SPAR类比推理模型学习(与常见小目标检测方法总结)
代码链接:Analogical-Reasoning
传统目标检测
RCNN
1. Selective Search:初始分割+相似区域(颜色、纹理)合并,生成候选框(约2000个)
2. 特征提取:对所有候选框进行裁剪缩放,输入到CNN中提取特征
3. 分类:将所有候选框特征送进多个SVM分类器(二分类模型),选择置信度最高的类别
4. 边界框回归:对正样本(IoU较高)的候选框做线性回归,修正框的大小和位置,让预测更接近目标真实边界
Faster RCNN
相对于普通RCNN:引入了RPN(Region Proposal Network)
1. 直接对整张图片进行特征提取
2. 生成候选框(RPN):判断anchor内是否有目标(置信度)+偏移量
3. Rol Pooling:把不同大小的候选框区域映射到特征图上,并池化成固定大小
4. 根据特征图得到类别
Yolo
1. 缩放图像到固定大小,特征提取(DarkNet)
2. 把图像分割成S*S的网格,每个网格负责预测落在该网格中心的物体
3. 预测内容(每个网格):
B个边界框:中心坐标(x,y)、高宽(w,h)
置信度:边界框内包含物体的置信度(P*IoU,预测框和真实框的交并比)
C个类别概率分布:每个已知类别的概率
输出张量:S*S*(B*5+C)(后续优化了边界框的参数化和解码方式:Anchor Box+偏移量,多尺度(分辨率)预测,损失函数优化)
4. 组合预测结果:对于一个边界框的Class Confidence=confidence * P(Class|Object)
5. NMS非极大值抑制:选取分数最高的检测框去掉与它IoU大于阈值的其它框,循环直至没有候选框
前言
卫星遥感图像检测的挑战:物体尺寸较小,动态背景
目前解决方向
1. 区域划分+局部放大,提升密集目标检测效果
2. 增加网络结构模块以提升特征提取效果(注意力机制/多尺度特征融合)
高分辨率:保留更多细节,但语义信息弱
低分辨率:目标位置模糊,但语义信息强
3. 图像增强技术
Related Works
1.1 ClusDet
先通过类似Faster-RCNN的方式生成集群区域检测框,得到映射后的特征图(Rol Pooling),对该集群区域进行检测,与全局检测结果进行NMS
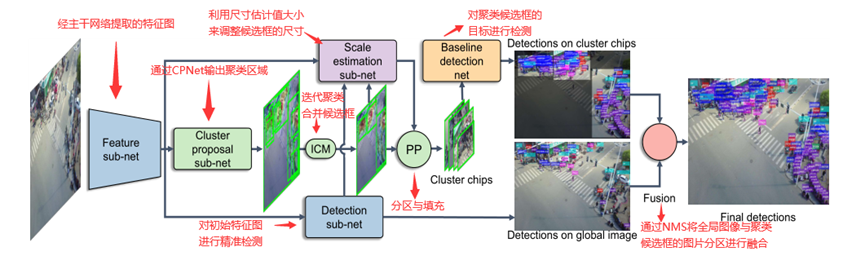
1.2 Casceded zoom-in
添加“crop”类,截取图像中物体密集区域标注为新类别,上采样后与原始图像一起加入训练,多级级联获得更详细子图。在推理时类似:识别基础类别物体与物体密集区,对高质量物体密集区(IoU合并结果)上采样后推理,合并检测结果
———————————————————————————————————————————
一点想法:先通过人工标注的物体密集区训练一个大模型,在该训练过程中,模型会截取物体密集区域并做裁剪、上采样等操作并合成为一个新的数据集,该数据集作为无监督学习/弱监督学习数据集在刚才的大模型基础上做微调。(大模型打伪标签/对比学习/半监督)
三路结构:
Backbone路:在无标注数据上做自监督预训练,学习图像特征,得到backbone初始化权重
Cluster路:训练Cluster Proposal Net:用少量密集区标注学习哪里有目标簇,裁切、上采样,生成密集区子图
Instance路:用少量实例级标注训练初始Teacher,Teacher给密集区子图&原图打伪标签用于Student半监督学习
训练阶段:
1. 自监督预训练(MAE/对比学习)
2. 双头监督预热:CPN头和Instance检测头,训练框簇预测模型和实例预测模型(Teacher v0)
3. 生成伪标签:CPN在无标签图上做预测+上采样获得子图,Teacher分别在原图和子图做推理,得到候选框做NMS作为伪标签
4. 半监督Student训练:监督损失(有标注)+无监督损失(未标注+弱标注)训练Student;Teacher更新
5. 迭代自训练:用当前更新的Teacher刷新伪标签,再训练
———————————————————————————————————————————
1.3 Adazoom
基于强化学习。
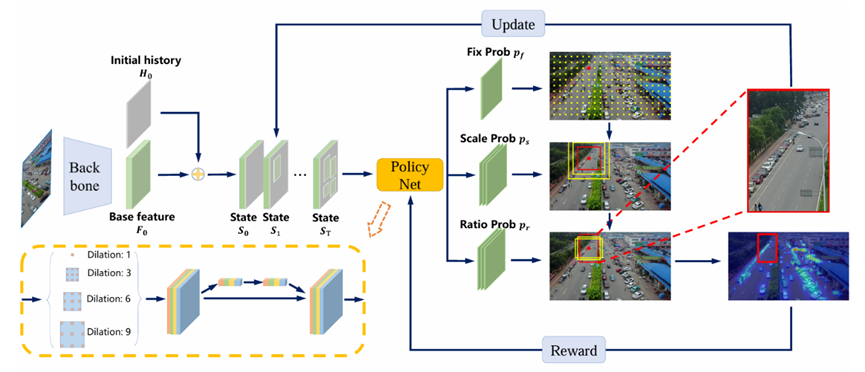
状态State:基础特征图+历史信息图(记录已被采样的区域)
动作Action:PolicyNet:动作被解耦为三类分量:Fixation(定位)、Scale(尺度)、Aspect ratio(长宽比);分别预测作为focus区域并用policy gradient优化
奖励Reward:对落在focus region内每个目标赋予权重(小目标高权重),region大尺度(与目标尺度相比)会被赋予系数衰减
检测网络:在原图和AdaZoom生成并放大的region上做检测;AdaZoom生成对检测有帮助的区域,检测器的输出反过来调整AdaZoom的reward(对检测器容易错过或置信度低的真实目标增加权重)
2.1 TPH-Yolo v5
在Yolo v5的基础上引入了注意力模块和多尺度融合
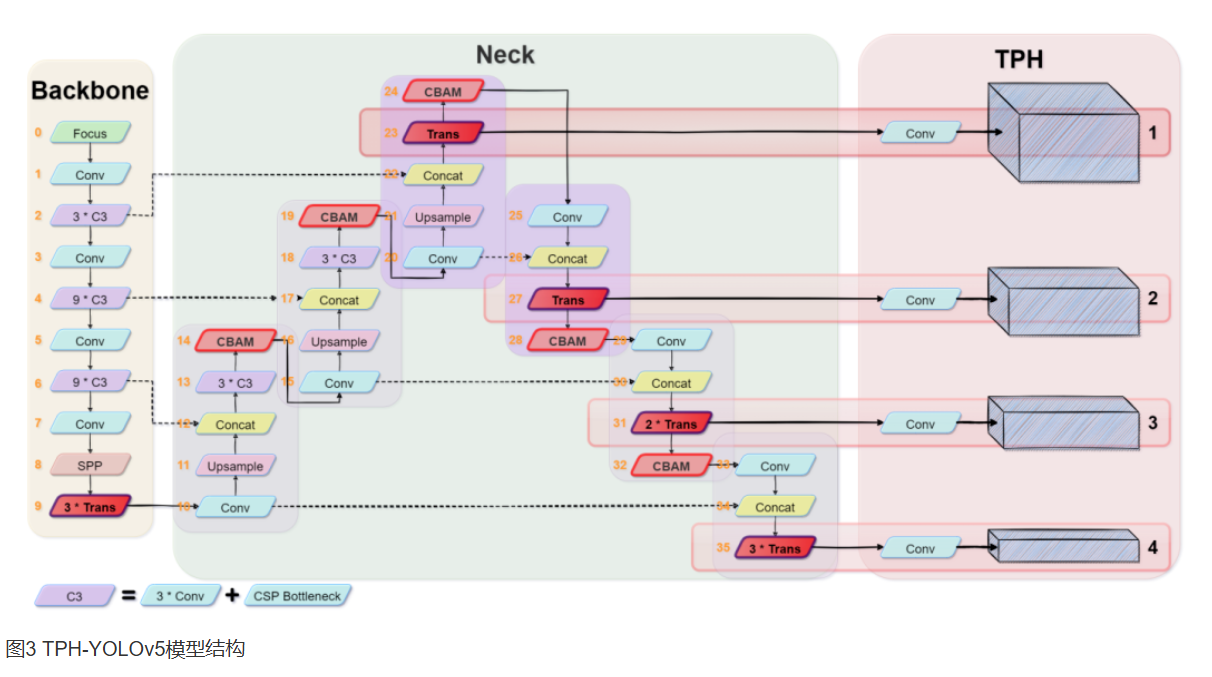
Backbone
Focus:把图片切分成4个部分并堆叠,类似对一张图片的Mosaic
Conv+C3(CSP Bottleneck):卷积层+跨阶段部分残差结构,提取特征
SPP:多尺度池化
Trans:用Transformer层代替部分卷积块,增强全局建模
Neck
Upsample+Concat:上采样+与浅层特征拼接
CBAM:通道注意力+空间注意力;输入特征按通道加权


TPH
在检测头中引入Transformer层:图像C、H、W(通道数、高度、宽度)展平成N*C(N=H*W),相当于一段长度为通道数的序列,每个“词”的维度数是图片像素数量
———————————————————————————————————————————
(基础知识学习)
1. 数据增强方法:扩展数据集,提升模型泛化能力。包括:Photometric(对图像色相、饱和度进行调整)、Geometric(对图像随机缩放、平移、裁剪、旋转等)、MixUp(通过线性插值生成新的图像和标签)、CutMix(切割并拼接两张图像的不同区域生成新的训练样本,混合标签)、Mosaic(将四张不同的图像按一定比例拼接成新的图像,调整标签)
2. 目标检测结果混合方法:多模型检测结果合并。包括:非极大值抑制(NMS)、Soft-NMS(根据IoU值对相邻边界box的置信度设衰减函数,而不是直接将其删除)、Weighted Boxes Fusion(WBF,通过加权平均来融合候选框,而不是抛弃)
3. 基于CNN的物体检测分类:
(1)One-Stage检测器:直接在图像的每个位置做端到端预测,无需生成候选框,例如Yolo v3
(2)Two-Stage检测器:先生成一组候选框,再对框进行精细预测,例如Faster-RCNN
(3)Anchor-Based检测器:使用预设的多尺度锚框,每个锚框代表一个潜在目标的位置, 训练尺度和比例,例如Scaled-Yolo v4、Yolo v5等
(4)Anchor-Free检测器:无需锚框,直接通过像素位置进行目标预测,例如YoloX
(5)无人机专用检测器:RRNet、PENet、CenterNet等
4. 检测器的组成
(1)Backbone:特征提取
(2)Neck:负责对特征图进行处理、融合和强化,包括:多尺度特征融合、通过额外层(自注意力层等)提高模型在复杂场景的辨识能力
(3)Head:检测头,输出目标类别和边界框
———————————————————————————————————————————
2.2 Sifdal
SIFDAL 利用通道拆分 + 对抗训练让模型分别学习“scale-related”(与尺度相关)和“scale-invariant”(与尺度无关)的特征,增强小目标检测对尺度变化的鲁棒性
3.1 CoOp
CoOp用可学习的上下文提示替代人工写的 prompt,并通过对比学习来优化,使 CLIP 在下游任务的表现更强。
CLIP在下游任务上zero-shot prediction的text encoder输入的text是固定的,例如:“A photo of a {object}”;而在CoOp中,输入的text是learnable的,它会随着下游任务的few-shot样本而更新。
CoOp设计了两种learnable prompt:
1. Unified Context
此时,输入text encoder的prompt可以表示为:
或者:
2. Class-Specific Context (CSC)
每个类别都有一个自己的Unified Context
3.2 EDA
EDA引入 对象级别的标注或检测,知道图像里的每个对象区域(bounding box)是什么;然后要求这些对象区域的特征和文本里的相应词语也要对齐。也就是说,EDA 方法利用对象级别的标注来指导训练,使模型不仅在全局上对齐图像和文本,还在局部对象-词语层面对齐,从而捕捉更细致的语义信息。
3.3 GLIP
GLIP把图片分成很多候选区域/边界框(region proposals);把文本拆分成短语;学习让 边界框特征 ↔ 文本短语特征 对齐。它通过学习这种跨模态对齐,使模型可以在更广泛的类别和场景下进行检测,而不仅仅局限于训练数据集里的预定义类别。
4.1 Vild
训练一个 学生探测器 (detector),学生的 区域嵌入 (region embedding) 要和 教师(teacher)CLIP 推断出的图像/文本嵌入 保持一致。
4.2 GridClip
将图像分成多个小 patch,每个 grid cell 经过视觉编码器(如 ResNet / ViT),得到一个 局部特征向量;将类别文本提示(如 "a photo of a dog")处理成若干词或短语 embedding;这些短语嵌入与图像的 局部 grid 特征 一一对齐。(类似EDA)
4.3 ProposalCLIP
用 CLIP 来做 弱监督/无监督目标检测。
4.4 ARegionClip
把 CLIP 扩展到 区域级 (region-level) 的预训练,显式学会 区域 ↔ 文本短语 对齐。
———————————————————————————————————————————
EDA:需要bounding box和标签来学习;GridCLIP:无bounding box,而是切割图像学习对齐;ARegionCLIP:生成一些候选框(不确定正确性),再学习区域和文本的对齐。
———————————————————————————————————————————
4.5 DenseCLIP
提取图像 密集特征(feature map),每个位置(像素/patch)都保留一个特征;把每个视觉位置的特征和文本 embedding 做对齐。
5. 目标检测中的关系推理 (Relational Reasoning)
5.1 基于上下文信息 (Contextual reasoning)
SMN:把多个目标实例整合成一个“伪图像 (pseudo-image)”,让模型在更大的上下文里做推理。
GCRN:用 图神经网络 (graph-based) 来建模上下文,帮助发现“出格”的物体(out-of-context objects),比如“鱼在天上”这样的不合理场景。
5.2 基于空间与语义关系 (Spatial & semantic reasoning)
Reasoning-RCNN:把全局语义知识和推理机制融合到 Faster R-CNN 框架中,改进分类和边界框回归。
C-GCN:用图卷积网络 (GCN) 来建模目标间的 两两关系(pairwise relations),特别适合小目标检测,因为小目标往往依赖周围上下文才能识别。
———————————————————————————————————————————
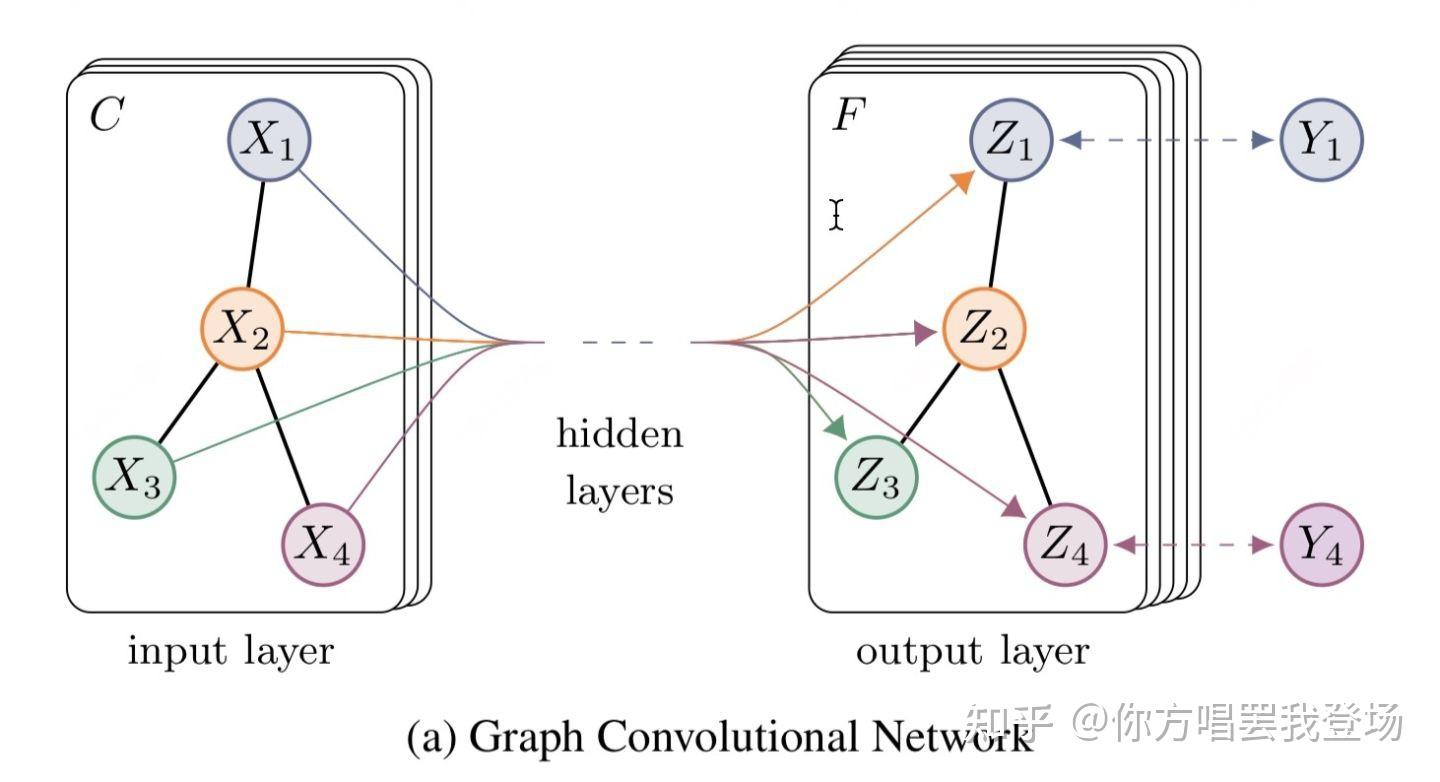
图卷积网络(GCN)
关键概念:
1. 邻接矩阵
表示节点i和j之间有一条边,否则为0;对于无向图,邻接矩阵是对称的(
);邻接矩阵用来表示图的连接结构,即决定“信息从哪些节点传播到哪些节点”
2. 度矩阵
是对角矩阵,第i个对角元素
=节点i的度(degree),也就是它和多少个邻居相连:
度矩阵用于归一化邻接矩阵,防止度数高的节点信息过强、度数低的节点信息过弱。
3. 拉普拉斯矩阵
对任意节点特征向量,考虑二次型:
又因为对称矩阵满足:
所以:
因此,如果两个相连节点特征i和j相差很大,这项就会贡献很大的能量,所以为了让尽量小,就要让相连的节点
尽量接近,从而鼓励相邻节点的特征值相似。
GCN主要用于解决只有少部分标签已知的节点分类问题
原理:
1. 在GCN中,每个节点(node)都有一组描述它的特征(feature);假设有5个节点,每个节点的NLP特征嵌入为一个3维向量,则总的特征矩阵为一个5*3的矩阵
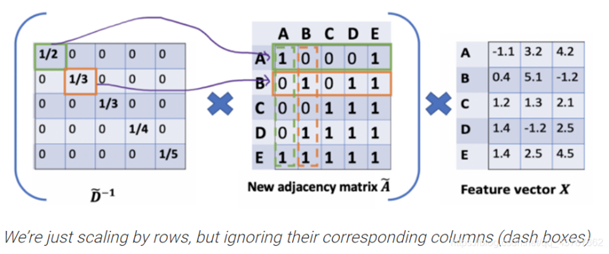
2. 我们对每个节点计算包括其本身的所有相连节点的特征平均值,得到平均特征矩阵;具体来说,假设邻接矩阵5*5表示节点相连信息,将邻接矩阵与特征矩阵相乘即可得到所有邻接特征向量的加权和,如下图所示:

但是这样直接相乘有两个问题:这个加权和并没有包括节点本身的信息,同时特别大或特别小的特征向量相乘时可能导致梯度爆炸或者梯度消失的问题;对于这两个问题,GCN提出:
(1)加自环
我们会先把邻接矩阵改成:
其中,为单位矩阵,
通常取 1,表示给每个节点加一条“自环边”,让节点在聚合邻居信息时也保留自己的特征;通过调整
,我们还能控制“自己 vs 邻居”的重要性比重。
(2)通过对度矩阵求倒数来计算平均
我们会对邻接矩阵做归一化,即:
或者:
其中是自加环后对应的度矩阵。这样,每个节点更新后的特征是它所有邻居特征的加权平均,而不是仅仅简单加和。避免了梯度的问题。
上面的过程可以如下图所示:
3. 由上所述,GCN层公式为:

整个计算过程包括:
(1)加自环:
(2)归一化邻接矩阵:
(3)特征传播:
(4)线性变换:乘权重矩阵,做特征空间映射
(5)非线性激活
输出得到下一层节点特征。
———————————————————————————————————————————
SPAR
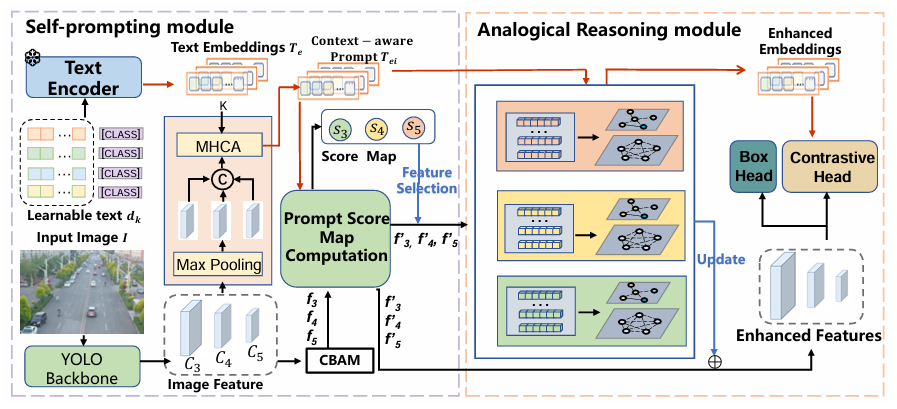
Self-Prompting模块
目的:把图像特定的上下文语义注入类别文本embedding,使文本embedding能更好指引像素级注意力,从而找到“更可能包含目标”的像素位置。
1. Prompt构造
每个类别的描述为:
其中,表示 N 个可学习的 prompt tokens,每个 token 是一个
维向量(embedding),它们在训练中像模型参数一样更新,不对应具体词,而是用来学习最佳的上下文表示。(类似CoOp)
然后通过 CLIP-text encoder 得到文本 embedding:
结果,对所有类别组合成矩阵
(每个类别对应一个文本embedding)。
2. 将局部视觉特征与文本进行交互
把 backbone 的三个尺度特征 做 max-pool 到 4×4,每个尺度变成 16×C,再把三尺度 concat 成
。这样把多尺度语义汇聚进一个小矩阵,便于跨尺度上下文融合。
然后对文本与图像做多头交叉注意力(text as Query,visual as Key/Value):
相当于Query是需要主动查找信息的对象;Key/Value相当于特征库,用于提供信息。

3. 得到 context-aware prompt
( 是可学习缩放因子)。这样每个类的文本 embedding 就包含了“当前图像的上下文信号”。
4. 生成 prompt score map
对每个尺度的视觉 feature map ,计算与
的相似度:
表示图像特征中,第
张图像在空间位置(h,w)的特征向量;
表示类别k的文本嵌入;
是可学习的缩放和偏置参数(scaling & bias),相乘后即可得到
,表示每个空间像素与类别K的相似度分数。得到每个位置的 prompt score:
5. 用 score map 更新视觉特征
是sigmoid,这样在高 objectness 的位置放大特征,在低区下降低响应,从而得到被提示增强的多尺度视觉表示。
总结Self-Prompting过程:
Self-Prompting = 自动生成图像相关的 prompts → prompts 与视觉特征交互得到相似度分布 → 用这个分布来引导/更新视觉特征,使模型专注于语义相关区域。
Analogical Reasoning(图推理)模块
目标:利用语言级别(类别语义)与像素级(视觉)之间的关系,通过图结构传播语义/特征,使“容易识别/语义明确”的节点把信息传给“难以检测/视觉模糊”的节点,从而实现类比式推断(analogical inference)。
1. 构图(Graph Construction)
类别节点:从 self-prompting 得到的更新后文本 embedding ,一共K个
像素节点:从增强后的特征图中选出 M 个高分区域,每个位置的特征向量就是节点特征。
把它们拼接,得到节点特征矩阵:
边和邻接矩阵:用节点之间的相似度(可学习度量 + 内积)构造邻接矩阵:
其中是
卷积变换,用于调整特征空间的维度,使不同尺度的原始特征能投影到一个最合适做相似度计算的空间;
是可学习对角矩阵,用以给不同特征维度不同的权重。这样设计可以让模型学习到“哪些特征维度更重要、哪些要被抑制”,实现可训练的相似度度量。
加自环:
计算度矩阵:
2. 归一化
对邻接矩阵做归一化,得到邻居特征的加权平均值:
3. 图卷积传播
更新节点特征:聚合邻居特征,得到加权平均;线性变换到新特征空间;非线性激活;
经过L层后,得到更新后的节点特征(分别用类别节点特征和像素节点特征表示):
4. 回写特征图
把更新后的像素节点特征回填到原始空间位置:
m表示对M个高分区域进行更新,文本节点也同时进行更新。
分类头与损失函数
1. 逐像素打分
增强后的特征图为:
更新后的类别文本嵌入为:
把每个位置的向量与所有类别向量做点积:
归一化得到类别分布(类似DenseCLIP):
2. 像素级标签
这样处理在计算损失时对图像标注的要求较高,要求每个像素都包含像素级标签;SPAR在训练时检测标注 (b, c)(框与类别)投影成像素级 one-hot 标签图:
对位于某个 GT 框内部的像素 (把二维坐标展平为索引
),其标签向量
在对应类别位置为 1,其余为 0;
背景像素则是全 0 向量(通常也会通过采样/权重进行平衡)。
3. 分类损失

将该损失与YOLO backbone损失结合:
得到最终损失函数。
改进方向
1. 将图卷积替换为更灵活的 图注意力(GAT)或 Transformer-on-graph,并尝试对类别节点做多提示(prompt ensemble);
2. 研究如何高效批处理可变大小图(e.g. 使用稀疏邻接或分组机制);
3. 结合 Region-proposal(而非像素网格)以获得更精确的局部节点(类似 ViLD/ARegionCLIP 的思路);
4. 研究是否把 CLIP 文本 encoder 微调(或保留冻结)对性能的影响。
全文总结
传统目标检测方法大多直接在图像上进行处理,并依赖于对检测框的回归和调优。随着 Transformer 的引入,以及 ViT、CLIP 等跨模态模型的发展,如何将文本信息与图像特征有效融合,成为提升目标检测性能的重要方向。针对小目标检测,现有研究大致可分为以下几类:
-
区域聚焦类方法(ClusDet、AdaZoom、Cascaded Zoom-in):通过显式选择或强化学习聚焦于目标密集区域,从而提升小目标的召回率。
-
骨干改进类方法(TPH-YOLOv5、SIFDAL):增强网络的全局建模能力和对尺度变化的鲁棒性。
-
跨模态对齐类方法(CoOp、EDA、GLIP、GridCLIP、DenseCLIP):引入文本提示和局部对齐,使检测器能够处理开放词表任务,并捕捉细粒度的语义关系。
-
关系推理类方法(SMN、C-GCN):通过建模上下文与目标间的空间或语义关系,提升复杂场景下的检测精度。
在此基础上,SPAR 提供了一种全新的“类比推理”思路。它不仅关注目标的外观特征,更关注上下文语义,并融合了 CLIP 风格的图文对齐机制,将容易检测目标的上下文信息迁移到小目标和困难目标的识别上:
-
Self-Prompting 阶段:生成的文本嵌入不再是静态模板,而是与当前图像交互后的结果,携带了图像特有的上下文语义,例如“车在马路上”这种组合信息。
-
Analogical Reasoning 阶段:类别节点作为图中的一部分,通过图卷积与像素节点进行双向信息传播。如果某个像素节点对应一辆难以识别的小车,它会从“容易识别的大车”节点吸收语义特征,包括“车一般出现在马路上”的上下文线索,从而补强自身特征。
-
特征增强与分类:更新后的像素特征被回写到特征图,分类头再与更新后的类别嵌入对齐,使得小目标能够借助上下文和类比信息被更可靠地判定。
综上,SPAR 通过文本嵌入更新、图卷积推理和特征增强多阶段协同,将上下文语义逐步融入检测过程,实现了从“容易目标”到“小目标”的语义迁移。这种方法突破了单纯依赖局部外观的检测范式,为小目标和困难目标的识别提供了新的解决思路。