构建日志采集和分析平台
Flume环境搭建
操作步骤:
-
下载安装包:
- 访问地址 http://archive.apache.org/dist/flume/
- 找到稳定版本(如
1.8.0)的目录,下载apache-flume-1.8.0-bin.tar.gz文件。
-
上传安装包:
- 使用
scp、FTP 工具或任何其他方式,将下载好的apache-flume-1.8.0-bin.tar.gz文件上传到服务器hadoop01的/home/hadoop/app目录下。
- 使用
-
登录服务器并解压:
- 使用 SSH 登录到
hadoop01节点。 - 执行以下命令:
- 使用 SSH 登录到
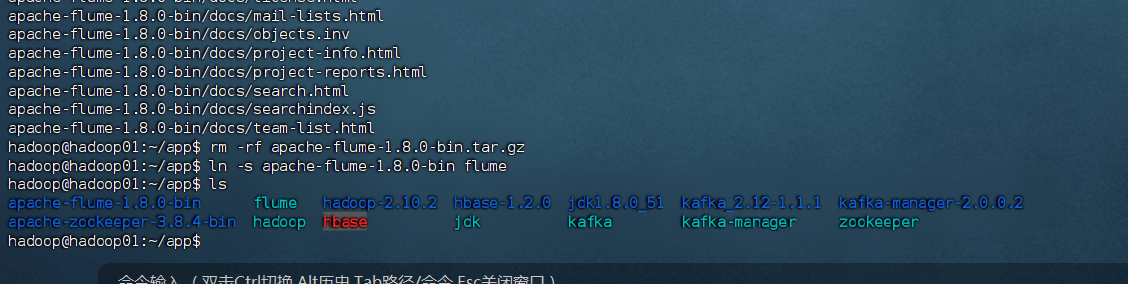
# 1. 切换到目标目录
[hadoop@hadoop01 ~]$ cd /home/hadoop/app# 2. 查看目录内容,确认安装包已上传
[hadoop@hadoop01 app]$ ls
apache-flume-1.8.0-bin.tar.gz# 3. 解压安装包
[hadoop@hadoop01 app]$ tar -zxvf apache-flume-1.8.0-bin.tar.gz# 4. (可选) 解压后删除压缩包以节省空间
[hadoop@hadoop01 app]$ rm -rf apache-flume-1.8.0-bin.tar.gz# 5. 创建一个软链接,方便以后使用和配置,避免路径因版本号而改变
[hadoop@hadoop01 app]$ ln -s apache-flume-1.8.0-bin flume# 6. 最终查看目录,确认解压和软链接创建成功
[hadoop@hadoop01 app]$ ls
apache-flume-1.8.0-bin flume
2. 修改 Flume 配置文件
操作步骤:
- 进入配置目录并准备配置文件:
[hadoop@hadoop01 app]$ cd flume/conf
[hadoop@hadoop01 conf]$ ls
flume-conf.properties.template flume-env.sh.template ...
[hadoop@hadoop01 conf]$ mv flume-conf.properties.template flume-conf.properties
- 欣赏配置文件:
[hadoop@hadoop01 conf]$ vim flume-conf.properties
- 内容如下:
# 定义Agent中各组件的名称
agent.sources = seqGenSrc
agent.channels = memoryChannel
agent.sinks = loggerSink# 配置Source(数据源):这里使用一个序列生成器,它只会不断产生自增的数字事件,用于测试
agent.sources.seqGenSrc.type = seq
agent.sources.seqGenSrc.channels = memoryChannel# 配置Sink(输出目的地):这里使用logger,将事件内容记录到日志文件(或控制台)
agent.sinks.loggerSink.type = logger
agent.sinks.loggerSink.channel = memoryChannel# 配置Channel(缓冲通道):这里使用内存通道,性能好但断电会丢失数据
agent.channels.memoryChannel.type = memory
# 设置内存通道的容量(可存储的事件数量)
agent.channels.memoryChannel.capacity = 100
重要提示:
- 这个配置定义了一个最简单的 Flume Agent,它包含:
- 一个Source:
seq(序列生成器),用于测试,它不停地产生数字。 - 一个Channel:
memory(内存通道),临时存储事件。 - 一个Sink:
logger(日志记录),将事件内容输出到日志。
- 一个Source:
3. 启动运行 Flume Agent
操作步骤:
- 返回到 Flume 的安装目录:
cd /home/hadoop/app/flume
- 执行启动命令:
bin/flume-ng agent \
-n agent \
-c conf \
-f conf/flume-conf.properties \
-Dflume.root.logger=INFO,console
命令行参数解释(严格按照您的说明):
flume-ng:Flume 的执行脚本。agent:表示要启动一个 Flume Agent 进程。-n agent:-n指定了 Agent 的名称。这个名称必须与配置文件中顶部的组件名称前缀(即agent.sources中的agent)保持一致。-c conf:-c指定了配置文件所在的目录(conf是相对当前路径的目录)。-f conf/flume-conf.properties:-f指定了具体的配置文件路径。-Dflume.root.logger=INFO,console:这是一个 Java 系统属性,它覆盖了日志配置文件中的设置,强制将日志输出到控制台(console),并且日志级别为 INFO。这非常便于我们实时查看测试结果。
预期结果:
执行命令后,Flume Agent 会启动并开始工作。您将在控制台上看到大量日志输出,其中会夹杂着类似以下的内容,这证明 Flume 正在正常运行:
... INFO ... Event: { headers:{} body: 48 65 6C 6C 6F 20 57 6F 72 6C 64 21 Hello World! }
... INFO ... Event: { headers:{} body: 48 65 6C 6C 6F 20 46 6C 75 6D 65 21 Hello Flume! }
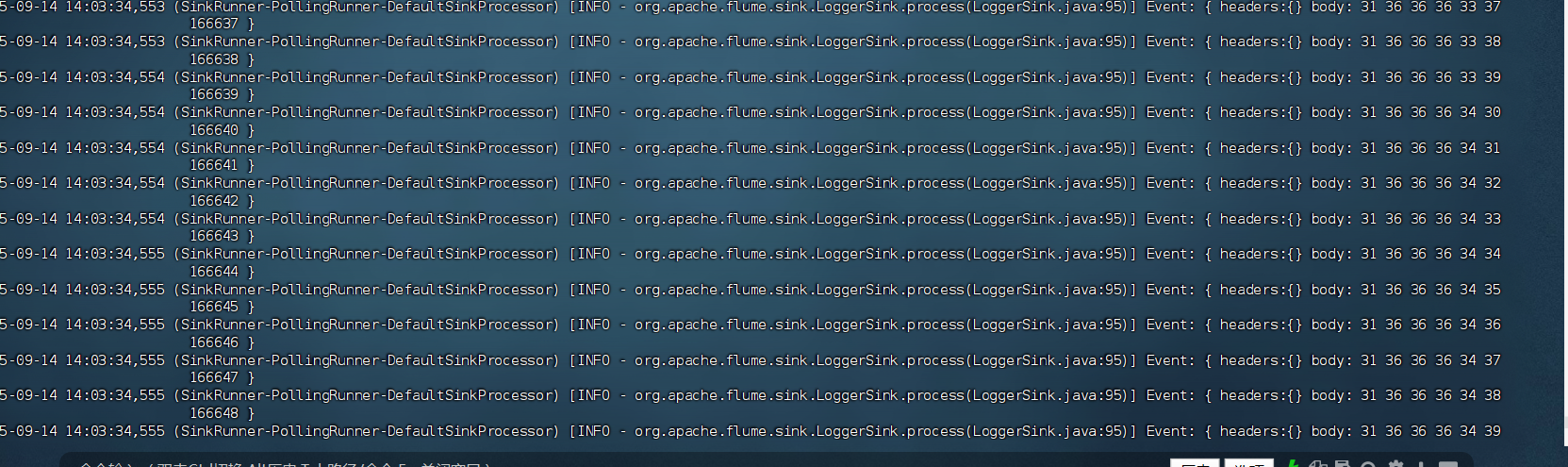
这些就是 loggerSink 打印出的事件内容。body 部分同时显示了字节序列(十六进制)和其对应的字符串格式。
停止 Flume:
要停止 Flume Agent,只需在控制台按下 Ctrl + C 组合键即可。
构建Flume集群
环境准备
假设有三台服务器:
- hadoop01: Web服务器/采集节点
- hadoop02: 聚合节点1
- hadoop03: 聚合节点2
分发:
# 分发 Flume 安装包到 hadoop02 的 /home/hadoop/app 目录
scp -r /home/hadoop/app/apache-flume-1.8.0-bin hadoop02:/home/hadoop/app/# 分发 Flume 软链接到 hadoop02(避免后续路径不一致)
scp -r /home/hadoop/app/flume hadoop02:/home/hadoop/app/# 同理,分发到 hadoop03
scp -r /home/hadoop/app/apache-flume-1.8.0-bin hadoop03:/home/hadoop/app/
scp -r /home/hadoop/app/flume hadoop03:/home/hadoop/app/
1. 在 hadoop01(采集节点)配置
1.1 创建配置文件
cd /home/hadoop/app/flume/conf/vim taildir-file-selector-avro.properties
1.2 配置内容
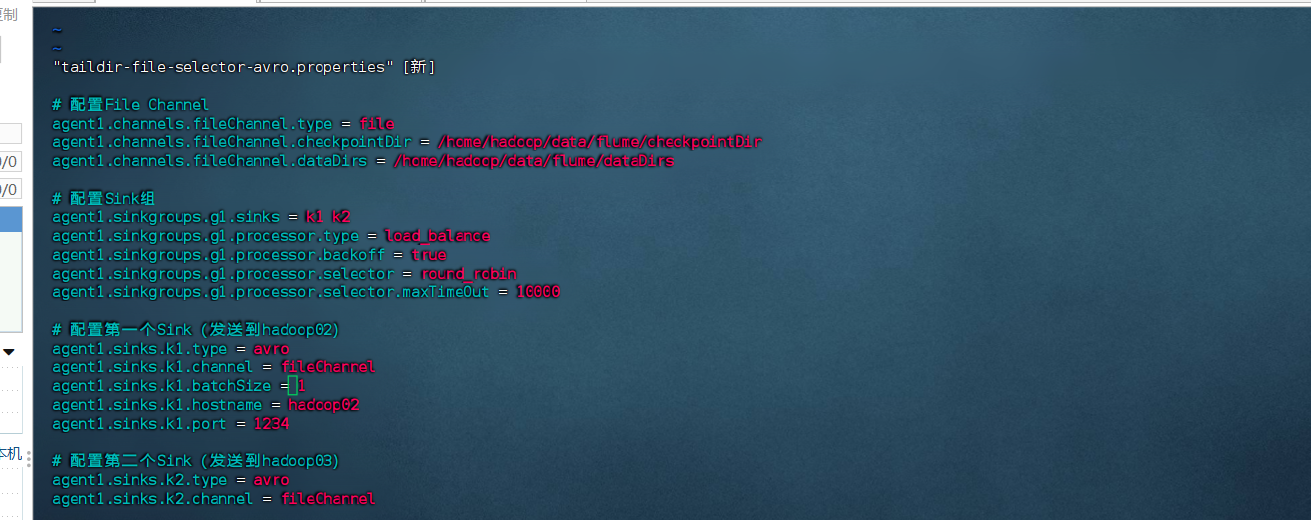
将以下配置复制到文件中:
# 定义Source、Channel、Sink的名称
agent1.sources = taildirSource
agent1.channels = fileChannel
agent1.sinkgroups = g1
agent1.sinks = k1 k2# 配置TAILDIR Source
agent1.sources.taildirSource.type = TAILDIR
agent1.sources.taildirSource.positionFile = /home/hadoop/data/flume/taildir_position.json
agent1.sources.taildirSource.filegroups = f1
agent1.sources.taildirSource.filegroups.f1 = /home/hadoop/data/flume/logs/sogou.log
agent1.sources.taildirSource.channels = fileChannel# 配置File Channel
agent1.channels.fileChannel.type = file
agent1.channels.fileChannel.checkpointDir = /home/hadoop/data/flume/checkpointDir
agent1.channels.fileChannel.dataDirs = /home/hadoop/data/flume/dataDirs# 配置Sink组
agent1.sinkgroups.g1.sinks = k1 k2
agent1.sinkgroups.g1.processor.type = load_balance
agent1.sinkgroups.g1.processor.backoff = true
agent1.sinkgroups.g1.processor.selector = round_robin
agent1.sinkgroups.g1.processor.selector.maxTimeOut = 10000# 配置第一个Sink(发送到hadoop02)
agent1.sinks.k1.type = avro
agent1.sinks.k1.channel = fileChannel
agent1.sinks.k1.batchSize = 1
agent1.sinks.k1.hostname = hadoop02
agent1.sinks.k1.port = 1234# 配置第二个Sink(发送到hadoop03)
agent1.sinks.k2.type = avro
agent1.sinks.k2.channel = fileChannel
agent1.sinks.k2.batchSize = 1
agent1.sinks.k2.hostname = hadoop03
agent1.sinks.k2.port = 1234
1.3 创建必要的目录
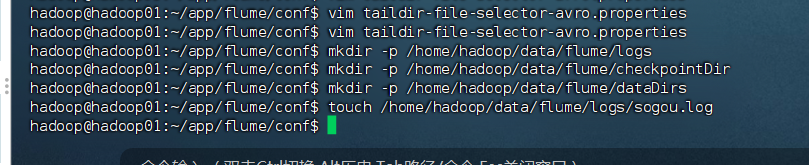
# 创建日志文件目录
mkdir -p /home/hadoop/data/flume/logs# 创建Channel数据目录
mkdir -p /home/hadoop/data/flume/checkpointDir
mkdir -p /home/hadoop/data/flume/dataDirs# 创建初始日志文件
touch /home/hadoop/data/flume/logs/sogou.log
2. 在 hadoop02 和 hadoop03(聚合节点)配置
2.1 创建配置文件
在两台节点上执行相同操作:
# 进入 Flume 配置目录
[hadoop@hadoop02 ~]$ cd /home/hadoop/app/flume/conf/
[hadoop@hadoop02 conf]$ vim avro-file-selector-logger.properties
2.2 配置内容
将以下配置复制到文件中:
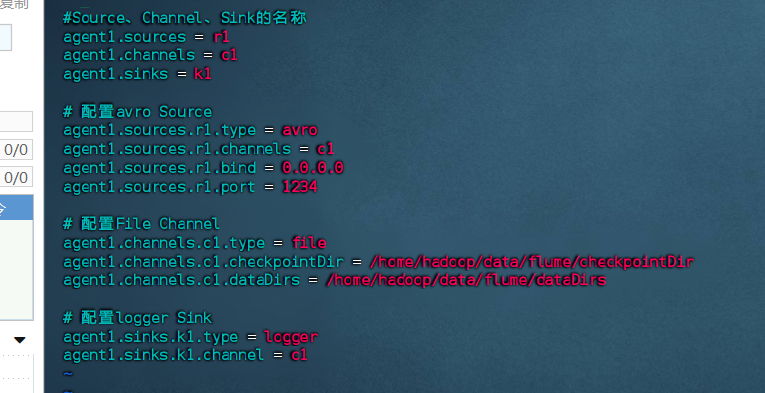
# 定义Source、Channel、Sink的名称
agent1.sources = r1
agent1.channels = c1
agent1.sinks = k1# 配置avro Source
agent1.sources.r1.type = avro
agent1.sources.r1.channels = c1
agent1.sources.r1.bind = 0.0.0.0
agent1.sources.r1.port = 1234# 配置File Channel
agent1.channels.c1.type = file
agent1.channels.c1.checkpointDir = /home/hadoop/data/flume/checkpointDir
agent1.channels.c1.dataDirs = /home/hadoop/data/flume/dataDirs# 配置logger Sink
agent1.sinks.k1.type = logger
agent1.sinks.k1.channel = c1
2.3 创建必要的目录
在两台节点上执行:
# 创建Channel数据目录
[hadoop@hadoop02 ~]$ mkdir -p /home/hadoop/data/flume/checkpointDir
[hadoop@hadoop02 ~]$ mkdir -p /home/hadoop/data/flume/dataDirs
3. 启动 Flume 集群服务
3.1 先启动聚合服务(hadoop02 和 hadoop03)
在 hadoop02 节点:
cd /home/hadoop/app/flume
bin/flume-ng agent -n agent1 -c conf -f conf/avro-file-selector-logger.properties -Dflume.root.logger=INFO,console

在 hadoop03 节点:
cd /home/hadoop/app/flume
bin/flume-ng agent -n agent1 -c conf -f conf/avro-file-selector-logger.properties -Dflume.root.logger=INFO,console

3.2 再启动采集服务(hadoop01)
在 hadoop01 节点:
cd /home/hadoop/app/flume
bin/flume-ng agent -n agent1 -c conf -f conf/taildir-file-selector-avro.properties -Dflume.root.logger=INFO,console
4. 测试 Flume 集群
4.1 生成测试数据
# 在 hadoop01 节点添加测试数据
cd /home/hadoop/data/flume/logs
echo '00:00:10 0971413028304674 [火炬传递路线时间] 1 2 www.olympic.cn/news/beijing/2008-03-19/1417291.html' >> sogou.log
echo '00:00:11 19400215479348182 [天津工业大学\] 1 65 www.tjpu.edu.cn/' >> sogou.log
echo '00:00:12 30567412345678901 [测试数据] 1 3 www.example.com/' >> sogou.log
4.2 验证结果
在 hadoop02 和 hadoop03 的控制台,您应该能看到类似这样的输出:
Event: { headers:{} body: 00:00:10 0971413028304674 [火炬传递路线时间] 1 2 www.olym... }
Event: { headers:{} body: 00:00:11 19400215479348182 [天津工业大学\] 1 65 www.tjpu... }
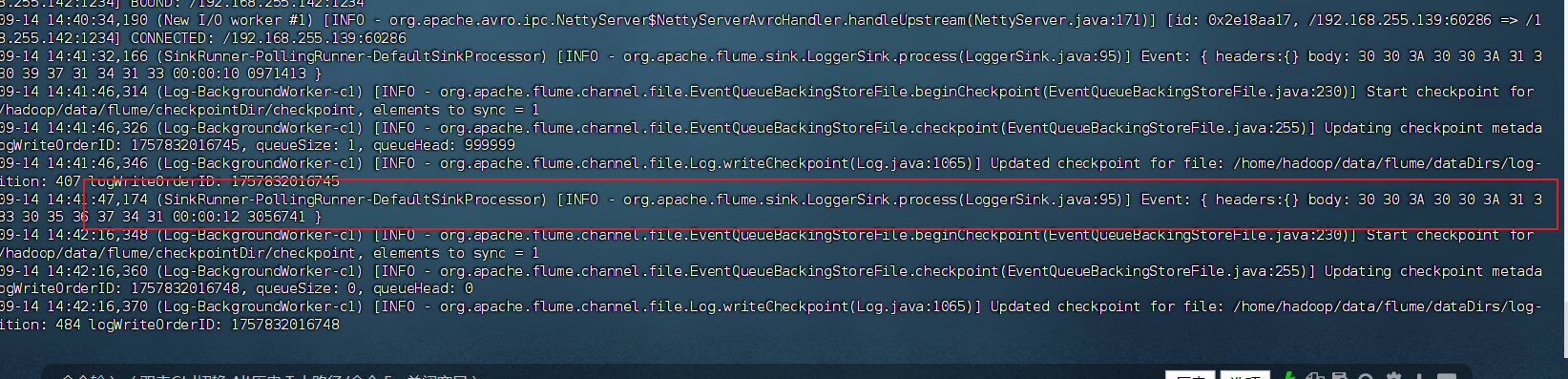
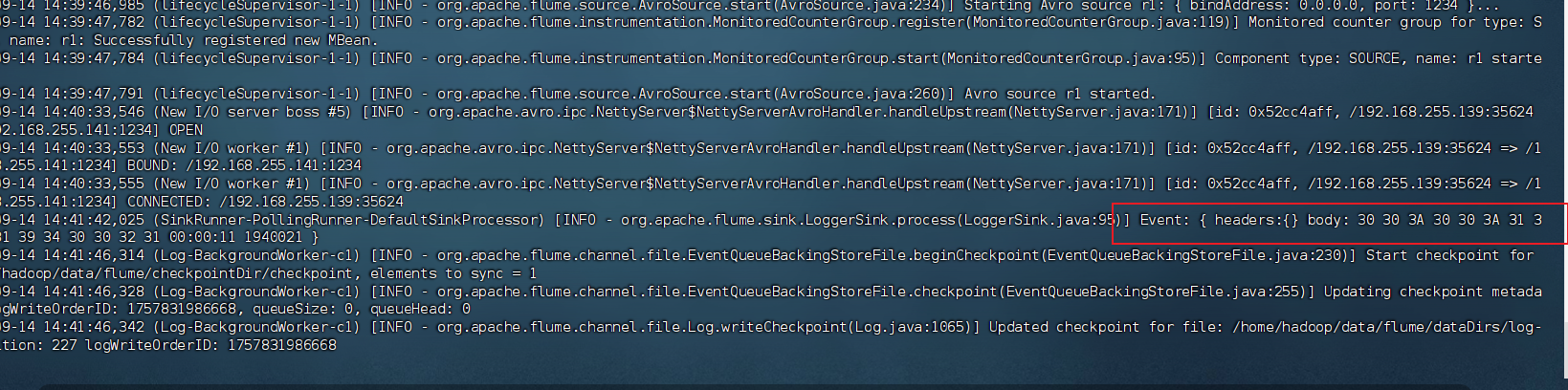
5. 关键点说明
-
启动顺序:必须先启动聚合节点(hadoop02、hadoop03),再启动采集节点(hadoop01)
-
负载均衡:配置中的
load_balance和round_robin会让数据轮询发送到两个聚合节点 -
目录权限:确保所有创建的目录对 hadoop 用户有读写权限
-
网络连通:确保三台服务器之间的网络连通,特别是 1234 端口
-
故障处理:如果某个聚合节点宕机,采集节点会自动将数据发送到另一个正常节点
6. 停止服务
在任何节点的控制台按 Ctrl + C 即可停止该节点的 Flume 服务。
停止顺序建议:先停止采集节点,再停止聚合节点。
Flume与Kafka集成测试
1. 配置 Flume 聚合服务(Kafka Sink)
在 hadoop02 和 hadoop03 节点上操作:
# 进入 Flume 配