Kafka 学习笔记
文章目录
- 一、消息队列应用场景
- 二、Kafka 集群搭建
- 三、消息测试
- 四、Java API
- 五、Kafka 相关概念
- 六、Kafka 幂等性
- 6.1 Kafka 幂等性的背景
- 6.2 Kafka 幂等性机制
- 七、分区和副本
- 7.1 生产者分区写入策略
- 1️⃣ 轮询分区策略
- 2️⃣ 随机分区策略
- 3️⃣ 按 Key 分区策略
- 4️⃣ 自定义分区策略
- 7.2 Rebalance 机制
- 7.3 消费者分区消费策略
- 1️⃣ RangeAssignor
- 2️⃣ RoundRobinAssignor
- 3️⃣ StickyAssignor
- 7.4 副本的 ACK 机制
一、消息队列应用场景
- 异步处理:当系统中某些任务耗时较长(如发送邮件、图片处理、视频转码、接口调用等),可以将任务发送到消息队列中,由后台异步处理,提高主流程的响应速度和系统吞吐量。如:用户注册后发送欢迎邮件,将邮件发送任务放入队列,由专门的邮件服务异步处理。
- 系统解耦:消息队列作为中间层,使得各系统或模块之间无需直接调用,通过消息传递实现耦合的最小化,便于系统的扩展与维护。如:电商平台下单后,订单系统、库存系统、物流系统通过消息队列通信,避免模块之间强依赖。
- 流量削峰(削峰填谷):在高并发场景下,将突发的请求流量写入队列中,后台服务按自身处理能力从队列中逐步拉取处理,避免系统瞬时压力过大导致崩溃。如:秒杀活动中,用户下单请求进入队列,后端按顺序处理订单,避免数据库或服务被瞬间打垮。
- 日志处理:将系统产生的日志消息发送到消息队列中,由专门的日志消费程序进行存储、分析或异步处理,提高主系统性能,便于实现日志中心化管理。如:Web 服务将访问日志发送到 Kafka,由日志系统统一消费并存入 Elasticsearch。
二、Kafka 集群搭建
为了简化服务配置,这里通过 docker 构建一个包含 3个 Kafka Broker + 1个 ZooKeeper 的集群,docker-compose.yml 配置文件:
services:zookeeper:image: zookeeper:3.7container_name: zookeeperports:- "2181:2181"environment:ZOO_MY_ID: 1ZOO_PORT: 2181kafka1:image: confluentinc/cp-kafka:latestcontainer_name: kafka1ports:- "9091:9091"depends_on:- zookeeperenvironment:KAFKA_BROKER_ID: 1KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://192.168.18.137:9091KAFKA_INTER_BROKER_LISTENER_NAME: PLAINTEXTkafka2:image: confluentinc/cp-kafka:latestcontainer_name: kafka2ports:- "9092:9092"depends_on:- zookeeperenvironment:KAFKA_BROKER_ID: 2KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://192.168.18.137:9092KAFKA_INTER_BROKER_LISTENER_NAME: PLAINTEXTkafka3:image: confluentinc/cp-kafka:latestcontainer_name: kafka3ports:- "9093:9093"depends_on:- zookeeperenvironment:KAFKA_BROKER_ID: 3KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://192.168.18.137:9093KAFKA_INTER_BROKER_LISTENER_NAME: PLAINTEXTkafka-ui:image: provectuslabs/kafka-ui:latestcontainer_name: kafka-uiports:- "9090:8080"depends_on:- kafka1- kafka2- kafka3environment:- KAFKA_CLUSTERS_0_NAME=local-kafka- KAFKA_CLUSTERS_0_BOOTSTRAPSERVERS=kafka1:9091,kafka2:9092,kafka3:9093
启动集群:
PS C:\Users\atreus\DockerProjects\KafkaCluster> docker-compose up -d
[+] Running 5/5✔ Container zookeeper Started 0.2s ✔ Container kafka1 Started 0.6s ✔ Container kafka3 Started 0.4s ✔ Container kafka2 Started 0.5s ✔ Container kafka-ui Started 0.8s
PS C:\Users\atreus\DockerProjects\KafkaCluster> docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
c478dfa1cd7b provectuslabs/kafka-ui:latest "/bin/sh -c 'java --…" 11 minutes ago Up 11 seconds 0.0.0.0:9090->8080/tcp kafka-ui
4438f682c119 confluentinc/cp-kafka:latest "/etc/confluent/dock…" 3 hours ago Up 11 seconds 0.0.0.0:9092->9092/tcp kafka2
23ddef90230d confluentinc/cp-kafka:latest "/etc/confluent/dock…" 3 hours ago Up 11 seconds 9092/tcp, 0.0.0.0:9093->9093/tcp kafka3
3f412db6a68d confluentinc/cp-kafka:latest "/etc/confluent/dock…" 3 hours ago Up 11 seconds 0.0.0.0:9091->9091/tcp, 9092/tcp kafka1
927d4bc46bc0 zookeeper:3.7 "/docker-entrypoint.…" 3 hours ago Up 12 seconds 2888/tcp, 3888/tcp, 0.0.0.0:2181->2181/tcp, 8080/tcp zookeeper
PS C:\Users\atreus\DockerProjects\KafkaCluster> docker exec -it zookeeper bash
root@927d4bc46bc0:/apache-zookeeper-3.7.2-bin# bin/zkCli.sh -server localhost:2181
Connecting to localhost:2181
...
Welcome to ZooKeeper!
...
[zk: localhost:2181(CONNECTED) 0] ls /brokers/ids
[1, 2, 3]
[zk: localhost:2181(CONNECTED) 1] get /brokers/ids/1
{"features":{},"listener_security_protocol_map":{"PLAINTEXT":"PLAINTEXT"},"endpoints":["PLAINTEXT://3f412db6a68d:9091"],"jmx_port":-1,"port":9091,"host":"3f412db6a68d","version":5,"timestamp":"1748079296428"}
[zk: localhost:2181(CONNECTED) 2]
ls /brokers/ids 输出 [1, 2, 3] 表明三个 Kafka 应用已经启动成功。
关闭集群:
PS C:\Users\atreus\DockerProjects\KafkaCluster> docker-compose stop
[+] Stopping 5/5✔ Container kafka-ui Stopped 2.6s ✔ Container kafka2 Stopped 10.5s ✔ Container kafka1 Stopped 1.5s ✔ Container kafka3 Stopped 1.7s ✔ Container zookeeper Stopped 0.8s
PS C:\Users\atreus\DockerProjects\KafkaCluster>
三、消息测试
创建 topic:
[appuser@3f412db6a68d bin]$ kafka-topics --create --bootstrap-server localhost:9091 --topic test_topic
WARNING: Due to limitations in metric names, topics with a period ('.') or underscore ('_') could collide. To avoid issues it is best to use either, but not both.
Created topic test_topic.
[appuser@3f412db6a68d bin]$ sh /bin/kafka-topics --list --bootstrap-server localhost:9091
test_topic
[appuser@3f412db6a68d bin]$
生产消息:
sh /bin/kafka-console-producer --broker-list localhost:9091 --topic test_topic
消费消息:
sh /bin/kafka-console-consumer --bootstrap-server localhost:9091 --topic test_topic --from-beginning
四、Java API
生产者:
public class KafkaProducerTest {private static final Logger log = LoggerFactory.getLogger(KafkaProducerTest.class);public static void main(String[] args) throws ExecutionException, InterruptedException {// 配置Properties props = new Properties();props.put("bootstrap.servers", "localhost:9091");props.put("acks", "all");props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");// 创建生产者KafkaProducer<String, String> producer = new KafkaProducer<>(props);// 发送消息for (int i = 0; i < 10; i++) {String now = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss.SSS").format(new Date());ProducerRecord<String, String> record = new ProducerRecord<>("test_topic", Integer.toString(i), now);Future<RecordMetadata> future = producer.send(record);future.get();log.info("Sent record: " + record);}// 关闭生产者producer.close();}
}
消费者:
public class KafkaConsumerTest {private static final Logger log = LoggerFactory.getLogger(KafkaConsumerTest.class);public static void main(String[] args) {// 配置Properties props = new Properties();props.put("bootstrap.servers", "localhost:9091");props.put("group.id", "test");props.put("enable.auto.commit", "true");props.put("auto.commit.interval.ms", "1000");props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");// 创建消费者KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);// 接收消息consumer.subscribe(Arrays.asList("test_topic"));while (true) {ConsumerRecords<String, String> records = consumer.poll(100);for (ConsumerRecord<String, String> record : records) {log.info(record.toString());}}}
}
五、Kafka 相关概念
| 概念 | 说明 |
|---|---|
| Broker | Kafka 集群中的一个服务器节点,负责接收、存储和转发消息。每个 Broker 可以处理多个 Topic 的数据。Kafka 集群通常包含多个 Broker 实现负载均衡和容错。 |
| Producer | 消息的发送者,负责将数据发送到指定的 Topic。支持同步/异步、分区策略、批量发送等功能。 |
| Consumer | 消息的接收者,从 Topic 中拉取消息进行处理。通常属于某个 Consumer Group,以支持并行消费。 |
| Topic | Kafka 中消息的逻辑分类,每条消息必须写入某个 Topic。一个 Topic 可以包含多个 Partition,用于分布式扩展。 |
| Partition | Topic 的物理划分,一个 Partition 是一个有序的、不可变的消息序列。消息在分区中通过 Offset 定位。Partition 的数量影响并发度和吞吐量。 |
| Replica | 分区的副本。用于高可用性,每个 Partition 有一个 leader 和多个 follower。leader 处理读写请求,follower 进行数据同步,客户端只与 Leader 通信。 |
| Consumer Group | 消费者组。一个组内的多个 Consumer 共同消费一个 Topic 的不同 Partition。实现负载均衡和容错。每个 Partition 在同一个 Consumer Group 内只能被一个 Consumer 消费,但一个 Consumer 可以消费多个 Partition。 |
| Offset | 消息在分区中的唯一编号,表示消费位置。消费者使用 offset 记录进度,可以手动或自动提交。Kafka 默认不会删除已消费的数据,而是根据保留策略保留一段时间。 |
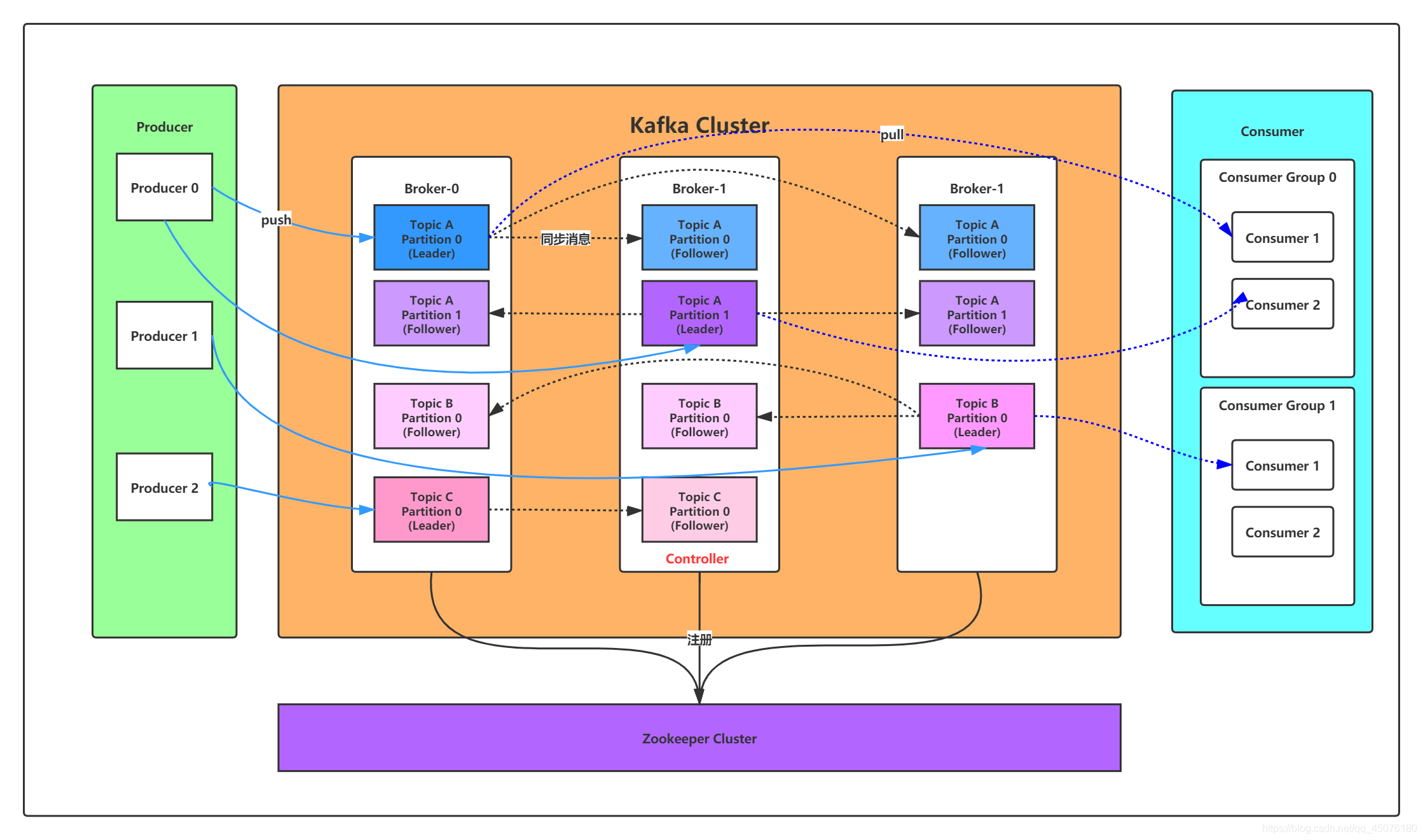
图片来自:https://blog.csdn.net/qq_45076180/article/details/111344822
六、Kafka 幂等性
Kafka 的幂等性是指 即使 producer 发生重试,也能保证消息只会被写入一次(Exactly Once),不会出现重复数据。
6.1 Kafka 幂等性的背景
在以下场景中,Kafka Producer 可能会重复发送消息:
- 由于网络抖动或超时,producer 没有收到 ack,主动重发。
- Leader 崩溃,producer 发送到了新的 leader。
- Producer 重启,重复发送缓冲区中的消息。
默认情况下,Kafka 的 Producer 是 at least once(至少一次)语义,可能会出现重复消息。
6.2 Kafka 幂等性机制
Producer 会为每个消息自动带上:
PID(Producer ID)标识某个 producer 实例。Sequence Number标识消息在当前 partition 中的顺序。- Broker 会为每个
(PID, Partition)记录最后一个成功的Sequence Number。 - 重试发送时,如果发现 sequence number 是重复的,就丢弃消息,不写入。
开启幂等性只需设置:
props.put("enable.idempotence", "true");
七、分区和副本
7.1 生产者分区写入策略
Kafka 中的每个 Topic 可以被划分为多个 Partition(分区),Producer 在发送消息时需要决定消息写入哪个分区。Kafka 提供了多种分区策略,常见的有以下几种:
1️⃣ 轮询分区策略
- 特点:默认策略(当 key 为空时),Producer 会将消息轮流发送到各个分区,实现负载均衡。
- 使用场景:不需要按照某个业务 key 做分区,只需要均匀分配消息。
- 缺点:同一类型的消息可能被写入不同分区,消息有序性无法保证。
new ProducerRecord<>("topic", null, value); // key 为 null
2️⃣ 随机分区策略
- 特点:Kafka 在早期版本支持的方式,Producer 会随机选择一个分区。现代版本中,如果设置了 key 为 null,通常实际使用的是轮询策略。
- 缺点:随机性导致分布不均衡的可能性较大。
3️⃣ 按 Key 分区策略
- 特点:Kafka 使用 key 的 hash 值对分区数取模进行分区分配:
partition = hash(key) % numPartitions - 优点:确保相同 key 的消息总是发送到相同的分区,从而可以保证有序性。
- 缺点:可能会导致分区数据倾斜(分区过热)。同时由于 Kafka 的消费是以分区为单位的,一个分区在一个时刻只能被一个 Consumer 消费,因此按 Key 分区也会限制消息并行消费能力。
- 使用场景:订单、用户行为等需要按业务 key 保序的场景。
new ProducerRecord<>("topic", "key", value); // 相同 key 的消息落在同一分区
4️⃣ 自定义分区策略
- 特点:开发者可以实现
org.apache.kafka.clients.producer.Partitioner接口,定义自己的分区规则。 - 使用场景:需要复杂逻辑(如动态路由、权重、地理位置等)来决定消息投递的分区。
示例:
public class MyCustomPartitioner implements Partitioner {@Overridepublic int partition(String topic, Object key, Object value, int numPartitions) {// 根据 key 或 value 实现自定义逻辑if (key.toString().startsWith("vip")) {return 0; // vip 用户全部写入分区 0} else {return 1;}}@Overridepublic void close() {}@Overridepublic void configure(Map<String, ?> configs) {}
}
然后在配置中指定:
props.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, "atreus.ink.MyCustomPartitioner");
7.2 Rebalance 机制
在 Kafka 中,一个 Topic 通常被划分为多个 Partition,而一个 Consumer Group 中的多个消费者实例会分配到不同的分区进行消费。为了确保消费的负载均衡和分区的唯一消费(即一个分区同一时刻只能被一个消费者消费),Kafka 使用 Rebalance 来动态分配分区。Rebalance 期间所有消费者会暂停拉取数据,会导致短暂的消费中断,对于低延迟要求的系统,这是不可忽略的开销。
Kafka 中的 Rebalance 通常会在以下几种情况发生:
- Consumer Group 中有新 Consumer 加入。
- 已有 Consumer 宕机或主动退出。
- 订阅的 Topic 数量变化。
- Topic 中 Partition 数量发生变化(如扩容)。
- 手动触发,如调用
unsubscribe()或subscribe()重新订阅 Topic。
7.3 消费者分区消费策略
1️⃣ RangeAssignor
每个消费者按 Topic 排序后顺序分配一段连续的分区。
C1 -> 分区 0, 1, 2
C2 -> 分区 3, 4, 5
2️⃣ RoundRobinAssignor
将所有 Topic 的分区合并为一个列表,然后按轮询方式分配给消费者。
C1 -> 分区 0, 2, 4
C2 -> 分区 1, 3, 5
3️⃣ StickyAssignor
基于 RoundRobin 的改进,尽可能维持上次分配结果,保持分区与消费者的粘性关系,尽量减少分区迁移,从而减少因频繁 Rebalance 导致的消费中断。
7.4 副本的 ACK 机制
生产者在发送消息时,可以设置 acks 参数来控制 Kafka 何时认为消息写入成功:
acks 值 | 含义 | 优点 | 风险或劣势 |
|---|---|---|---|
0 | 不等待任何 Broker 的确认,发送后即认为成功。 | 最高吞吐,最低延迟 | 无法保证消息是否成功写入 |
1 | 只等待 Leader 副本写入成功即可返回 ACK。 | 较快,适度可靠 | 如果 Leader 写入后崩溃,Follower 可能未同步 |
-1 或 all | 等待所有 ISR(in-sync replicas)中的副本都写入成功后才 ACK。 | 最强可靠性,避免数据丢失 | 延迟较高,吞吐相对较低 |