【论文速读】LLM Compiler:并行函数调用的新范式
1st author
- Sehoon Kim
- Suhong Moon
paper
- [2312.04511] An LLM Compiler for Parallel Function Calling
code
- [SqueezeAILab/LLMCompiler: ICML 2024] LLMCompiler: An LLM Compiler for Parallel Function Calling
5. 总结 (结果先行)
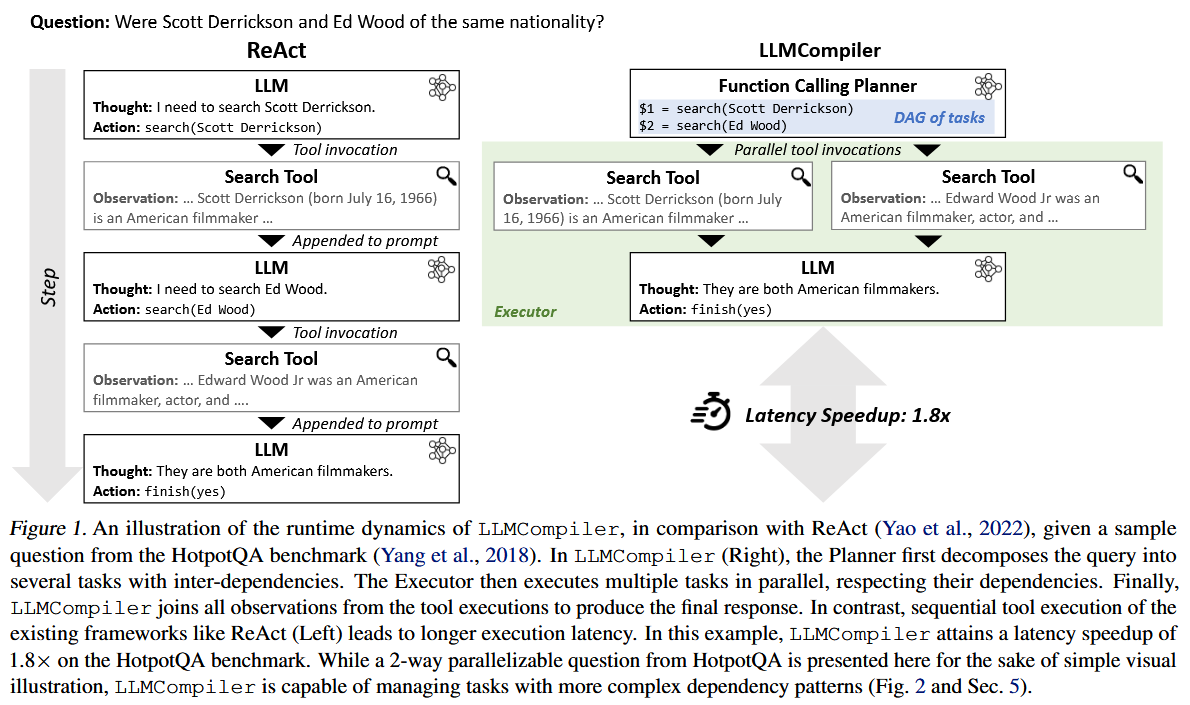
这篇论文的核心思想,是将经典的编译器优化理论应用于大型语言模型 (LLM) 的函数调用 (Function Calling) 过程。传统方法如 ReAct 像一个解释器,逐行执行 “思考-行动” 循环,导致在可并行任务上效率低下。LLMCompiler 则扮演了编译器的角色:它首先进行一次性的 “编译”——让 LLM Planner 分析整个问题,生成一个包含所有任务及其依赖关系的有向无环图 (DAG),然后将图中无依赖的任务并行执行。
这一范式转变带来了显著的工程价值:
- 性能:通过并行化,实现了高达 3.7x 的延迟降低和 6.7x 的成本 (token消耗) 节省。
- 鲁棒性:通过预先规划,有效规避了 ReAct 等框架中常见的错误模式,如不必要的循环和过早停止,从而提升了 ~9% 的准确率。
- 通用性:该框架不仅适用于简单的并行任务,还能通过动态重规划 (Dynamic Replanning) 机制处理需要根据中间结果调整执行路径的复杂任务,并兼容开源模型 (如 LLaMA-2)。
LLMCompiler 是智能体 (Agent) 架构从单线程、顺序执行向多线程、事件驱动演进的关键一步。它将 LLM 的角色从一个纯粹的"思考者"提升到了一个"规划者"或"任务编排者",而将具体的执行和调度交给了更高效、更廉价的确定性组件。这预示着未来复杂 Agent 系统的构建将更多地借鉴分布式系统和操作系统的设计思想。
1. 思想
-
大问题:
- 当前的 LLM Agent 框架 (如 ReAct) 以顺序 (sequential) 的方式调用工具。对于一个需要多次独立查询的任务,这种模式会因多次 LLM 调用和串行等待而产生巨大的延迟和成本。
- 如何让 LLM Agent 高效地执行包含内在并行性的复杂任务?
-
小问题:
- 如何自动识别一个复杂任务中哪些子任务可以并行执行,哪些存在依赖关系?
- 如何管理任务间的依赖,确保一个任务的输出能正确地作为另一个任务的输入?
- 如何在不牺牲规划能力的前提下,最小化昂贵的 LLM 调用次数?
- 对于执行路径依赖于中间结果的动态任务,如何支持计划的调整和重新生成?
-
核心思想: 编译,而非解释 (Compilation, not Interpretation)
- 规划即编译 (Planning as Compilation): 模仿编译器的工作原理。引入一个 Planner 模块 (由 LLM 驱动),它不执行任何操作,而是一次性地将用户的自然语言请求“编译”成一个任务依赖图 (DAG)。这个图明确了所有需要执行的函数调用以及它们之间的数据流。
- 依赖管理 (Dependency Management): 在 DAG 中,后续任务使用占位符变量 (e.g.,
$1,$2) 来引用前置任务的输出。这是一种经典的数据流表示方法。 - 并行执行与调度 (Parallel Execution & Scheduling): 引入两个非 LLM 的轻量级组件:
- Task Fetching Unit: 一个简单的调度器,负责监控 DAG,将所有依赖项已满足的 “就绪” 任务分发出去。
- Executor: 一个执行器,维护一个工作线程池,并发执行来自调度器的任务。
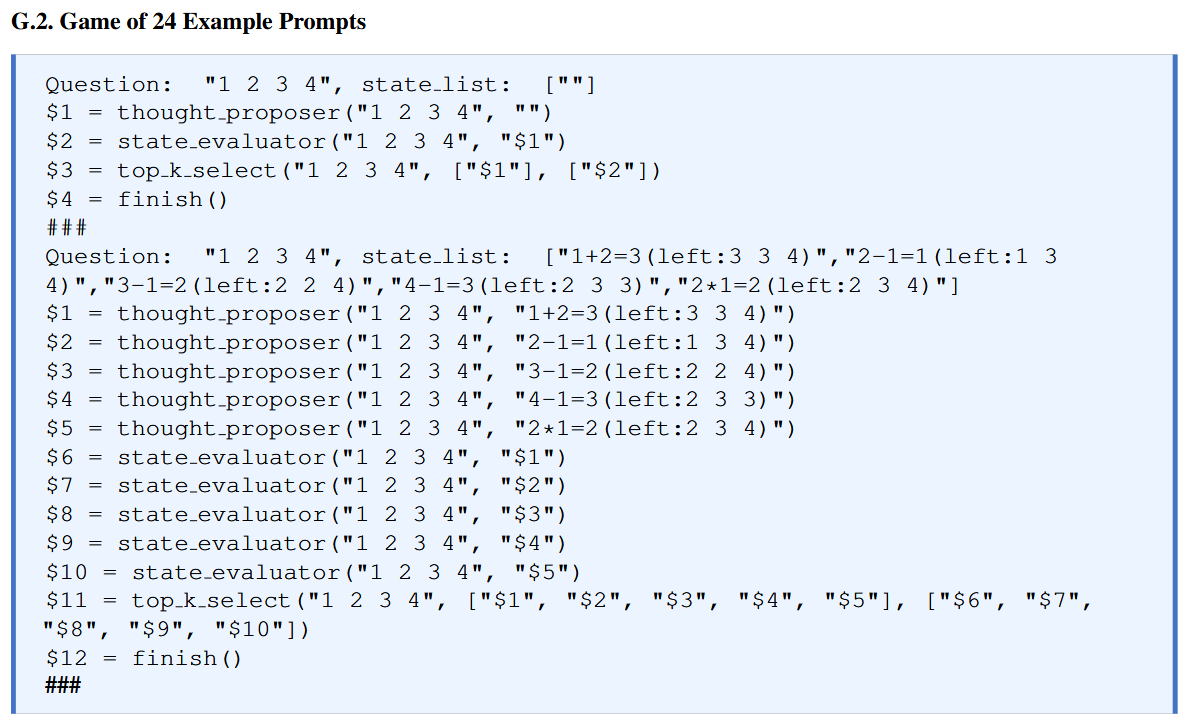
- 动态重规划 (Dynamic Replanning): 对于无法一次性静态规划的复杂任务 (如 Game of 24),
LLMCompiler设计了一个反馈循环。当执行完一个阶段的计划后,如果问题未解决,会将中间结果反馈给 Planner,重新生成下一阶段的计划,实现了动态和迭代式的规划。
2. 方法
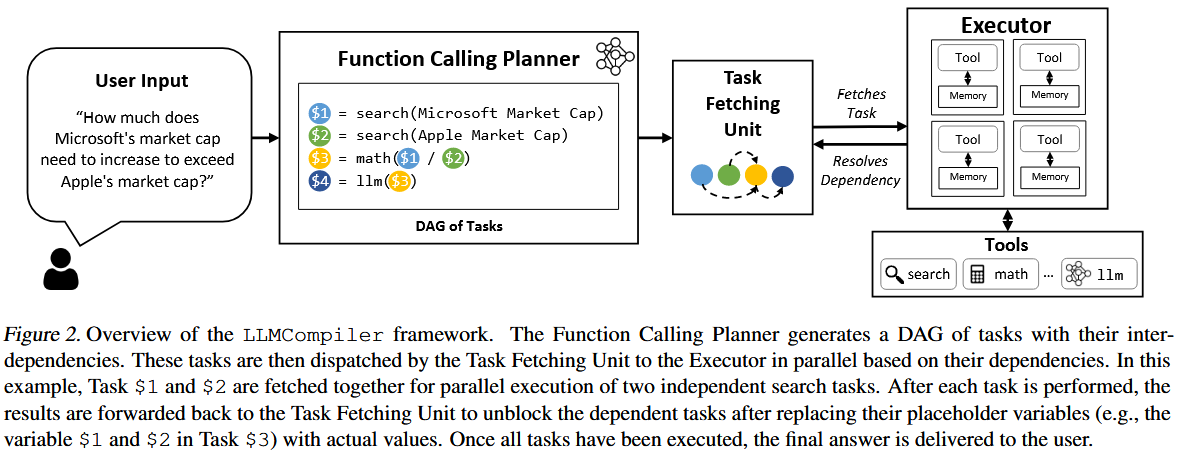
LLMCompiler 的架构由三个核心组件构成,优雅地解耦了规划 (高成本的 LLM 工作) 与执行 (可并行的确定性工作)。
1. Function Calling Planner (规划器)
这是整个框架中唯一需要强大 LLM 的地方。它的职责是将用户的自然语言查询转换为结构化的执行计划。
- 输入: 用户问题 (自然语言) 和一系列可用的工具定义。
- 输出: 一个任务依赖图 (DAG),通常以文本形式表示。每个节点代表一个函数调用,边代表数据依赖。
- 机制: Planner 通过精心设计的 Prompt Engineering,引导 LLM 生成如下格式的计划。例如,对于问题 “微软市值需要增加多少才能超过苹果?”:
$1 = search("Microsoft Market Cap") $2 = search("Apple Market Cap") $3 = math("$2 / $1") $4 = finish($3)$1和$2是两个可以并行执行的search任务。$3依赖于$1和$2的输出,所以必须在它们完成后执行。"$1"和"$2"就是占位符。$4是最终的聚合步骤。
2. Task Fetching Unit (任务获取单元)
这是一个轻量级的调度逻辑单元,无需 LLM。它像 CPU 中的指令提取单元一样工作。
- 职责:
- 解析 DAG: 接收 Planner 生成的计划,并将其解析为内部的数据结构。
- 分派就绪任务: 持续扫描 DAG,找出所有入度为零的节点 (即没有未完成的依赖项),并将这些任务发送给 Executor。
- 更新依赖: 当一个任务 (如
$1) 由 Executor 完成后,该单元会接收到结果。它会将结果值替换掉 DAG 中所有引用$1的占位符,然后重新检查是否有新的任务变为 “就绪” 状态 (如$3)。
3. Executor (执行器)
这是实际执行工具调用的工作单元,也无需 LLM。
- 职责:
- 维护工作池: 管理一个线程池或进程池。
- 异步执行: 从 Task Fetching Unit 接收任务,并将其分配给一个空闲的工作单元异步执行。这保证了多个独立的
search或math调用可以同时进行。 - 返回结果: 任务完成后,将输出结果连同其任务 ID (如
$1) 一并返回给 Task Fetching Unit。
4. 数学建模:延迟分析
该论文在附录中提供了对延迟的清晰数学建模,这深刻揭示了其性能优势的来源。
-
ReAct 延迟模型:
TR=∑i=1N(TPR(Pi)+TE(Ei))T_R = \sum_{i=1}^{N} (T_P^R(P_i) + T_E(E_i))TR=∑i=1N(TPR(Pi)+TE(Ei))- TRT_RTR: ReAct 的总延迟。
- NNN: 任务中的总步骤数。
- TPR(Pi)T_P^R(P_i)TPR(Pi): 在第 iii 步进行规划的延迟 (一次 LLM 调用)。
- TE(Ei)T_E(E_i)TE(Ei): 在第 iii 步执行工具的延迟。
- 关键在于这是一个累加过程,规划和执行的延迟在每个步骤中线性叠加。
-
LLMCompiler 延迟模型 (对于可完全并行的 N 个任务):
TC=TPC+maxk=1,...,NTE(Ek)T_C = T_P^C + \max_{k=1,...,N} T_E(E_k)TC=TPC+maxk=1,...,NTE(Ek)- TCT_CTC: LLMCompiler 的总延迟。
- TPCT_P^CTPC: 一次性的总规划延迟 (一次 LLM 调用生成整个 DAG)。
- maxk=1,...,NTE(Ek)\max_{k=1,...,N} T_E(E_k)maxk=1,...,NTE(Ek): 所有并行任务中,耗时最长的那个任务 (关键路径) 的执行延迟。
- 模型的差异一目了然:ReAct 的延迟与任务数 NNN 成正比,而
LLMCompiler的延迟主要由最慢的单个任务决定,规划成本是一个固定的初始开销。
3. 优势
- 并行化: 核心优势。通过预先识别并同时执行独立任务,从根本上解决了顺序执行的瓶颈。
- 成本效益: 将多次零散的 LLM 调用(ReAct 中的 “Thought”)合并为一次集中的规划调用,极大地减少了与 LLM API 交互的总 token 数量和请求开销。
- 准确性提升:
- 避免中间干扰: ReAct 在每一步都会将工具的观察结果追加到上下文中,这可能"污染" LLM 的后续推理。
LLMCompiler将所有观察结果收集完毕后,再交给最终的finish步骤进行聚合,上下文更干净。 - 规避常见故障: 有效地解决了 ReAct 中因无法正确解析状态而导致的重复调用或过早停止问题。
- 避免中间干扰: ReAct 在每一步都会将工具的观察结果追加到上下文中,这可能"污染" LLM 的后续推理。
- 框架通用性:
- 模型无关: 设计上不依赖于特定模型,实验证明其在 GPT 系列和 LLaMA-2 上均有效。
- 任务灵活性: 通过动态重规划,其适用性从静态 DAG 任务扩展到了需要迭代探索的动态任务。
4. 实验
实验设计覆盖了从简单到复杂的多种函数调用模式,全面验证了 LLMCompiler 的性能和鲁棒性。
- 实验设置:
- 基线: 主要与 ReAct 进行比较,同时也与 OpenAI 的原生并行函数调用功能进行了对比。
- 模型: 使用了闭源的 GPT-3.5/4 和开源的 LLaMA-2 70B。
- Benchmark:
- 简单并行 (Embarrassingly Parallel):
- HotpotQA: 比较两个实体,需要两次独立的搜索。
- Movie Recommendation: 比较多部电影,需要八次独立的搜索。
- 复杂依赖 (Complex Dependencies):
- ParallelQA (自建): 需要多次搜索,然后将结果用于后续的数学计算,形成了更复杂的 DAG。
- 动态重规划 (Dynamic Replanning):
- Game of 24: 一个需要通过试错和迭代来寻找解法的任务,完美契合重规划场景。
- 交互式决策 (Interactive Decision Making):
- WebShop: 模拟在线购物,需要在环境中进行多步探索以完成任务。
- 简单并行 (Embarrassingly Parallel):
- 实验结论:
- 性能全面超越: 在所有任务上,
LLMCompiler在延迟和成本方面均显著优于 ReAct。在 Movie Recommendation 这种高度并行的任务上,取得了 3.74x 的速度提升和 6.73x 的成本降低。 - 与 OpenAI 原生并行功能对比:
LLMCompiler甚至比 OpenAI 官方的并行功能更快、更省钱。论文推测这可能是因为其 Planner 的 prompt 更高效,并且避免了 OpenAI API 可能存在的额外验证开销。 - 准确性提升源于故障规避: 附录中的详细分析指出,ReAct 的准确性损失主要源于过早停止 (没完成所有必要的搜索就给出答案) 和重复调用 (陷入循环)。
LLMCompiler的静态计划从机制上避免了这些问题,带来了稳定的准确性提升。 - 开源模型赋能: 成功地将并行函数调用的能力赋予了 LLaMA-2 等开源模型,证明了该框架的普适性和价值。
- 动态规划有效: 在 Game of 24 中,
LLMCompiler比基于 Tree-of-Thoughts 的串行方法快 2.89x,证明了其在动态环境中通过并行探索状态空间来加速求解的能力。
- 性能全面超越: 在所有任务上,