阿里云视觉多模态理解大模型开发训练部署
与阿里云一起
轻松实现数智化
让算力成为公共服务:用大规模的通用计算,帮助客户做从前不能做的事情,做从前做不到的规模。让数据成为生产资料:用数据的实时在线,帮助客户以数据为中心改变生产生活方式创造新的价值。
视觉多模态理解大模型架构
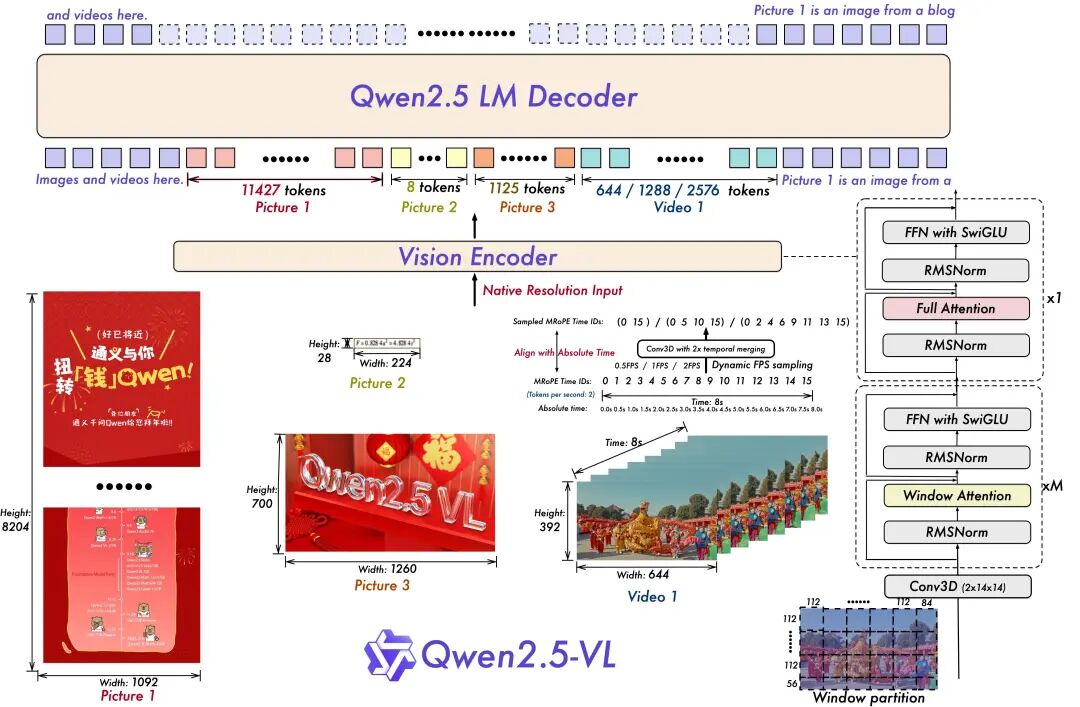
用于视频理解的动态分辨率和帧率训练:将动态分辨率扩展到时间维度,采用动态FPS采样,使模型能够在不同的采样率下理解视频。
简化且高效的视觉编码器:通过在ViT中策略性地实现窗口注意力机制,提高了训练和推理速度。
视觉多模态理解大模型特性视觉理解能力:Qwen2.5-VL不仅擅长识别常见的物体如花、鸟、鱼和昆虫,而且在分析图像中的文本、图表、图标、图形和布局方面也非常出色。 自主代理能力:Qwen2.5-VL可以直接作为视觉代理,能够进行推理并动态指导工具的使用,具备计算机和手机操作的能力。 理解和捕捉长视频中的事件:Qwen2.5-VL可以理解超过1小时的视频,并且这次新增了通过定位相关视频片段来捕捉事件的能力。 不同格式下的视觉定位能力:Qwen2.5-VL可以通过生成边界框或点准确地在图像中定位物体,并能提供稳定的JSON输出,包括坐标和属性。 生成结构化输出:对于发票扫描件、表格等数据,Qwen2.5-VL支持其内容的结构化输出,适用于金融、商业等领域。 |
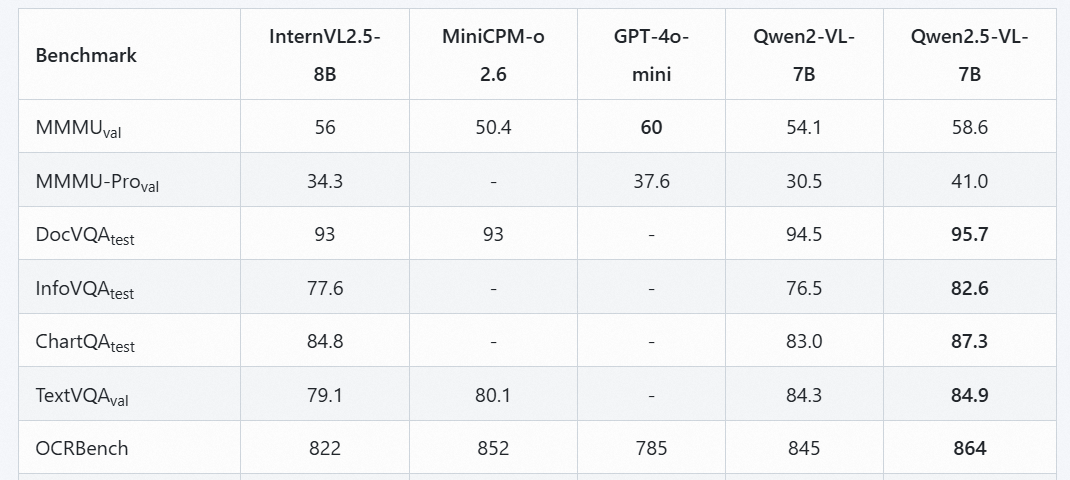
图像基准测试
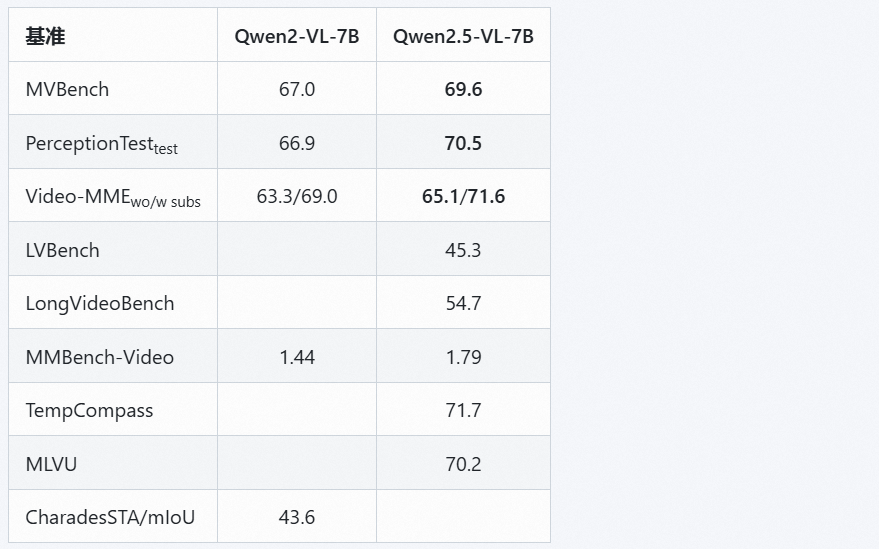
视频基准测试
快速安装命令行
在ModelScope开源社区提供的大模型运行环境中,使用以下命令行执行安装:

代码使用示例
从ModelScope开源社区的大模型库,下载阿里云视觉多模态理解大模型到本地开发环境中,导入大模型开发依赖库,初始化大模型实例,用于对输入的信息执行推理:

初始化大模型处理器实例,用于对输出的信息执行解码:

定义输入的需求提示词信息,其中,包括多模态中的文本、图像以及视频资源的输入参数:

从输入参数中分别提取出文本内容、图像内容以及视频内容:

对输入的参数内容执行标准化处理:

调用大模型实例执行生成式推理:

调用大模型处理器实例执行解码:

多图片的输入参数处理:

多图片作为视频内容的输入参数定义:
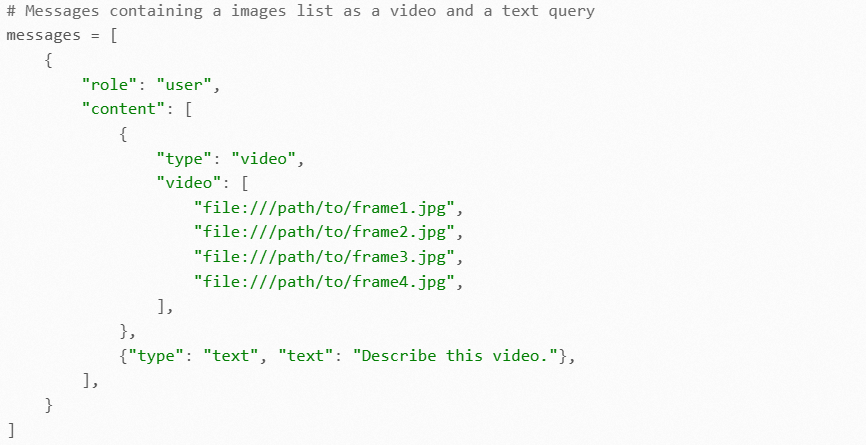
本地视频文件的输入参数定义:

在线视频文件的输入参数定义:

多图片与多视频的输入参数处理:

批量输入的参数定义:

批量输入的参数处理:

模型训练
在阿里云人工智能业务平台PAI中,查找对应规格的视觉多模态理解大模型:
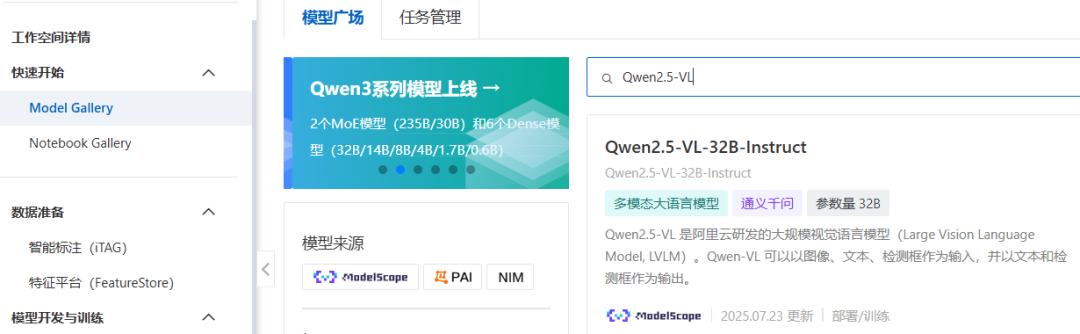
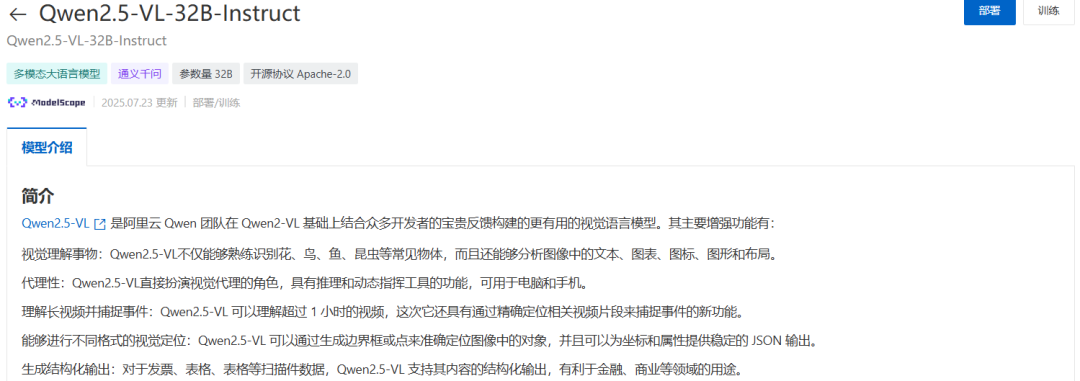
在视觉多模态理解大模型的详情页面中,点击部署或者训练按钮,开始设置部署或者训练的属性参数:
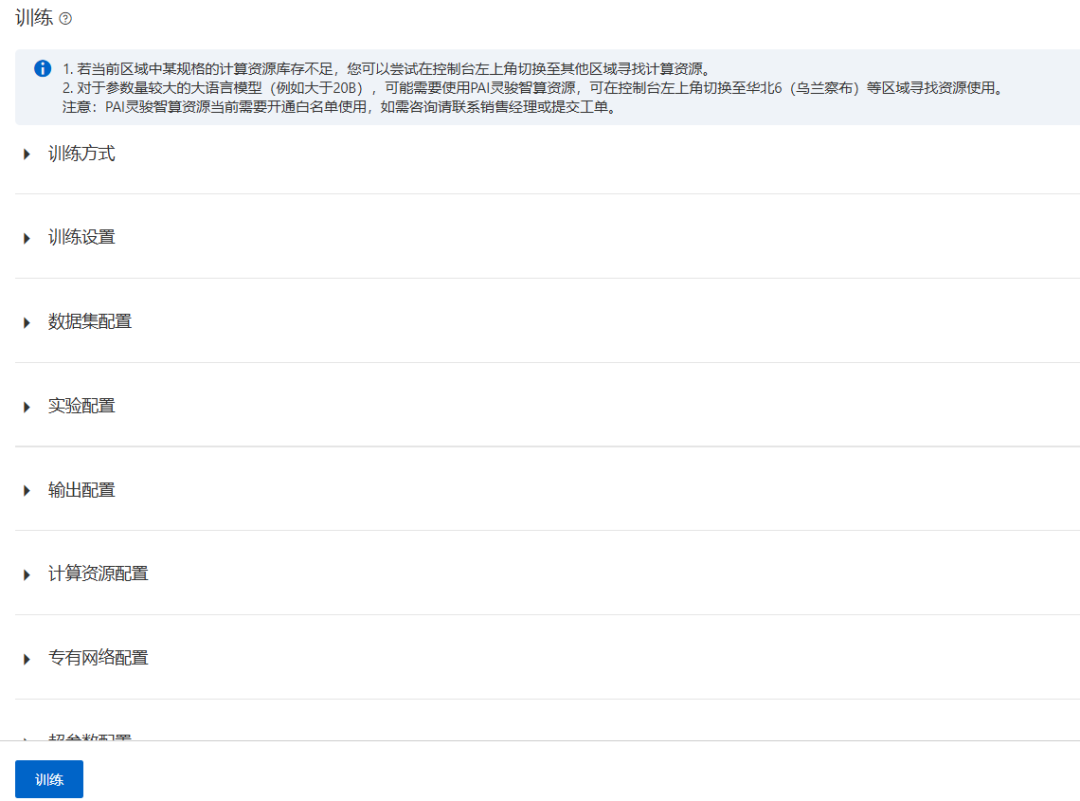
在视觉多模态理解大模型的训练的属性参数设置页面中,设置完成,点击训练按钮,开始执行模型训练:
模型部署
在视觉多模态理解大模型的部署的属性参数设置页面中,设置完成,点击部署按钮,开始执行模型部署: