Python4-seaborn
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 前言
- 1. seaborn
- 1.1 可视化数据的分布
- 1.2 绘制单变量分布
- 1.3 绘制双变量分布
- 1.4 绘制散点图
- 1.5 绘制二维直方图
- 1.6 绘制核密度估计图形
- 1.7 绘制成对的双变量分布
- 2. 用分类数据绘图
- 2.1 类别散点图
- 2.2 类别内的数据分布
- 2,3 绘制箱形图
- 2.4 绘制提琴图
- 2.5 类别内的统计估计
- 2.6 绘制条形图点图
- 3. 案例:NBA球员数据分析
- 3.1 效率值分析
- 3.2 基本分析
- 3.3 seaborn单变量
- 3.3 seaborn双变量
- 3.5 多变量
- 3.6 衍生变量
- 3.7 球队数据分析
- 4. 北京租房数据统计分析
- 4.1 重复值和空值处理
- 4.2 数据转换类型
- 4.3 房源数量、位置分布分析
- 4.4 户型数量分析
- 4.5 平均租金分析
- 4.6 面积区间分析
- 总结
前言
1. seaborn
Matplotlib虽然已经是比较优秀的绘图库了,但是它有个今人头疼的问题,那就是API使用过于复杂,它里面有上千个函数和参数,属于典型的
那种可以用它做任何事,却无从下手。
Seaborn基于 Matplotlib核心库进行了更高级的API封装,可以轻松地画出更漂亮的图形,而Seaborn的漂亮主要体现在配色更加舒服,以及图
形元素的样式更加细腻。
不过,使用Seaborn绘制图表之前,需要安装和导入绘图的接口,具体代码如下:
# 安装
pip install seaborn
# 导入
import seaborn as sns
1.1 可视化数据的分布
当处理一组数据时,通常先要做的就是了解变量是如何分布的。
对于单变量的数据来说 采用直方图或核密度曲线是个不错的选择,
对于双变量来说,可采用多面板图形展现,比如 散点图、二维直方图、核密度估计图形等。
针对这种情况, Seaborn库提供了对单变量和双变 量分布的绘制函数,如 displot()函数、 jointplot()函数,下面来介绍这些函数的使用,具体内容如下:
1.2 绘制单变量分布
可以采用最简单的直方图描述单变量的分布情况。 Seaborn中提供了 histplot()函数,它默认绘制的是一个带有核密度估计曲线的直方图。
distplot()函数的语法格式如下。
import seaborn as sns
import numpy as np
arr = np.random.randn(100)
sns.histplot(arr, bins=10, kde=True)
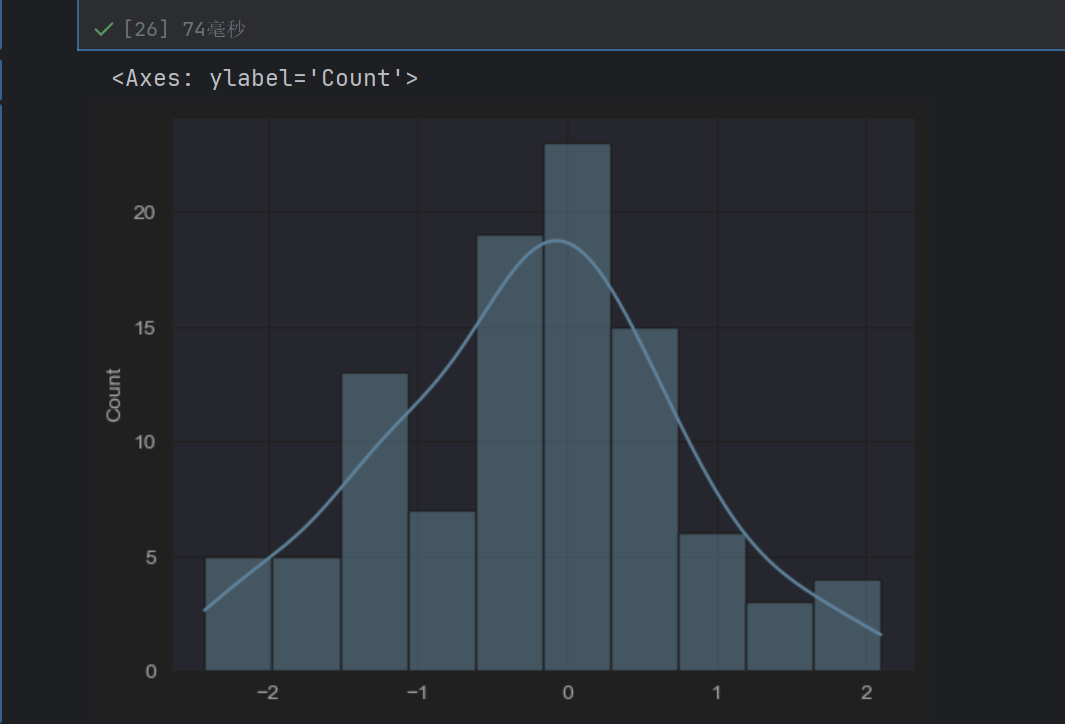
核密度估计曲线就是上面的曲线
np.random.seed(0)
arr = np.random.randn(100)
sns.histplot(arr, bins=10, kde=True)
加上np.random.seed(0),随机数生成都是一样的,图也是一样的了
1.3 绘制双变量分布
两个变量的二元分布可视化也很有用。在 Seaborn中最简单的方法是使用 jointplot()函数,该函数可以创建一个多面板图形,比如散点图、二维直方图、核密度估计等,以显示两个变量之间的双变量关系及每个变量在单坐标轴上的单变量分布
jointplot()函数的语法格式如下。
seaborn.jointplot(x, y, data=None,
kind='scatter', stat_func=None, color=None,
ratio=5, space=0.2, dropna=True)
上述函数中常用参数的含义如下:
(1) kind:表示绘制图形的类型。
(3) color:表示绘图元素的颜色。
(5) ratio:表示中心图与侧边图的比例。该参数的值越大,则中心图的占比会越大。
(6) space:用于设置中心图与侧边图的间隔大小。
下面以散点图、二维直方图、核密度估计曲线为例,为大家介绍如何使用 Seaborn绘制这些图形。
1.4 绘制散点图
调用 seaborn.jointplot()函数绘制散点图的示例如下。
import numpy as np
import pandas as pd
import seaborn as sns
# 创建DataFrame对象
dataframe_obj = pd.DataFrame({"x": np.random.randn(500),"y": np.random.randn(500)})
# 绘制散布图
sns.jointplot(x="x", y="y", data=dataframe_obj)
df = pd.DataFrame({"x":np.random.randn(500),"y":np.random.randn(500)})
sns.jointplot(x="x",y="y",data=df)
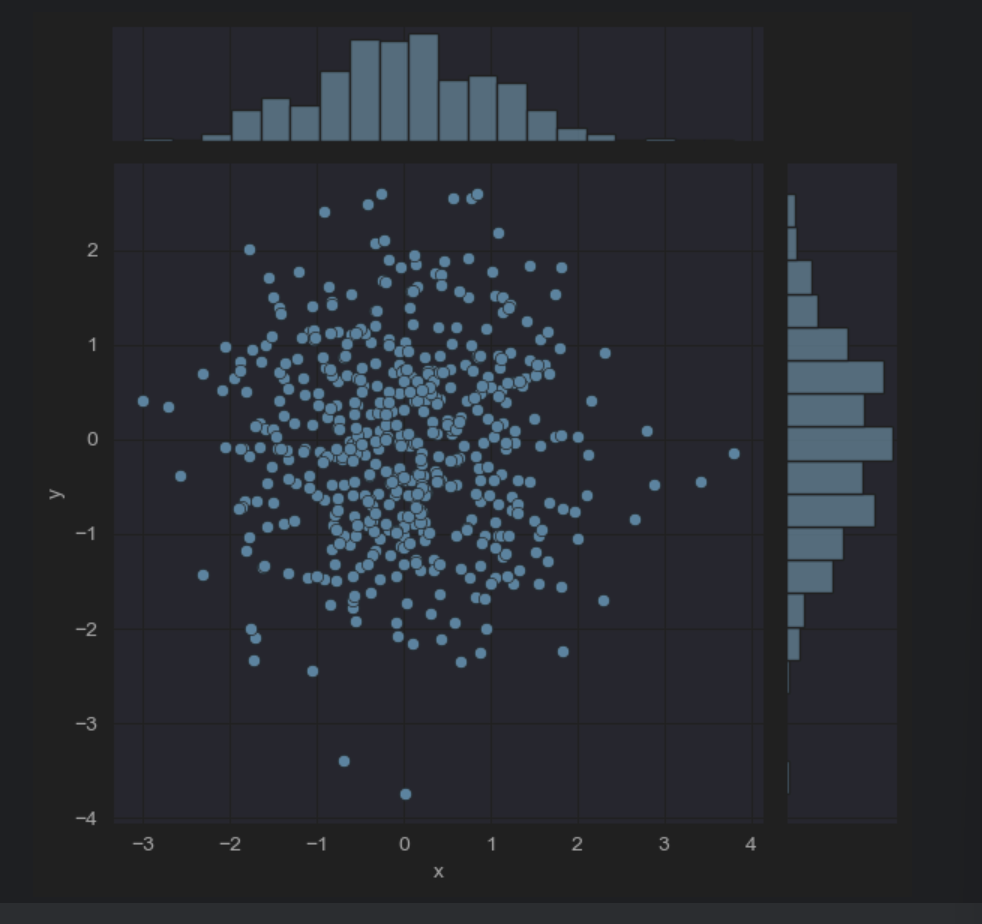
这个x是df里面的x列数据,所以为"x"
df = pd.DataFrame({"x":np.random.randn(500),"y":np.random.randn(500)})
sns.jointplot(x="x",y="y",data=df,kind="scatter")
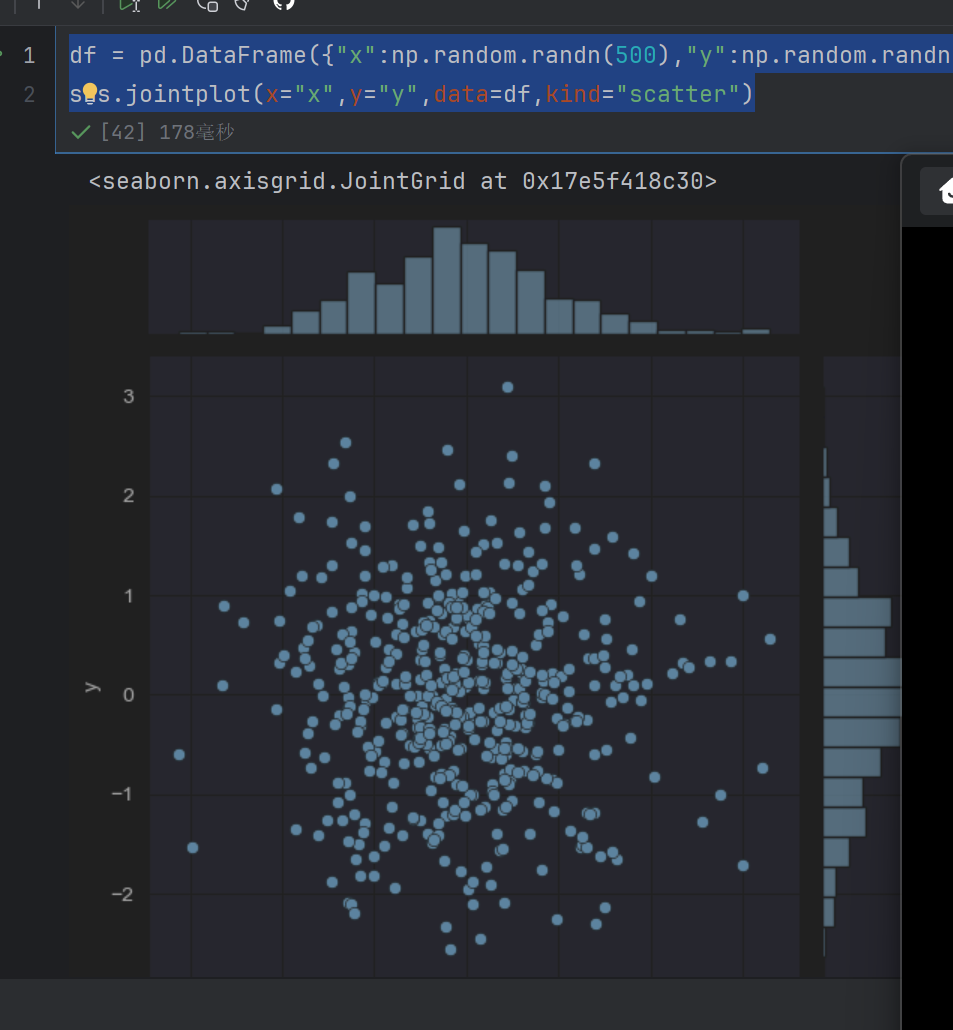
scatter就是散点图
df = pd.DataFrame({"x":np.random.randn(500),"y":np.random.randn(500)})
sns.jointplot(x="x",y="y",data=df,kind="scatter",color="r")
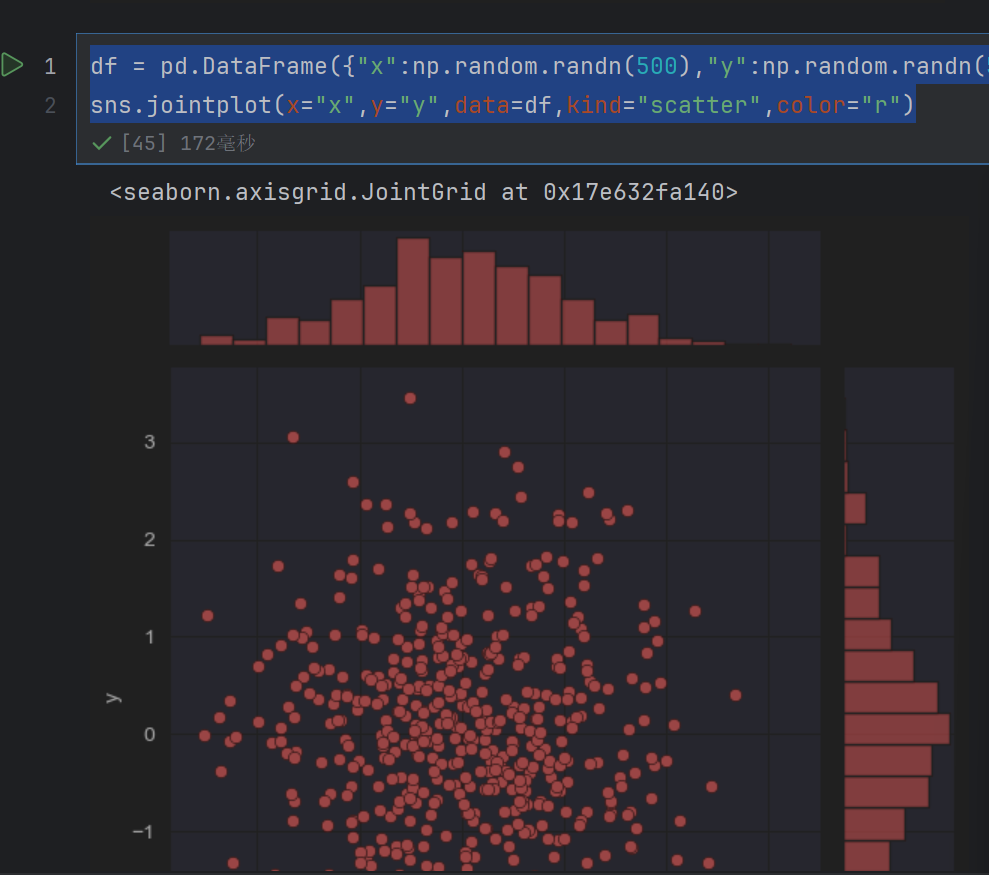
df = pd.DataFrame({"x":np.random.randn(500),"y":np.random.randn(500)})
sns.jointplot(x="x",y="y",data=df,kind="scatter",color="r",ratio=80)
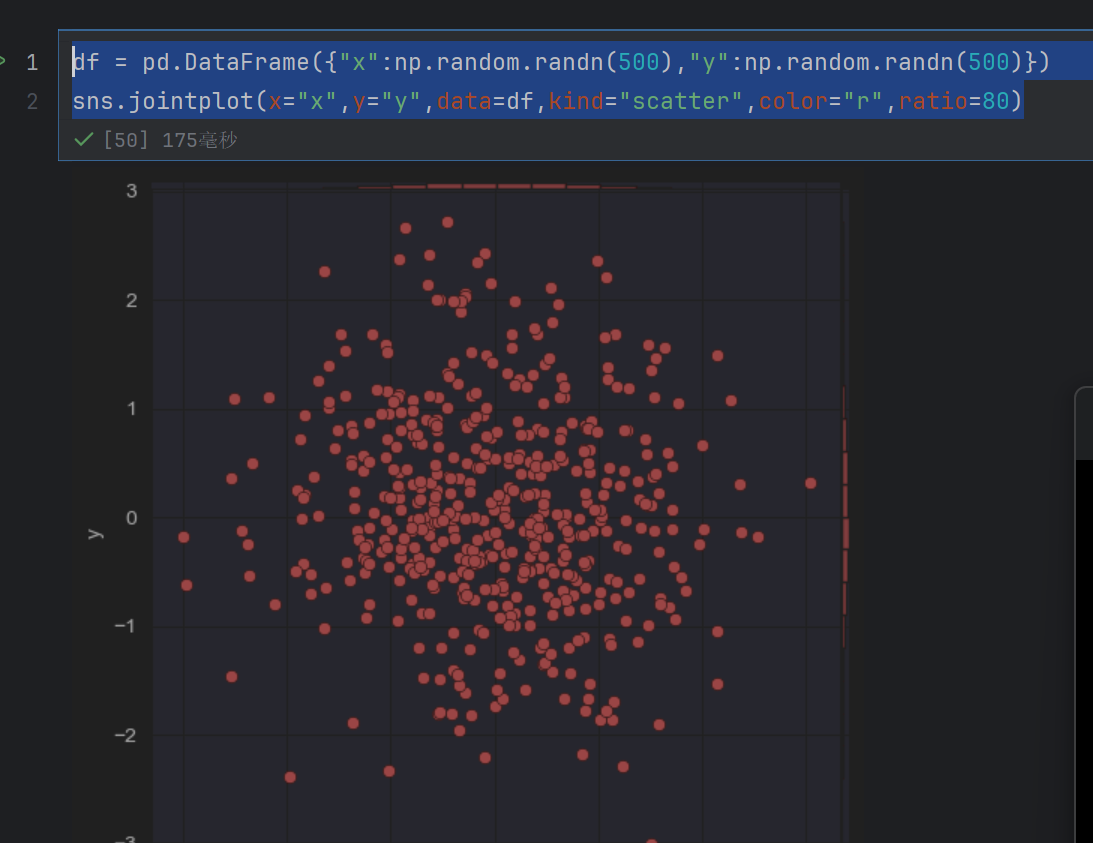
df = pd.DataFrame({"x":np.random.randn(500),"y":np.random.randn(500)})
sns.jointplot(x="x",y="y",data=df,kind="scatter",color="r",ratio=5,space=5)
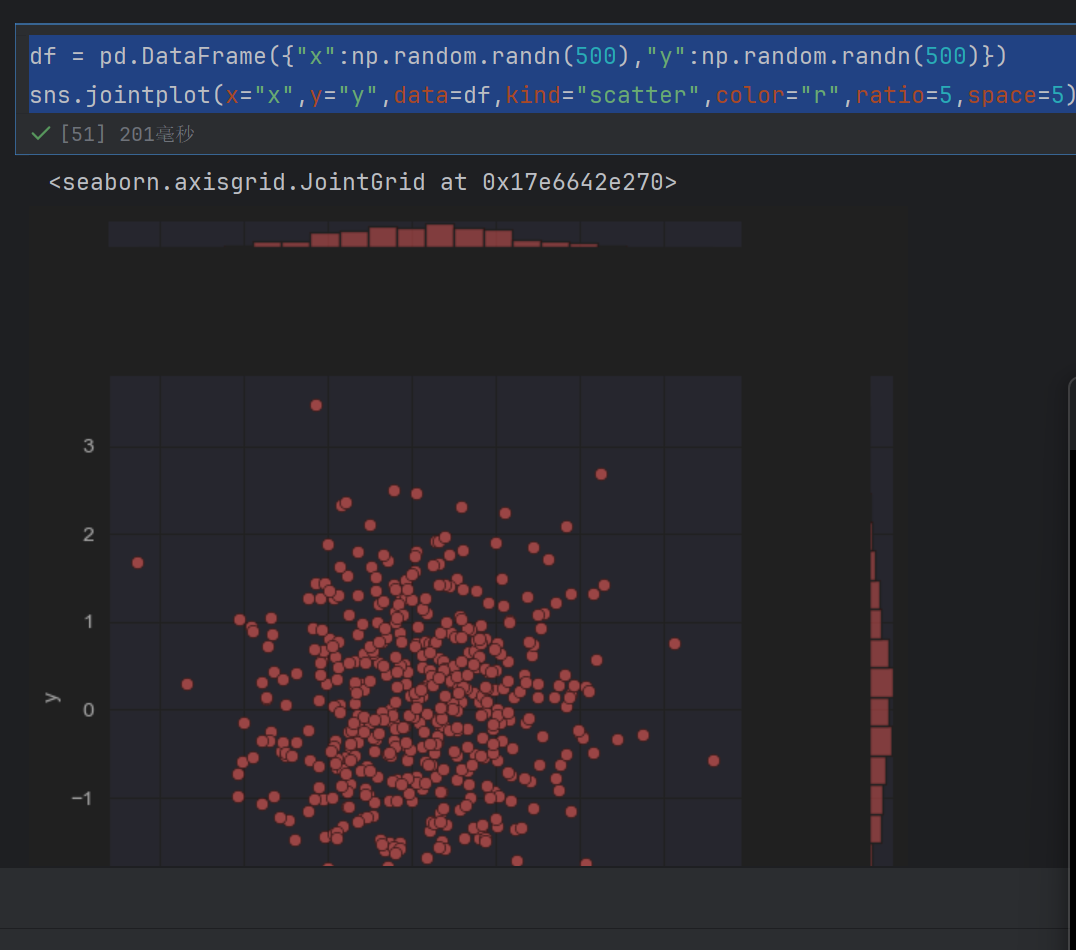
1.5 绘制二维直方图
二维直方图类似于“六边形”图,主要是因为它显示了落在六角形区域内的观察值的计数,适用于较大的数据集。当调用 jointplot()函数时,只要传入kind=“hex”,就可以绘制二维直方图,具体示例代码如下。
从六边形颜色的深浅,可以观察到数据密集的程度,另外,图形的上方和右侧仍然给出了直方图。注意,在绘制二维直方图时,最好使用白色背景。
sns.jointplot(x="x",y="y",data=df,kind="hex")
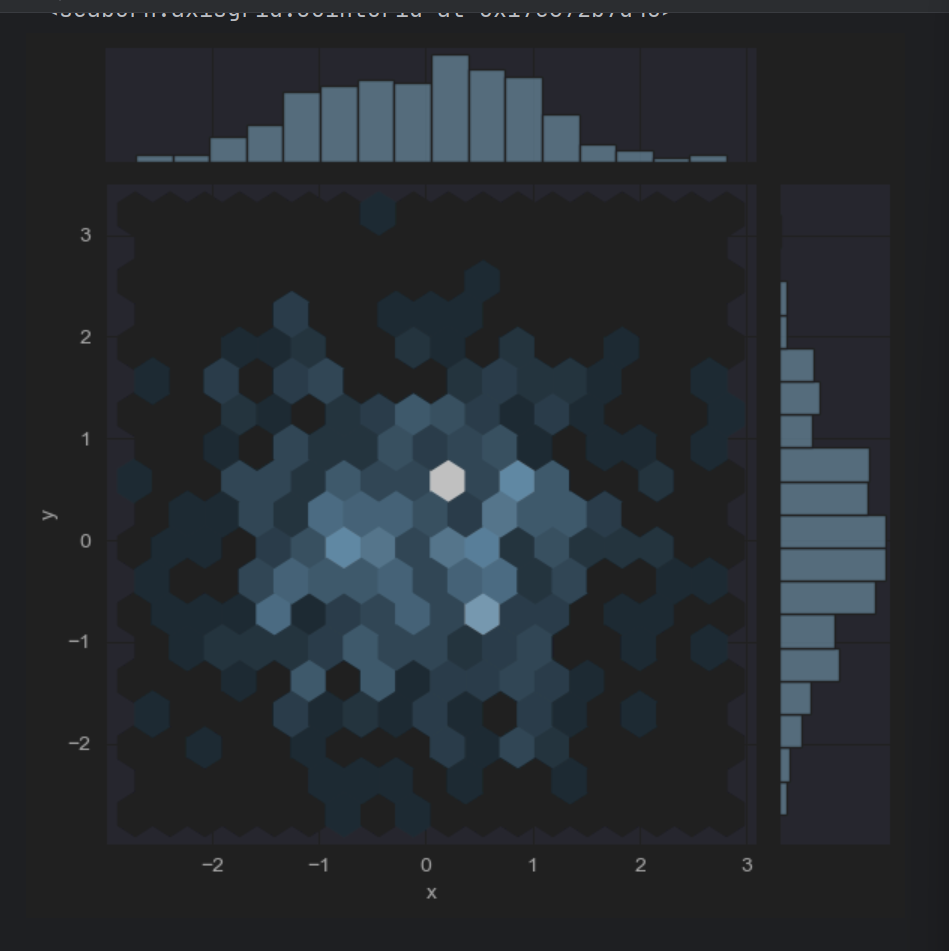
1.6 绘制核密度估计图形
通过观等高线的颜色深浅,可以看出哪个范围的数值分布的最多,哪个范围的数值分布的最少
sns.jointplot(x="x",y="y",data=df,kind="kde")
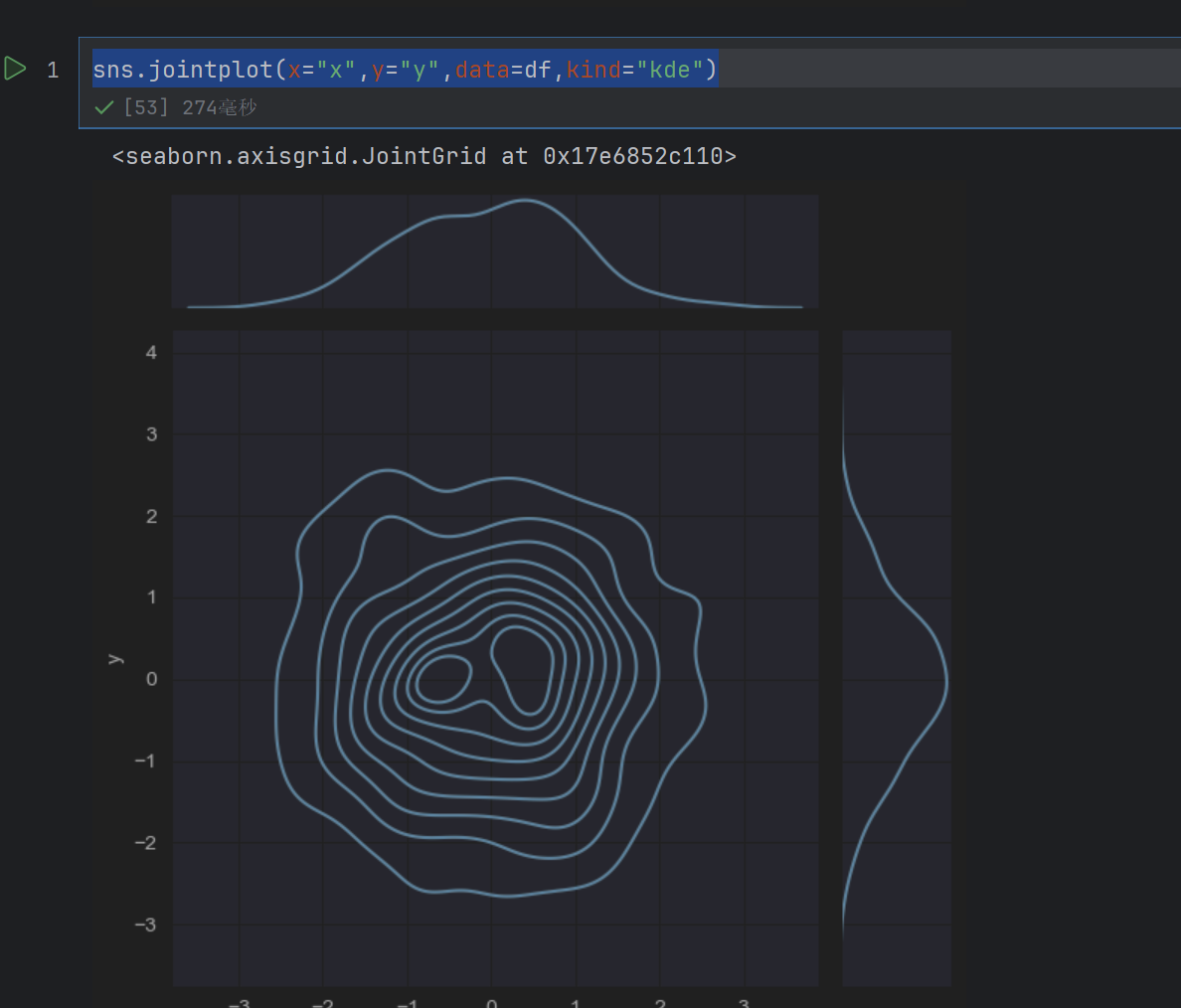
sns.jointplot(x="x",y="y",data=df,kind="kde",fill=True)
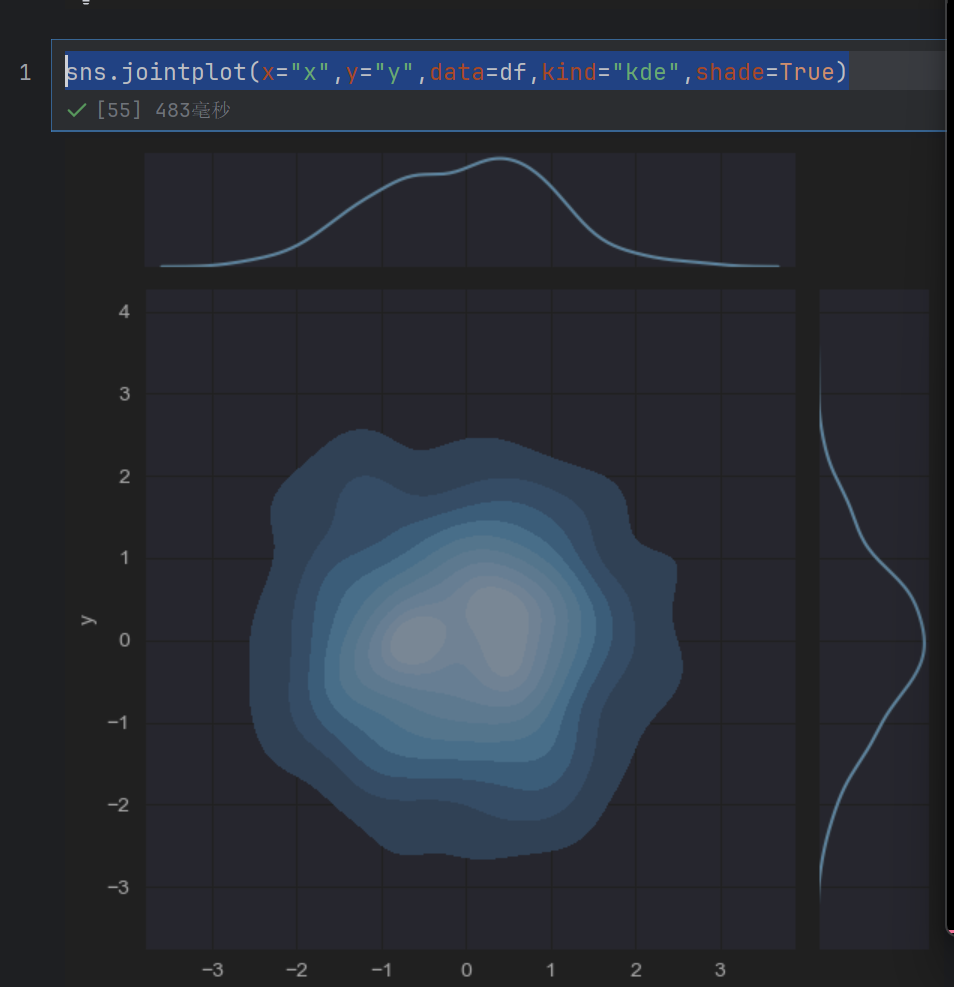
1.7 绘制成对的双变量分布
要想在数据集中绘制多个成对的双变量分布,则可以使用pairplot()函数实现,该函数会创建一个坐标轴矩阵,并且显示Datafram对象中每对变量的关系。另外,pairplot()函数也可以绘制每个变量在对角轴上的单变量分布。
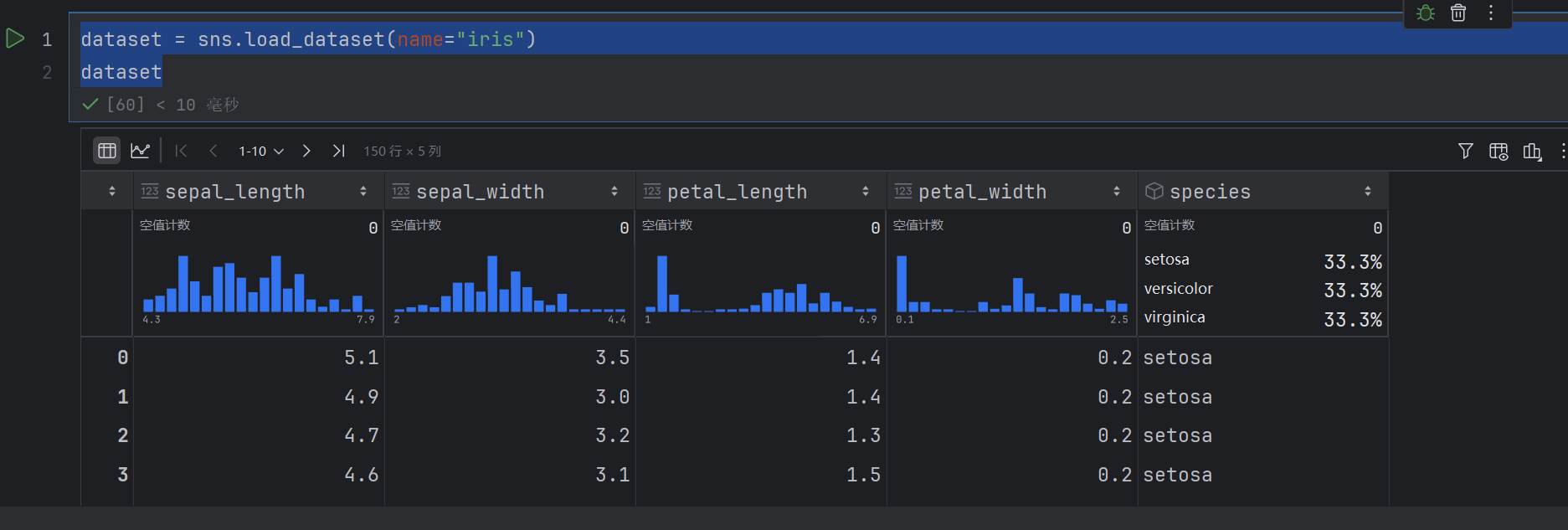
# 加载seaborn中的数据集
dataset = sns.load_dataset(name="iris")
dataset
sns.pairplot(dataset)
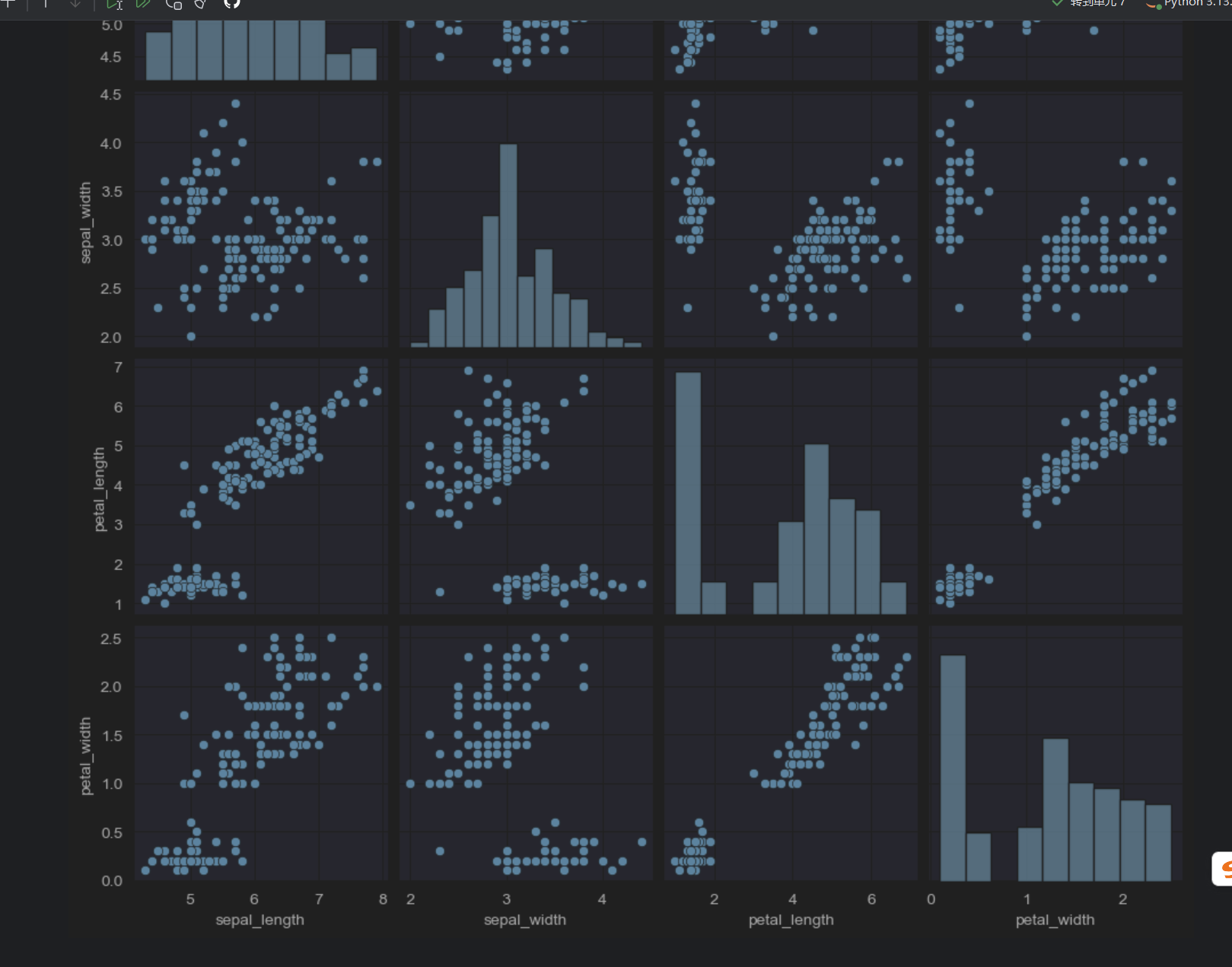
我们就可以看出,有些有线性关系,斜着的,都是直方图,表示这个字段本身的分布
2. 用分类数据绘图
数据集中的数据类型有很多种,除了连续的特征变量之外,最常见的就是类别型的数据了,比如人的性别、学历、爱好等,这些数据类型都不能用连续的变量来表示,而是用分类的数据来表示。
Seaborn针对分类数据提供了专门的可视化函数,这些函数大致可以分为如下三种:
分类数据散点图: swarmplot()与 stripplot()。
类数据的分布图: boxplot() 与 violinplot()。
分类数据的统计估算图:barplot() 与 pointplot()。
2.1 类别散点图
通过 stripplot()函数可以画一个散点图, stripplot0函数的语法格式如下。
seaborn.stripplot(x=None, y=None, hue=None, data=None, order=None, hue_order=None, jitter=False)
(1) x,y,hue:用于绘制长格式数据的输入。
(2) data:用于绘制的数据集。如果x和y不存在,则它将作为宽格式,否则将作为长格式。
(3) jitter:表示抖动的程度(仅沿类別轴)。当很多数据点重叠时,可以指定抖动的数量或者设为Tue使用默认值。
hue是标签值–》不同类,按照不同的颜色,order是目标情况,
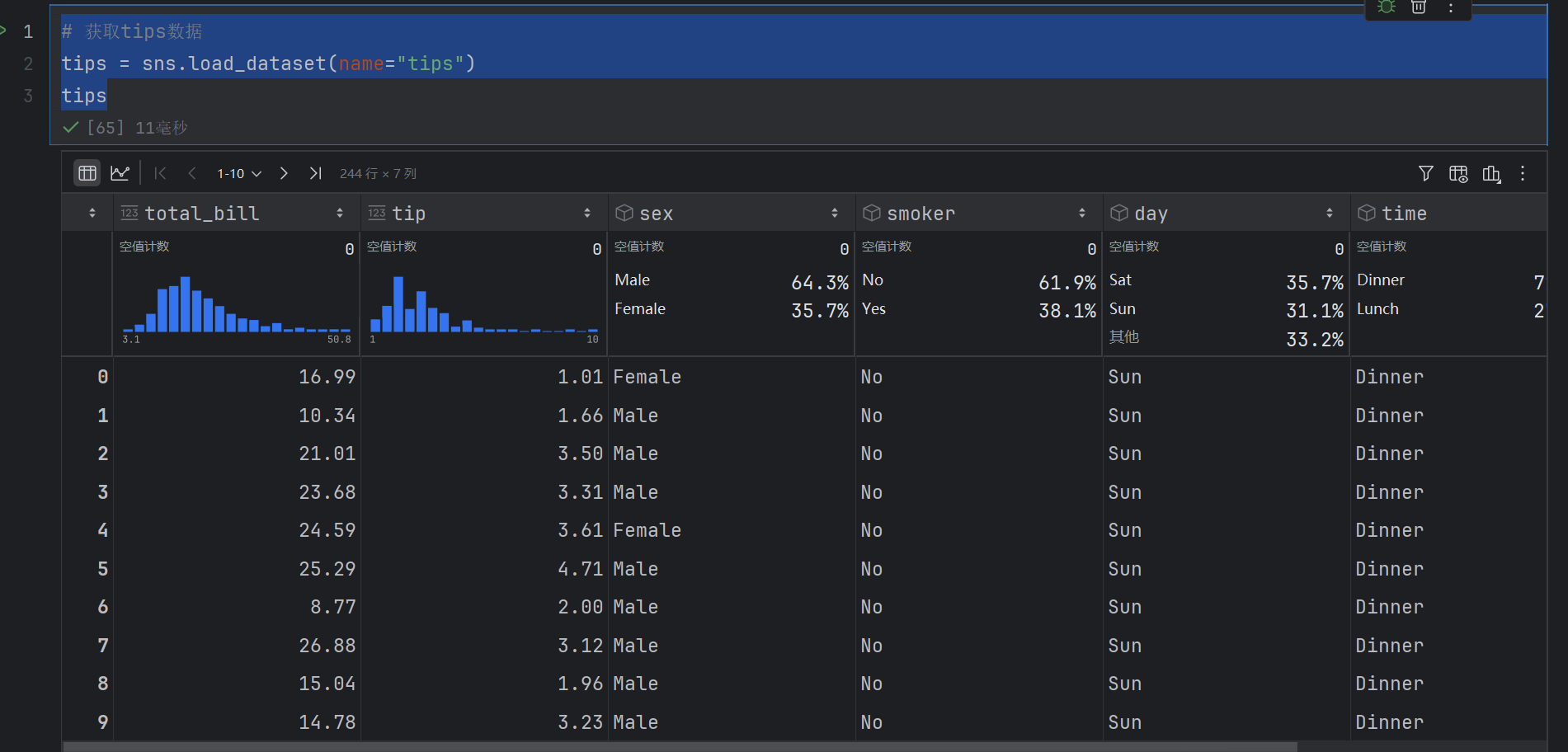
# 获取tips数据
tips = sns.load_dataset(name="tips")
tips
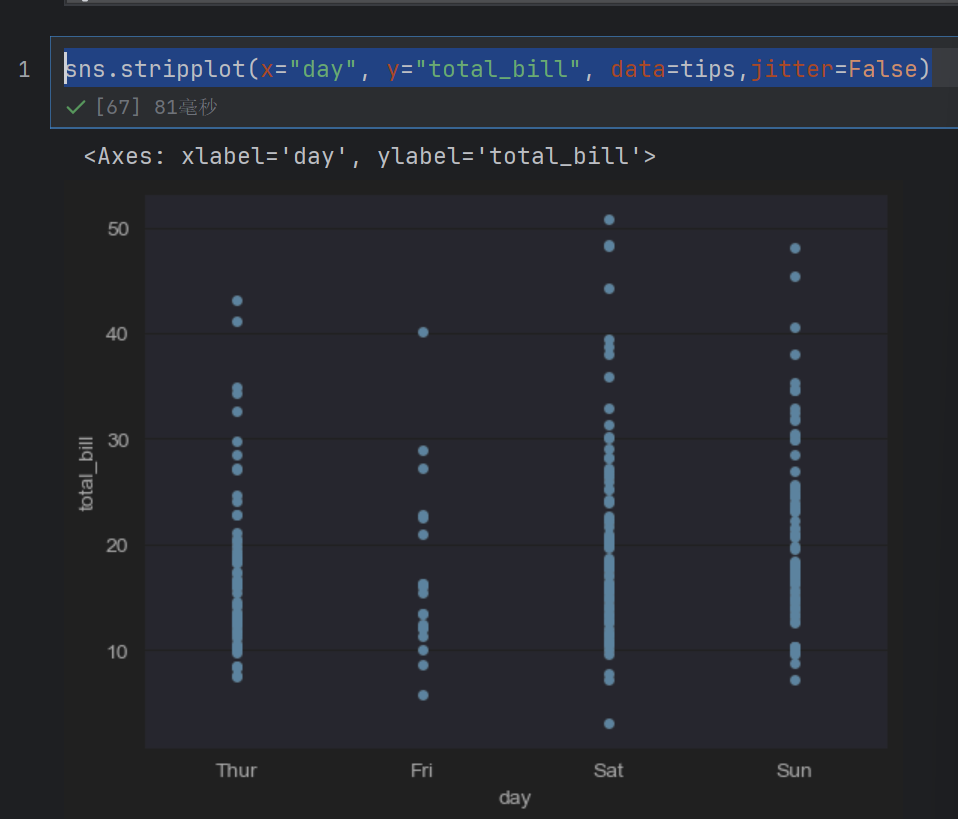
sns.stripplot(x="day", y="total_bill", data=tips,jitter=False)
sns.stripplot(x="day", y="total_bill", data=tips,jitter=False,hue="time")
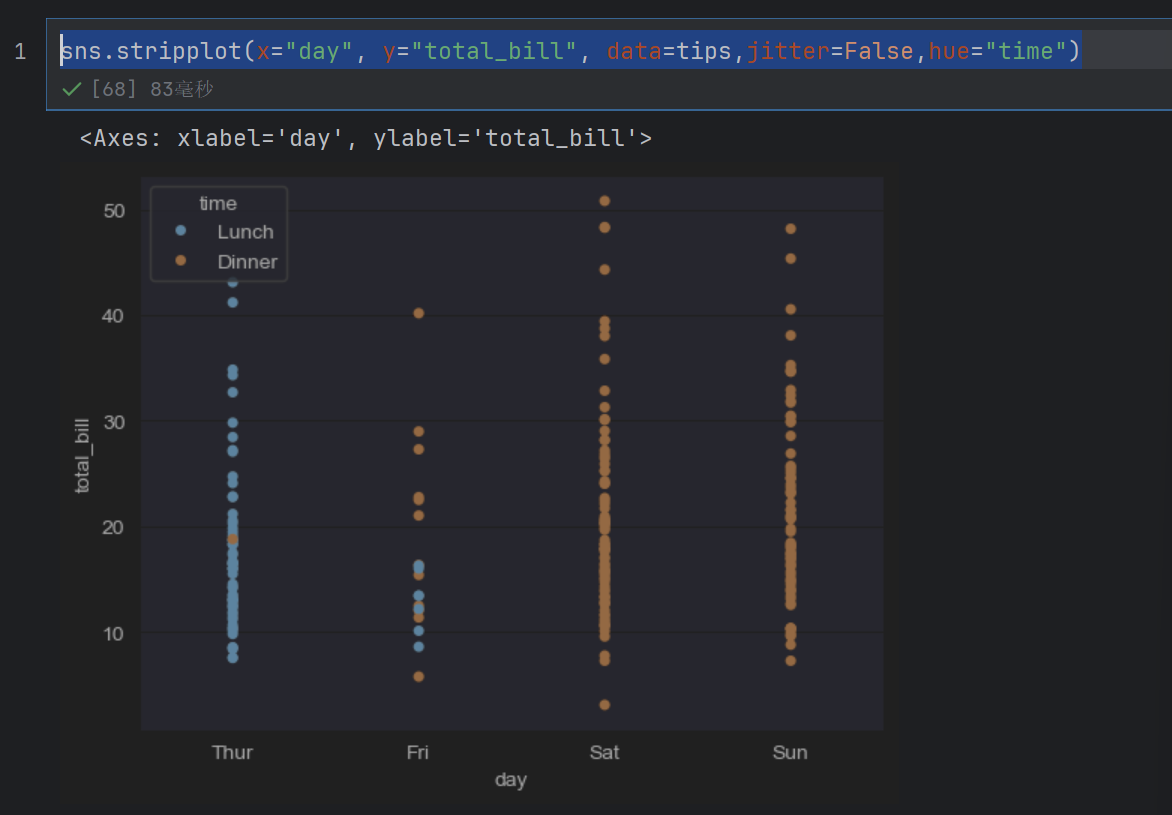
hue是目标值,我们传入的这个time只有两种值,所以用两个颜色区分
sns.stripplot(x="day", y="total_bill", data=tips,jitter=True,hue="time")
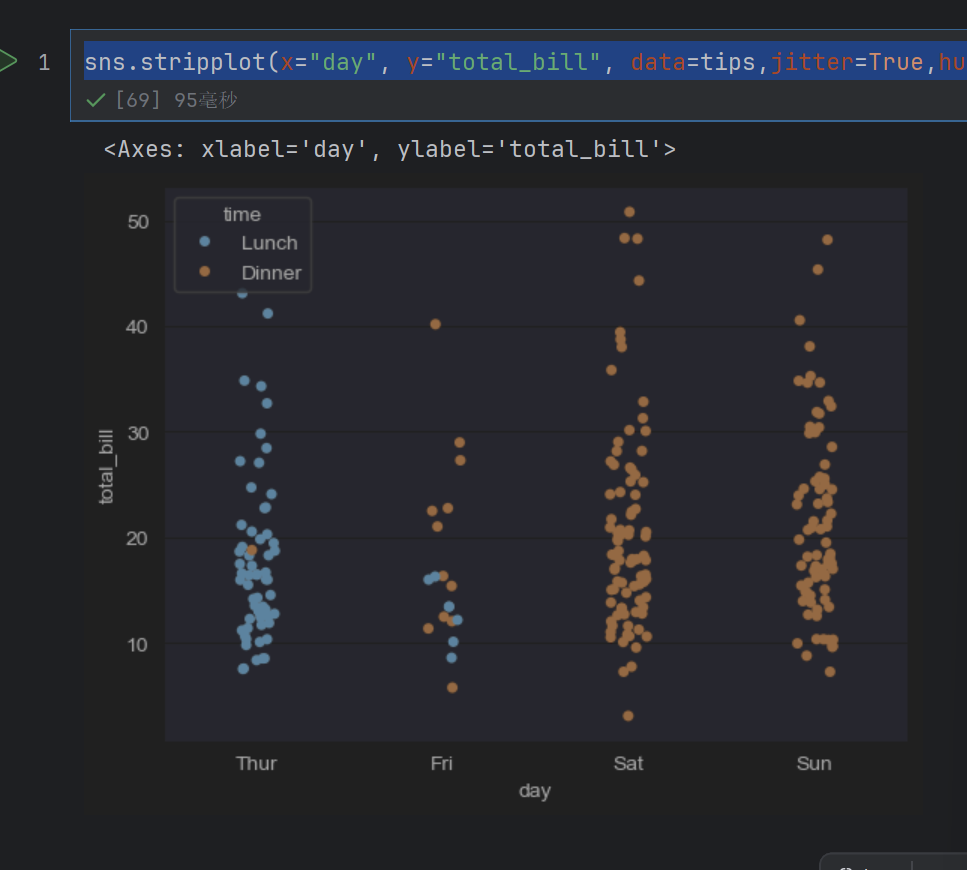
这样就抖动起来了,尽量不重合
sns.swarmplot(x="day", y="total_bill", data=tips)
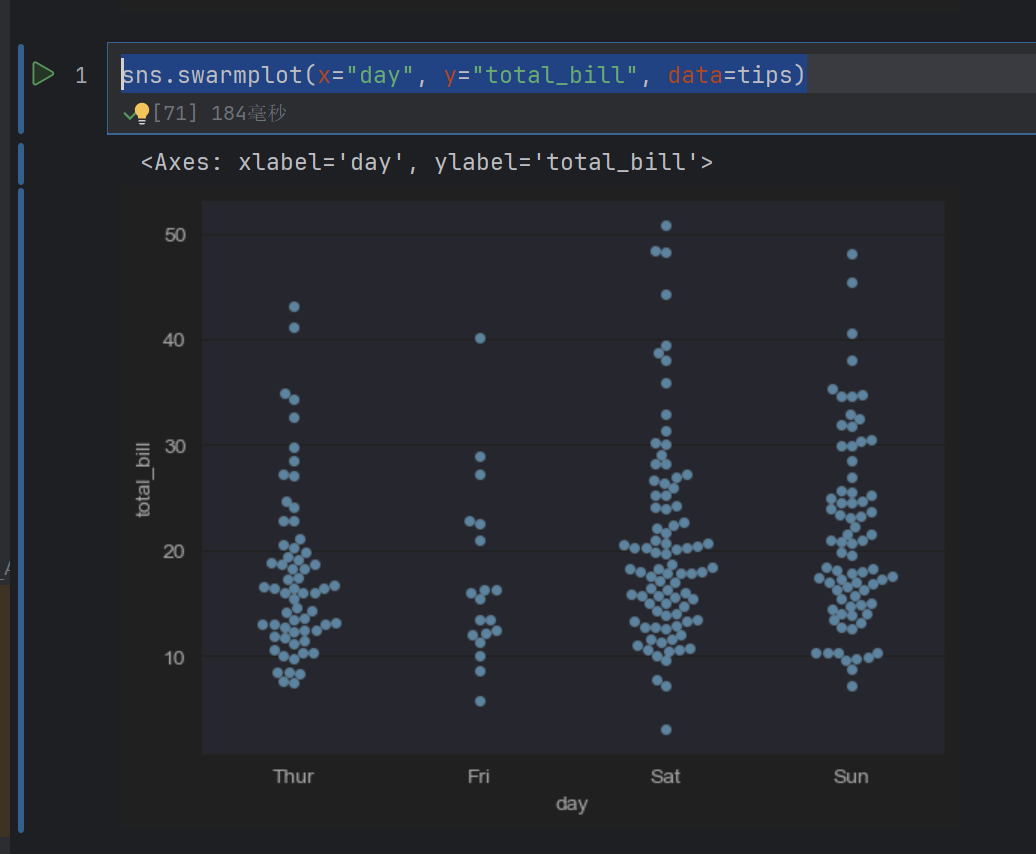
这个是严格不重叠
2.2 类别内的数据分布


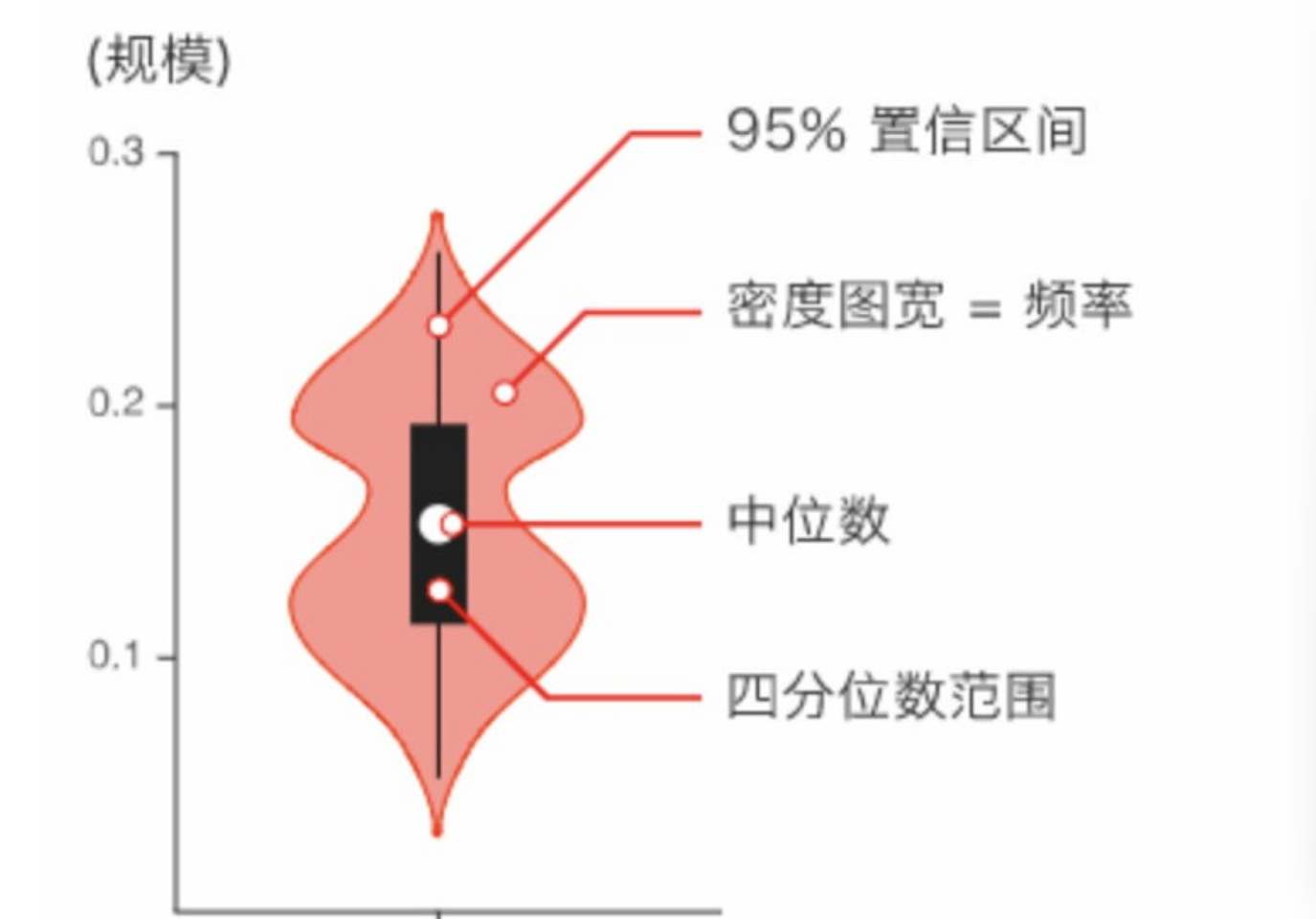
2,3 绘制箱形图
seaborn中用于绘制箱形图的函数为 boxplot(),其语法格式如下:
seaborn.boxplot(x=None, y=None, hue=None, data=None, orient=None, color=None, saturation=0.75, width=0.8)
常用参数的含义如下:
(1) palette:用于设置不同级别色相的颜色变量。---- palette=["r","g","b","y"]
(2) saturation:用于设置数据显示的颜色饱和度。---- 使用小数表示
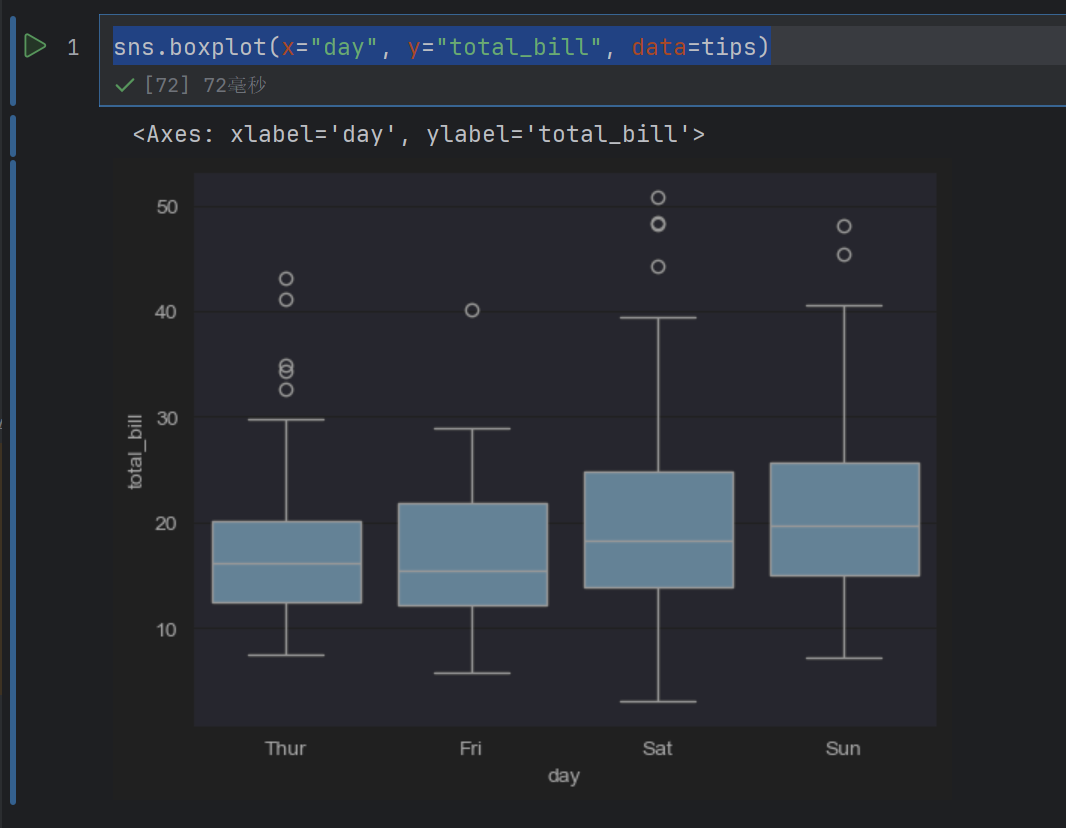
sns.boxplot(x="day", y="total_bill", data=tips)
sns.boxplot(x="day", y="total_bill", data=tips,hue="time")
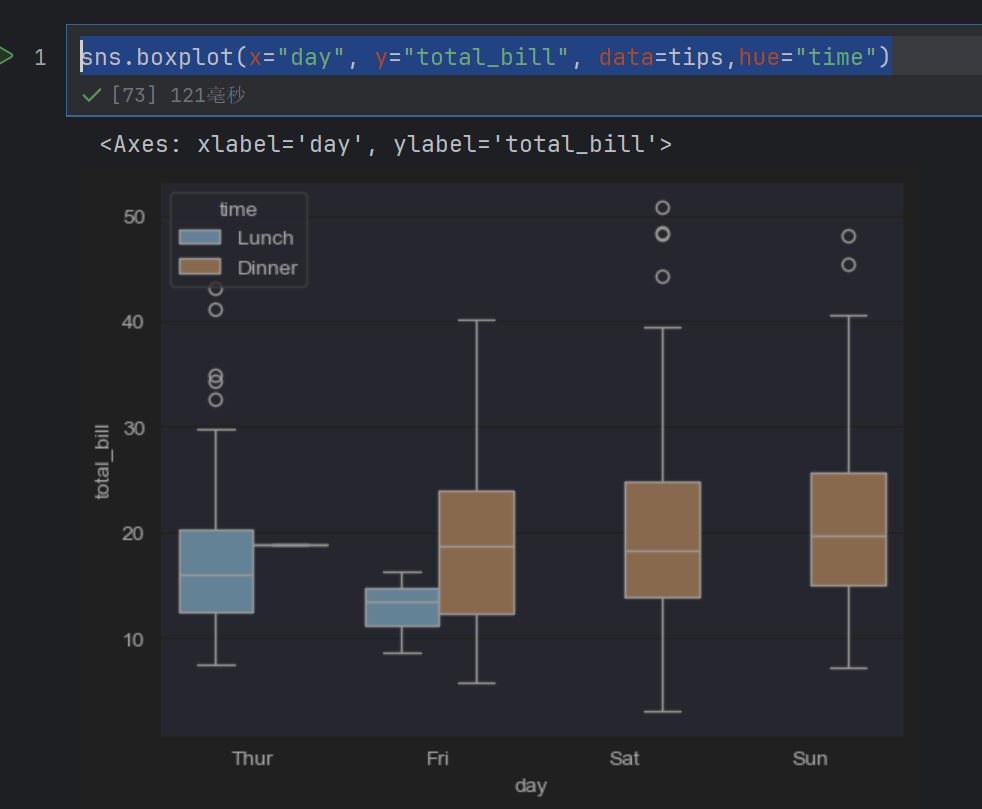
这样就有两块了
sns.boxplot(x="day", y="total_bill", data=tips,hue="time",palette=["g","b"])
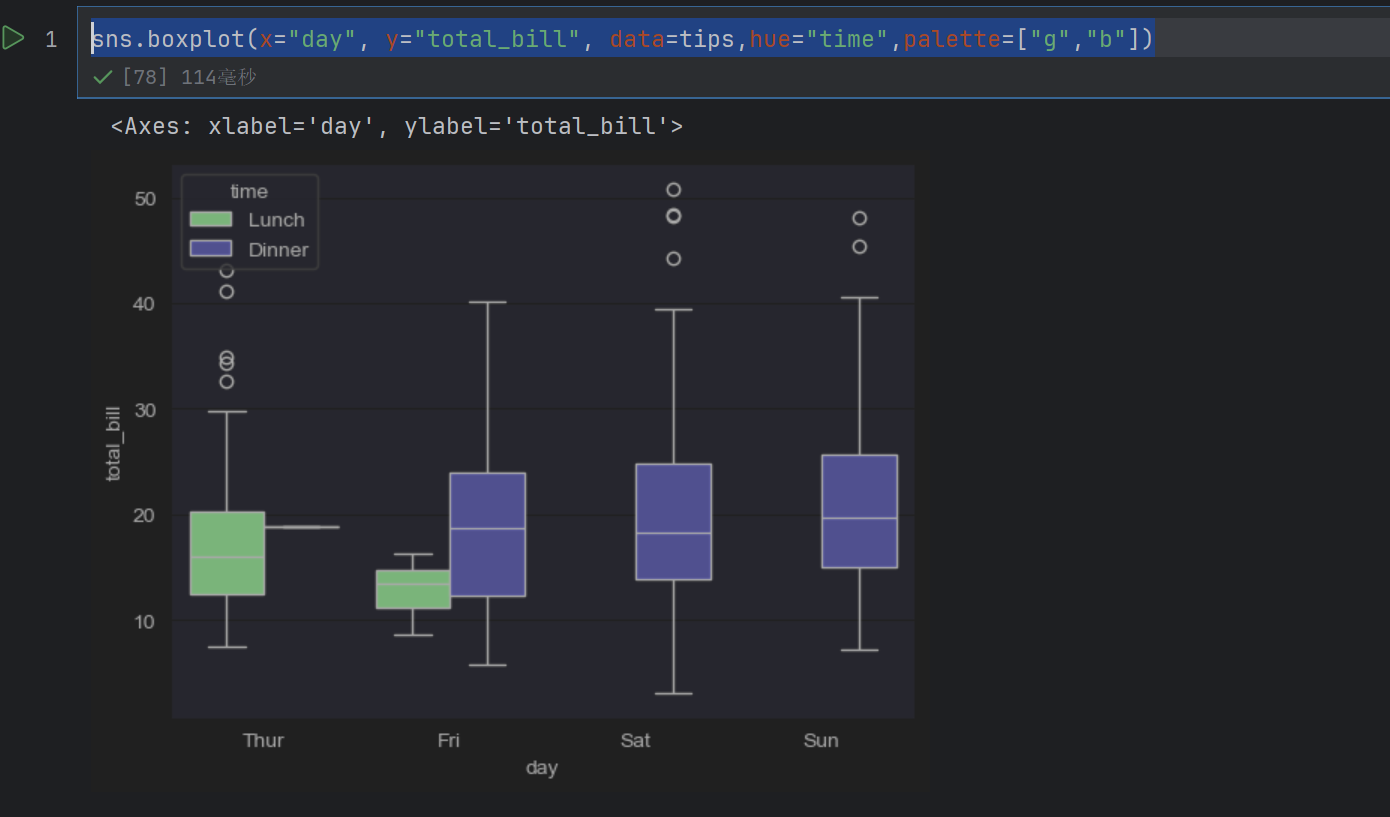
这个颜色是给hue的颜色
sns.boxplot(x="day", y="total_bill", data=tips,hue="time",palette=["g","b"],saturation=0.1)
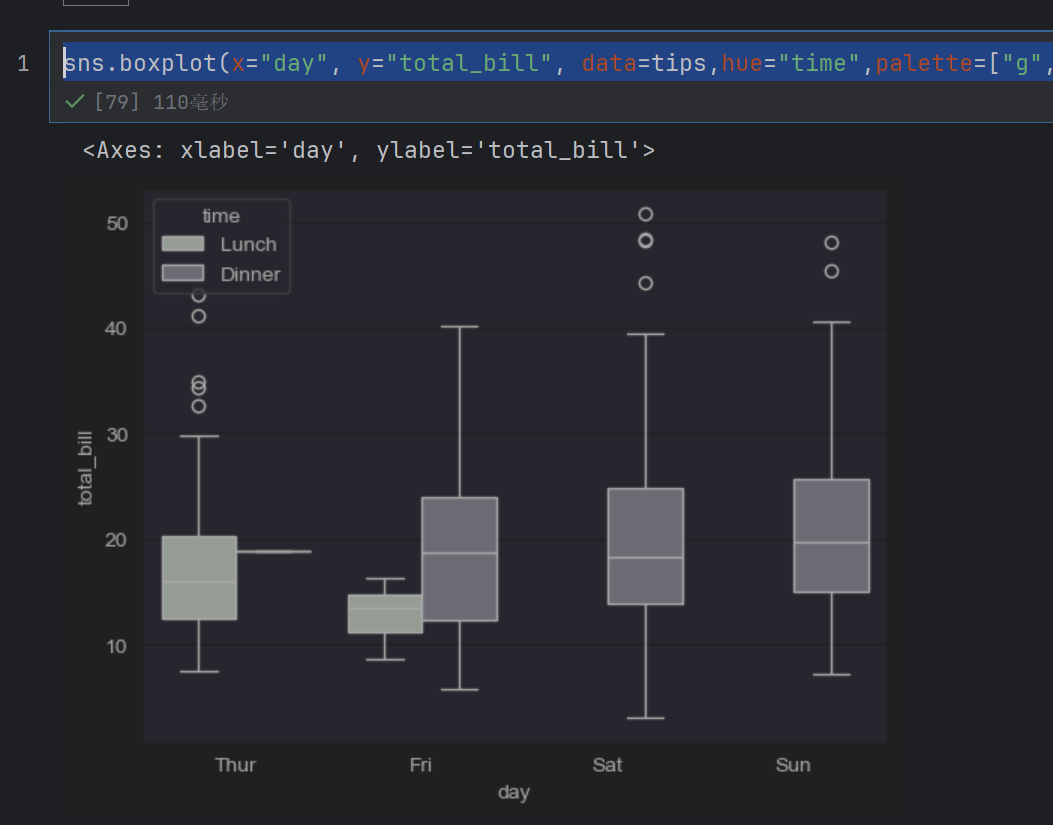
saturation是饱和度
2.4 绘制提琴图
seaborn中用于绘制提琴图的函数为violinplot(),其语法格式如下
seaborn.violinplot(x=None, y=None, hue=None, data=None)
sns.violinplot(x="day", y="total_bill", data=tips)
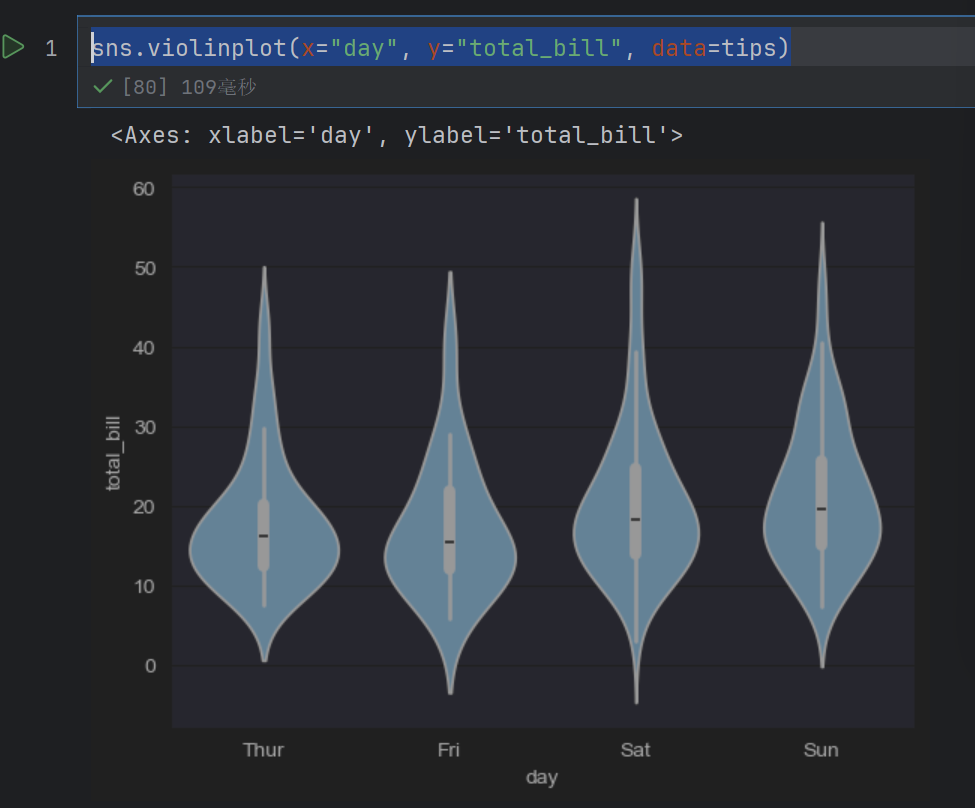
2.5 类别内的统计估计
要想查看每个分类的集中趋势,则可以使用条形图和点图进行展示。 Seaborn库中用于绘制这两种图表的具体函数如下
barplot()函数:绘制条形图。
pointplot()函数:绘制点图
2.6 绘制条形图点图
最常用的查看集中趋势的图形就是条形图。默认情况下, barplot函数会在整个数据集上使用均值进行估计。若每个类别中有多个类别时(使用了hue参数),则条形图可以使用引导来计算估计的置信区间(是指由样本统计量所构造的总体参数的估计区间),并使用误差条来表示置信区间。
sns.barplot(x="day", y="total_bill", data=tips)
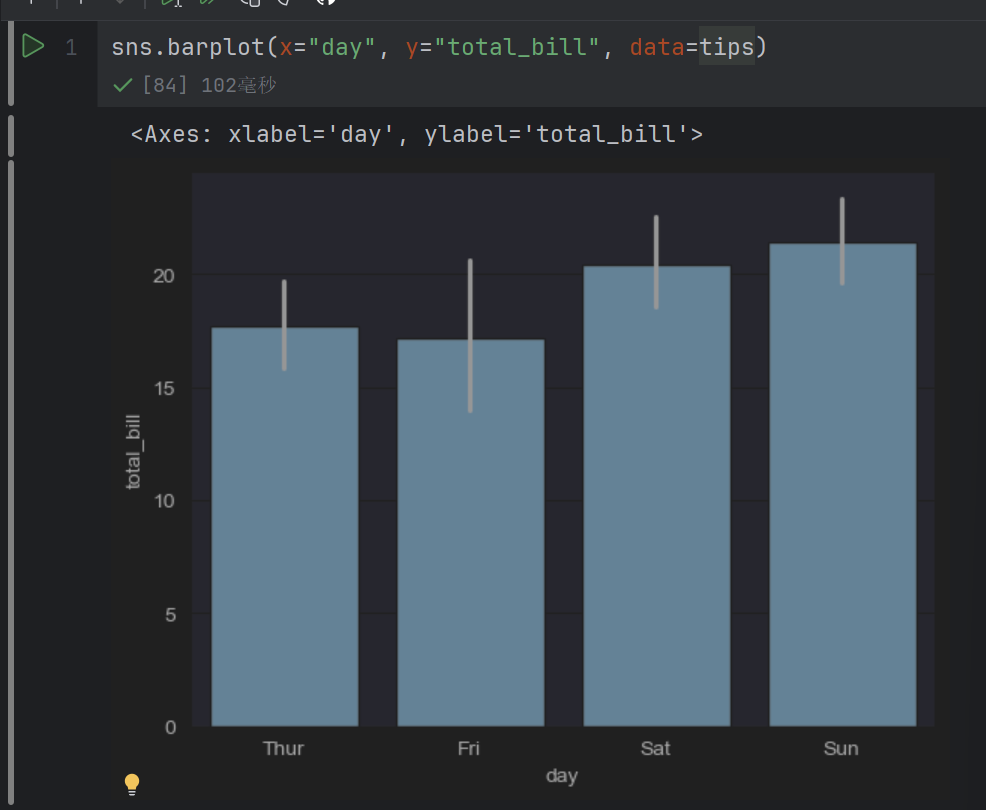
另外一种用于估计的图形是点图,可以调用 pointplot()函数进行绘制,该函数会用高度低计值对数据进行描述,而不是显示完整的条形,它只会绘制点估计和置信区间。
sns.pointplot(x="day", y="total_bill", data=tips)
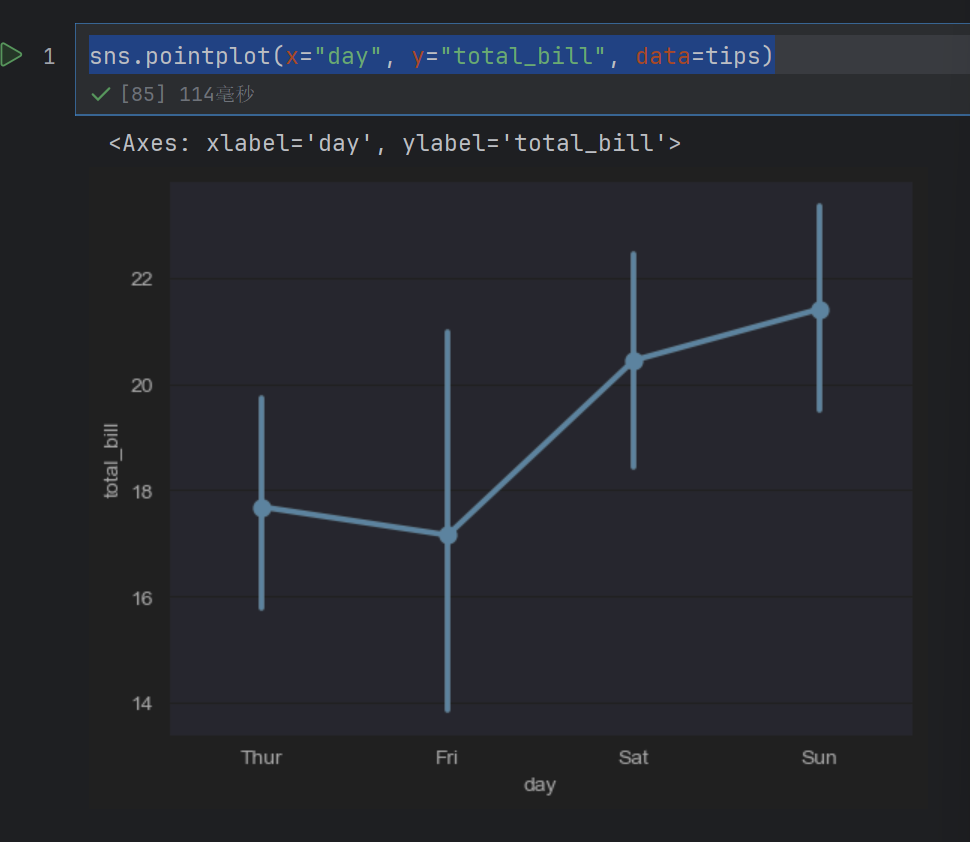
3. 案例:NBA球员数据分析
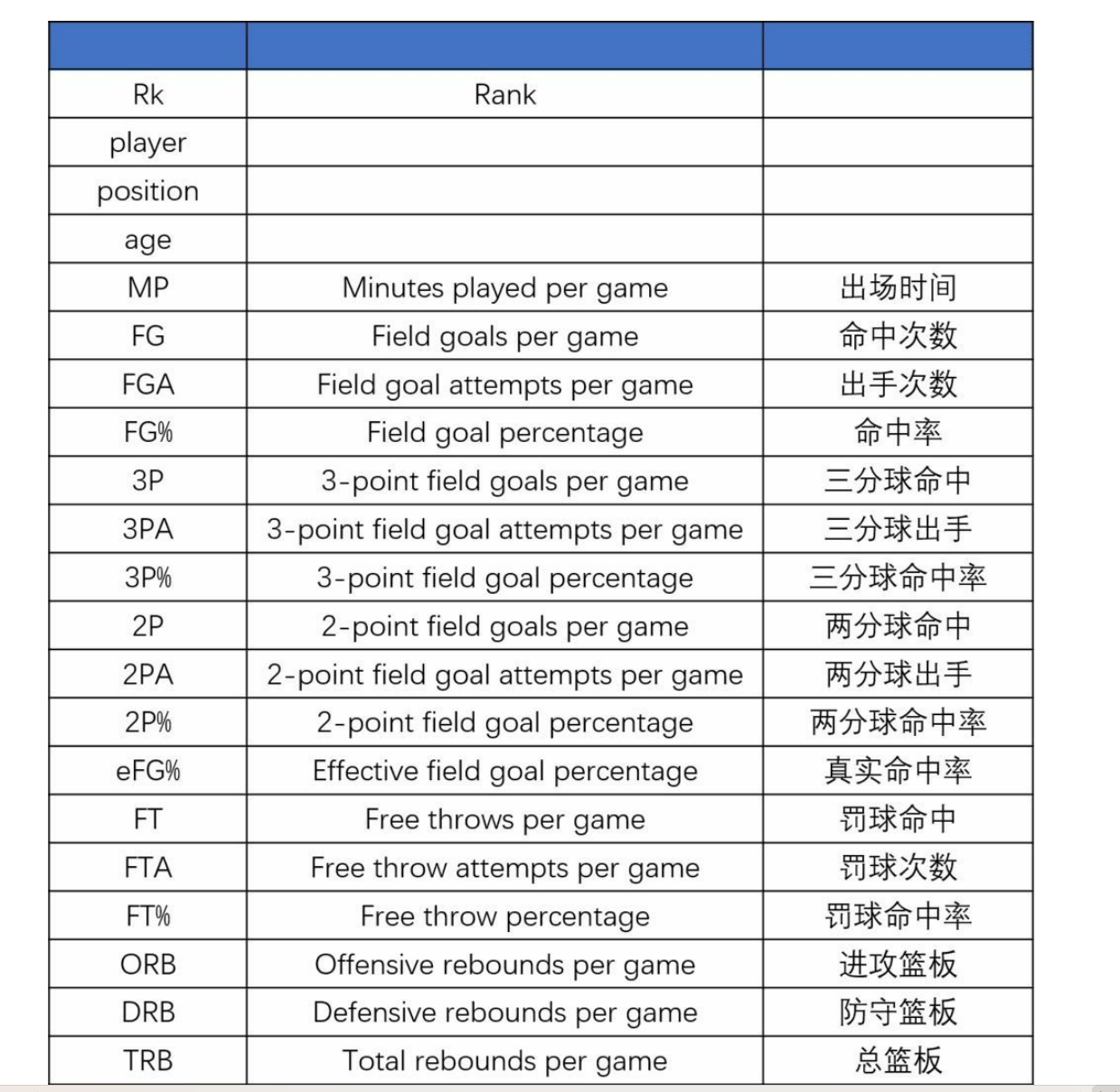
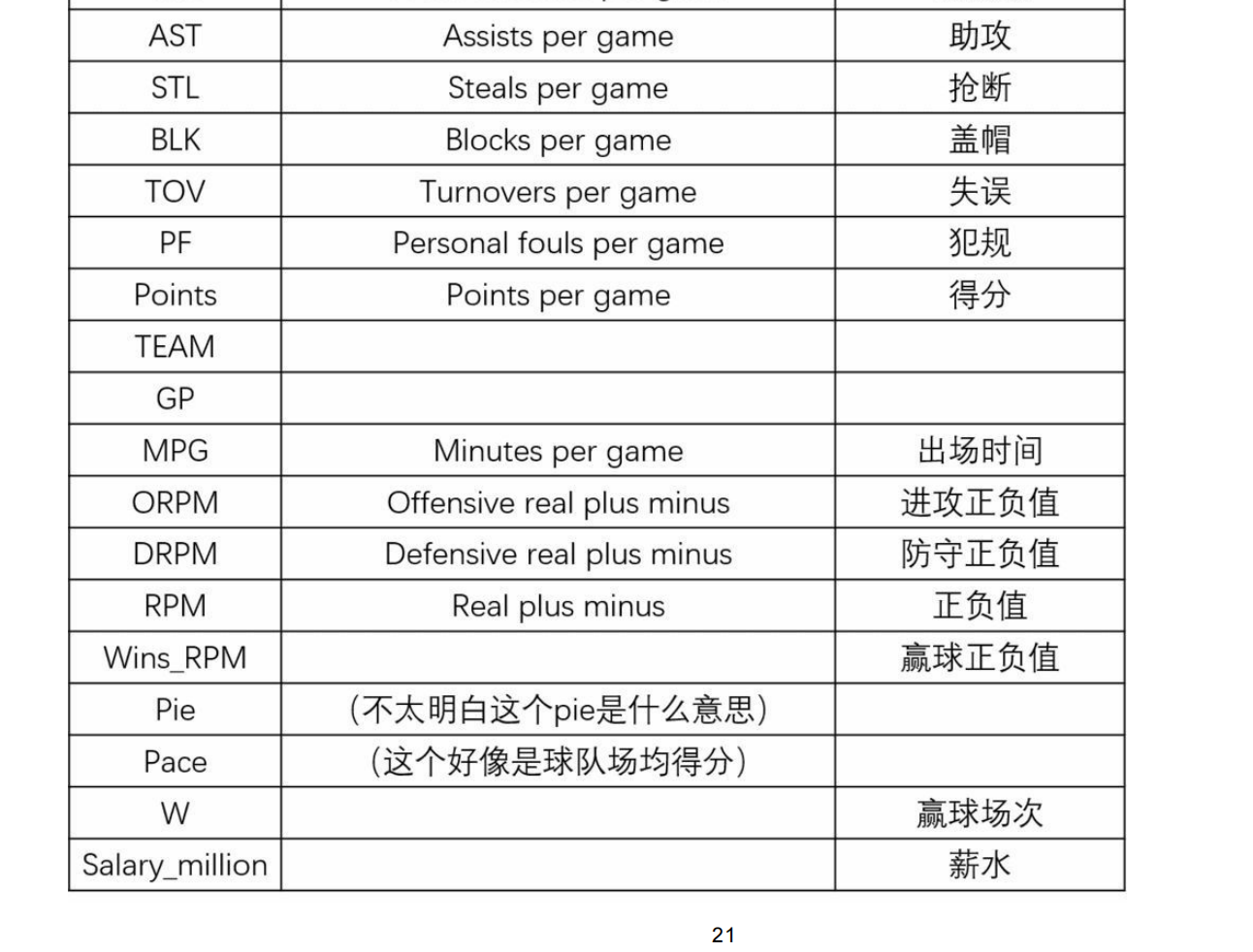
3.1 效率值分析
data = pd.read_csv("./source/nba_2017_nba_players_with_salary.csv")
data
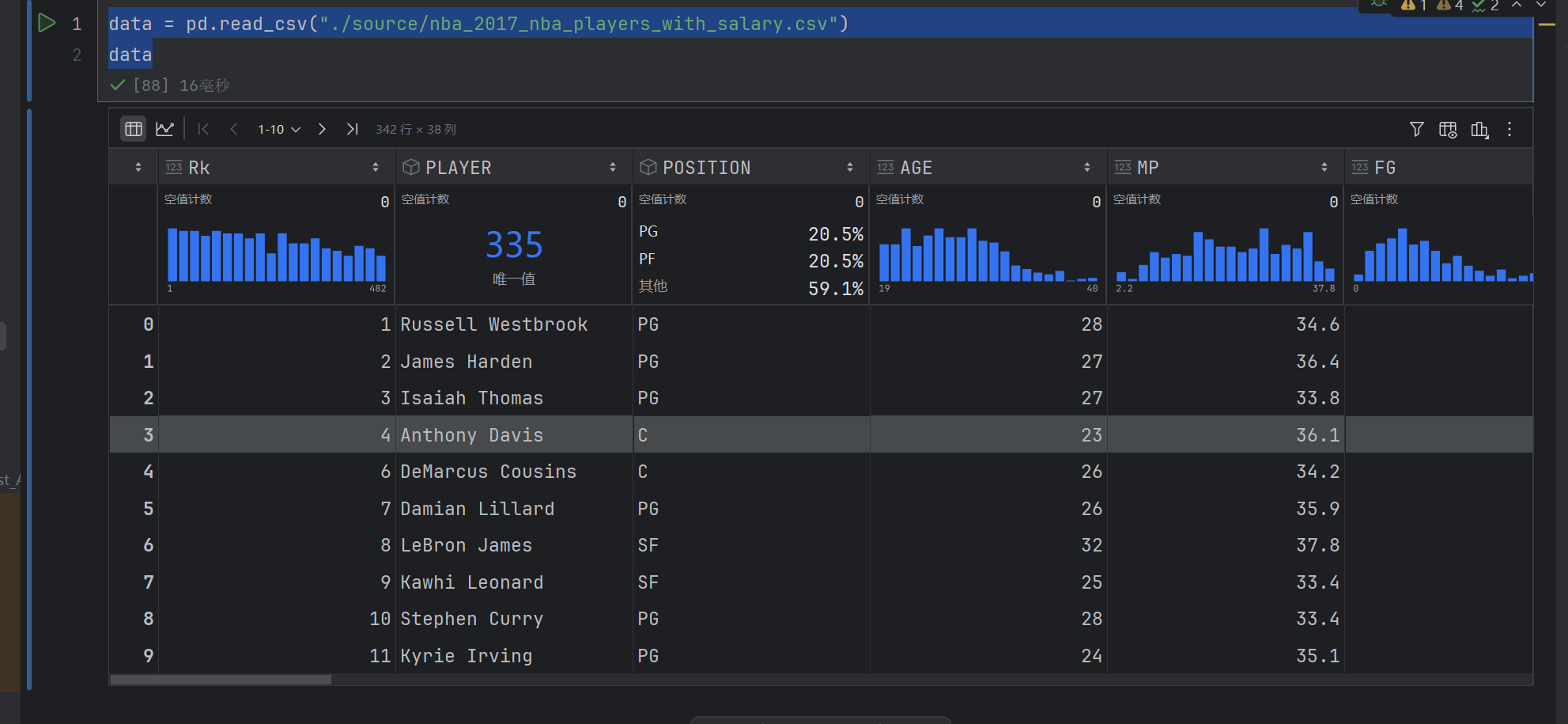
data.shape
data.describe()
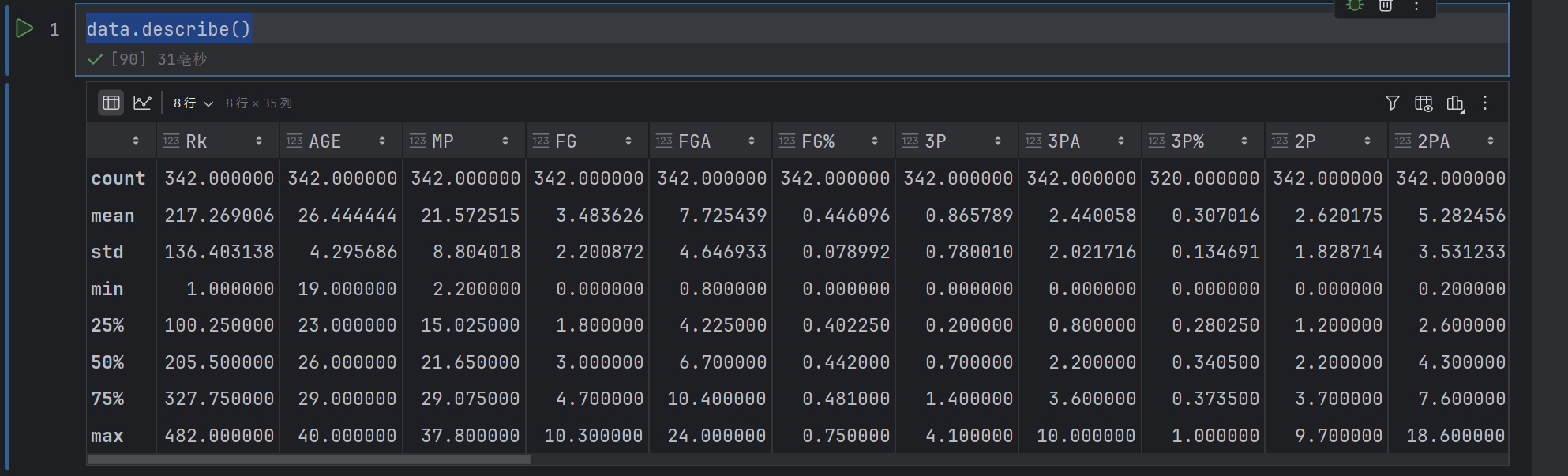
data_cor = data.loc[:, ['RPM', 'AGE', 'SALARY_MILLIONS', 'ORB', 'DRB', 'TRB','AST', 'STL', 'BLK', 'TOV', 'PF', 'POINTS', 'GP', 'MPG', 'ORPM', 'DRPM']]
data_cor
这个是获取指定列
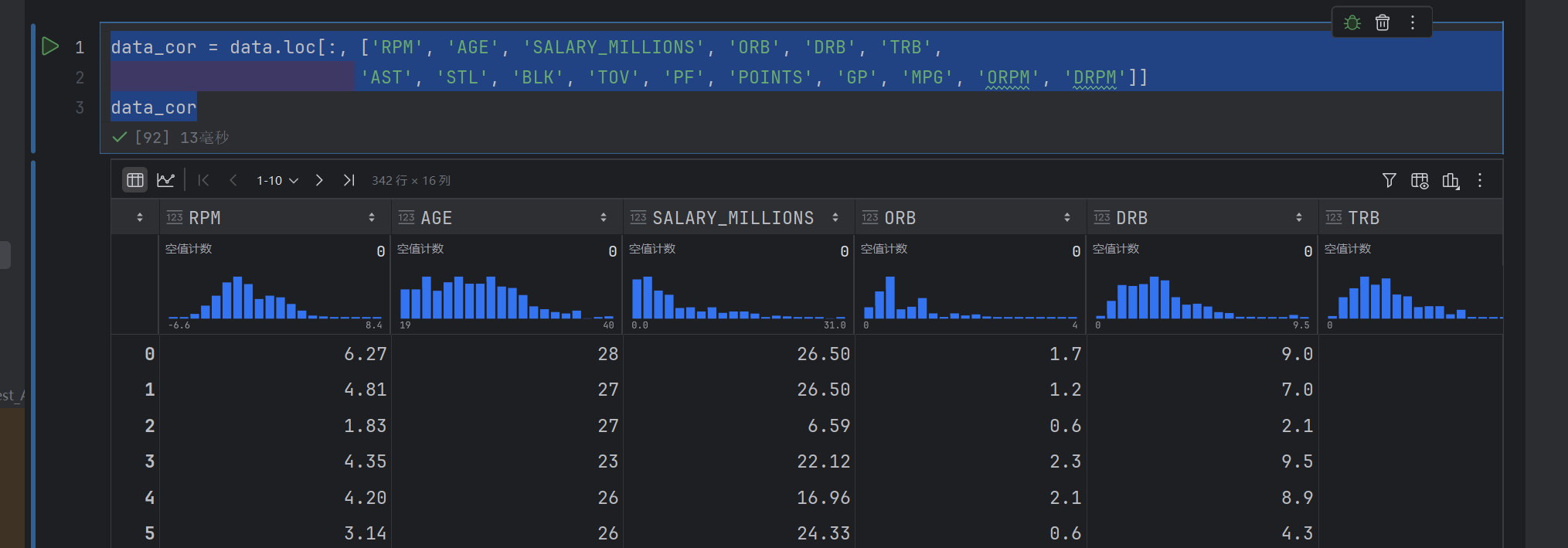
corr = data_cor.corr()
corr
这个是获取列之间的相关性
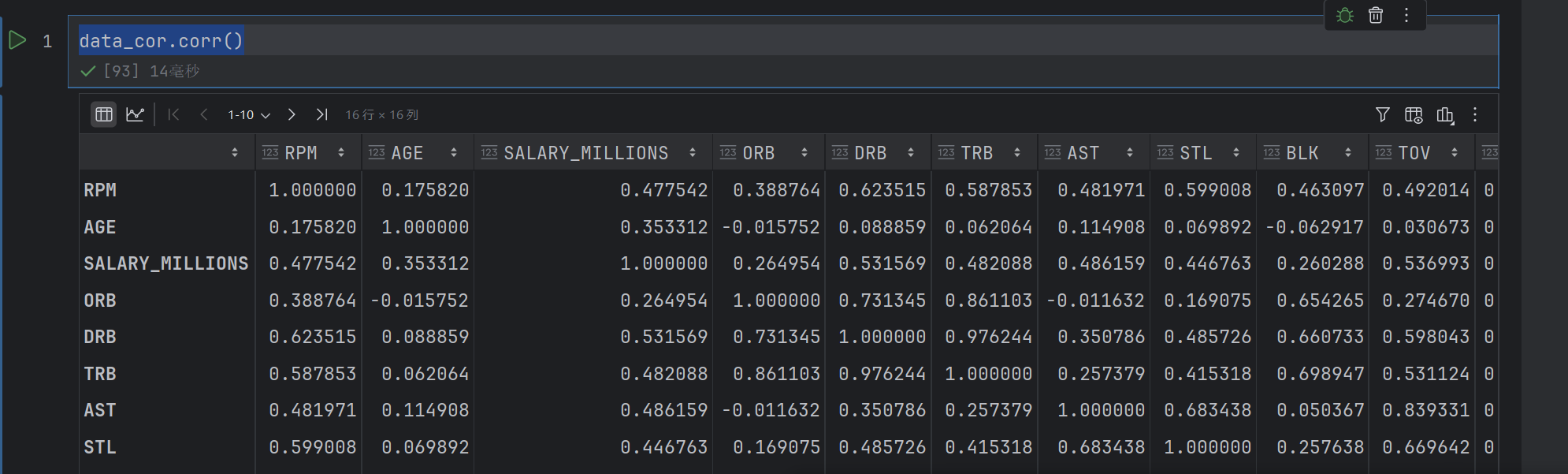
sns.heatmap(corr)
这个是绘制相关性的图
sns.heatmap(corr,square=True)
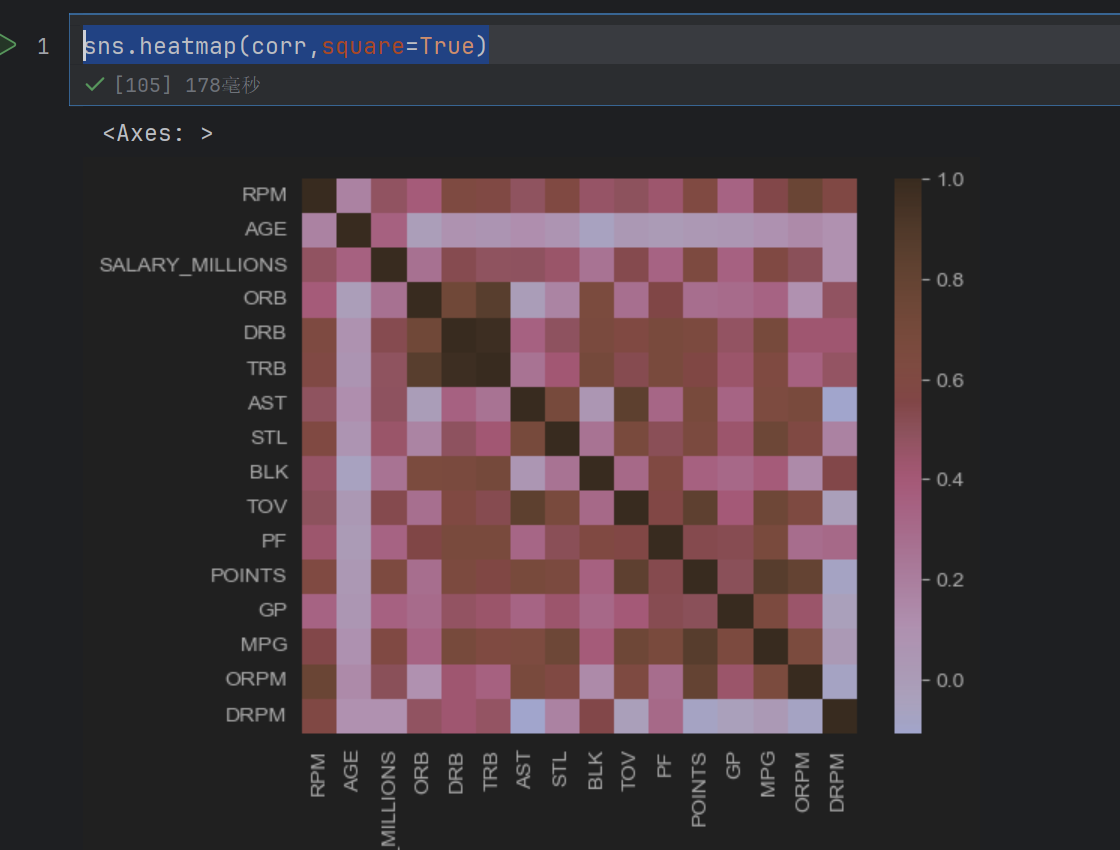
这个是变成一个正方形了
sns.heatmap(corr,square=True,linewidths=0.1)
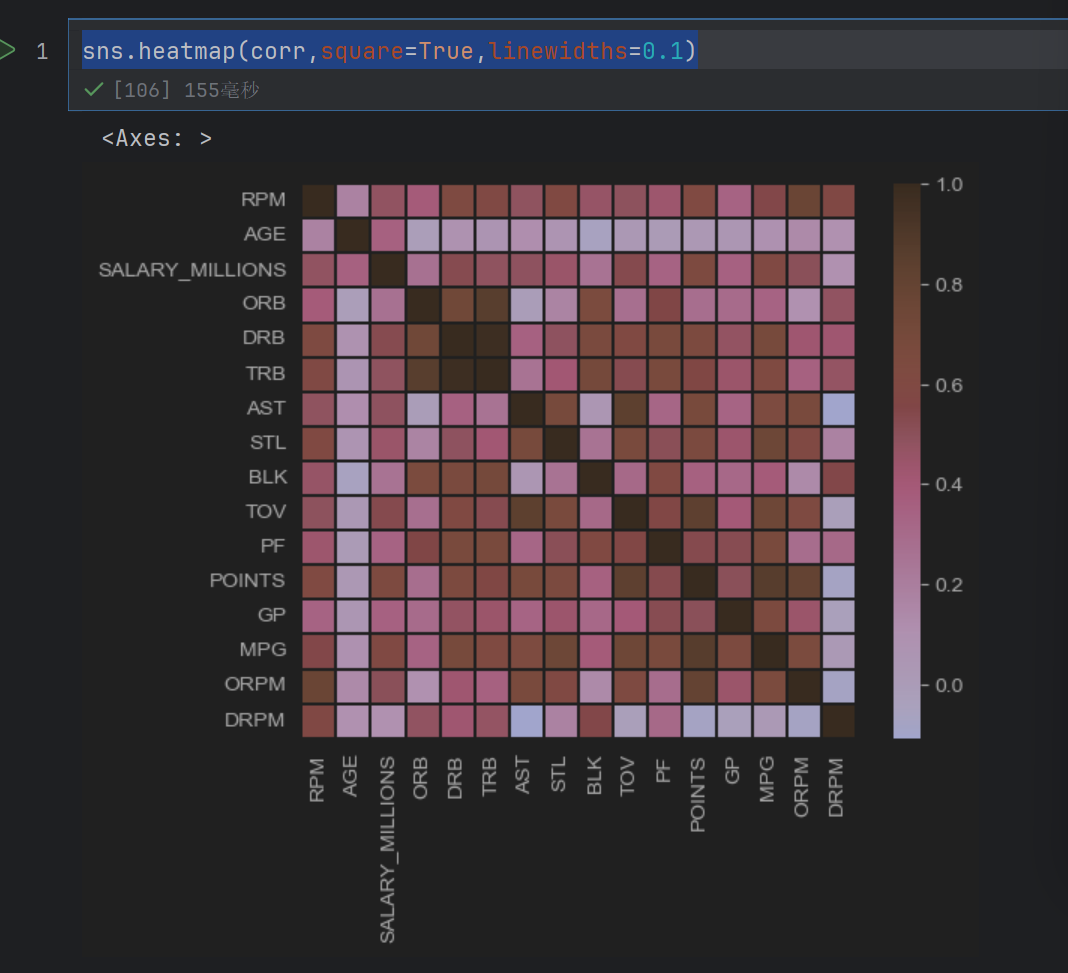
这个是+一个0.1mm的线
sns.heatmap(corr, square=True, linewidths=0.1,annot=True)
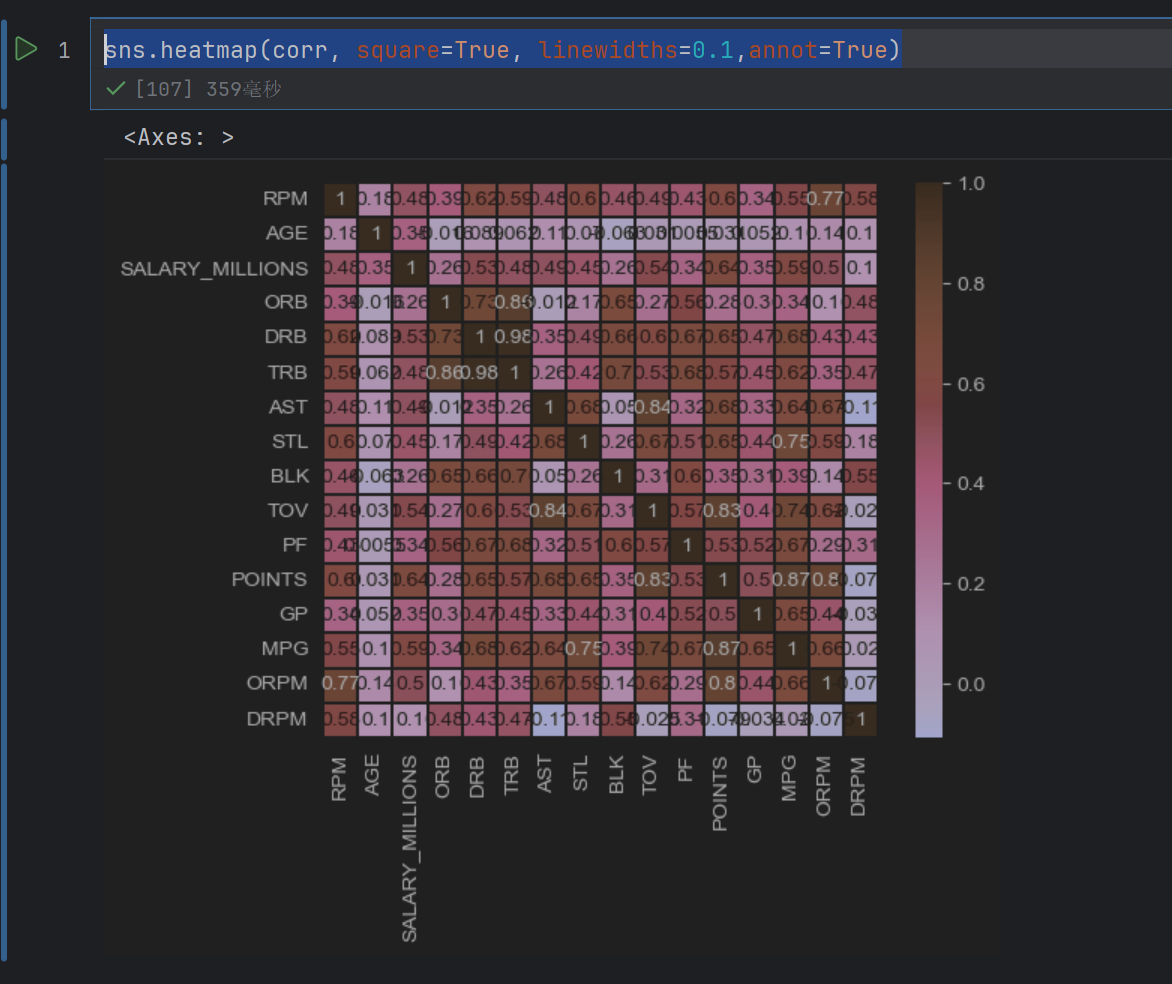
这个是在图上显示具体的值
plt.figure(figsize=(20,8))
sns.heatmap(corr, square=True, linewidths=0.1,annot=True)
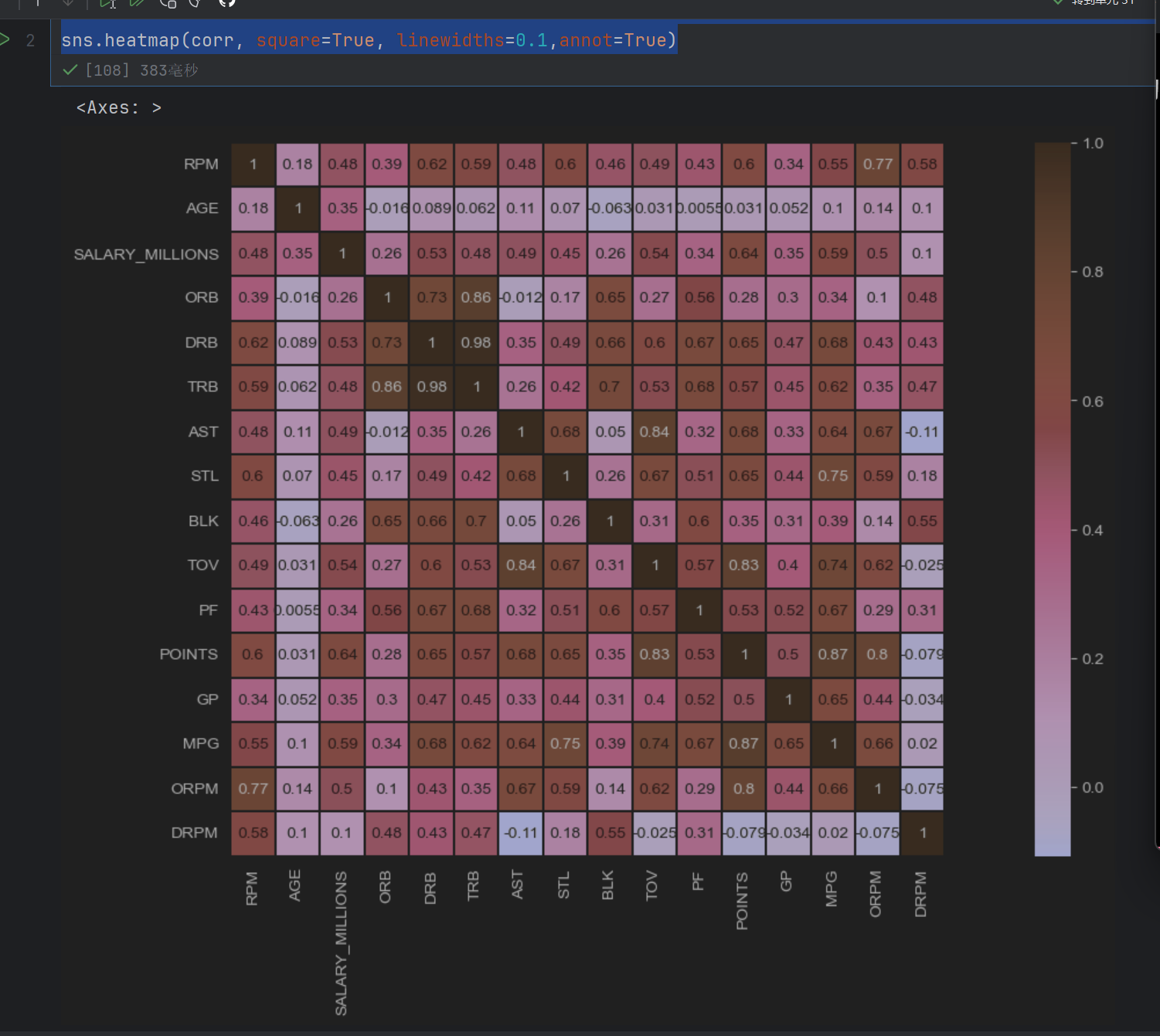
这样就变大了
3.2 基本分析
data.loc[:,["PLAYER","RPM","AGE"]].sort_values(by="RPM",ascending=False)
这个按照RPM排序,降序排序
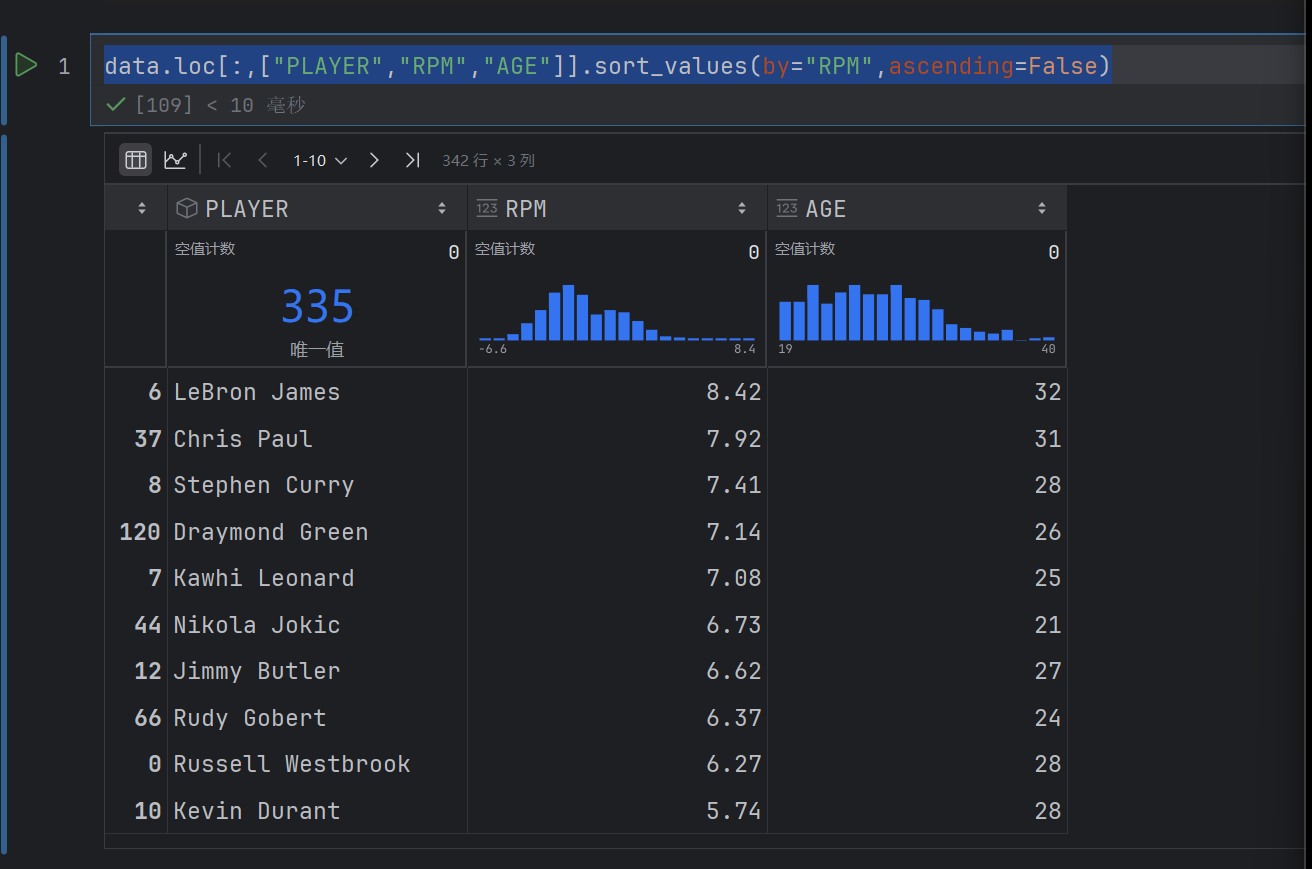

这样写是不行的
3.3 seaborn单变量
sns.set_style("darkgrid")
plt.figure(figsize=(10,10))
plt.subplot(3,1,1)
第一行代码意思是设置背景为暗灰色
plt.subplot(3,1,1)意思是要画三行一列,三幅图,现在画的是第一个图
sns.set_style("darkgrid")#暗灰色
plt.figure(figsize=(10,10))
plt.subplot(3,1,1)
sns.histplot(data["SALARY_MILLIONS"],kde=True)
plt.ylabel("salary")
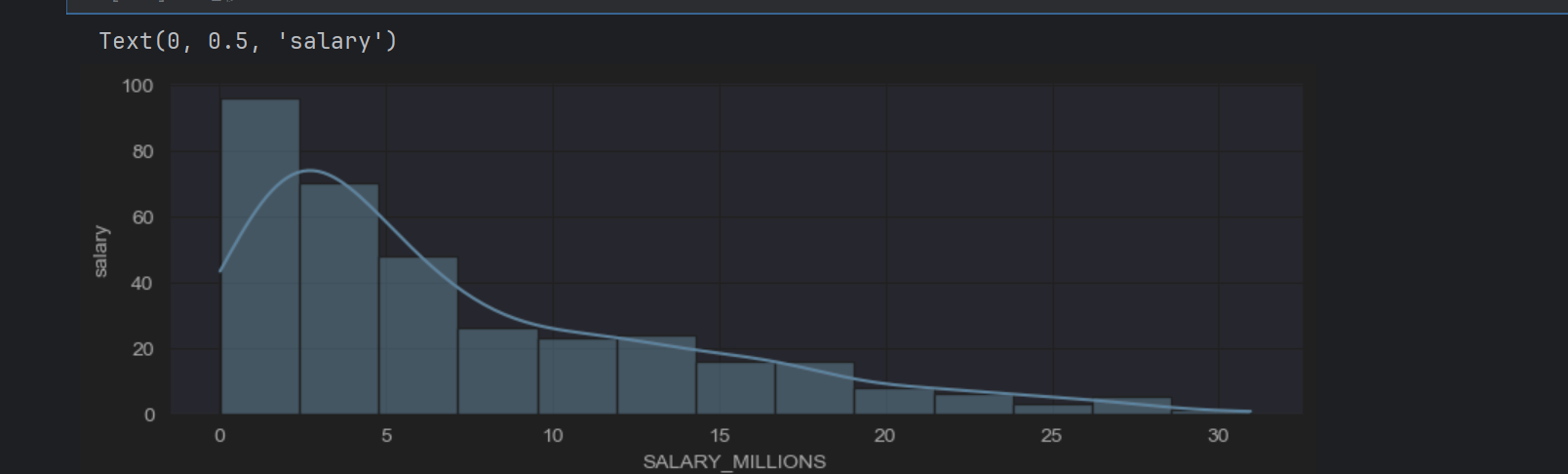
sns.set_style("darkgrid")#暗灰色
plt.figure(figsize=(10,10))
plt.subplot(3,1,1)
sns.histplot(data["SALARY_MILLIONS"],kde=True)
plt.ylabel("salary")plt.subplot(3,1,2)
sns.histplot(data["RPM"],kde=True)
plt.ylabel("RPM")plt.subplot(3,1,3)
sns.histplot(data["AGE"],kde=True)
plt.ylabel("AGE")
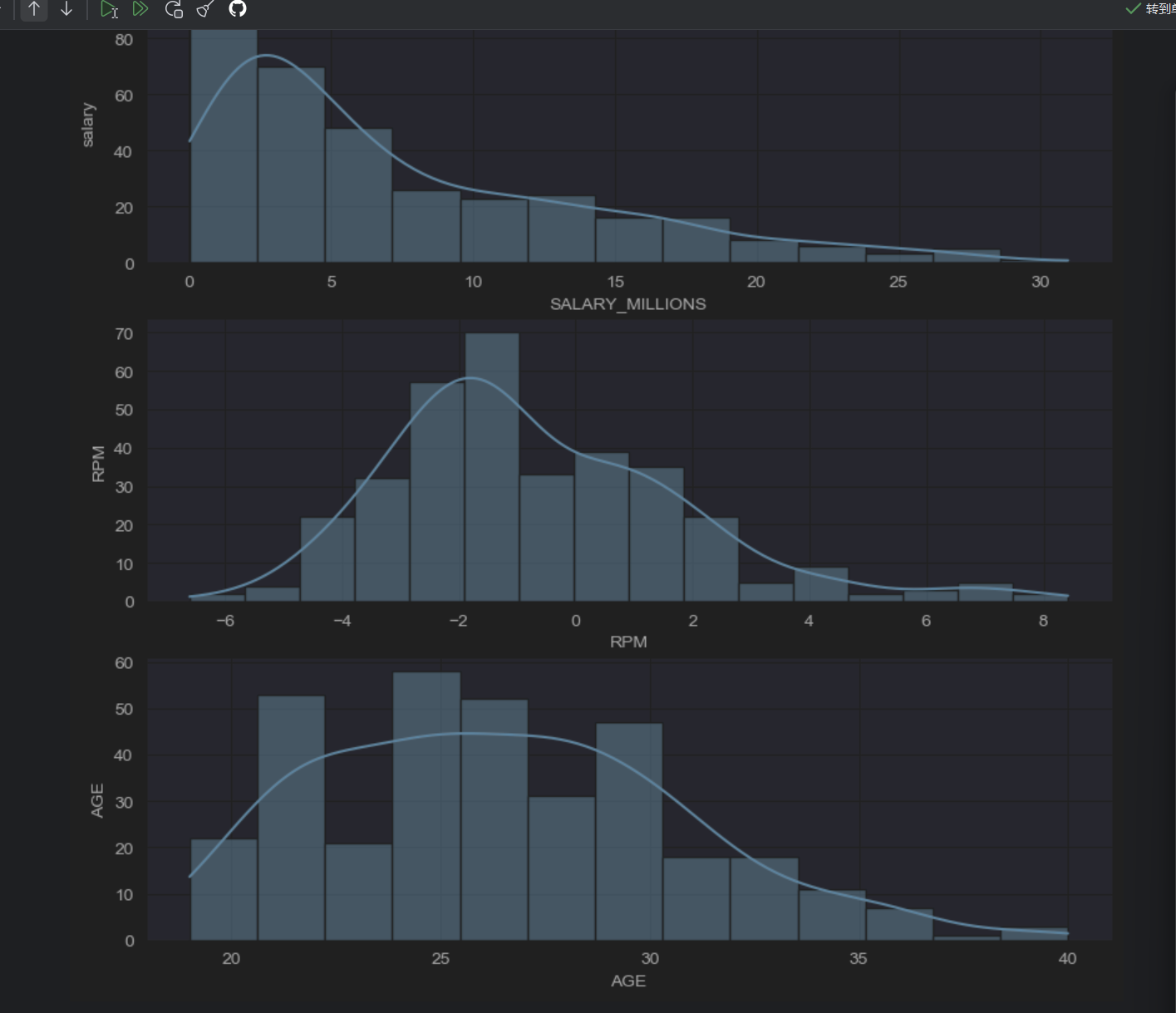
薪资不太符合正态分布
3.3 seaborn双变量
sns.jointplot(x=data.AGE,y=data.SALARY_MILLIONS,kind="hex")
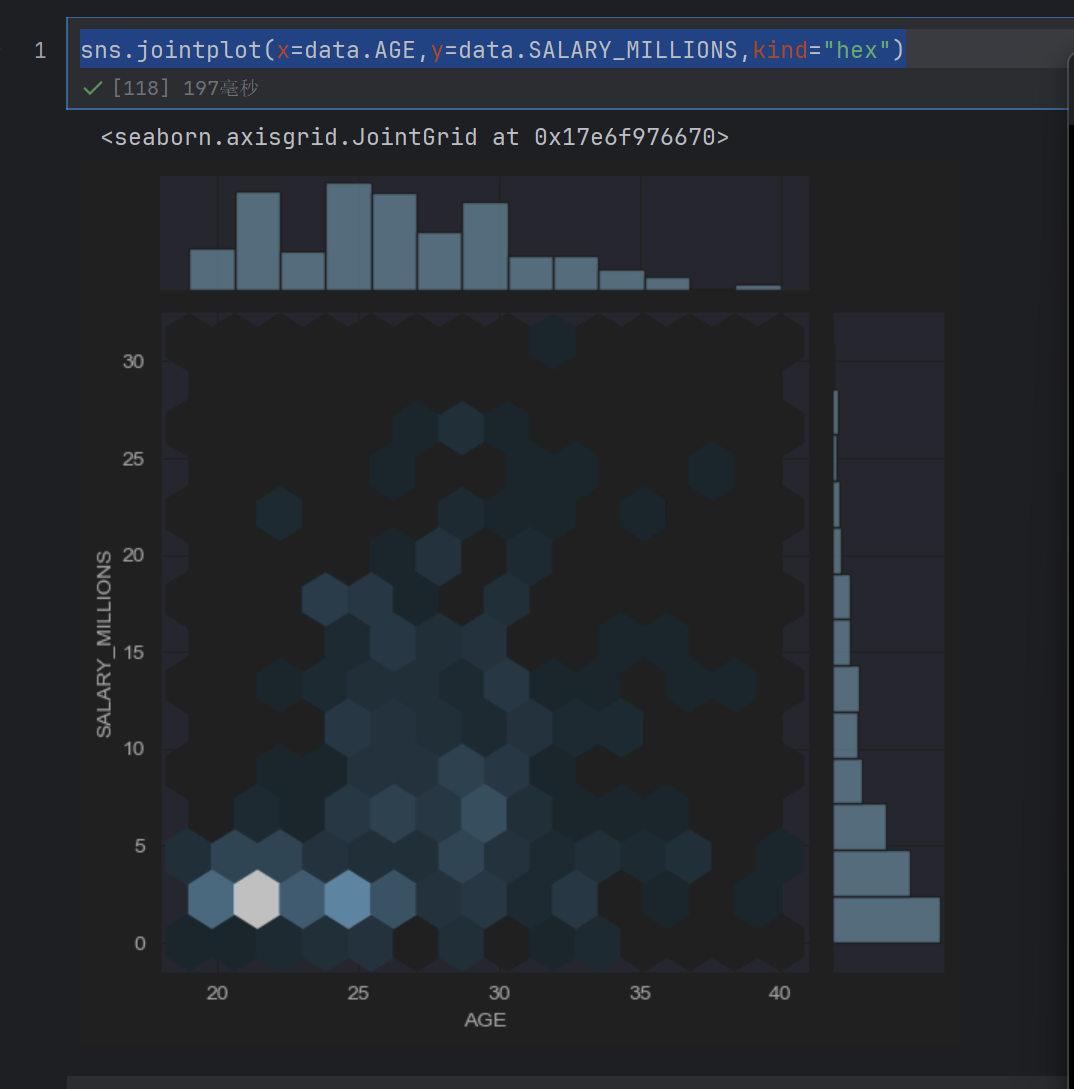
这个是画六边形散点图
发现年龄小的人多,然后薪资也低
但是年龄大,薪资多的人少
3.5 多变量
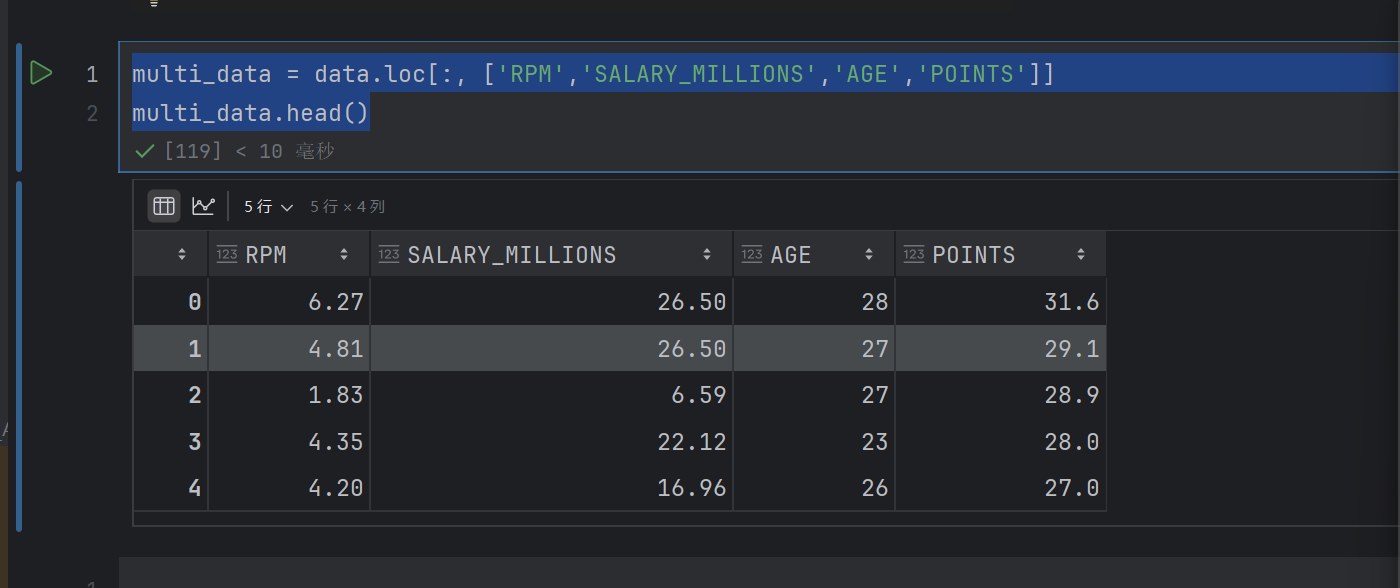
multi_data = data.loc[:, ['RPM','SALARY_MILLIONS','AGE','POINTS']]
multi_data.head()
sns.pairplot(data=multi_data)
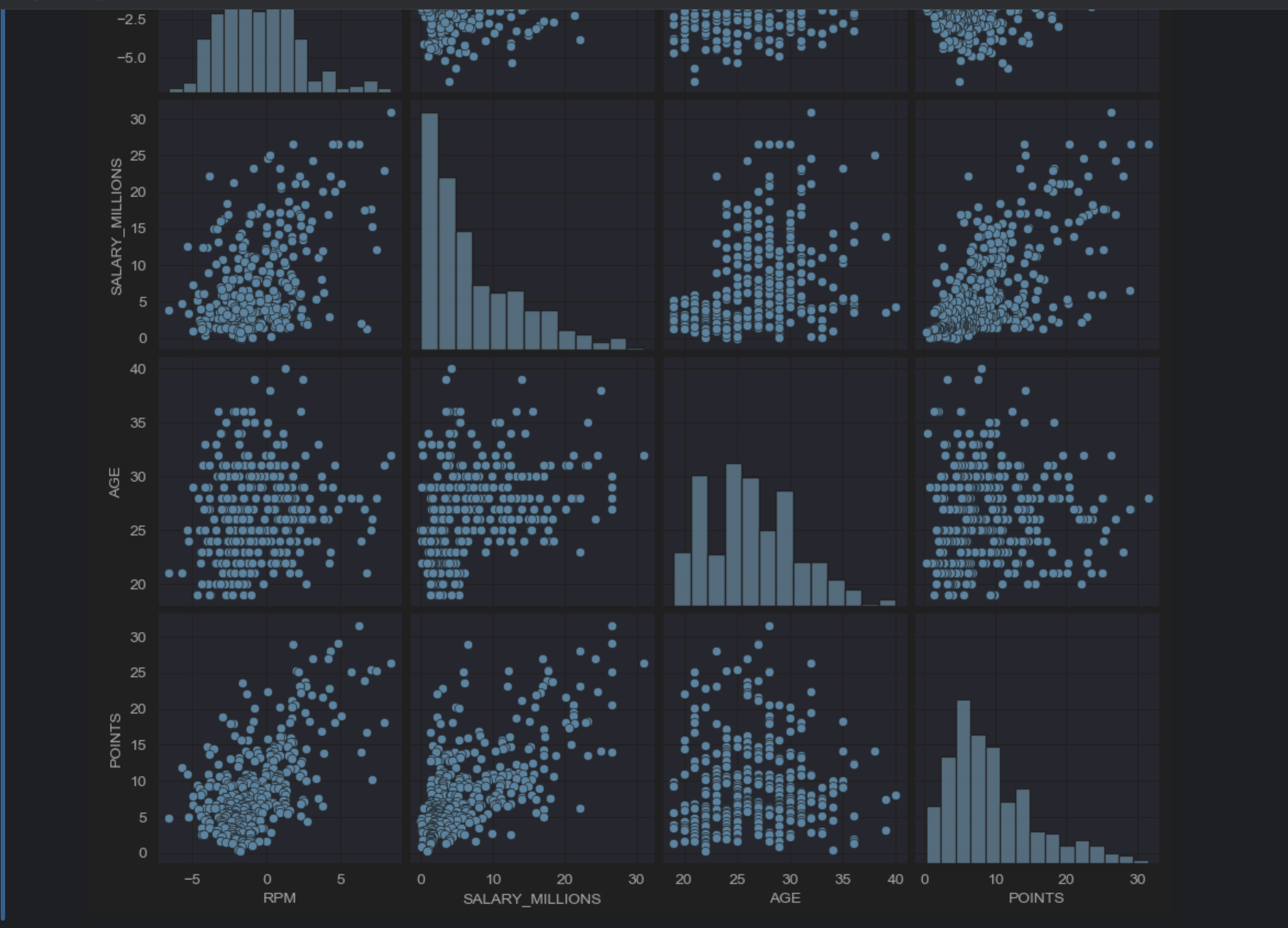
发现RPM和POINTS有点线性关系,RPM与AGE关系不大
3.6 衍生变量
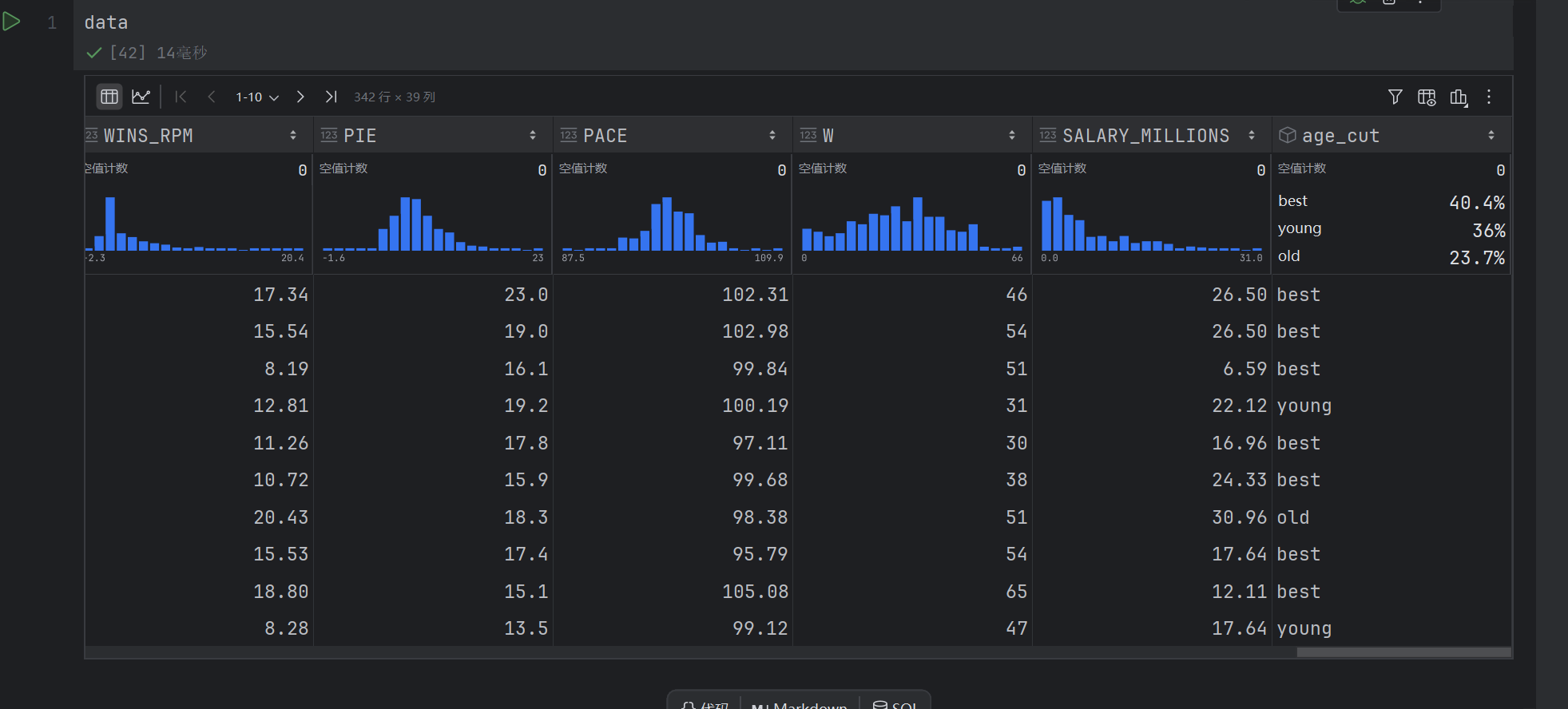
def age_cut(df):if df.AGE <= 24:return "young"elif df.AGE >= 30:return "old"else:return "best"
data["age_cut"] = data.apply(lambda x: age_cut(x), axis=1)
整体作用是:遍历数据框 data 的每一行,根据该行的 AGE 列值,使用 age_cut 函数进行判断,最终为每一行生成一个年龄分组标签(“young”、“best” 或 “old”)。
执行后会得到一个新的 Series(序列),其长度与原数据框的行数相同,每个元素对应原数据中该行的年龄分组结果。你可以将这个结果赋值给原数据框的一个新列
data["cut"]=1
在创建一列方便计数
data.loc[data.age_cut =="best"]
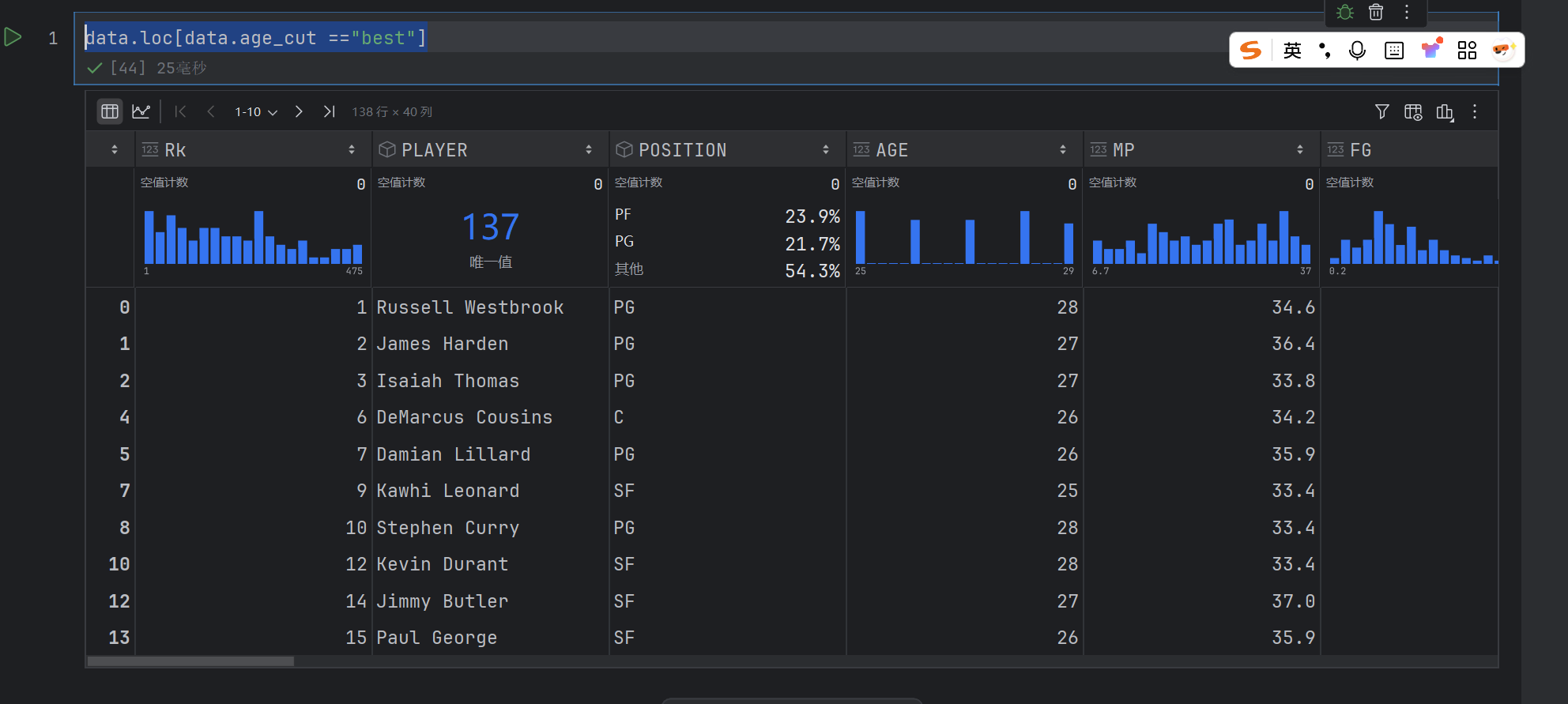
这个是得到所有为best的行
data.loc[data.age_cut =="best"].SALARY_MILLIONS
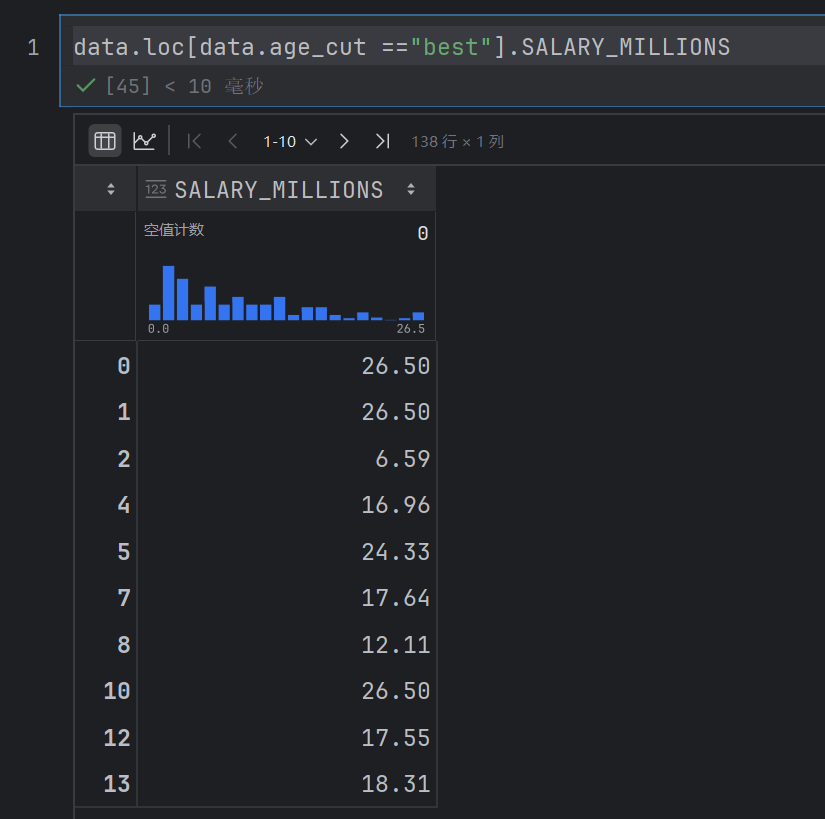
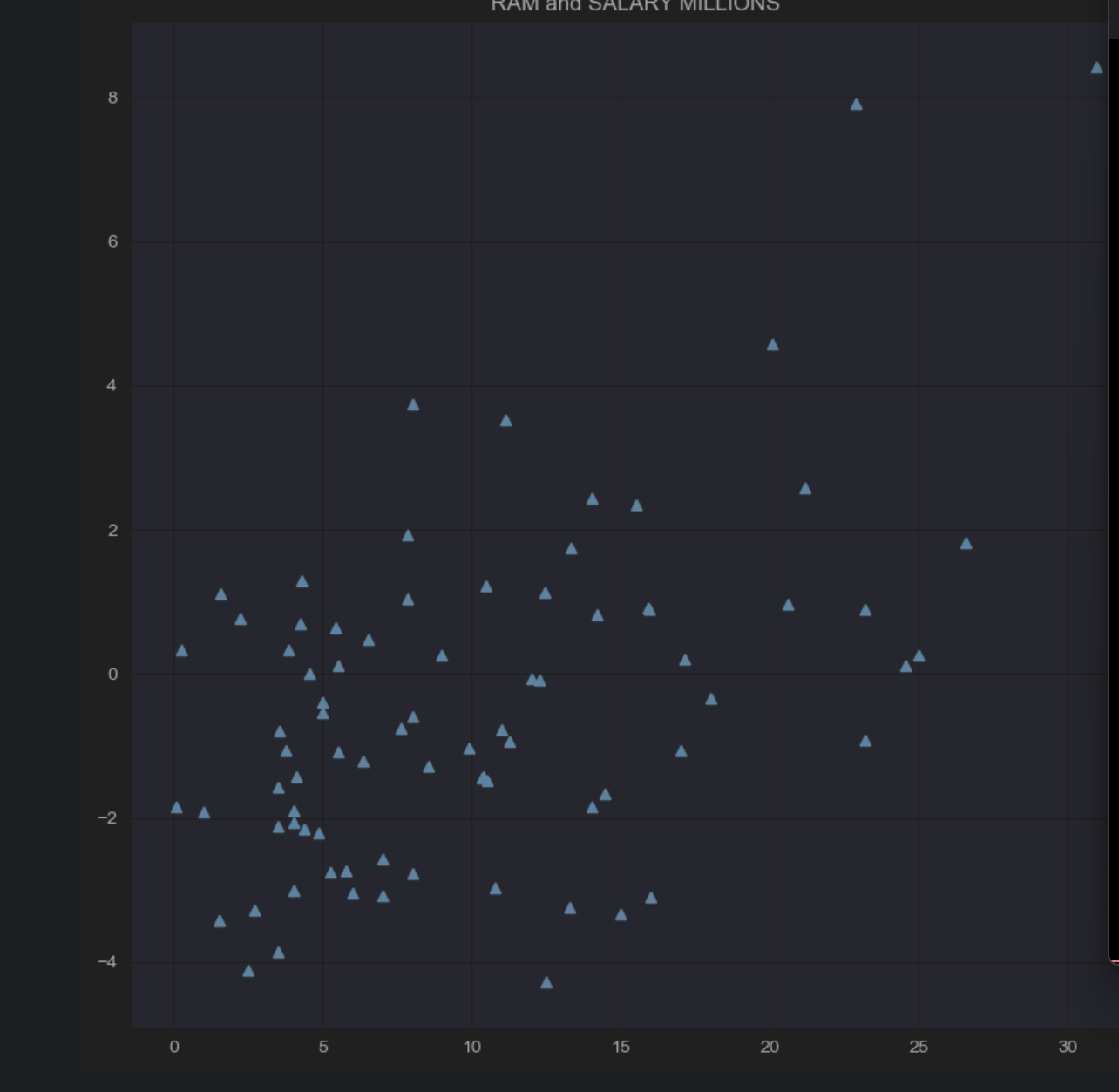
sns.set_style("darkgrid")
plt.figure(figsize=(10,10),dpi=100)
plt.title("RAM and SALARY MILLIONS")
x1 = data.loc[data.age_cut =="old"].SALARY_MILLIONS
y1 = data.loc[data.age_cut =="old"].RPM
plt.plot(x1,y1,"^")
plt.plot(x1,y1,“^”)表示用上三角的形式绘制
sns.set_style("darkgrid")
plt.figure(figsize=(10,10),dpi=100)
plt.title("RAM and SALARY MILLIONS")
x1 = data.loc[data.age_cut =="old"].SALARY_MILLIONS
y1 = data.loc[data.age_cut =="old"].RPM
plt.plot(x1,y1,"^")x2= data.loc[data.age_cut =="best"].SALARY_MILLIONS
y2 = data.loc[data.age_cut =="best"].RPM
plt.plot(x2,y2,"^")x3 = data.loc[data.age_cut =="young"].SALARY_MILLIONS
y3 = data.loc[data.age_cut =="young"].RPM
plt.plot(x3,y3,".")
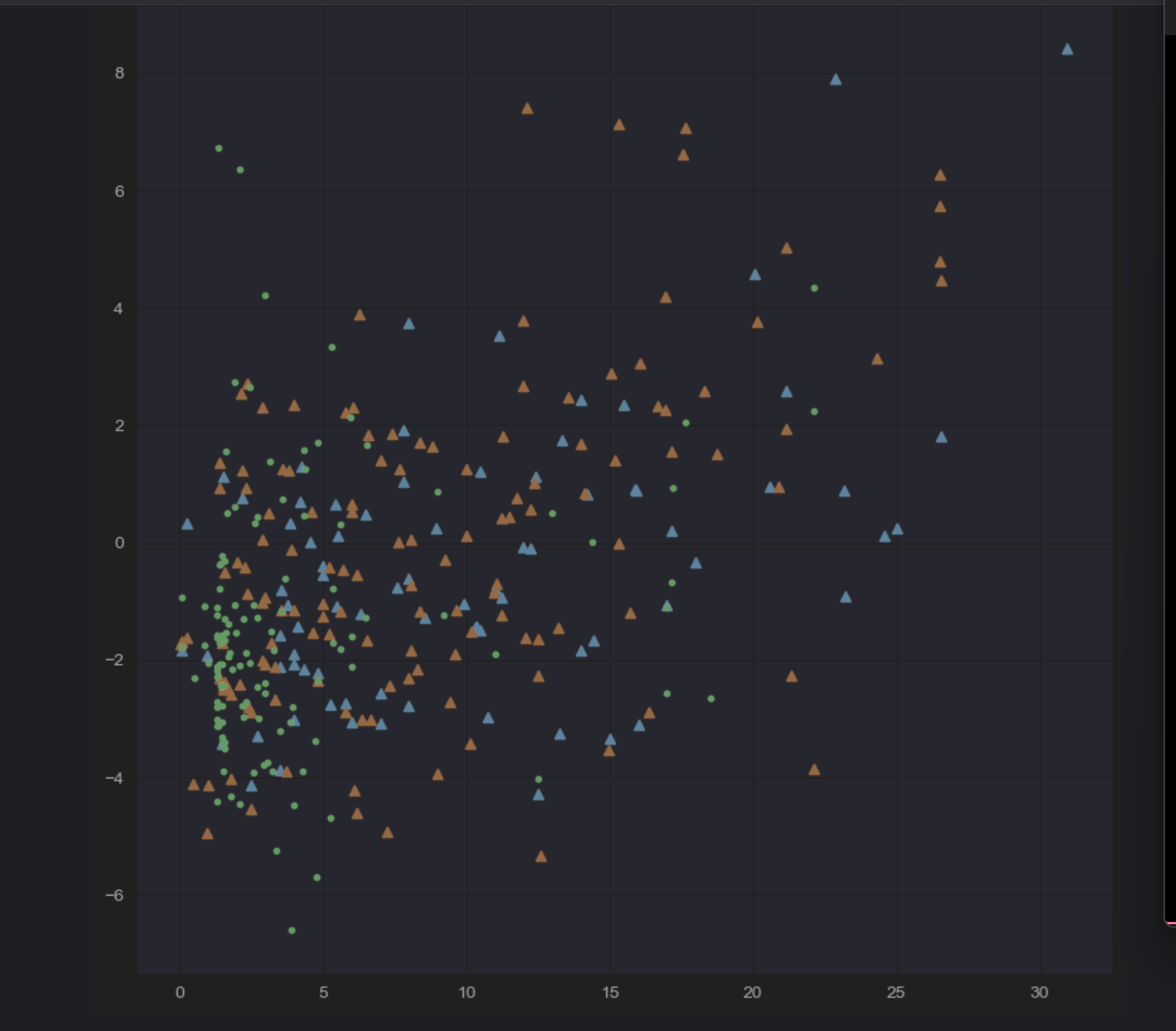
这个就是三种年龄,RPM与薪资的分布图了
multi_data2 = data.loc[:, ['RPM','POINTS','TRB','AST','STL','BLK','age_cut']]sns.pairplot(multi_data2, hue="age_cut")
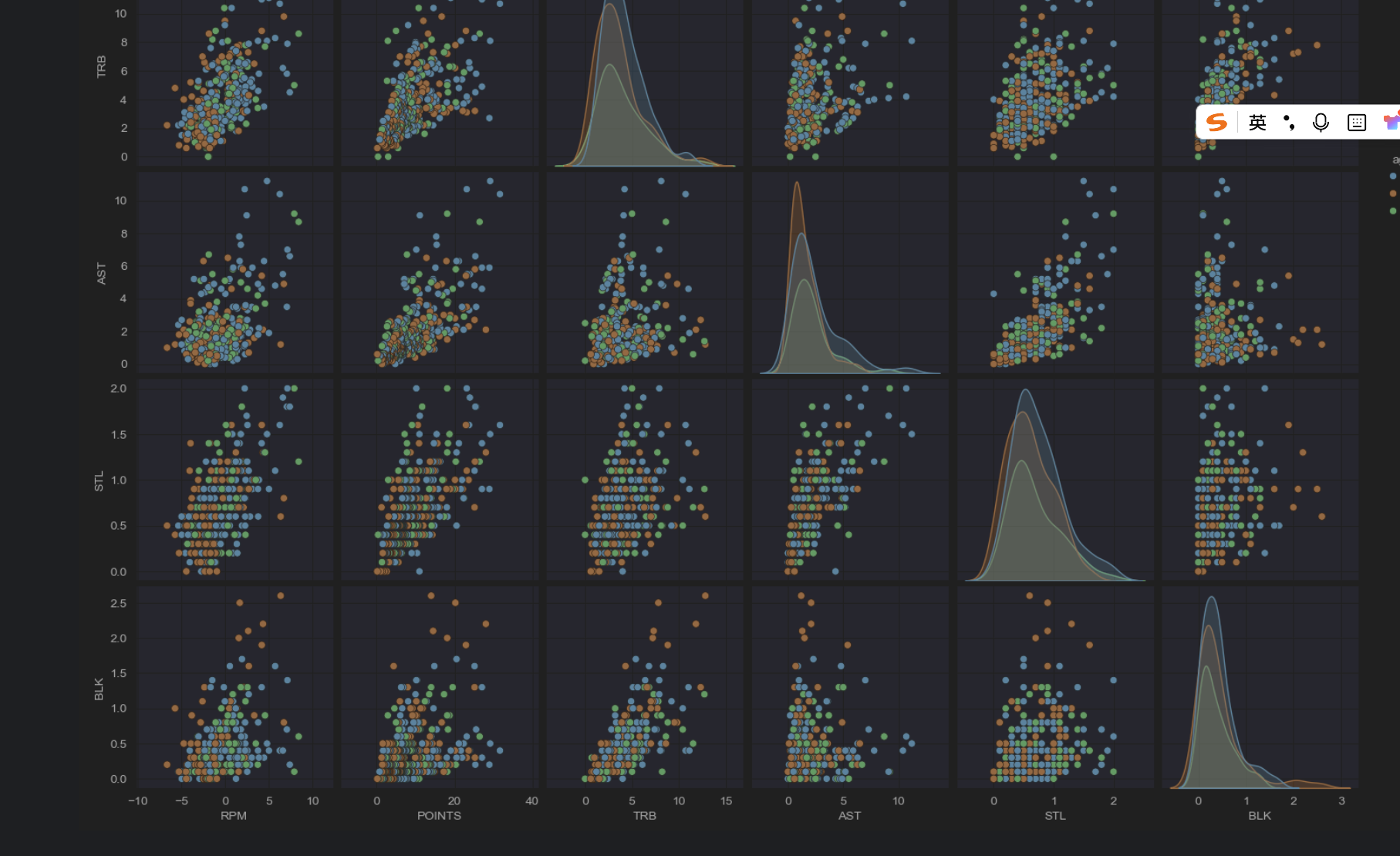
这个就是不同字段之间得到关系,然后以颜色作为目标值
3.7 球队数据分析
data.groupby(by="age_cut").agg({"SALARY_MILLIONS": "mean"})
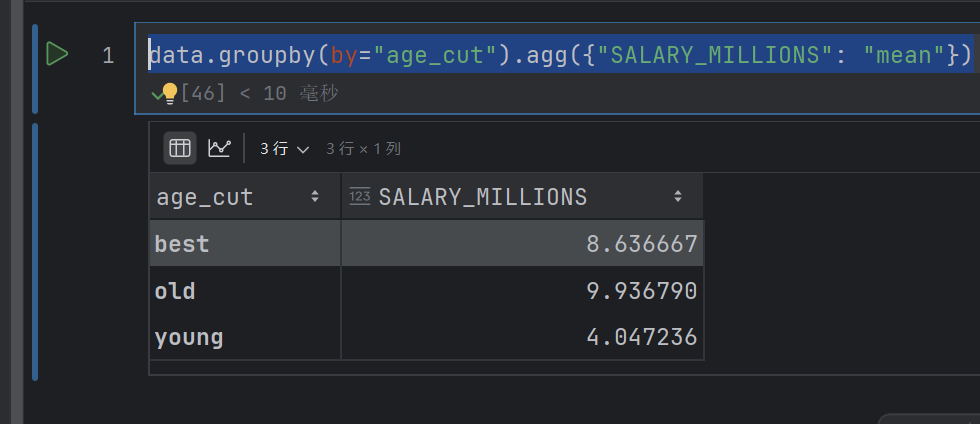
这个代码意思就是先根据age_cut分组,然后求出每个组薪水的平均值
data.groupby(by="age_cut").agg({"SALARY_MILLIONS": "max"})
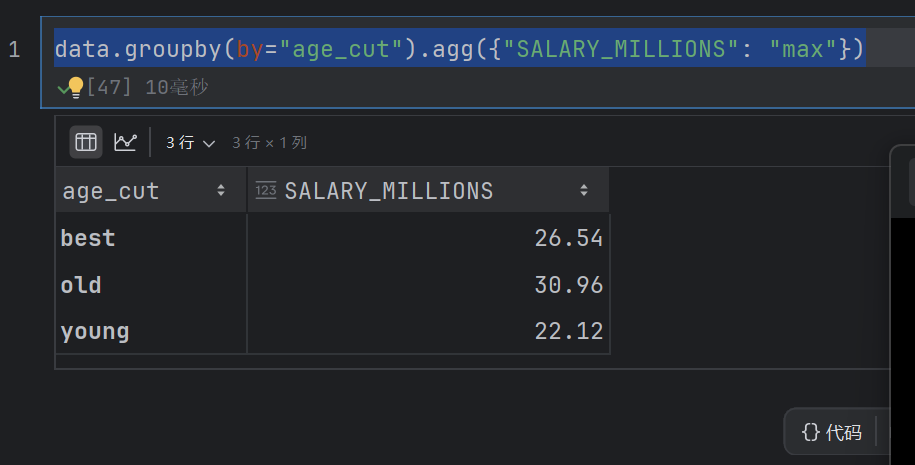
这个是求出最大值
data.groupby(by="TEAM").agg({"SALARY_MILLIONS": "mean"})
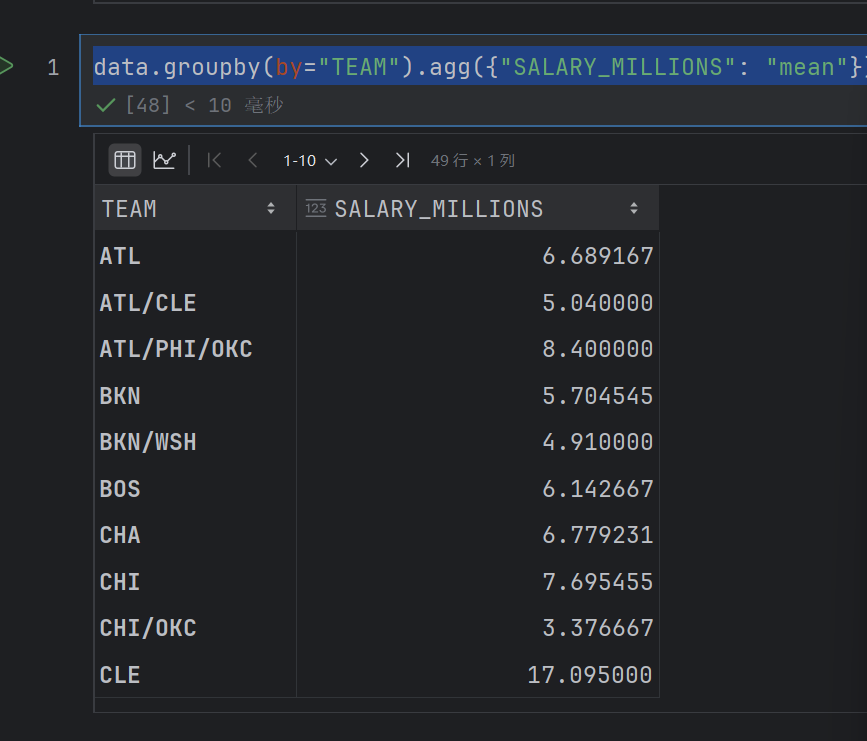
data_team = data.groupby(by="TEAM").agg({"SALARY_MILLIONS": "mean"})
data_team.sort_values(by=["SALARY_MILLIONS"], ascending=False).head(10)
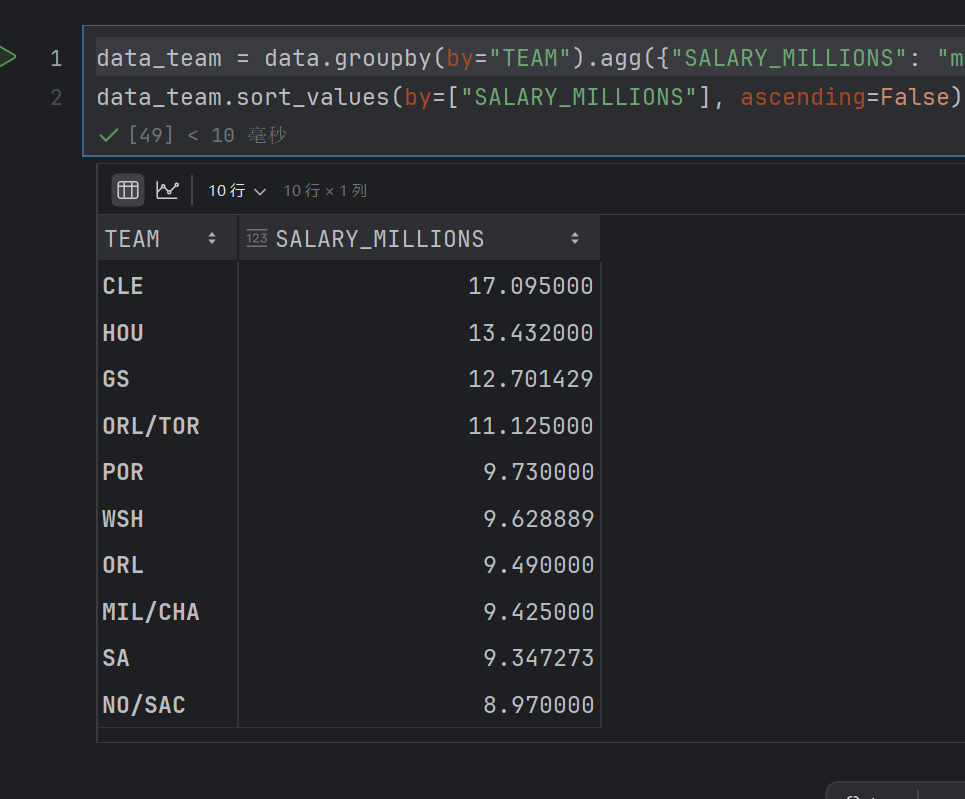
这个就是先求出每个队的平均薪资,然后按照平均薪资进行排序,降序,前十
data_rpm=data.groupby(by=["TEAM","age_cut"]).agg({"SALARY_MILLIONS": "mean","RPM":"mean","PLAYER":"size"})
data_rpm
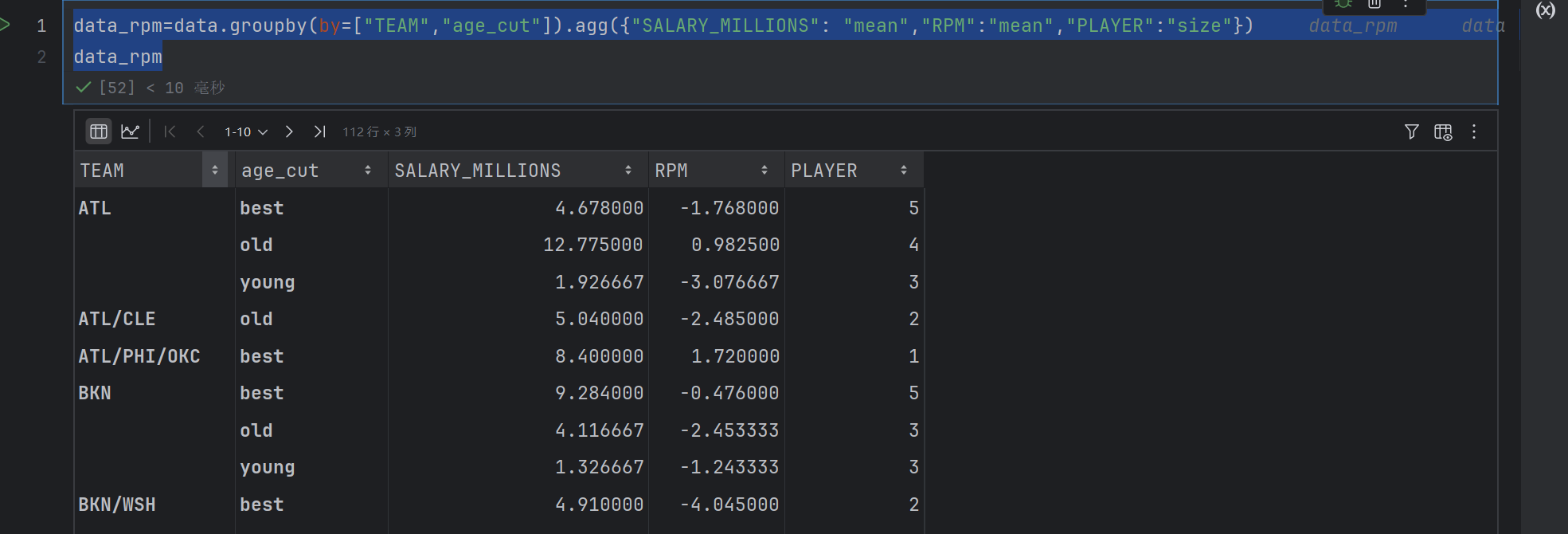
data_rpm.sort_values(by=["PLAYER","RPM"], ascending=False)
按照球员数量排序,然后是RPM
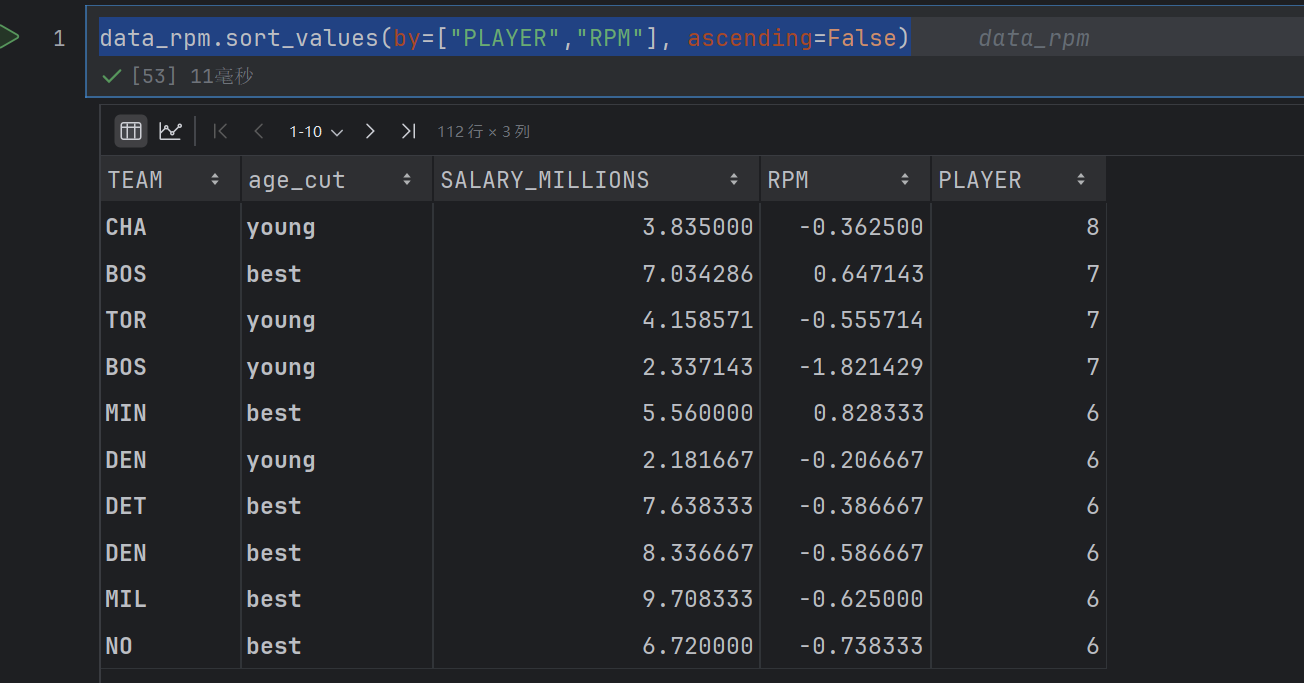
data_rpm2 = data.groupby(by=['TEAM'], as_index=False).agg({'SALARY_MILLIONS': "mean",'RPM': "mean",'PLAYER': "size",'POINTS': "mean",'eFG%': "mean",'MPG': "mean",'AGE': "mean"})
data_rpm2
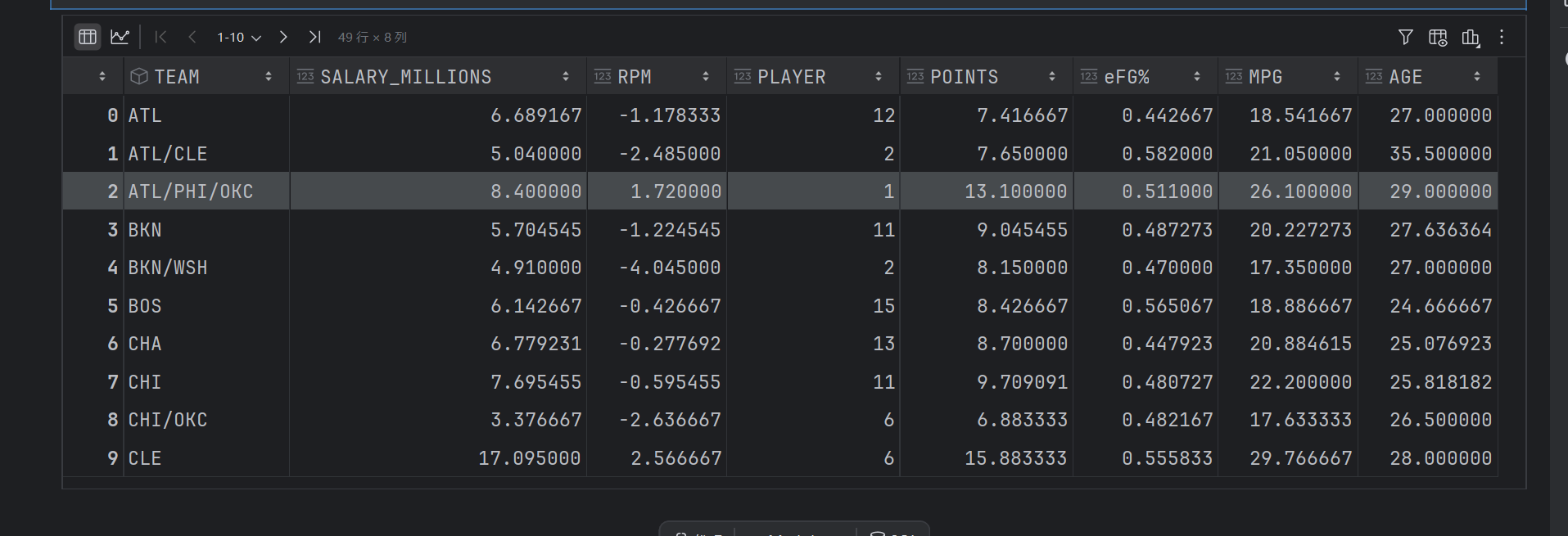
data_rpm2.sort_values(by=["RPM"], ascending=False)
data.TEAM.isin(['GS', 'CLE', 'SA', 'LAC', 'OKC', 'UTAH', 'CHA', 'TOR', 'NO', 'BOS'])
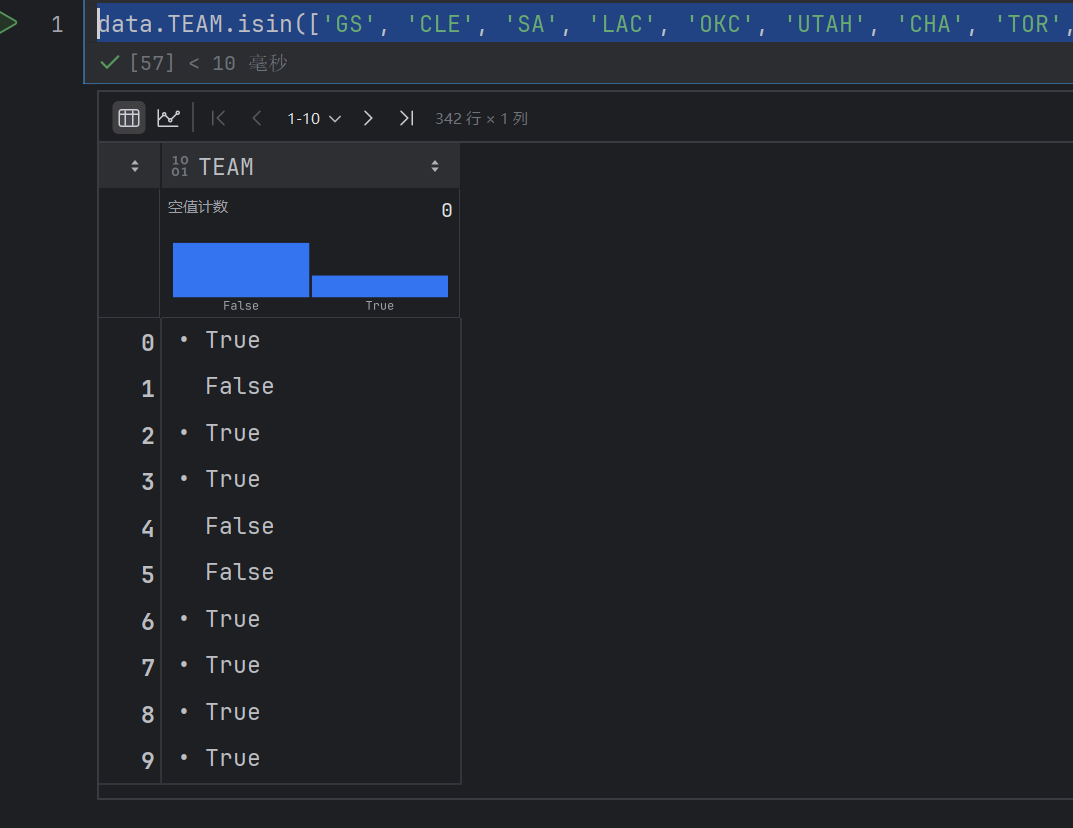
这个就是判断data.TEAM的每行是不是属于上面的其中一个team
data[data.TEAM.isin(['GS', 'CLE', 'SA', 'LAC', 'OKC', 'UTAH', 'CHA', 'TOR', 'NO', 'BOS'])]
作用是从 data 数据框中,筛选出 TEAM 列值属于指定球队列表([‘GS’, ‘CLE’, ‘SA’, ‘LAC’, ‘OKC’, ‘UTAH’, ‘CHA’, ‘TOR’, ‘NO’, ‘BOS’])的所有行。
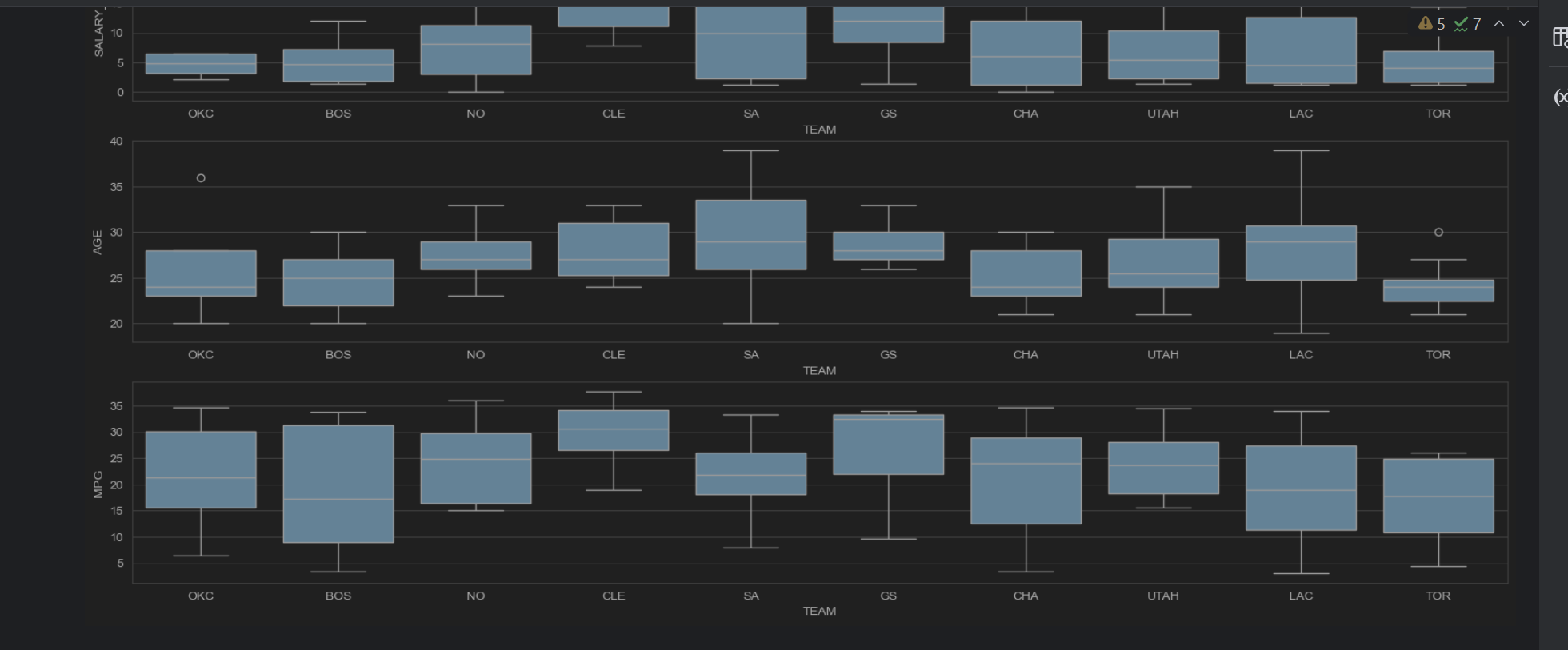
sns.set_style("whitegrid")
plt.figure(figsize=(20,10))
data_team2 = data[data.TEAM.isin(['GS', 'CLE', 'SA', 'LAC', 'OKC', 'UTAH', 'CHA', 'TOR', 'NO', 'BOS'])]
plt.subplot(3,1,1)
sns.boxplot(x="TEAM", y="SALARY_MILLIONS", data=data_team2)plt.subplot(3,1,2)
sns.boxplot(x="TEAM", y="AGE", data=data_team2)plt.subplot(3,1,3)
sns.boxplot(x="TEAM", y="MPG", data=data_team2)
sns.set_style("whitegrid")
plt.figure(figsize=(20,10))
data_team2 = data[data.TEAM.isin(['GS', 'CLE', 'SA', 'LAC', 'OKC', 'UTAH', 'CHA', 'TOR', 'NO', 'BOS'])]
plt.subplot(3,1,1)
sns.violinplot(x="TEAM", y="3P%", data=data_team2)plt.subplot(3,1,2)
sns.violinplot(x="TEAM", y="eFG%", data=data_team2)plt.subplot(3,1,3)
sns.violinplot(x="TEAM", y="POINTS", data=data_team2)

4. 北京租房数据统计分析
(1)统计每个区域的房源总数量,并使用热力图分析房源位置分布情况。
(2)使用条形图分析哪种户型的数量最多、更受欢迎。
(3)统计每个区域的平均租金,并结合柱状图和折线图分析各区域的房源数量和租金情况。
(4)统计面积区间的市场占有率,并使用饼图绘制各区间所占的比例。
通过网络爬虫技术,爬取链家网站中列出的租房信息(爬取结束时间为2018年9月10日),具体包括所属区域、小区名称、房屋、价格、房屋面积、户型。需要说明的是,链家官网上并没有提供平谷、怀柔、密云、延庆等偏远地区的租房数据,所以本案例的分析不会涉及这四个地区。
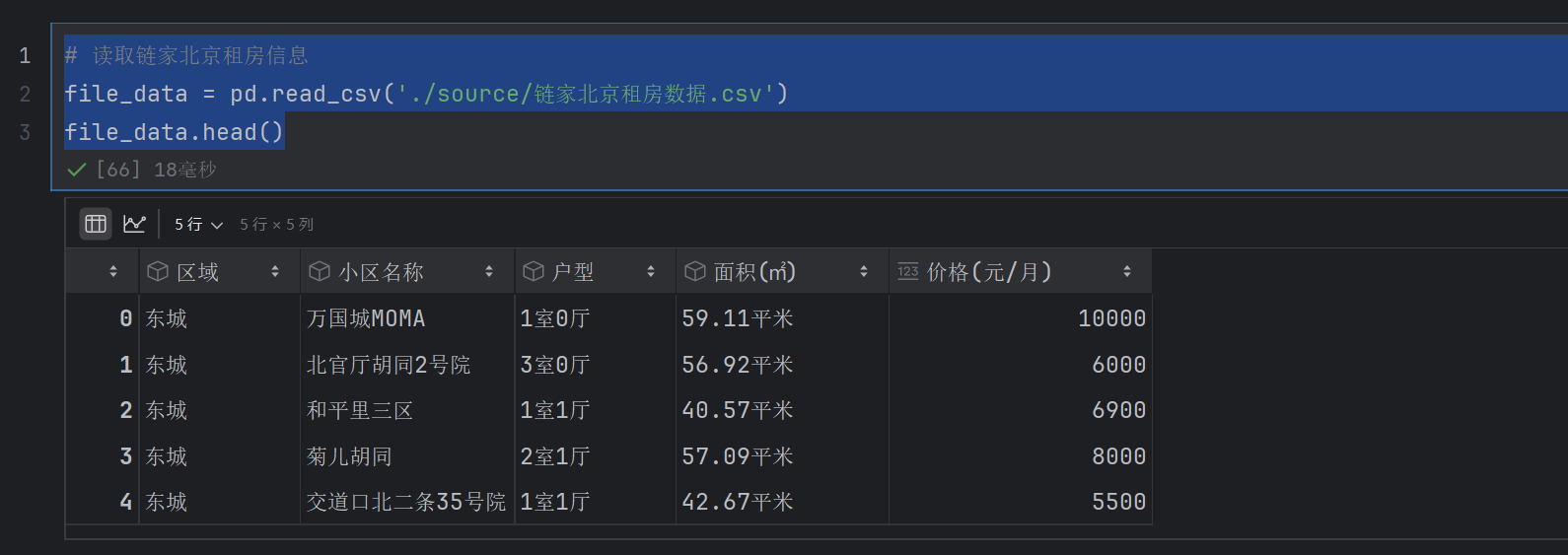
将爬到的数据下载到本地,并保存在“链家北京租房数据.csv”文件中,打开该文件后可以看到里面有很多条(本案例爬取的数据共计8224条)信息
# 读取链家北京租房信息
file_data = pd.read_csv('./source/链家北京租房数据.csv')
file_data.head()
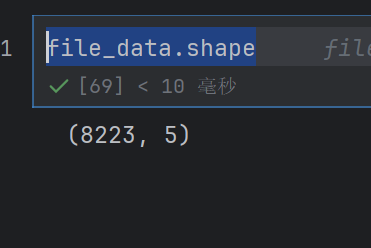
file_data.shape
file_data.info()
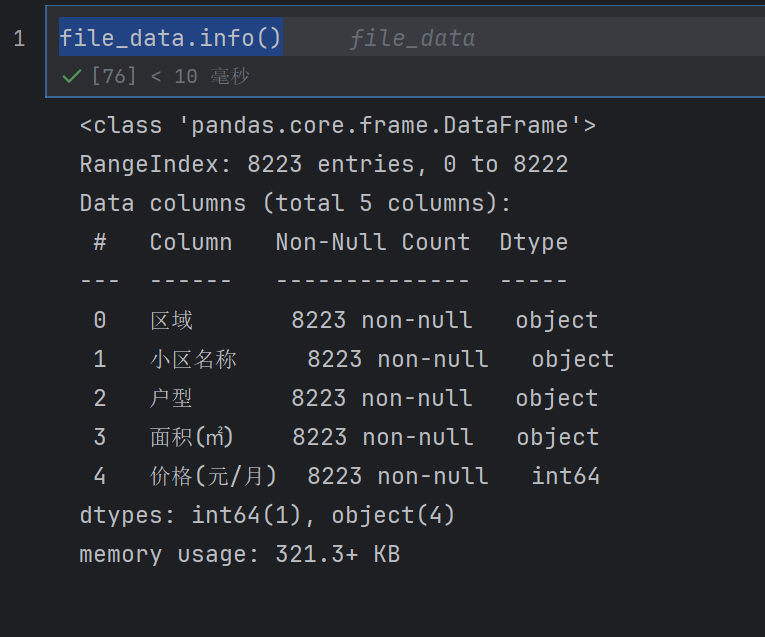
file_data.describe()
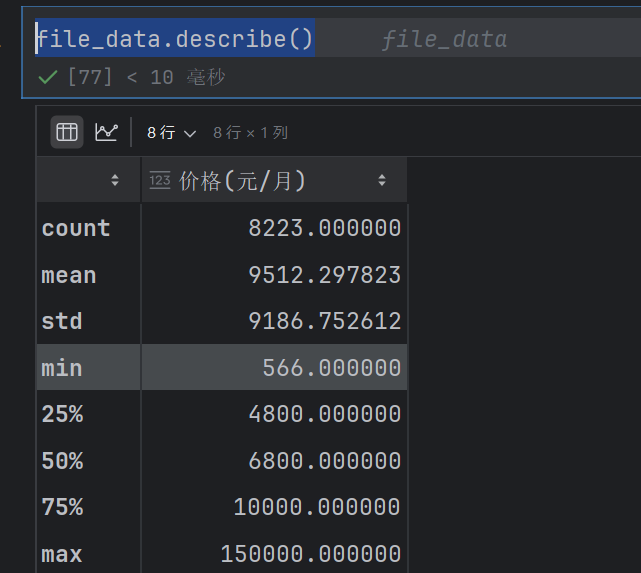
describe只对数进行处理
4.1 重复值和空值处理
file_data.duplicated()
只要有重复的数据就会映射为True,
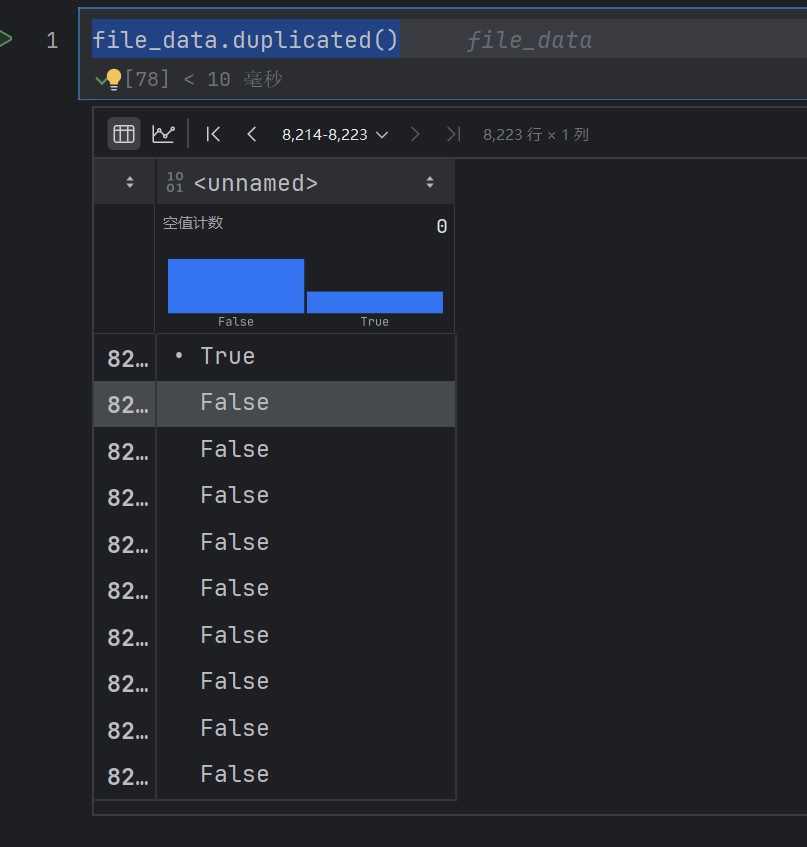
# 删除重复数据
file_data = file_data.drop_duplicates()
file_data.shape
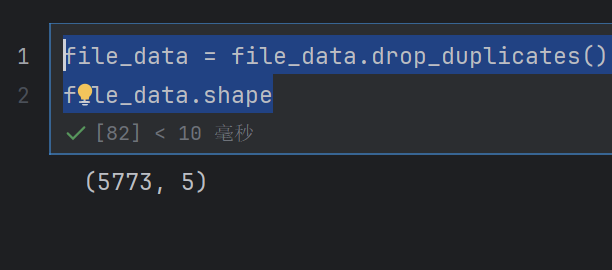
变小了,说明删除了
#删除空值
file_data.dropna()
file_data.shape
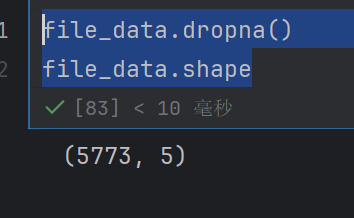
说明没有空值
4.2 数据转换类型
在这套租房数据中,“面积(m )”一列的数据里面有中文字符,说明这一列数据都是字符串类型的。为了方便后续对面积数据进行数学运算,所以需要将“面积(m)”一列的数据类型转换为float类型
面积(㎡)这个东西直接复制
file_data["面积(㎡)"].values
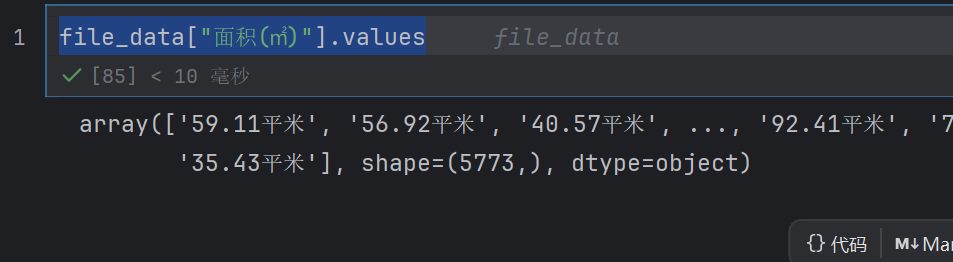
file_data["面积(㎡)"].values[0]
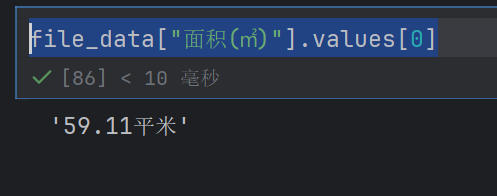
file_data["面积(㎡)"].values[0][:-2]
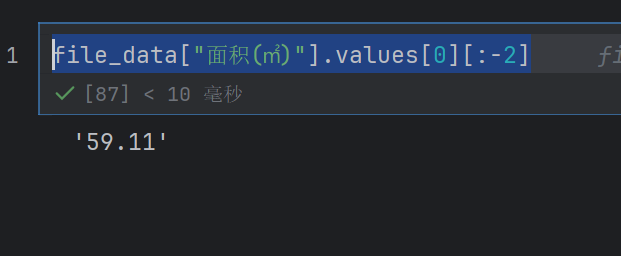
data_new = np.array([])
data_area = file_data["面积(㎡)"].values
for i in data_area:data_new = np.append(data_new, np.array(i[:-2]))
data_new
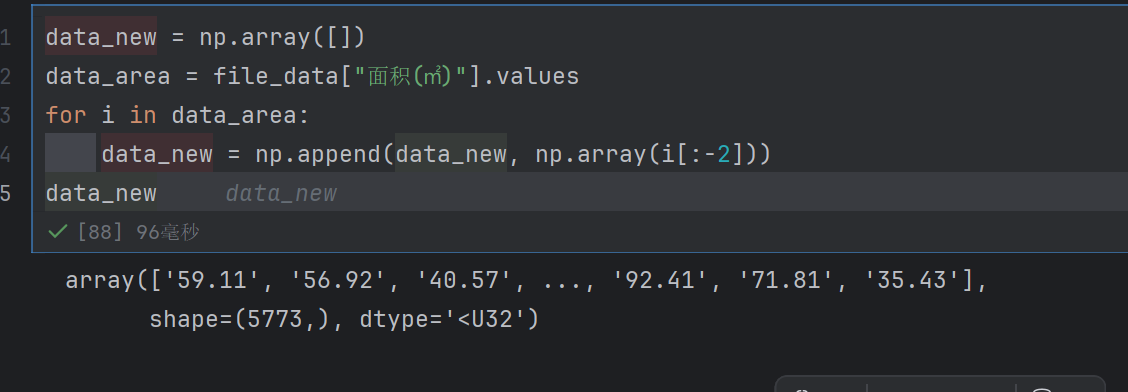
np.append(data_new, …):将处理后的元素追加到data_new数组中。
data_new = data_new.astype(np.float64)
file_data.loc[:,"面积(㎡)"] = data_new
file_data
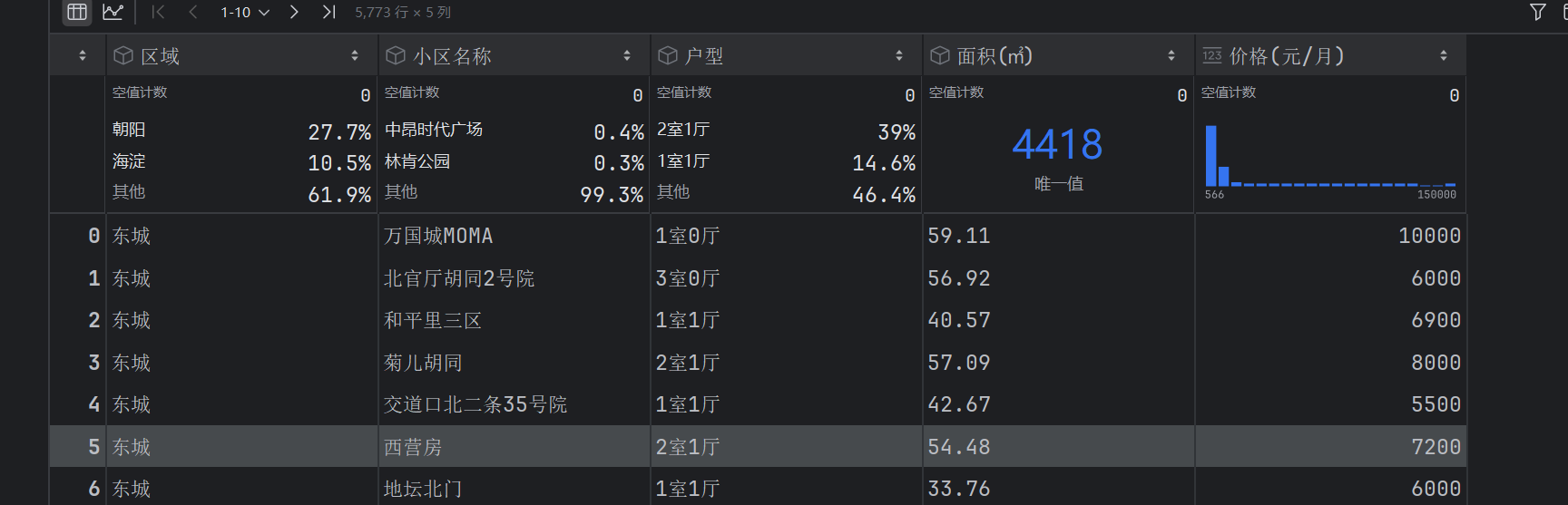
这样就转化成功了
现在转化户型
还有几房间几卫的
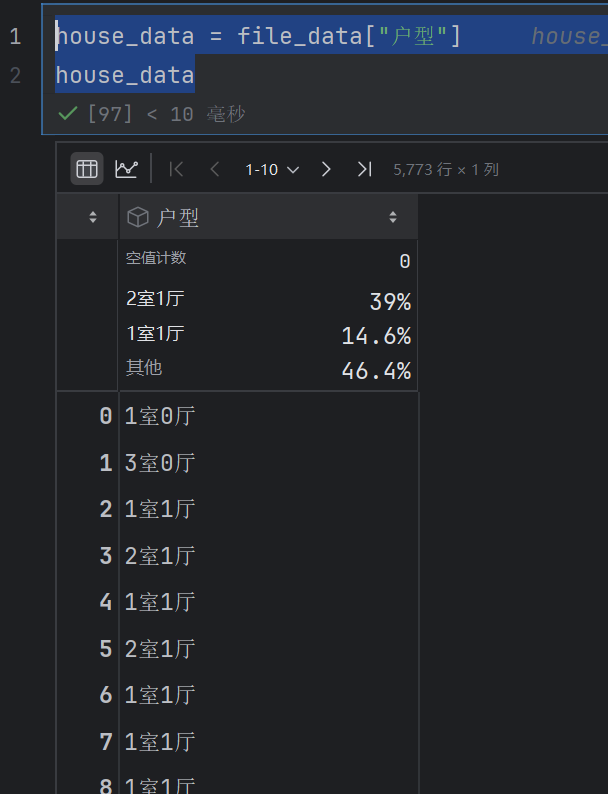
house_data = file_data["户型"]
temp_list = []
for i in house_data:print(i)
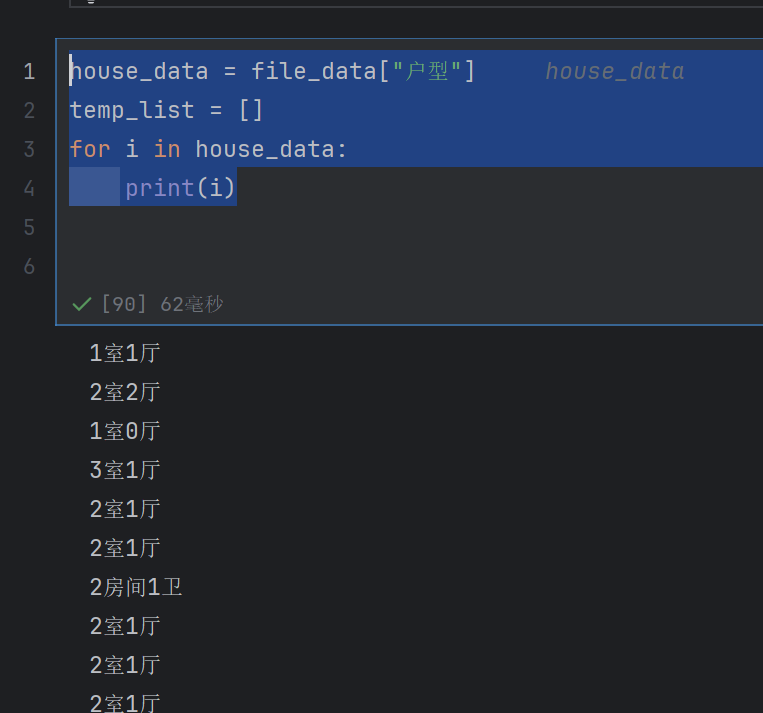
house_data = file_data["户型"]
temp_list = []
for i in house_data:new_info = i.replace("房间","室")temp_list.append(new_info)
temp_list
这个就是把所有得到房间都替换为室
没有的话就不替换,所以temp_list里面就是所有正确的数据了
file_data.loc[:,"户型"]=temp_list
file_data.loc[:,"户型"]
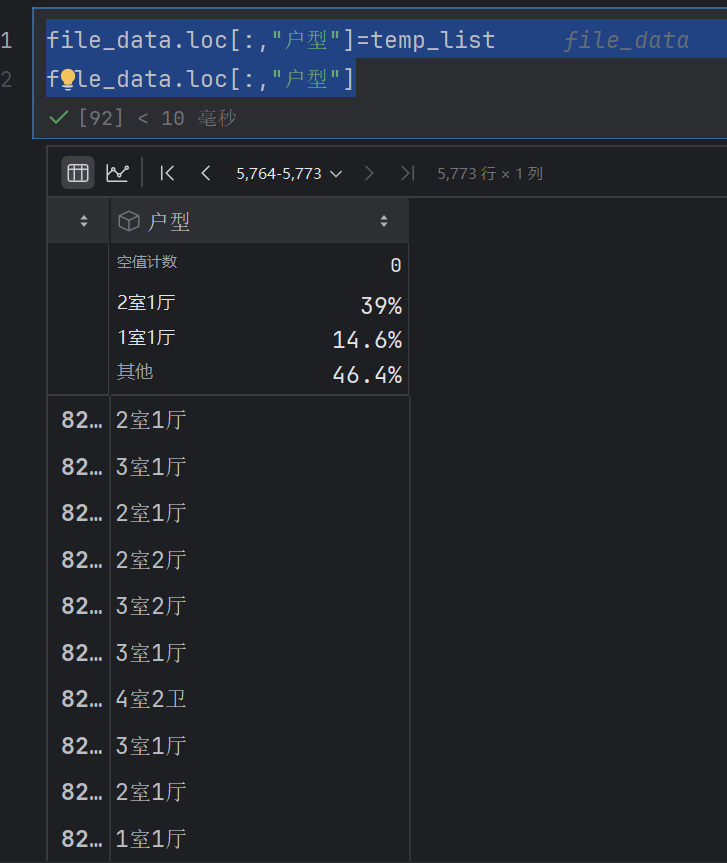
卫字就不替换了
4.3 房源数量、位置分布分析
file_data["区域"].unique()

这个是检索所有的区域
new_df = pd.DataFrame({"区域":file_data["区域"].unique(),"数量":[0]*13})
new_df
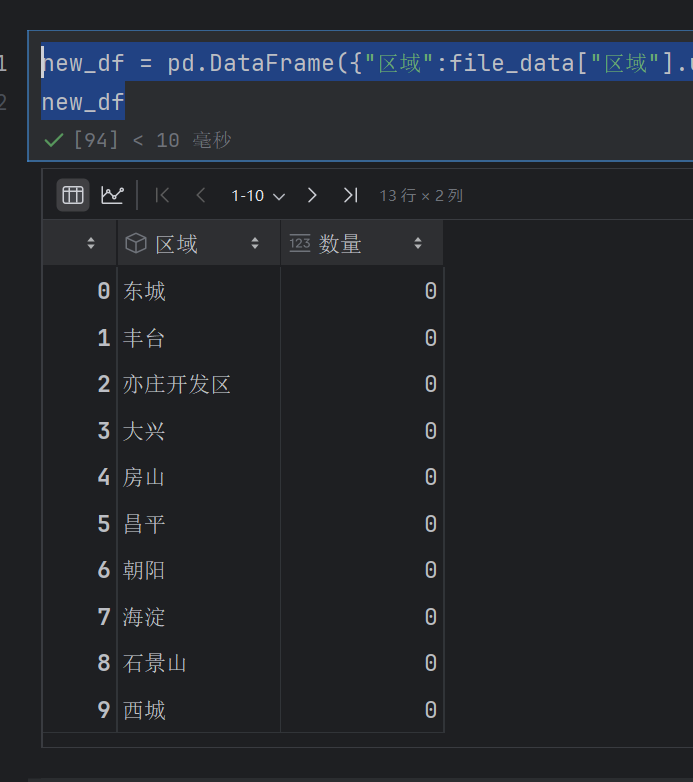
然后就是获取数量了
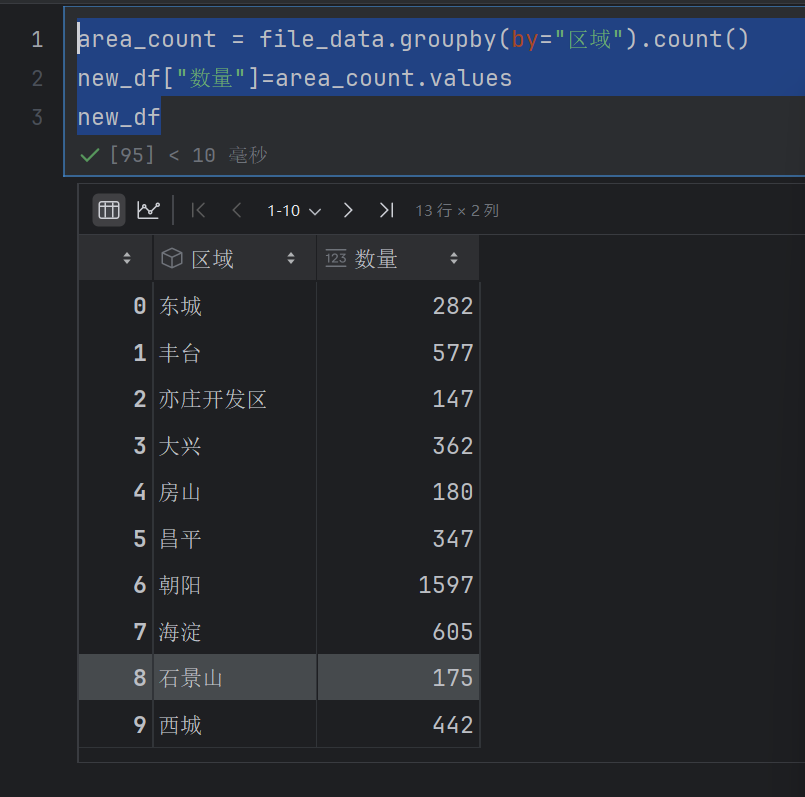
area_count = file_data.groupby(by="区域").count()
new_df["数量"]=area_count.values
new_df
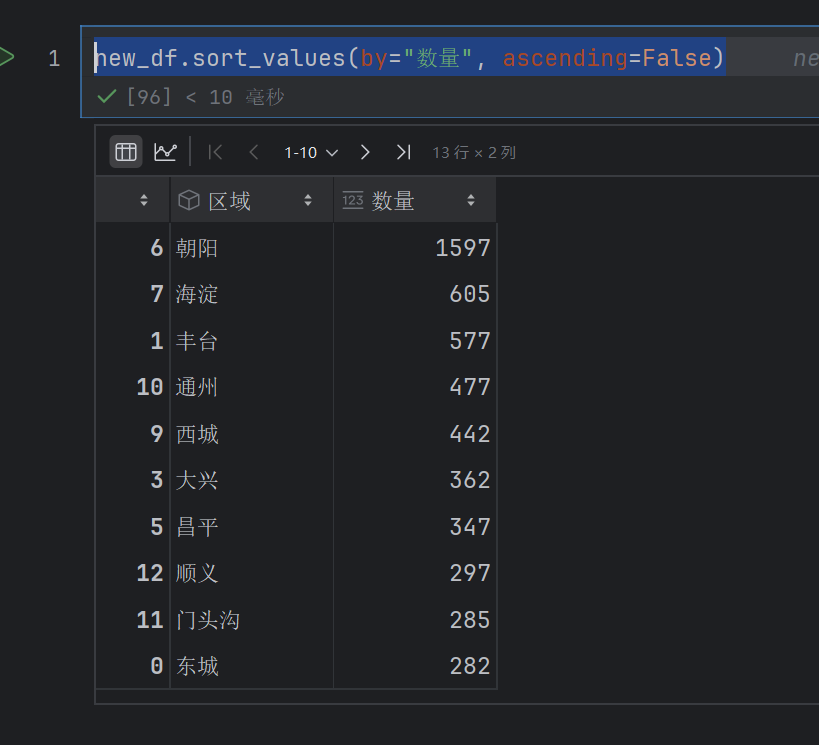
new_df.sort_values(by="数量", ascending=False)
4.4 户型数量分析
house_data = file_data["户型"]
house_data
#%%
def all_house(arr):key = np.unique(arr)result={}for k in key:mask = (arr == k)arr_new =arr[mask]v = arr_new.sizeresult[k]=vreturn result
key = np.unique(arr)
使用 numpy 的 unique 函数获取数组 arr 中所有不重复的元素(即唯一值),存储在 key 中。
例如:如果 arr = np.array([‘A’, ‘B’, ‘A’, ‘C’, ‘B’]),则 key 会是 [‘A’, ‘B’, ‘C’]。
result = {}
初始化一个空字典 result,用于存储最终的统计结果(键为唯一元素,值为该元素出现的次数)
假设输入的 arr 是一个 numpy 数组,例如:
arr = np.array([‘苹果’, ‘香蕉’, ‘苹果’, ‘橙子’, ‘香蕉’, ‘苹果’])
而 key 是通过 np.unique(arr) 得到的唯一元素数组:
key = [‘苹果’, ‘香蕉’, ‘橙子’]
遍历 key 中的每个唯一元素(即 ‘苹果’、‘香蕉’、‘橙子’)。每次循环,k 会依次代表其中一个元素

(arr == k)就是把arr中所有等于k的变为True


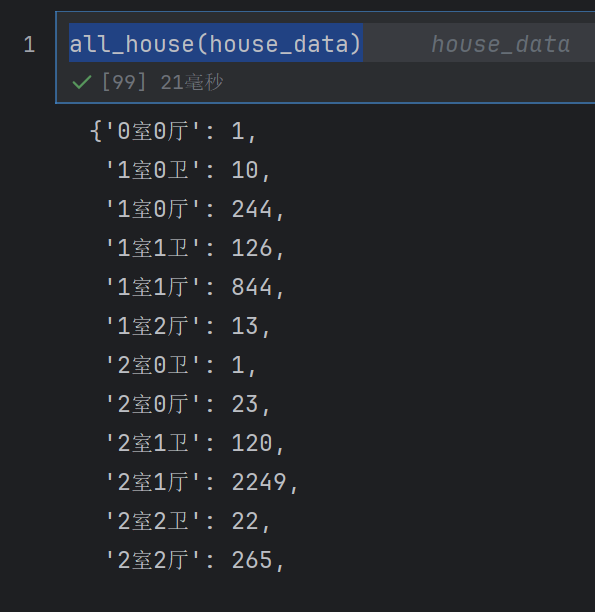
house_info = all_house(house_data)
house_info
house_data = dict((key,value) for key,value in house_info.items() if value > 50)
house_data
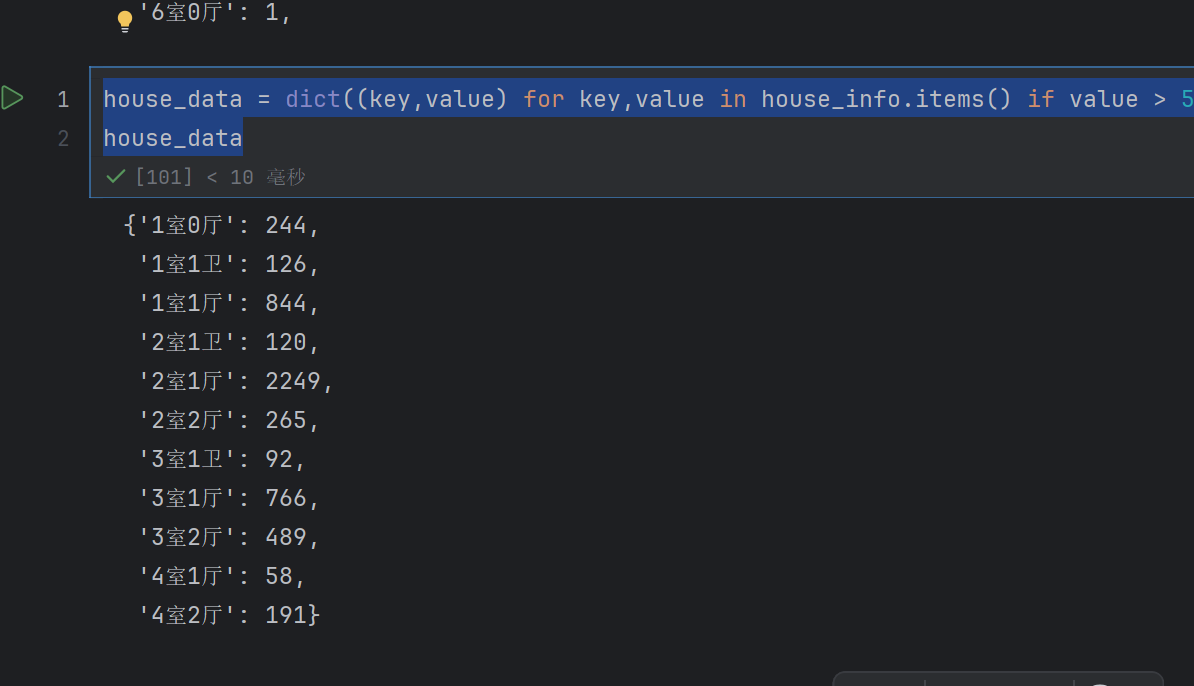
这个就是删除里面小于50的数据
house_info.items():返回字典 house_info 中所有键值对的视图(类似 (key, value) 元组的集合)。
for key, value in house_info.items():遍历 house_info 中的每个键值对,每次循环将键赋值给 key,值赋值给 value。
if value > 50:过滤条件,只保留值(value)大于 50 的键值对。
dict((key, value) … ):将筛选后的 (key, value) 元组转换为新的字典。
可以看成这样
(key,value) for key,value in house_info.items() if value > 50
在用dict()装起来为字典
show_house= pd.DataFrame({"户型":[x for x in house_data.keys()],"数量":[x for x in house_data.values()]})
show_house
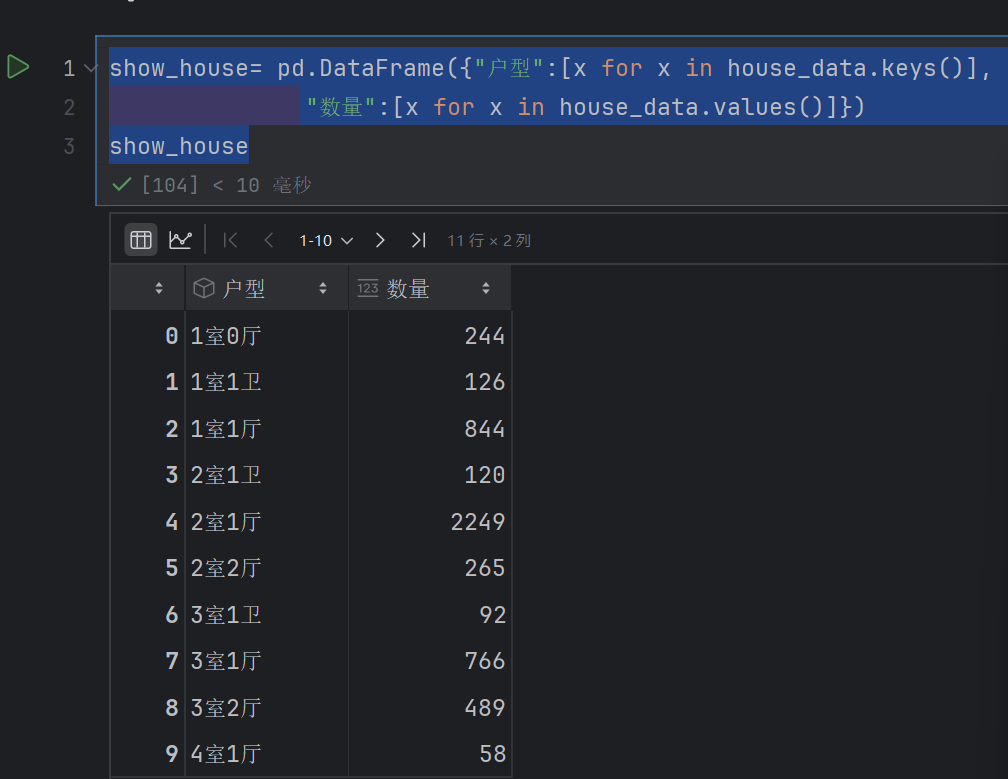
然后是图像展示了
house_type = show_house["户型"]
house_type_num = show_house["数量"]
plt.barh(range(11),house_type_num)
range(11)表示有多少个区间
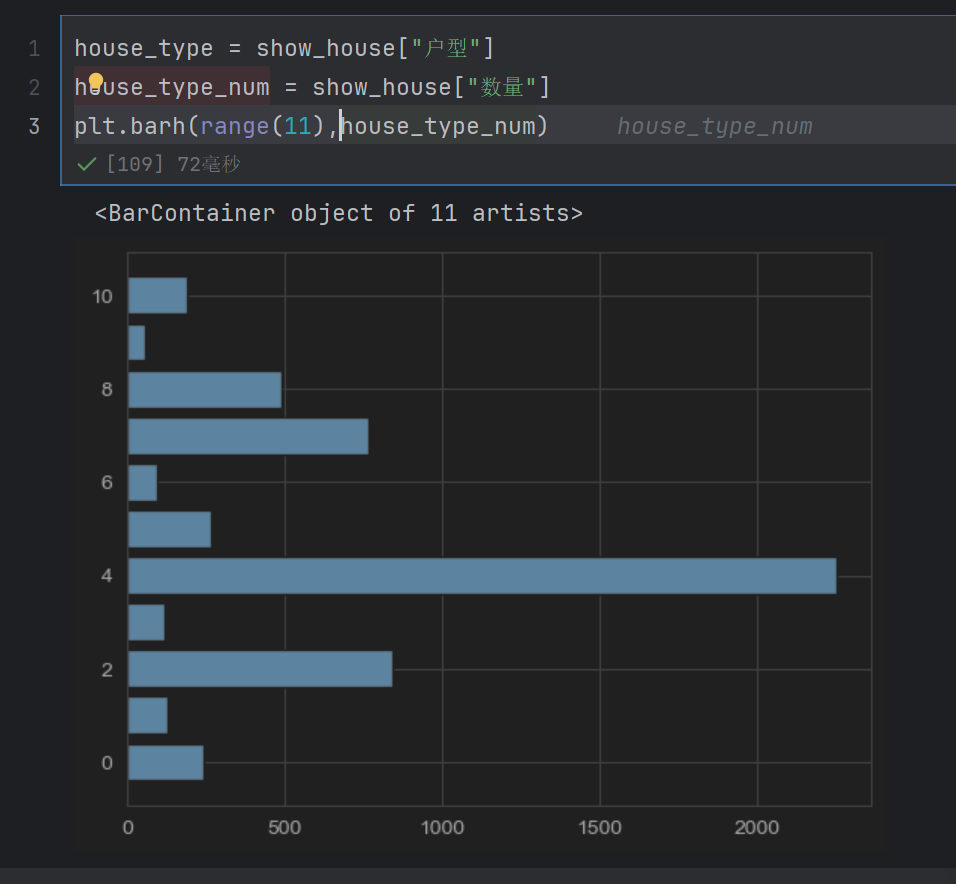
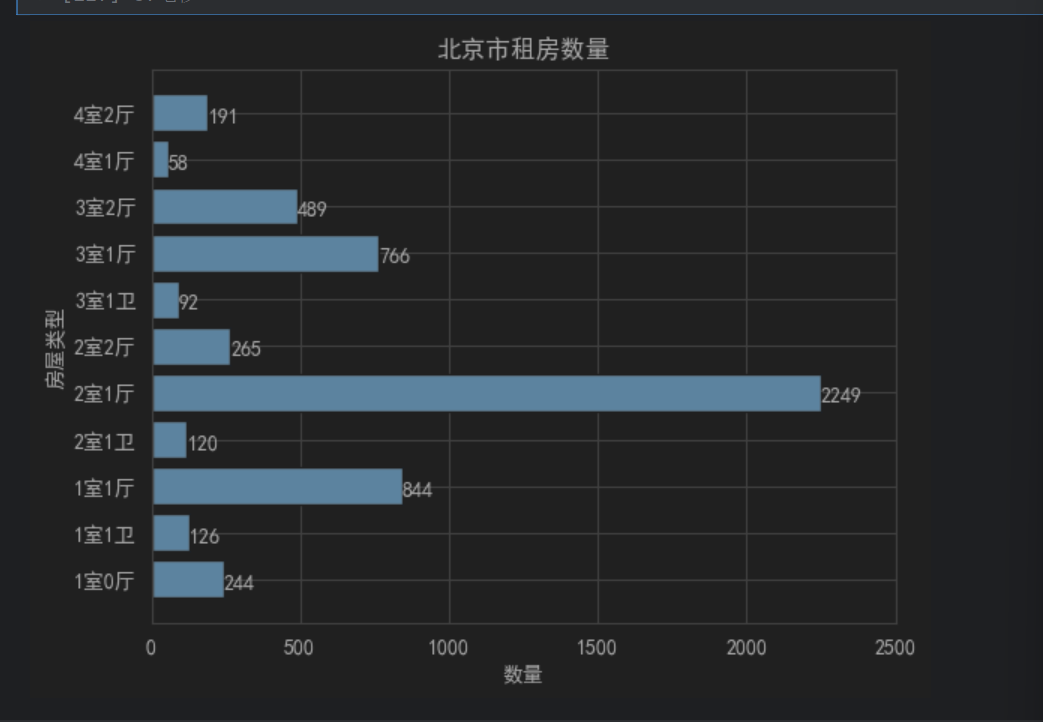
house_type = show_house["户型"]
house_type_num = show_house["数量"]
plt.barh(range(11),house_type_num)
plt.yticks(range(11),house_type)
plt.xlim(0,2500)
plt.title("北京市租房数量")
plt.xlabel("数量")
plt.ylabel("房屋类型")
for x,y in enumerate(house_type_num):plt.text(y+0.5,x-0.2,"%s"%y)
plt.show()
matplotlib.pyplot.text() 是用于在 matplotlib 图表上添加文本注释的函数,其基本语法为:
plt.text(x, y, s, …)
x:文本在图表中水平方向(x 轴)的位置坐标
y:文本在图表中垂直方向(y 轴)的位置坐标
s:要显示的文本内容
for x,y in enumerate(house_type_num):print(x,y)
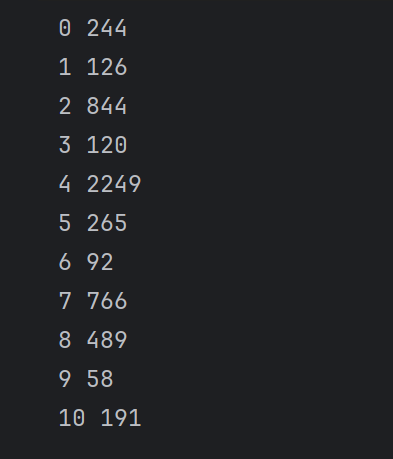
所以是plt.text(y, x)
%s 是一个格式占位符,表示 “这里需要插入一个字符串”(s 是 string 的缩写)。
% 是格式化运算符,用于将右边的变量值填充到左边字符串的占位符中。
整体含义:把变量 y 的值转换为字符串,并替换掉 “%s” 这个占位符。
4.5 平均租金分析
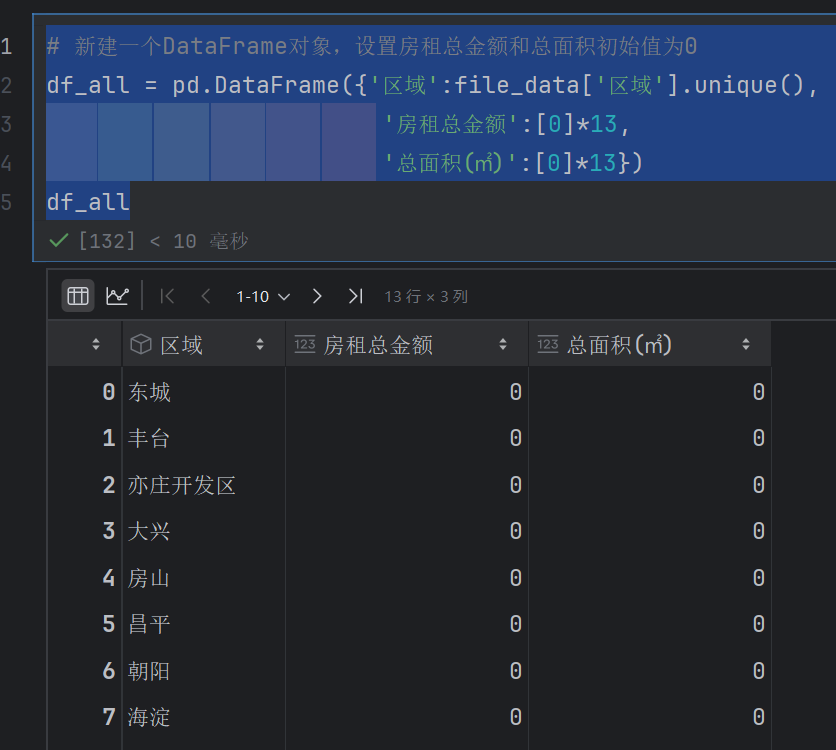
# 新建一个DataFrame对象,设置房租总金额和总面积初始值为0
df_all = pd.DataFrame({'区域':file_data['区域'].unique(),'房租总金额':[0]*13,'总面积(㎡)':[0]*13})
df_all
# 求总金额和总面积
sum_price = file_data['价格(元/月)'].groupby(file_data['区域']).sum()
sum_price
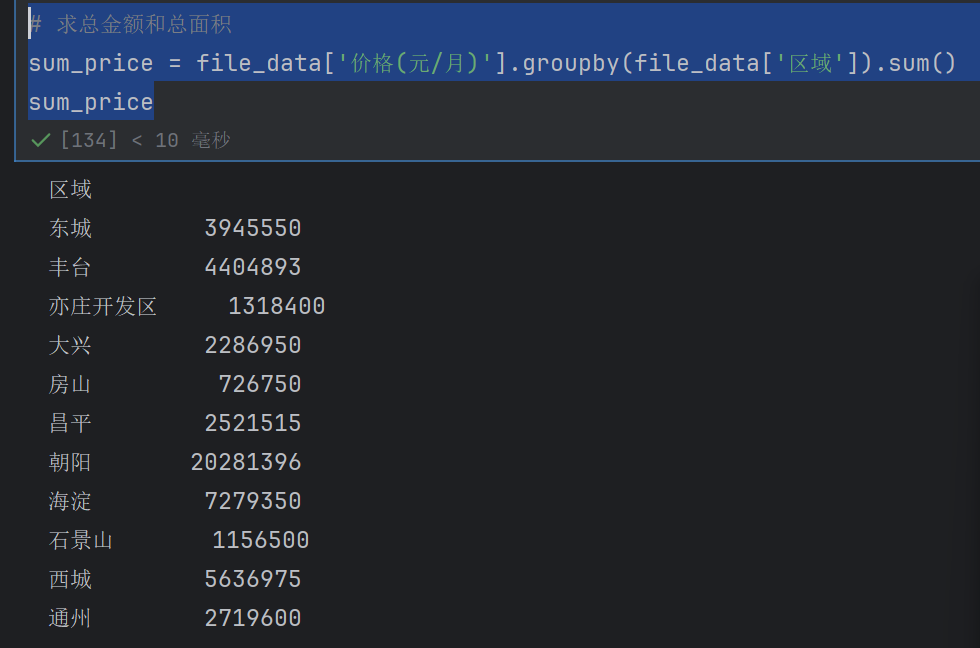
sum_area = file_data['面积(㎡)'].groupby(file_data['区域']).sum()
df_all['房租总金额'] = sum_price.values
df_all['总面积(㎡)'] = sum_area.values
df_all
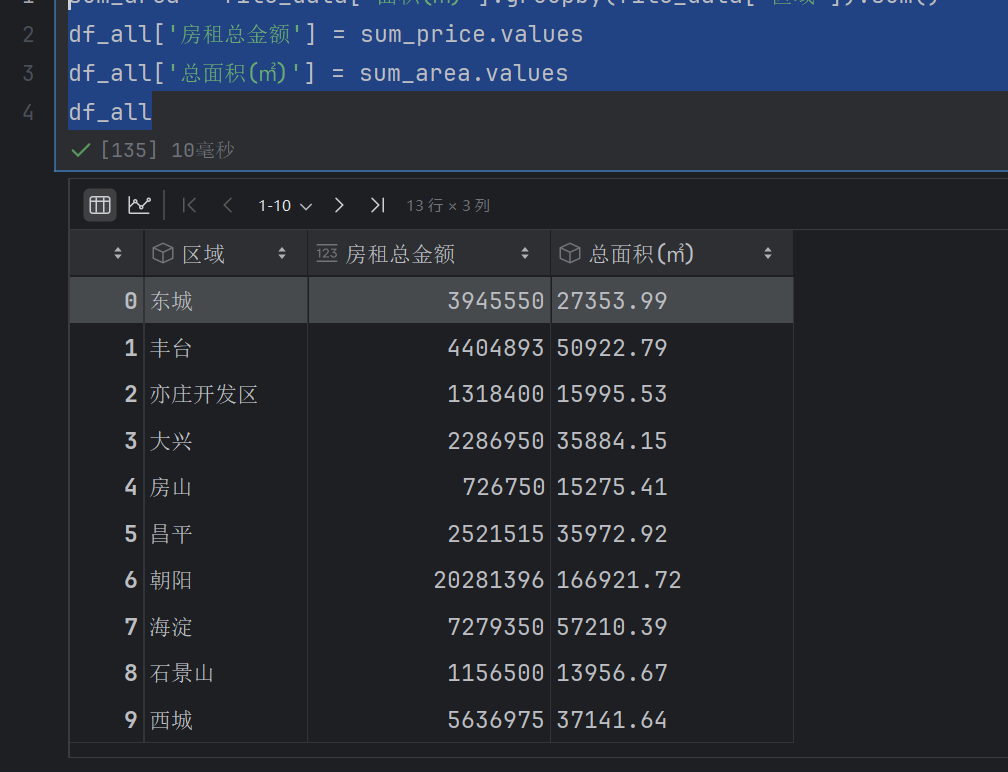
注意我们前面有一个错误,就是没有把平方米那一列转化为float
file_data["面积(㎡)"]=file_data["面积(㎡)"].astype("float64")
file_data.info()
用这个astype(“float64”)就可以了,不要用np.float64
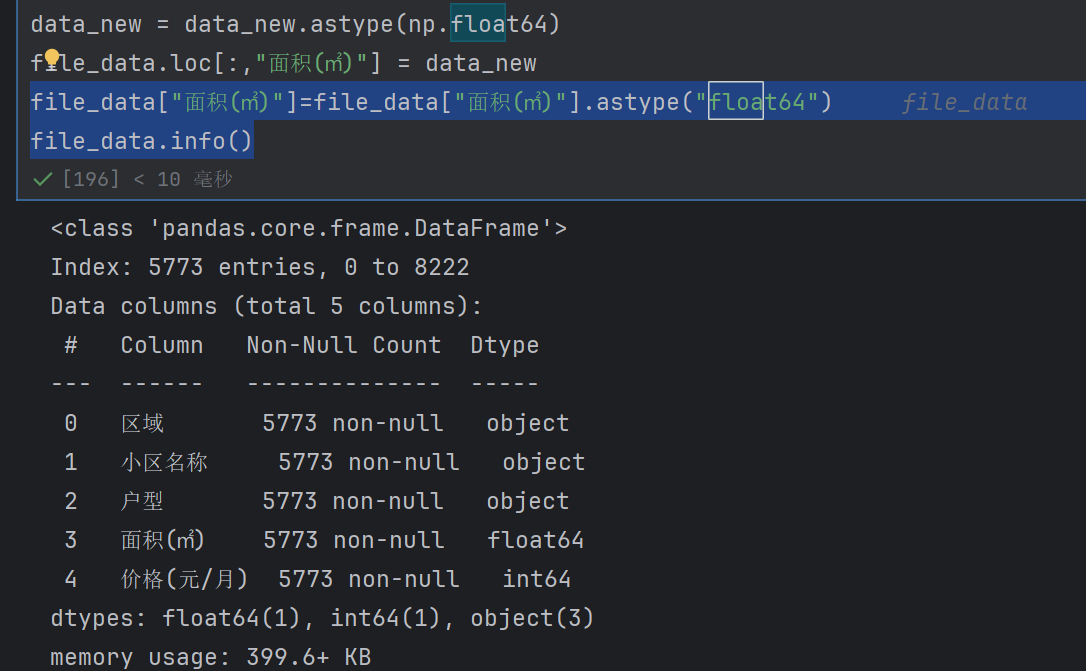
没有变为float是无法计算的
# 计算各区域每平米房租价格,并保留两位小数
df_all['每平米租金(元)'] = round(df_all['房租总金额'] / df_all ['总面积(㎡)'], 2)
df_all
指的是保留两位小数
/:对两列进行元素级除法—— 即第一行的房租总金额 ÷ 第一行的总面积,第二行的房租总金额 ÷ 第二行的总面积,以此类推,得到每一行对应的 “每平米租金”(未四舍五入的原始值)
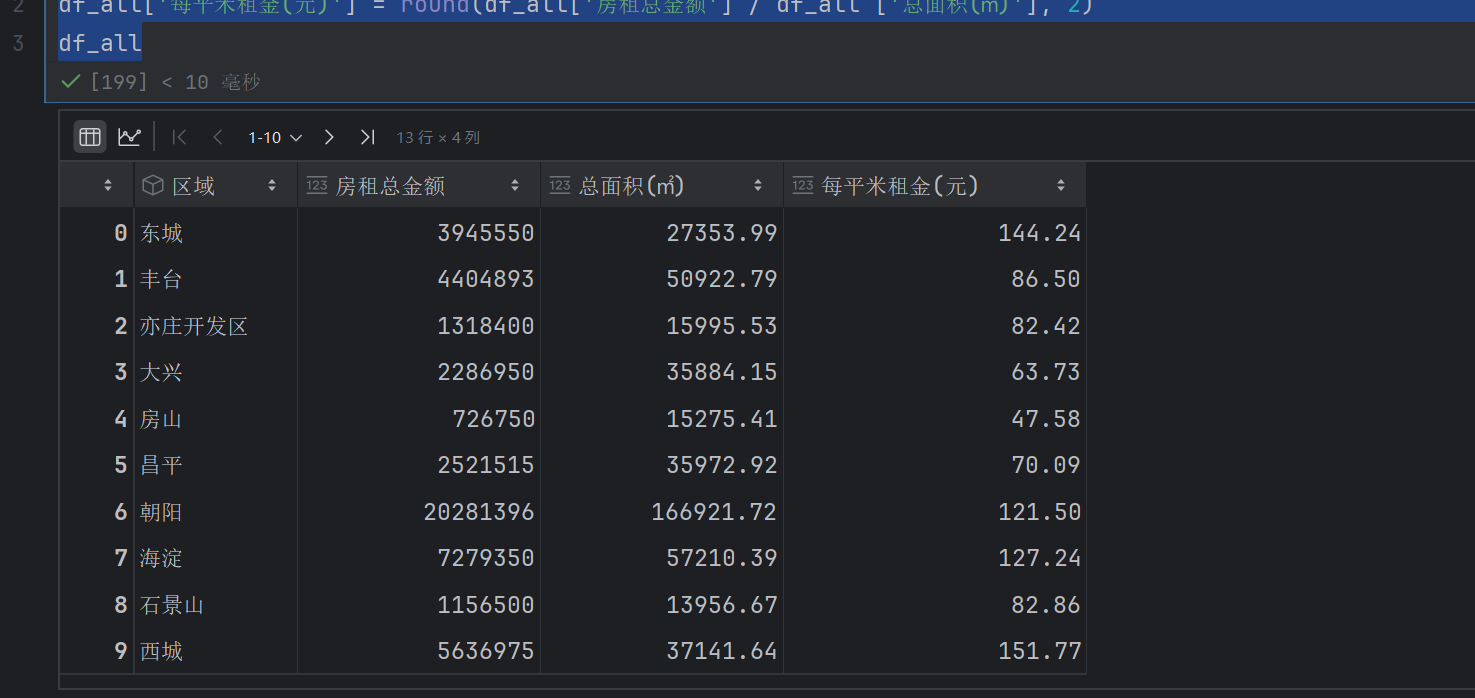
df_merge = pd.merge(new_df,df_all)
df_merge
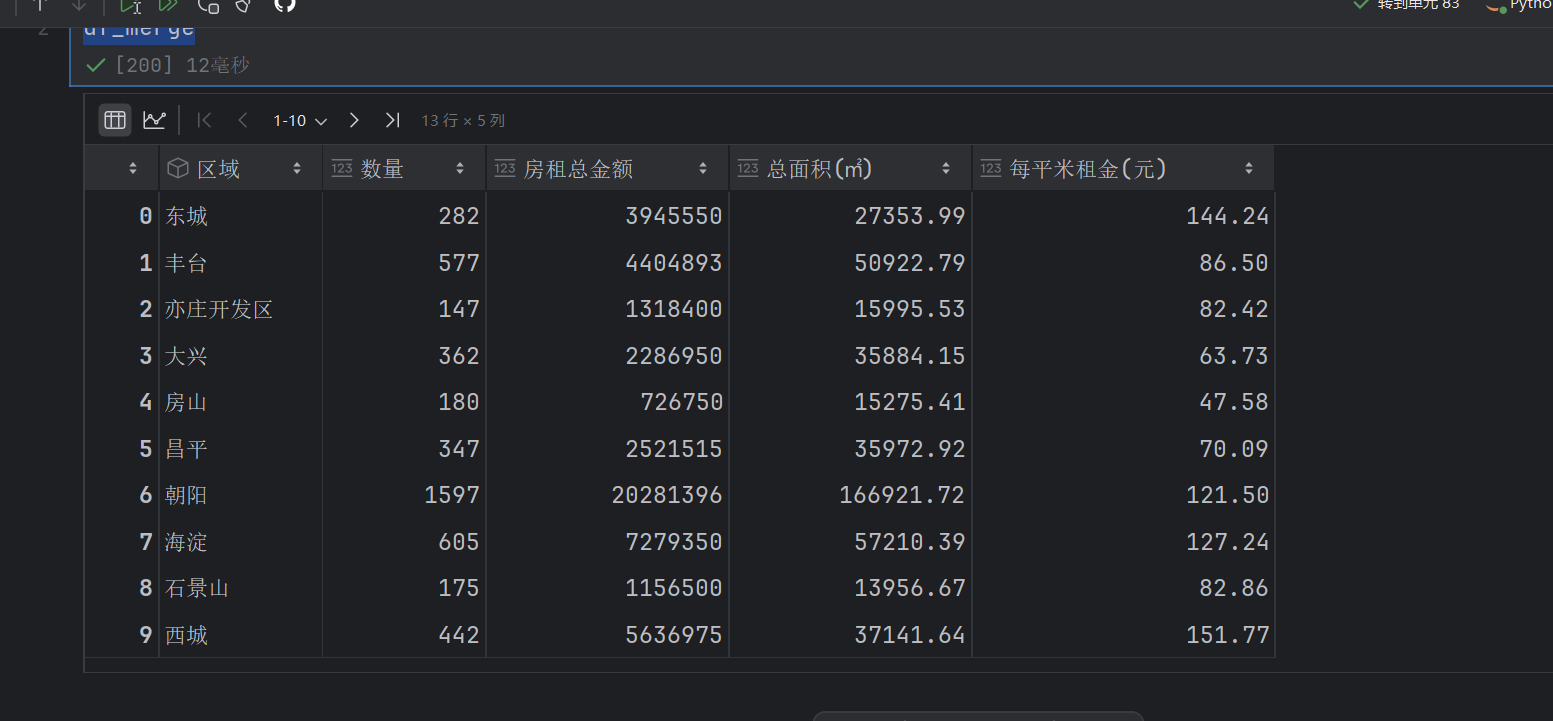
这个是把两个图给合并
num= df_merge['数量'] # 数量
price=df_merge['每平米租金(元)'] # 价格
lx=df_merge['区域']
l=[i for i in range(13)]
plt.figure(figsize=(20, 8), dpi=100)
fig = plt.figure(figsize=(10, 8), dpi=100)
# 显示折线图
ax1 = fig.add_subplot(111)
ax1.plot(l, price)
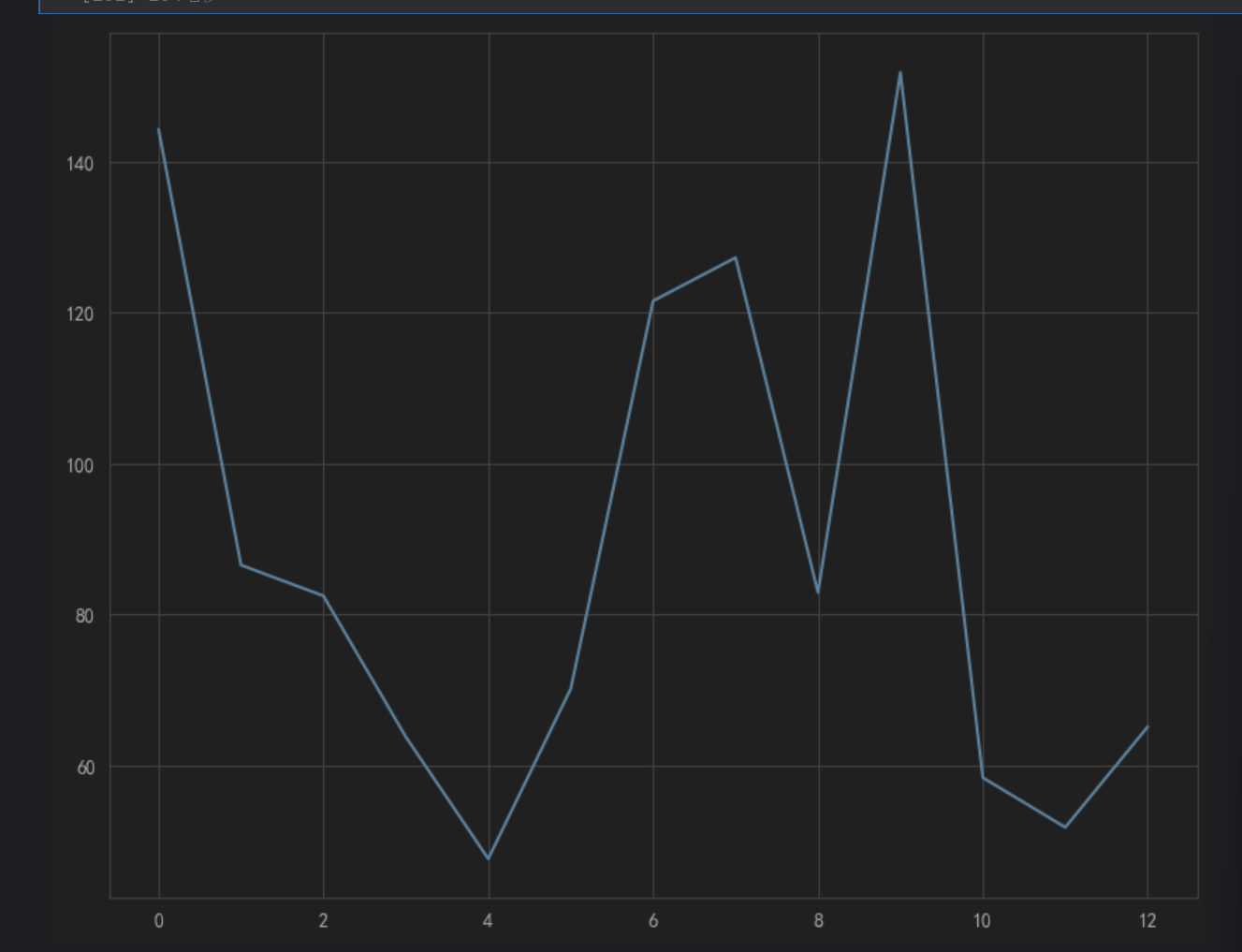
在 ax1.plot(l, price) 中,第一个参数 l 表示折线图上每个数据点的x 轴坐标
第二个参数 price 表示对应的数据值(y 轴坐标)
因为代码中手动指定了 x 轴坐标 l,所以 matplotlib 会严格按照 l 提供的位置绘图。如果想让 price 的索引作为 x 轴坐标,不需要手动创建 l,直接用 ax1.plot(price) 即可 —— 此时 matplotlib 会自动将 price 的索引作为 x 轴坐标,值作为 y 轴坐标。
add_subplot() 是 matplotlib 中用于在一个 figure(画布)上创建子图的方法,它可以将画布分割成多个区域,每个区域可以绘制独立的图表(如折线图、柱状图等)。
111 是一个三位数的参数,含义是将画布分割为 1 行(第一个 1)、1 列(第二个 1) 的网格,当前子图位于第 1 个位置(第三个 1)。
通俗来说,111 表示 “在当前画布上只创建 1 个子图,占据整个画布”。
变量 ax1 是创建出的子图对象,后续可以通过 ax1 调用绘图方法(如 ax1.plot() 画折线图)。
ax1.plot(l, price,"or-")
o表示圈圈,r表示red
num= df_merge['数量'] # 数量
price=df_merge['每平米租金(元)'] # 价格
lx=df_merge['区域']
l=[i for i in range(13)]
plt.figure(figsize=(20, 8), dpi=100)
fig = plt.figure(figsize=(10, 8), dpi=100)
# 显示折线图
ax1 = fig.add_subplot(111)
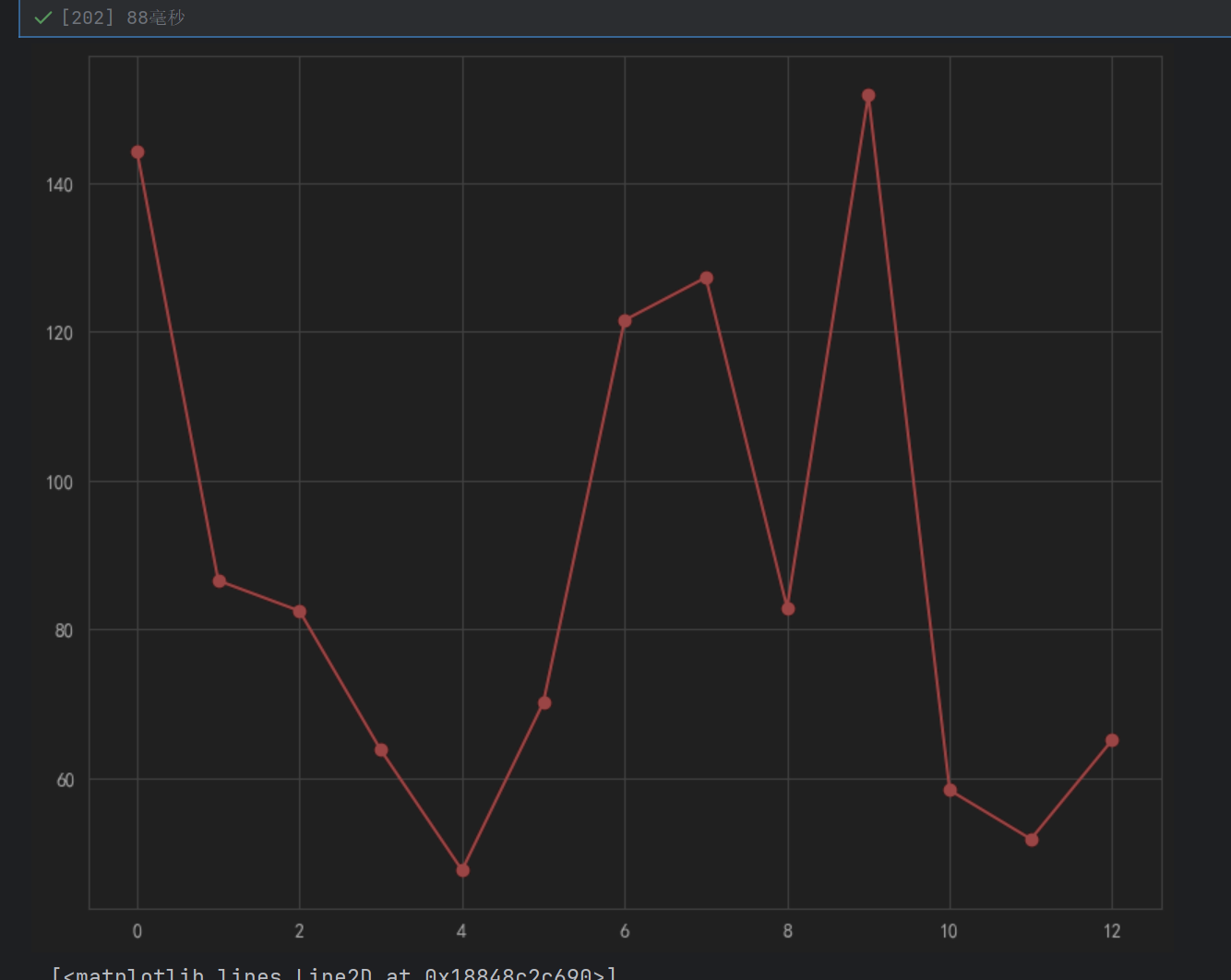
ax1.plot(l, price,"or-",label="价格")
for i ,(_x,_y) in enumerate(zip(l,price)):plt.text(_x+0.2,_y,price[i])
plt.show()
- zip(l, price)
l 是 x 轴坐标列表([0,1,2,…,12]),price 是 y 轴数值(每平米租金)。
zip(l, price) 将 l 和 price 中的元素按顺序一一配对,生成类似 (0, 价格1), (1, 价格2), …, (12, 价格13) 的元组序列。
例如:如果 l = [0,1]、price = [100, 200],则 zip(l, price) 会生成 (0,100), (1,200)。 - enumerate(zip(l, price))
enumerate() 函数会为 zip 生成的每个元组添加一个索引值 i,格式为 (i, (x, y))。
接上例:enumerate(…) 会生成 (0, (0,100)), (1, (1,200)),其中 i 依次为 0,1。
作用:i 用于后续获取 price 中的具体数值(price[i])。 - i, (_x, _y)
这是解包操作,将 enumerate 生成的 (i, (x, y)) 拆分为三个变量:
i:当前数据点的索引(0,1,…,12);
_x:当前数据点的 x 轴坐标(来自 l 的元素);
_y:当前数据点的 y 轴坐标(来自 price 的元素)。 - plt.text(_x + 0.2, _y, price[i])
plt.text(x, y, s) 是 matplotlib 添加文本的函数,参数分别为:
_x + 0.2:文本的 x 轴位置(在数据点 _x 右侧偏移 0.2,避免与折线重叠);
_y:文本的 y 轴位置(与数据点 _y 对齐,确保标签在点的旁边);
price[i]:要显示的文本内容(当前索引 i 对应的价格值)
lx=df_merge['区域']
l=[i for i in range(13)]
plt.figure(figsize=(20, 8), dpi=100)
fig = plt.figure(figsize=(10, 8), dpi=100)
# 显示折线图
ax1 = fig.add_subplot(111)
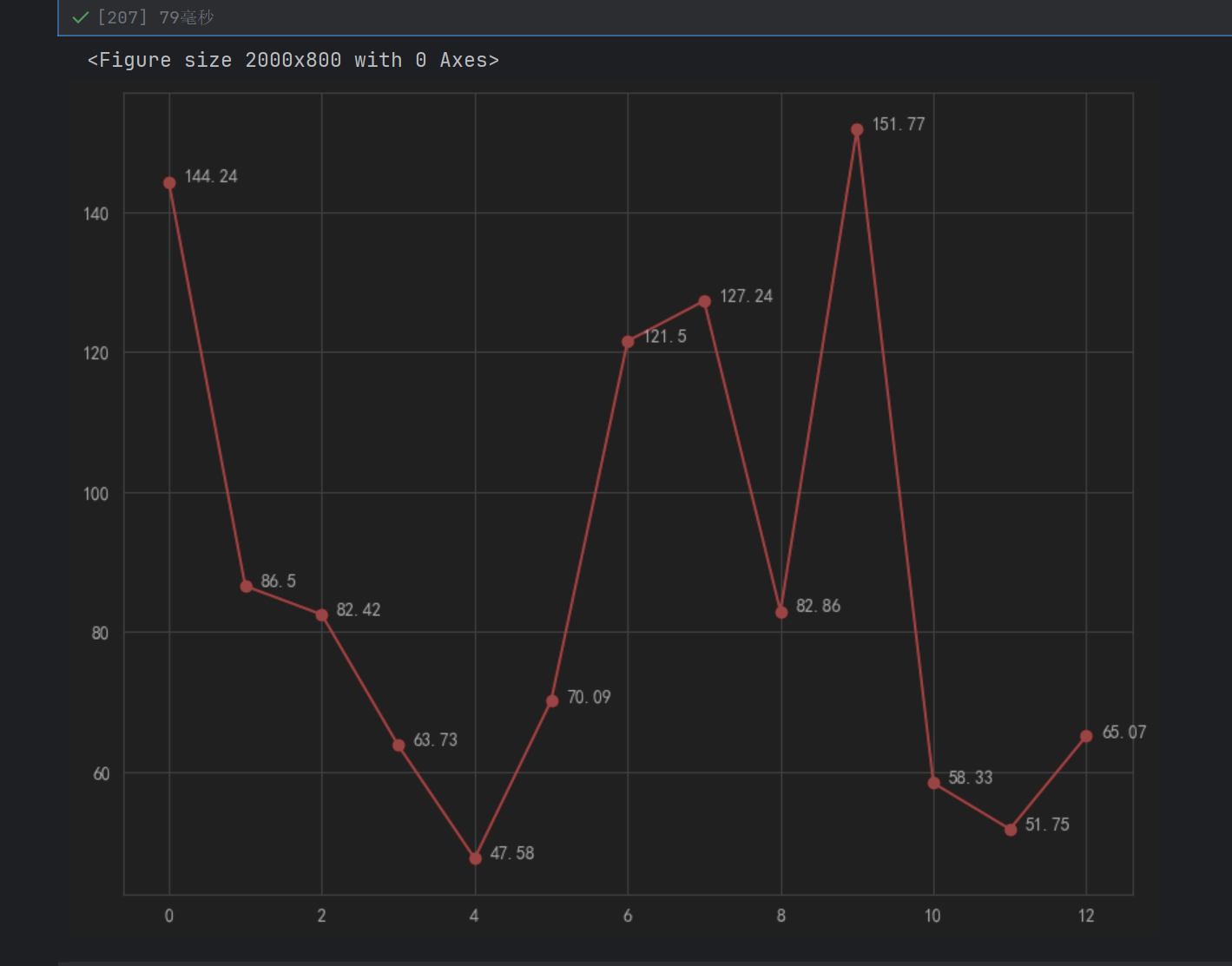
ax1.plot(l, price,"or-",label="价格")
for i ,(_x,_y) in enumerate(zip(l,price)):plt.text(_x+0.2,_y,price[i])
ax1.set_ylim(0,160)#设置y范围为0~160
ax1.set_ylabel("价格")
ax1.legend(loc="upper right")
plt.show()
ax1.set_ylim(0,160)#设置y范围为0~160
ax1.legend(loc=“upper right”)是显示ax1的label在右上角
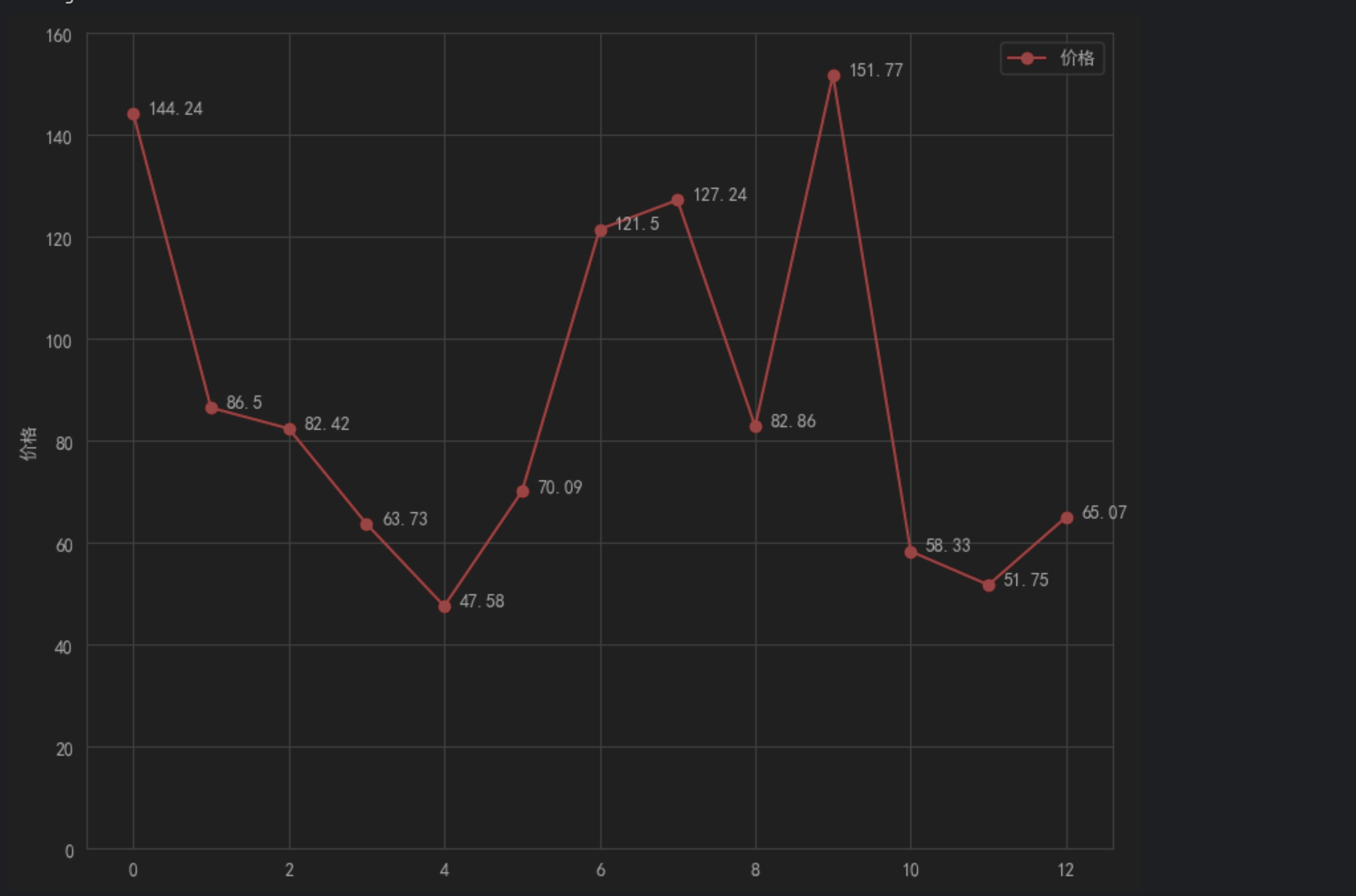
num= df_merge['数量'] # 数量
price=df_merge['每平米租金(元)'] # 价格
lx=df_merge['区域']
l=[i for i in range(13)]
plt.figure(figsize=(20, 8), dpi=100)
fig = plt.figure(figsize=(10, 8), dpi=100)
# 显示折线图
ax1 = fig.add_subplot(111)
ax1.plot(l, price,"or-",label="价格")
for i ,(_x,_y) in enumerate(zip(l,price)):plt.text(_x+0.2,_y,price[i])
ax1.set_ylim(0,160)#设置y范围为0~160
ax1.set_ylabel("价格")
ax1.legend(loc="upper right")#显示条形图
ax2 = ax1.twinx()
plt.bar(l,num,label="数量",alpha=0.2)plt.show()
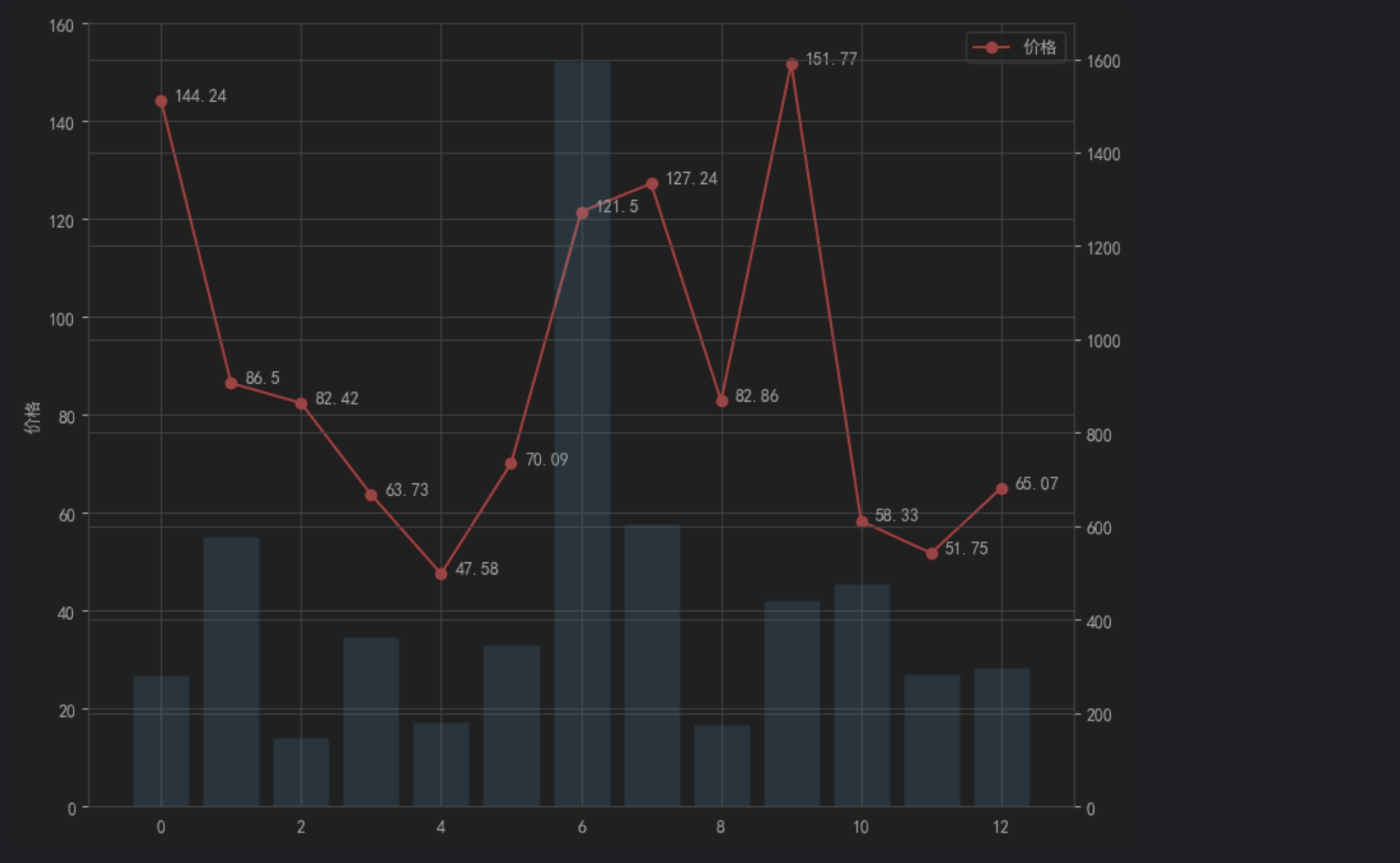
ax2 = ax1.twinx() 是 matplotlib 中一个非常实用的功能,它的作用是在同一个子图上创建一个与 ax1 共享 x 轴,但拥有独立 y 轴的新坐标轴 ax2。
twinx() 中的 “twin” 表示 “孪生”,ax2 可以理解为 ax1 的 “孪生兄弟”。
共享 x 轴:ax1 和 ax2 的 x 轴刻度、范围完全相同(在你的代码中,都是 l = [0,1,…,12] 对应的区域)。
独立 y 轴:ax1 和 ax2 有各自独立的 y 轴(左侧可能是 ax1 的价格轴,右侧是 ax2 的数量轴),两者可以有不同的数值范围和标签。
ax1 绘制折线图(价格,price),y 轴是 “每平米租金 (元)”,范围是 0~160;
ax2 绘制条形图(数量,num),y 轴是 “房屋数量”,数值范围可能与价格完全不同(比如可能是 0~2000)。
如果不使用 twinx(),两种数据会共用一个 y 轴,由于数值范围差异大(比如价格最高 160,数量可能达 2000),会导致其中一种图表被 “压缩” 得无法看清(比如折线图会几乎贴在 x 轴上)。
使用 ax2 = ax1.twinx() 后:
折线图(价格)用左侧 y 轴(ax1 控制);
条形图(数量)用右侧 y 轴(ax2 控制);
两者共享 x 轴(区域),可以直观对比同一区域的 “价格” 和 “数量” 关系。
alpha是透明度,防止覆盖
num= df_merge['数量'] # 数量
price=df_merge['每平米租金(元)'] # 价格
lx=df_merge['区域']
l=[i for i in range(13)]
plt.figure(figsize=(20, 8), dpi=100)
fig = plt.figure(figsize=(10, 8), dpi=100)
# 显示折线图
ax1 = fig.add_subplot(111)
ax1.plot(l, price,"or-",label="价格")
for i ,(_x,_y) in enumerate(zip(l,price)):plt.text(_x+0.2,_y,price[i])
ax1.set_ylim(0,160)#设置y范围为0~160
ax1.set_ylabel("价格")
ax1.legend(loc="upper right")#显示条形图
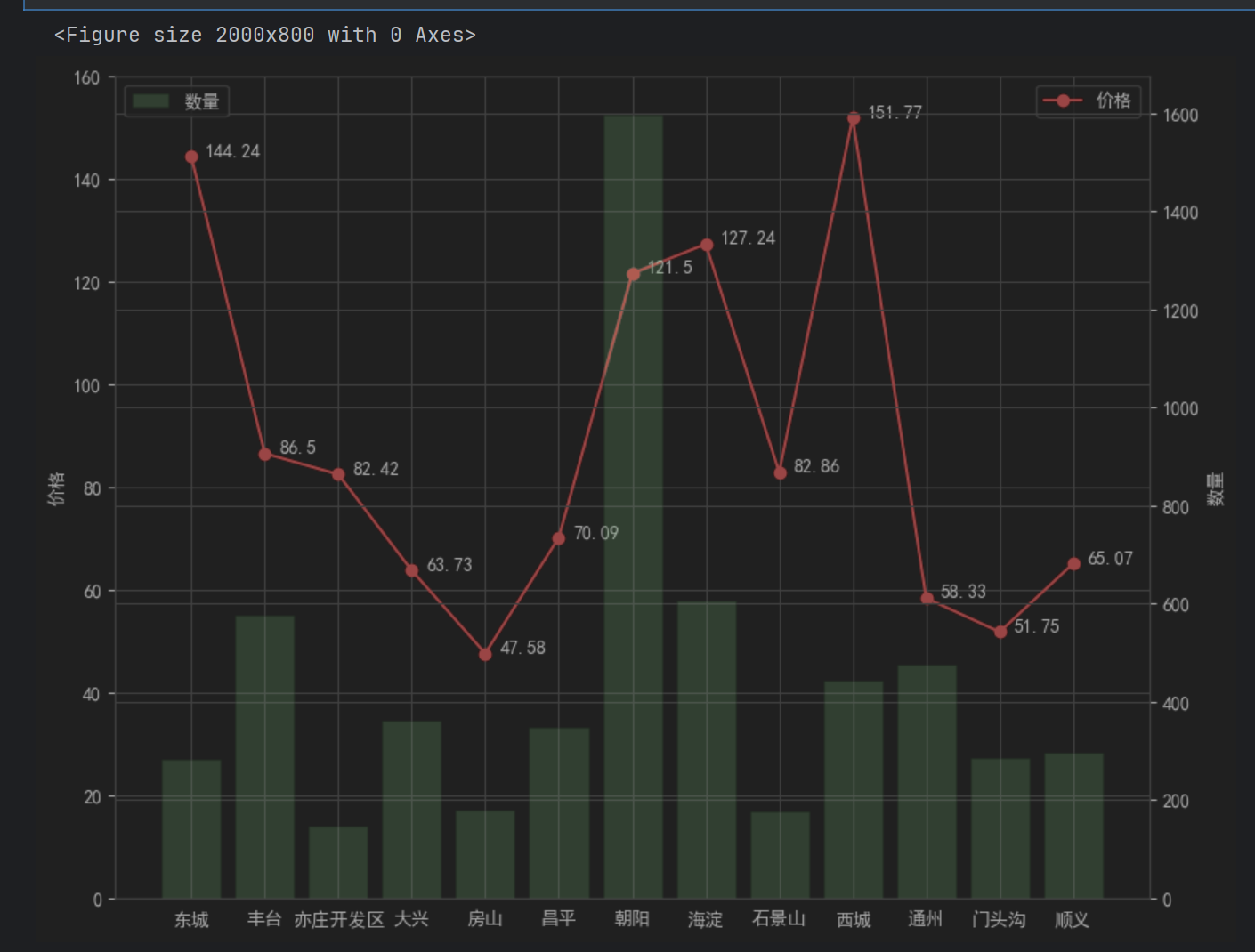
ax2 = ax1.twinx()
plt.bar(l,num,label="数量",alpha=0.2,color="green")
ax2.set_ylabel("数量")
plt.legend(loc="upper left")
plt.xticks(l,lx)plt.show()
4.6 面积区间分析
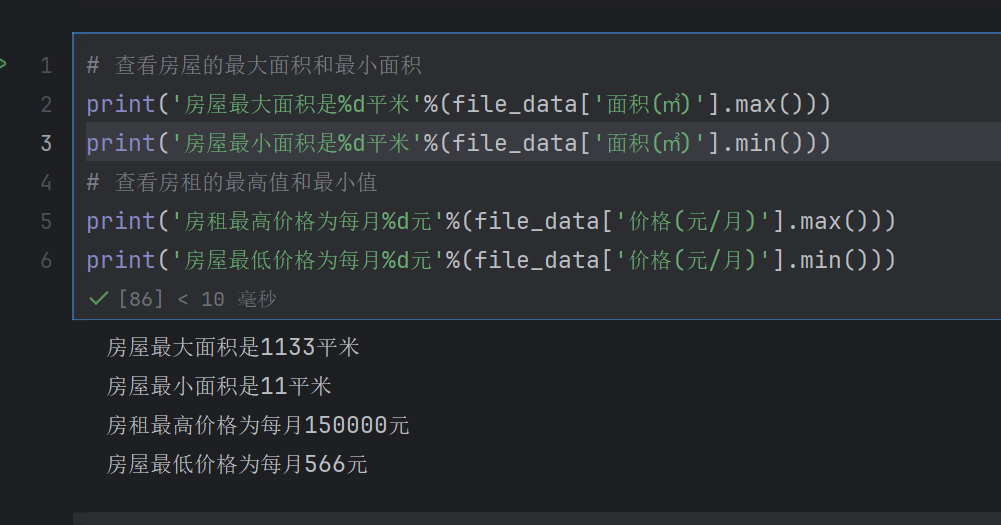
# 查看房屋的最大面积和最小面积
print('房屋最大面积是%d平米'%(file_data['面积(㎡)'].max()))
print('房屋最小面积是%d平米'%(file_data['面积(㎡)'].min()))
# 查看房租的最高值和最小值
print('房租最高价格为每月%d元'%(file_data['价格(元/月)'].max()))
print('房屋最低价格为每月%d元'%(file_data['价格(元/月)'].min()))
# 面积划分
area_divide = [1, 30, 50, 70, 90, 120, 140, 160, 1200]
area_cut = pd.cut(file_data["面积(㎡)"],area_divide)
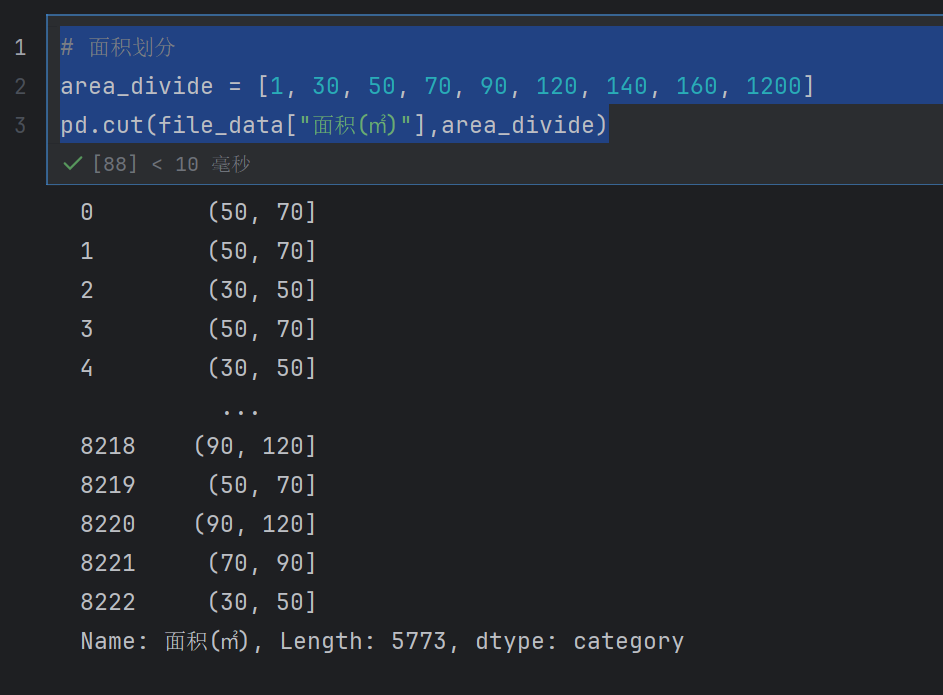
表示的就是每一行属于哪一个区间
# 面积划分
area_divide = [1, 30, 50, 70, 90, 120, 140, 160, 1200]
area_cut = pd.cut(list(file_data["面积(㎡)"]),area_divide)
area_cut
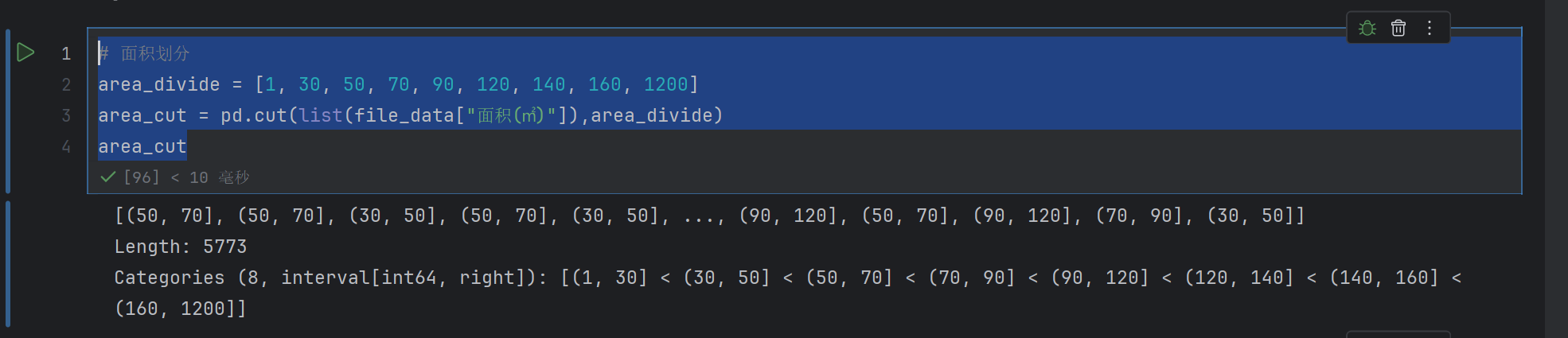
这个是对list进行划分
list() 的作用是 “将 pandas 数据列转为纯 Python 列表”
area_cut_num = area_cut.describe()
area_cut_num
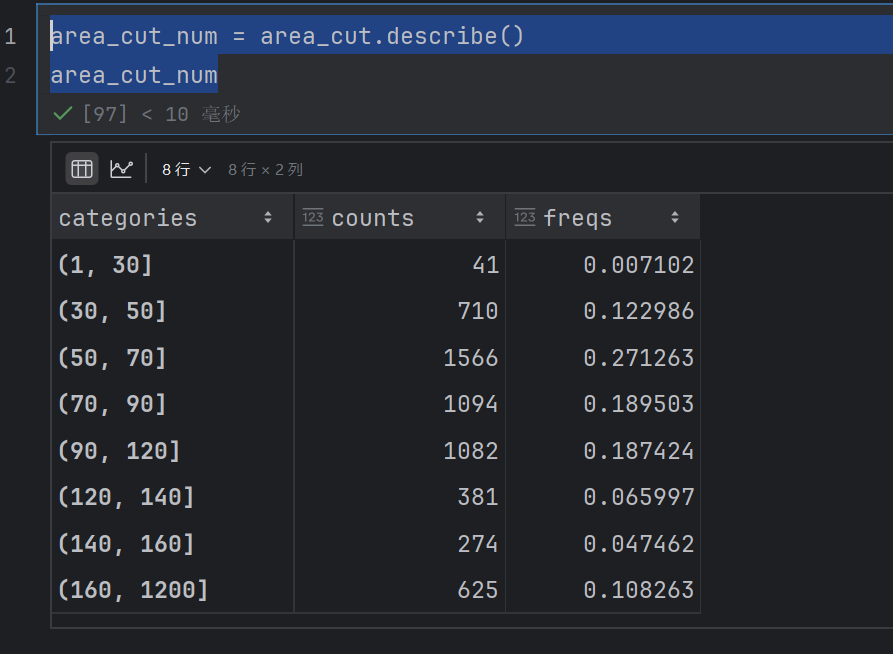
freqs就是百分比
接下来就是图像展示了
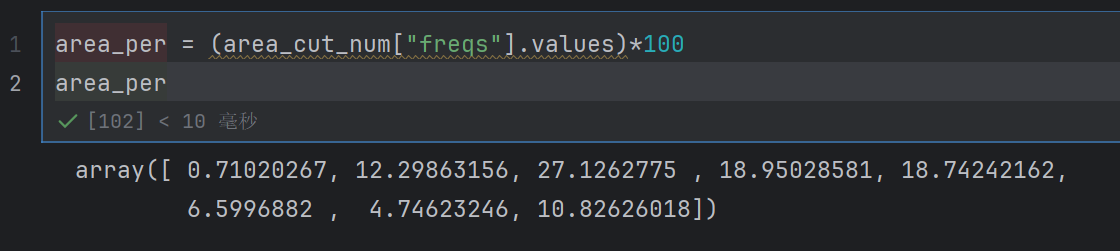
area_per = (area_cut_num["freqs"].values)*100
area_per
labels = ['30平米以下', '30-50平米', '50-70平米', '70-90平米',
'90-120平米','120-140平米','140-160平米','160平米以上']
plt.figure(figsize=(20, 8), dpi=100)
plt.axes()
plt.pie(x=area_per)
plt.show()
plt.axes() 可以接收一个列表 [left, bottom, width, height](取值范围 0-1,相对于画布的比例),手动指定坐标轴在画布上的位置和尺寸。
labels = ['30平米以下', '30-50平米', '50-70平米', '70-90平米',
'90-120平米','120-140平米','140-160平米','160平米以上']
plt.figure(figsize=(20, 8), dpi=100)
plt.axes()
plt.pie(x=area_per,labels=labels)
plt.legend()
plt.show()
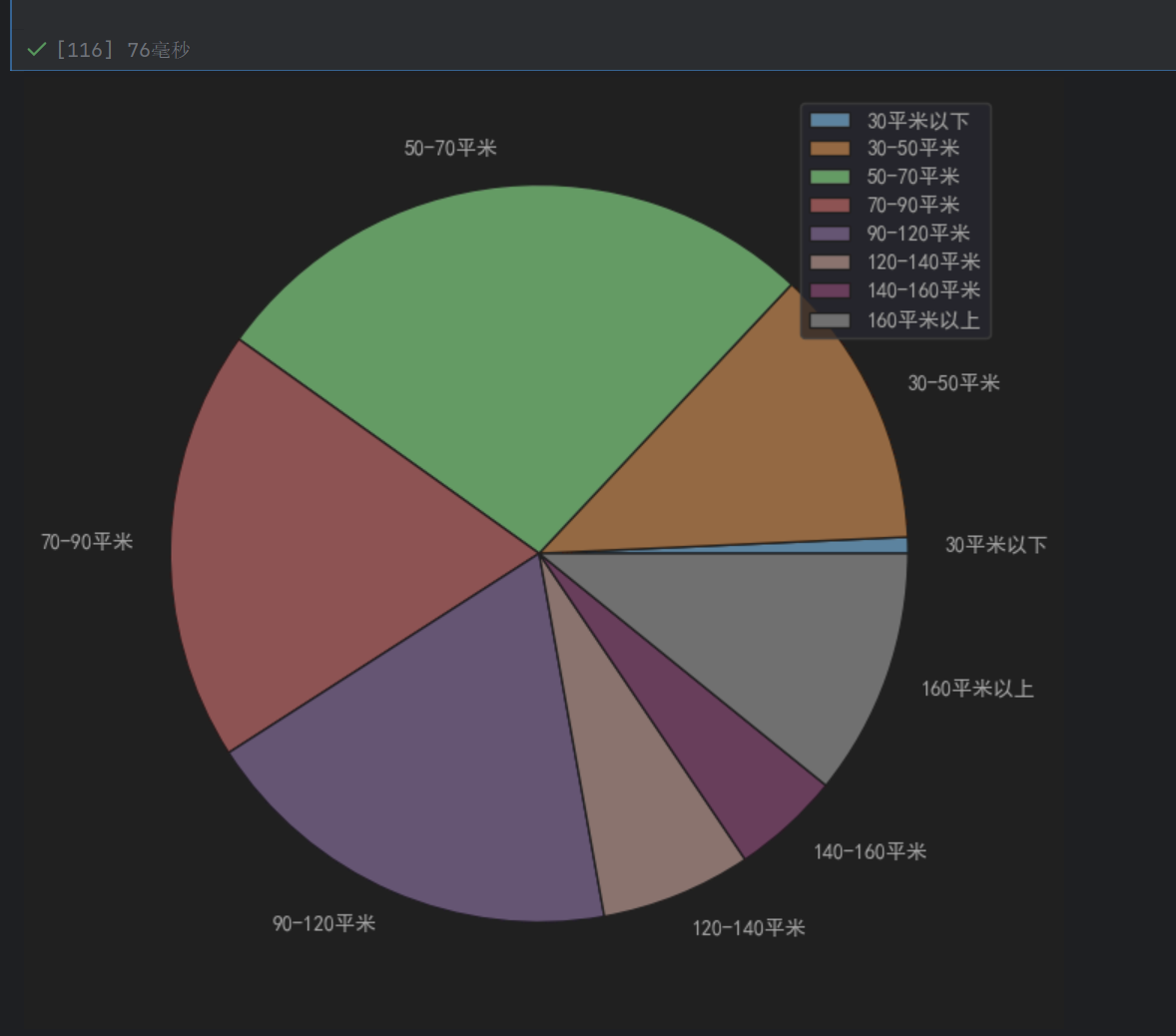
legend显示的是右上角的labels,至于每个饼上面的显示是labels自带的显示
labels = ['30平米以下', '30-50平米', '50-70平米', '70-90平米',
'90-120平米','120-140平米','140-160平米','160平米以上']
plt.figure(figsize=(20, 8), dpi=100)
plt.axes()
plt.pie(x=area_per,labels=labels,autopct='%.2f%%')
plt.legend()
plt.show()
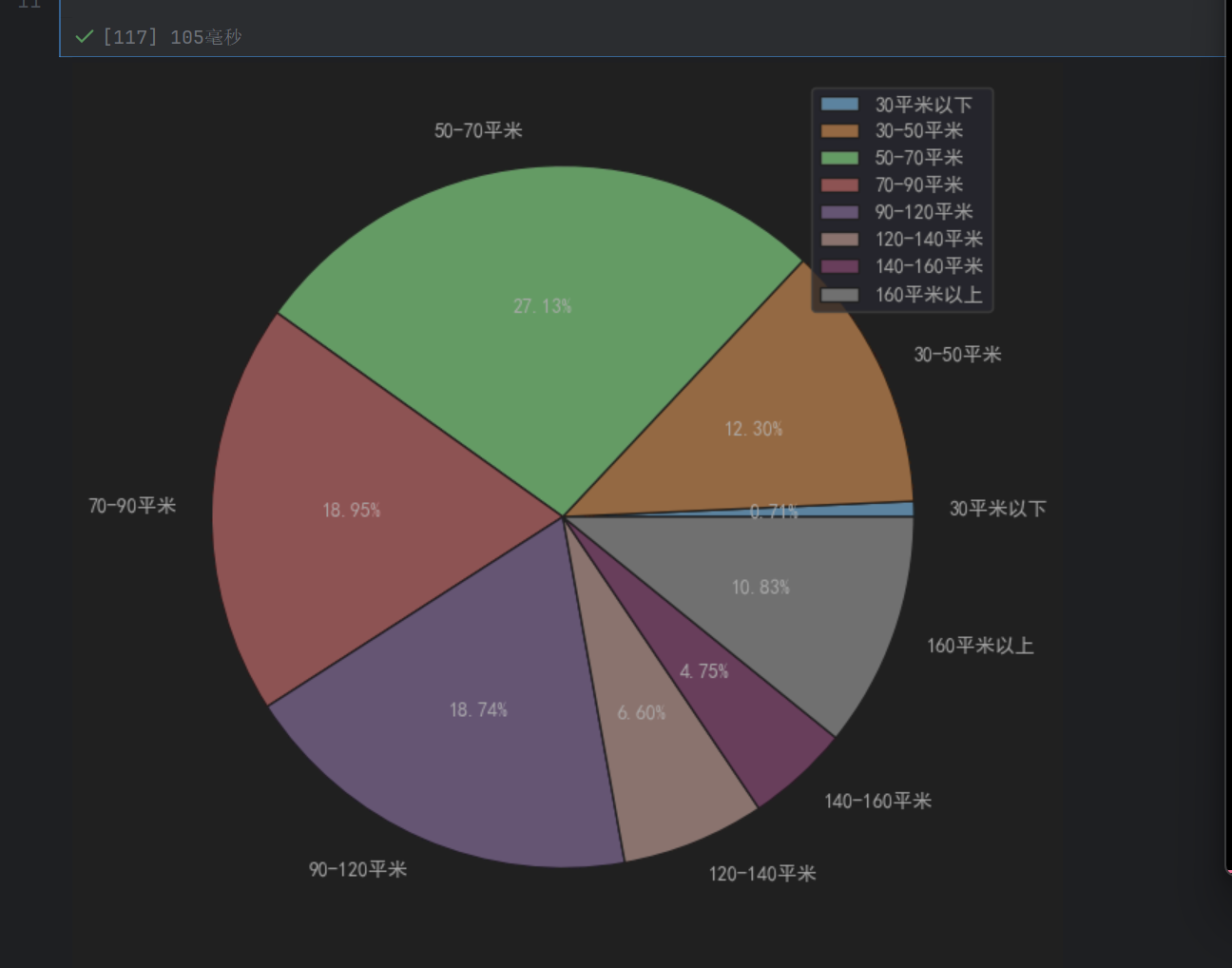
plt.axes(aspect=1) 是 Matplotlib 中用于创建或配置坐标轴区域,并强制设置其纵横比(宽高比)为 1:1 的代码。
labels = ['30平米以下', '30-50平米', '50-70平米', '70-90平米',
'90-120平米','120-140平米','140-160平米','160平米以上']
plt.figure(figsize=(20, 8), dpi=100)
plt.axes(aspect=1)
plt.pie(x=area_per,labels=labels,autopct='%.2f%%')
plt.legend()
plt.show()
但是默认就是1:1的,所以没什么区别,所以这个没用,默认就是圆