联邦学习论文分享:DPD-fVAE
摘要
研究背景
传统 FL 大多用于训练分类模型,但由于数据敏感性,这些模型及其训练过程仍然存在隐私风险。
近年来有研究提出:与其直接训练分类器,不如训练一个数据生成模型,可以合成一个“新的、不受隐私限制”的数据集,方便后续研究和模型评估。
提出的方法:DPD-fVAE
一种带差分隐私保护的联邦变分自编码器(fVAE)。
关键创新点:只在联邦学习中同步 解码器(Decoder),这样能减少每一轮训练的隐私开销,从而提升生成数据的质量。
隐私保护
在训练过程中引入差分隐私机制,作为额外的保护层,进一步降低真实数据泄露风险。
实验与结果
在 MNIST、Fashion-MNIST 和 CelebA 数据集上做了实验。
结果表明:该方法生成的数据质量较好(通过 Fréchet Inception Distance 评价),并且在用合成数据训练分类器时,分类性能也具有竞争力。
引言
1. 研究背景与问题
深度学习的挑战:现代 ML/深度学习需要大量数据,但数据通常分散在不同机构,而且受到隐私法规限制(如 GDPR、HIPAA),导致难以集中利用。
医疗领域痛点:患者数据特别敏感,研究人员常常无法直接获取;而且不同来源的数据差异性很重要,但又难以整合。
2. 现有方法:联邦学习(Federated Learning, FL)
优点:通过共享模型参数/更新而不是数据本身,医院等机构可以在不交出数据的情况下参与训练。
不足:单纯的 FL 并不能完全防止隐私泄露——攻击者仍可能通过模型更新推断甚至重构原始数据。
3. 差分隐私(Differential Privacy, DP)引入
解决思路:在训练中加入噪声,掩盖个体数据对模型的影响,从而提供正式的隐私保障。
两种方式:
CDP(中央差分隐私):保护用户级别的参与信息。
LDP(本地差分隐私):保护单个数据点。
挑战:在 FL 场景中结合 DP 往往很难,因为要保证严格隐私界限,就得加很多噪声,导致模型性能下降。
4. 研究动机:为什么要做生成模型
目前大部分 FL 研究集中在训练分类模型。
但作者认为:
训练 生成模型(如 VAE)更有价值,因为生成的合成数据可以广泛用于后续各种研究任务,而不是仅限于一个分类器。
合成数据还能被分发给不同研究者,用于不同问题。
生成模型还能缓解真实数据集中类别不平衡的问题。
前提知识
变分自编码器
1. VAE 基本结构
VAE 是一种基于神经网络的生成模型,由 编码器(Encoder, E) 和 解码器(Decoder, D) 两部分组成:
编码器:把输入数据映射到一个潜在空间(latent space)的概率分布。
解码器:从潜在空间采样并重建输入数据。
条件 VAE(Conditional VAE) 还会利用类别标签 (y) 辅助建模。
2. VAE 的概率建模
编码器学习近似后验分布:
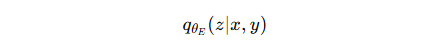
解码器根据采样的潜在变量重建原始输入:

优化目标是最大化数据对数似然

因为直接优化对数似然很难,VAE 使用 证据下界(ELBO) 作为替代目标,其中包含:
重建损失(让生成结果接近原始输入)
KL 散度(KLD)(让编码分布接近先验分布 p(z∣y))。
3. β-VAE 的改进
在标准 VAE 的损失函数中,β-VAE 引入一个权重参数 β 来控制 KL 散度的影响。
损失函数形式:
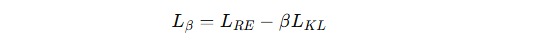
LRE:重建损失,保证生成样本的保真度。
LKL:KL 散度,起到正则化作用,约束潜在空间的分布。
补充1
1. 自编码(Autoencoder, AE)
含义:自动把输入 编码(encode)再解码(decode),目标是让输出尽量还原输入。
为什么叫“自”?因为模型的 监督信号就是输入本身,即 “自我监督”。
例如:输入一张图片,编码器把它压缩成潜在向量,解码器再试图重建出原图。
没有外部标签,输入就是标签。
核心思想:自我重建。
2. 自回归(Autoregressive, AR)
含义:模型通过前面的内容,预测序列中的下一个元素。
为什么叫“自”?因为预测时依赖的是 序列自身过去的部分,而不是外部额外的信息。
例如:语言模型中,预测下一个单词时,只用前面出现的单词。
数学上写成:
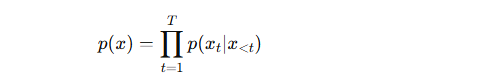
应用:GPT 就是典型的自回归模型。
核心思想:用自己过去的部分预测未来。
3. 直观类比
自编码:就像你看一张模糊的照片(编码),再试着把它画清楚(解码),目标是还原自己看到的东西。
自回归:就像你听别人说话,每次都猜下一句会说什么,猜的时候只靠前面已经听到的话。
补充2
1. 整体目标:学一个“数据生成器”
VAE 想做的事情其实很简单:
给它很多真实的数据(比如手写数字的图片),它要学会一个“生成器”,以后能自己画出新的、像真的一样的图片。
2. 核心思路:先学一个“潜在空间”
潜变量 (latent variable):
你可以想象,每张图的背后都有一些“隐藏的因素”,比如:数字是几(0,1,2,…)
写字人的笔迹粗细、倾斜度
图像的亮度
这些“隐藏特征”就是潜变量。它们不是直接给出的,而是模型需要自己去学出来的。
VAE 的想法是:与其直接记忆图片,不如学一个“隐藏世界(潜在空间)”,然后从里面采样,再通过“解码器”画出图片。
3. 先验分布 / 后验分布 / 似然 这些词怎么理解?
先验分布:就像“默认假设”。比如我们假设所有隐藏特征(潜变量)一开始都服从一个很简单的分布(比如高斯分布,像一团圆圆的云)。
后验分布:当你真的看见一张图片后,你会更新你对“它的潜变量可能是什么”的看法。比如看到一张“1”,那潜变量就不会是“圆圆的 0”,而会偏向“竖直的 1”。
似然:就是“给定一个潜变量,生成一张图片的可能性有多大”。比如潜变量里有“圆形”的特征,那生成出“0”的图片的可能性就大。
最大化下界 (ELBO):因为直接算“这张图片到底多大概率能被生成器画出来”太难了,VAE 退一步:用一个“下界”来近似它,并且把这个下界尽量调高。你可以理解为:虽然我们没法精确算出“生成这张图的分数”,但我们找到一个“安全的最低分”,然后努力把它提高。这样间接就让生成器越来越靠谱。
4. 训练过程怎么走?
整个流程像是一个“翻译 + 再绘画”的游戏:
编码器 (Encoder):先看一张真实图片,把它翻译成“潜变量”的描述(比如:这是个 1,写得有点歪,笔画粗)。
加点随机性:不要只翻译成一个死板的答案,而是给一小片区域(像在潜在空间画一个小泡泡),以后可以从这里面随便挑点来生成。这样保证生成器不会死记硬背。
解码器 (Decoder):拿到这个潜变量,再把它翻译回图片,尽量重画出原始的样子。
训练目标:
希望解码器画出来的图要和原图尽量接近(重建损失)。
希望潜变量们都服从我们假设的“圆圆的云”(正态分布),不要乱跑(正则化的作用)。
两个目标平衡,就能学到一个既能重建、又能生成新图的模型。
5. 为什么这样有效?
如果只有重建 → 模型可能死记硬背,只能处理训练过的图片。
如果只靠先验(潜变量必须像圆形的云)→ 模型会生成很模糊、没意义的图。
把这两个结合起来,VAE 就能既记住“数据的样子”,又让潜变量空间变得“平滑可控”。这样只要在潜在空间随便取一个点,解码器都能画出一张合理的新图。
6. 理解VAE:
编码器:把真实数据翻译成“隐藏世界的坐标”。
潜在空间:一个结构化的“创意空间”,里面的点对应不同的可能数据。
解码器:拿着“隐藏坐标”重新画出一张数据。
训练目标:保证“翻译-还原”循环靠谱,同时让隐藏世界保持一个整齐、圆润、好采样的结构。
联邦学习
背景:FL 的目的就是在不集中数据的情况下训练机器学习模型。数据不离开本地,隐私风险更低。
基本思想:
数据留在各个客户端(如医院、手机),
客户端只把模型更新(权重差异)发送给服务器,
服务器收集并聚合这些更新,形成新的全局模型。
训练循环(三步走,每一轮 global round):
服务器发送:选择一部分客户端,把当前全局模型参数发给他们。
客户端训练:客户端在自己的本地数据上训练若干个 epoch,然后把本地更新(参数差异)传回服务器。
服务器聚合:服务器对收集到的更新做加权平均(权重通常取决于各客户端数据量),并更新全局模型。
重复迭代:上面的过程会持续 T 轮,直到全局模型收敛。
差分隐私
1. 差分隐私的基本目标
最初应用在数据库领域,用来衡量和限制数据在多次查询中可能泄露的隐私。
核心思想:通过在查询结果中 加入噪声,保证“即使某个具体样本在不在数据库里,查询结果也几乎一样”。
这样就能为个体数据提供 “合理否认”(plausible deniability),避免别人确定某个样本是否被包含。
2. 形式化定义 — (ϵ,δ)-DP
一个随机机制 M (输入是数据集,输出是某种结果)满足 (ϵ,δ)-差分隐私,当对于任意只差一个样本的数据集 d,d′,以及任意可能的输出集合 S,有:
![]()
ϵ:隐私损失参数(越小隐私越强)。
δ:例外概率,表示有多大可能性隐私保护不严格成立。
换句话说:即使攻击者知道几乎所有数据,只差一个数据点,他也几乎分不清这个点在不在。
3. 差分隐私的重要性质 — 组合定理(Composition Theorem)
在实际应用中,DP 机制会被反复调用(比如多次训练迭代、多个查询)。
组合定理告诉我们:如果每次机制 Mi 都满足 (ϵi,δi)-DP,那么整体机制的隐私预算就是:
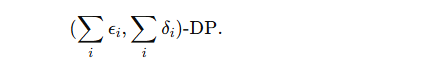
这意味着:多次使用 DP 机制会累积消耗隐私预算,要谨慎管理 ϵ,δ。
差分隐私用于机器学习
1. DP 引入到机器学习
Abadi 等人首次把差分隐私引入到机器学习模型的训练中。
核心思想:每一次参数更新(如 SGD 的一步)都会产生隐私消耗,因此需要对梯度更新过程进行控制和加噪。
2. 在优化中实现 DP 的两个关键步骤
梯度裁剪 (gradient clipping):把每个 batch 的全局梯度 L2 范数裁剪到阈值 S,限制敏感度。
梯度加噪 (gradient perturbation):在裁剪后的平均梯度上加高斯噪声,噪声标准差是 zS,其中 z 是噪声倍数,决定隐私保护强度与模型性能的权衡。
3. 隐私消耗的累积
根据差分隐私的组合定理(之前介绍过),多次 DP 更新会让隐私预算 (ϵ,δ) 逐步消耗。
因此需要有一种机制来跟踪累计的隐私花费。
4. Moments Accountant 与 RDP
Moments Accountant:Abadi 等人提出的方法,用来跟踪多次 DP 更新的累积隐私消耗,并在预算即将耗尽时终止训练。
Rényi Differential Privacy (RDP):实践中常用的另一种会计方法(隐私账本),它更方便计算和跟踪隐私开销。
差分隐私用于联邦学习
1. 背景
FL 的初衷是保护数据隐私(数据不出本地),但研究表明原始的 FL 算法仍然可能被恶意客户端或服务器攻击,从而重建原始数据。
因此,很多改进方法会结合 DP 来提供 形式化的隐私保证。
2. 两种差分隐私在 FL 中的实现方式
(1) 本地差分隐私 (LDP)
每个客户端在本地执行 DP 优化:
自己做梯度裁剪 + 加噪。
自己跟踪隐私预算消耗。
一旦某个客户端的本地隐私预算耗尽,它就不再能参与后续的训练轮次。
保护粒度:样本级 —— 每条数据都受到 DP 保护。
(2) 集中式差分隐私 (CDP, 又叫用户级 / 客户端级)
客户端只对 整体模型更新 做 L2 范数裁剪,然后发送给服务器。
噪声由 服务器在聚合时统一添加。
这种方式要求客户端 信任服务器,否则服务器可能直接利用原始更新推测出敏感信息。
保护粒度:客户端级 —— 只保证整个客户端的数据不被区分,而不是单条样本。
3. 区别总结
LDP:更强的保护(每个样本),但代价更大(每个客户端要自己加噪、算隐私预算,噪声更大,模型精度可能下降)。
CDP:保护粒度较弱(只到客户端级),但通信和训练更高效,对模型性能影响较小。
相关工作
DP-GAN
1. 背景
合成数据生成是一个活跃的研究领域,常用模型包括:
VAE(变分自编码器)
GAN(生成对抗网络)
以及其他统计方法。
大多数研究依赖中心化数据集(数据集中在一个地方),而使用 联邦学习 (FL) 的研究较少。
本文只关注 隐私保护的合成数据生成方法。
2. DP-GAN(差分隐私 GAN)相关工作
GAN 的核心机制:
生成器 (Generator):生成假数据,想骗过判别器。
判别器 (Discriminator):区分真假数据。
两者通过对抗训练(min-max game)共同优化。
GAN 的生成能力强,能生成高质量图片,但训练过程不稳定,需要大量数据,并且可能不收敛。
结合差分隐私 (DP) 的方法:
PATE-GAN(Jordon 等人):把差分隐私的教师集合框架 PATE 引入 GAN。
CDP-GAN(Augenstein 等人):在联邦学习中,只在客户端更新判别器,生成器由服务器训练,保证 DP。
其他方法:
只同步生成器,判别器加 DP,从而间接给生成器引入隐私。
顺序训练 GAN(而不是并行),提高 DP 和数据使用效率。
将 DP-GAN 扩展到更复杂的架构,如 InfoGAN。
3. 总结要点
DP-GAN 是当前差分隐私合成数据生成的主流方法。
在 FL 场景中,常见策略是:客户端更新判别器(本地数据)+ 服务器更新生成器,或者只同步生成器,确保隐私。
不同研究在训练方式(并行/顺序)、同步策略(生成器/判别器)、DP 实现方式上有所区别。
DP-VAE
1. 研究现状
使用 联邦 VAE (FL-VAE) 来生成数据的工作非常少,只有三篇论文和一篇学位论文涉及。
绝大多数工作仍然是 中心化训练,即生成器训练在一个集中的数据集上完成。
2. 具体方法和贡献
Chen et al. [11]:研究 AE 和 VAE 在对抗三种攻击下的鲁棒性;在 FL 场景下只考虑了 AE,没有用 VAE。
Lomurno et al. [34]:
在本地训练带 DP 的生成器(VAE 或 AE),
收集到服务器形成生成器池(generator pool),供所有参与者生成数据,
类似本文关注解码器,但没有使用 FL 来聚合生成器。
Jiang et al. [26]:提出改进的 LDP 算法,通过两阶段维度选择只聚合稀疏的本地更新,从而降低每步隐私成本。
Georgios [17]:
研究了 LDP 和 CDP 两种 DP 在 FL-VAE 中的应用,
训练条件 VAE(conditional VAE),可以为每个类别生成数据,
局限性:实验只在少量客户端上,使用了较高的隐私预算,认为增加客户端数量可以降低隐私成本。
3. 总结要点
联邦 VAE + DP 的研究数量很少。
大多数工作集中在局部训练生成器 + LDP,而 CDP 很少被考虑,因为它提供的隐私保护比 LDP 弱(用户级 vs 样本级)。
本文的创新在于:通过 FL 聚合 VAE 的解码器,同时引入 DP,提高生成器的实用性和隐私保护。
算法
1. 方法核心思想
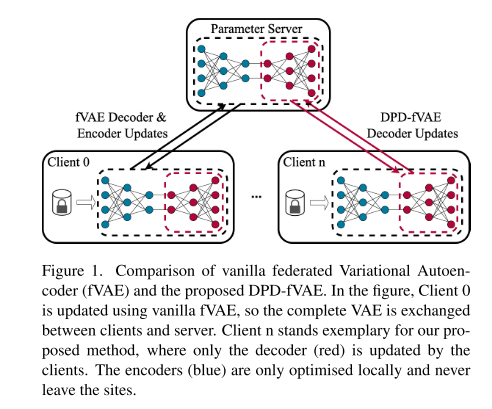
只同步 VAE 的解码器 (Decoder) 部分,而编码器 (Encoder) 保留在客户端私有、个性化。
原因:训练结束后,只需要解码器来生成新数据,编码器在生成新数据时不必共享。
这种做法适用于 CDP(集中式 DP) 或 LDP(本地 DP),分别称为 C-DPD-fVAE 和 L-DPD-fVAE。
2. 训练流程(核心步骤)

服务器初始化 解码器权重 和 隐私账本。
每个客户端初始化 本地编码器权重。
训练循环(多轮 global rounds):
服务器随机选择部分客户端。
每个客户端在本地做若干轮训练(更新编码器和解码器权重),
客户端计算 解码器权重更新 Δθ,并进行 L2 范数裁剪。
服务器聚合这些 Δθ,并加入高斯噪声(控制 DP),更新全局解码器。
随时检查隐私预算,如果耗尽就停止训练。
LDP 的做法:裁剪、加噪和隐私累计在客户端完成;CDP 的做法:服务器统一加噪。
3. DPD-fVAE 的 DP 优势
只同步解码器 → 聚合参数减少约一半 → 可以选择较小的 L2 范数裁剪值 S → 需要的噪声更少 → 同样的隐私预算下模型效果更好。
编码器更新可以用非 DP 优化器 → 不直接引入噪声 → 训练效果更好。
减少传输参数 → 提高通信效率(虽然本文未专门评估)。
4. 超参数与训练效果的关系
L2 范数裁剪 S:
太大 → 少裁剪,但需要加更多噪声。
太小 → 多裁剪,信息丢失,训练受影响。
影响 L2 范数大小的因素:
本地学习率、优化器类型(是否带动量)、本地训练轮数 E。
网络参数数量越多 → 全局 L2 范数越大 → 需要更多噪声。
因此 只同步解码器 可以降低 L2 范数、减少噪声消耗,同时保证 DP。
实验
实验设置
1. 数据集(Datasets)
MNIST / Fashion-MNIST:28×28 灰度图像,10 个类别,每个数据集 60,000 训练样本,10,000 测试样本。
数据按 i.i.d. 分布分配到 500 或 100 个客户端,每个客户端有 120 或 600 样本,用于模拟不同现实场景。
CelebA:32×32 RGB 名人脸图片,标签为性别(male/female),分组按 celebrity ID,训练样本 177,457,客户端 9,343,每个客户端平均 19 张训练样本。
约 10% 的图片被拆分成中心化测试集(22,831 样本)。
2. 评价指标(Evaluation Metrics)
主观视觉检查:人工观察生成图像质量。
分类器准确率:用生成的合成数据训练分类器(Logistic Regression、MLP、CNN),在中心化测试集上评估,反映生成数据的可用性。
Fréchet Inception Distance (FID):衡量生成数据与真实数据在特征分布上的相似性,数值越低越好。
3. 实现细节(Implementation)
使用 TensorFlow 2.5 + TensorFlow Federated 0.19,RDP accountant 跟踪 DP 隐私消耗。
模拟分布式场景在单 GPU 上并行执行。
VAE 架构:编码器和解码器使用 CNN。
实验使用 NVIDIA A100、A40 或 RTX Titan GPU。
4. 超参数优化(Hyperparameter Optimisation)
策略:
参数组合少于 150 → 全部网格搜索
参数组合多 → 随机搜索 100 次
模型相关:先用中心化训练确定最佳模型架构、潜在维度和 β 值(重建与 KL 权衡),固定 β=0.01。
非私有实验:优化批次大小 B、本地轮数 E、客户端采样概率 q、优化器、学习率 η 和全局动量 ρ。
DP 实验:
隐私参数 δ=1e-5,ε 默认 10,也做了 ε=1 的低隐私预算实验。
优化 L2 范数裁剪阈值 S 和噪声倍数 z,同时优化 FL 相关超参数。
训练直到隐私预算耗尽或最大 1000 轮。
非隐私保护版本
1. 实验目的
验证在 不使用 DP 的情况下,只同步解码器的联邦 VAE 是否还能达到和全 VAE 同步相当的性能。
不进行梯度裁剪和加噪,保持训练简单。
2. 实验结果
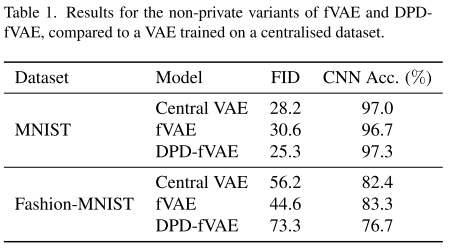
对比指标:CNN 分类器准确率和 FID(生成数据与真实数据的相似度)。
与三种方法比较:
只同步解码器的联邦 VAE(本文方法的非 DP 版本)
传统全 VAE 同步的联邦训练(vanilla fVAE)
中心化训练的 VAE
结果显示:
只同步解码器的联邦 VAE 与全同步联邦 VAE 和中心化 VAE 性能相当,在 Fashion-MNIST 上略低一些。
超参数优化显示,两种联邦 VAE 训练都很稳健,不同参数组合下都能取得较好分数。
3. 结论
只同步解码器不会降低数据生成器的性能。
这为后续引入差分隐私(只加噪解码器)打下了基础,因为非 DP 情况下性能已经可比全同步 VAE。
DPD-fVAE 在差分隐私训练中对 L2 范数裁剪和噪声的鲁棒性
1. L2 范数裁剪的鲁棒性
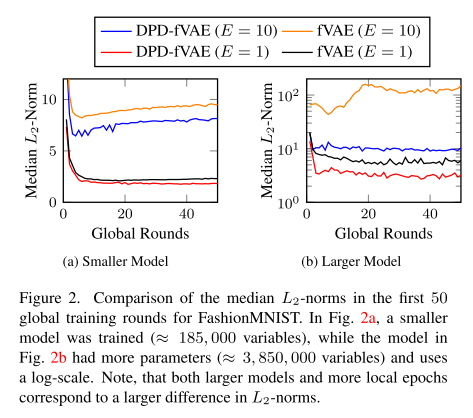
背景:在集中式差分隐私 (CDP) 联邦学习中,需要对客户端的权重更新做 L2 范数裁剪,限制更新幅度,再加噪声保证隐私。
发现:
DPD-fVAE(只同步解码器)相比全 VAE 同步的 FL,客户端更新的 L2 范数更小。
小的 L2 范数意味着裁剪对更新的影响更小,因此模型对裁剪更 鲁棒。
实验验证:在全局 L2 范数裁剪 S = 0.2 时,DPD-fVAE 生成的图像比 vanilla fVAE 更清晰。
影响因素:本地训练轮数更多、批次更小、网络更大 → 这种鲁棒性差异更明显。
2. 噪声的鲁棒性

背景:差分隐私训练还需要在聚合更新时加入高斯噪声。
实验:设置不同噪声水平(标准差 σ),比较 DPD-fVAE 和 vanilla fVAE 的生成效果。
结果:
σ = 0.05 时,DPD-fVAE 仍能生成较清晰图像。
vanilla fVAE 在相同噪声下生成的图像明显模糊、质量下降。
3. 结论
只同步解码器减少了被裁剪和加噪的参数量,降低了更新幅度,因此 DPD-fVAE 在 CDP 环境下对 L2 范数裁剪和噪声更 鲁棒。
这说明 DPD-fVAE 可以在保持差分隐私的同时,更好地维护生成数据质量。
隐私保证
1. 实验目标与数据集选择
目标:评估 DPD-fVAE 在 CDP(集中式 DP)和 LDP(本地 DP)场景下的性能。
数据集选择依据:
CDP:需要大量客户端以便全局采样概率 q 可以较小,同时 qN 仍够大 → 使用 MNIST(500 客户端)和 CelebA(9343 客户端)。
LDP:依赖每个客户端的本地数据量 → 使用 MNIST(120 本地样本)和 Fashion-MNIST(600 本地样本)。
2. 主要发现
隐私预算对生成效果的影响:
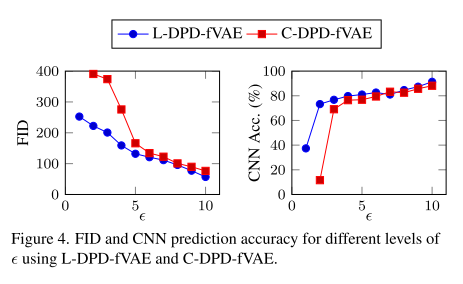

较小的 ε → 隐私更强,但生成的数据质量下降。
在 500 个客户端、每个 120 样本的 MNIST 实验中,L-DPD-fVAE 性能优于 C-DPD-fVAE。
与 vanilla fVAE 对比:
使用相同 L2 范数裁剪和 LDP 条件下,vanilla fVAE 很难收敛,生成图像质量差。
DPD-fVAE 能够生成高质量图像,验证了只同步解码器的优势。
跨数据集实验:

对 MNIST、Fashion-MNIST 和 CelebA 进行 CDP/LDP 测试。
CelebA 图像质量较差,原因是客户端数据极少,即使在非私有 FL 下也很难训练。
但仍获得 FID 261.7 和 CNN 准确率 69.0,与已有工作相当。
3. 结论
DPD-fVAE 在 CDP 和 LDP 下均能生成合理质量的合成数据,尤其在 LDP 条件下优于 vanilla fVAE。
数据分布和客户端数量对生成效果有显著影响(小数据量或极端分布会降低生成质量)。
与其他方法对比
1. 性能对比
表格中展示了 DPD-fVAE 在 MNIST 和 Fashion-MNIST 上的性能,与相关工作对比(参考 [9, 25] 的结构)。
结果显示:
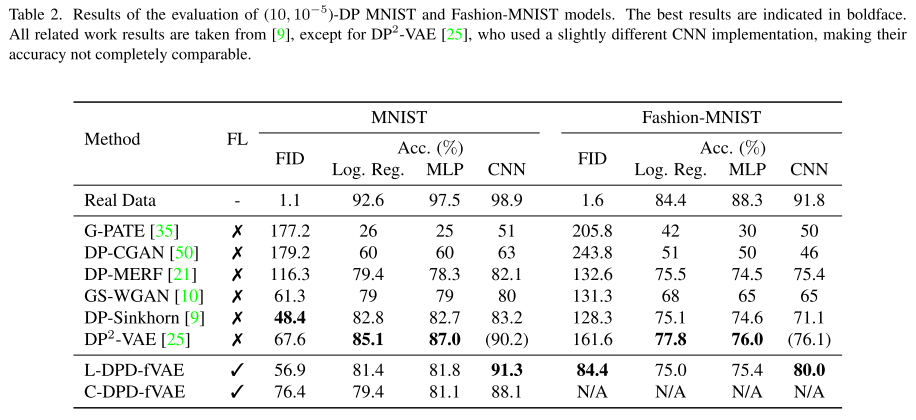
DPD-fVAE 达到非常有竞争力的成绩,即使其他可对比的工作 没有使用联邦学习。
本文实验中 LDP 的本地采样概率更低 → 训练更困难,但仍能取得优异表现。
图 8 给出了 MNIST 的可视化对比,其他数据集可视化结果见附录。

2. 与现有 FL+DP 方法的差异
大多数使用 联邦学习训练生成器的工作没有考虑 DP → 对隐私敏感的现实场景不适用。
那些考虑 DP 的方法 [41, 55, 56]:
未公开代码
使用不同数据集 → 无法直接比较
[10] 做了联邦实验,但:
使用非常大的、不现实的隐私预算
GitHub 不包含 FL 代码 → 无法复现
3. 总结
DPD-fVAE 在考虑隐私保护和联邦学习的条件下,仍能达到或接近非联邦、非私有方法的性能。
同时,本方法在现实可用性(FL + DP + 代码可复现)方面更有优势。