CV论文速递 | 13篇前沿论文精选:生成与处理、3D视觉、医学影像等核心方向(09.08-09.12)
本周精选 13篇CV领域前沿论文,覆盖视频生成与处理、图像生成与编辑、3D 视觉、医学影像、VLM、目标检测与分割等核心方向。原文、源码都已经整理好,感兴趣的自取~
论文这里

一、视频生成与处理
1. SpatialVID: A Large-Scale Video Dataset with Spatial Annotations**
-
作者:Jiahao Wang, Yufeng Yuan, Rujie Zheng, et al.
-
亮点:针对现有动态场景数据集缺乏精确相机运动真值、规模有限且多样性不足的问题,构建了包含大规模真实世界动态场景的视频数据集。数据集不仅提供像素级空间标注,还包含精确的相机内外参和运动轨迹,支持空间重建、视觉定位等任务的细粒度评估。通过多源数据融合(如多视角同步拍摄、激光雷达辅助标定),解决了动态目标遮挡下的标注歧义问题,为空间智能算法提供了更贴近实际应用的训练基准。

-
论文:http://arxiv.org/abs/2509.09676v1
-
开源代码:https://nju-3dv.github.io/projects/SpatialVID
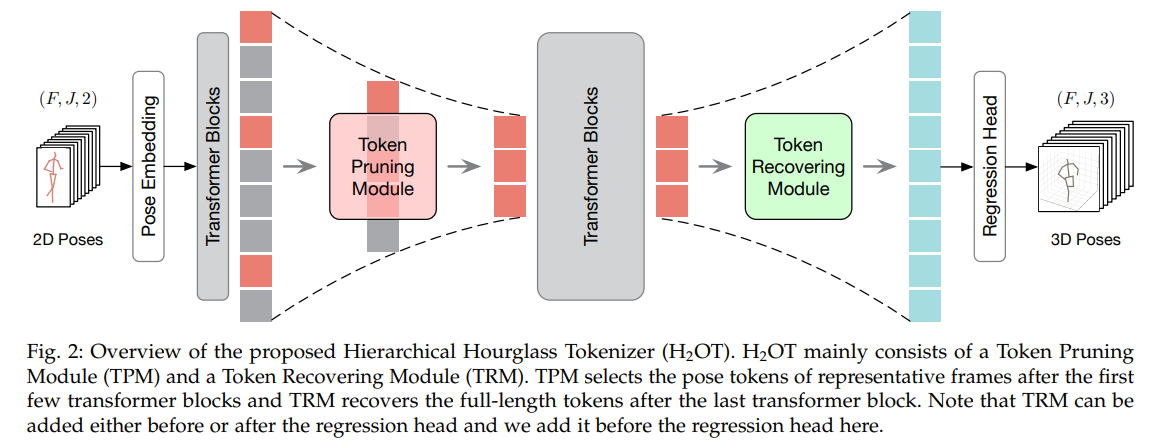
2. HU₂OT: Hierarchical Hourglass Tokenizer for Efficient Video Pose Transformers
-
作者:Wenhao Li, Mengyuan Liu, Hong Liu, et al.
-
亮点:针对视频姿态Transformer计算成本过高、难以部署在边缘设备的问题,提出分层沙漏令牌化框架。通过“修剪-恢复”机制,先逐步减少冗余姿态令牌(如静态背景区域),再在高优先级区域(如关节点附近)恢复细节令牌,实现精度与效率的平衡。
-
论文:http://arxiv.org/abs/2509.06956v1
-
开源代码:https://github.com/NationalGAILab/HoT
二、图像生成与编辑
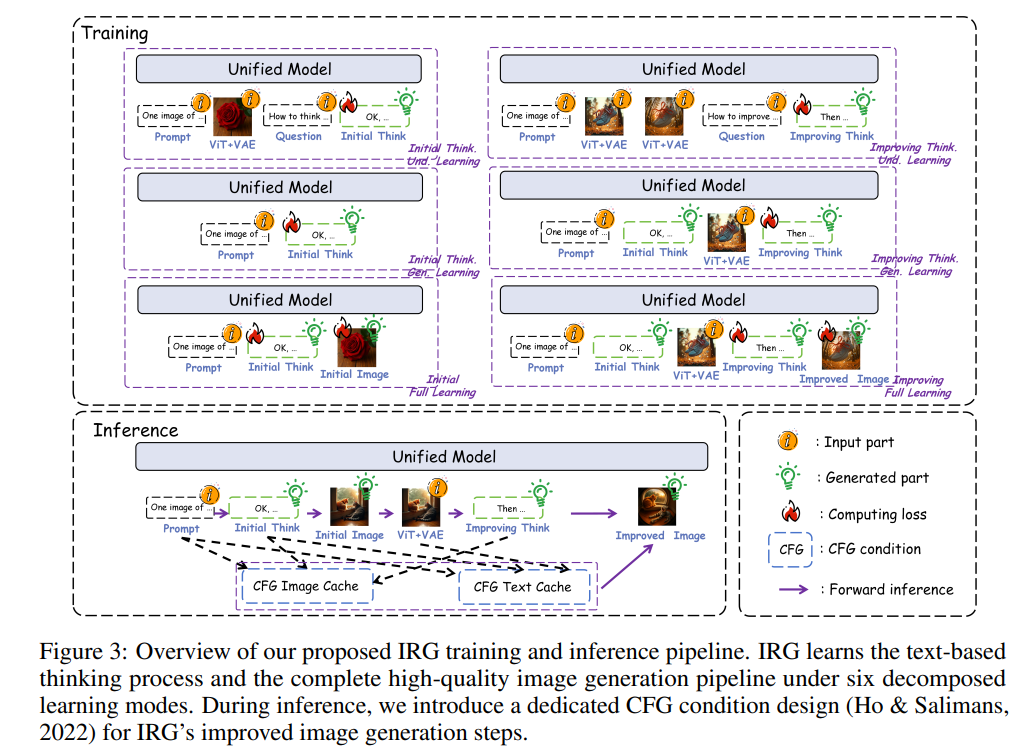
3. Interleaving Reasoning for Better Text-to-Image Generation
-
作者:Wenxuan Huang, Shuang Chen, Zheyong Xie, et al.
-
亮点:研究提出“交错推理生成”(Interleaving Reasoning Generation,IRG)框架,该框架在基于文本的思考与图像合成之间交替进行:模型先生成一段文本思考以指导初步图像生成,随后对生成结果进行反思,在保持语义的基础上进一步优化细节、视觉质量和审美效果。为有效训练IRG,研究进一步提出“交错推理生成学习”(Interleaving Reasoning Generation Learning,IRGL),其目标包含两个子任务:(1)强化初始的“思考-生成”阶段,以建立核心内容和基础质量;(2)实现高质量的文本反思,并在后续图像中忠实执行这些优化。
-
论文:http://arxiv.org/abs/2509.06945v2
-
开源代码:https://github.com/Osilly/Interleaving-Reasoning-Generation
4. TIDE: Achieving Balanced Subject-Driven Image Generation via Target-Instructed Diffusion Enhancement
-
作者:Jibai Lin, Bo Ma, Yating Yang, et al.
-
亮点:本文提出了一种名为“目标指令扩散增强”(TIDE)的框架,通过目标监督和偏好学习,在无需测试时微调的前提下有效缓解这一矛盾。TIDE首次引入了目标监督的三元组对齐机制,利用(参考图像、指令、目标图像)三元组来建模主体适应过程。该方法基于“直接主体扩散”(DSD)目标,通过成对的“优质”(保持与编辑平衡)和“劣质”(失真)目标进行训练,这些目标通过量化指标系统生成和评估,从而实现隐式的奖励建模以达到最佳的保持与编辑平衡。

-
论文:http://arxiv.org/abs/2509.06499v1
-
开源代码:https://github.com/KomJay520/TIDE
三、3D视觉与重建
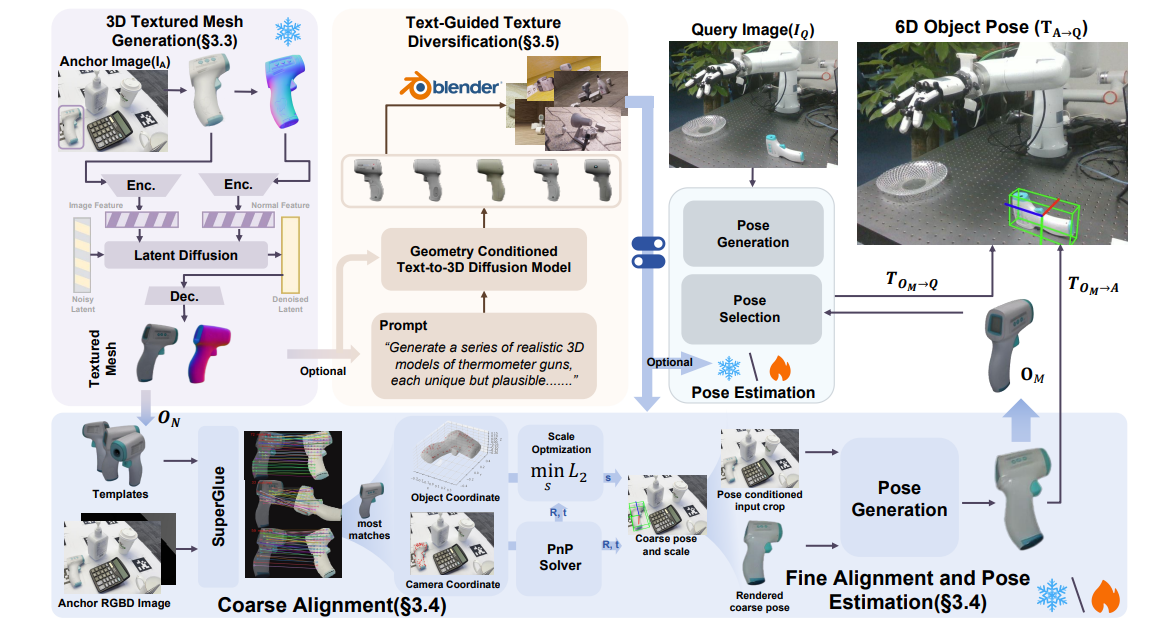
5. One View, Many Worlds: Single-Image to 3D Object Meets Generative Domain Randomization for One-Shot 6D Pose Estimation
-
作者:Zheng Geng, Nan Wang, Shaocong Xu, et al.
-
亮点:提出了OnePoseViaGen,这一流程通过两个关键组件应对上述挑战。首先,一个由粗到精的对齐模块通过结合多视角特征匹配与渲染比对优化,联合优化尺度与姿态;其次,一种文本引导的生成式域随机化策略对纹理进行多样化处理,从而利用合成数据有效微调姿态估计器。通过以上步骤,使得高质量的单视角3D生成能够支持可靠的一次性6D姿态估计。在多个具有挑战性的基准测试(YCBInEOAT、Toyota-Light、LM-O)中,OnePoseViaGen实现了最先进的性能,远超以往方法。
-
论文:http://arxiv.org/abs/2509.07978v1
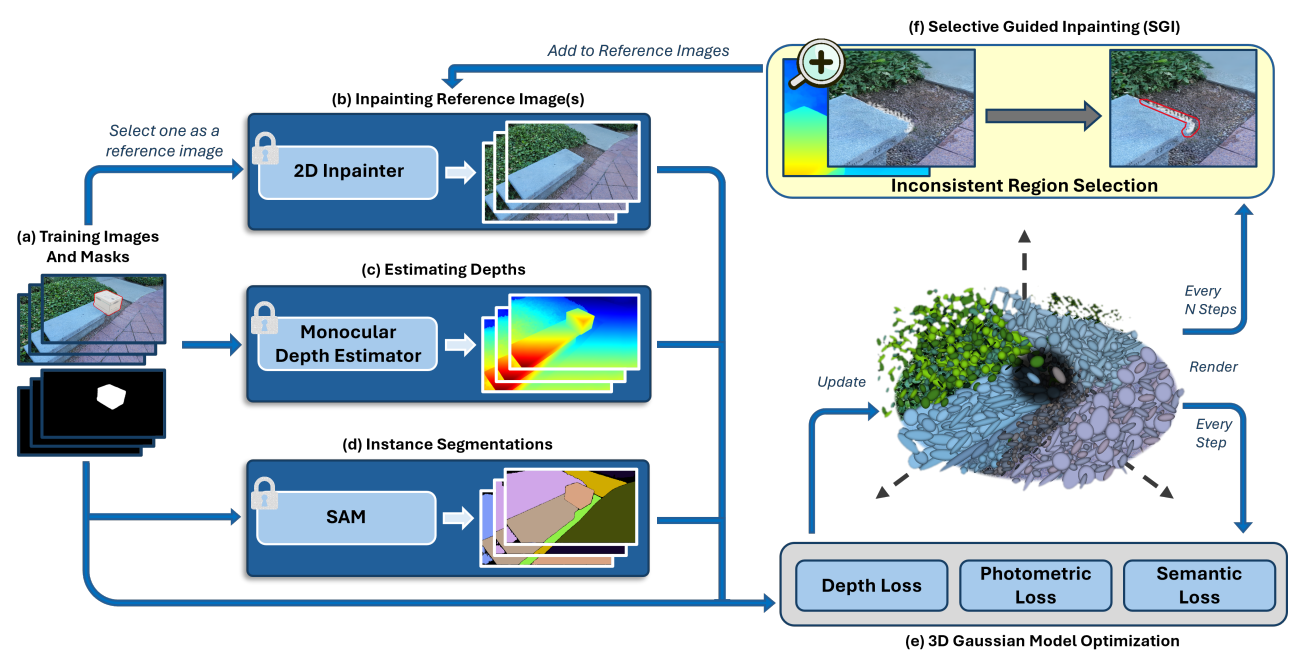
6. SplatFill: 3D Scene Inpainting via Depth-Guided Gaussian Splatting
- 作者:Mahtab Dahaghin, Milind G. Padalkar, Matteo Toso, Alessio Del Bue
- 亮点:突破传统3D场景补绘中几何不一致、细节模糊的瓶颈,基于深度引导的高斯溅射技术,实现遮挡区域的高质量恢复。通过深度图约束高斯分布的空间位置(如前景物体后方的墙面需与深度趋势一致),并引入“多视角一致性损失”确保补绘区域在任意视角下的渲染真实性。
- 论文:http://arxiv.org/abs/2509.07809v1
四、医学影像分析
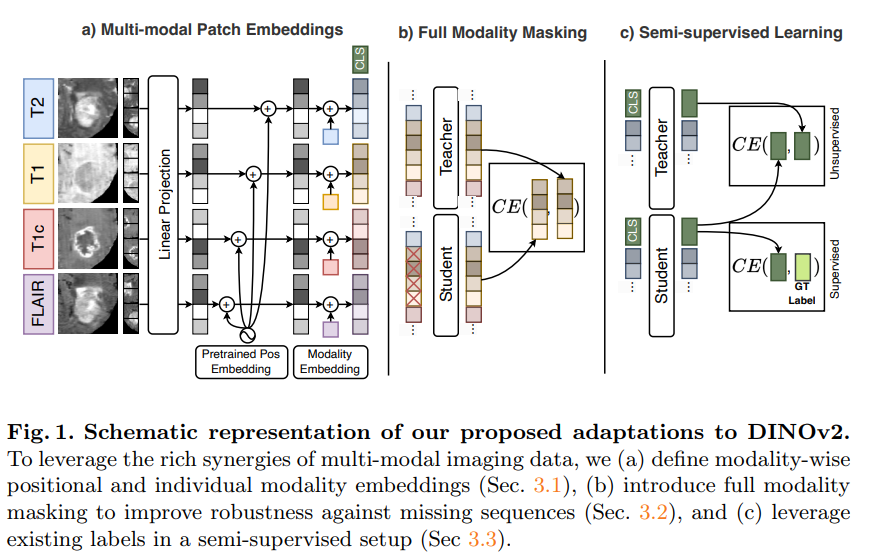
7. MM-DINOv2: Adapting Foundation Models for Multi-Modal Medical Image Analysis
-
作者:Daniel Scholz, Ayhan Can Erdur, Viktoria Ehm, et al.
-
亮点:研究提出 MM-DINOv2 框架,通过多模态图像块嵌入适配 DINOv2 处理多模态数据,采用全模态掩码策略应对模态缺失,结合半监督学习利用未标注数据。在多序列脑部 MRI 胶质瘤亚型分类中,该方法在外部测试集马修斯相关系数达 0.6,超越当前最优有监督方法 11.1%,为多模态医学成像提供了可扩展且稳健的解决方案,兼顾自然图像预训练模型优势与临床数据挑战。
-
论文:http://arxiv.org/abs/2509.06617v1
-
开源代码:https://github.com/daniel-scholz/mm-dinov2
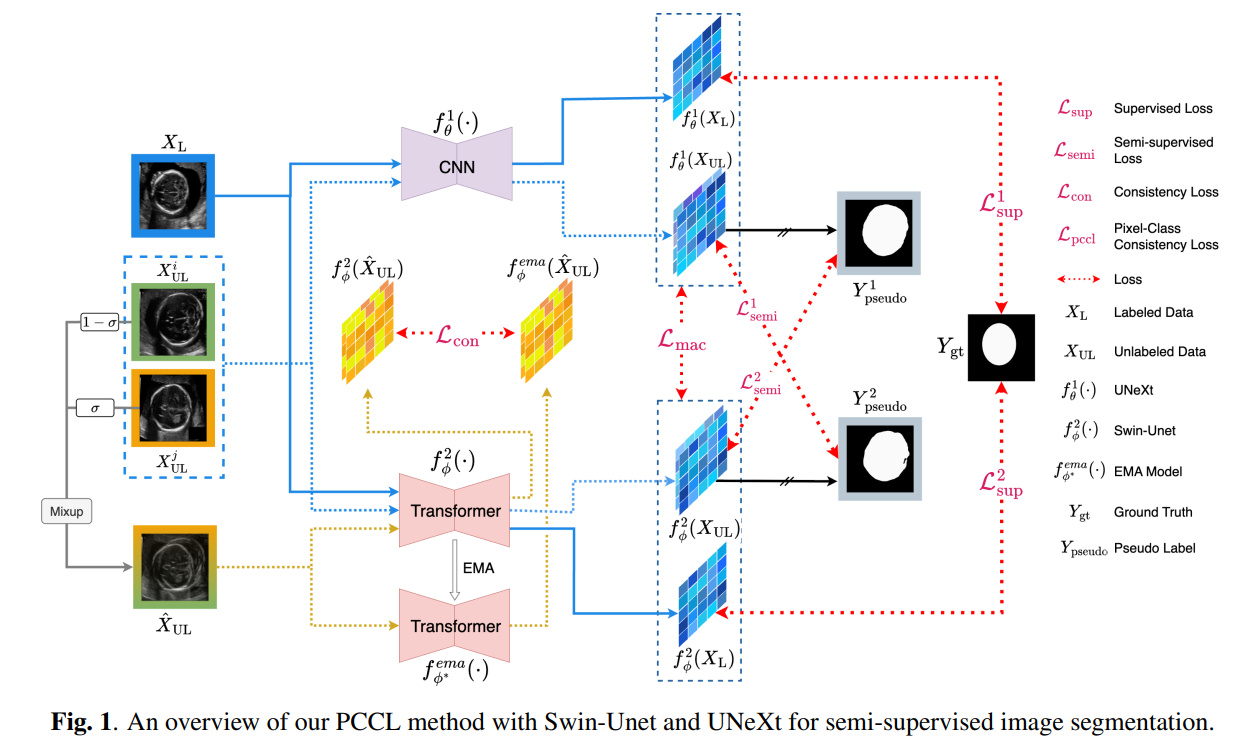
8. Leveraging Information Divergence for Robust Semi-Supervised Fetal Ultrasound Image Segmentation
-
作者:Fangyijie Wang, Guénolé Silvestre, Kathleen M. Curran
-
亮点:视觉基础模型(如 DINOv2)在医学成像中显潜力,但因适用于单模态分析,在多模态医学任务中受限,且有监督模型难以利用未标注数据、应对模态缺失。研究提出 MM-DINOv2 框架,通过多模态图像块嵌入适配 DINOv2 处理多模态数据,以全模态掩码策略应对模态缺失,结合半监督学习利用未标注数据。在多序列脑部 MRI 胶质瘤亚型分类中,其外部测试集马修斯相关系数达 0.6,超越当前最优有监督方法 11.1%,为多模态医学成像提供了兼顾自然图像预训练模型优势与临床数据挑战的可扩展稳健方案。
-
论文:http://arxiv.org/abs/2509.06495v1
五、视觉-语言模型(VLM)
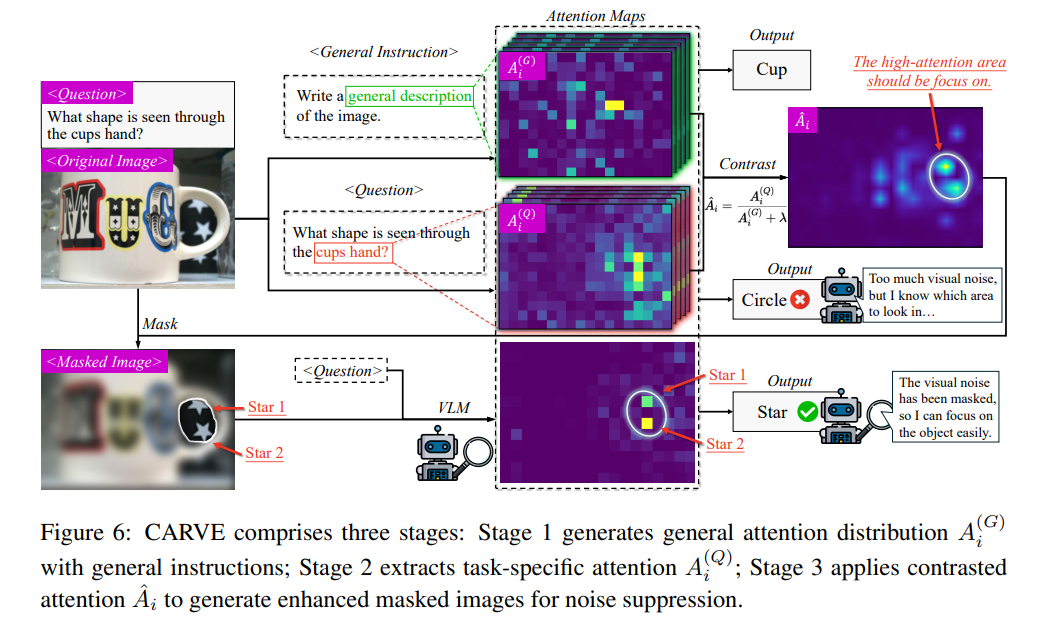
9. Focusing by Contrastive Attention: Enhancing VLMs’ Visual Reasoning
- 作者:Yuyao Ge, Shenghua Liu, Yiwei Wang, et al.
- 亮点:揭示现有VLMs在复杂场景中注意力分散的问题(如“找出戴红帽的小孩”时错误关注红色气球),提出对比注意力机制。通过正负样本对训练(如正确标注与错误标注的注意力图对比),强化模型对关键视觉元素的聚焦能力;发现“视觉复杂度-注意力熵”负相关规律,动态调整注意力温度参数,在视觉问答(VQA)任务中准确率提升。
- 论文:http://arxiv.org/abs/2509.06461v2
-
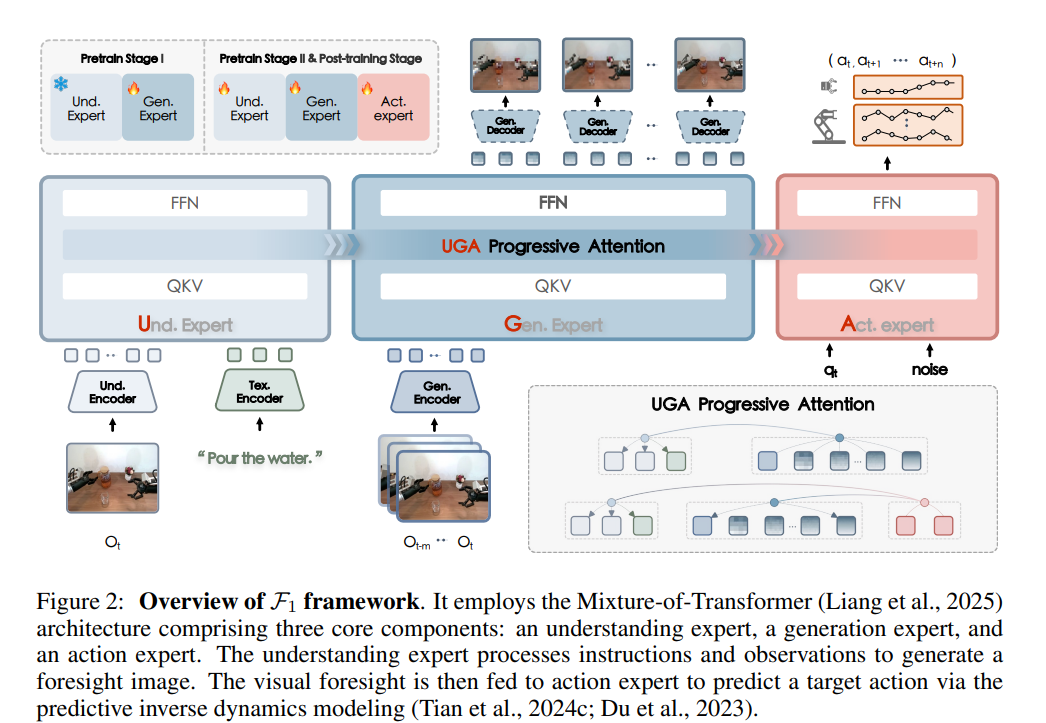
F1: A Vision-Language-Action Model Bridging Understanding and Generation to Actions
- 作者:Qi Lv, Weijie Kong, Hao Li, et al.
- 亮点:在动态视觉环境中执行语言条件任务是具身人工智能的核心挑战,现有视觉-语言-动作(VLA)模型因采用反应式状态到动作映射,易出现短视行为且动态场景鲁棒性差。为此提出的预训练VLA框架F1,通过混合Transformer架构整合感知、预见生成和控制模块,以“下一阶段预测”机制合成目标条件的视觉预见作为规划目标,将动作生成转化为预见引导的逆动力学问题;借助含136种任务、超33万条轨迹数据集上的三阶段训练,F1强化了模块化推理与可迁移视觉预见能力,在真实世界和仿真任务中,其成功率与泛化能力均显著优于现有方法。
- 论文:http://arxiv.org/abs/2509.06951v2
- 开源代码:https://github.com/InternRobotics/F1-VLA
六、目标检测与分割
-
InsFusion: Rethink Instance-level LiDAR-Camera Fusion for 3D Object Detection
- 作者:Zhongyu Xia, Hansong Yang, Yongtao Wang
- 亮点:多视角相机和激光雷达的三维目标检测是自动驾驶和智能交通系统中的关键组成部分。然而,在基础特征提取、视角变换和特征融合的过程中,噪声和误差会逐渐累积。为了解决这一问题,作者提出了InsFusion,该方法可以从原始特征和融合特征中提取候选区域,并利用这些候选区域去查询原始特征,从而减轻累积误差的影响。此外,通过在原始特征上引入注意力机制,进一步降低了误差累积带来的负面影响。在nuScenes数据集上的实验表明,InsFusion可以与多种先进的基线方法兼容,并在三维目标检测任务中实现了新的性能突破。
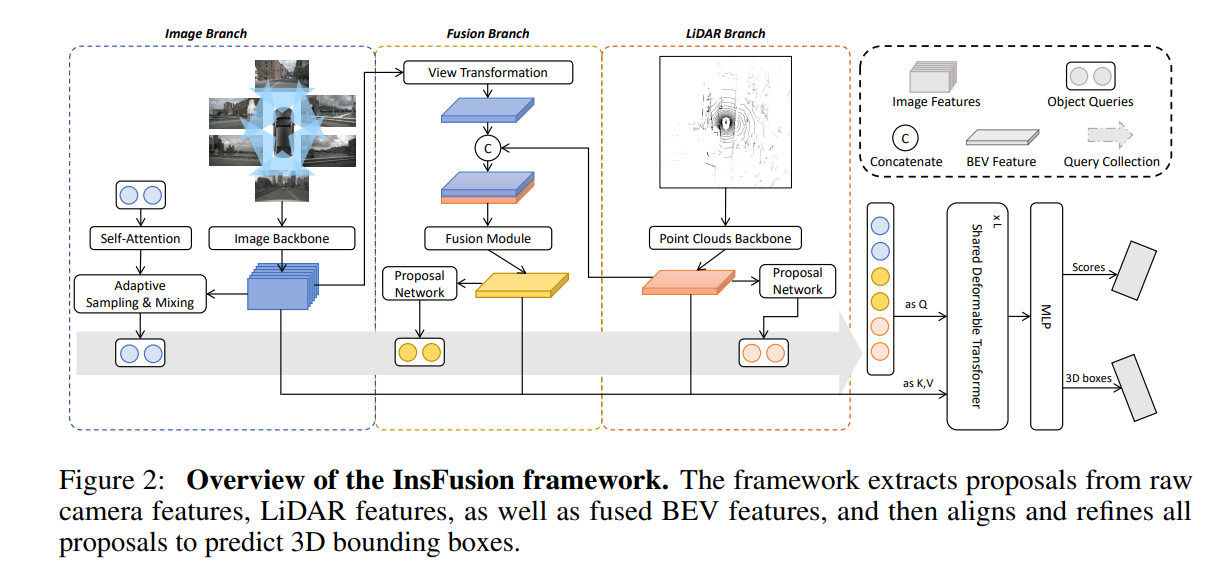
- 论文:http://arxiv.org/abs/2509.08374v1
-
BioLite U-Net: Edge-Deployable Semantic Segmentation for In Situ Bioprinting Monitoring
-
作者:Usman Haider, Lukasz Szemet, Daniel Kelly, et al.
-
亮点:针对生物打印实时监控的算力限制,设计轻量级U-Net变体。通过“多分支特征增强”模块,分别处理噪声抑制、边缘检测和对比度提升,在保留关键细节(如生物墨水挤出状态)的同时降低计算量;模型体积仅2.3MB,在嵌入式设备上实现20fps的实时分割,对生物打印过程中“喷嘴堵塞”“墨水飞溅”等异常的识别准确率达92%,为自动化生物制造提供核心技术支持。
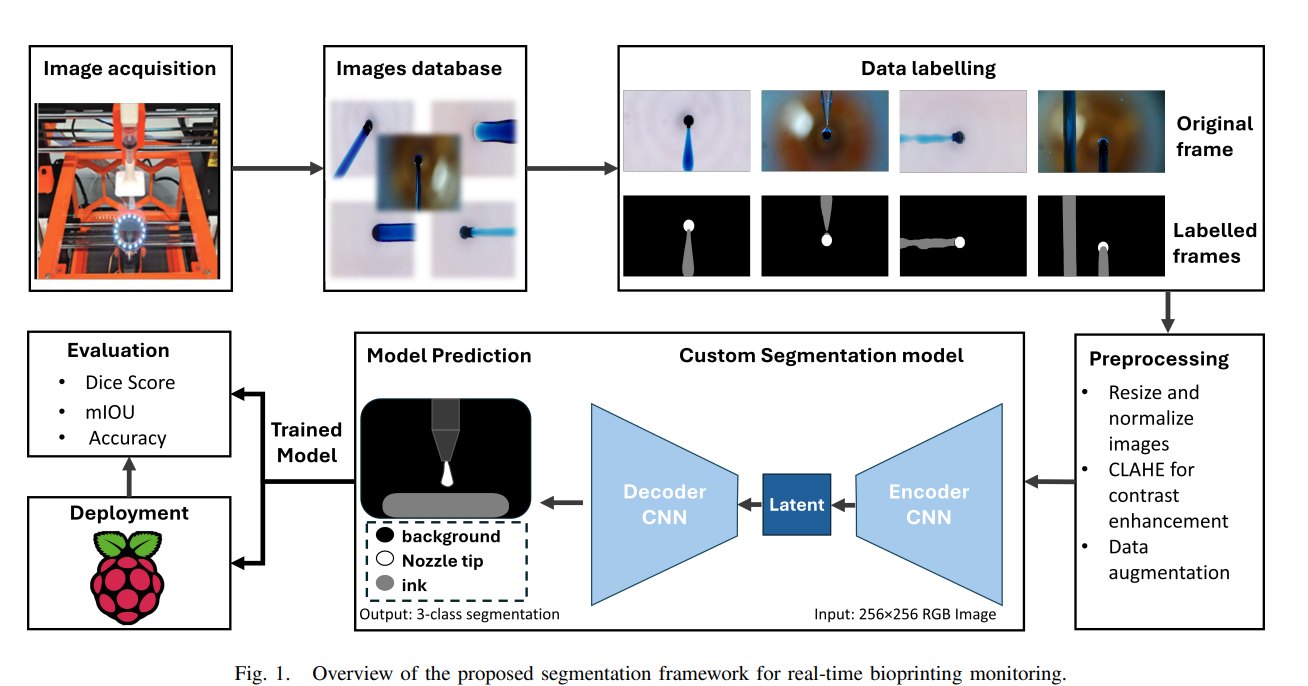
-
论文:http://arxiv.org/abs/2509.06690v1
-
七、视觉表示与低级别视觉
- BIR-Adapter: A Low-Complexity Diffusion Model Adapter for Blind Image Restoration
-
作者:Cem Eteke, Alexander Griessel, Wolfgang Kellerer, Eckehard Steinbach
-
亮点:本文提出面向扩散模型的低复杂度盲图像复原适配器BIR-Adapter,无需训练辅助特征提取器,即可利用预训练大规模扩散模型先验信息实现盲图像复原。其借助预训练模型鲁棒性,从退化图像提取特征并扩展自注意力机制,还引入采样引导机制减少幻觉。实验表明,该适配器在合成及真实退化数据上性能与当前最优方法相当甚至更优,且复杂度更低;基于适配器的设计使其能集成到其他扩散模型,应用潜力广泛,如将仅支持超分辨率的模型扩展为可更好应对未知附加退化的情形。
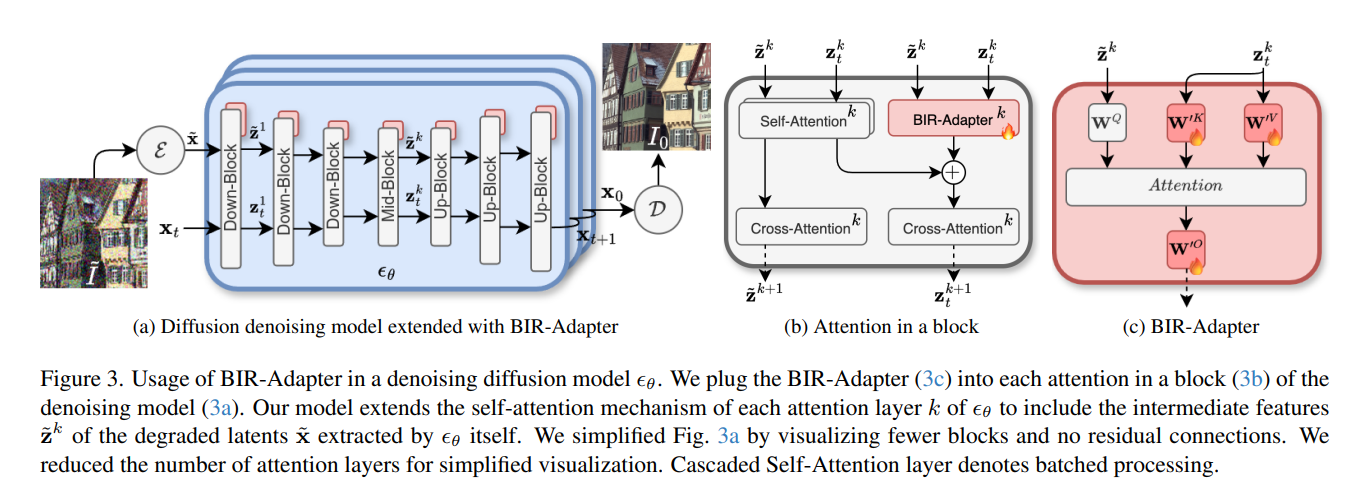
-
论文:http://arxiv.org/abs/2509.06904v1
-