分布式推理与量化部署
分布式推理与量化部署
一、大模型部署
定义 : 将训练好的模型在特定软硬件环境中启动的过程,使模型能够接收输入并返回预测结果。为了满足性能和效率的需求,常常需要对模型进行优化,例如模型压缩和硬件加速。
产品形态: 云端、边缘计算端、移动端
计算设备: CPU、GPU、NPU、TPU 等
1.1 大模型的特点
内存开销巨大:
- 庞大的参数量,
7B模型仅权重就需要14+G内存; - 采用自回归生成
token,需要缓存Attention的kv,带来巨大的内存开销;
动态shape(“shape”指的是输入或输出数据在张量(Tensor)层面的维度):
- 请求数不固定
- 每个推理批次(batch)中包含的请求数量是动态变化的。
- 例如:某一时刻有 4 个用户同时请求生成文本,下一时刻可能只有 1 个,再下一刻可能有 16 个。这导致输入张量的
batch size维度是动态的,比如输入的input_ids张量 shape 可能从(4, 128)变为(1, 256),再到(16, 512),不断变化。
Token逐个生成,且数量不定- 大模型以 自回归方式 逐个生成 token(即输出一个 token 后,作为输入继续生成下一个)。
- 每个请求生成的 token 数量不同:
- 用户 A 可能只需要生成 20 个 token;
- 用户 B 可能需要生成 500 个 token 才结束。
- 因此,输出序列的长度是动态的,无法预先确定。
相对视觉模型,LLM结构简单:
- Transformers结构,大部分是解码器结构;
1.2 大模型部署挑战
设备 :
- 如何应对巨大的存储问题?
- 低存储设备(消费级显卡、手机等)如何部署大模型?
- 移动端只能跑很小的大模型,比如
0.5B的大模型;
- 移动端只能跑很小的大模型,比如
推理 :
- 如何加速token的生成速度?如何解决动态shape,让推理可以不间断?
- 如何有效管理和利用内存?
服务 :
- 如何提升系统整体吞吐量?
- 对于个体用户如何降低响应时间?
1.3 大模型部署方案
技术点:
- 模型中张量并行
transformer计算和访存优化- 低比特量化
Continuous Batch:动态合并不同长度的请求到一个计算批次,最大化GPU利用率,通过窗口期缓冲来实现;- 比如我们调用大模型时,可能会等个几秒,将不同的批次合并到一起使得每次访问模型的批次尽可能都相等;
Page Attention:借鉴OS内存分页机制,高效管理KV Cache;
方案:
huggingface transformers- 专门的推理加速框架
| 云端 | 移动端 |
|---|---|
LmDeploy, vLLM, tensorrt-llm, DeepSpeed | llama.cpp, mlc-llm |
-
tensorrt-llm是英伟达推出的推理框架,最好的方式是使用C/C++去调用,拔高了入门的门槛; -
做分布式推理基本上会用到
deepspeed进行核心框架的构建;
二、分布式推理
引言:如果一个大模型的应用,涉及到用户量过多,导致服务器的性能跟不上,那么最终只有一个解决方案,就是加服务器或者加显卡GPU,如果不加GPU进行分布式推理,那么出现的情况就是像DeepSeek一样服务器未响应,服务器繁忙。
2.1 什么是分布式推理
分布式推理部署是一种利用多个计算节点(如服务器、GPU 或 TPU 等)协同完成深度学习模型推理任务的技术。它通过将计算负载分散到多个设备上,以提高处理效率、降低延迟,并支持大规模并发请求。
2.2 主要目标
高性能: 加速推理速度,满足实时性需求(如自动驾驶、实时翻译)。
高吞吐: 处理大量并发请求(如推荐系统、AIGC 服务)。
可扩展性: 动态扩展资源应对负载波动。
2.3 关键实现方式
分布式推理是指将大模型的计算任务拆分到多个GPU设备上并行执行,以解决单卡显存不足、提升推理速度的技术。其核心在于张量并行(Tensor Parallelism)和流水线并行(Pipeline Parallelism),其中张量并行将模型的权重矩阵按维度切分到不同 GPU 上,每个 GPU 负责部分计算,最终合并结果。
- 例如,在
Llama-13B等大模型推理中,单卡显存可能不足,分布式推理可显著降低显存占用并提高吞吐量。
2.4 高并发与分布式推理的区别
AI模型输入的是数据,一般数据是带有批次的
batchSize,如果在训练模型时的批次为10,相当于我们一次性给模型输入了10条数据;如果在推理过程中批次为10,就相当于在同一时刻有10个用户使用模型,那么模型返回的结果也是10个。
这就是一个并发问题,那么高并发就是人数突然变的很多(之前10个人时模型还可以跑,现在突然激增成1000人就跑不了,相当于batchSize变成1000),这就会引发两个问题:
-
第一个就是显存不足,
Out of memory; -
第二个问题是算力不足,就是说我们批次为10时,它的计算速度一定比批次为1000时计算速度快
我们在推理模型时,其实跟训练时是如出一辙的,只不过推理的过程中,模型只计算矩阵乘法,不算导数,不更新参数。所以高并发问题就是要解决用户量过多了怎么办?实际上我们是要解决的是两个问题:
-
显存不足的问题
-
算力不足导致这个模型推理速度变慢的问题
解决的方式:分布式部署解决并发问题。
之前模型运行在一张卡上,现在用户数量由10人增加到1000人,一张卡跑不动了,需要增加到8张卡。
2.5 实际案例
案例场景:
单卡显存不足: 如 QwQ-32B(320亿参数)需在双 A6000 显卡上部署
高并发请求: 在线服务需同时处理多用户请求,分布式推理通过连续批处理提升效率。
我们一般在做模型部署的时候,这个模型部署是基于一套系统来做的,系统上面有最大用户量的限制(限流),当用户量超过最大承载量以后,就会以队列的模式进行排队,这就是为什么前段时间DeepSeek爆火时,白天访问它是访问不了的,因为我们不在队列中。
2.6 计算模型的体积
模型的体积分为:微调时模型的体积、推理时模型的体积。
以一个 7B 模型为例,就是我们模型所需要的显存是多少?
首先:7B 的这个B表 70 亿个参数,然后查看模型的配置文件显示torch_dtype:bfloat16
- 现在大多数模型都是16位的,
bfloat16代表的意思就是每个参数用的是16位的浮点数。
确定参数量:
7B参数 = $ 7 × 10^9 B $确定数据类型占用的字节数: 上面是
bfloat16代表每个参数占用2个字节计算总字节数: = $ 7 × 10^9 ×2 = 14 × 10^9 $
转换标准:$ 1GB=103MB=106KB=10^9B $
转换为GB: $ \frac{14 × 109}{109} = 14G $
上面得出来 7B 的模型需要占用显存的大小是 14GB,但是显存至少需要 16G 才能推理这个模型,因为服务器还会有其他程序来占用这个显存;如果是微调训练,那还涉及到了中间层的存储和反向传播过程,需要比这个空间要大得多。注意:
上述的 14GB显存大小是在无人访问时,当有人访问时如何计算显存?
假设模型的
max_length为8000,hidden_size=1000(这个是模型的维度d_model),就相当于是8000个参数,1个人提问推理时占用显存为:8000×1000×2=16000000=16MB(因为还有位置编码,注意力掩码等内容,实际占用会更高),所以的模型在推理时显存的占用应该控制在90%左右。
问题:厂商标注的显存 24GB 和系统显示的 GiB不同?
因为厂商按 十进制 $ GB(10^9 Byte)$ 标称的,操作系统按二进制$ GiB(1024^3 Byte) $ 统计的。
例如:一块标称 24 GB 显存的显卡,系统会显示为:
24×10910243≈22.35GiB \frac{24×10^9}{1024^3} ≈ 22.35GiB 1024324×109≈22.35GiB
Gibibyte(GiB): 是二进制的存储容量单位,全称为Gibi Binary Byte,主要用于精确衡量计算机内存、显存、文件大小等场景。
三、vLLM分布式推理实现
vLLM 通过PagedAttention 和张量并行技术优化显存管理和计算效率,支持多 GPU 推理。
3.1 核心机制
张量并行: 通过 tensor_parallel_size 参数指定GPU数量,模型自动拆分到多个显卡。
PagedAttention: 将注意力机制的键值(KV)缓存分块存储,减少显存碎片提升利用率。
现在的模型都是基于
Transformer构建的,Transformer本质就是自注意力层和前向计算层(前馈神经网络FNN)两个部分来构建的,我们要进行分布式推理的时候就涉及到一个问题,怎么把模型拆开,这时候需要拆两个部分:注意力机制部分和神经网络部分。因为神经网络本身是序列的,所以神经网络实际上比较好拆,但是注意机制不存在顺序关系,所以PagedAttention的提出就是为了划分Transformer模型中的注意力机制的。
连续批处理: 在 PagedAttention存储过后,我们推理的时候模型是持续执行的,所以它还涉及到连续的批处理。
比如说这一次是10个用户,下一次是20个用户,再下一次是30个用户,它的批次在不断的变化,模型每次推理必须先把前面的任务执行完,再去执行后面的任务。所以在整个执行过程中,模型涉及到了批次的长度不一样,因为每一时刻的用户量都在发生变化,所以在
PagedAttention分完块之后,需要动态合并不同长度的请求,减少GPU空闲时间。
3.2 分布式推理
- 单 GPU(无分布式推理) :如果模型可以容纳在单个
GPU中,即不需要使用分布式推理。只需使用单个 GPU 运行推理即可。 - 单节点多 GPU(张量并行推理) :如果模型太大无法容纳在单个
GPU中,但可以容纳在具有多个GPU的单台服务器中,则可以使用张量并行。张量并行大小是服务器中GPU的数量。- 例如:单台服务器中有 4 个
GPU,可以将张量并行大小设置为 4。
- 例如:单台服务器中有 4 个
- 多节点多 GPU(张量并行加流水线并行推理) :如果模型太大无法容纳在单个服务器上(服务器有多张显卡),可以将张量并行与流水线并行结合使用。张量并行大小是每个节点中 GPU 的数量,流水线并行大小是服务器数量。
- 例如:在 2 台服务器中有 16 个 GPU(每台服务器 8 个 GPU),可以将张量并行大小设置为 8,流水线并行大小设置为 2。
单节点GPU推理:
$ vllm serve /root/lanyun-tmp/LLM/Qwen/Qwen2.5-1.5B-Instruct \
--tensor-parallel-size 2# vllm server xxx:使用 vLLM(一个高效的大语言模型推理框架)启动服务,加载的是xxx模型
# --tensor-parallel-size 2:启用张量并行,将模型参数在 2 个 GPU 之间拆分。
# 适用于单机多卡场景,通过将矩阵运算分块并行加速计算
多节点多 GPU推理:
$ vllm serve \
/root/lanyun-tmp/LLM/Qwen/Qwen2.5-1.5B-Instruct \
--tensor-parallel-size 4 \
--pipeline-parallel-size 2# --pipeline-parallel-size 2:启用流水线并行,将模型按层拆分到 2 个 GPU 上
# 适用于模型过大无法单卡存放时,按层划分到不同设备
3.3 KV Cache缓存占用情况
3.3.1 未进行推理时缓存占用情况
在单卡的情况下:
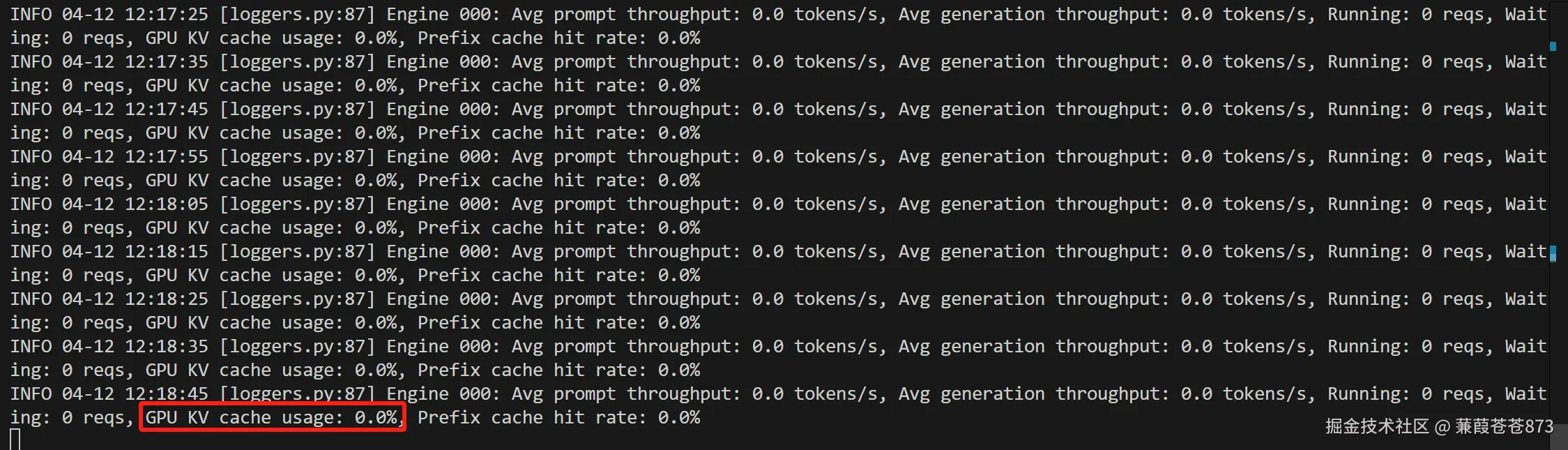
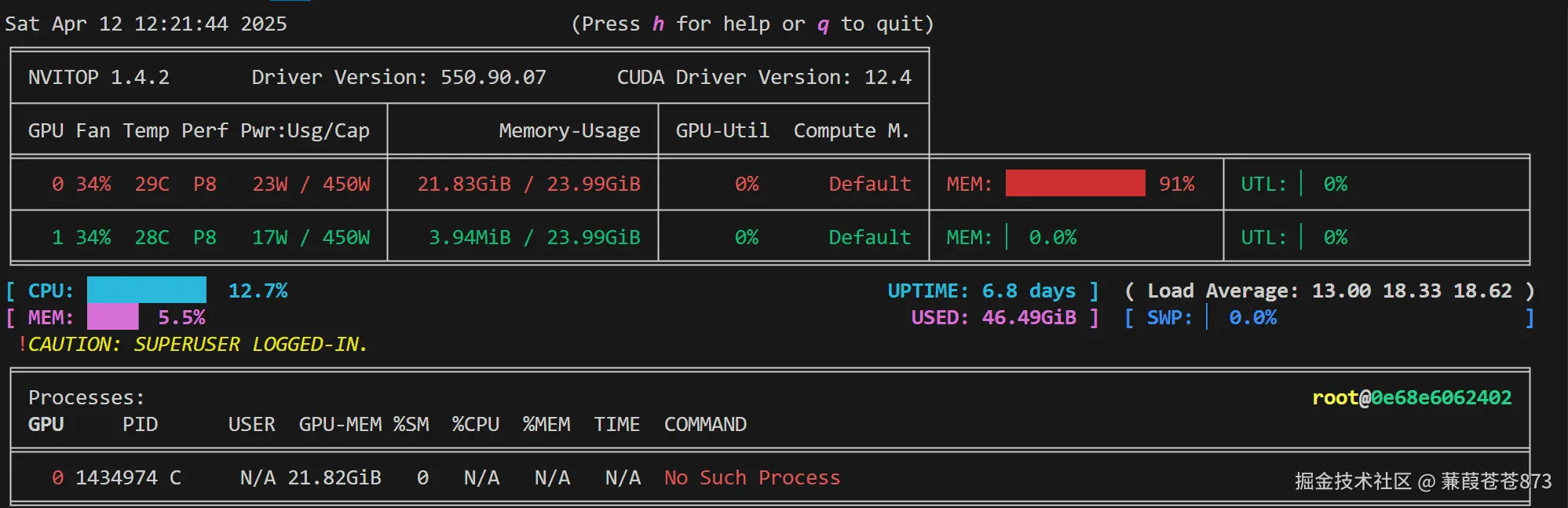
- 上图显示:在单卡的情况下:
GPU KV cache usage:0.0%,缓存占用0%,但是nvitop命令展示的窗口GPU显存占用达到了91%,这是因为即使模型没有进行推理,当模型启动后,vLLM框架会占用好显存以便在使用的时候进行调度。
多卡的情况:
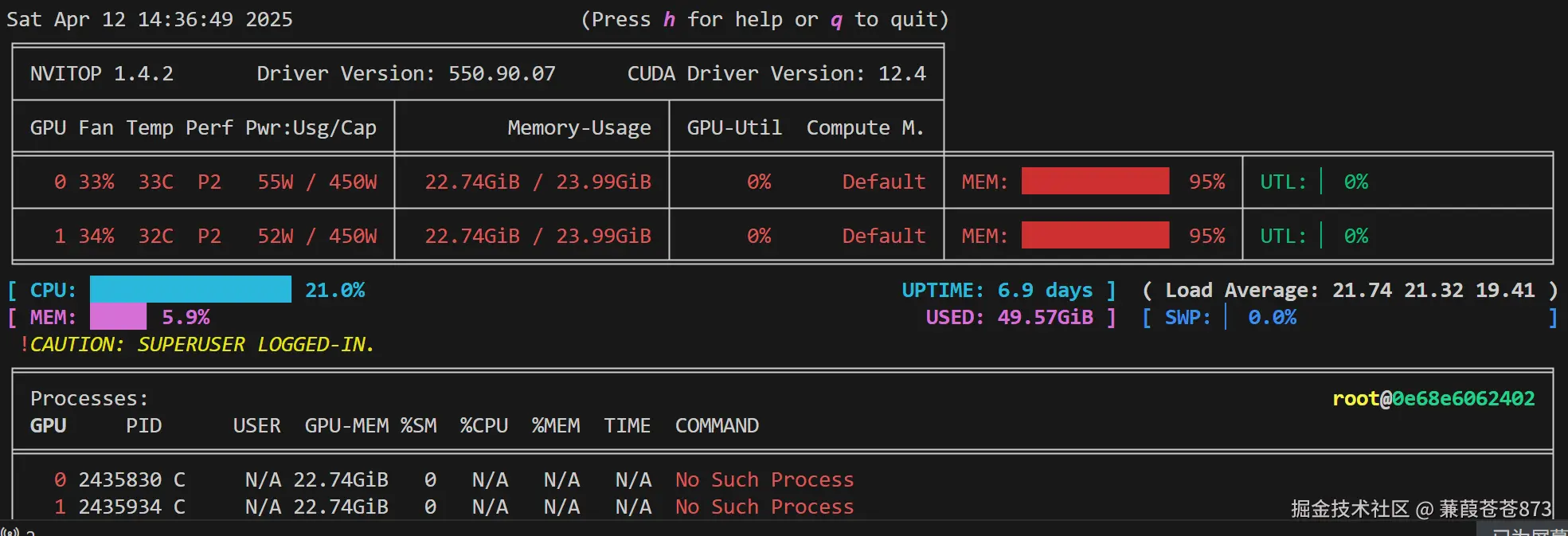
vLLM框架会占用好多个显存,以便在使用的时候进行调度。
3.3.2 分布式推理后缓存情况

- 前缀缓存命中率(
Prefix Cache Hit Rate)表示在序列生成(如大语言模型推理)过程中,重复使用已缓存的前缀数据的效率。
基本概念解释
1、前缀缓存(Prefix Cache) :
大语言模型通过自回归方式生成文本时,每生成一个新的词元(token),需要计算所有之前词元的注意力键值(KV)状态。为了优化性能,系统会缓存这些计算结果,称为 KV缓存(KV Cache) 。
- 前缀缓存特指对输入中相同前缀部分(例如多个用户请求共享的初始提示词)的KV缓存复用。例如:
# 举例如下:
提示词1: "巴黎是法国的首都,它的地标建筑是"
提示词2: "巴黎是法国的首都,它的美食文化以"↑↑↑↑↑↑↑↑↑[可复用的前缀]
2、命中率(Hit Rate) :
60%的命中率 = 系统在60%的请求中找到了可复用的前缀缓存,无需重新计算,剩余的40%需要重新生成完整KV缓存。
3、60%命中率的意义:
-
性能优化:
-
吞吐量提升: 重复使用前缀缓存会减少计算量,直接提高响应速度。
例如在批量处理100个相似请求时,60个请求复用了已有缓存,理论吞吐量可提高约0.6倍。
-
-
硬件成本降低: 缓存复用减少了GPU显存带宽和计算资源占用。
根据业务场景判断:
-
高命中率(
60%+)可能意味着:- 用户请求的前缀相似性高(如重复的查询模板、结构化提示词)。
- 使用的缓存分块(Chunk)策略适配了实际请求长度。
-
低命中率(如
30%以下)可能表明请求差异性大或缓存配置不合理。
四、LMDeploy推理框架
LMDeploy是专为高效部署设计的框架,支持量化技术与分布式推理,尤其适合低显存环境。
- 项目地址:http://github.com/InternLM/Imdeploy
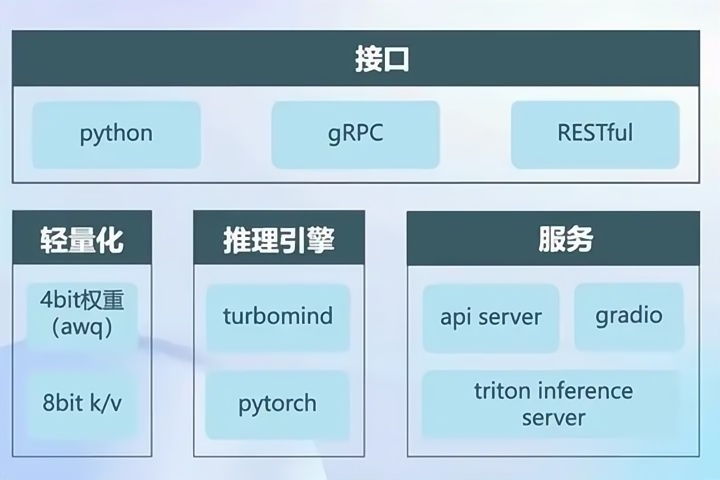
LMDeploy 支持 python、gRPC、RESTful 接口;
LMDeploy 主要支持两种轻量化:AWQ离线量化和KvCache`在线量化,
LMDeploy 支持的推理引擎主要是 turbomind和 pytorch;
turbomind要比pytorch快;
LMDeploy 提供的服务主要是api server,gradio,triton inference server。
LMDeploy 的优势如下:
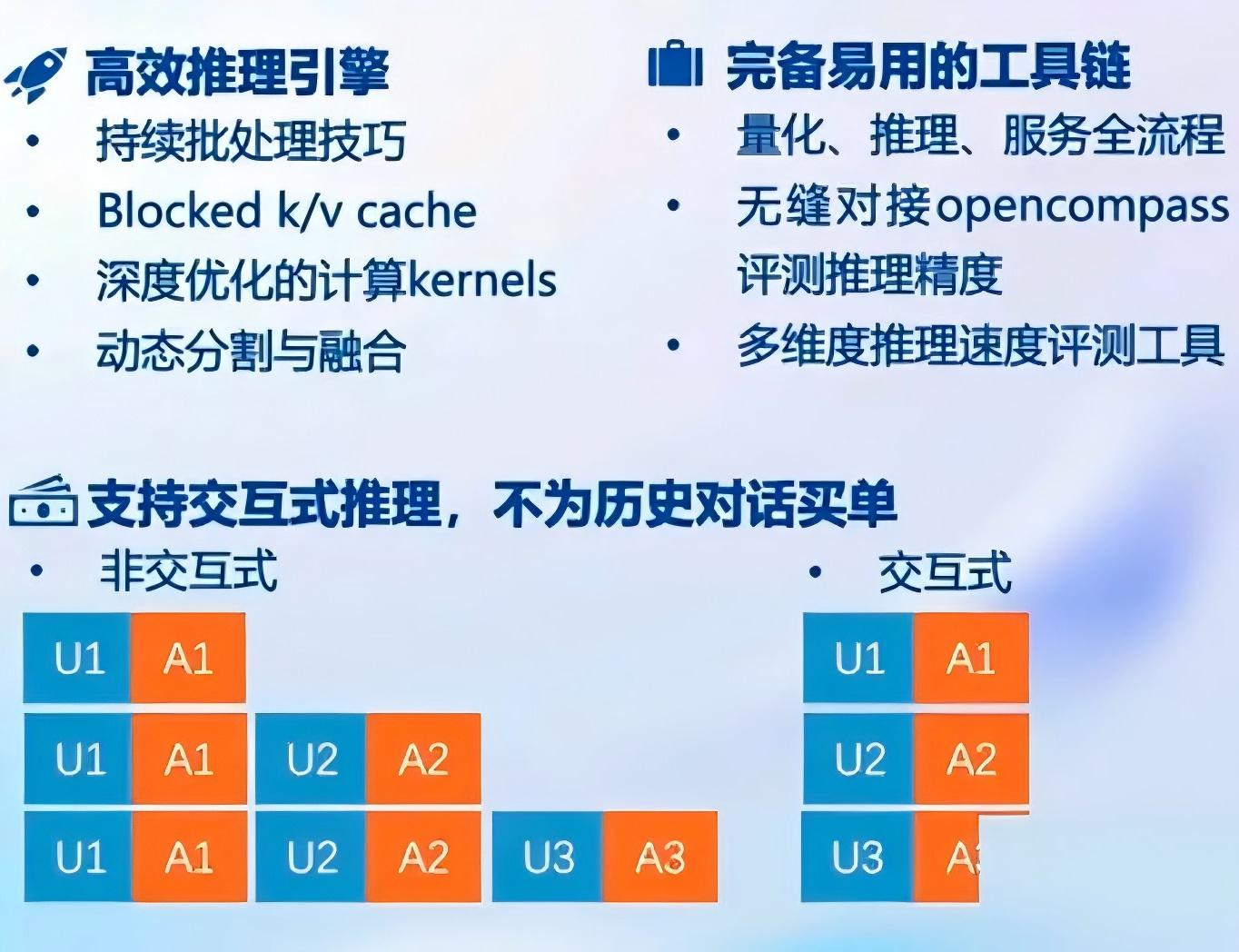
4.1 静态推理性能
固定batch(批次)的大小,对比输入/输出token数量:蓝色是vllm,橙色是lmdeploy。
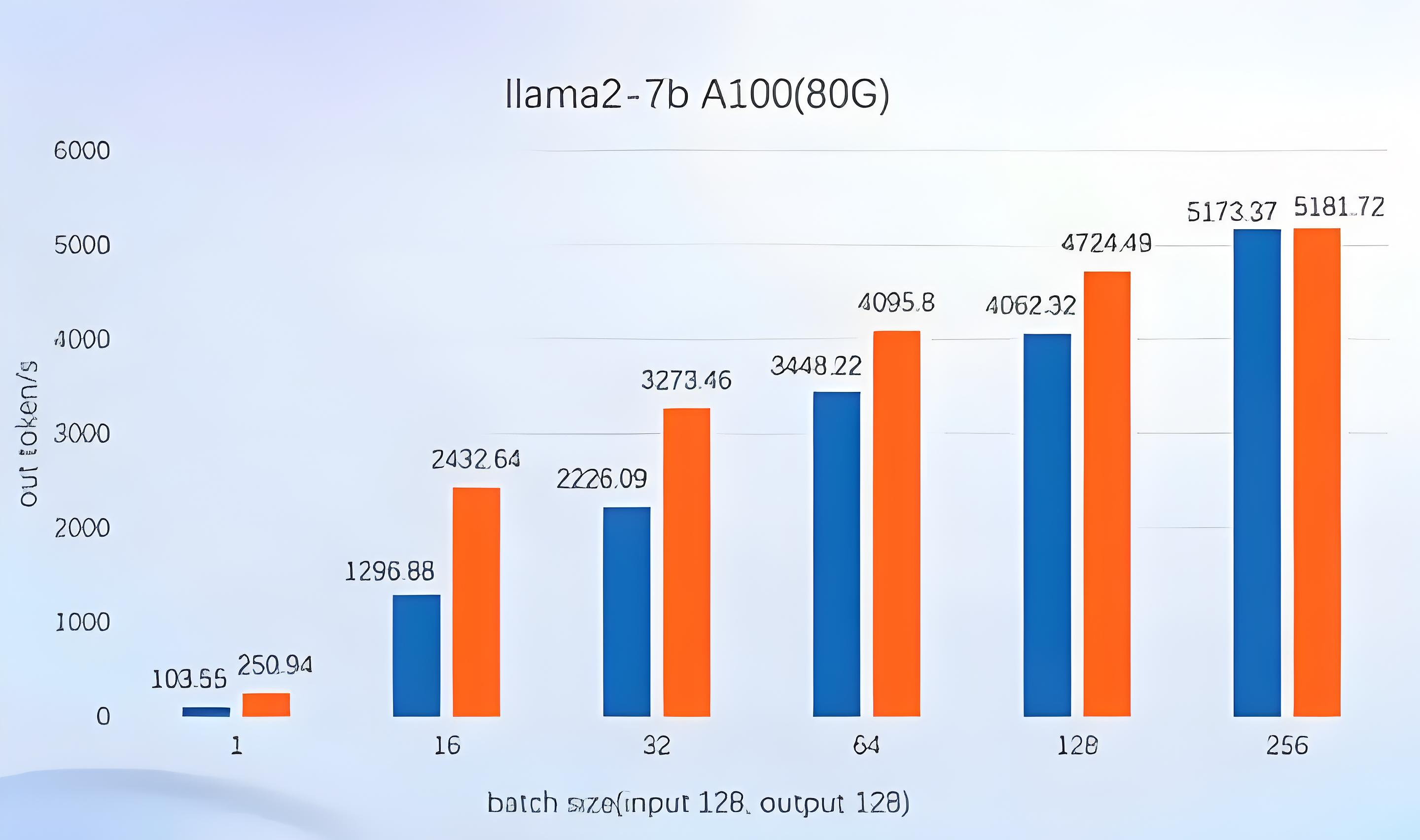
- 用
llama2-7b模型在A100(80G)的显卡上做对比,横轴为批次,纵轴是tonken的吞吐量,LMDeploy W4a16与fp16性能做对比,W4a16的推理性能是fp16的2倍多。
4.2 动态推理性能
在真实对话场景中,不定长的输入输出
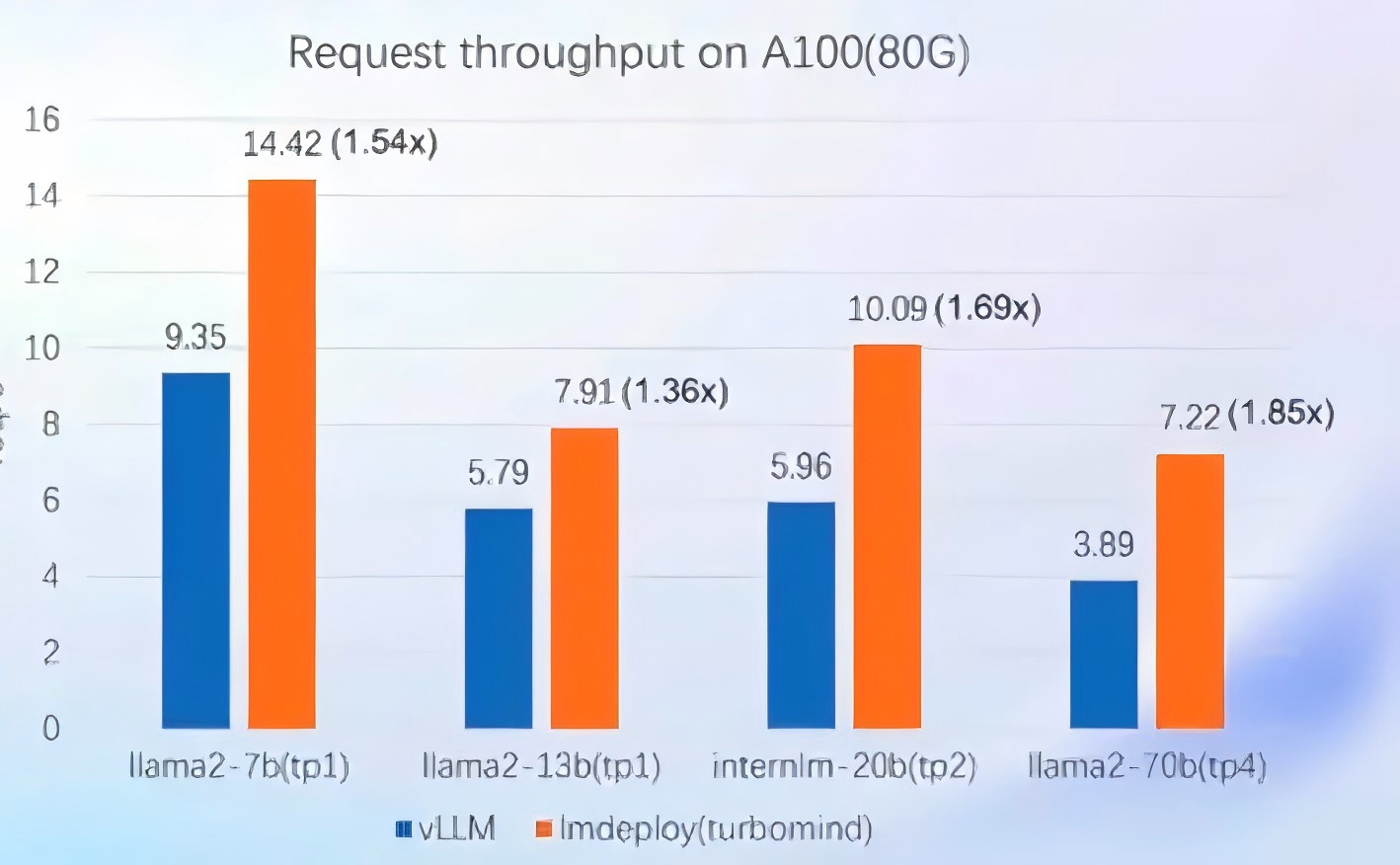
由上图可知,所以官网写着lmdeploy的速度是vLLM的1.8倍多;
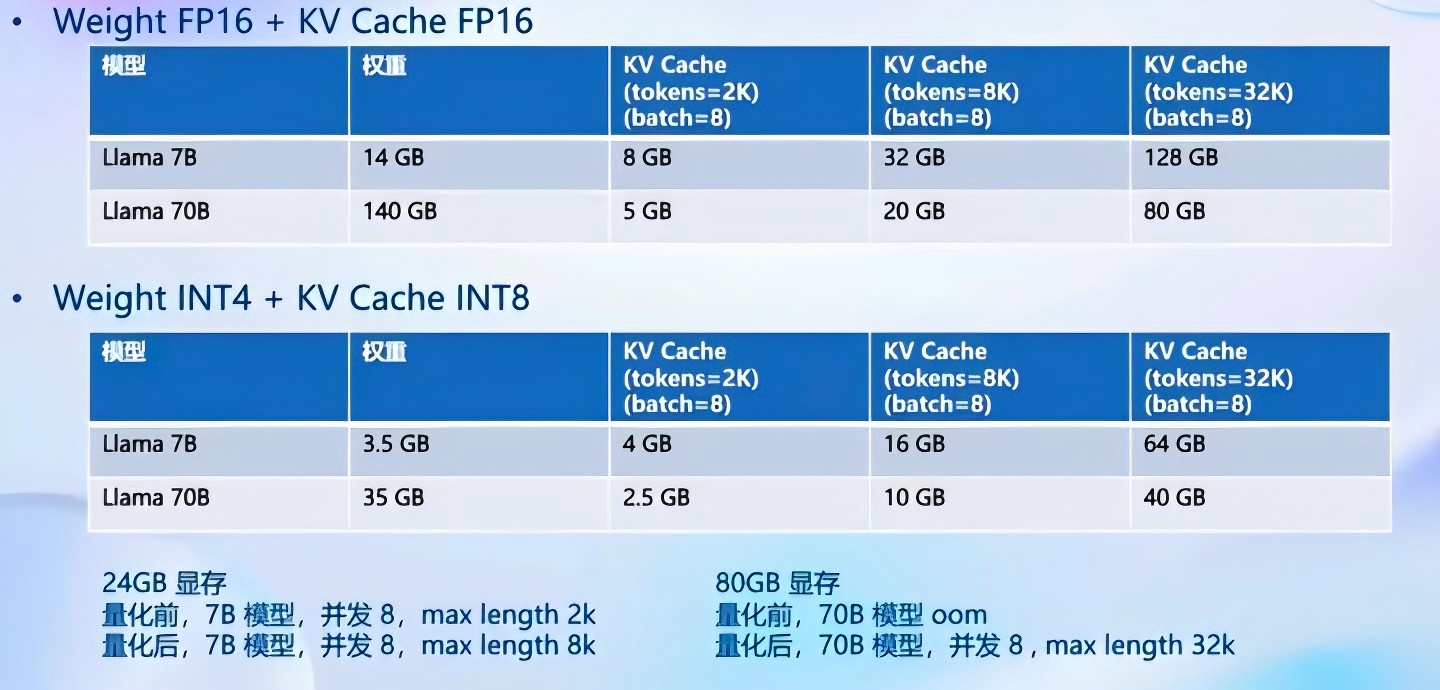
4.3 核心功能一量化
lmdeploy量化效果如下:
4.3.1 为什么要做量化?
两个基本概念:
-
计算密集(
compute-bound): 针对计算密集场景,可以通过使用更快的硬件计算单元来提升计算速度。- 比如量化为
W8A8使用INT8 Tensor Core来加速计算。
- 比如量化为
-
访存密集(
memory-bound): 针对访存密集型场景,一般是通过提高计算访存比来提升性能。
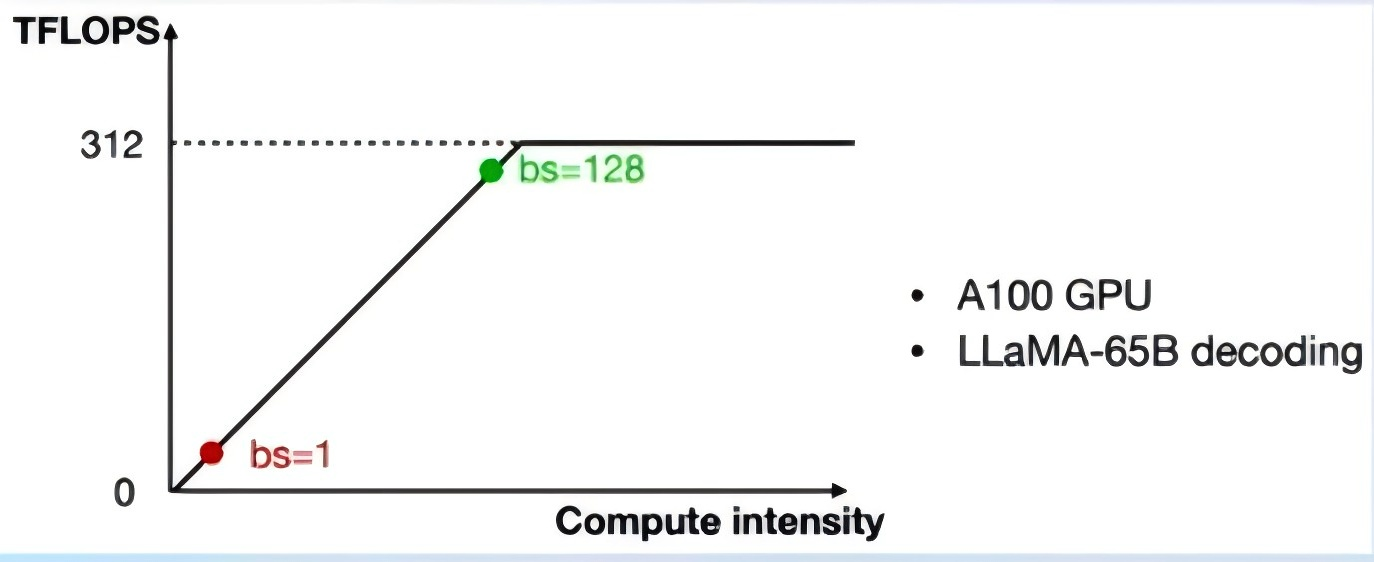
LLM是典型的访存密集型任务,常见的LLM模型是解码器架构。推理时大部分时间消耗在逐个Token生成阶段(Decoding阶段),是典型的访存密集型场景。
如下图,A100 的 FP16 峰值算力为 312 TFLOPS,只有在 Batch Size 达到128这个量级时,计算才成为推理的瓶颈,但由于LLM模型本身就很大,推理时的 KV Cache 也会占用很多显存,还有一些其他的因素影响(如Persistent Batch),实际推理时很难做到128这么大的 Batch Size(很多时候我们在推理大模型的时候,它的计算量没发挥出来,但是显存已经占满了) 。
Weight Only量化一举多得4 bit Weight Only量化,将FP16的模型权重量化为INT4,访存量直接降为FP16模型的1/4,大幅降低了访存成本,提高了解码的速度。
- 加速的同时还节省了显存,同样的设备能够支持更大的模型以及更长的对话长度
4.3.2 如何做Weight Only的量化?
LMDeploy 使用 MIT HAN LAB 开源的 AWQ算法:将模型量化为4bit,推理时,先把4bit权重反量化回 FP16(在Kernel内部进行,从Global Memory读取时仍是4bit),依旧使用的是FP16计算。
- 虽然模型是
4bit,但推理时会比4bit的精度高,比直接使用4bit的精度要高。
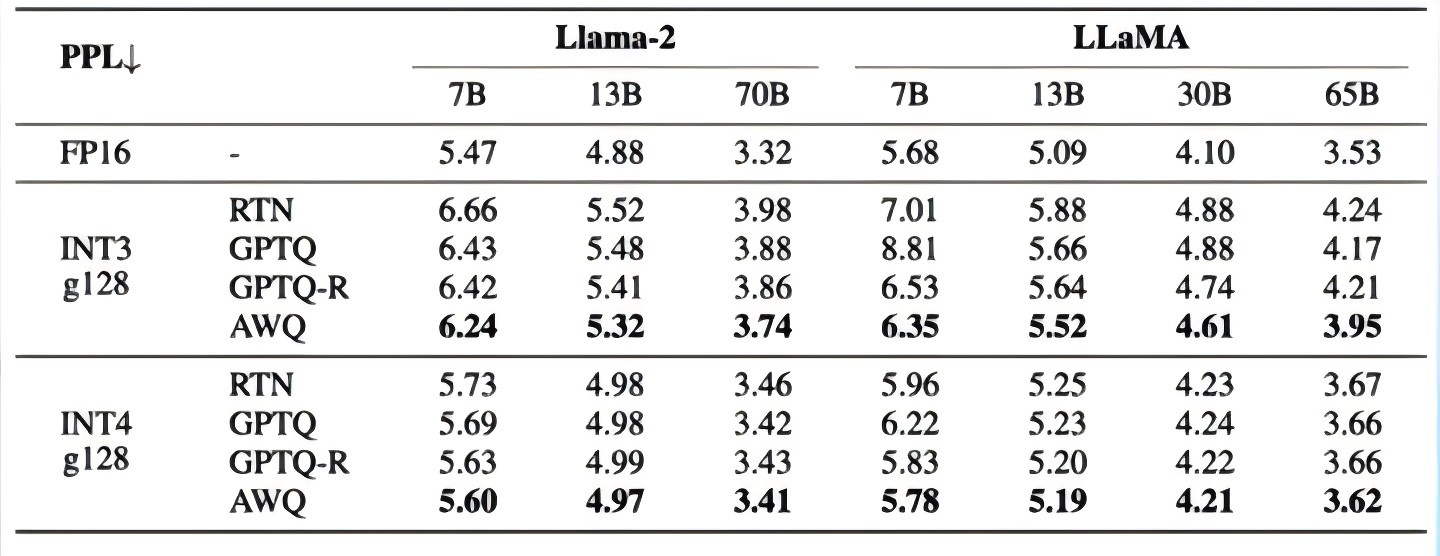
相较于社区使用比较多的
GPTQ算法,AWQ的推理速度更快,量化的时间更短。
对比不同量化等级各种算法的区别:
4.4 核心功能-推理引擎TurboMind
首选
TurboMind而非pytorch。
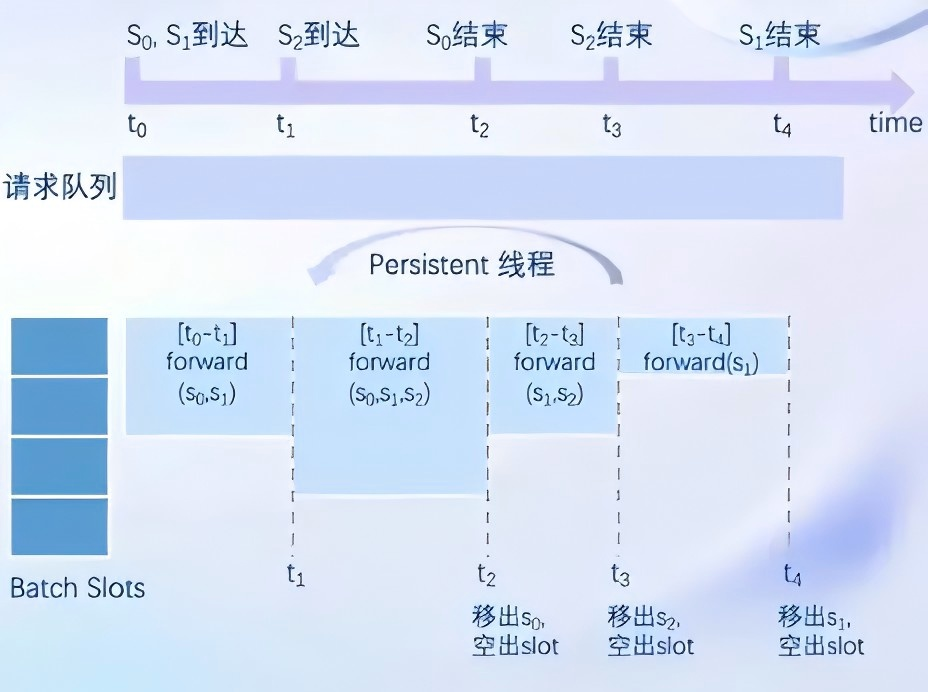
1、持续批处理
请求可以及时加入 batch 中推理,Batch 中已经完成推理请求及时退出。
下图中:虽然 S0S_0S0 和 S1S_1S1 先到达,但它们被分在同一个批次 $[t_0 - t_1] 中,并且可能被分配到同一个计算单元或线程上。中,并且可能被分配到同一个计算单元或线程上。中,并且可能被分配到同一个计算单元或线程上。 S_2$ 虽然后到达,但它可能被分配到一个不同的GPU,这个GPU在处理完 S0S_0S0 和 S1S_1S1 的部分后,可能比处理 S1S_1S1 的GPU更早空闲。因此,S2S_2S2 可以在 S1S_1S1 之前完成处理。
2、有状态的推理
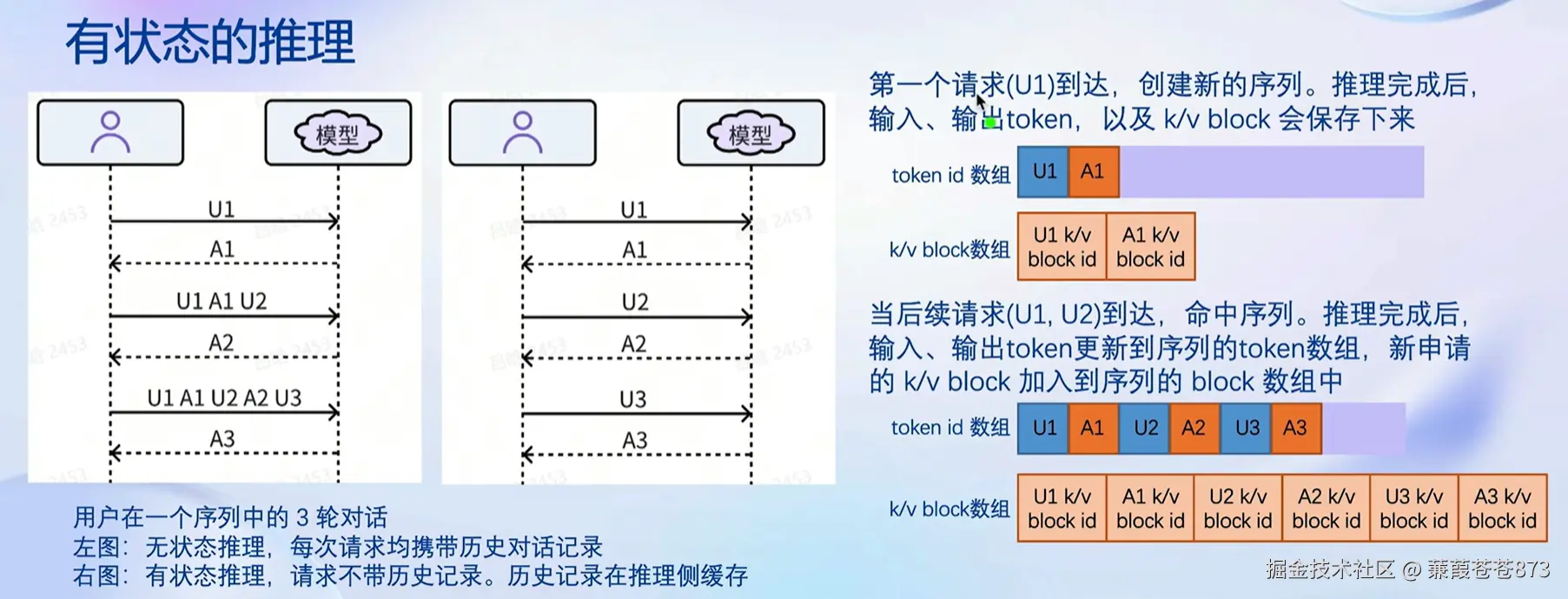
上图表示用户与模型的交互,图中展示了用户在一个序列中的三轮对话:
右图表示无状态推理:在无状态推理中,每次请求都独立处理,不携带历史对话记录。这意味着每次用户发送请求(U1, U2, U3),模型都会独立处理这些请求,生成响应(A1, A2, A3),而不考虑之前的对话内容。
左图表示有状态推理:在有状态推理中,每次请求不仅处理当前的用户输入,还携带之前的历史对话记录。
-
第一个请求(U1):创建新的序列。
- 推理完成后,输入、输出token,以及k/v block(键值对块)会被保存下来,存在显存中(这样才能满足频繁读取,有些模型,支持放在内存,通常用在显存不足,用内存来替代的地方)。
- 图中显示了token id数组和k/v block数组的存储情况。
-
后续请求(U1, U2):
- 命中序列,继续在同一序列中处理。
- 推理完成后,输入、输出token更新到序列的token数组,新申请的k/v block加入到序列的block数组中。
-
这样,模型在生成响应时会考虑之前的对话内容,从而生成更连贯和相关的回复。
具体步骤
第一个请求(U1):
-
输入:U1
-
输出:A1
-
存储:token id数组(U1,A1),k/v block数组(A1的k/v block id)
第二个请求(U1,U2):
-
输入:U1,U2
-
输出:A2
-
更新存储:token id数组(U1,A1,U2,A2),k/v block数组(A2的k/v block id加入)
第三个请求(U1,A1,U2,A2,U3):
-
输入:U1,A1,U2,A2,U3
-
输出:A3
-
更新存储:token id数组(U1,A1,U2,A3),k/v block数组(A3的k/v block id加入)
在有状态推理中,用户与其token以及块(k/v block)的关联是通过对话历史和上下文管理来实现的。以下是详细的解释:
-
序列管理:
-
每个序列都有一个唯一的标识符,用于管理对话历史。
-
当新的请求到达时,系统会检查是否存在与该请求相关的序列。如果存在,系统会命中序列并继续在该序列上进行推理。
-
-
Token ID数组:
-
每个序列都有一个token ID数组,用于存储序列中所有输入和输出的token ID。
-
当新的请求到达时,新的token ID会被添加到相应的token ID数组中。
-
-
K/V块数组:
-
K/V块(键值对块)用于存储模型推理过程中的中间状态,这些状态对于生成连贯的响应至关重要。
-
每个序列都有一个K/V块数组,用于存储序列中所有请求的K/V块。
-
当新的请求到达时,新的K/V块会被添加到相应的K/V块数组中。
-
-
关联机制:
-
用户的每次请求都通过其token ID数组和K/V块数组与特定的序列关联。
-
系统通过这些数组来维护和更新对话历史,确保每次推理都能考虑到之前的对话内容。
-
总结来说,用户与其token以及K/V块的关联是通过对话历史记录、序列管理、token ID数组和K/V块数组来实现的。这些机制确保了有状态推理能够生成连贯和相关的响应。
通过这样的方式可以最大限度的减少显存占用。
3、Blocked k/v cache 机制

图中展示的是 lmdeploy 的 TurboMind 引擎中K/V(键值对)缓存机制的讲解,特别是 Blocked k/v cache 的设计和工作原理。以下是对图中内容的详细解释:
左侧图示:Blocked k/v cach
-
支持功能:
- 支持分页注意力(
Paged Attention) - 支持有状态推理(
Stateful Inference)
- 支持分页注意力(
-
结构:
-
K/V缓存被分为K部分和V部分,分别存储键(Keys)和值(Values)。
-
每个
block的大小(BlockSize)由以下公式计算:BlockSize = 2 × Layers × HeadDim × Seq × B。Layers:模型的层数。HeadDim:每个注意力头的维度。Seq:一个block里的序列长度,默认为128。B:k/v数值精度对应的字节数。 -
对于
llama-7b模型,2K序列长度,k/v block内存为1G。
-
-
状态迁移:
-
缓存状态可以迁移,包括从
Free(空闲)到Active(活跃)的分配(Allocate),以及从Active到Cache的锁定(Lock)和解锁(Unlock)。 -
当缓存空间不足时,可能会发生驱逐(Evict)操作,将某些block从缓存中移除。
-
右侧图示:Block 状态和状态迁移
-
Block状态:-
Free:未被任何序列占用。 -
Active:被正在推理的序列占用。 -
Cache:被缓存中的序列占用。 -
Block状态迁移:-
当序列S0S_0S0到达时,如果有足够的空闲
block,这些block会转为active状态。 -
当S1S_1S1结束时,S0S_0S0占用的
block会转回cache状态。 -
当序列S1S_1S1到达时,如果有足够的空闲block,这些block会转为active状态。
-
如果S2S_2S2申请不到足够的空闲
block,会驱逐S2S_2S2的cache block,将其转为free状态,然后重新获取足够的free blocks(这里驱逐就相当于丢弃,等后面再来再重新计算,一般不会卸载到内存的,因为非常慢)。
-
-
这个过程会随着时间(t0,t1,t2,t3,t4t_0, t_1, t_2, t_3,t_4t0,t1,t2,t3,t4)进行,确保每个序列在推理时都有足够的资源。
-
总结:
Blocked k/v cache机制通过管理block的状态(Free,Active,Cache)和在不同状态之间的迁移,有效地支持了分页注意力和有状态推理。这种设计允许TurboMind引擎在处理连续对话或序列化任务时,能够高效地利用缓存资源,提高推理性能。
- 比如说用
DeepSeek,第一次提问他有了一个答复,第二次一问他告诉你超时了,因为他重新去申请这个缓存的时候,申请不到别人把这个队列给占了。
4、高性能的cuda内核
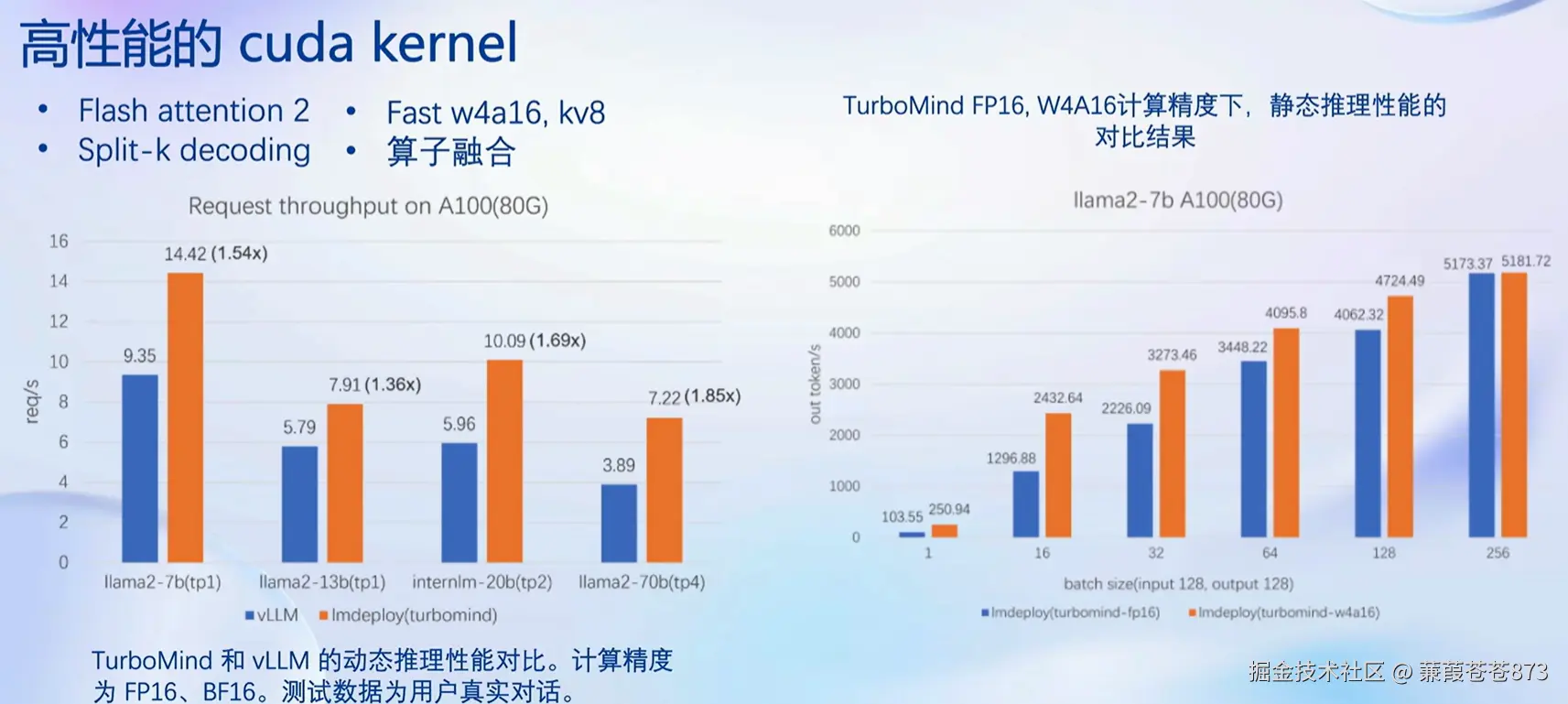
通过 Flash attention 2 对 KV Cache将中间状态的缓存进行分级管理、Split-k decoding、Fast w4a16、 kv8、 算子融合这些方式来进行计算加速或者说解码加速。
5、推理服务api server
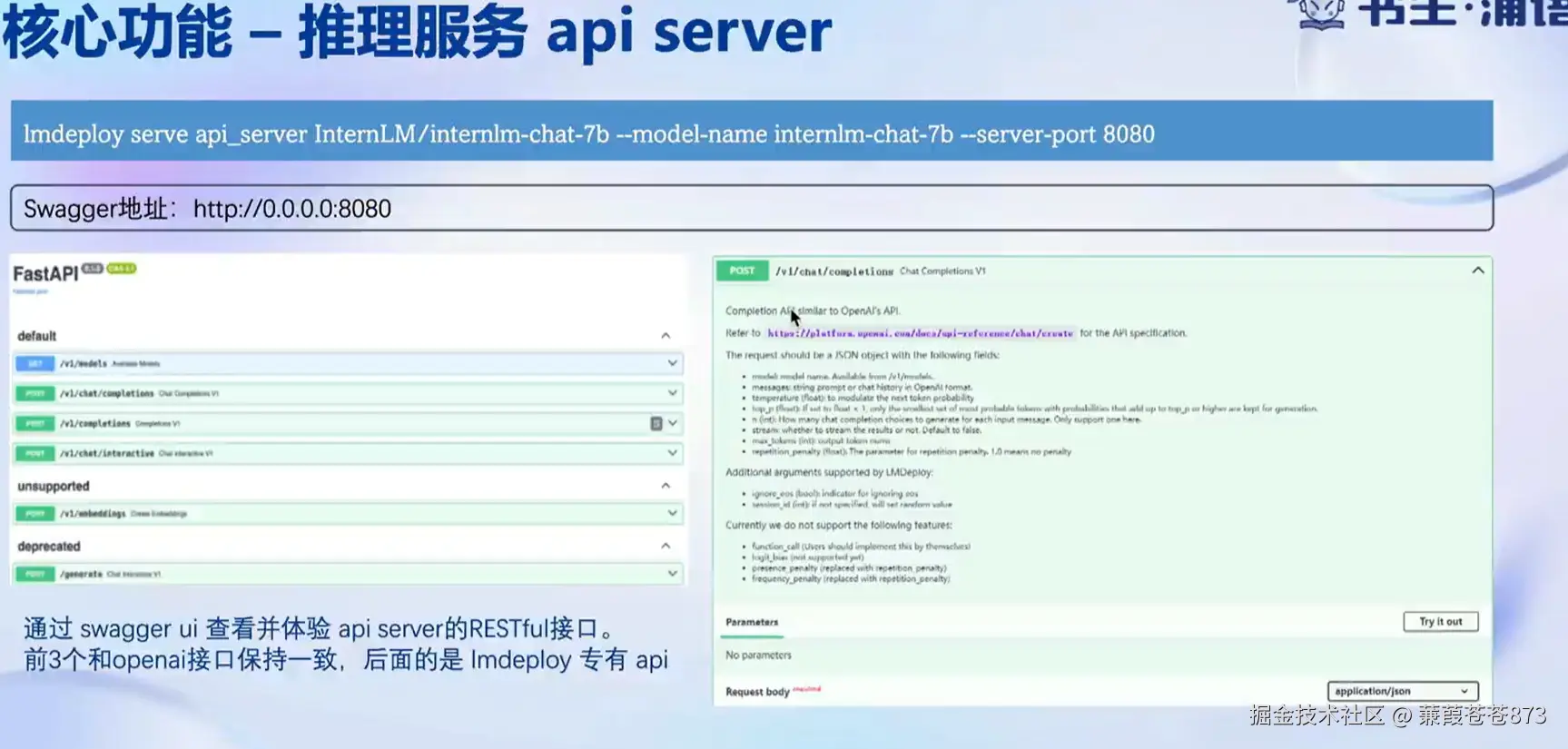
通过:lmdeploy serve_api命令启动 api server,来实现模型推理提供给前端或者后端使用。
4.5 lmDeploy分布式推理
4.5.1 分布式推理实现
核心机制:
-
张量并行: 通过
--tp参数指定GPU数量,支持多卡协同计算 -
KV Cache量化:支持INT8/INT4量化,降低显存占用24%,一种可以让模型在推理过程中进行量化的技术。
-
动态显存管理: 通过
--cache-max-entry-count控制KV缓存比例。
比如说使用lmDeploy推理FP16位模型的时候,可以做两种量化操作:
-
第一个操作:先把这个模型通过框架量化到
int 8或者int 4,这个模型就变成一个8位或者4位的模型了,再去推理它。 -
第二种操作:先不量化这个模型,而是通过
lmDeploy框架加载F16模型的时候对它进行量化,这就是动态的显存管理,它是通过--cache-max-entry-count来控制KV缓存的比例,这是这个lmDeploy框架的一个核心特色。
缓存量化的实现: 通过缓存多轮对话过程中 attention 的 k/v,记住对话历史,从而避免重复处理历史会话。显著提升长文本多轮对话场景中的效率。我们通过缓存多轮对话过程中attention的KV值,来记住对话的历史,从而避免重复处理历史会话;引入这个技术会有一个额外的开销,会使显存占用变高,所以如果用lmdeploy去推理一个模型,从刚开始推理的时候,显存占用会低一些,但是如果这个对话特别长,显存不做控制就会溢出。
4.5.2 进行分布式推理
$ lmdeploy serve api_server \
/root/lanyun-tmp/LLM/Qwen/Qwen2.5-1.5B-Instruct \
--model-format hf \
--quant-policy 0 \
--server-name 0.0.0.0 \
--tp 2 \
--model-name Qwen \
--server-port 23333
-
api_server这个命令用于启动API服务器:--model-format hf:指定了模型的格式,hf代表“Hugging Face”格式;--quant-policy 0:这个参数指定了量化策略;--server-name 0.0.0.0:这个参数指定了服务器的名称。在这里,0.0.0.0是一个特殊的IP地址,表
示所有网络接口;--tp设置张量并行;--session-len设置推理的最大上下文窗口长度;--cache-max-entry-count调整k/v cache的内存使用比例--cache-max-entry-count这个参数不建议去设置,在不填参数的情况下默认进行配置
-
--model-name Qwen:指定模型Qwen名称后,即可在api调用:
# 未指定--model-name Qwen时,需要写Qwen的绝对路径
chat_complition = client.chat.completions.create(messages=chat_history,model="/root/lanyun-tmp/LLM/Qwen/Qwen2.5-1.5B-Instruct")# 指定--model-name Qwen后,修改为:
chat_complition = client.chat.completions.create(messages=chat_history,model="Qwen")
4.6 lmDeploy模型量化
随着模型变得越来越大,我们需要一些大模型压缩技术来降低模型部署的成本,并提升模型的推理性能。
LMDeploy提供了 权重量化 和k/v cache两种量化策略。
4.6.1 k/v cache量化
1)设置最大kv cache缓存大小
kv cache是一种缓存技术,通过存储键值对的形式来复用计算结果,以达到提高性能和降低内存消耗的目的。在大规模训练和推理中,kv cache 可以显著减少重复计算量,从而提升模型的推理速度。理想情况下,kv cache 全部存储于显存,以加快访存速度。
模型在运行时,占用的显存可大致分为三部分:模型参数本身占用的显存、kv cache占用的显存,以及中间运算结果占用的显存。LMDeploy 的 kv cache 管理器可以通过设置 --cache-max-entry-count 参数,控制 kv 缓存占用剩余显存的最大比例。默认的比例为0.8。
设置kv 最大比例为0.4,执行如下命令:
$ lmdeploy chat /root/models/internlm2_5-7b-chat --cache-max-entry-count 0.4
2)设置在线 kv cache int4/int8 量化
自 v0.4.0 起,LMDeploy 支持在线 kv cache int4/int8 量化,量化方式为 per-head per-token 的非对称量化。此外,通过 LMDeploy 应用 kv 量化非常简单,只需要设定 quant_policy 和cache-max-entry-count参数。
目前,
LMDeploy规定qant_policy=4表示kv int4量化,quant_policy=8表示kv int8量化。
$ lmdeploy serve api_server \
/root/models/internlm2_5-7b-chat \
--model-format hf \
--quant-policy 4 \
--cache-max-entry-count 0.4\
--server-name 0.0.0.0 \
--server-port 23333 \
--tp 1
从直观上看,量化 kv 有利于增加
kv block的数量。与fp16相比,int4/int8 kv的kv block分别可以增加到 4 倍和 2 倍。这意味着,在相同的内存条件下,kv 量化后,系统能支撑的并发数可以大幅提升,从而最终提高吞吐量。但是,通常量化会伴随一定的模型精度损失。我们使用了
opencompass评测了若干个模型在应用了int4/int8量化后的精度:int8 kv精度几乎无损,int4 kv略有损失。
这种量化的优势在于模型依然是16位的,但是模型是以8位的形式来推理的,它的推理速度会更快,虽然从nvitop看显存占用看不出来,因为这个显存的占用是由框架来分配的,所以用nvitop看它是一模一样的,它最大的区别在于,现在模型可以输入更长的长度。
4.6.2 权重量化
W4A16 模型量化和部署
准确说,模型量化是一种优化技术,旨在减少机器学习模型的大小并提高其推理速度。量化通过将模型的权重和激活从高精度(如16位浮点数)转换为低精度(如8位整数、4位整数、甚至二值网络)来实现。
那么标题中的 W4A16 又是什么意思呢?
-
W4:通常表示权重量化为4位整数(int4)。这意味着模型中的权重参数将从它们原始的浮点表示(例如Internlm2.5精度为BF16)转换为4位的整数表示。这样做可以显著减少模型的大小。 -
A16:这表示激活(或输入/输出)仍然保持在16位浮点数(例如FP16或BF16)。
激活是在神经网络中传播的数据,通常在每层运算之后产生。因此,W4A16的量化配置意味着:
-
权重被量化为4位整数。
-
激活保持为16位浮点数。
在最新的版本中,LMDeploy 使用的是 AWQ 算法,能够实现模型的 4bit 权重量化。输入以下指令,执行量化工作。(本步骤耗时较长,请耐心等待)
$ lmdeploy lite auto_awq \
/root/models/internlm2_5-7b-chat \
--calib-dataset 'ptb' \
--calib-samples 128 \
--calib-seqlen 2048 \
--w-bits 4 \
--w-group-size 128 \
--batch-size 1 \
--search-scale False \
--work-dir /root/models/internlm2_5-7b-chat-w4a16-4bit
命令解释:
lmdeploy lite auto_awq:LMDeploy用于启动量化过程,而auto_awq代表自动权重
量化(auto-weight-quantization)。--calib-dataset 'ptb':指定了一个校准数据集,这里使用的是’ptb’(Penn Treebank:一
个常用的语言模型数据集)。--calib-samples 128:指定了用于校准的样本数量,128个样本--calib-seqlen 2048:指定了校准过程中使用的序列长度,1024--w-bits 4:表示权重(weights)的位数将被量化为4位。--work-dir /root/models/internlm2_5-7b-chat-w4a16-4bit:这是工作目录的路径,用于存储量
化后的模型和中间结果。
输出日志如下:
Move model.layers.13 to CPU.
Move model.layers.14 to CPU.
Move model.layers.15 to CPU.
Move model.layers.16 to CPU.
Move model.layers.17 to CPU.
Move model.layers.18 to CPU.
Move model.layers.19 to CPU.
Move model.layers.20 to CPU.
Move model.layers.21 to CPU
......
等待推理完成,便可以直接在你设置的目标文件夹看到对应的模型文件。
推理后的模型和原本的模型区别是:模型文件大小以及占据显存大小。
我们可以输入如下指令查看在当前目录中显示所有子目录的大小:
$ cd /root/models/
$ du -sh *
0 InternVL2-26B
0 internlm2_5-7b-chat
4.9G internlm2_5-7b-chat-w4a16-4bit
(lmdeploy) root@intern-studio-50009084:~/models#
那么原模型大小呢?输入以下指令查看:
$ cd /root/share/new_models/Shanghai_AI_Laboratory/
$ du -sh *
17G internlm-xcomposer2-4khd-7b
17G internlm-xcomposer2-7b
6.6G internlm-xcomposer2-7b-4bit
4.6G internlm-xcomposer2-vl-1_8b
17G internlm-xcomposer2-vl-7b
74G internlm2-20b-chat-xxx
3.6G internlm2-chat-1_8b
7.1G internlm2-chat-1_8b-sft
37G internlm2-chat-20b
37G internlm2-chat-20b-sft
15G internlm2-chat-7b
15G internlm2-chat-7b-sft
15G internlm2-math-7b
15G internlm2-math-base-7b
37G internlm2-math-plus-20b
38G internlm2-wqx-20b
41G internlm2-wqx-vl-20b
3.6G internlm2_5-1_8b
3.6G internlm2_5-1_8b-chat
37G internlm2_5-20b-chat
15G internlm2_5-7b-chat
15G internlm2_5-7b-chat-1m
对比发现,模型的大小 15G 和 4.9G ,差异还是比较大。
可以输入下面的命令启动量化后的模型:
$ lmdeploy chat /root/models/internlm2_5-7b-chat-w4a16-4bit/ --model-format awq
补充:W4A16 量化 + KV cache + KV cache 量化
输入以下指令,让我们同时启用量化后的模型、设定 kv cache 占用和 kv cache int4 量化:
$ lmdeploy serve api_server \
/root/models/internlm2_5-7b-chat-w4a16-4bit/ \
--model-format awq \
--quant-policy 4 \
--cache-max-entry-count 0.4\
--server-name 0.0.0.0 \
--server-port 23333 \
--tp 1