深度学习(八):学习率
在深度学习训练中,学习率(Learning Rate, LR)是最关键的超参数之一,它决定了模型参数更新的步长大小,从而直接影响训练的速度和收敛质量。学习率设置得合适,可以让模型快速收敛到全局或局部最优;学习率过大,则可能导致训练不稳定甚至发散;学习率过小,则训练收敛过慢,容易陷入局部最优。
学习率的定义
在梯度下降(Gradient Descent)或其变种优化器中,学习率控制模型参数 θ 的更新幅度:
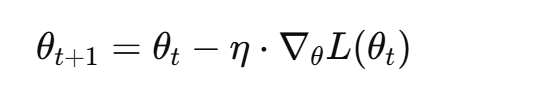
其中:
- θ 为第 t 次迭代的参数;
- η 为学习率;
- ∇θL(θt) 为损失函数关于参数的梯度。
简单理解:
- 学习率越大:每次更新幅度大,训练快速但可能震荡或发散;
- 学习率越小:每次更新幅度小,训练稳定但收敛慢。
学习率的重要性
学习率对训练过程的影响主要体现在以下几个方面:
- 收敛速度
- 高学习率可以快速接近最优,但过大可能跳过最优点。
- 低学习率训练稳定,但需要更多迭代次数。
- 训练稳定性
- 学习率过大时,梯度更新过强,会导致损失震荡甚至 NaN。
- 学习率过小可能导致参数更新缓慢,训练停滞。
- 模型泛化能力
- 适当的学习率和衰减策略可以让模型找到“平坦最优”,提升泛化。
- 学习率过高容易让模型在训练集上震荡,难以泛化。
学习率的类型
固定学习率
最简单的策略,整个训练过程中使用一个固定值。优点是简单,但缺点明显:
- 训练初期可能太慢;
- 后期可能无法收敛到最优解。
学习率衰减
随着训练进行,逐渐减小学习率,提高训练稳定性。常用方法:
-
阶梯衰减(Step Decay)
每隔固定步数或 epoch,将学习率降低一个比例: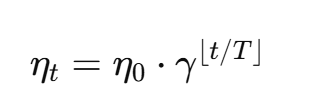
其中 γ<1 为衰减系数,T 为衰减间隔。
-
指数衰减(Exponential Decay)
学习率按指数函数衰减: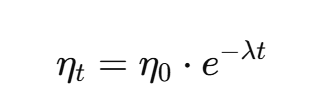
λ 为衰减速率,衰减平滑。
-
余弦衰减(Cosine Annealing)
先大后小,呈余弦曲线变化: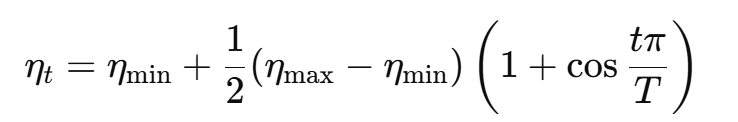
-
学习率热重启(SGDR, Cosine Annealing with Restarts)
定期将学习率重置到较高值,模拟多次训练轮次,提高逃脱局部最优能力。
自适应学习率
一些优化器会根据梯度自动调整每个参数的学习率:
- AdaGrad:对稀疏梯度有效,历史梯度平方和增加,学习率逐渐减小。
- RMSProp:在 AdaGrad 基础上增加指数加权平均,适合非平稳目标。
- Adam/AdamW:结合动量和 RMSProp,训练效果稳定,常用默认学习率 0.001。
- AdaBound、Ranger:进一步改进自适应优化器,兼顾收敛速度和泛化。
学习率调节技巧
学习率预热(Warm-up)
- 训练初期使用较小学习率,逐渐升至目标值。
- 避免初始化梯度过大导致训练不稳定。
- 常用于大规模模型(如 Transformer、BERT)训练。
循环学习率(Cyclic LR)
- 在一定区间内周期性调整学习率:
- 上升阶段快速探索;
- 下降阶段收敛。
- 有助于逃离局部最优。
自动学习率搜索
- 使用工具自动调整最优初始学习率:
- LR range test(Leslie Smith 方法):线性增加学习率,观察 loss 曲线选择最佳。
- 调度器 + 回调:训练过程中自动降低学习率,例如 Keras 的
ReduceLROnPlateau。
实际经验与建议
- 初始值选择
- SGD 常用 0.01~0.1;
- Adam 常用 0.001;
- 大模型通常需要学习率预热。
- 衰减策略
- 对大多数任务,采用阶梯或余弦衰减效果较好。
- 小数据集或精调任务,可考虑指数衰减。
- 观察指标
- 训练损失:学习率过大时损失震荡;
- 验证损失:监控泛化,避免过早降低学习率。
- 自适应优化器
- Adam/AdamW 初学者推荐,可节省调参时间。
- SGD + Momentum 对大规模训练和泛化能力更优,但需要调参。
- 批量大小与学习率关系
- 大批量训练通常需要更大学习率;
- 可使用 线性缩放法则:
总结
- 学习率是深度学习中最关键的超参数之一,决定训练速度和稳定性。
- 常用策略:固定、衰减(阶梯、指数、余弦)、自适应、循环和预热。
- 调节学习率需要结合优化器、数据集大小和模型复杂度。
- 实际训练中,通常使用预热 + 衰减 + 自适应优化器的组合,既保证收敛速度,又能提升泛化能力。
- 通过观察损失曲线和验证指标,可以动态调整学习率,实现高效训练。