Another Redis Desktop Manager 的 SCAN 使用问题与风险分析
一、背景
在日常运维或开发中,很多人习惯使用 Another Redis Desktop Manager (ARDM) 这类图形化工具来管理 Redis。

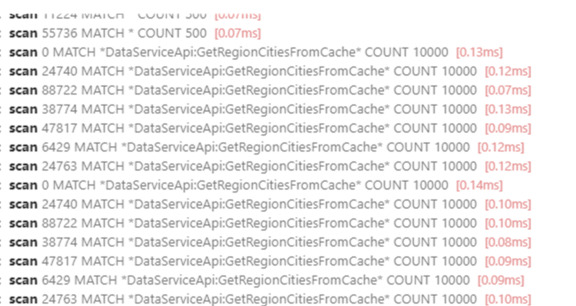
在该工具的「搜索 key」功能中,输入模糊匹配条件(如 *DataServiceApi:GetRegionCitiesFromCache*),工具会自动执行 Redis 的 SCAN 命令来遍历数据库。
典型命令如下:
SCAN 246290605464956 MATCH *DataServiceApi:GetRegionCitiesFromCache* COUNT 10000这并不是用户手动输入的,而是 ARDM 内部逻辑自动发出的请求。
二、SCAN 的工作机制
-
渐进式遍历:
SCAN不会一次性返回所有结果,而是返回一部分 key 和一个游标(cursor),客户端需要循环调用才能遍历完全部 key。 -
非阻塞:
与KEYS不同,SCAN单次执行不会阻塞整个 Redis,适合大数据量场景下的 key 搜索。 -
CPU 开销:
如果加上MATCH *pattern*,每个候选 key 都要做字符串匹配,会消耗 Redis 的 CPU 时间。
三、Another Redis Desktop Manager 的实现逻辑
-
输入 完整 key 时
- 工具直接调用
GET或EXISTS,不会触发SCAN。
- 工具直接调用
-
输入 模糊搜索(通配符) 时
- 工具循环执行
SCAN cursor MATCH xxx COUNT n。 - 默认
COUNT值可能比较大(如 10000),意味着 Redis 要返回更多候选 key。 - 为了获取完整结果,工具会重复发送上百次甚至上千次
SCAN。
- 工具循环执行
四、潜在风险
1. 性能风险
- 每次
SCAN都需要遍历部分哈希槽,如果 key 数量达到百万级别,反复执行会导致 CPU 使用率升高。 - Redis 是单线程的,高频
SCAN会占用执行队列,造成普通业务请求(GET/SET)排队延迟上升。
2. 生产事故隐患
-
如果运维人员在生产环境中习惯直接搜索
*xxx*,工具会扫描全库,极端情况下可能导致:- 响应时间显著升高
- CPU 接近 100%,影响正常业务
- 在高并发业务场景下甚至造成短暂“假死”
3. 不可控的操作
- 开发或运维人员可能无意间在高峰期搜索 key,触发大量
SCAN,对业务产生影响。 - 由于
SCAN本身是非阻塞的,不会有明显“危险操作警告”,因此风险更隐蔽。
五、是否应该在生产环境禁止使用?
建议:强烈不推荐在生产环境使用 ARDM 搜索功能
-
如果一定要查 key,建议在测试环境、从库或影子库操作。
-
在生产环境中,应该通过 前缀规范 来管理 key,而不是依赖模糊搜索。
- 例如:
User:{id}、Order:{id}、Cache:RegionCities:{id}
- 例如:
-
如果必须在生产环境做批量清理,建议:
- 使用分批
SCAN+DEL脚本,由运维人员控制节奏。 - 或者通过业务日志、数据库表来精确定位要清理的 key,而不是全库模糊匹配。
- 使用分批
六、总结与最佳实践
-
**Another Redis Desktop Manager 在模糊搜索时一定会触发
SCAN**,并可能循环成百上千次。 -
单次
SCAN不会阻塞 Redis,但大规模、频繁执行会带来 CPU 飙高 + 延迟增加 的风险。 -
生产环境建议禁止使用 GUI 工具直接搜索 key,避免因运维习惯造成潜在事故。
-
更好的方案是:
- 通过命名规范控制 key 范围;
- 在从库或测试环境执行搜索;
- 必要时用分批脚本安全执行。
✅ 一句话结论:
Another Redis Desktop Manager 的 SCAN 搜索功能在生产环境属于高风险操作,建议禁用或严格管控。
将markdown 转化为图片,pdf,word,html格式工具