缓存有难度,需要确保任意操作都是O(1)
LeetCode 146. LRU 缓存
https://leetcode.cn/problems/lru-cache/description/
请你设计并实现一个满足 LRU (最近最少使用) 缓存 约束的数据结构。
实现
LRUCache类:
LRUCache(int capacity)以 正整数 作为容量capacity初始化 LRU 缓存int get(int key)如果关键字key存在于缓存中,则返回关键字的值,否则返回-1。void put(int key, int value)如果关键字key已经存在,则变更其数据值value;如果不存在,则向缓存中插入该组key-value。如果插入操作导致关键字数量超过capacity,则应该 逐出 最久未使用的关键字。函数
get和put必须以O(1)的平均时间复杂度运行。示例:
输入 ["LRUCache", "put", "put", "get", "put", "get", "put", "get", "get", "get"] [[2], [1, 1], [2, 2], [1], [3, 3], [2], [4, 4], [1], [3], [4]] 输出 [null, null, null, 1, null, -1, null, -1, 3, 4]解释 LRUCache lRUCache = new LRUCache(2); lRUCache.put(1, 1); // 缓存是 {1=1} lRUCache.put(2, 2); // 缓存是 {1=1, 2=2} lRUCache.get(1); // 返回 1 lRUCache.put(3, 3); // 该操作会使得关键字 2 作废,缓存是 {1=1, 3=3} lRUCache.get(2); // 返回 -1 (未找到) lRUCache.put(4, 4); // 该操作会使得关键字 1 作废,缓存是 {4=4, 3=3} lRUCache.get(1); // 返回 -1 (未找到) lRUCache.get(3); // 返回 3 lRUCache.get(4); // 返回 4提示:
1 <= capacity <= 30000 <= key <= 100000 <= value <= 10^5- 最多调用
2 * 105次get和put
注和这些题一样:
https://leetcode.cn/problems/lru-cache-lcci/description/
https://leetcode.cn/problems/OrIXps/description/
分析
题目中提到"函数 get 和 put 必须以 O(1) 的平均时间复杂度运行",而且需要key-value结构,可以想到unordered_map<int,int>(LeetCode提供的key和value的类型都是int),其查找和更新的时间复杂度是,但如何找出LRU缓存?
LRU缓存涉及到缓存顺序问题,可以使用双向链表,例如list<pair<int,int>>,设计为: 链表的末尾是最近最少使用缓存数据,而新增的缓存数据都头插到链表中(当然也可以设计为链表的头部是最近最少使用缓存数据,LeetCode对测试用例的解释就是这样的)
缓存的空间是有限的,可以控制链表的最大长度为capacity
如果像这样设计仍然有缺陷:
unordered_map<int,int> _hash;
list<pair<int,int>> _LRU_list;虽然查找和新增的时间复杂度为,但是更新的时间复杂度为
,更新慢在查找链表中旧的缓存数据的位置,由于_hash没有存储在链表中的位置,需要先遍历然后更新,最后移动到链表的头部
解决方法:哈希表中不仅要记录每个缓存数据,而且要记录每个缓存数据,在链表中的位置(C++可以使用迭代器,C语言可以使用指针),如下图
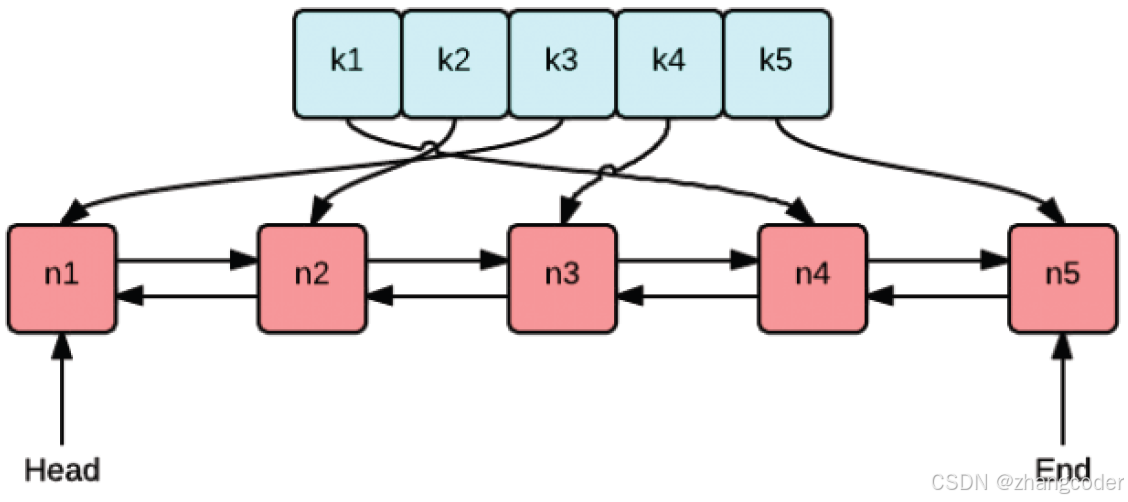
typedef list<pair<int, int>>::iterator LRU_index;
unordered_map<int, LRU_index> _hash;
list<pair<int,int>> _LRU_list;那么LRUCache类的成员变量:
private: unordered_map<int, LRU_index> _hash;list<pair<int,int>> _LRU_list;int _capacity;构造函数
为_capacity成员变量初始化值即可,可以使用初始化成员列表
LRUCache(int capacity)
:_capacity(capacity)
{}get函数
★get(key)t涉及到查找节点,即访问了_LRU_list的缓存数据,需要更新_LRU_list上的数据,指的是将节点移动到链表头部(前面定义过了"链表的末尾是最近最少使用缓存数据,而新增的缓存数据都头插到链表中")有以下两种方法:
方法1.可以使用转移成员函数splice,将节点剪切到链表头部,不用更新LRU_index,未删除节点,指针仍然有效,因此迭代器不会失效
方法2.先删除(erase)再头插(push_front),要更新LRU_index,因为迭代器会失效,之前讲过迭代器的本质是指针
这里使用方法2:
注: 返回关键字的值指的是返回key的value
int get(int key)
{auto ret=_hash.find(key);if (ret!=_hash.end()){//先更新_LRU_list.这里迭代器不会失效_LRU_list.splice(_LRU_list.begin(),_LRU_list,ret->second);//返回时取两次,ret取得_hash的迭代器,ret->second取得_LRU_list的迭代器,ret->second->second取得valuereturn ret->second->second;}return -1;
}put函数
和get函数类似,设计到到数据的访问(插入新数据,本质上也是访问数据)也要更新数据,如果_LRU_list满了,注意先删除最近最少使用缓存,然后再插入新数据
void put(int key, int value)
{auto ret=_hash.find(key);if (ret!=_hash.end()){ret->second->second=value;_LRU_list.splice(_LRU_list.begin(),_LRU_list,ret->second);}else{if (_hash.size()<_capacity){_LRU_list.push_front(make_pair(key,value));_hash.insert(make_pair(key,_LRU_list.begin()));}else//_hash.size()==_capacity{auto back=_LRU_list.back();_hash.erase(back.first);_LRU_list.pop_back();_LRU_list.push_front(make_pair(key,value));_hash.insert(make_pair(key,_LRU_list.begin()));}}
}注:不建议写成_LRU_list.size()<_capacity,原因是某些STL版本的list没有size成员变量,内部实现会手动遍历
可以写得更简洁些:如果关键字key不存在,无论_hash.size()是<_capacity还是==_capacity都要对哈希表插入pair,而且插入哈希表可以不用Insert,使用operator[]更简洁,如下代码:
void put(int key, int value)
{auto ret=_hash.find(key);if (ret!=_hash.end()){ret->second->second=value;_LRU_list.splice(_LRU_list.begin(),_LRU_list,ret->second);}else{auto elem=make_pair(key,value);if (_hash.size()<_capacity){_LRU_list.push_front(elem);}else//_hash.size()==_capacity{auto back=_LRU_list.back();_hash.erase(back.first);_LRU_list.pop_back();_LRU_list.push_front(elem);}_hash[key]=_LRU_list.begin();}
}完整代码
class LRUCache
{
typedef list<pair<int, int>>::iterator LRU_index;
public:LRUCache(int capacity) :_capacity(capacity){}int get(int key) {auto ret=_hash.find(key);if (ret!=_hash.end()){//先更新_LRU_list.这里迭代器不会失效_LRU_list.splice(_LRU_list.begin(),_LRU_list,ret->second);//返回时取两次,ret取得_hash的迭代器,ret->second取得_LRU_list的迭代器,ret->second->second取得valuereturn ret->second->second;}return -1;}void put(int key, int value) {auto ret=_hash.find(key);if (ret!=_hash.end()){ret->second->second=value;_LRU_list.splice(_LRU_list.begin(),_LRU_list,ret->second);}else{auto elem=make_pair(key,value);if (_hash.size()<_capacity){_LRU_list.push_front(elem);}else//_hash.size()==_capacity{auto back=_LRU_list.back();_hash.erase(back.first);_LRU_list.pop_back();_LRU_list.push_front(elem);}_hash[key]=_LRU_list.begin();}}private: unordered_map<int, LRU_index> _hash;list<pair<int,int>> _LRU_list;int _capacity;
};提交结果
牛客网 REAL600 LRU Cache
https://www.nowcoder.com/practice/3da4aeb1c76042f2bc70dbcb94513338?tpId=182&tqId=34883&ru=/exam/oj
描述
设计一个数据结构,实现LRU Cache的功能(Least Recently Used – 最近最少使用缓存)。它支持如下2个操作: get 和 put。 int get(int key) – 如果key已存在,则返回key对应的值value(始终大于0);如果key不存在,则返回-1。 void put(int key, int value) – 如果key不存在,将value插入;如果key已存在,则使用value替换原先已经存在的值。如果容量达到了限制,LRU Cache需要在插入新元素之前,将最近最少使用的元素删除。 请特别注意“使用”的定义:新插入或获取key视为被使用一次;而将已经存在的值替换更新,不算被使用。 限制:请在O(1)的时间复杂度内完成上述2个操作。
输入描述:
第一行读入一个整数n,表示LRU Cache的容量限制。 从第二行开始一直到文件末尾,每1行代表1个操作。
如果每行的第1个字符是p,则该字符后面会跟随2个整数,表示put操作的key和value。
如果每行的第1个字符是g,则该字符后面会跟随1个整数,表示get操作的key。输出描述:
按照输入中get操作出现的顺序,按行输出get操作的返回结果。示例1
输入:2 p 1 1 p 2 2 g 1 p 2 102 p 3 3 g 1 g 2 g 3
输出:1 1 -1 3说明:2 //Cache容量为2 p 1 1 //put(1, 1) p 2 2 //put(2, 2) g 1 //get(1), 返回1 p 2 102 //put(2, 102),更新已存在的key,不算被使用 p 3 3 //put(3, 3),容量超过限制,将最近最少使用的key=2清除 g 1 //get(1), 返回1 g 2 //get(2), 返回-1 g 3 //get(3), 返回3
注:和https://www.nowcoder.com/practice/5dfded165916435d9defb053c63f1e84?tpId=196&tqId=37137&ru=/exam/oj题一样
修改LeetCode上的代码即可,注意和LeetCode不一样的地方:
说明中"p 2 102 //put(2, 102),更新已存在的key,不算被使用"
缓存大小可以为0,而LeetCode是1 <= capacity <= 3000
完整代码
#include <iostream>
#include <list>
#include <unordered_map>
#include <string>
using namespace std;
class LRUCache
{typedef list<pair<int, int>>::iterator LRU_index;
public:LRUCache(int capacity):_capacity(capacity){}void get(int key){auto ret = _hash.find(key);if (ret != _hash.end()){_LRU_list.splice(_LRU_list.begin(), _LRU_list, ret->second);cout << ret->second->second << endl;return;}cout << -1 << endl;}void put(int key, int value){auto ret = _hash.find(key);if (ret != _hash.end()){ret->second->second = value;}else{if (_capacity==0)return;auto elem = make_pair(key, value);if (_hash.size() < _capacity){_LRU_list.push_front(elem);}else//_hash.size()==_capacity,且_capacity>0{auto back = _LRU_list.back();_hash.erase(back.first);_LRU_list.pop_back();_LRU_list.push_front(elem);}_hash[key] = _LRU_list.begin();}}
private:unordered_map<int, LRU_index> _hash;list<pair<int, int>> _LRU_list;int _capacity;
};int main()
{int n;string str;cin >> n;LRUCache obj(n);while (cin>>str){if (str=="p"){int key, value;cin >> key;cin >> value;obj.put(key, value);}else//str=="g"{int key;cin >> key;obj.get(key);}}return 0;
}提交结果
注:C语言模拟实现的代码将在下一篇讲
3.拓展资料
1.《Operating Systems. Design and Implementation Third Edition Andrew S. Tanenbaum Albert S. Woodhull》的4.4 PAGE REPLACEMENT ALGORITHMS中的4.4.6 The Least Recently Used (LRU) Page Replacement Algorithm和4.4.7 Simulating LRU in Software
2.阿里、腾讯校招都爱问的 LRU 缓存,你能手写出来吗?(附详细代码及GitHub项目)
3.C++ 读取输入直至EOF的方法: How to Read Input Until EOF in C++?