DataCollatorForLanguageModeling 标签解析(92)
DataCollatorForLanguageModeling 标签解析
- 老兄,我的标签去哪儿了?
- DataCollatorForLanguageModeling
- 补充说明
老兄,我的标签去哪儿了?
到目前为止,我们一直把标签视为理所当然。在语言建模中,核心任务是“下一个token预测”,因此输入和标签之间唯一的区别就是标签会向后偏移一个位置,这一点是合理的。当我们教模型学习人类语言的结构时,相同的数据——即文本序列,既充当输入,又充当输出。
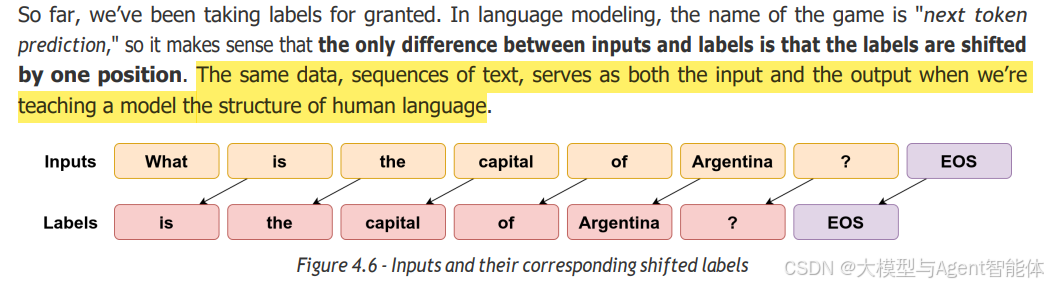
所以,除非你要在明确的有监督任务(例如判断是否为垃圾邮件、情感分析)上对模型进行微调,否则你其实无需担心为数据分配标签,也无需担心(前文提到的)标签偏移问题。当然,这是假设你使用的是Hugging Face生态系统的前提下。
尽管如此,我们仍需深入探究在底层机制中,输入数据究竟经历了怎样的处理过程。
DataCollatorForLanguageModeling
顾名思义,这个整理器(collator)是为语言建模构建的,或者说,是为自监督任务构建的。要知道,在这类任务中,标签与输入完全相同(只是会有偏移,这一点我们很快会详细说明)。
这是我们将在下一节讨论的SFTTrainer类所使用的默认整理器。因此,如果你是对数据集进行填