CLIP、DALL·E 1的解读
0. 前言
之前的图像分类任务都是如果训练1000个类别,那预测的就是这1000个类别的概率,无法拓展,新增类别还需要重新训练,重新标注,太麻烦了,能不能一劳永逸呢?
而GPT最大的特点就是zero-shot,这个在文本任务中是有极强的泛化能力的,在视觉中,能不能把视觉模型也尽可能做出zero-shot的感觉呢?
Constrastive language-image pre-traning == CLIP 利用文本的监督信号训练一个迁移能力很强的视觉模型。这件事肯定不好做,网络结构和训练策略都会不一样。
CLIP的论文指出,17年就开始有这些方法了,但是没获得太多关注,当时类似的方法效果都很差,openai说明不是方法不行,而是资源没到位,氪金就完事了,openai直接大力出奇迹。
CLIP在完全不使用 ImageNet 中的数据进行训练的前提下,直接zero-shot的结果与ResNet50 在128w ImageNet 数据训练后的结果一样。传闻CLIP使用了4亿个数据对和文本进行训练的。现在CLIP的下游任务已经很多了,GAN,检测,分割等等。
1. 训练过程
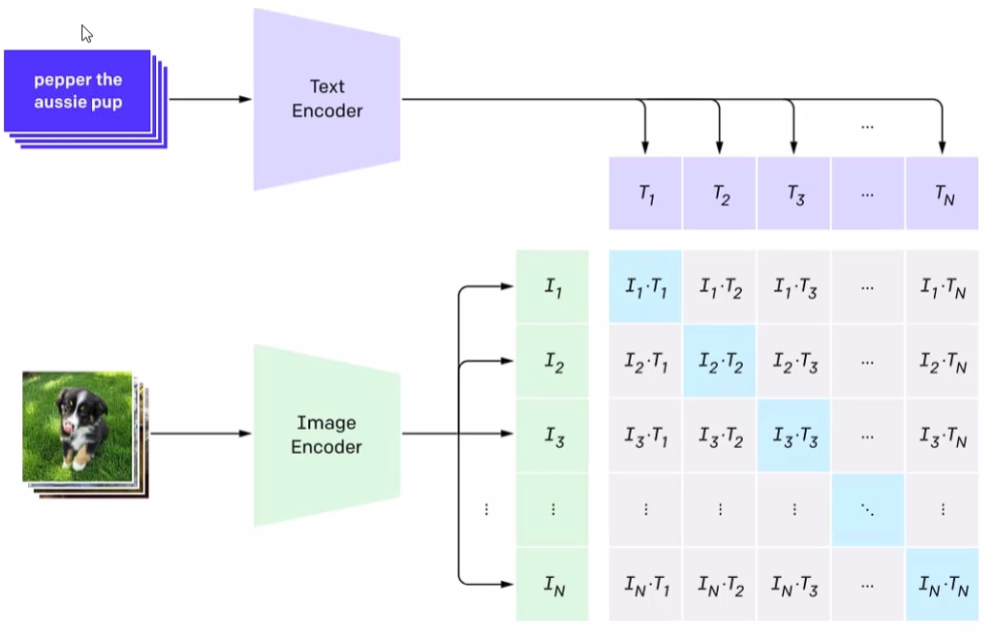
比如我们的数据集是左下角的图片数据,每个图像都有一个对应的描述文本。
通过Encoder把图像的特征提取出来,转化为向量;文本也通过编码器编码成特征向量。
现在要通过对比学习:
- 正样本:图像是一条狗,文本描述也是说"这是一条狗"
- 负样本:图像是一条狗,文本描述也是说"这是一架飞机"
在训练中,让对角线上的自己和自己的描述相似度最高,非对角线就是低的,N个数据的话,正样本就有N个,负样本就是N²-N个。我们希望的是模型能够预测出一张图片之中是什么内容,而不是预测类别的概率,现在是学到了本质,这张图中到底是个什么东西。
2. 如何进行推理
训练好模型之后怎么用模型输出结果呢?
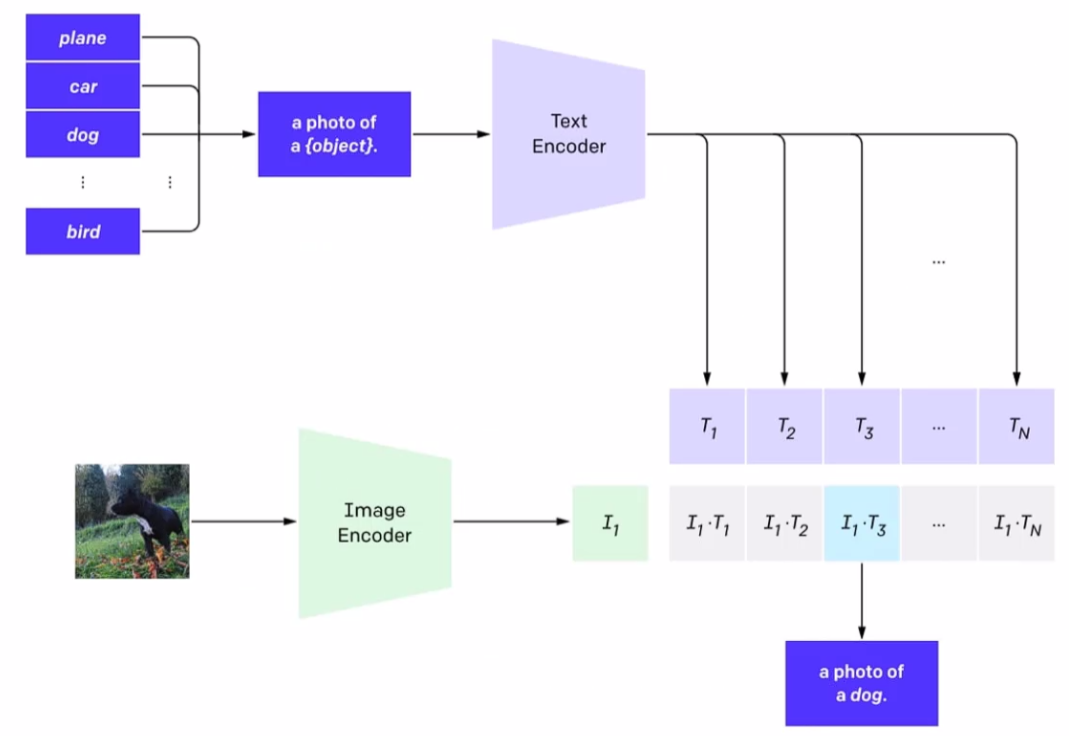
输入一张图像,经过encoder提取出向量,那怎么能得知预测的结果呢?在文本中给出所有可能的文本信息,他会计算图像特征和所有文本信息中的相似度,这个文本就可以随便写,想写多少都行,在众多文本中,算出来和“一张狗的图片”相似度最高,ok,得出结果了。
那么所需的就是,图像,模型,文本提示,如果文本提示中没有相关性比较好的,那可能最终结果就是很离谱的,所以最终结果和提示的质量是密切相关的。
2.1 简单看一下代码样例

比如我们这里有一张鬼的图片,我们直接用openai预训练的CLIP模型去预测一下看看会出现什么结果:
from PIL import Image
import requests
from transformers import CLIPProcessor, CLIPModel # 拿到预训练模型
model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32") # openai/clip-vit-base-patch32
processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
# url = "http://images.cocodataset.org/val2017/000000039769.jpg"
# image = Image.open(requests.get(url, stream=True).raw)
image = Image.open('gui.jpg')# text自己定,写什么都行,当然也可以写完整,中文是不行的,英文才可
text = ['God', 'ghost', 'human']
inputs = processor(text=text, images=image, return_tensors="pt", padding=True)outputs = model(**inputs)
logits_per_image = outputs.logits_per_image # this is the image-text similarity score
probs = logits_per_image.softmax(dim=1) # we can take the softmax to get the label probabilities
# 遍历文本中的类别和取得的概率
for i in range(len(text)):print(text[i], ':', probs[0][i])

真能预测出来ghost的概率最高,没有其他任何微调。
同理一张金毛的图片也可以这样预测。
text = ['golden retriever', 'teddy', 'husky']
CLIP为了避免偏见和隐私,在数据集中把带有歧义的都剔除掉了。
预测的时候提示也很重要,描述的内容多一点,提示的全面,结果也会提升,例如: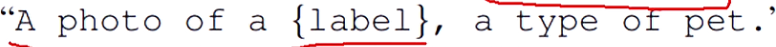
3. 实验对比
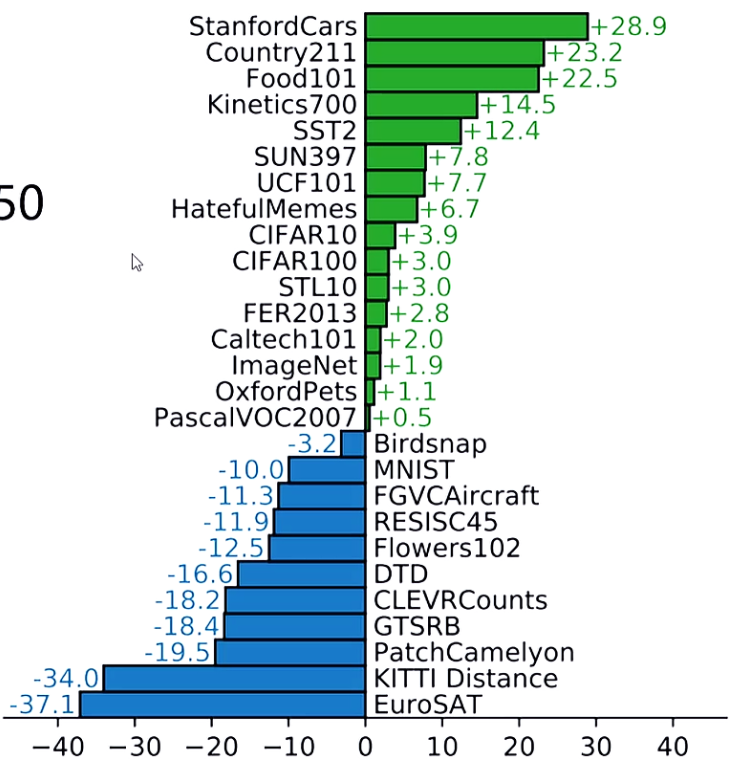
不同数据集只训练最后一层FC来微调,在Mnist中效果很一般,论文中说是可能因为这种数据是人工合成的。
4. DALL-E
4.1 简介
这东西是干什么的呢?这个都是有论文的,但是我们看技术博客就可以。
既然我们在上面能够构建图片和文字之间的关系,那能不能通过文字反向生成图片呢?

想写什么东西都可以,把文本做一个编码,根据这个编码生成图片
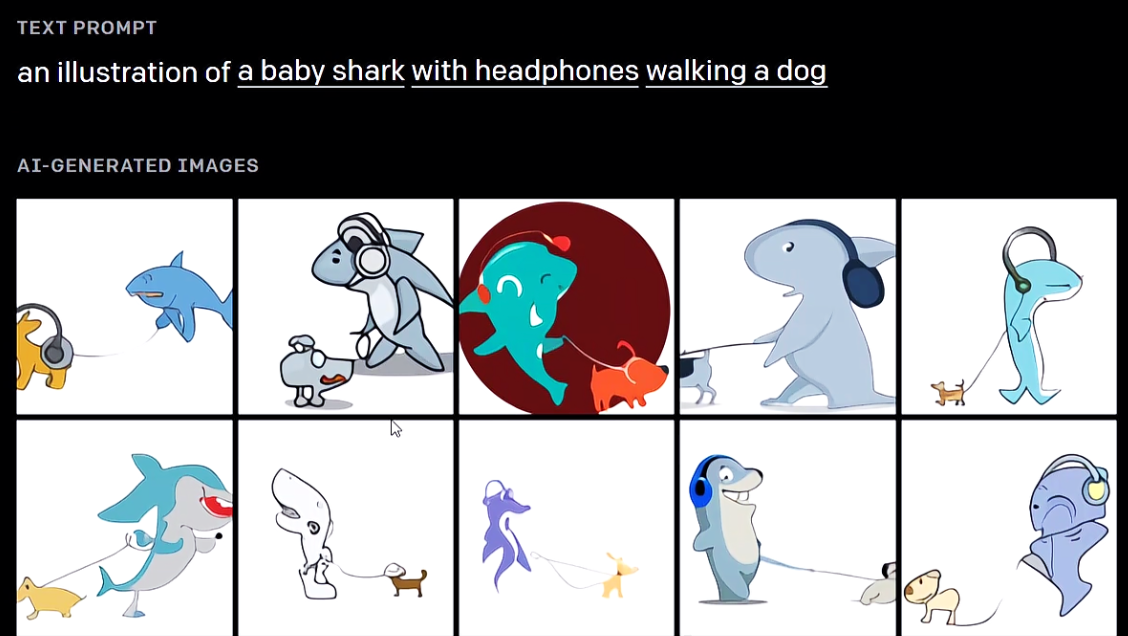
首先得熟悉下VQGAN,它相当于生成器,CLIP相当于判断器(看生成结果与描述是否相同)。
图像如何表示,NLP中我们对文本向量化,我们能否对图像离散向量化?
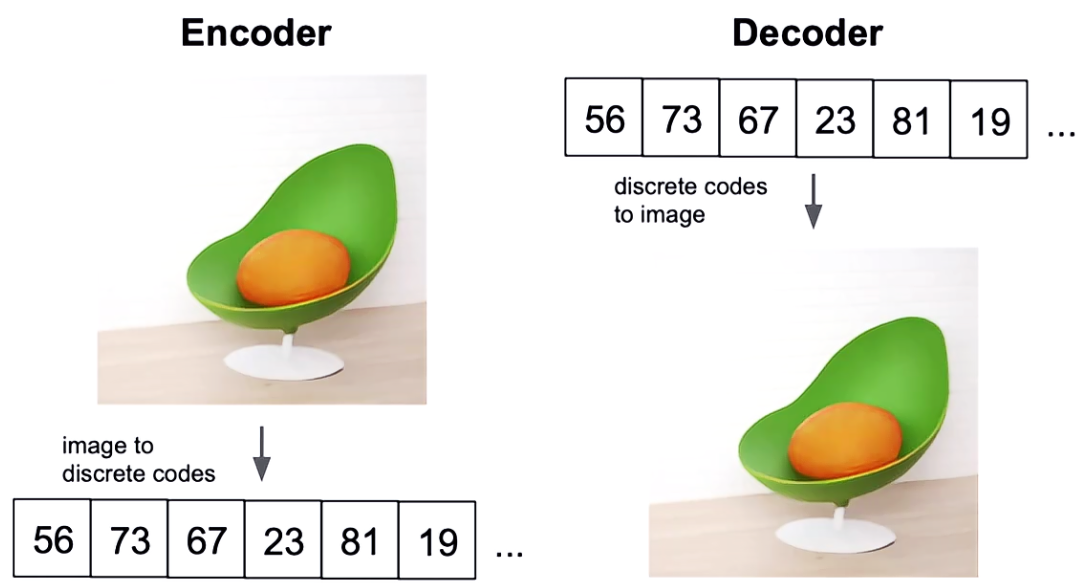
怎么做离散化呢?通过 codebook,首先特征这个东西肯定是连续的一些值,组合在一起的,那就得把特征离散化再整合。
输入一张图像,图像就是各种像素值,这时我们有一个8000个形容词的特征映射表codebook,把图像中的每个位置都映射成一个唯一的特征映射表中的值,表是固定的,图像每个位置只能在表中选一个。
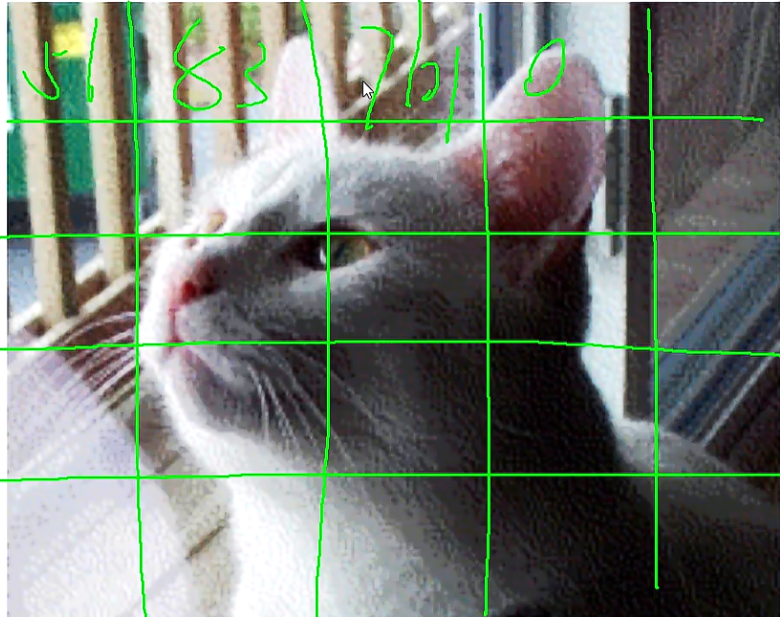
那构建图像就是根据文本去找codebook中的特征去构建。
4.2 VQGAN大致流程
图像经过编码器得到特征,然后根据相似度得到离散特征(其实就是查codebook)。
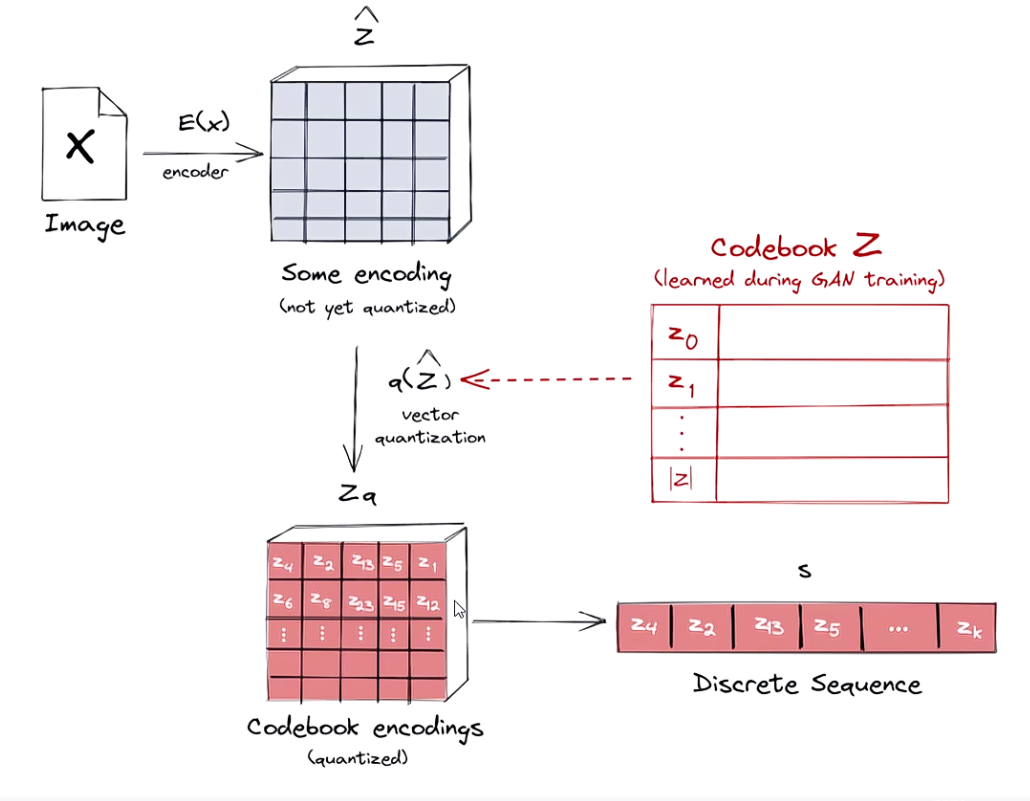
DALL·E是要生成一个结果,那么也是根据特征序列逐步生成,类似GPT,一点一点生成,生成过程中考虑他们之间的关系,但并不是全局特征都会用到,论文中指的是邻近的特征:

VQGAN相当于给DALL·E提供了基本出发点。
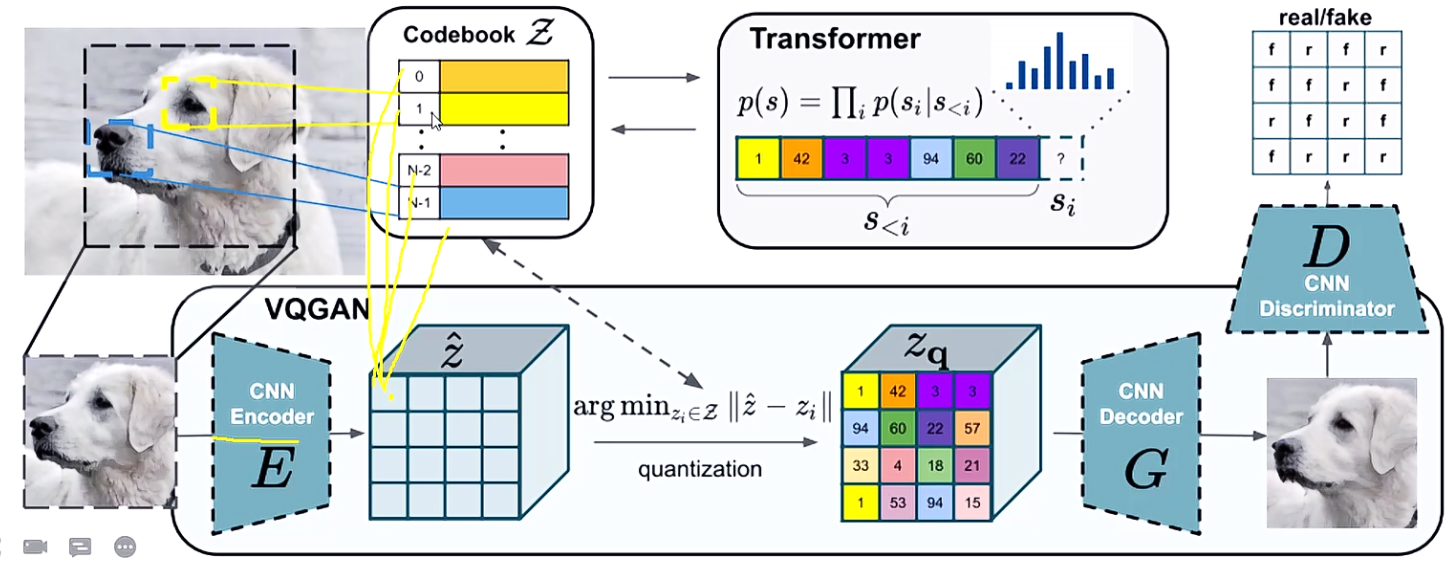
codebook也是学出来的,图像提取特征之后会和codebook中每个特征码计算相似度,和谁最相关就是谁,之后再解码得到真实的图片。
在训练codebook时,也是用到了transformer,1号就会考虑和他离得近的code,他们之间也会考虑互相之间的关系,这可以帮助优化codebook。
当然VQGAN+CLIP是一个民间的项目,距离DALL·E还是有很大差距的,生成的挺抽象的。

4.3 DALL·E
DALL·E 1:用 dVAE/VQ-VAE 把图片编码成离散 token,然后用 autoregressive Transformer 从文本 token 直接生成图像 token(端到端训练的生成器)。
与 VQGAN 类似,DALL-E 1 的训练分为两个阶段,第一阶段训练 dVAE(论文中叫 dVAE,实际就是 VQVAE)和 codebook,来作为图片 tokenizer,第二阶段训练一个 12B 的decoder-only 的 Transformer 自回归模型,作为 prior 模型。
DALL·E 2:使用了扩散模型,方法与 OpenAI 之前另一篇扩散模型的工作 GLIDE 非常相似。在此基础上,为了实现更好的文本引导,OpenAI 还结合了自家提出的 CLIP 模型,可以生成 4xDALL-E 1 大小的图像。
后续我们讲了扩散之后再研究 DALL·E 2。
5 DALL·E 2
目前已经出到了DALL·E 3,论文并没有完整地介绍整个生图系统所使用的技术